
- 1微信小程序|岳阳市美术馆预约平台的设计与实现
- 2InceptionNext:当Inception遇到ConvNeXt_inceptnext
- 3ARCHPR学习笔记_不能载入regdll
- 4Python文字识别_python识别文字
- 5鸿蒙系列--自定义组件_鸿蒙自定义组件
- 6uniapp兼容问题一些经常出现的问题_低版本安卓系统与uni-app的兼容性
- 7【UniAPP X快速上手】如何使用UniAPPX开发一个原生安卓商城_uni-app x
- 8腾讯云获国际专业流媒体测评肯定:三大场景下视频编码性能全部最优_腾讯云海外 视频云分析
- 9Android自定义TextView排版优化_android 开发中textview 文字排版的优化
- 10华为机考:HJ3 明明的随机数
时间序列预测实战(十八)利用Prophet实现长期预测(附代码+数据集+详细讲解)_prophet预测模型
赞
踩

一、本文介绍
Prophet是一个用于时间序列预测的经单模型。这个工具特别适合于具有强季节性影响和多个历史数据季节的业务时间序列数据。Prophet的主要思想是将数据分解为如下三个部分:趋势、季节性、节假日和特殊事件。这个模型非常适合于处理具有强烈季节性和趋势变化的业务时间序列数据(这里为什么适合的是业务数据呢是因为它考虑了节假日等特殊事件,同时其面对数据中的缺失值和异常值时也能保持其性能)。Prophet通过这种方式,可以有效地预测未来的趋势和模式。需要注意的是Prophet是一种介于机器学习和传统的时间序列预测方法中间的一种方法,其中分解趋势、季节性这种属于是传统的方法,但是其又可以自动拟合属于机器学习的方法。
预测类型:长期预测、单元预测。
预测效果图如下(未知数据)->
目录
二、Prophet介绍
2.1 Prophet的主要思想
Prophet的主要思想是:提供一个灵活且易于使用的工具,用于处理各种业务时间序列数据的预测。它基于一个加性模型,其中非线性趋势与年度、周度和日度季节性模式结合,还可以包括节假日效应。这个模型包括几个主要部分:
趋势模型:它捕捉数据的长期趋势,可以处理趋势的变化,如趋势中的拐点。
季节性模型:识别并拟合数据的季节性模式,如一周内或一年内的周期性变化。
节假日组件:用户可以指定影响模型的特定日期或事件,如公共假期或特别活动。
Prophet的目标是将这些复杂的时间序列分析技术变得更加易于理解和使用,即使是对于非专业人士来说。
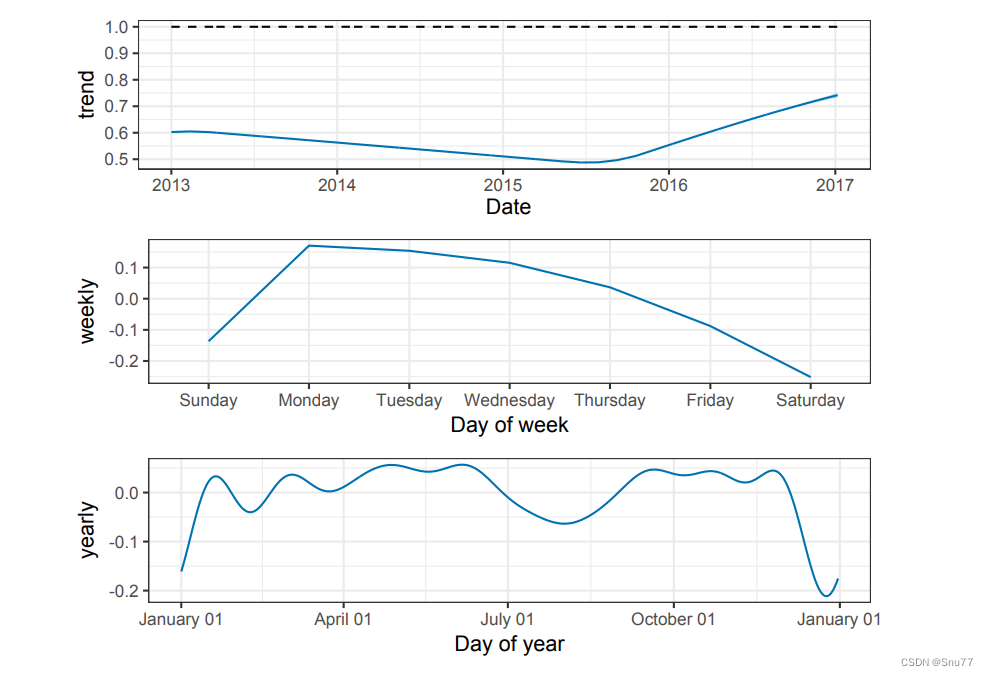
下图为Prophet处理时间这一特征时其考虑时间的方法
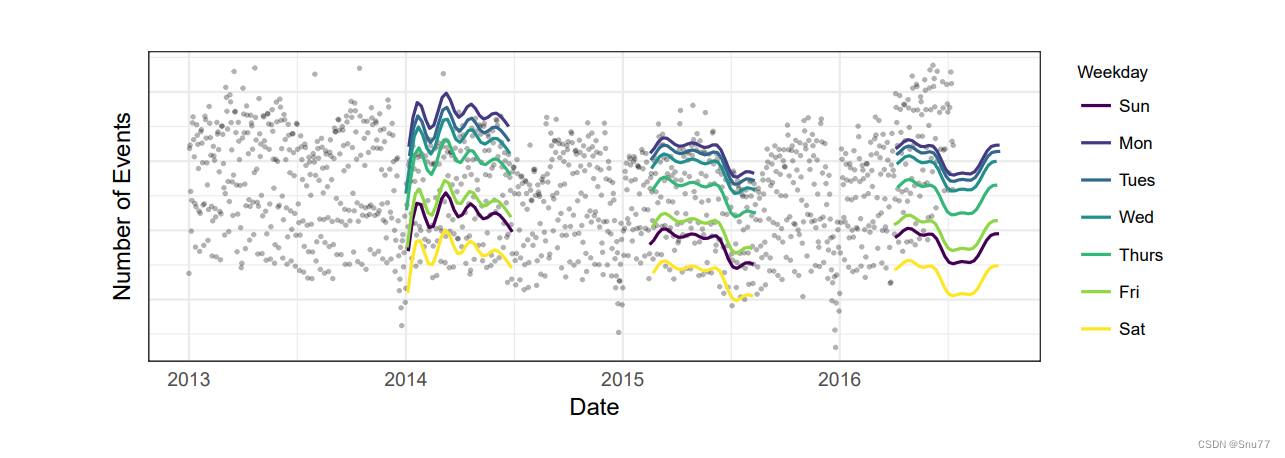 而且岂会将时间处理为不同的维度进行处理如下图所示:分别为年月周日等多个维度。
而且岂会将时间处理为不同的维度进行处理如下图所示:分别为年月周日等多个维度。
2.2 Prophet的优缺点
Prophet的优点
Prophet是一个由Facebook开发的开源工具,用于时间序列预测。这个工具特别适合于具有强季节性影响和多个历史数据季节的业务时间序列数据。Prophet的主要有点包括:
1. 易于使用:Prophet旨在为分析师和开发者提供一个简单、直观的接口,使他们能够快速做出高质量的预测。
2. 适应性强:它可以自动检测时间序列数据的变化趋势和季节性模式,甚至在存在缺失数据或历史数据的情况下也能进行有效的预测。
3. 可定制:用户可以调整模型来适应特定的业务需求,比如通过添加节假日效应或者考虑特定的事件。
4. 鲁棒性:它对异常值和缺失数据具有良好的抵抗力,能够生成准确的预测。
总结:Prophet在许多类型的时间序列数据上都表现出色,特别是在处理日常、周末和年度节假日的影响方面具有独特优势。
Prophet的缺点
尽管如此,Prophet也有其局限性,它可能不适用于处理非常不规则或复杂的时间序列数据。此外,Prophet在进行预测时可能需要大量的历史数据来识别模式。
三、数据集介绍
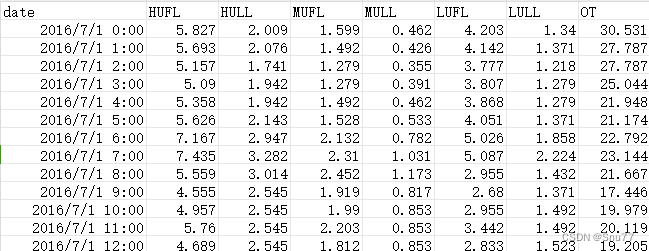
我们本文用到的数据集是官方的ETTh1.csv ,该数据集是一个用于时间序列预测的电力负荷数据集,它是 ETTh 数据集系列中的一个。ETTh 数据集系列通常用于测试和评估时间序列预测模型。以下是 ETTh1.csv 数据集的一些内容:
数据内容:该数据集通常包含有关电力系统的多种变量,如电力负荷、价格、天气情况等。这些变量可以用于预测未来的电力需求或价格。
时间范围和分辨率:数据通常按小时或天记录,涵盖了数月或数年的时间跨度。具体的时间范围和分辨率可能会根据数据集的版本而异。
以下是该数据集的部分截图->
四、参数讲解
Prophet模型提供了多个参数,大家可以根据具体的数据集和业务需求调整模型。以下是这些参数及其接受的类型:
| 参数名称 | 参数类型 | 参数介绍 | |
|---|---|---|---|
| 1 | growth | 字符串 | 指定增长模型,通常是'linear'或'logistic'大家需要注意的是如果输入logistic则需要再输入数据中多加一个cap列表明你的数据可能的最大值,否则会报错。 |
| 2 | changepoints | Python列表 | python列表,指明数据什么时候会变化,这个一般不用输入,类似于某个特殊时间点。 |
| 3 | n_changepoints | 整数 | 自动选择的潜在趋势变化点的数量,这两参数比较重要大家需要反复尝试 |
| 4 | changepoint_range | 浮点数 | 用于选择变化点的数据历史比例,这两参数比较重要大家需要反复尝试 |
| 5 | yearly_seasonality | 布尔值或整数 | 年度季节性组件,是否开启True自动计算按照一年来,否则可以输入整数2、3年等。 |
| 6 | weekly_seasonality | 布尔值或整数 | 周季节性组件,和上面同理 |
| 7 | daily_seasonality | 布尔值或整数 | 日季节性组件,和上面同理 |
| 8 | holidays | DataFrame | 包含假期信息的数据框 |
| 9 | seasonality_prior_scale | 浮点数 | 季节性组件的平滑度,这个参数其实需要用一些交叉验证或者网格搜索进行求最优化。 |
| 10 | holiday_prior_scale | 浮点数 | 假期组件的平滑度,这个参数其实需要用一些交叉验证或者网格搜索进行求最优化。 |
| 11 | changepoint_prior_scale | 浮点数 | 趋势变化点的灵敏度,这个参数其实需要用一些交叉验证或者网格搜索进行求最优化。 |
| 12 | mcmc_samples | 整数 | MCMC采样的数量 |
| 13 | interval_width | 浮点数 | 预测区间的宽度 |
| 14 | uncertainty_samples | 整数 | 不确定性估计的模拟抽样数量 |
五、模型实战
5.1 模型完整代码块
下面的代码大家复制粘贴即可运行,本文的模型Prophet用法十分简单只需要调用官方的接口既可以。
- import pandas as pd
- from matplotlib import pyplot as plt
- from prophet import Prophet
- from sklearn.metrics import mean_absolute_error, mean_squared_error
-
- pre_length = 24 # 预测未来数据的长度,我的数据是一小时一间隔24等于一天
-
- df = pd.read_csv('ETTh1.csv')[['date', 'OT']] # 因为我的数据有多列,在这里我给这两列进行的单独提取出来
-
-
- # 从数据的末尾提出来一部分数据用于后面的对比
- train_df = df[:len(df) - pre_length]
- test_df = df[-pre_length:]
-
- # 这里需要将你的时间列和数据列进行重命名因为Prophet需要的两列名字固定是ds 和 y
- train_df.rename(columns={'date': 'ds', 'OT': 'y'}, inplace=True)
- test_df.rename(columns={'date': 'ds', 'OT': 'y'}, inplace=True)
- test_df.reset_index(drop=True, inplace=True)
-
- # 初始化Prophet模型
- model = Prophet(
- yearly_seasonality=True, # 启用年度季节性
- weekly_seasonality=True, # 启用周季节性
- daily_seasonality=True, # 启用日季节性
- changepoint_prior_scale=0.5, # 调整趋势变化点的灵敏度
- seasonality_prior_scale=5.0, # 调整季节性组件的灵敏度
- )
-
- # 拟合模型
- model.fit(train_df)
-
- # 创建未来日期的数据框,这里假设我们预测未来1天
- future = model.make_future_dataframe(periods=pre_length)
-
- # 进行预测
- forecast = model.predict(future).tail(pre_length)
-
- forecast.reset_index(inplace=True, drop=True) # 将索引重新排序
-
- # 展示预测结果
- print(forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']])
-
- mae = mean_absolute_error(test_df['y'], forecast['yhat'])
- mse = mean_squared_error(test_df['y'], forecast['yhat'])
-
- print("预测值和真实值的MAE:", mae)
- print("预测值和真实值的MSE:", mse)
-
- # 设置主题
- plt.style.use('ggplot')
-
- # 创建图表
- fig, ax = plt.subplots(figsize=(10, 6))
- # 绘制真实值
- ax.plot(test_df['y'], label='Actual', color='blue')
-
- # 绘制预测值
- ax.plot(forecast['yhat'], label='Forecast', color='cyan')
-
- # 绘制预测的不确定性范围(上下界)
- ax.fill_between(range(pre_length), forecast['yhat_lower'], forecast['yhat_upper'], color='grey', alpha=0.5)
-
- # 设置标题和标签
- ax.set_title('Prophet Forecast with Confidence Interval', fontsize=16)
- ax.set_xlabel('Date', fontsize=12)
- ax.set_ylabel('Value', fontsize=12)
-
- # 添加图例
- ax.legend()
-
- # 显示图表
- plt.show()

5.2 模型训练和输出结果
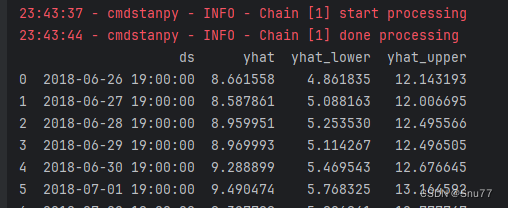
当我们将上面的代码复制到一个py文件之后输入你的文件路径和要预测的数据周期之后,我们可以进行训练,控制台的输出如下图所示,其中的前两行为模型拟合过程,下面的结果为模型的预测输出结果,其中yhat就是模型的预测值。
六、结果展示和分析
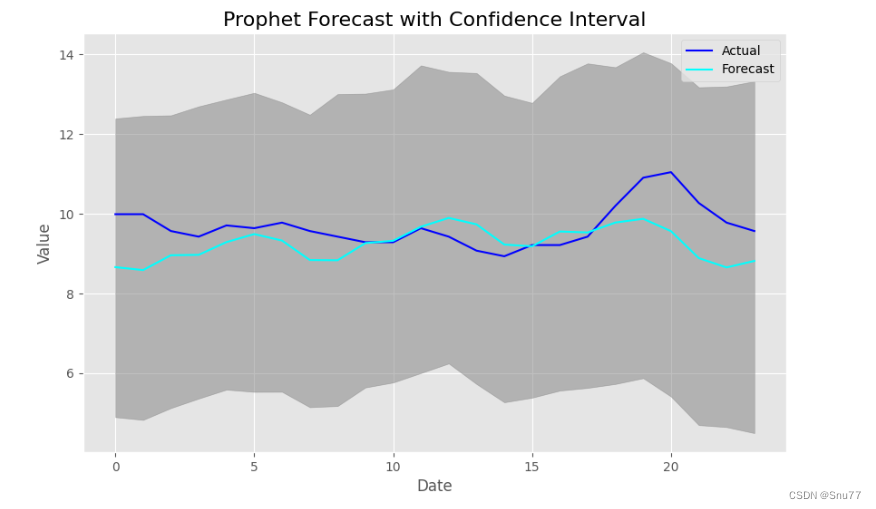
下面的结果就是预测值和真实值的对比图,我这里的数据是按照小时为间隔,可以看到我这里预测了未来的24个时间点的数据也就是一天的数据,效果还可以吧只能说这个模型主要就是用法简单官方以只提供接口省去了很多训练的麻烦。
同时我们可以看到下面的MAE和MSE的结果在控制台输出如下->

六、全文总结
到此本文已经全部讲解完成了,希望能够帮助到大家,在这里也给大家推荐一些我其它的博客的时间序列实战案例讲解,其中有数据分析的讲解就是我前面提到的如何设置参数的分析博客,最后希望大家订阅我的专栏,本专栏均分文章均分98,并且免费阅读。


