
- 1隐语开源社区「2022年度开源报告」
- 2Github Copilot 的使用方法和快捷键_github copilot使用
- 3UniVue一个基于MVVM设计的Unity高效率UI框架_unity mvvm的ui
- 4词云(附带操作实例)
- 5上海计算机考研避雷,25考研慎报
- 62024年GitHub上最流行前25大Python开源项目,你收藏了吗?_github上python专门用于分割石头和沙粒的事物_python学习项目 github
- 7android 是Application类先运行还是AndroidManifest.xml中action先运行?Application类先运行
- 8【华为OD机试B卷】服务器广播、需要广播的服务器数量(C++/Java/Python)
- 9【LeetCode刷题(简单程度)】面试题 02.02. 返回倒数第 k 个节点_leetcode刷到什么程度
- 10【Rust】日志库log_rust log
论文阅读:H-ViT,一种用于医学图像配准的层级化ViT
赞
踩
来自CVPR的一篇文章,https://openaccess.thecvf.com/content/CVPR2024/papers/Ghahremani_H-ViT_A_Hierarchical_Vision_Transformer_for_Deformable_Image_Registration_CVPR_2024_paper.pdf
用CNN+Transformer混合模型做图像配准。可变形图像配准是一种在相同视场内比较或整合单模态或多模态视觉数据的技术,它旨在找到两幅图像之间的非线性映射关系。
1,模型结构
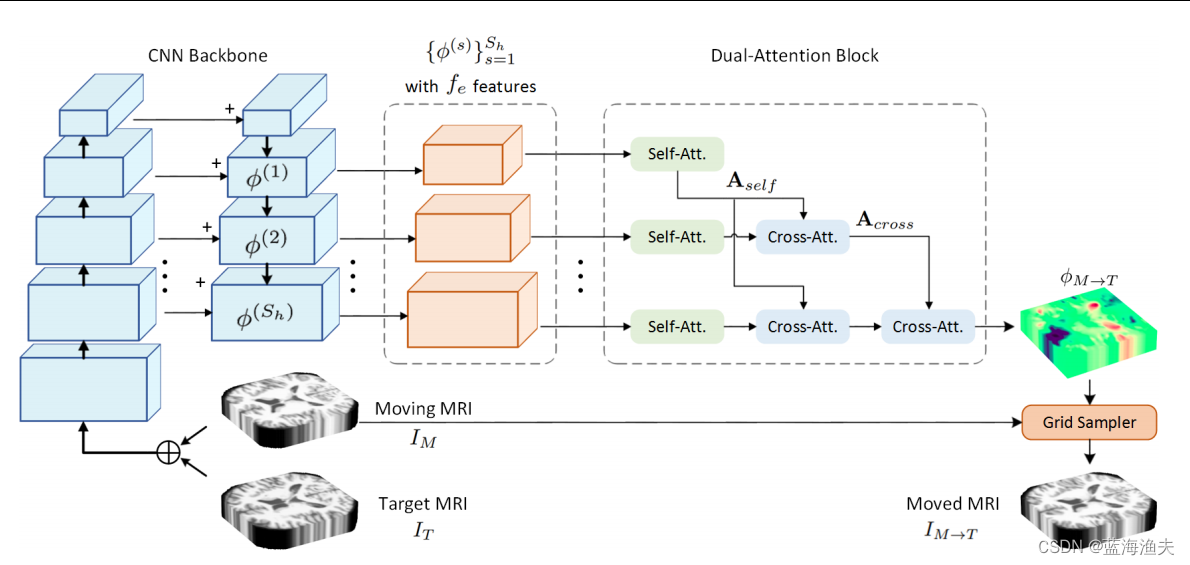
首先,使用类似特征金字塔网络(FPN)的CNN作为主干网络,用于从输入图像中提取多尺度的特征图。顶层的Sh个CNN特征被用来生成Transformer特征。这些特征首先会被映射成通道数量为fe,然后做embedding。然后输入双注意力模块。双注意力模块会生成变形场,最后网格采样器根据变形场生成目标图像。
2,双注意力模块
双注意力模块由自注意力和交叉注意力组成,
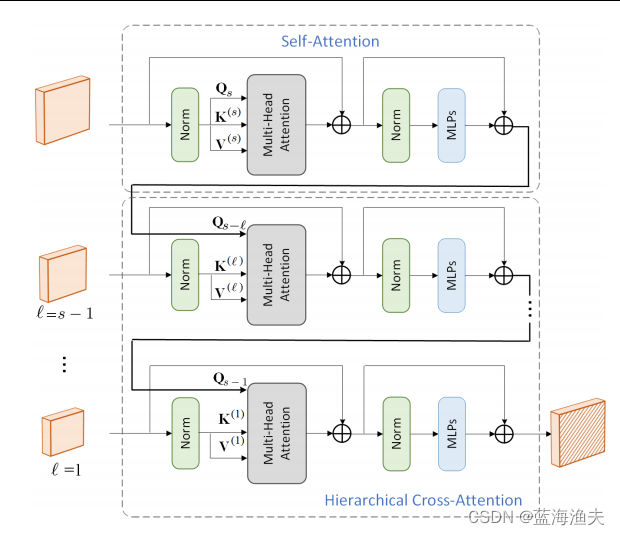
如图展示了双注意力模块在不同尺度上应用自注意力和交叉注意力的过程。交叉注意力和自注意力都是QKV结构。
其中第一部分是自注意力,QKV均来自同一尺度特征。下面两个部分是交叉注意力,Q和KV来自不同尺度的特征。
3,损失函数
本文模型使用的损失函数包含两个部分:相似性损失和平滑性损失。
相似性损失的公式如下:

平滑性损失的作用是为了防止产生不连续的变形场,公式如下:

平滑性损失计算的是变形场的空间梯度的L2范数,这样可以更强烈地惩罚那些梯度较大的区域。
整体损失函数公式如下:

其中λ是预定义的系数。
4,变形场和网格采样器
4.1 变形场
变形场(Deformation Field)是图像配准中的一个重要概念,是一个从移动图像(源图像)到目标图像的映射。它定义了移动图像中每个点在目标图像空间中的新位置。数学上,变形场可以表示为一个向量场,其中每个向量指向源图像中相应点在目标图像中的位置偏移。
4.2网格采样器
它的作用是根据一个给定的变形场来重新采样图像的像素网格,从而实现图像的变形或映射。变形场通常是一个向量场,网格采样器根据变形场中的向量,计算出原始图像中每个像素点的新位置。如果新位置是子像素位置,则需要使用插值方法来计算这个新位置的像素值。
5,实验
5.1 使用的度量
为了量化模型的性能,使用了多种度量标准,如Dice分数、HD95、SDlogJ等。
其中,HD95:是Hausdorff距离的95%分位数,意味着在95%的情况下,配准误差不会超过这个值。这是一种衡量两组几何对象之间相似度的方法,常用于评估图像配准算法的性能。Hausdorff距离是度量两个点集A和B之间最大距离的度量。计算公式为:H(A,B) = max(h(A,B), h(B,A)),其中h(A,B)表示集合A中的点到集合B中最近点的最大距离,h(B,A)表示集合B中的点到集合A中最近点的最大距离。
SDlogJ:Standard Deviation of the Logarithm of the Jacobian Determinant,是一个统计量,用于度量变形场中雅可比行列式对数值的标准差。雅可比行列式描述了一个点从一个坐标系统映射到另一个坐标系统时体积变化的比率。简单来说,它反映了变换过程中局部体积的膨胀或收缩情况。由于雅可比行列式值可能非常大或非常小,为了方便数学处理和比较,通常会取其对数值。这样做可以使得数据更加平稳。
5.2 实验结果
实验使用了五个公开可用的T1 MRI数据库,包括OASIS、IXI、ADNI、LPBA和Mindboggle。对比了VoxelMorph、MIDIR、CycleMorph、ViT-V-Net和TransMorph等基准方法。实验表格比较多那就不贴了,总之就是超越了这些方法。

