
- 1大数据——Spark
- 2Golang笔记:使用exec包执行外部程序与Shell命令_golang exec
- 3大一python编程题库和答案,大一python选择题库答案_给出range(1,10,3)的值(1,4,7)为什么是2.75
- 4判断推理刷题1
- 5【C语言】QuickSort---快速排序
- 6一文解决用C语言实现一个链表(全都是细节)_c语言实现链表
- 7深度解读CharGPT基本原理
- 8kafkaStream实时流式计算_kafka 实时计算
- 9Git日常操作详解_reset current branch to here -hard 会提交git吗
- 10微软AI PC全面“亮剑”!Copilot融入Windows 11,GPT 4o“很快”加持
【API部署】fastapi与nuitka打包py项目_nuitka fastapi
赞
踩
提示:分两部分:fastapi接口调用,与nuitka快速打包
功能:作为一名算法工程师,训练机器学习模型只是为客户提供解决方案的一部分。 除了生成和清理数据、选择和调整算法之外,还需交付和部署结果,以便在生产中使用
实现python或基于虚拟环境的pytorch项目,在终端部署。即py文件最终变成exe,可脱离python环境,在任意终端运行。
如何测试
前端如何向后端发送请求
1.利用python中的request
Requests建立在世界上下载量最大的Python库urllib3上,它令Web请求变得非常简单,功能强大且用途广泛。
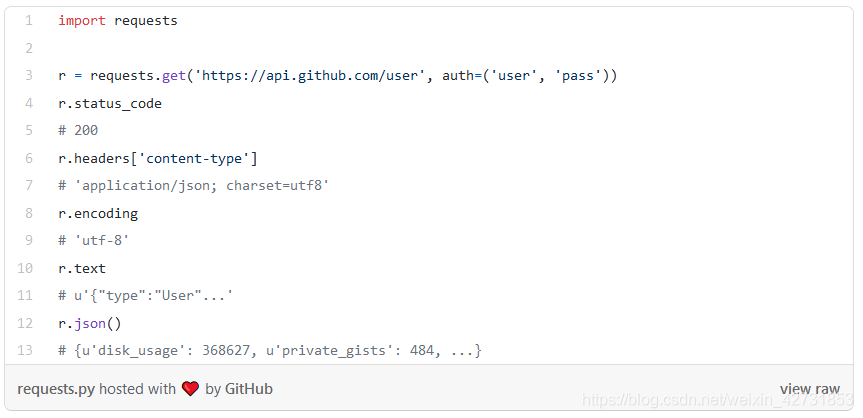
上面是get请求,用于从访问的地址中获取信息。还可用post请求,来向后端传入数据
result = requests.post('https://127.0.0.1:8000/detect', data = Data)
- 1
输入与输出数据格式与定义,在后端定义,见下文。
2.利用软件postman
ubuntu与windows都可用的前后端通信软件:
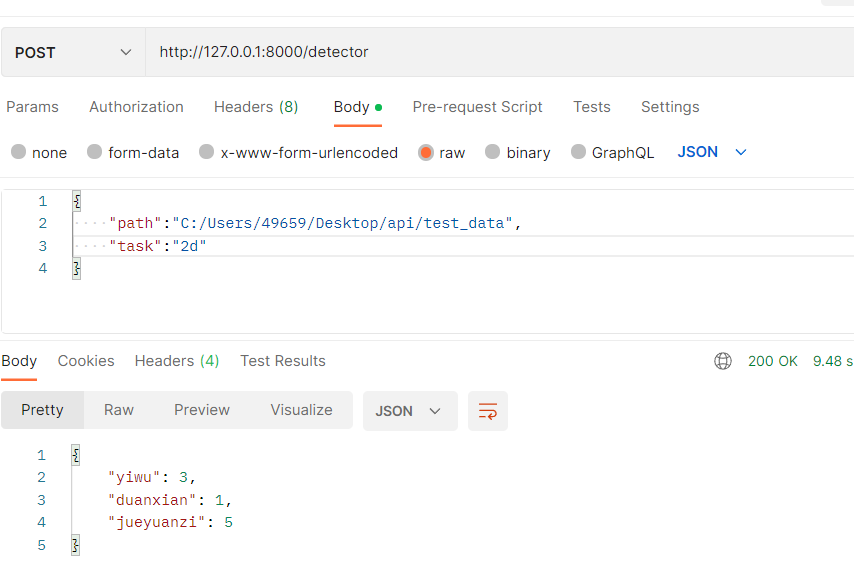
以上是通过发送数据所在路径,实现2d检测的一个功能。后端返回检测结果,输入输出都是json即字典格式
一、fastapi(创建API服务)
1.安装
注意是在win10的虚拟环境中安装,同样在win10上运行
pip install fastapi
pip install "uvicorn[standard]"
- 1
- 2
2.小示例
先创建 main.py 文件:
from typing import Optional
from fastapi import FastAPI
#创建FastAPI实例
app = FastAPI()
#创建访问路径
@app.get("/")
def read_root():#定义根目录方法
return {"message": "Hello World"}#返回响应信息
#定义方法,处理请求
@app.get("/items/{item_id}")
async def read_item(item_id: int):
return {"item_id": item_id}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
以上示例共包含两个 get接口,调用任意一个,都会默认执行后续的 def 函数。
在终端中的使用以下命令,来启动服务:
uvicorn main:app --reload
# 注意:--reload 表示让服务器在更新代码后重新启动。仅在开发时使用该选项。
- 1
- 2
启动服务后,可在前端(如postman中访问localhost/items?=id 来进行测试)
3.完整代码
以下是完整的main.py文件,可直接用python执行来启动服务
(重点是其中 post接口以及接收文件的格式定义 )
from typing import Optional import uvicorn from fastapi import FastAPI,File from pydantic import BaseModel from ml.predict import load_model,Features,predict #创建FastAPI实例 app = FastAPI() # 自定义接收数据的结构 class hkk(BaseModel): file: str num: int #创建访问路径 @app.get("/") def read_root(): return {"message": "Hello World"} # 访问根目录即显示 # 加载模型 models = load_model() def test(file): feature = Features(file) return model.predict(feature) #调用模型接口 @app.post("/detect/v2") async def detect2(item: hkk): # async 表示异步执行,hkk为自定义的类 img = item.file index= item.num res = test(img) return { "filename": file.filename, "attributes": (len(content),str(type(f)),str(type(content))), "result": res } #运行 if __name__ == '__main__': uvicorn.run(app, host="127.0.0.1", port=8000)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
测试可见前言中 postman截图,传参选 Body> raw> JSON 文件,也可用以下python文件调用:
import requests
url2 = 'http://127.0.0.1:8000/detect/v2'
filename2 = "examples/123.jpg"
files = {
'file':filename2,
'num':int(2)
}
response2 = requests.post(url2, files=files)
print(response2.content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4.拓展 (返回其他类型、数据库实战)
- 前端传入 json时,后端代码:
from fastapi import Body
@app.post("/login")
async def login(data = Body(None)):
return {"data":data} # 除了上述自定义文件类型外,也可采用Body格式
- 1
- 2
- 3
- 4
- 5
2. 前端传入list 时,在postman 中传参选 Body> form-data ,输入一个list(含两个文件),后端代码:
from fastapi import FastAPI, Header, Body, Form
# 注意要提前 pip install python-multipart
@app.post("/login")
async def login(username= Form(None), password = Form(None)):
return {"data":{"username":username, "password":password}}
- 1
- 2
- 3
- 4
- 5
- 6
3. 返回图片、网页
通过以下三个包,可返回不同类型。
from fastapi.responses import JSONResponse, HTMLResponse, FileResponse app = FastAPI() #创建访问路径 @app.get("/user") def user(): return JSONResponse( content = { "msg": "get user" }, status_code = 202, headers = { "a": "b" }) # 给返回的header增加新的key:a @app.get("/") def user(): html_content = " " " <html> <body><p style = "color:red"> Hello World</p></body> <html> " " " return HTMLResponse( content = html_content) # 访问根目录 / 得到设置好的html网页 @app.get("/avater") def user(): avater = "E:/user/123.jpg" return FileResponse( avater ,filename = '123.jpg' ) # 访问目录 /avater ,得到下载提示 return FileResponse( avater ) # 只显示图片
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
jinja2模板 返回HTML (以文件形式导入html)
from fastapi import FastAPI,Request
from fastapi.templating import Jinja2Templates # 需要 pip install jinja2
app = FastAPI()
template = Jinja2Templates ("pages") # 保存 .html 文件的文件夹
@app.get("/")
def user( req: Request ) :
return template.TemplateResponse( "index.html" , content = { "request": req})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 数据库实战
①先在 teacher.py 文件中 创建teacher类,用来模拟数据库
from pydantic import BaseModel, Field
class TeacherSchema(BaseModel):
id: int
name: str = Field (default = name, min_length=6) # 规定数据格式
course: None|str = "python 测试" # 旧版: Union[None,str]
salary: float=8000
full_time: bool=True
- 1
- 2
- 3
- 4
- 5
- 6
- 7
实例化类的两种方法:
t1 = TeacherSchema (id=3, name=“abc”, salary = “2000”…)
print (t1.dict()) # 返回字典
print (t1.json()) # 返回字符串
data = { “id”: 3 , “name”: “周老师”, “salary”: 90332}
或者从文件导入:
data = load_json(“123.json”)
t1 = TeacherSchema.parse_obj(data)
三种加载方法:
import json
import yaml
def load_json(file):
with open(file, 'r', encoding='utf-8') as fp:
return json.load(fp)
def save_json(data, file):
with open(file, 'w', encoding='utf-8') as fp:
json.dump(data, fp, ensure ascii=False)
def load_yaml(yaml_file) ->Dict: # 定义返回类型
with open(yaml_file, mode ='rb') as fp:
yaml_cont = yaml.load(fp, Loader = yaml.FullLoader)
return yaml_cont
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 定制返回信息
二、nuitka打包与部署
nuitka是一个用来将python代码打包为exe可执行文件,方便其在没有相关环境的windows系统上运行的工具(也支持打包成linux系统下的可执行程序,暂未尝试)。其原理为:将部分python代码(自己写的部分)转换成C代码,以提高运行的速度;import的第三方包不进行编译,在运行时,通过一个python3x.dll的动态链接库 执行第三方包的python代码,通过这样的方式减少exe包的大小。
nuitka 适合将python 编写(基于pyqt5库)的可视化图形界面(GUI)打包,打包速度快,打包完的程序也不大,而 pyinstaller打包的程序一般都非常大,而且运行的速度很慢
1.环境与安装
环境:
conda 4.7.12
Python 3.6.13
numpy 1.16.4 (容易出错,建议不要高于此版本)
pyqt5 5.15.4
① 下载C编译器:MinGW64 8.1(这个版本最稳定)。
下载地址:https://sourceforge.net/projects/mingw-w64/files
也可使用百度盘:https://pan.baidu.com/share/init?surl=CpdGxZj2hRsU_Z0ukp6kqg#list/path=/
密码8888
其他两个文件保留,是nuitka的附属文件,等会会用
② 将文件3 MinGW64 8.1 解压到C盘,并添加环境变量
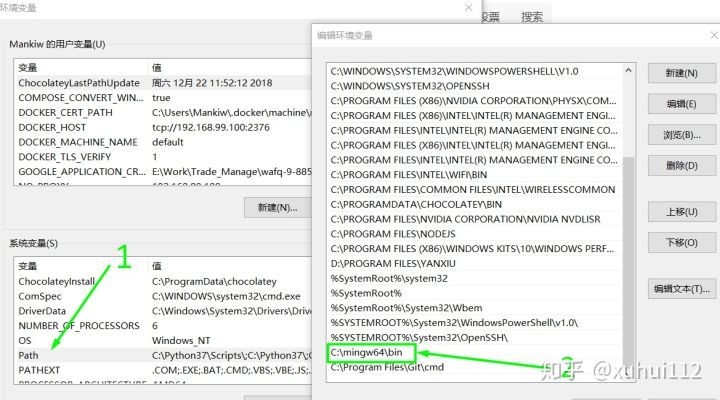
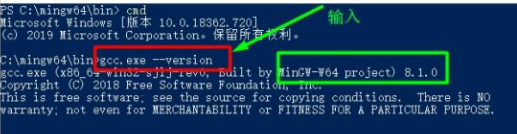
③ 打开cmd命令,使用gcc.exe --version测试是否添加上。
2.下载Nuitka
pip install nuitka
3.使用nuitka简单打包python代码
(1)新建一个简单的python文件,测试运行没有出错
(2)使用nuitka xxx.py命令进行打包。在打包过程中会有提示下载一个包到***\nuitka***这样一个文件夹中,下载进度条可能不动或者很慢,就可以使用 ctrl + C终止进程,手动将百度云下载的文件1解压到提示的这个文件家中
(3)重新使用nuitka xxx.py命令进行打包。还会提示下载另一个包,同样的方式将文件2解压放入
(4)重新使用nuitka xxx.py命令进行打包,这次应该就没问题了
4.使用nuitka打包pyqt5项目
参数作用:
–mingw64 默认为已经安装的vs2017去编译,否则就按指定的比如mingw(官方建议)
–standalone 独立环境,这是必须的(否则拷给别人无法使用)
–windows-disable-console 没有CMD控制窗口
–output-dir=out 生成exe到out文件夹下面去
–show-progress 显示编译的进度,很直观
–show-memory 显示内存的占用
–include-qt-plugins=sensible,styles 打包后PyQt的样式就不会变了
–plugin-enable=qt-plugins 需要加载的PyQt插件
–plugin-enable=tk-inter 打包tkinter模块的刚需
–plugin-enable=numpy 打包numpy,pandas,matplotlib模块的刚需
–plugin-enable=torch 打包pytorch的刚需
–plugin-enable=tensorflow 打包tensorflow的刚需
–windows-icon-from-ico=你的.ico 软件的图标
–windows-company-name=Windows下软件公司信息
–windows-product-name=Windows下软件名称
–windows-file-version=Windows下软件的信息
–windows-product-version=Windows下软件的产品信息
–windows-file-description=Windows下软件的作用描述
–windows-uac-admin=Windows下用户可以使用管理员权限来安装
–linux-onefile-icon=Linux下的图标位置
–onefile 像pyinstaller一样打包成单个exe文件(2021年我会再出教程来解释)
–include-package=复制比如numpy,PyQt5 这些带文件夹的叫包或者轮子
–include-module=复制比如when.py 这些以.py结尾的叫模块
–show-memory 显示内存
–show-progress 显示编译过程
–follow-imports 全部编译
–nofollow-imports 不选,第三方包都不编译
–follow-stdlib 仅选择标准库
–follow-import-to=MODULE/PACKAGE 仅选择指定模块/包编译
–nofollow-import-to=MODULE/PACKAGE 选择指定模块/包不进行编译
完整命令为:

nuitka --standalone --mingw64(visual 编译可以去掉) --show-progress --show-memory --output-dir=out --diasble-plugins=anti-bloat main.py
// --standalone环境独立
// --mingw64选择之前下载的C编译器
// --show-progress --show-memory显示进度和内存
// --nofollow-imports所有包都不编译
// --plugin-enable=qt-plugins --include-qt-plugins=sensible,styles 添加qt插件,导入相关包
// --output-dir=out --windows-icon-from-ico=favicon.ico 导出路径以及图标
- 1
- 2
- 3
- 4
- 5
- 6
- 7
打包完成后会生成一个文件夹,包含xx.build和xx.dist两个目录,前一个无用。后一个就是我们需要的打包好的文件夹,里面有一个exe可执行文件。继续调试添加依赖包:
调试添加包的过程:
(1)在xx.dist目录下打开cmd或者powershell(shift+鼠标右键,点击打开powershell)
(2)运行./xx.exe
(3)查看报错信息,缺少的第三方包就从D:\Anaconda3\envs\myenv(虚拟环境路径)下搜索关键字,将其复制保存到xx.dist目录下。缺少的自己的包,也将其复制过来。一步一步调试,直到把所有的依赖包全都复制到这个目录下,程序完美执行。(记得把这些依赖包复制备份)
(4)之前的命令打包的程序为了调试有一个console黑框框,正式打包的话不要console,在之前的命令中添加–windows-disable-console,具体命令为:
**感谢博主「ha_lee」的原创文章
三、Docker部署
即将完成

