
- 1kafka rebalance与数据重复消费问题_you can address this either by increasing max.poll
- 2RELU6
- 3深度学习神经网络实战:多层感知机,手写数字识别
- 4基于JavaEE人力资源管理系统_javaee资源管理
- 5【Python 爬虫】简单的网页爬虫_对网页进行爬虫操作csdn
- 6网康科技-下一代防火墙 rce_网康下一代防火墙 命令执行批量rce
- 7linux中$?,$#等代表什么_-,#_¥)
- 8运行npm报错:npm ERR! errno ETIMEDOUTnpm ERR! network request to https://registry.npm的解决方案
- 9Flutter 时间选择组件_flutter筛选组件
- 10JavaEE程序员必读图书大推
fastDFS介绍_文件服务器 oss、fastdsf、ftp描述
赞
踩
1 什么是分布式文件系统
1.1 技术应用场景
优酷拥有大量优质的视频教程,并且免费提供给用户去下载,文件太多如何高效存储?用户访问量大如何保证
下载速度?分布式文件系统将解决这些问题。
分布式文件系统解决了海量文件存储及传输访问的瓶颈问题,对海量视频的管理、对海量图片的管理等。
1.2 什么是分布式文件系统
1.2.1什么是文件系统

image.png
总结:文件系统是负责管理和存储文件的系统软件,它是操作系统和硬件驱动之间的桥梁,操作系统通过文件系统提供的接口去存取文件,用户通过操作系统访问磁盘上的文件。如下图:
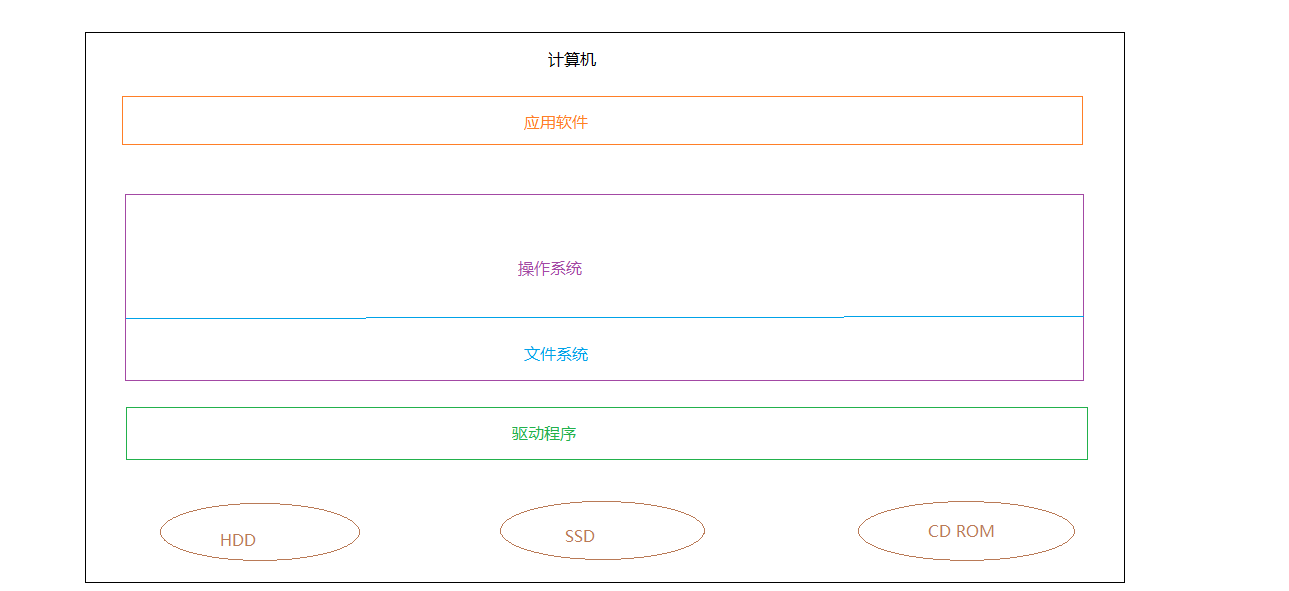
image.png
常见的文件系统:FAT16/FAT32、NTFS、HFS、UFS、APFS、XFS、Ext4等 。
1.2.2什么是分布式文件系统
image.png
为什么会有分布文件系统呢?
分布式文件系统是面对互联网的需求而产生,互联网时代对海量数据如何存储?靠简单的增加硬盘的个数已经满足不了我们的要求,因为硬盘传输速度有限但是数据在急剧增长,另外我们还要要做好数据备份、数据安全等。
采用分布式文件系统可以将多个地点的文件系统通过网络连接起来,组成一个文件系统网络,结点之间通过网络进行通信,一台文件系统的存储和传输能力有限,我们让文件在多台计算机上存储,通过多台计算共同传输。如下图:
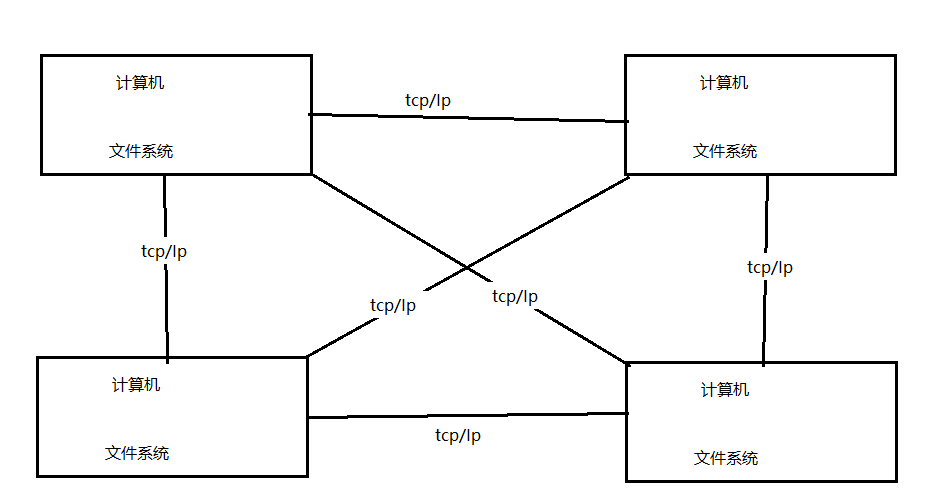
image.png
好处:
1、一台计算机的文件系统处理能力扩充到多台计算机同时处理。
2、一台计算机挂了还有另外副本计算机提供数据。
3、每台计算机可以放在不同的地域,这样用户就可以就近访问,提高访问速度。
1.3 主流的分布式文件系统
1、NFS

image.png
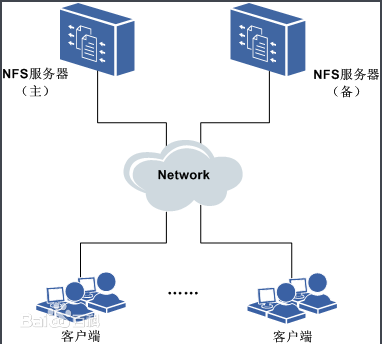
image.png
1)在客户端上映射NFS服务器的驱动器。
2)客户端通过网络访问NFS服务器的硬盘完全透明。
2、GFS
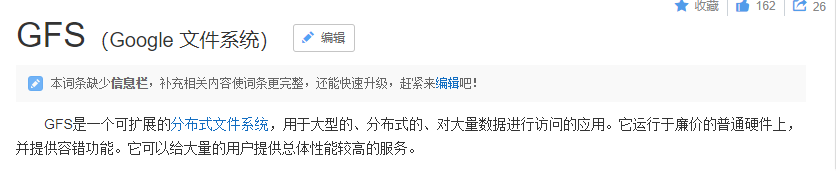
image.png
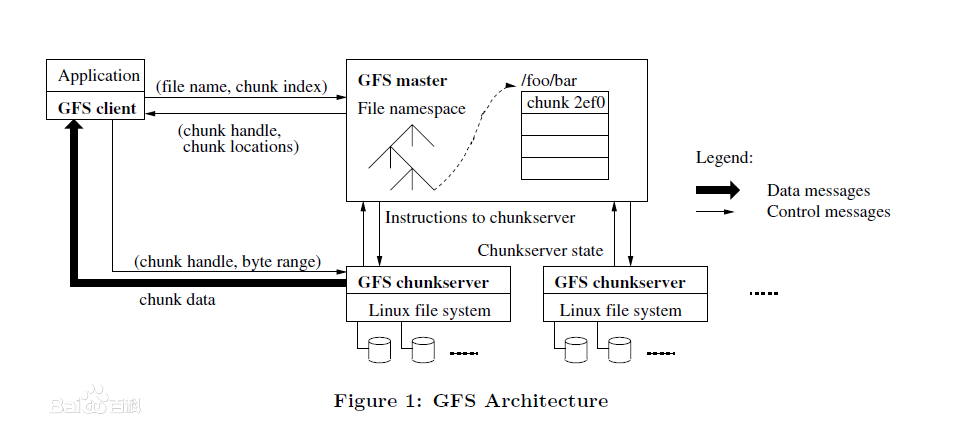
image.png
1)GFS采用主从结构,一个GFS集群由一个master和大量的chunkserver组成。
2)master存储了数据文件的元数据,一个文件被分成了若干块存储在多个chunkserver中。
3)用户从master中获取数据元信息,从chunkserver存储数据。
3、HDSF

image.png
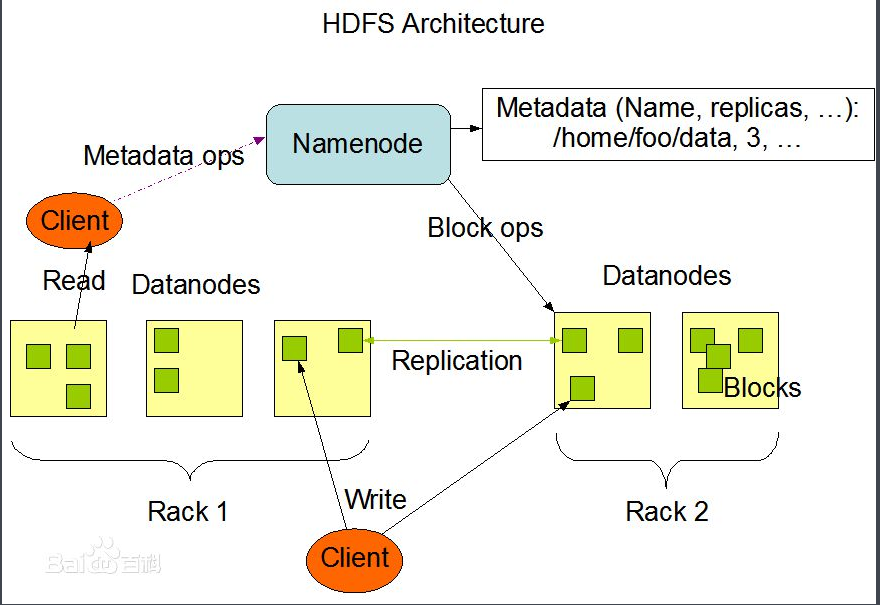
image.png
1)HDFS采用主从结构,一个HDFS集群由一个名称结点和若干数据结点组成。名称结点存储数据的元信息,一个完整的数据文件分成若干块存储在数据结点。
2)客户端从名称结点获取数据的元信息及数据分块的信息,得到信息客户端即可从数据块来存取数据。
1.4分布式文件服务提供商
1)阿里的OSS

image.png
2)七牛云存储
3)百度云存储
2 什么是fastDFS
2.1 fastDSF介绍
FastDFS是用c语言编写的一款开源的分布式文件系统,它是由淘宝资深架构师余庆编写并开源。FastDFS专为互联网量身定制,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标,使用FastDFS很容易搭建一套高性能的文件服务器集群提供文件上传、下载等服务。
为什么要使用fastDFS呢?
上边介绍的NFS、GFS都是通用的分布式文件系统,通用的分布式文件系统的优点的是开发体验好,但是系统复杂性高、性能一般,而专用的分布式文件系统虽然开发体验性差,但是系统复杂性低并且性能高。fastDFS非常适合存储图片等那些小文件,fastDFS不对文件进行分块,所以它就没有分块合并的开销,fastDFS网络通信采用socket,通信速度很快。
2.2 fastDSF工作原理
2.2.1 fastDSF架构
FastDFS架构包括 Tracker server和Storageserver。客户端请求Tracker server进行文件上传、下载,通过Tracker server调度最终由Storage server完成文件上传和下载。
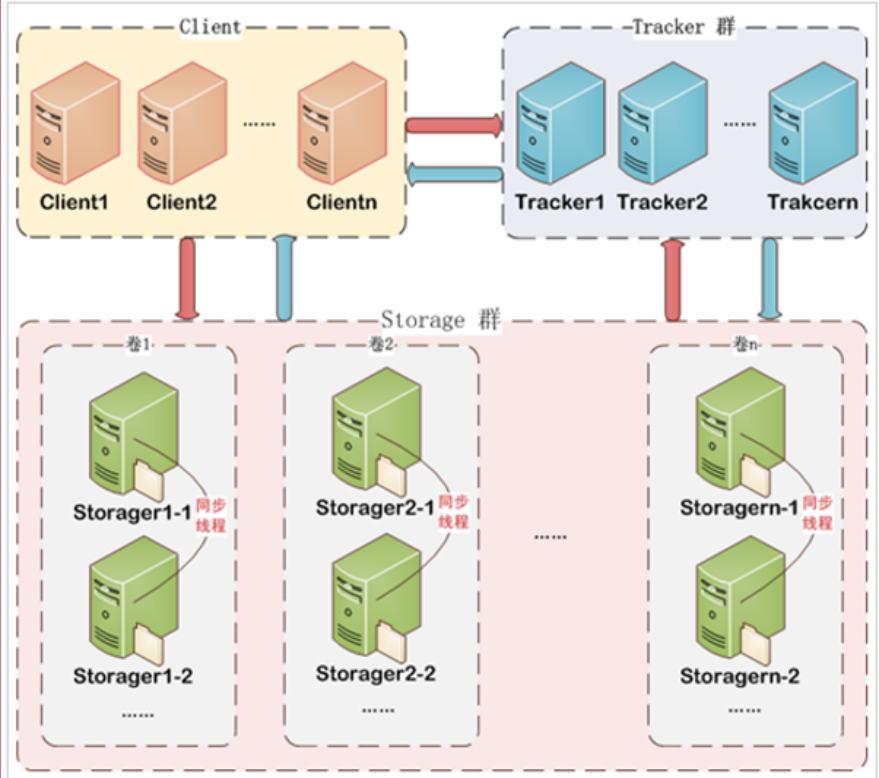
image.png
1)Tracker
Tracker Server作用是负载均衡和调度,通过Tracker server在文件上传时可以根据一些策略找到Storage server提供文件上传服务。可以将tracker称为追踪服务器或调度服务器。
FastDFS集群中的Tracker server可以有多台,Tracker server之间是相互平等关系同时提供服务,Tracker server不存在单点故障。客户端请求Tracker server采用轮询方式,如果请求的tracker无法提供服务则换另一个tracker。
2)Storage
Storage Server作用是文件存储,客户端上传的文件最终存储在Storage服务器上,Storage server没有实现自己的文件系统而是使用操作系统的文件系统来管理文件。可以将storage称为存储服务器。
Storage集群采用了分组存储方式。storage集群由一个或多个组构成,集群存储总容量为集群中所有组的存储容量之和。一个组由一台或多台存储服务器组成,组内的Storage server之间是平等关系,不同组的Storage server之间不会相互通信,同组内的Storage server之间会相互连接进行文件同步,从而保证同组内每个storage上的文件完全一致的。一个组的存储容量为该组内的存储服务器容量最小的那个,由此可见组内存储服务器的软硬件配置最好是一致的。
采用分组存储方式的好处是灵活、可控性较强。比如上传文件时,可以由客户端直接指定上传到的组也可以由tracker进行调度选择。一个分组的存储服务器访问压力较大时,可以在该组增加存储服务器来扩充服务能力(纵向扩容)。当系统容量不足时,可以增加组来扩充存储容量(横向扩容)。
3)Storage状态收集
Storage server会连接集群中所有的Tracker server,定时向他们报告自己的状态,包括磁盘剩余空间、文件同步状况、文件上传下载次数等统计信息。
2.2.2文件上传流程
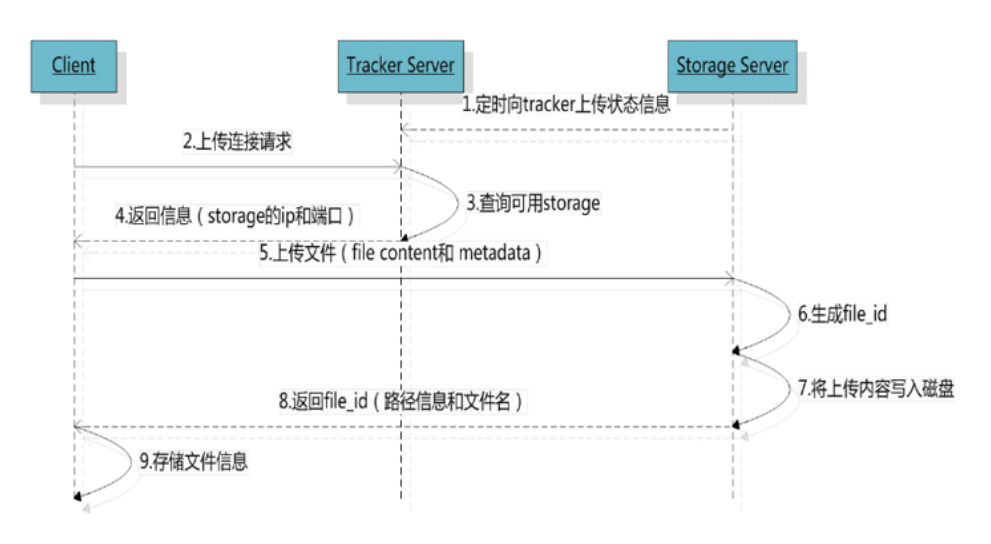
image.png
客户端上传文件后存储服务器将文件ID返回给客户端,此文件ID用于以后访问该文件的索引信息。文件索引信息包括:组名,虚拟磁盘路径,数据两级目录,文件名。

image.png
-
组名:文件上传后所在的storage组名称,在文件上传成功后有storage服务器返回,需要客户端自行保存。
-
虚拟磁盘路径:storage配置的虚拟路径,与磁盘选项store_path*对应。如果配置了store_path0则是M00,
如果配置了store_path1则是M01,以此类推。 -
数据两级目录:storage服务器在每个虚拟磁盘路径下创建的两级目录,用于存储数据文件。
-
文件名:与文件上传时不同。是由存储服务器根据特定信息生成,文件名包含:源存储服务器IP地址、文件
创建时间戳、文件大小、随机数和文件拓展名等信息。
2.2.3 文件下载流程
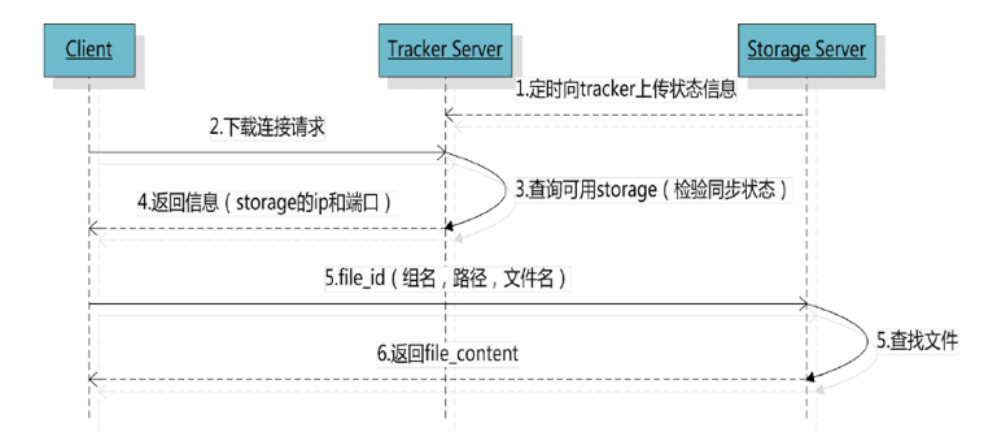
image.png
tracker根据请求的文件路径即文件ID 来快速定义文件。
比如请求下边的文件:
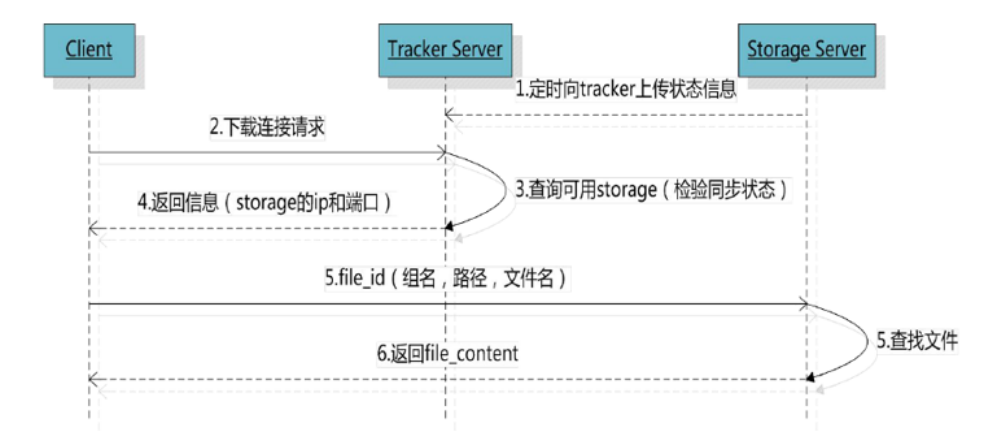
image.png
1.通过组名tracker能够很快的定位到客户端需要访问的存储服务器组是group1,并选择合适的存储服务器提供客户端访问。
2.存储服务器根据“文件存储虚拟磁盘路径”和“数据文件两级目录”可以很快定位到文件所在目录,并根据文件名找到客户端需要访问的文件。
作者:striveSmile
链接:https://www.jianshu.com/p/d7e687967209
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

