
- 1信号处理基础之噪声与降噪(二)| 时域降噪方法(平滑降噪、SVD降噪)python代码实现_信号去噪平滑度指标
- 2【网络安全 | CTF】攻防世界 simple_php 解题详析_小宁听说php是最好的语言,于是她简单学习之后写了几行php代码。
- 3MobileNet实战:tensorflow2(1),2024年最新跳槽 面试
- 4微信小程序实现 API Promise 化_微信小程序new promise
- 5GitHub的Fork的作用(Github fork 和 git clone的区别)_fork仓库的好处
- 6数据可视化分析教学课件——FineBI实验册节选====高校招生数据分析_招生、流失可视化分析
- 7【日常问题】解决git clone提示unable to access 问题_git clone unable to access
- 8【自然语言处理】【大模型】DeepSeek-V2论文解析_deepseek v2
- 9外卖扫码点餐全开源小程序源码_点餐小程序下载开源
- 10YoloV8改进策略:蒸馏改进|CWDLoss|使用蒸馏模型实现YoloV8无损涨点|特征蒸馏
工具调用效果比肩GPT-4!本地可微调的多模型协作工具学习agent框架α-UMi
赞
踩

目前,基于大模型调用 API、function 和代码解释器的工具学习 agent,例如 OpenAI code interpretor [1],AutoGPT [2] 等项目,在工业界和学术界均引起了广泛关注。在外部工具的加持下,大模型能够自主完成例如网页浏览、数据分析、地址导航等更复杂的任务,因此 AI agent 也被誉为大模型落地的一个重要方向[3]。
然而,上述项目主要基于闭源 ChatGPT、GPT-4 大模型,其本身在推理、步骤规划、调用请求生成和总结回复等能力上已经足够强。相比之下开源小模型,例如 LLaMA-2-7b 等,由于模型容量和预训练能力获取的限制,单个模型无法在推理和规划、工具调用、回复生成等任务上同时获得比肩大模型等性能,目前也有相关工作验证了小模型上存在不同能力之间的冲突 [4],这对训练本地可微调的开源小模型完成 agent 任务造成了限制。
为了解决这个问题,中山大学、阿里通义实验室联合提出了 :一种本地可微调的多个小模型协作 agent 框架。

论文地址:
https://arxiv.org/abs/2401.07324
项目代码:
https://github.com/X-PLUG/Multi-LLM-Agent
魔搭社区:
https://modelscope.cn/models/iic/alpha-umi-planner-7b/summary
总的来说,本文的主要贡献在于两个方面:
提出了一种多模型协作的 agent 框架,该框架利用三个小模型:planner、caller 和 summarizer 分别负责路径规划、工具调用和总结回复,对小模型进行工作负荷的卸载。同时该框架对比单模型 agent 支持更灵活的 prompt 设计。其在 ToolBench [5],ToolAlpaca corpus [6] 等多个 benchmark 上超过单模型 agent 框架,获得比肩 GPT-4的性能。
提出了一种“全局-局部”的多阶段微调范式(GLPFT),利用该范式成功在开源小模型上训练了多模型协作框架,实验结果表明这种两阶段范式为目前探索出的最佳训练多模型协作 agent 范式。

:多模型协作框架
与普通的单模型 agent 在概念上的对比如下图所示:
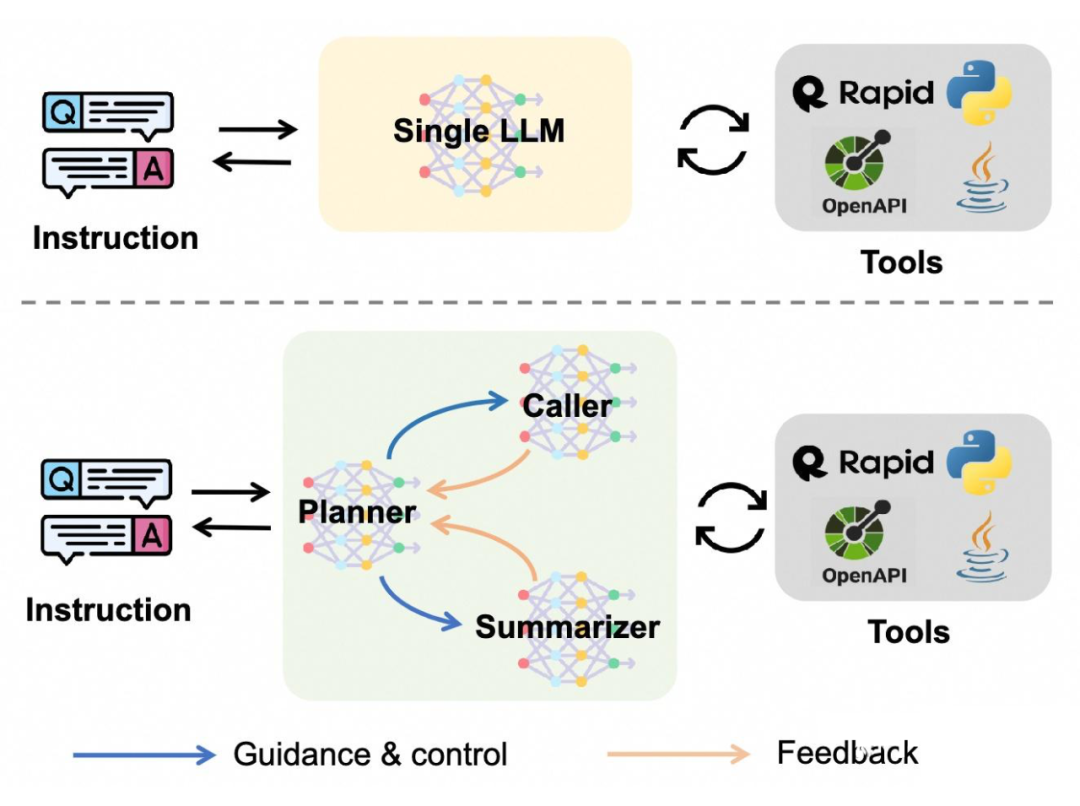
中包含三个小模型 planner、caller 和 summarizer,其中 planner 模型为系统的核心大脑,负责在某一 agent 执行步骤内激活 caller 或 summarizer,并给予对应的推理(rationale)指导,而 caller 和 summarizer 则分别负责接收 planner 的指导完成该步后续工作。具体来说:
Planner: planner 以其对应 prompt ,用户请求 q 和历史执行记录 作为模型输入,输出当前执行步骤的推理 rationale:

中包含两部分内容,第一部分为模型推理,即大模型 agent 范式中的 thought 部分,起到辅助后续动作执行的作用。第二部分为一个特殊的选择文段,如果该选择文段内容为 “Next: Caller”,会激活 caller 模型与外部工具产生交互;文段内容为 “Next: Summarizer”,会激活 summarizer 模型生成最终回复;文段内容为 “Next: Give up”,则带 planner 判断用户请求在当前环境下无法完成,需要放弃执行任务或稍后尝试。
Caller: 当 caller 被planner 激活后,以其对应 prompt ,用户请求 q,历史执行记录 以及 planner 在当前步骤的 rational 作为输入,输出当前执行步骤与外部交互的动作:
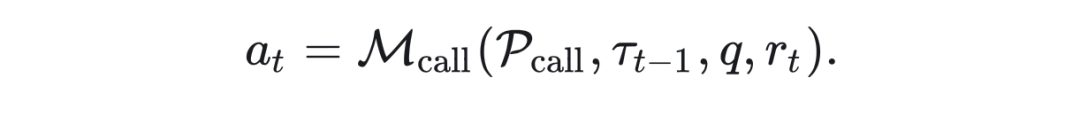
受外部工具种类不同, 表现为不同格式,在 api 调用时, 表现为 “Action:api 名 Action Input:api 调用参数”,在执行代码时 表现为可运行的 python 代码。
Summarizer: 当 summarizer 被 planner 激活后,其将负责根据历史执行内容总结出最后的回复。
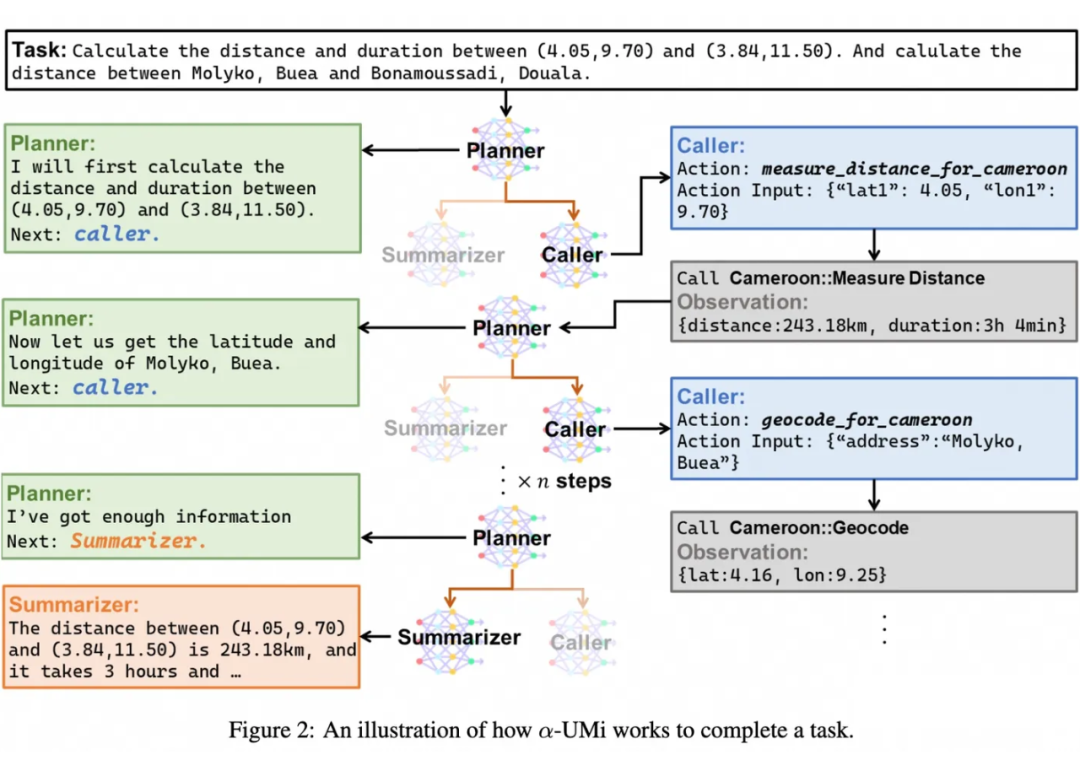
下图直观展示了一个 系统解决真实用户问题的流程:

GLPFT:全局-局部多阶段微调范式
多模型协作框架的训练并非一件简单的事,有两个作用截然相反的影响因素:
1. 生成 Rationale,Action 和 Final Answer 三个任务在训练中可以相互促进的,同时也能增强模型对于 agent 任务的全局理解,因此目前大部分工作均训练单个模型同时生成 rationale,action 和 final answer。
2. 模型的容量,不同任务的数据配比等也限制了我们很难训练单个模型同时在三个任务上获得表现峰值。综合考虑上述两点,本文提出了一种“全局-局部”的多阶段训练方法,目标在于利用充分利用 Rationale,Action 和 Final Answer 在训练中相互促进的优势,获得一个较好的单模型初始化,再进行多模型微调,专攻子任务性能的提升。
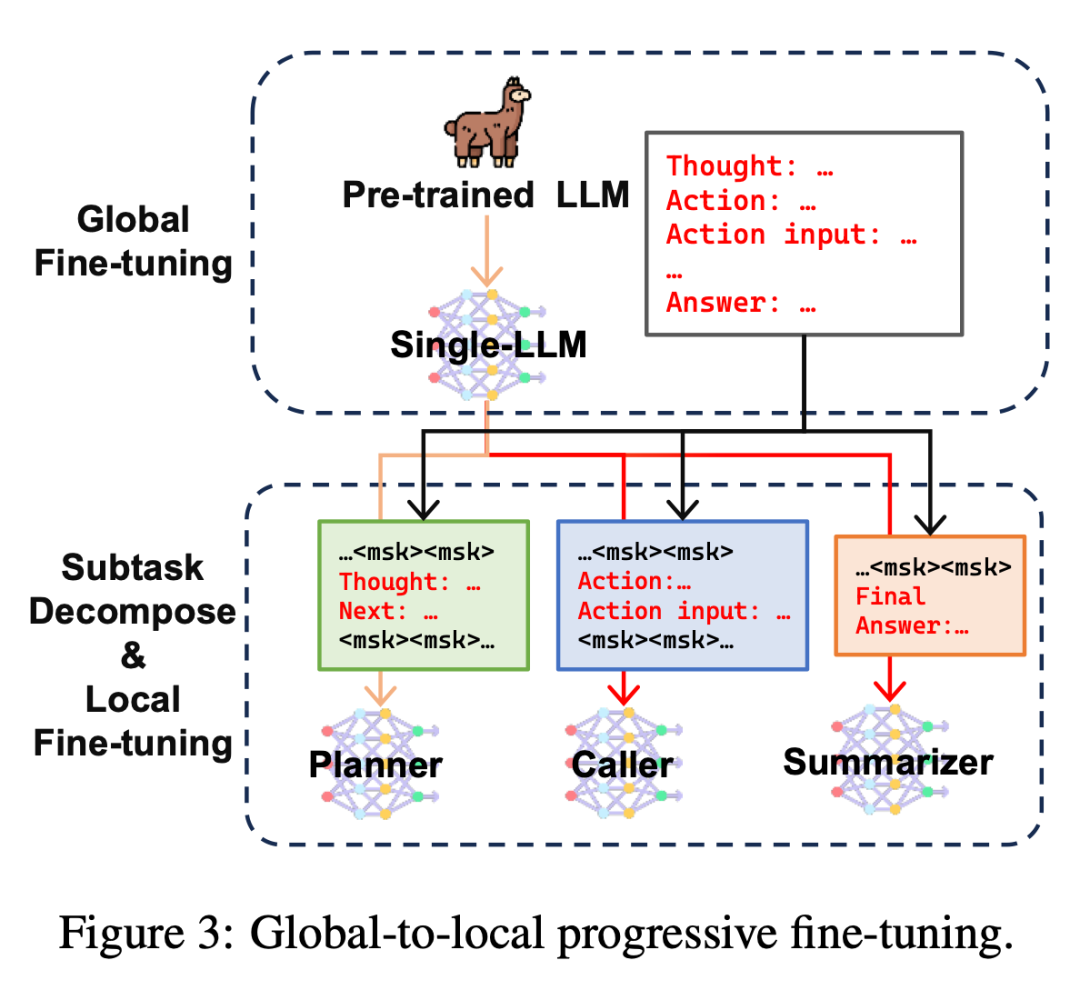
上图展示这种多阶段微调的流程,在第一阶段中,使用预训练 LLM 在完成工具调用 agent 任务上微调,获得一个单模型的 agent LLM 初始化。
接着,在第二阶段中,本文对工具调用 agent 任务的训练数据进行重构,分解成生成 rationale,生成工具交互 action 和生成最终回复三个子任务,并将第一阶段训练好的 Single-LLM agent 底座复制三份,分别在不同子任务上进一步微调。
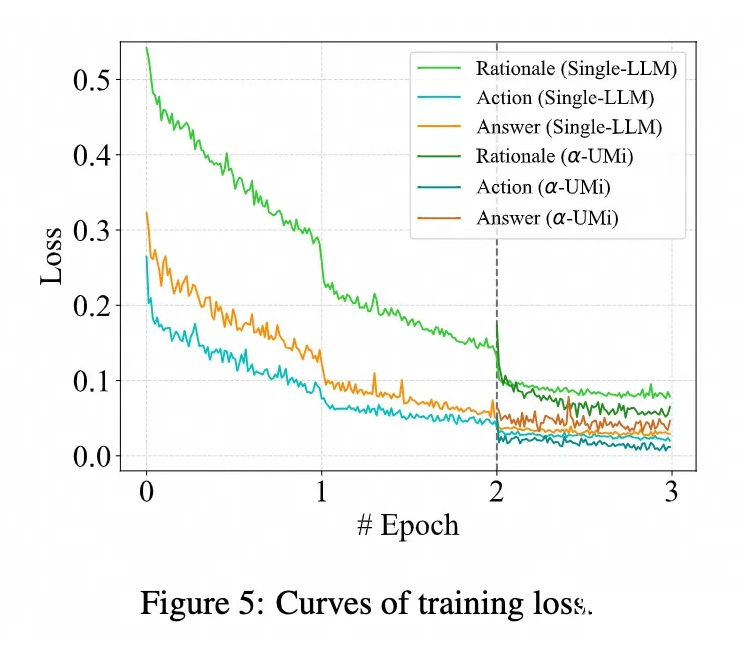
下图的训练 loss 曲线展示了当单模型 agent 底座在第 2 个 epoch 结束之后拆分成 planner、caller 和 summarizer 三个模型,并获得进一步的优化空间。也揭示了这种多阶段训练的本质:当单模型 agent 在工具调用 agent 任务中到达性能上界之后,通过进一步拆分和子任务微调,多模型协作 agent 能够在各个子任务中获得更好的表现。

实验结果
3.1 静态评估
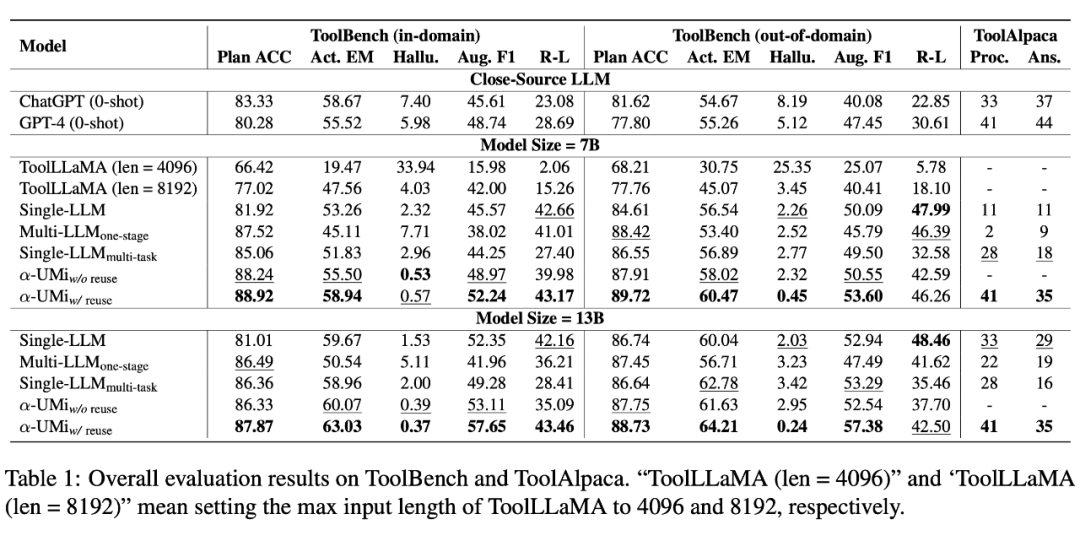
在静态评估中,本文将所有对比 baseline 的输出结果与标注输出进行对比,可以看到:
系统表现显著超过了 ChatGPT 和工具调用开源模型 ToolLLaMA,性能与 GPT-4 比肩。值得一提的是,ToolLLaMA 需要 8192 的输出长度以获得令人满意的结果,当输入长度为 4096 时,其效果急剧下降,幻觉率飙升,而对比之下 只需要 4096 的输入长度,这得益于多模型框架带来的更灵活的 prompt 设计。
对比本文作者团队复现的单模型 agent 框架, 也取得了性能的显著提高。
在多模型协作框架模型的微调方案对比上,直接微调三个模型、或单个模型多任务微调均无法使多模型协作框架发挥效果,只有使用多阶段微调 GLPFT 才能达到最佳性能,突出了文章提出的 GLPFT 在多模型协作框架微调中的必要性。
3.2 真实api调用评估
单纯与标注比对无法全面展示 agent 框架性能,因此作者也在 ToolBench 数据集上引入了一种真实 api 调用的评估方式,该评估方式对比 agent 框架完成任务的成功率(pass rate)和 agent 框架与标准 baseline 框架(ChatGPT-ReACT)对比的胜率(win rate)。实验结果如下:
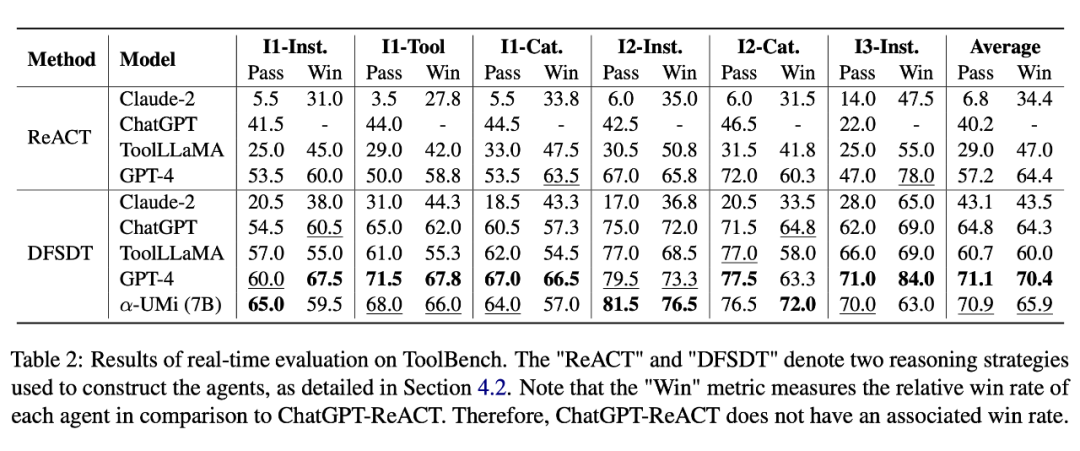
在该真实 api 调用实验结果中,依然战胜了 ChatGPT 和 ToolLLaMA,并在成功率上取得了与 GPT-4 相当的结果。
3.3 Data scaling law
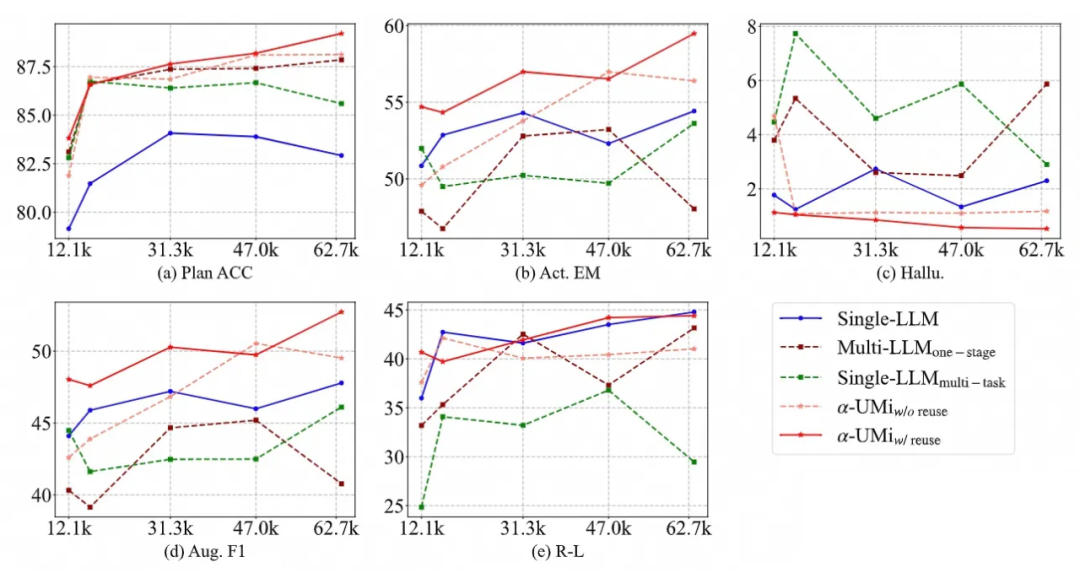
通过比对不同训练数据下的模型表现,我们可以发现两点结论:
除了 rouge-L 指标外,多模型协作的 在不同训练数据量、不同指标下都一致地超过了单模型 agent 架构。特别是在 Plan ACC 和 Aug F1 这类关系到工具调用 agent 到规划能力和工具调用能力的指标上, 对比单模型 agent 的表现提升更加明显,反映了文章提出的多模型协作架构对于工具调用 agent 的适用性。
可以观察到,单模型 agent 在各项指标上达到峰值所需的数据量是不同的,而 却能随着数据量的增加,在各个指标上都获得稳定的表现提升,这更加凸显了多模型协作的必要性:我们很难找到一个在所有指标上达到峰值的数据量和模型检查点,而通过多模型协作,我们可以解决这个问题。
3.4 模型开销
多模型协作会引入更多成本,作者探究了多模型协作框架在训练、推理及储存阶段的开销对比:
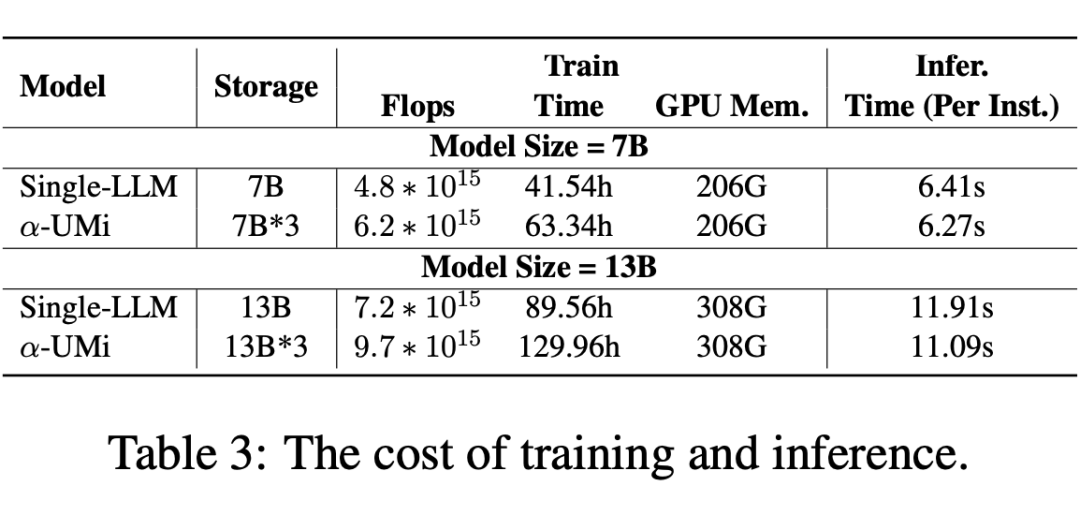
总体来说,多模型协作框架确实会在训练和模型参数储存上引入更高的开销,但其推理速度与单模型框架相当。当然,考虑到多模型协作 agent 框架使用 7B 底座的性能远超 13B 单模型 agent 性能,总开销也更少。这意味着我们可以选择小模型为底座的多模型协作 agent 框架来降低开销,并超过大模型的单模型 agent 框架。

总结
本文以缓解小模型在工具调用 agent 任务中的容量限制为出发点,设计了多个小模型协作的工具调用 agent 框架及其对应的多阶段微调方法,在多个工具调用 benchmark 上取得了超过单模型 agent baseline,比肩 GPT-4 的工具调用结果。
该框架的成功主要得益三点:
1. 多模型协作框架减轻了单个模型的工作负载,通过任务分解让工具调用任务变得更简单,更适合能力稍差的开源小模型;
2. 多模型协作框架支持更精细的 prompt 制定,能够让每个模型专注于自身任务,减少其他冗余信息的干扰;
3. “全局-局部”的多阶段微调方式综合了各种微调范式的优势,是多模型协作在开源模型底座下成为可能。
该工作未来仍有一定扩展空间,例如增强 planner 的泛化性,使其使用于更广泛的 agent 任务场景,进行 caller 模型的本地私有化,使其专注于本地工具调用任务,以及云端大模型结合本地小模型的“大-小”模型协同框架。

参考文献
[1] GPT-4 code interpretor: https://chat.openai.com/?model=gpt-4-code-interpreter
[2] AutoGPT: https://github.com/Significant-Gravitas/Auto-GPT
[3] Navigating the AI Agent Landscape: Insights into Advancements and Opportunities: https://medium.com/@VAI_LABS/navigating-the-ai-agent-landscape-insights-into-advancements-and-opportunities-75c4e67ffc8e
[4] How abilities in large language models are affected by supervised fine-tuning data composition.
[5] ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
[6] ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

