
- 1图生图—AI图片生成Stable Diffusion参数及使用方式详细介绍_stable diffusion图生图
- 2用Python编写猜数字游戏_python猜数字游戏编程
- 3easyExcel中的注解_@excelproperty
- 4Spring Boot图书管理系统项目实战-6.图书管理_项目实战spring 图书管理系统
- 5Vue 3.2+Vite2 + Element-Plus 开发的后台管理系统(后台模板)_vue3 + javascript + elementplus后台框架教程
- 6抖音短视频数据抓取实战系列(十二)——抓取实战BUG总集_抖音 大模型抓去 视频的整体内容
- 7终于有人把AB实验讲明白了
- 8利用Python+selenium技术,实现浏览器基本操作详解,代码有详细注释_python浏览器
- 9GCC Manual_-fdump-tree-pre
- 10阿里巴巴程序员等级_程序员hollis是阿里p几
llama.cpp模型推理之界面篇_llama.cpp server api
赞
踩
目录
前言
在《基于llama.cpp学习开源LLM本地部署》这篇中介绍了基于llama.cpp学习开源LLM本地部署。在最后简单介绍了API 的调用方式。不习惯命令行的同鞋,也可以试试 llama.cpp 界面的交互方式,本章就详细介绍一下server。
一、llama.cpp 目录结构

整个目录比较简洁,没多少东西,以最少的代码实现最全的功能,值得学习。文档都很全,基本上在学习该推理框架时遇到或者没有想到,你都能在根目录或子目录的README.md 找到。
本章主要讲 server的界面。可以在examples/server下看看README。或者直接翻到根目录下打开README.md. 找到如下点击:
二、llama.cpp 之 server 学习
1. 介绍
llama.cpp 的 server 服务是基于 httplib 搭建的一个简单的HTTP API服务和与llama.cpp交互的简单web前端。
server命令参数:
--threads N,-t N: 设置生成时要使用的线程数.-tb N, --threads-batch N: 设置批处理和提示处理期间使用的线程数。如果未指定,则线程数将设置为用于生成的线程数-m FNAME,--model FNAME: 指定 LLaMA 模型文件的路径(例如,models/7B/ggml-model.gguf).-a ALIAS,--alias ALIAS: 设置模型的别名。别名将在 API 响应中返回.-c N,--ctx-size N: 设置提示上下文的大小。默认值为 512,但 LLaMA 模型是在 2048 的上下文中构建的,这将为更长的输入/推理提供更好的结果。其他模型的大小可能有所不同,例如,百川模型是在上下文为 4096 的情况下构建的.-ngl N,--n-gpu-layers N: 当使用适当的支持(目前为 CLBlast 或 cuBLAS)进行编译时,此选项允许将某些层卸载到 GPU 进行计算。通常会导致性能提高.-mg i, --main-gpu i: 使用多个 GPU 时,此选项控制哪个 GPU 用于小张量,对于这些张量,在所有 GPU 之间拆分计算的开销是不值得的。有问题的 GPU 将使用稍多的 VRAM 来存储暂存缓冲区以获得临时结果。默认情况下,使用 GPU 0。需要 cuBLAS.-ts SPLIT, --tensor-split SPLIT: 使用多个 GPU 时,此选项控制应在所有 GPU 之间拆分多大的张量。SPLIT 是一个以逗号分隔的非负值列表,用于分配每个 GPU 应按顺序获取的数据比例。例如,“3,2”会将 60% 的数据分配给 GPU 0,将 40% 分配给 GPU 1。默认情况下,数据按 VRAM 比例拆分,但这可能不是性能的最佳选择。需要 cuBLAS.-b N,--batch-size N: 设置用于提示处理的批大小。默认值:512.--memory-f32: 使用 32 位浮点数而不是 16 位浮点数来表示内存键 + 值。不推荐.--mlock: 将模型锁定在内存中,防止在内存映射时将其换出.--no-mmap: 不要对模型进行内存映射。默认情况下,模型映射到内存中,这允许系统根据需要仅加载模型的必要部分.--numa: 尝试对某些 NUMA 系统有帮助的优化.--lora FNAME: 将 LoRA(低秩适配)适配器应用于模型(隐含 --no-mmap)。这允许您使预训练模型适应特定任务或领域.--lora-base FNAME: 可选模型,用作 LoRA 适配器修改的层的基础。此标志与 --lora 标志结合使用,并指定适配的基本模型.-to N,--timeout N: 服务器读/写超时(以秒为单位)。默认值:600.--host: 设置要侦听的主机名或 IP 地址. 默认127.0.0.1.--port: 将端口设置为侦听。默认值:8080--path: 从中提供静态文件的路径 (default examples/server/public)--embedding: 启用嵌入提取,默认值:禁用.-np N,--parallel N: 设置进程请求的槽数(默认值:1)-cb,--cont-batching: 启用连续批处理(又名动态批处理)(默认:禁用)-spf FNAME,--system-prompt-file FNAME:将文件设置为加载“系统提示符(所有插槽的初始提示符)”,这对于聊天应用程序很有用.--mmproj MMPROJ_FILE: LLaVA 的多模态投影仪文件的路径.
2. 编译部署
编译部署请参考《基于llama.cpp学习开源LLM本地部署》。会在跟目录下生成 ./server
3. 启动服务
./server -m ../models/NousResearch/Llama-2-7b-chat-hf/ggml-model-q4_0.gguf -c 2048服务启动成功后,如下:

点击或者在浏览器中输入:http://127.0.0.1:8080
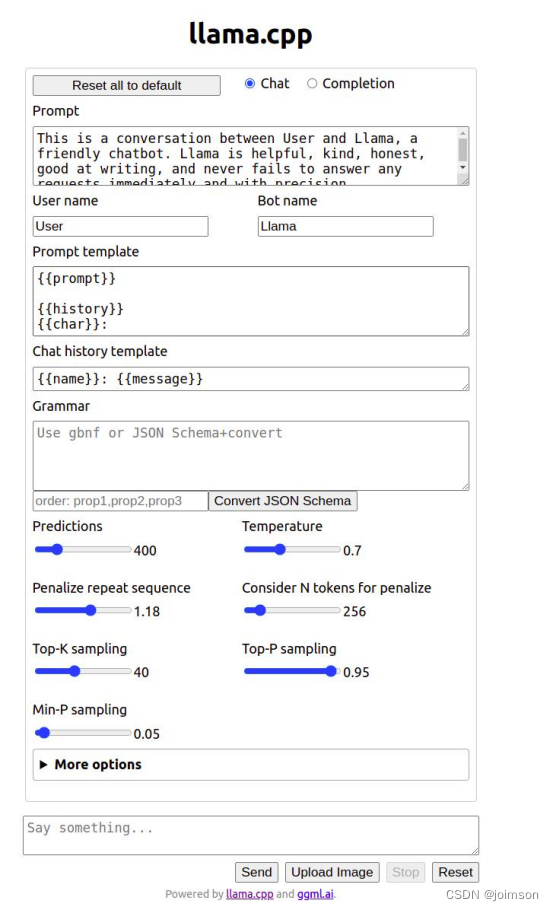
可以看到:交互模式,提示词、用户名、提示词模板还有模型参数等设置。打开“更多选型”,如下:
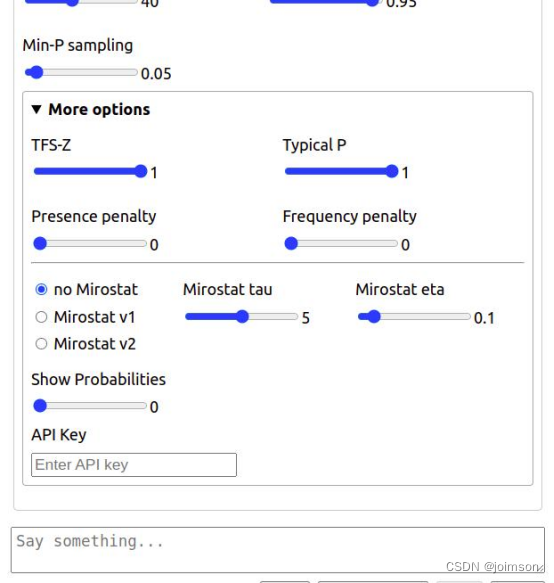
这些参数默认就行,也可以根据实际情况调整。
在最下面输入一些内容,点击“send”,就能与模型进行聊天了。
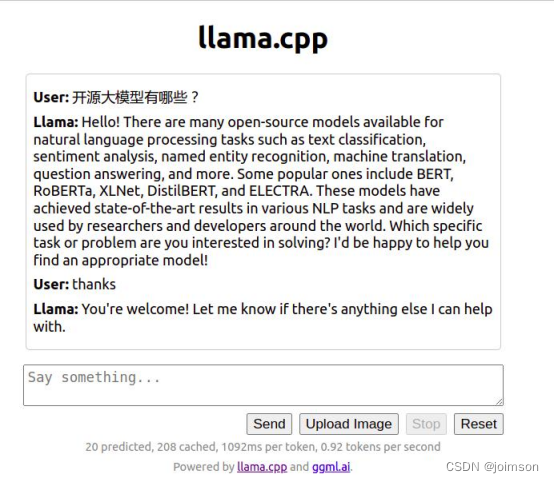
从学习的角度来看,是不是很方面。不用敲命令,也不用单独搭建前端。直接就能体验大模型,也能学习里面机制与原理。
4、扩展或构建其他的 Web 前端
web静态文件的默认位置是“examples/server/public”。您可以通过运行./server并将“--path”设置为“./your-directory”并导入“/completion.js”来访问 llamaComplete() 方法来扩展前端。
- A simple example is below:
-
- <html>
- <body>
- <pre>
- <script type="module">
- import { llama } from '/completion.js'
-
- const prompt = `### Instruction:
- Write dad jokes, each one paragraph.
- You can use html formatting if needed.
- ### Response:`
-
- for await (const chunk of llama(prompt)) {
- document.write(chunk.data.content)
- }
- </script>
- </pre>
- </body>
- </html>

5、其他
更多功能和参数,详见llama.cpp/examples/server/README.md。

