
- 1PyCharm 安装插件Vue_社区版pycharm 如何安装vue.js
- 2centos8安装教程,个人笔记本_红米电脑怎么下载centos
- 3如何用自己电脑架设服务器!自助建站将不再是梦想_有硬盘自己架设关键词服务器怎么办啊
- 4SQL数据库select基本使用_sql中select的用法
- 5Ubuntu 搭建MQTT服务器_ubuntu搭建mqtt服务器
- 6MATLAB-画图汇总_matlab画图代码
- 7nacos作为SpringCloud注册中心_nacos作为springcloud的注册中心
- 8zynq FPGA 的双目视觉毕业设计(八)之FPGA最终实现_fpga研究生毕设
- 9java 聊天室 私聊_Java 网络编程 -- 基于TCP 实现聊天室 群聊 私聊
- 10Android Studio快捷键使用收藏_android studio如何实现收藏功能
AlexNet和VGGNet重点摘要总结(包含Fancy PCA详解和SGD)_从alexnet改成vggnet 超参数怎么调?
赞
踩
AlexNet和VGGNet重点摘要总结(包含Fancy PCA详解和SGD)
由于之前都是跟着李宏毅sir和Andrew Ng学习ML,DL和CV,缺少了阅读CV界基础的一些论文这一个必需块:),所以这两天简要的读了一下AlexNet和VGG Net的论文,并对一些重要的创新点做了一些摘要
尤其是AlexNet里data augmentation里的Fancy PCA(也叫 PCA Jittering)更是让我很感兴趣,所以做了比较详细的解释,可能也是我这篇文的卖点?!嘿嘿
同时还复习了一下SGD,参考其他blog写了一些自己的理解
原文:
AlexNet
参考与引用:
1.AlexNet:https://blog.csdn.net/qq_24695385/article/details/80368618
2.Fancy PCA:https://blog.csdn.net/b1055077005/article/details/96013305
3.BGD与SGD:https://blog.csdn.net/kokopop007/article/details/105008643
4.VGG:https://blog.csdn.net/u013181595/article/details/80974210
AlexNet’s Discoveries and Summaries
1.ReLU Nonlinearity(非线性非饱和函数训练速度极快)
首先解答自己的几个问题!
Q:为什么“ReLU增加了网络的稀疏性”且稀疏性“主要来源于负半轴”。网络稀疏性增加的优势是什么?
首先解释稀疏性,学过数据结构的话应该听过稀疏矩阵,就是矩阵里有很多的0呗~,没错稀疏性指数据有一定的比例为0;
稀疏性增加的优势是避免模型复杂,具有特征选择的功能,有很多0就表示模型对某些特征进行了选择,因为0就代表被选掉了的特征嘛,如果全是非0,则所有特征值都用上,即没有选择性了
而ReLU的负半轴输出都是0,所以增加稀疏性
继续讲论文!
一般神经元的激活函数会选择sigmoid函数或者tanh函数
然而Alex发现在训练时间的梯度衰减方面,这些非线性饱和函数要比非线性非饱和函数慢很多。(饱和函数:sigmoid,tanh;非饱和:ReLU,LeakyReLU)
(不饱和,梯度就不容易消失,饱和了梯度就很小)
在AlexNet中用的非线性非饱和函数是f=max(0,x),即ReLU。
实验结果表明,要将深度网络训练至training error rate达到25%的话,ReLU只需5个epoches的迭代,但tanh单元需要35个epoches的迭代,用ReLU比tanh快6倍。
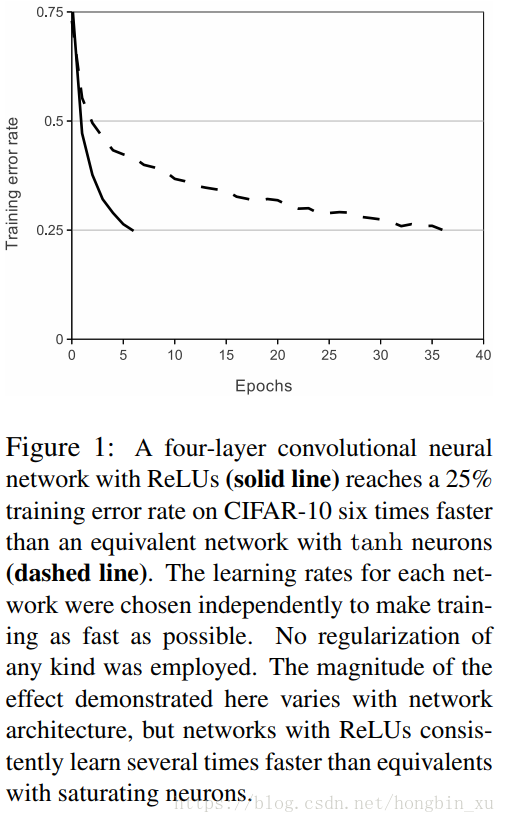
2.双GPU并行运行(可以提高运行速度和网络运行规模)
3.LRN(Local Response Normalization)局部响应归一化(学到了可用验证集确定超参)
由于ReLU是非饱和函数,所以本来是不需要对输入进行标准化,但AlexNet论文发现进行局部的标准化可以提高性能表现
这种归一化操作实现了某种形式的横向抑制,这也是受真实神经元的某种行为启发。
具体公式如下:
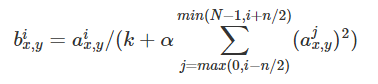
k, n, α和β是超参数,他们的值的确定是由Validation Set(验证集)确定的**(我学到的一种确定超参的办法————用validation set确定)**
我对此公式理解不是很好(也是因为现在都用BN,个人没有用过LRN,主要是Andrew Ng在课程里说不怎么好用,所以也没怎么去了解嘿嘿)
故只粘贴了参考链接1的解释内容:
其中a代表在feature map中第i个卷积核(x,y)坐标经过了ReLU激活函数的输出,n表示相邻的几个卷积核。N表示这一层总的卷积核数量。
4.减少overfitting
①数据增强(data augmentation)(pytorch里的transforms)
增强图片数据集最简单和最常用的方法是在不改变图片核心元素**(即不改变图片的分类(个人理解:不改变label))**的前提下对图片进行一定的变换,比如在垂直和水平方向进行一定的唯一,翻转等。
我比较感兴趣的是AlexNet论文中提到的第二种数据增强方式:
针对色彩(R、G、B)进行的一种PCA Jittering**(像是加了一个滤镜)**
这种方案在名义上得到了自然图像的重要特性,也就是说,目标是不随着光照强度和颜色而改变的
我认为这种方案完全可以应用在我的软件课设————火焰检测上,因为火焰在不同光源作为背景下,检测的accuracy差异是很大的,尤其在阳光下性能很差,是否可以采用这种数据增强的方式呢?
跑偏了,下面谈谈具体如何实现的:
主要思想:在图像中每个像素的R、G、B值分别加上一个数,用到的方法为PCA(主成分分析)。
例如:是256x256的RGB图像,对于每个通道,都有256 * 256个数字,对此,我们像每张图片reshape到((256 * 256),3)这样的矩阵,即3个列对应R、G、B三个颜色通道,每一列有256x256个数,一个数对应一个像素的对应通道的值
这样reshape之后,每一行就是一个三维向量(x,y,z)对应R、G、B
接下来便是PCA的操作:
然后对reshape后矩阵进行中心化,即每一个通道减去这个通道的均值
将中心化过后的矩阵乘上它的转置,然后除以(N - 1),N代表维度,求得协方差矩阵
这个covariance matrix 是3x3的协方差矩阵
然后对这个协方差矩阵求特征值和特征向量,接下来按一下方式求得:
对于图像每个像素,增加以下量:
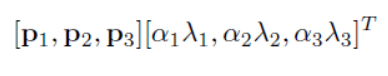
p是主成分,lamda是特征值,alpha是N(0,0.1)高斯分布中采样得到的随机值。(这样计算就得到了一个(3x1)的向量,即加在每个像素的RGB三个通道上的值)
alpha对于每张图片每次进入网络是一样的,但两次进入网络的时候,alpha是不同的,即每次有不同值的噪声(可认为是每次的滤镜是不同的)
注意:这个值是加在原图图像(即未标准化到【0,1】的输入原图像)上的
个人绘制的流程图处理流程图如下:

(原文:Therefore to each RGB image pixel Ixy = [IRxy,IGxy, IBxy]T
we add the following quantity:
[p1, p2, p3][α1λ1, α2λ2, α3λ3]T
where pi and λi are ith eigenvector and eigenvalue of the 3 × 3 covariance matrix of RGB pixel values, respectively, and αi is the aforementioned random variable. Each αi is drawn only once for all the pixels of a particular training image until that image is used for training again, at which point it is
re-drawn)
- 1
- 2
- 3
- 4
- 5
②drop-out
即按概率p将hidden layer的神经元设置为输出0(即按概率p drop掉这个神经元,这轮不训练他了)
运用了这种机制的神经元不会干扰前向传递也不影响后续操作
5.学习细节(SGD)
AlexNet采用了SGD随机梯度下降(stochastic gradient descent)
并结合了动量momentum和weight decay权重衰减
下面主要介绍SGD与BGD(batch gradient descent 批梯度下降)的区别:
首先需要知道,BGD就是针对整个batch里的数据确定损失函数的梯度,即这个梯度是由batch里所有数据得来的,即:是这个batch整体对应的梯度
如:选用MSE损失函数:

BGD计算的搜索方向就是梯度的方向,即:损失函数下降最快的方向
而这样就会面临一个问题:BGD每次都要计算整个batch的数据,当m很大的时候,计算量也很大,收敛的速度是比较慢的
SGD的话则随机选取这个batch里的一个数据,即一个X^(i)
这里应理解为,SGD的搜索方向不再是梯度的方向,而是梯度的一个分量!
(梯度是由m个分量通过向量相加运算得到的)
下图分别是BGD和SGD的搜索过程:


可以看的,BGD是直冲圆心,SGD则是兜兜转转最终到圆心。
这其实告诉我们,SGD虽然比BGD计算和收敛更快,但可能性能会有所欠缺,但如果迭代次数epoch足够,SGD的性能和BGD是几乎一致的
但SGD也有与BGD一样的问题:容易陷入鞍点,即局部最优
AlexNet里就采用了动量momentum来一定程度上解决这个问题
VGG Net Summaries
VGGNet全部使用3 * 3的卷积核和2 * 2的池化核,通过不断加深网络结构来提升性能。网络层数的增长并不会带来参数量上的爆炸,因为参数量主要集中在最后三个全连接层中。同时,两个3 * 3卷积层的串联相当于1个5 * 5的卷积层,3个3 * 3的卷积层串联相当于1个7 * 7的卷积层,即3个3 * 3卷积层的感受野大小相当于1个7 * 7的卷积层。但是3个33的卷积层参数量只有77的一半左右,同时前者可以有3个非线性操作,而后者只有1个非线性操作,这样使得前者对于特征的学习能力更强。
(上面一段话节选自参考文献4)
我认为VGG Network的关键创新点即在,能将一个7 * 7的卷积层拆分成3个3 * 3的卷积层,这使得VGG Network实现了Very Deep CNN,即在深度上比前面的一些网络更好
下面我将粘贴自己对这个关键创新点的理解图:


