
- 1RHCE9学习指南 第7章 服务管理
- 2Python学习笔记_python 3.12.1 (tags/v3.12.1:2305ca5, dec 7 2023, 2
- 3css 纯样式实现绘出进度条_进度条 纯css 样式
- 4看漫画学python!终于有人把python整理成漫画书了,让人茅塞顿开_漫画python
- 5vue动态路由权限管理_路由meta标签roles
- 6Nacos_nacos 网关
- 7Nacos集群搭建并整合springboot完整教程_springboot nacos集群
- 8模拟a标签下载文件(同源下载、跨域下载)_a标签下载附件跨域
- 901 React入门、虚拟DOM_reactdom.createroot
- 10Innodb_buffer_pool_pages_innodb_buffer_pool_pages_data
时间序列基础操作:使用python与eviews对AR与ARMA模型进行定阶与预报_sm.tsa.arma_order_select_ic
赞
踩
一般处理时间序列的基本过程:(无季节趋势)

注:上图中LB检验的统计量纠正:n*(n+2),而不是n*(n-2)
几种基础时间序列模型(模型的具体形式补充见文末):

目录
以《应用时间序列分析》王燕,第四版中p94-p96页中17题数据为例
基础介绍:
一、Python处理
重点参考文章:
时间序列模型(ARIMA和ARMA)完整步骤详述_Foneone的博客-CSDN博客_arma_order_select_ic
1.1.step1:平稳性检验与白噪音检验
首先可以绘制线图直接观察数据走势粗略判断平稳性,既无趋势也无周期;
df.plot(color='blue',title='data-17') #绘制时间序列的线图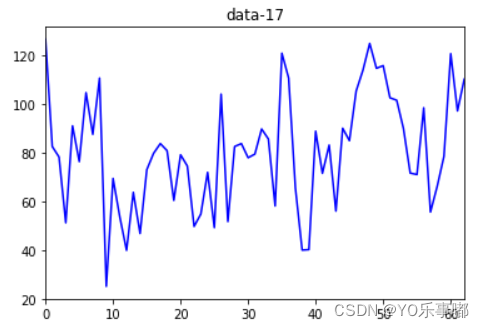
1.1.1平稳性检验:ADF检验
· 检验假设:H0:存在单位根 vs H1:不存在单位根
如果序列平稳,则不应存在单位根,所以我们希望能拒绝原假设
· python代码:adfuller
- from statsmodels.tsa.stattools import adfuller
- adftest = adfuller(x, autolag='AIC') #ADF检验
检验结果如下:
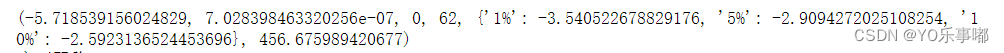
adftest[0]:ADF检验的t值; adftest[1]:ADF检验的t值的p值; adftest[4:6]:ADF检验对应三个置信度(1%,5%,10%)的t值,可以直接将 adftest[0]与这三个值做比较;
由本输出结果来看-5.7185显著小于后面三个t值,且p值接近为0,因而在1%的显著水平下拒绝原假设,认为该序列平稳;
1.1.2差分修正:
若不平稳可以考虑做差分运算修正为平稳序列。若差分后平稳,则对原序列建立ARIMA模型。
· python代码:timeseries.diff( )
- #### 差分运算
- def diff(timeseries):
- d1_sale=timeseries.diff(periods=1).dropna()#dropna删除NaN
- d1_sale.plot(color='orange',title='diff1')
- return d1_sale
1.1.3白噪音检验:L-B统计量/Q统计量
· 检验假设与统计量:

(上图a.中的“残差”应当替换为“序列”)通常m取【n/10】or【根号n】若观测量较小也可以取【n/4】;若拒绝原假设则认为不是白噪音检验
· python代码:acorr_ljungbox
- from statsmodels.stats.diagnostic import acorr_ljungbox #白噪声检验
- test_value = acorr_ljungbox(timeseries, lags=1)
检验结果如下:
![]()
test_value[1]为p值,所以可以在5%的显著水平下认为该序列不是一个白噪音序列
1.2.step2:模型识别与定阶
1.2.1法一:观察ACF与PACF的拖尾与截尾

· python代码:
plot_acf(timeseries,lags) #lags:延迟阶数
plot_pacf(timeseries,lags)
- import statsmodels.api as sm
- from statsmodels.graphics.tsaplots import plot_acf,plot_pacf
- def determinate_order_acf(timeseries):
- plot_acf(timeseries,lags=30) #自己定延迟数
- plot_pacf(timeseries,lags=30)
- plt.show()
输出结果如下:
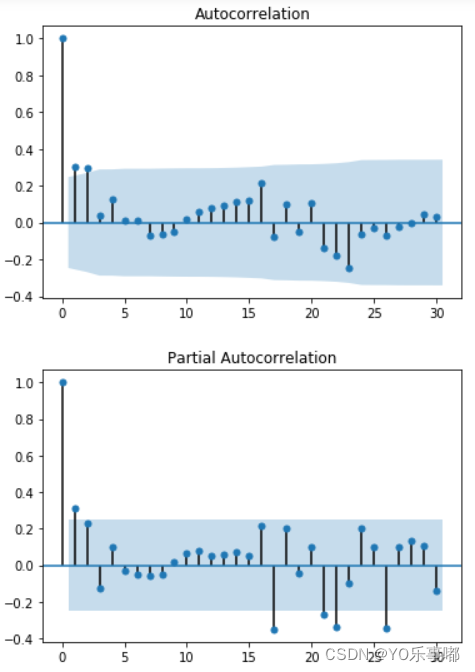
1.2.2法二:AIC与BIC信息准则
迭代不同p与q的取值下的估计,选取AIC与BIC最小的参数p与q;
注:AIC可能高估阶数,BIC可能低估阶数
· python代码:sm.tsa.arma_order_select_ic
- #AIC
- AIC_summary=sm.tsa.arma_order_select_ic(timeseries,max_ar=4,max_ma=0,ic='aic')
- #BIC
- BIC_summary=sm.tsa.arma_order_select_ic(timeseries,max_ar=4,max_ma=0,ic='bic')
输出结果:

如果想直接得到AIC与BIC最小的阶数则直接加入索引:['aic_min_order']
- #AIC
- AIC=sm.tsa.arma_order_select_ic(timeseries,max_ar=ar_max,max_ma=ma_max,
- ic='aic')['aic_min_order']
- #BIC
- BIC=sm.tsa.arma_order_select_ic(timeseries,max_ar=ar_max,max_ma=ma_max,
- ic='bic')['bic_min_order']
- print('the AIC is{},\nthe BIC is{}\n'.format(AIC,BIC))
1.3.step3:模型构建与预报
· 模型构建:arma_model = ARMA(train_data,order).fit()
· 模型预报:arma_model.forecast(pred_end)
- #### 模型构建:利用机器学习的知识(?
- def ARMA_model(train_data,order,pred_end): # train_data:(训练数据,测试数据)拟合数据,order:所定阶数
- arma_model = ARMA(train_data,order).fit()#ARMA模型训练器
- #拟合结果
- print(arma_model.summary())
- #给出一个残差序列的方差 尝试作为sigma的估计值(不确定对不对
- print('随机扰动项的标准差sigma估计:',np.std(arma_model.resid))
- #out_sample_pred = arma_model.predict(start=len(train_data),end = len(train_data)+pred_end-1,dynamic=True)
- #print(out_sample_pred)
- print('预测未来{}天,其预测结果\n{}\n标准误差\n{}\n置信区间如下:\n{}'.format(pred_end,
- arma_model.forecast(pred_end)[0],
- arma_model.forecast(pred_end)[1],
- arma_model.forecast(pred_end)[2]))
缺点:ARMA模型训练器的结果似乎没有含随机扰动项服从方差的估计(输出残差序列arma_model.resid尝试计算其方差来替代)使用ARIMA模型似乎可以得到sigma的估计值(?不确定 ARIMA的操作还没学www)
输出结果:
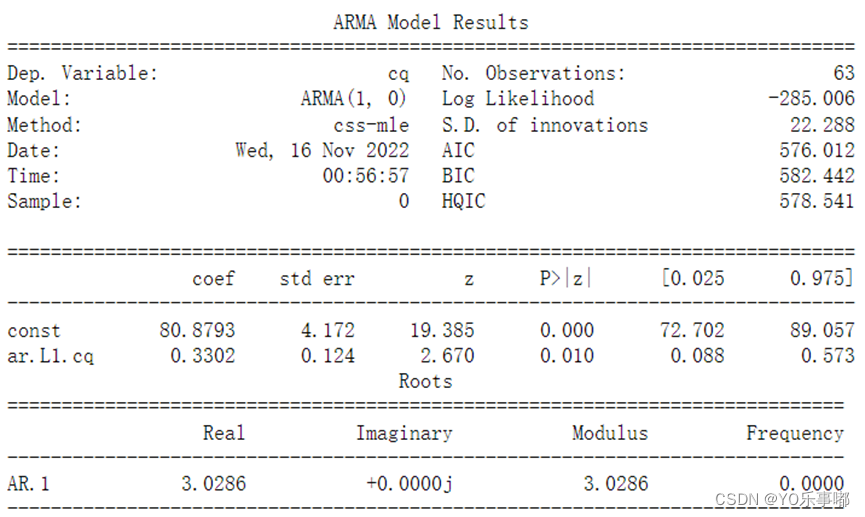
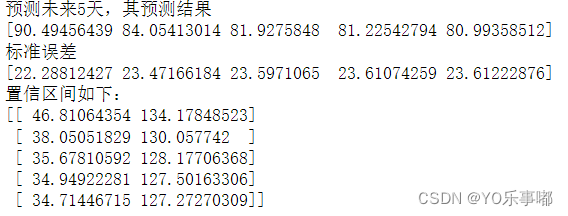
1.3.4step4:模型检验
把残差序列再做一次白噪音检验;其余还有qq图检验正态性等(待补充)
二、Eviews处理
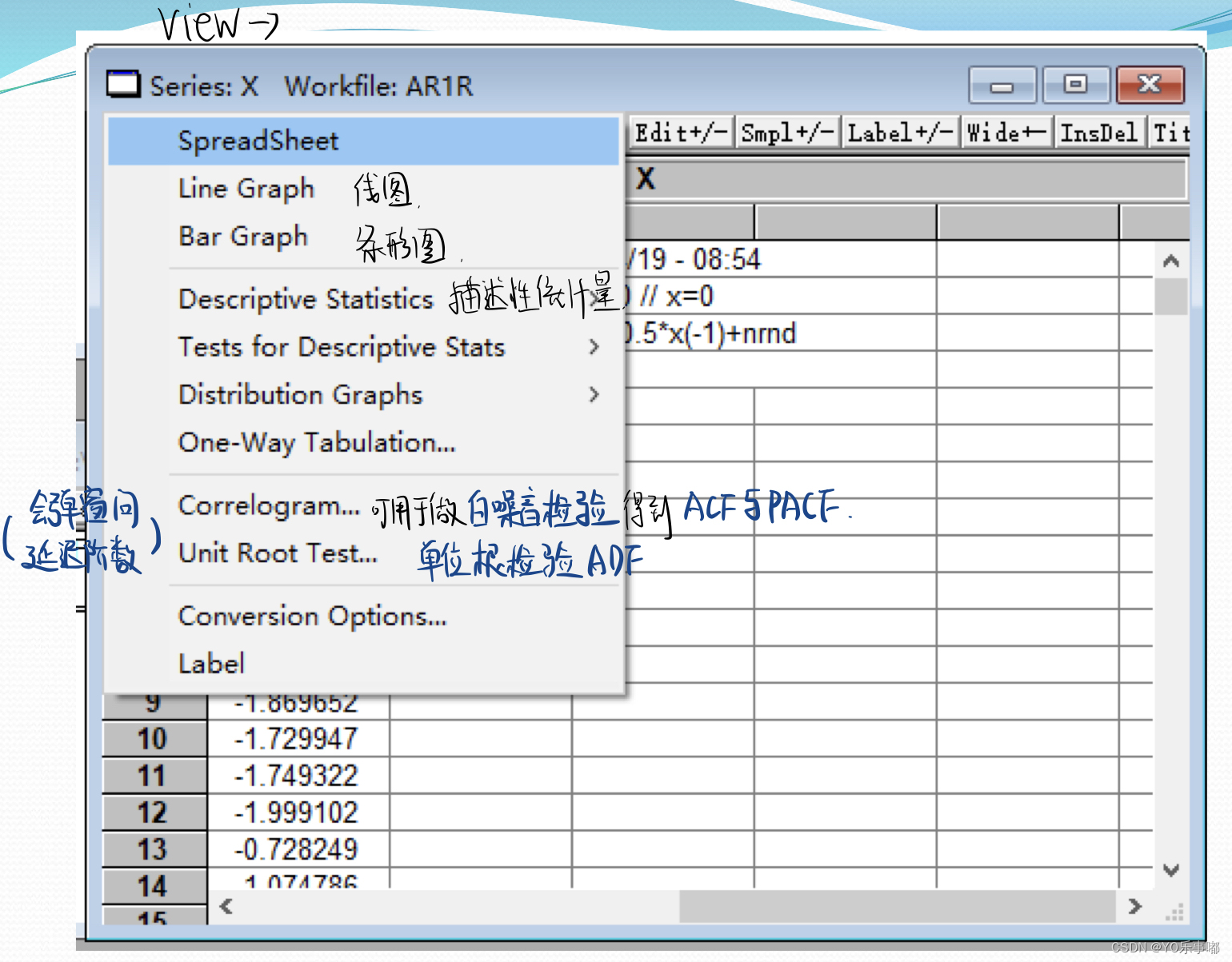
2.1.step1:平稳性检验与白噪音检验
2.1.1平稳性检验:ADF检验:UnitRoot Test
2.1.2白噪音检验:Correlogram 直接观察ACF的Q检验统计量与p值。本题输出结果如下图,可以拒绝原假设,即是一个非随机序列。如果p值较大,接受原假设,认为是白噪音序列(但此时要注意观察序列线图,有没有存在异方差问题,如果存在异方差,则也不能认为是白噪音)
2.2.step2:模型识别与定阶
法一:观察ACF与PACF的拖尾与截尾:Correlogram 直接观察即可。
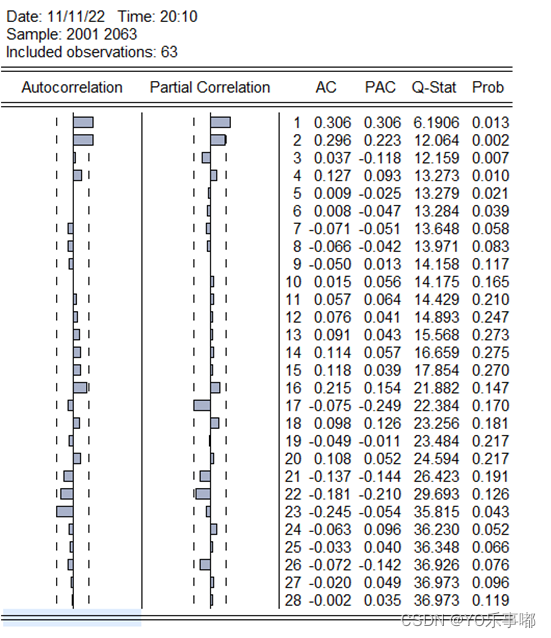
法二:AIC与BIC准则:eviews内部没有自动迭代检测最小AIC与BIC的方法,只能自行选取几个备选模型分别做拟合,得到的结果中含有AIC的值,自己人工比较;
2.3.step3:模型构建与预报
2.3.1模型构建:
补一些建模指令:
MA(1)模型:ls x c ma(1)
生成一阶差分:genr->d(x)或x-x(-1)


关于随机扰动项服从标准差的估计值:利用resid序列的统计学描述,选取Std.Dev.作为估计值;
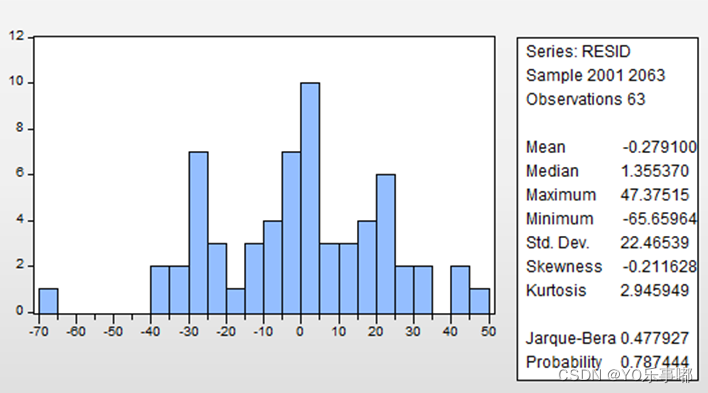
2.3.2模型预报:
![]()
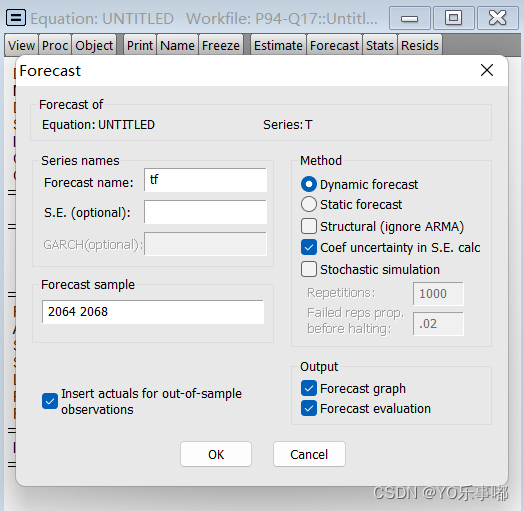
先expand序列的长度,再在拟合的模型上点击forecast,选取预测范围,得到的新的序列内即含有预测的结果;
注:eviews不会提供预报的误差具体值,只会提供一个置信区间的图;
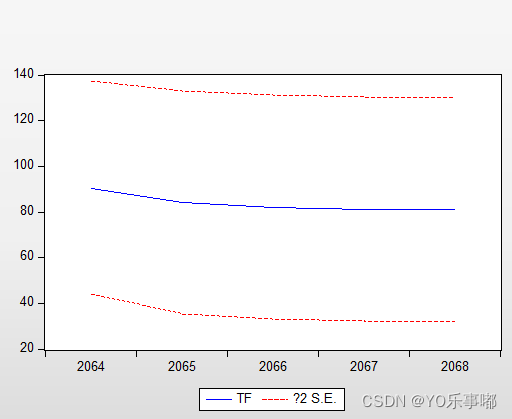
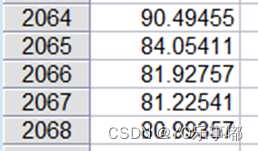
2.4.step4:模型检验
残差的白噪音检验:选择数据框内的r(残差序列)继续:Correlogram 观察ACF的Q检验统计量与p值。
2.5ARCH模型的检验和建立
(此处使用的是一组新数据)
ARCH模型的形式:

step1:按照前面的方式建立合适的主回归模型
step2:ARCH效应检验:LM检验
对主模型的残差做ARCH效应的LM检验
View→Residual Diagnostics→Heteroskedasticity Tests→ARCH 然后再lags处自己定延迟阶数

LM检验:H0不存在ARCH效应的异方差问题
观察检验的p值:若p值很小,则拒绝原假设,认为残差具有异方差问题,存在ARCH效应。


step3:对残差建立ARCH模型
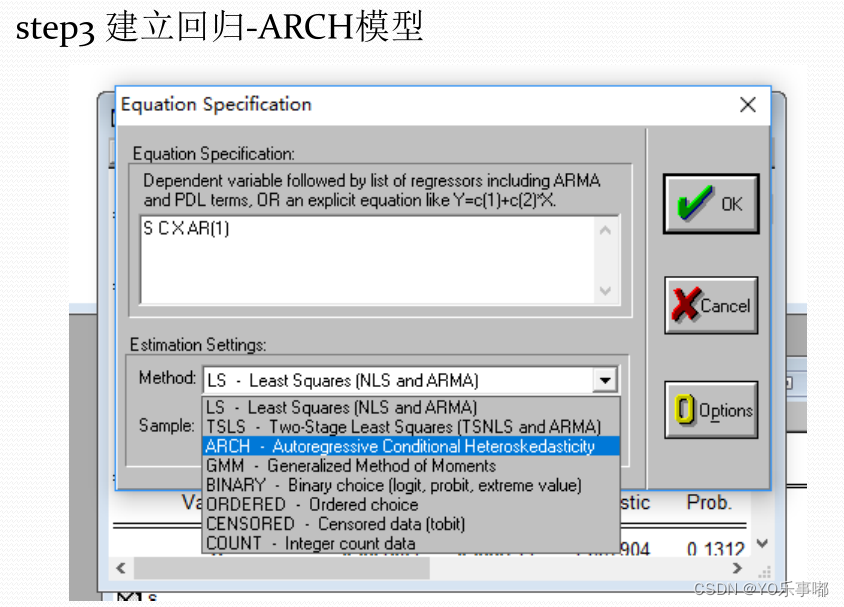
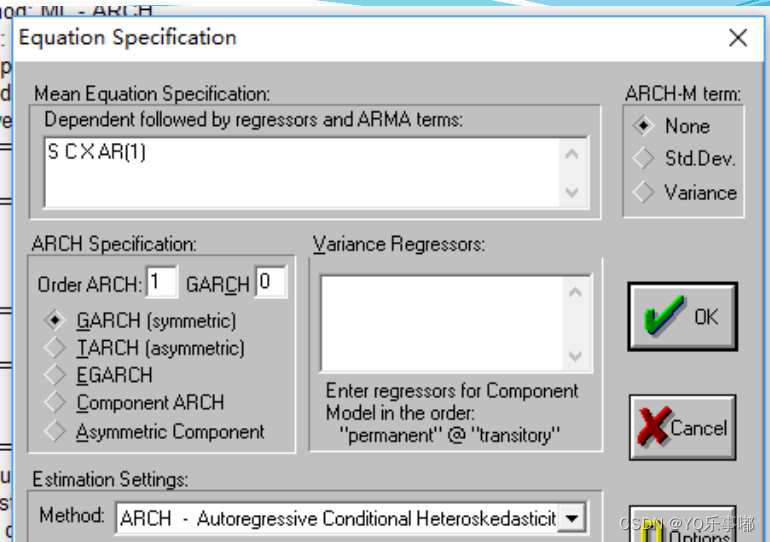
三、Python实践过程
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt #画图
- import statsmodels.api as sm
-
- from statsmodels.graphics.tsaplots import plot_acf,plot_pacf #ACF与PACF
- from statsmodels.tsa.stattools import adfuller #ADF检验
- from statsmodels.stats.diagnostic import acorr_ljungbox #白噪声检验
- from statsmodels.tsa.arima_model import ARMA #ARMA模型
- from statsmodels.tsa.arima_model import ARIMA #ARIMA模型
step1:平稳性检验与白噪音检验
- #### 平稳性检验
- def ADF_test(timeseries):
- x = np.array(timeseries) #转为一维数组
- adftest = adfuller(x, autolag='AIC') #ADF检验
- print (adftest)
- if adftest[0] < adftest[4]["1%"] and adftest[1] < 10**(-6):
- # 对比Adf结果和10%的时的假设检验 以及 P-value是否非常接近0(越小越好)
- print("序列平稳")
- return True
- else:
- print("非平稳序列")
- return False
-
- #### 随机性检验(白噪声检验)
- def random_test(timeseries) :
- p_value = acorr_ljungbox(timeseries, lags=1) # p_value 返回二维数组,第二维为P值
- #print(p_value)
- if p_value[1] < 0.05:
- print("非随机性序列")
- return True
- else:
- print("随机性序列,即白噪声序列")
- return False
- """
- ————————————————
- 版权声明:本文为CSDN博主「Foneone」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
- 原文链接:https://blog.csdn.net/foneone/article/details/90141213
- """

注:我在实际使用上述ADF检验时会出现与eviews的ADF检验输出的统计量结果相差很多的情况,暂时不知道问题出在了哪里。
差分运算:
- #### 差分运算
- def diff(timeseries):
- d1_sale=timeseries.diff(periods=1).dropna()#dropna删除NaN
- d1_sale.plot(color='orange',title='diff1')
- return d1_sale
step2:模型选择与定阶
模型选择:绘制ACF与PACF
- #### 绘制ACF与PACF的图像
- def plot_acf_pacf(timeseries): #利用ACF和PACF判断模型阶数
- plot_acf(timeseries,lags=30) #延迟数
- plot_pacf(timeseries,lags=30)
- plt.show()
AIC与BIC定阶:两种方法
#法一:利用自带函数:ARIMA模型则需要用差分后的序列带入。
#法二:迭代调优
法二参考文章:时间序列分析ARIMA及其Python实现_木星健谈能手的博客-CSDN博客_arima python实现
- #### AIC与BIC定阶
- #法一:利用自带函数
- def detetminante_order(timeseries,ar_max,ma_max): #信息准则定阶:AIC、BIC
- #AIC
- AIC_summary=sm.tsa.arma_order_select_ic(timeseries,max_ar=ar_max,max_ma=ma_max,ic='aic')
- #BIC
- BIC_summary=sm.tsa.arma_order_select_ic(timeseries,max_ar=ar_max,max_ma=ma_max,ic='bic')
- print('the AIC is{},\nthe BIC is{}\n'.format(AIC_summary.['aic_min_order'],BIC.['bic_min_order']))
- print(AIC_summary,'\n',BIC_summary)
-
- #法二:迭代调优
- def determine_aic_arima(train_data,pmax,I,qmax):
- aic_matrix=[]
- for p in range(pmax+1):
- tmp=[]
- for q in range(qmax+1):
- try:
- tmp.append(ARIMA(train_data,order=(p,I,q)).fit().aic)
- except:
- tmp.append(None)
- aic_matrix.append(tmp)
- aic_matrix=pd.DataFrame(aic_matrix)
- p,q=aic_matrix.stack().idxmin() #最小值的索引
- print('用AIC方法得到最优的p值是%d,q值是%d'%(p,q))
-
- def determine_bic_arima(train_data,pmax,I,qmax):
- bic_matrix=[]
- for p in range(pmax+1):
- tmp=[]
- for q in range(qmax+1):
- try:
- tmp.append(ARIMA(train_data,order=(p,I,q)).fit().bic)
- except:
- tmp.append(None)
- bic_matrix.append(tmp)
- bic_matrix=pd.DataFrame(bic_matrix)
- p,q=bic_matrix.stack().idxmin() #最小值的索引
- print('用AIC方法得到最优的p值是%d,q值是%d'%(p,q))
step3:模型构建与预报
如果需要拟合ARIMA,则只需要替换为ARIMA(train_data,order).fit()即可
- #### 模型构建:利用机器学习的知识(?
- def ARMA_model(train_data,order,pred_end): # train_data:(训练数据,测试数据)拟合数据,order:所定阶数
- arma_model = ARMA(train_data,order).fit()#ARMA模型训练器
- print(arma_model.summary()) #拟合结果
- print('随机扰动项的标准差sigma估计:',np.std(arma_model.resid))#给出一个残差序列的方差 尝试作为sigma的估计值(不确定对不对
- print('预测未来{}天,其预测结果\n{}\n标准误差\n{}\n置信区间如下:\n{}'.format(pred_end,
- arma_model.forecast(pred_end)[0],
- arma_model.forecast(pred_end)[1],
- arma_model.forecast(pred_end)[2]))
正式过程:
- df1=pd.read_excel(r'F:\个人嘿嘿嘿\北师大BNU\研一上-课业资料\时间序列\作业2\timeseries17.xlsx')
- df17=df1['cq']
-
- df17.plot(color='blue',title='data-17') #绘制时间序列的线图
- plot_acf_pacf(df17) #绘制时间序列的ACF与PACF
- ADF_test(df17) #平稳性检验
- random_test(df17) #白噪音检验
- detetminante_order(df17,4,0) #AIC,BIC定阶
- ARMA_model(df17,(1,0),5) #模型拟合和预报
四、时序常见模型的形态
(一)AR模型(自回归模型)
当前时间点的数据与过去自身数据的关系。

(二)MA模型(滑动平均模型)
当前时间点的数据与过去噪声的关系。

(三)ARMA模型(自回归滑动平均模型)

(四)ARIMA模型:针对有趋势的时间序列

(五)乘积的ARMA模型:有季节周期的时间序列

(六)乘积的ARIMA模型:有趋势+周期的时间序列

(七)ARCH模型+GARCH模型
ARCH模型:自回归条件异方差模型
特点:当自回归模型的残差是异方差时,对残差形式做了变换,使其等于过去残差的某种变换,从而满足同方差假定;

GARCH模型:引入滞后算子的自回归条件异方差模型


