
- 1探究Microsoft Visual C++ 可再发行组件的多重用途_visual c++ redistributable
- 2使用AOP实现防止表单重复提交问题,解决后端幂等性问题_aop加唯一索引实现幂等防重
- 3【视频理解】2022-CVPR-Video Swin Transformer
- 4IE8下提示'console'未定义错误_ie8 console未定义
- 5[.net] ADO.net和sql 存储过程实例_"command.parameters.add(new sqlparameter(\"returnv
- 6实时解答SpringCloud+Nginx秒杀实战,Zuul内部网关实现秒杀限流_springcloud zuul+nginx
- 7Vue + Element UI——监听DOM元素高度和宽度解决方案整理(八种方法)_vue3监听dom元素高度变化
- 8总结一下NDK crash排查步骤
- 9鸿蒙系统扫盲(五):再谈鸿蒙开发用什么语言?_鸿蒙next 后端语言
- 10OpenHarmony 4.0 Release发布,同步升级API 10
linux C/C++多进程教程(多进程原理以及多进程的应用【以多连接socket服务端为例(fork子进程处理socket_fd),同时介绍了僵尸进程产生原因与解决方法】)(getpid、fork)_c++多进程编程
赞
踩
多进程原理
一、进程的概念
什么是进程?进程这个概念是针对系统而不是针对程序员的,对程序员来说,我们面对的概念是程序,当输入指令执行一个程序的时候,对系统而言,它将启动一个进程。
进程就是正在内存中运行中的程序,Linux下一个进程在内存里有三部分的数据,就是“代码段”、“堆栈段”和“数据段”。
- “代码段”,顾名思义,就是存放了程序代码。
- “堆栈段”存放的就是程序的返回地址、程序的参数以及程序的局部变量。
- “数据段”则存放程序的全局变量,常数以及动态数据分配的数据空间(比如用new函数分配的空间)。
系统如果同时运行多个相同的程序,它们的“代码段”是相同的,“堆栈段”和“数据段”是不同的(相同的程序,处理的数据不同)。
二、进程的编号
1、查看进程
ps 查看当前终端的进程。

ps -ef 查看系统全部的进程。
ps -ef | more 查看系统全部的进程,结果分页显示。

(海康容器)

UID :启动进程的操作系统用户。
PID :进程编号。
PPID :进程的父进程的编号。
C :CPU使用的资源百分比。
STIME :进程启动时间。
TTY :进程所属的终端。
TIME :使用掉的CPU时间。
CMD :执行的是什么指令。
ps -ef |grep book查看系统全部的进程,然后从结果集中过滤出包含“book”单词的记录。程序员用得最多的指令就是这个了。

2、getpid库函数
getpid库函数的功能是获取本程序运行时进程的编号。
函数声明:
pid_t getpid();
- 1
函数没有参数,返回值是进程的编号,pid_t就是typedef int pid_t。
示例:test_process.c
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
printf("本程序的进程编号是:%d\n",getpid());
sleep(30); // 是为了方便查看进程在shell下用ps -ef|grep test_process查看本进程的编号。
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
运行效果:在test_process运行时,切换到其它的窗口,执行ps -ef | grep test_process可以查看进程,如下。
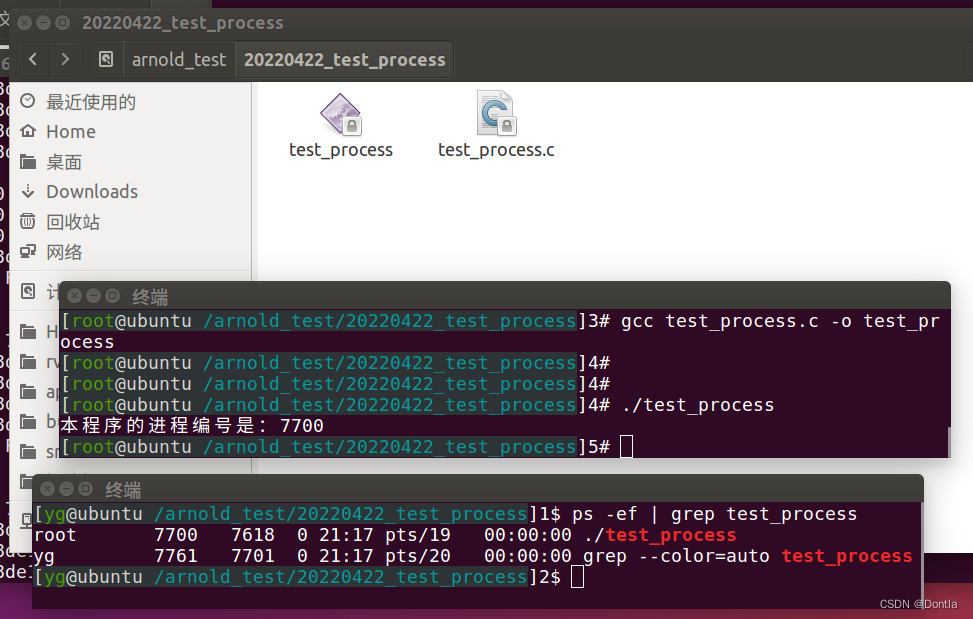
注意两个细节:
1)进程的编号是系统动态分配的,相同的程序在不同的时间执行,进程的编号是不同的。
2)进程的编号会循环使用,但是,在同一时间,进程的编号是唯一的,也就是说,不管任何时间,系统不可能存在两个编号相同的进程。
三、多进程 fork()
fork在英文中是“分叉”的意思。为什么取这个名字呢?因为一个进程在运行中,如果使用了fork函数,就产生了另一个进程,于是进程就“分叉”了,所以这个名字取得很形象。下面就看看如何具体使用fork函数,这段程序演示了使用fork的基本框架。
函数声明:
pid_t fork();
- 1
fork函数用于产生一个新的进程,函数返回值pid_t是一个整数,在父进程中,返回值是子进程编号,在子进程中,返回值是0。
示例:test_fork_return.c
#include <stdio.h> #include <sys/types.h> #include <unistd.h> int main() { printf("本程序的进程编号是:%d\n",getpid()); int ipid=fork(); sleep(1); // sleep等待进程的生成。 //printf("ipid=%d\n",ipid); if (ipid!=0) printf("ipid=%d, 父进程编号是:%d\n", ipid, getpid()); else printf("ipid=%d, 子进程编号是:%d\n", ipid, getpid()); sleep(30); // 是为了方便查看进程在shell下用ps -ef|grep book252查看本进程的编号。 }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
运行结果:

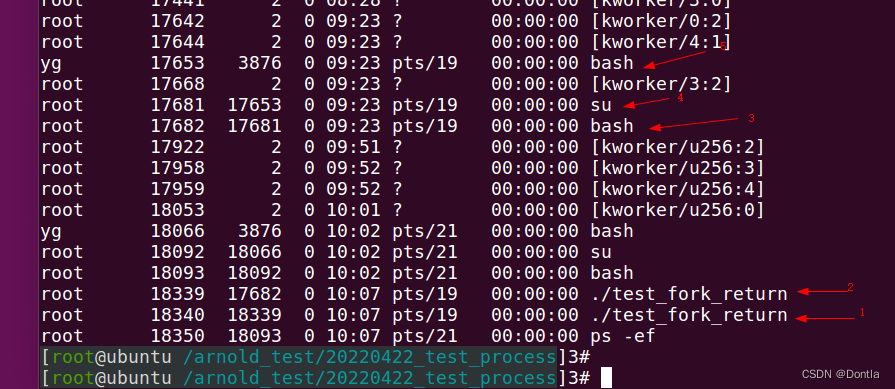
看看一层一层上去它们的父进程是什么





初学者可能用点接受不了现实。
1)一个函数(fork)返回了两个值?
2)if和else中的代码能同时被执行?
那么调用这个fork函数时发生了什么呢?fork函数创建了一个新的进程,新进程(子进程)与原有的进程(父进程)一模一样。子进程和父进程使用相同的代码段;子进程拷贝了父进程的堆栈段和数据段。子进程一旦开始运行,它复制了父进程的一切数据,然后各自运行,相互之间没有影响。
fork函数对返回值做了特别的处理,调用fork函数之后,在子程序中fork的返回值是0,在父进程中fork的返回是子进程的编号,程序员可以通过fork的返回值来区分父进程和子进程,然后再执行不同的代码。
示例:test_process2.c
#include <stdio.h> #include <sys/types.h> #include <unistd.h> void fatherfunc() // 父进程流程的主函数 { printf("我是老子,我喜欢孩子他娘。\n"); } void childfunc() // 子进程流程的主函数 { printf("我是儿子,我喜欢西施。\n"); } int main() { if (fork()>0) { printf("这是父进程,将调用fatherfunc()。\n"); fatherfunc();} else { printf("这是子进程,将调用childfunc()。\n"); childfunc();} sleep(1); printf("父子进程执行完自己的函数后都来这里。\n"); sleep(1); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
运行结果:
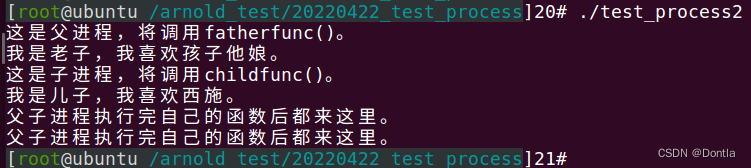
在上文上已提到过,子进程拷贝了父进程的堆栈段和数据段,也就是说,在父进程中定义的变量子进程中会复制一个副本,fork之后,子进程对变量的操作不会影响父进程,父进程对变量的操作也不会影响子进程。
示例:test_process3.c
#include <stdio.h> #include <sys/types.h> #include <unistd.h> int ii=10; //data segment int main() { int jj=20; //stack segment if (fork()>0) //father process { ii=11;jj=21; sleep(1); printf("父进程:ii=%d,jj=%d\n",ii,jj); } else //child process { ii=12;jj=22; sleep(1); printf("子进程:ii=%d,jj=%d\n",ii,jj); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
运行结果:

四、课后作业
1)编写一个多进程程序,验证子进程是复制父进程的内存变量,还是父子进程共享内存变量?
2)编写一个示例程序,由父进程生成10个子进程,在子进程中显示它是第几个子进程和子进程本身的进程编号。
3)编写示例程序,由父进程生成子进程,子进程再生成孙进程,共生成第10代进程,在各级子进程中显示它是第几代子进程和子进程本身的进程编号。
4)利用尽可能少的代码快速fork出更多的进程,试试看能不能把linux系统搞死。
5)ps -ef |grep book251命令是ps和grep两个系统命令的组合,各位查一下资料,了解一下grep命令的功能,对程序员来,grep是经常用到的命令。
多进程的应用
前面的章节介绍socket通信的时候,socket的服务端在同一时间只能和一个客户端通信,并不是服务端有多忙,而是因为单进程的程序在同一时间只能做一件事情,不可能一边等待客户端的新连接一边与其它的客户端进行通信。
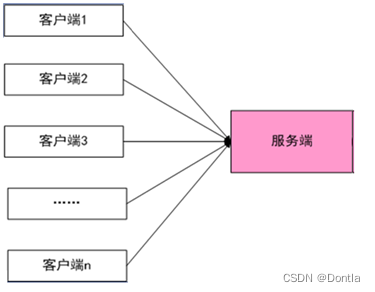
1、服务端
把book248.cpp修改一下,改为多进程。
示例(book250.cpp)
/* * 程序名:book250.cpp,此程序用于演示多进程的socket通信服务端。 * 作者:C语言技术网(www.freecplus.net) 日期:20190525 */ #include <stdio.h> #include <string.h> #include <unistd.h> #include <netdb.h> #include <sys/types.h> #include <sys/socket.h> #include <arpa/inet.h> class CTcpServer { public: int m_listenfd; // 服务端用于监听的socket int m_clientfd; // 客户端连上来的socket CTcpServer(); bool InitServer(int port); // 初始化服务端 bool Accept(); // 等待客户端的连接 // 向对端发送报文 int Send(const void *buf,const int buflen); // 接收对端的报文 int Recv(void *buf,const int buflen); void CloseClient(); // 关闭客户端的socket void CloseListen(); // 关闭用于监听的socket ~CTcpServer(); }; CTcpServer TcpServer; int main() { // signal(SIGCHLD,SIG_IGN); // 忽略子进程退出的信号,避免产生僵尸进程 if (TcpServer.InitServer(5051)==false) { printf("服务端初始化失败,程序退出。\n"); return -1; } while (1) { if (TcpServer.Accept() == false) continue; if (fork()>0) { TcpServer.CloseClient(); continue; } // 父进程回到while,继续Accept。 // 子进程负责与客户端进行通信,直到客户端断开连接。 TcpServer.CloseListen(); printf("客户端已连接。\n"); // 与客户端通信,接收客户端发过来的报文后,回复ok。 char strbuffer[1024]; while (1) { memset(strbuffer,0,sizeof(strbuffer)); if (TcpServer.Recv(strbuffer,sizeof(strbuffer))<=0) break; printf("接收:%s\n",strbuffer); strcpy(strbuffer,"ok"); if (TcpServer.Send(strbuffer,strlen(strbuffer))<=0) break; printf("发送:%s\n",strbuffer); } printf("客户端已断开连接。\n"); return 0; // 或者exit(0),子进程退出。 } } CTcpServer::CTcpServer() { // 构造函数初始化socket m_listenfd=m_clientfd=0; } CTcpServer::~CTcpServer() { if (m_listenfd!=0) close(m_listenfd); // 析构函数关闭socket if (m_clientfd!=0) close(m_clientfd); // 析构函数关闭socket } // 初始化服务端的socket,port为通信端口 bool CTcpServer::InitServer(int port) { if (m_listenfd!=0) { close(m_listenfd); m_listenfd=0; } m_listenfd = socket(AF_INET,SOCK_STREAM,0); // 创建服务端的socket // 把服务端用于通信的地址和端口绑定到socket上 struct sockaddr_in servaddr; // 服务端地址信息的数据结构 memset(&servaddr,0,sizeof(servaddr)); servaddr.sin_family = AF_INET; // 协议族,在socket编程中只能是AF_INET servaddr.sin_addr.s_addr = htonl(INADDR_ANY); // 本主机的任意ip地址 servaddr.sin_port = htons(port); // 绑定通信端口 if (bind(m_listenfd,(struct sockaddr *)&servaddr,sizeof(servaddr)) != 0 ) { close(m_listenfd); m_listenfd=0; return false; } // 把socket设置为监听模式 if (listen(m_listenfd,5) != 0 ) { close(m_listenfd); m_listenfd=0; return false; } return true; } bool CTcpServer::Accept() { if ( (m_clientfd=accept(m_listenfd,0,0)) <= 0) return false; return true; } int CTcpServer::Send(const void *buf,const int buflen) { return send(m_clientfd,buf,buflen,0); } int CTcpServer::Recv(void *buf,const int buflen) { return recv(m_clientfd,buf,buflen,0); } void CTcpServer::CloseClient() // 关闭客户端的socket { if (m_clientfd!=0) { close(m_clientfd); m_clientfd=0; } } void CTcpServer::CloseListen() // 关闭用于监听的socket { if (m_listenfd!=0) { close(m_listenfd); m_listenfd=0; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
解释一下:
- 在CTcpServer中增加了两个成员函数。
void CloseClient(); // 关闭客户端的socket
void CloseListen(); // 关闭用于监听的socket
- 1
- 2
- 当有客户端连上来的时候,主进程执行fork,这时候会客户端的socket(m_clientfd)被复制了一份,对父进程来说,只负责监听客户端的连接,不需要与客户端通信,所以父进程关闭m_clientfd,注意,
父进程关闭m_clientfd对子进程中的m_clientfd没有影响。 - 当有客户端连上来的时候,主进程执行fork,这时候服务端用于监听的socket(m_listenfd)也会被复制了一份,对子进程来说,只需要与客户端通信,不需要监听客户端的连接,所以子进程关闭监听的m_listenfd,同理,
子进程关闭m_listenfd对父进程中的m_listenfd没有影响。(因为只是使引用计数-1:参考文章:linux C语言 socket编程教程(附两个例子)(socket教程)EINTR) - 子进程执行完任务后,要调用retrun或exit(0)退出,如果没有调用return或exit(0),子进程将又会回到while循环首部。
2、客户端
把book247.cpp修改一下,循环的次数改为50,每次与服务端完成报文交互后sleep一秒,方便观察程序运行的效果。
示例(book249.cpp)
/* * 程序名:book249.cpp,此程序对book247.cpp略作修改,用于测试多进程的socket通信客户端 * 作者:C语言技术网(www.freecplus.net) 日期:20190525 */ #include <stdio.h> #include <string.h> #include <unistd.h> #include <netdb.h> #include <sys/types.h> #include <sys/socket.h> #include <arpa/inet.h> // TCP客户端类 class CTcpClient { public: int m_sockfd; CTcpClient(); // 向服务器发起连接,serverip-服务端ip,port通信端口 bool ConnectToServer(const char *serverip,const int port); // 向对端发送报文 int Send(const void *buf,const int buflen); // 接收对端的报文 int Recv(void *buf,const int buflen); ~CTcpClient(); }; int main() { CTcpClient TcpClient; // 向服务器发起连接请求 if (TcpClient.ConnectToServer("172.16.0.15",5051)==false) { printf("TcpClient.ConnectToServer(\"172.16.0.15\",5051) failed,exit...\n"); return -1; } char strbuffer[1024]; for (int ii=0;ii<50;ii++) { memset(strbuffer,0,sizeof(strbuffer)); sprintf(strbuffer,"这是第%d个超级女生,编号%03d。",ii+1,ii+1); if (TcpClient.Send(strbuffer,strlen(strbuffer))<=0) break; printf("发送:%s\n",strbuffer); memset(strbuffer,0,sizeof(strbuffer)); if (TcpClient.Recv(strbuffer,sizeof(strbuffer))<=0) break; printf("接收:%s\n",strbuffer); sleep(1); // sleep一秒,方便观察程序的运行。 } } CTcpClient::CTcpClient() { m_sockfd=0; // 构造函数初始化m_sockfd } CTcpClient::~CTcpClient() { if (m_sockfd!=0) close(m_sockfd); // 析构函数关闭m_sockfd } // 向服务器发起连接,serverip-服务端ip,port通信端口 bool CTcpClient::ConnectToServer(const char *serverip,const int port) { m_sockfd = socket(AF_INET,SOCK_STREAM,0); // 创建客户端的socket struct hostent* h; // ip地址信息的数据结构 if ( (h=gethostbyname(serverip))==0 ) { close(m_sockfd); m_sockfd=0; return false; } // 把服务器的地址和端口转换为数据结构 struct sockaddr_in servaddr; memset(&servaddr,0,sizeof(servaddr)); servaddr.sin_family = AF_INET; servaddr.sin_port = htons(port); memcpy(&servaddr.sin_addr,h->h_addr,h->h_length); // 向服务器发起连接请求 if (connect(m_sockfd,(struct sockaddr *)&servaddr,sizeof(servaddr))!=0) { close(m_sockfd); m_sockfd=0; return false; } return true; } int CTcpClient::Send(const void *buf,const int buflen) { return send(m_sockfd,buf,buflen,0); } int CTcpClient::Recv(void *buf,const int buflen) { return recv(m_sockfd,buf,buflen,0); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
测试运行
先启动服务端book250,然后启动多个book249,可以看到服务端可以同时与多个客户端进行通信,查看服务端的进行如下:ps -ef | grep book250

注意,服务端book250的主程序的while是一个死循环,没有退出机制,可以按Ctrl+c强制中止它,这不是正确的办法,后面我会介绍正确的方法。
我把connect ip改成了127.0.0.1,然后在ubuntu上编译测试
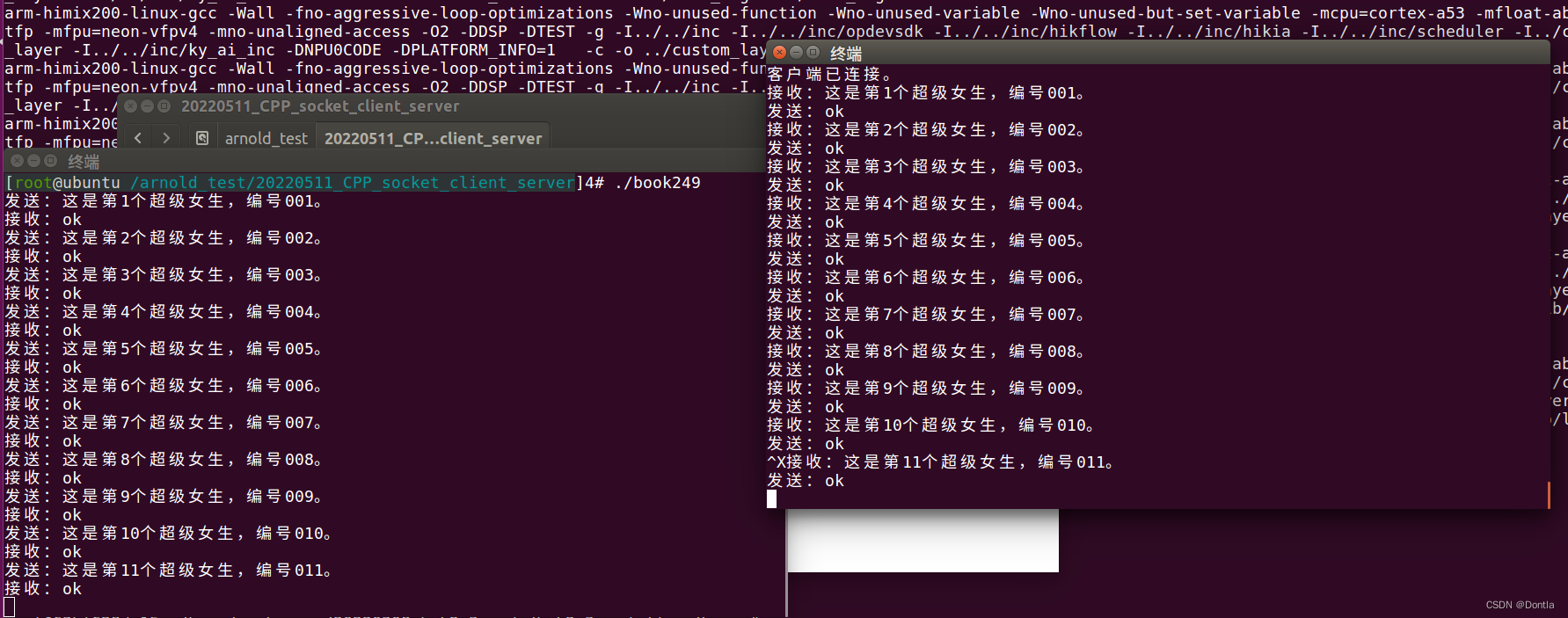
二、僵尸进程
1、僵尸进程产生的原因
一个子进程在调用return或exit(0)结束自己的生命的时候,其实它并没有真正的被销毁,而是留下一个僵尸进程。
先启动服务端程序book250,然后多次启动客户端程序book249,马上查看book250的进程,如下图:

等全部的客户端book249程序运行完成后,再查看book250的进程,如下图。

被选中的就是僵尸进程,有<defunct>标志。
如果按Ctrl+c终止book250后,父进程退出,僵尸进程随之消失。
2、僵尸进程的危害
僵尸进程是子进程结束时,父进程又没有回收子进程占用的资源。
僵尸进程在消失之前会继续占用系统资源。
如果父进程先退出,子进程被系统(init进程)接管,子进程退出后系统会回收其占用的相关资源,不会成为僵尸进程。父进程先退出的应用场景在以后的章节中介绍。
3、如何解决僵尸进程
解决僵尸进程的方法有两种。
子进程退出之前,会向父进程发送一个信号,父进程调用wait函数等待这个信号,只要等到了,就不会产生僵尸进程。这话说得容易,在并发的服务程序中这是不可能的,因为父进程要做其它的事,例如等待客户端的新连接,不可能去等待子进程的退出信号,这个方法我就不介绍了。
另一种方法就是父进程直接忽略子进程的退出信号,具体做法很简单,在主程序中启用以下代码:
signal(SIGCHLD,SIG_IGN); // 忽略子进程退出的信号,避免产生僵尸进程
- 1
signal函数的用法暂时不介绍,以后会有详细说明。
先启动服务端程序book250,然后多次启动客户端程序book249,等book249运行结束后再查看book250的进程,不再有僵尸进程。
三、应用经验(采用多进程的主要目的是处理多个并发的任务,而不是为了提高程序的效率)
在学习了多进程的基础知识之后,初学者可能会认为多进程是一个高大上的技术,认为多进程处理数据肯定比单进程快,其实不是。在实际开发中,采用多进程的主要目的是处理多个并发的任务,而不是为了提高程序的效率。
从效率方面来说,某些场景下多进程的效率比单进程低,原因很简单,因为在有限的硬件资源中,多进程程序的内存开销更大,还会产生资源的竞争。就像多个人端着一盆水,不如一个人端着一盆水走得快。


