
- 1VCS学习笔记——VCS编译/仿真选项_ic验证中的编译选项和仿真选项
- 2浅谈ARM Cortex-M0
- 3【Android】开机亮度问题_android开机默认亮度
- 4jmeter如何通过后置处理器提取(正则提取器、json提取器)做接口关联?_jmeter后置处理器怎么提取对象
- 5Android程序员:干到三十,我就不干了,kotlin实现接口_android kontlin 实例化接口
- 6YOLOV5学习笔记(一)——原理概述
- 7下载Windows ISO镜像的方法_windows镜像下载
- 8毕业设计:基于python的动漫电影推荐系统 大数据_python实现基于svd矩阵分解的动漫推荐系统设计
- 9远程连接PostgreSQL:配置指南与安全建议_pgsql远程连接
- 10自动驾驶芯片的算力和性能分析_自动驾驶的算力
PP-ChatOCRv2赋能金融报告信息智能化抽取,新金融效率再升级
赞
踩

数据不仅推动着金融创新,还是金融风险预警的利器,为金融监管提供有力支持。深圳市今日投资数据科技有限公司在金融数据服务与应用领域持续深耕,凭借其卓越的数据清洗与加工能力,已根据市场动态及客户需求围绕股票、基金等核心应用场景,构建了一套全面的产品体系,为金融机构和投资者提供包括数据、算法、策略及软件工程在内的一站式解决方案。
然而,随着业务的不断深入和市场的日益复杂,金融报告数据的处理与应用逐渐成为了一个新的挑战。金融报告,作为行业专家智慧的结晶,本应是投资决策的得力助手,却因其信息过载、内容冗长复杂以及数据时效性等问题,使得企业在提取和利用报告数据时面临着巨大的困难。
目前,公司对报告数据的处理主要依赖传统文本解析方法,这不仅效率低下,而且在面对复杂版本的时候易出错。在海量的报告数据中,人工提取有价值的信息无异于大海捞针,而且数据的准确性和时效性也无法得到有效保证。特别是在金融数据服务行业竞争日趋激烈的今天,如何高效、准确地处理和利用报告数据,成为了公司提升核心竞争力的关键。
深圳市今日投资数据科技有限公司正逐步从传统模式向人工智能的创新模式转型,并与百度飞桨在报告版面分析和关键信息抽取方面展开紧密合作。希望借助先进技术提升数据处理的自动化水平,减少人工干预,确保数据的准确性和时效性。助力其实现对报告版面的精准分析和信息的高效抽取,为企业内部系统和策略提供有力支持。
 场景难点
场景难点
准确提取金融报告中的各类信息,需要攻克的关键难点包括:
精准预测各类报告复杂的版面布局,以实现对报告信息的分区管理和高效整合;
精确识别报告中各类复杂版式表格信息(合并单元格、多种数据形式等),满足不同分析需求;
分析整合并准确抽取报告中分布在不同版面和表格中关联关系复杂的关键信息。
因此在搭建智能金融数据信息抽取系统时,技术上面临着几个显著的挑战:

版面布局的复杂性
报告文档的版面布局往往复杂多变,包含了标题、子标题、正文、图表、表格、来源、声明等18个不同类别元素。这些元素在文档中的位置、大小和样式各异,给版面分析带来了挑战。


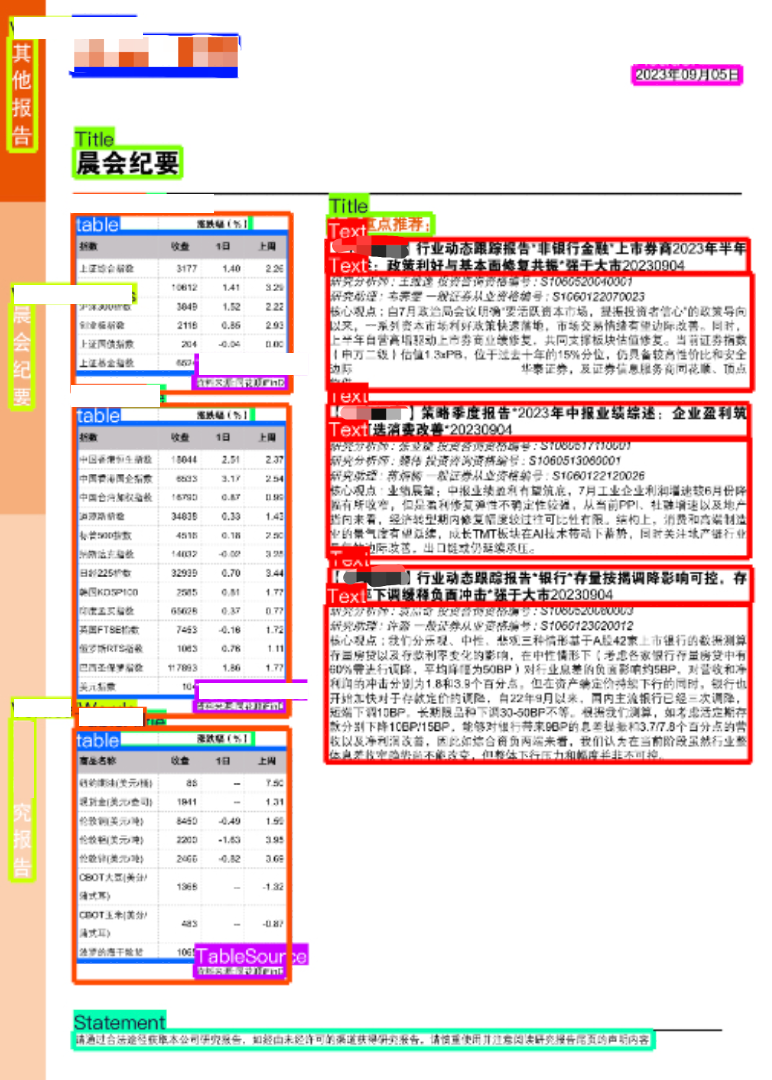

表格结构的多变性
报告文档中经常包含各种复杂的版式的表格,这些表格中蕴藏着丰富的数据信息。然而,表格的复杂性给信息提取带来了极大的挑战,表格可能具有不同的结构和样式,包括合并单元格、跨行跨列、有线表、无线表、不同的颜色单元格等等。此外,表格中的数据可能以文本、数字、日期等多种形式呈现,进一步增加了表格识别的难度。
单线表
跨行表

无线表
滑动查看更多图片

信息的关联与整合
在提取了报告文档中的各类信息后,如何将这些信息进行有效的整合和抽取也是一个难点。报告文档中的信息通常分布在不同的版面和表格中,它们之间可能存在复杂的关联关系。如何准确地识别这些关联关系,并将相关信息进行有效的整合,以便后续的分析和应用,是一个需要深入研究和解决的问题。
综上所述,报告文档的信息提取任务涉及版面分析、表格识别、OCR以及信息抽取这些关键技术。我们需要综合运用这些技术,以实现对报告文档中各类信息的精确提取和有效利用。
 方案设计
方案设计
基于上述问题难点,本场景依赖高精度的版面分析、表格识别、OCR和信息整合抽取能力,因此非常适合选用飞桨低代码开发工具中的文档场景信息抽取(PP-ChatOCRv2_doc)模型产线作为解决方案。该产线融合了文本图像版面分析技术、表格识别技术和OCR技术,使得其能深入解析文档的版面结构并识别表格信息,也能够准确识别文档中的文字。同时,结合文心大模型强大的能力,还可以完成信息的准确抽取。
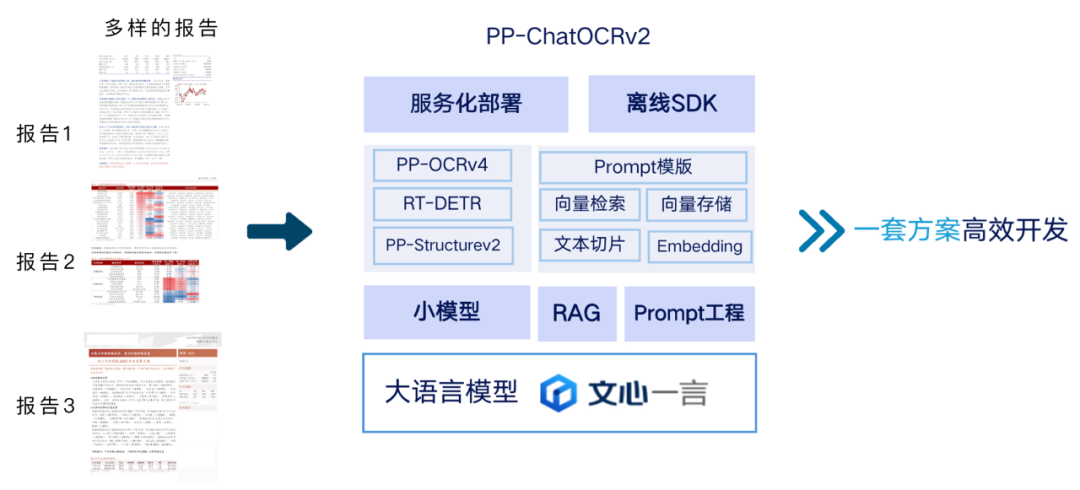
本场景中上述的难点问题,我们可以通过飞桨低代码开发工具,高效地优化文档场景信息抽取产线中的技术模块。具体地,针对报告版面布局的复杂性的难题,文档场景信息抽取产线中集成了先进的文本图像版面分析Pico_Det_layout模型,通过报告的版面分析标注数据对模型进行微调训练,使得模型更加适应金融报告的版面布局特点,提高了检测的准确性和效率;其次,针对多样式且复杂的表格结构,产线中集成了表格识别SLANet模型,我们通过自动生成不同表格样式数据训练表格识别模型,从而优化报告表格识别的效果,提高准确性;最后,基于该产线中的文本切片、向量检索、等技术能力,基于预设prompt模版给大语言模型输入相关信息,通过文心一言的信息整合和理解,实现对关键信息的准确提取。总体而言,采用PP-ChatOCRv2_doc模型产线作为金融报告文档信息提取的解决方案,将极大地提高信息提取的准确性和效率,为金融行业的报告分析提供有力支持。

零代码开发
版面分析
数据校验
本次的训练数据来自金融报告数据,通过数据标注工具获得几千张高质量标准数据,包含"标题、作者、表格、声明、图表"等18个预测类别。标注工具将自动导出为 COCO 标注格式,可以直接提交到零代码产线中进行数据校验。经过数据上传和数据校验我们可以得到如下结果,包含了数据集在训练集、验证集抽样的 10 个样本带可视化标签的图像,方便校验数据标注的正确性。
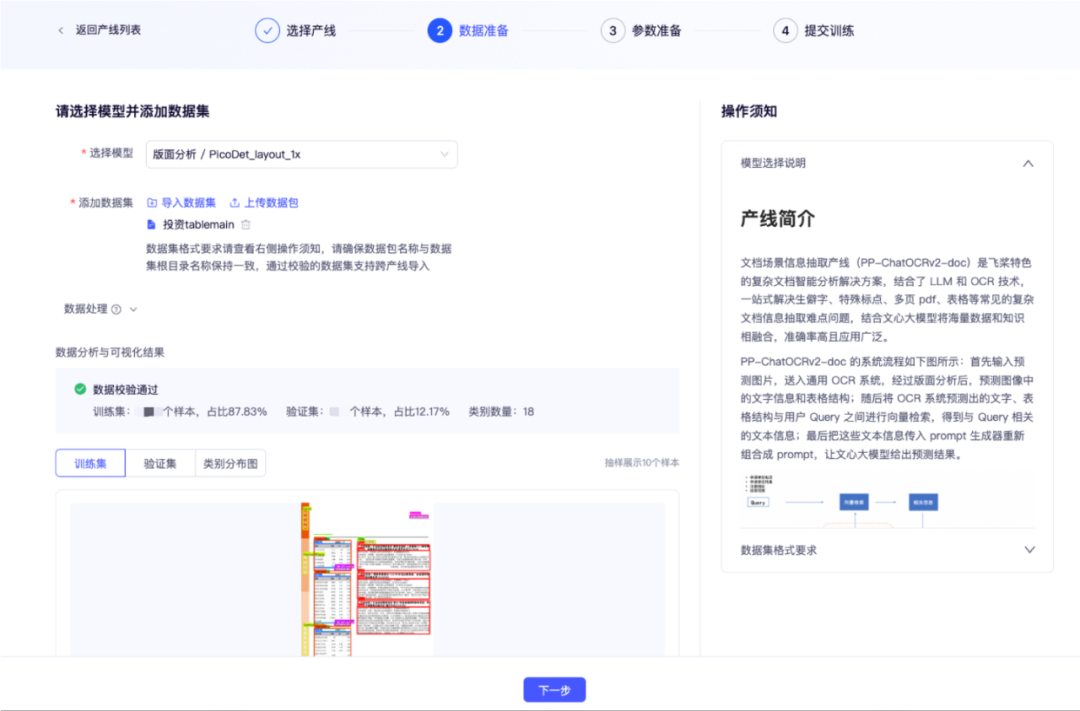
模型训练
在深度学习中,超参数选取对模型的训练起着至关重要的作用,星河零代码产线将模型中影响最大的超参数展示在前端页面上,方便用户快速设置,进行实验调试。在文档版面分析任务中,选择 Pico_Det_layout 算法模型后 ,对结果精度影响最大的超参数是学习率和训练轮数,我们将选取这两个参数作为我们测试调试的选项。
为了让我们的实验尽可能可靠准确,我们使用控制变量法进行了4组对比实验 ,基于固定的训练轮数(50),初步选定了合适的学习率(0.1):
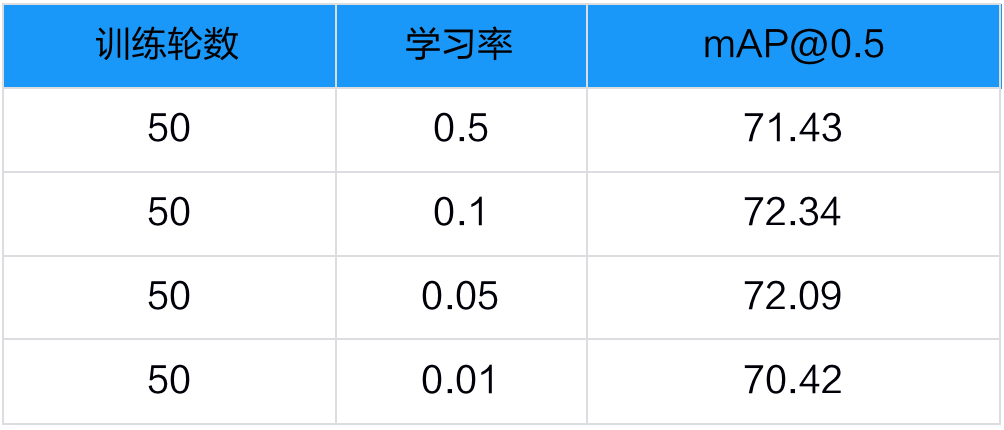
性能调优
版面分析模型(mAP@0.5为 xx%)能够初步检测出文档的布局分类等信息,为了让检测框的位置更加精准,可以在评估界面观察到验证集分数在训练末期仍有增长趋势,因此我们进一步增大训练轮次。复用先前训练时采取的模型学习率超参,分别训练100 epoch、300epoch、500epoch。最终版面分析模型最高精度为74.33%,较之前提升约2%
表格识别
数据校验
本次的表格识别的数据是自动生成的5w+数据。自动生成的表格数据涵盖了各种复杂的表格结构,如合并单元格、跨行跨列、嵌套表格以及多种单元格颜色等,有助于模型学习并适应各种真实场景中的表格结构。表格数据自动生成也会在后续的版本中上线该功能,便于用户使用和优化表格识别模型。经过数据上传,并用8:2的比例划分训练和验证集,通过数据校验我们可以得到如下结果,包含了数据集在训练集、验证集抽样的 10 个样本带可视化标签的图像,方便校验数据标注的正确性。
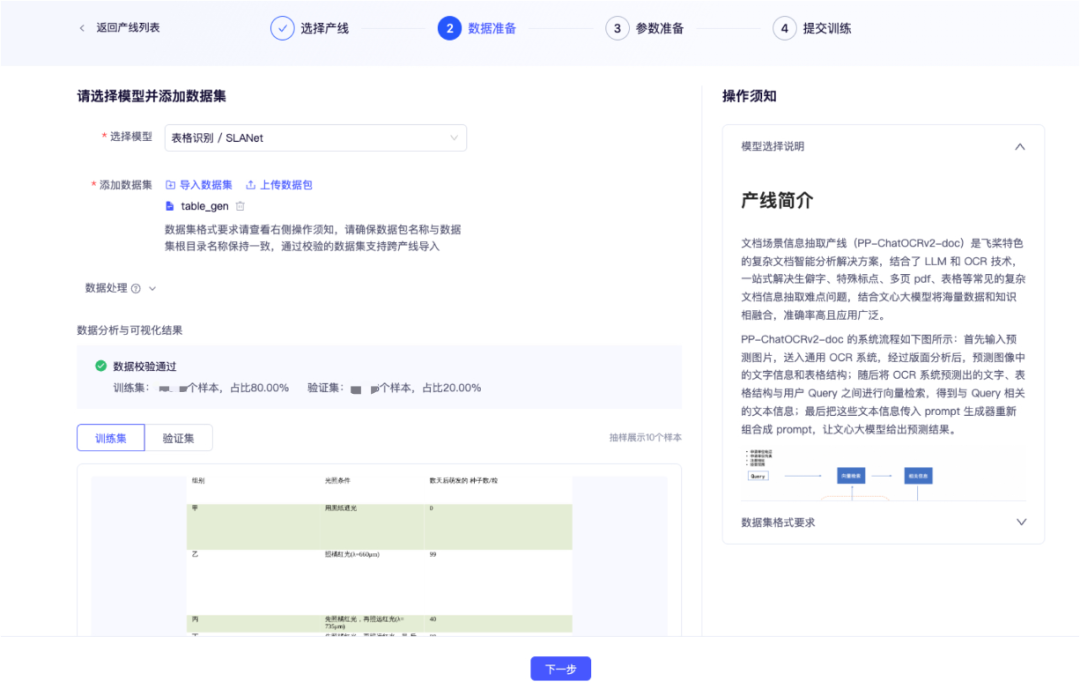
模型训练
在表格识别任务中,选择 SLANet 算法模型后 ,与上面的版面分析一样,调整对结果精度影响最大的超参数学习率和训练轮数,我们将选取这两个参数作为我们测试调试的选项。
为了让我们的实验尽可能可靠准确,我们使用控制变量法进行了3组对比实验 ,基于固定的训练轮数(20),初步选定了合适的学习率(0.1):
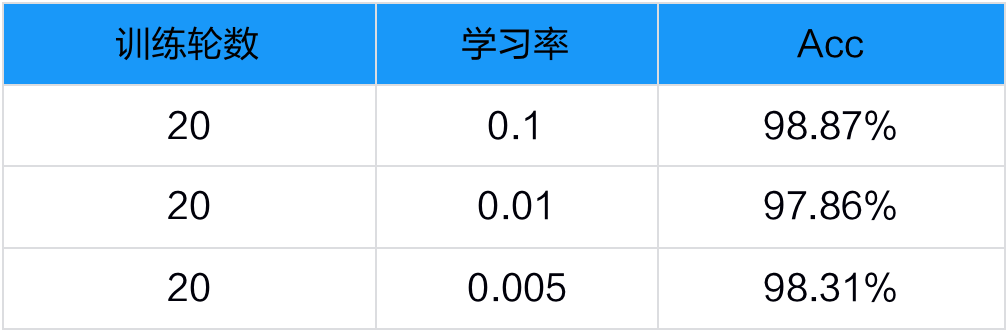
性能调优
为了进一步提升性能,我们进一步增大训练轮次。复用先前训练时采取的模型学习率超参,训练50epoch。最终表格识别模型最高精度为99.55%,较之前提升约0.7%。
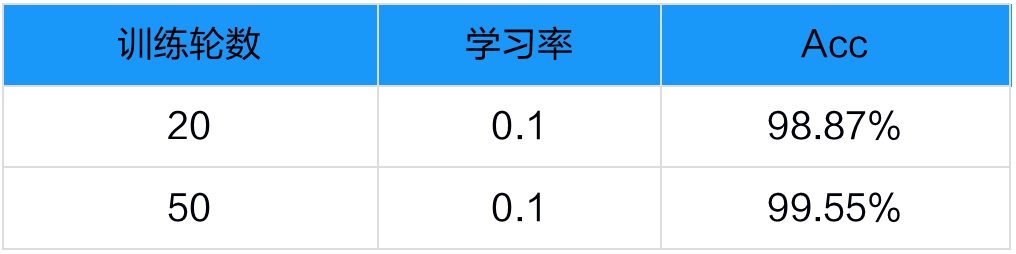
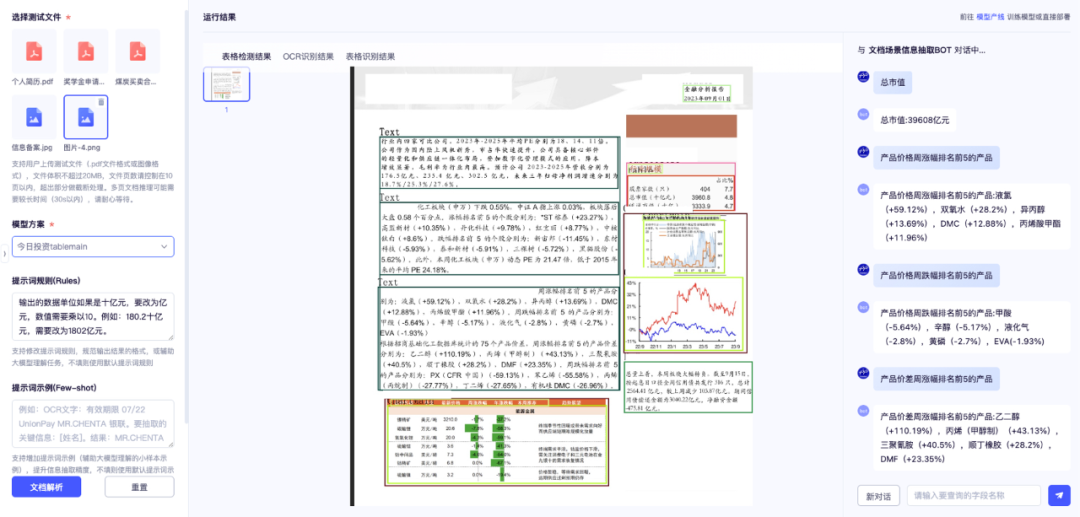
 模型部署与信息抽取效果展示
模型部署与信息抽取效果展示
星河零代码产线极大地简化了模型部署流程,使得用户可以轻松选择已标记的模型权重,并通过一键操作将其部署为在线服务API。这一功能不仅允许其他联网设备轻松调用API,还提供了在线体验应用,用户可借助单图测试迅速验证模型的效果。
下图为选择自己部署的模型方案进行在线体验,通过版面分析、表格识别与OCR的结合,同时基于大语言模型的信息整合和抽取能力,可以精准地预测出文档中的多个版面区域,并准确抽取文档中的多个关键信息。

单线表信息抽取
文本信息抽取
跨行表格信息抽取
若希望将模型部署到离线设备上进行更深入的代码定制,PaddleX还支持获取离线部署包。该部署包不仅包含了模型的标记权重,还配备了特定环境的示例代码。借助这些示例文档,您可以在自己的设备上轻松实现快速且准确的模型部署。
 用户声音
用户声音
对报告版面分析及信息抽取的目的在于通过提取和分析有价值的数据,对企业内部系统、策略进行赋能,提高产品的策略准确性及个性化的投资建议。接入百度飞桨后,能提升数据自动化的效率,减少人工的干预,对数据中的错误、缺失值及异常值进行判别,大幅度提升了数据质量。同时提升数据分析的深度和广度,结合大模型的辅助,能提升挖掘数据的深度,结合大数据的实时分析,能及时调整策略并优化,大大提升投研效率。
 精彩课程预告
精彩课程预告
为了让小伙伴们更快速地了解应用范例教程,百度研发工程师将于6月6日(周四)19:00为大家深度解析从数据准备、数据校验、模型训练、性能调优到模型部署的开发全流程开发难点,从场景、产线、工具完成产业实操体验。赶快扫描下方海报二维码预约报名!

相关链接
云端体验地址:
https://aistudio.baidu.com/pipeline/mine
官方文档:
https://ai.baidu.com/ai-doc/AISTUDIO/6lu57ycbb
文档场景信息抽取产线使用文档:
https://ai.baidu.com/ai-doc/AISTUDIO/Blu5jv0zm
通用场景信息抽取产线使用文档:
https://ai.baidu.com/ai-doc/AISTUDIO/plvkdkk2v
通用OCR产线使用文档:
https://ai.baidu.com/ai-doc/AISTUDIO/Elvkdprq9
通用表格识别产线使用文档:
https://ai.baidu.com/ai-doc/AISTUDIO/1lvkdr2yd
飞桨低代码开发工具交流频道链接:
https://aistudio.baidu.com/community/channel/610




关注【飞桨PaddlePaddle】公众号
获取更多技术内容~

