
- 1elementPlus 图标不显示 属性模式不显示
- 2数据格式转换(labelme、labelimg、yolo格式相互转换)_labelme转yolo
- 3GIT 客户端出现 libpng warning: iCCP: known incorrect sRGB profile_iccp: konwn incorrect chunk does not match srgb
- 451单片机资源——直接榨干_单片机的资源10个
- 5深度估计(一)
- 6微信小程序笔记_this.selectcomponent
- 7pip安装 numpy, nltk,torch,transformers_runtimeerror: numpy is not available
- 8数字信号处理 | 实验二 MATLAB z换和z逆变换分析+求解差分方程+求解单位冲击响应+求解幅频相频特性曲线+求解零极点_matlab逆z变换
- 9mysql查询语句and,or
- 10mysql cache_Mysql 数据库缓存cache功能总结
图数据库 之 Neo4j - 应用场景3 - 知识图谱(8)_知识图谱数据neo
赞
踩
背景
-
知识图谱的复杂性:知识图谱通常包含大量的实体、关系和属性,以及它们之间的复杂关联。传统的关系型数据库在处理这种复杂性时可能面临性能和灵活性的挑战。
-
图数据库的优势:图数据库是一种专门用于存储和处理图结构数据的数据库。它们使用节点和边来表示实体和关系,并提供了高效的图查询语言和图算法,以便更好地处理和分析图数据。
原理
-
数据模型:图数据库使用图数据模型来表示知识图谱。图数据模型由节点(表示实体)和边(表示关系)组成。节点和边可以具有属性,用于描述实体和关系的特征。
-
存储结构:图数据库使用存储结构来存储图数据。通常,图数据库使用邻接表或邻接矩阵等数据结构来表示节点和边之间的关系。这种存储结构使得查询和遍历图数据更加高效。
-
查询语言:图数据库提供了专门的图查询语言,如Cypher、Gremlin等,用于查询和操作图数据。这些查询语言具有图模式匹配、路径遍历和图算法等功能,可以更好地满足知识图谱的查询需求。
-
图算法:图数据库通常内置了一些常用的图算法,如最短路径、社区发现、推荐等。这些算法可以帮助用户发现图数据中的模式、关联和洞察力。
优势
-
灵活性:图数据库的数据模型非常灵活,可以轻松地表示实体、关系和属性。这使得知识图谱的建模更加自然和直观,可以更好地反映现实世界中的实体和它们之间的关系。
-
复杂关系的处理:知识图谱中的实体之间通常存在复杂的关系,如社交网络中的朋友关系、组织结构中的层级关系等。图数据库提供了高效的图查询语言和图算法,可以轻松地查询和遍历图数据,发现实体之间的复杂关联。
-
推理和推荐功能:图数据库支持推理和推荐功能,可以通过定义规则和查询来推断新的关系和属性。这使得知识图谱可以不断演化和丰富,从而提供更多的信息和洞察力。
-
高性能:图数据库使用专门的存储结构和查询优化技术,可以实现高效的图数据存储和查询。这使得在大规模知识图谱中的数据处理和分析更加高效和可扩展。
案例分析
假设我们要构建一个电影知识图谱,其中包含电影、演员和导演之间的关系。我们可以使用Neo4j来表示电影、演员和导演,并使用关系来表示他们之间的关联。
创建电影节点
CREATE (:Movie1 {title: 'The Shawshank Redemption', year: 1994});
CREATE (:Movie1 {title: 'The Godfather', year: 1972});
CREATE (:Movie1 {title: 'Pulp Fiction', year: 1994});
创建演员节点
CREATE (:Actor1 {name: 'Tim Robbins'});
CREATE (:Actor1 {name: 'Morgan Freeman'});
CREATE (:Actor1 {name: 'Marlon Brando'});
CREATE (:Actor1 {name: 'Al Pacino'});
CREATE (:Actor1 {name: 'John Travolta'});
创建导演节点
CREATE (:Director1 {name: 'Frank Darabont'});
CREATE (:Director1 {name: 'Francis Ford Coppola'});
CREATE (:Director1 {name: 'Quentin Tarantino'});
创建电影、演员和导演之间的关系
MATCH (m:Movie1 {title: 'The Shawshank Redemption'}), (a:Actor1 {name: 'Tim Robbins'})
CREATE (a)-[:ACTED_IN]->(m);MATCH (m:Movie1 {title: 'The Shawshank Redemption'}), (a:Actor1 {name: 'Morgan Freeman'})
CREATE (a)-[:ACTED_IN]->(m);MATCH (m:Movie1 {title: 'The Godfather'}), (a:Actor1 {name: 'Marlon Brando'})
CREATE (a)-[:ACTED_IN]->(m);MATCH (m:Movie1 {title: 'The Godfather'}), (a:Actor1 {name: 'Al Pacino'})
CREATE (a)-[:ACTED_IN]->(m);MATCH (m:Movie1 {title: 'Pulp Fiction'}), (a:Actor1 {name: 'John Travolta'})
CREATE (a)-[:ACTED_IN]->(m);MATCH (m:Movie1 {title: 'The Shawshank Redemption'}), (d:Director1 {name: 'Frank Darabont'})
CREATE (d)-[:DIRECTED]->(m);MATCH (m:Movie1 {title: 'The Godfather'}), (d:Director1 {name: 'Francis Ford Coppola'})
CREATE (d)-[:DIRECTED]->(m);MATCH (m:Movie1 {title: 'Pulp Fiction'}), (d:Director1 {name: 'Quentin Tarantino'})
CREATE (d)-[:DIRECTED]->(m);
查询1990年后的电影以及对应的演员和导演
MATCH (a:Actor1)-[:ACTED_IN]->(m:Movie1)<-[:DIRECTED]-(d:Director1)
WHERE m.year > 1990
RETURN a,m,d

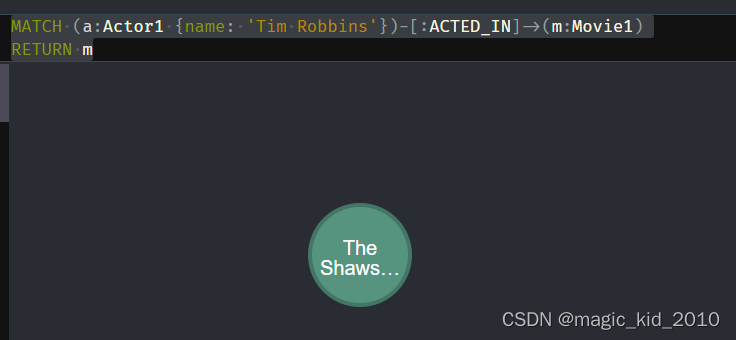
查询某个演员参演的所有电影
MATCH (a:Actor1 {name: 'Tim Robbins'})-[:ACTED_IN]->(m:Movie1)
RETURN m
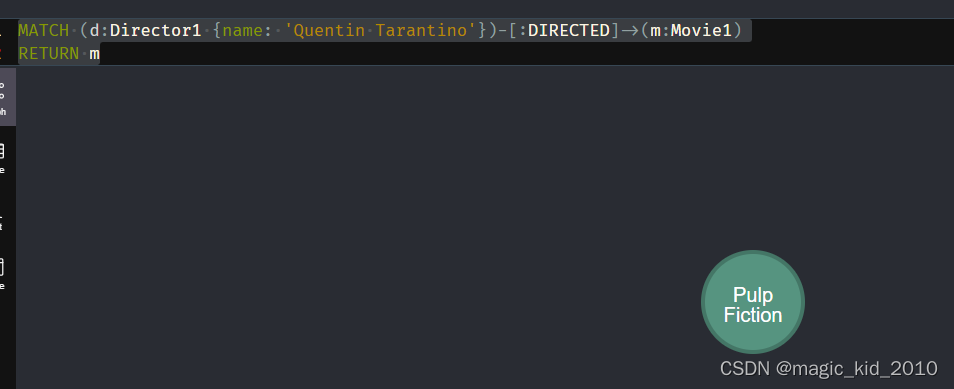
查询某个导演指导的所有电影
MATCH (d:Director1 {name: 'Quentin Tarantino'})-[:DIRECTED]->(m:Movie1)
RETURN m
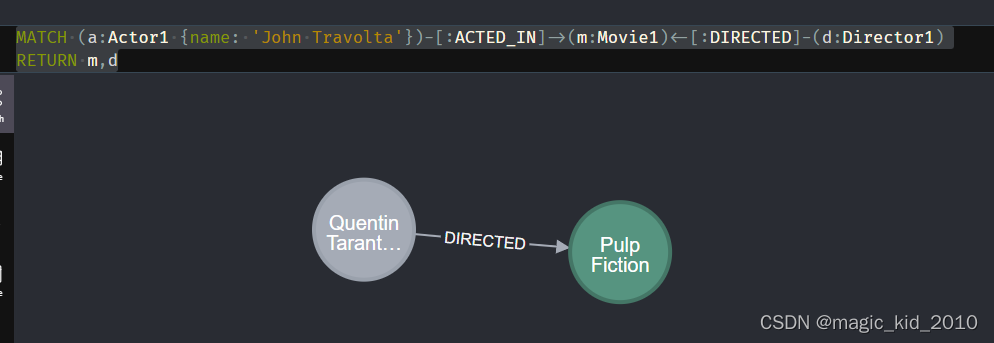
查询某个演员和导演之间的共同作品
MATCH (a:Actor1 {name: 'John Travolta'})-[:ACTED_IN]->(m:Movie1)<-[:DIRECTED]-(d:Director1)
RETURN m,d
推荐与某个电影相似的电影
MATCH (m:Movie1 {title: 'The Shawshank Redemption'})<-[:ACTED_IN|DIRECTED]-(p)-[:ACTED_IN|DIRECTED]->(rec:Movie1)
WHERE m <> rec
RETURN rec.title, COUNT(*) AS similarity
ORDER BY similarity DESC
匹配与电影《The Shawshank Redemption》有共同参演或导演的节点,并按照共同参演或导演的数量从高到低进行排序。这样可以推荐与《The Shawshank Redemption》相似的电影,因为它们有相同的演员或导演。
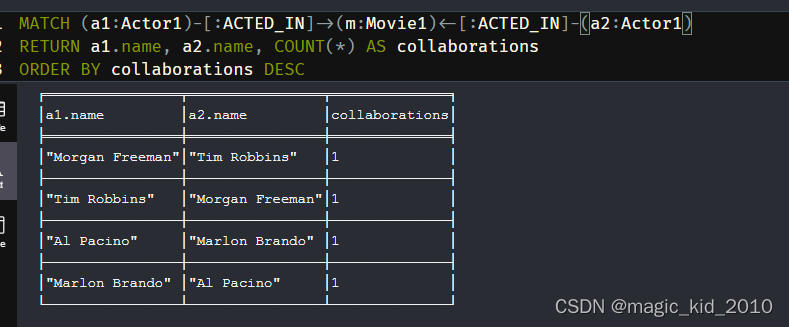
根据演员之间的关系构建合作网络
MATCH (a1:Actor1)-[:ACTED_IN]->(m:Movie1)<-[:ACTED_IN]-(a2:Actor1)
RETURN a1.name, a2.name, COUNT(*) AS collaborations
ORDER BY collaborations DESC
查询演员之间的合作次数,并按照合作次数从高到低进行排序。这样可以找出演员之间合作最频繁的组合,从而了解他们之间的合作关系。
拓展

