
热门标签
热门文章
- 1How do I enable large page support on Windows?_jvm cannot use large page memory because it does n
- 2YOLOv8有效涨点,添加GAM注意力机制,使用Wise-IoU有效提升目标检测效果
- 3商业模式_商业模式定义谁提出来的
- 4人工智能写论文chat免费平台有那些?_写论文的chatai
- 5用google colab t4部署phi2(公网可访问)_phi-2部署
- 6FFmpeg + Opencv 解码和显示_mmfpeg+opencv
- 7Linux安装docker并运行jar包_linux docker启动jar包
- 8手把手教你制作R包(一)_r包制作
- 9Android studio+真机 运行报错[INSTALL_FAILED_INSUFFICIENT_STORAGE]解决方法_android studio installexception: install_failed_in
- 10win7 64位官方旗舰版上搭建ruby on rails的步骤_riseon.lzradyj.cn
当前位置: article > 正文
Python实现Excel转Html和读取Pdf为Text文本_python3 pdfminer.six pdf转html
作者:很楠不爱3 | 2024-03-16 13:55:23
赞
踩
python3 pdfminer.six pdf转html
一、Excel -> Html
需求如下:
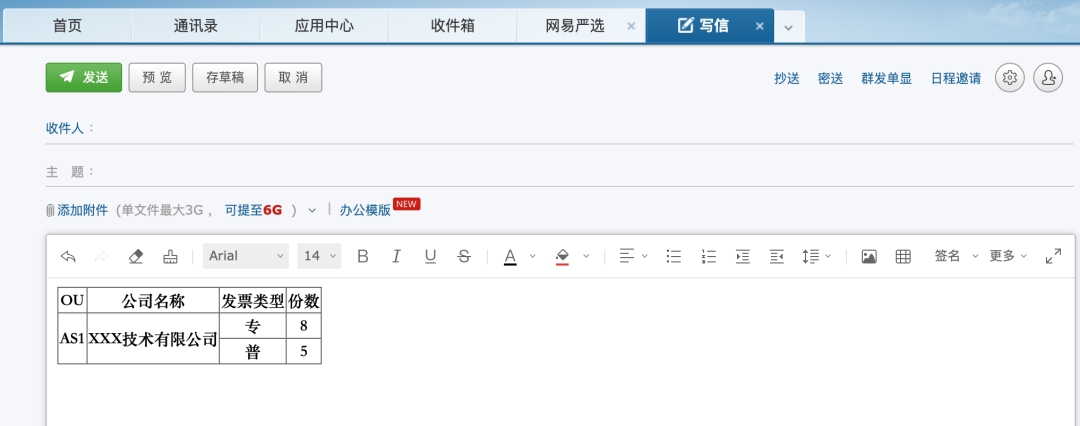
对现有excel文档做分类处理,处理了结果以邮件形式发送!
分析:
因为是excel文件处理,处理的结果需要展示在邮件中。
截图实现:打开处理的excel结果文件,截图,添加截图。因excel无法展示放弃。
文件转换:将excel结果文件转为邮件源码Html代码进行展示。
代码实现:
- import openpyxl
- from dominate.tags import *
- import dominate
-
- def excel_html(file_path):
- wd = openpyxl.load_workbook(file_path)
- ws = wd.active
- data = get_data(ws)
- return to_html(data)
-
- def get_data(wt):
- ws_data = []
- for row in wt:
- row_data = []
- for cell in row:
- if isinstance(cell, openpyxl.cell.cell.Cell):
- row_data.append(cell.value)
- else:
- row_data.append("merge")
- ws_data.append(row_data)
- data = []
- for row_index, row in enumerate(ws_data):
- row_data = []
- for cell_index, cell in enumerate(row):
-
- if cell != "merge":
- row_span = 1
- col_span = 1
- for cell_back in row[cell_index:]:
- if cell_back == "merge":
- row_span+=1
- continue
- break
-
- for row_back in ws_data[row_index+1:]:
- if row_back[cell_index] == "merge":
- col_span+=1
- continue
- break
- row_data.append({"value": cell, "rowspan":row_span, "colspan": col_span})
-
- data.append(row_data)
-
- return data
-
- def to_html(data):
- doc = dominate.document(title='excel-to-html')
- with doc:
- with div(id='excel_table').add(table(style="border-collapse: collapse; border-color: rgb(102, 102, 102); border-width: 1px; border-style: solid;")):
- for row in data:
- table_row = tr()
- for value in row:
- with table_row.add(td(
- style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);",
- rowspan=value.get("colspan"),
- align="center",
- colspan=value.get("rowspan"))):
- p(value.get("value"))
- return str(doc)
-
- if __name__ == '__main__':
-
- file_path = r"/Users/Young/Downloads/AS1-发票分类明细.xlsx"
- ret = excel_html(file_path)
- print(ret)

原excel文件

转换后的代码:
- <!DOCTYPE html>
- <html>
- <head>
- <title>excel-to-html</title>
- </head>
- <body>
- <div id="excel_table">
- <table style="border-collapse: collapse; border-color: rgb(102, 102, 102); border-width: 1px; border-style: solid;">
- <tr>
- <td align="center" colspan="1" rowspan="1" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
- <p>OU</p>
- </td>
- <td align="center" colspan="1" rowspan="1" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
- <p>公司名称</p>
- </td>
- <td align="center" colspan="1" rowspan="1" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
- <p>发票类型</p>
- </td>
- <td align="center" colspan="1" rowspan="1" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
- <p>份数</p>
- </td>
- </tr>
- <tr>
- <td align="center" colspan="1" rowspan="2" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
- <p>AS1</p>
- </td>
- <td align="center" colspan="1" rowspan="2" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
- <p>XXX技术有限公司</p>
- </td>
- <td align="center" colspan="1" rowspan="1" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
- <p>专</p>
- </td>
- <td align="center" colspan="1" rowspan="1" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
- <p>8</p>
- </td>
- </tr>
- <tr>
- <td align="center" colspan="1" rowspan="1" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
- <p>普</p>
- </td>
- <td align="center" colspan="1" rowspan="1" style="padding-top: 1px; padding-right: 1px; padding-left: 1px; color: rgb(0, 0, 0); font-size: 14.6667px; font-weight: 700; font-style: normal; text-decoration: none solid rgb(0, 0, 0); font-family: 宋体; border: 1px solid rgb(102, 102, 102); background-color: rgba(0, 0, 0, 0);">
- <p>5</p>
- </td>
- </tr>
- </table>
- </div>
- </body>
- </html>
效果图:

一、Pdf -> Text
需求:
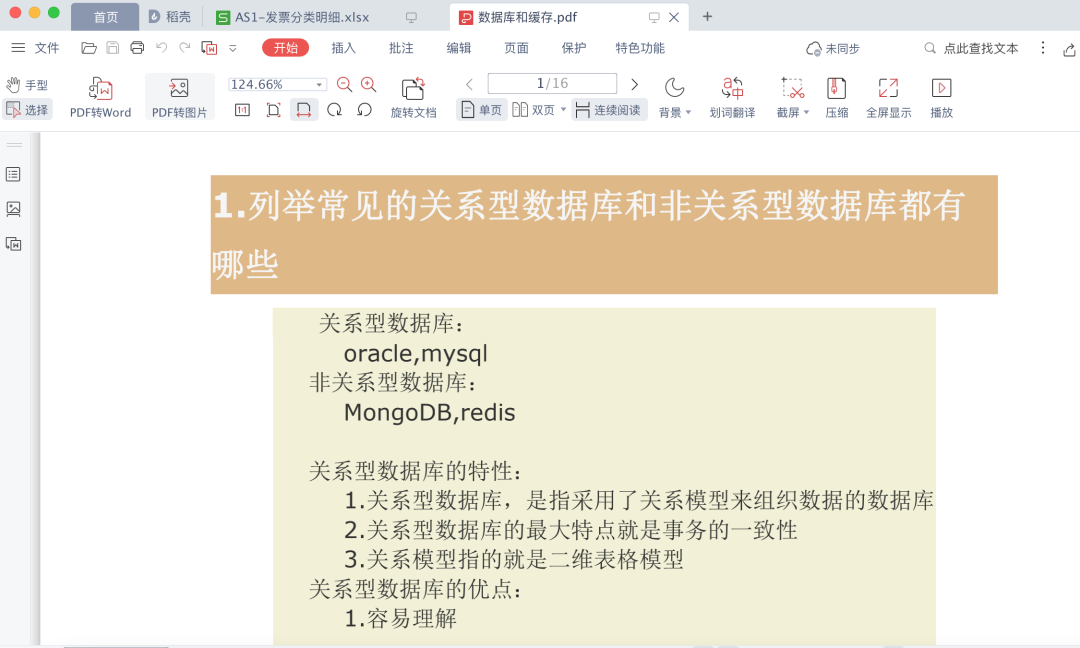
获取pdf文件部分信息
处理方式:
先转为text内容,然后通过正则获取关键信息
pdf转文本代码:
- from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
- from pdfminer.pdfpage import PDFPage
- from pdfminer.converter import XMLConverter, HTMLConverter, TextConverter
- from pdfminer.layout import LAParams
- import io
-
-
- class PDFParser(object):
- """PDF 解析器类"""
- pdf_file_path: str
-
- def __init__(self, pdf_file_path):
- """
- :param pdf_file_path: pdf文件路径
- :return:
- """
- self.pdf_file_path = pdf_file_path
-
- def to_text(self):
- """
- 将pdf转化为文字
- :return: 文件文本信息
- """
- fp = open(self.pdf_file_path, 'rb')
- rsrcmgr = PDFResourceManager()
- retstr = io.StringIO()
- codec = 'utf-8'
- laparams = LAParams()
- # device = TextConverter(rsrcmgr, retstr, codec=codec, laparams=laparams)
-
- device = TextConverter(rsrcmgr, retstr, laparams=laparams)
- # Create a PDF interpreter object.
- interpreter = PDFPageInterpreter(rsrcmgr, device)
- # Process each page contained in the document.
- for page in PDFPage.get_pages(fp):
- interpreter.process_page(page)
- fp.close()
- return retstr.getvalue()
-
- if __name__ == '__main__':
- file_path = r"/Users/Young/Downloads/数据库和缓存.pdf"
- pdf = PDFParser(file_path)
- ret = pdf.to_text()
- print(ret)
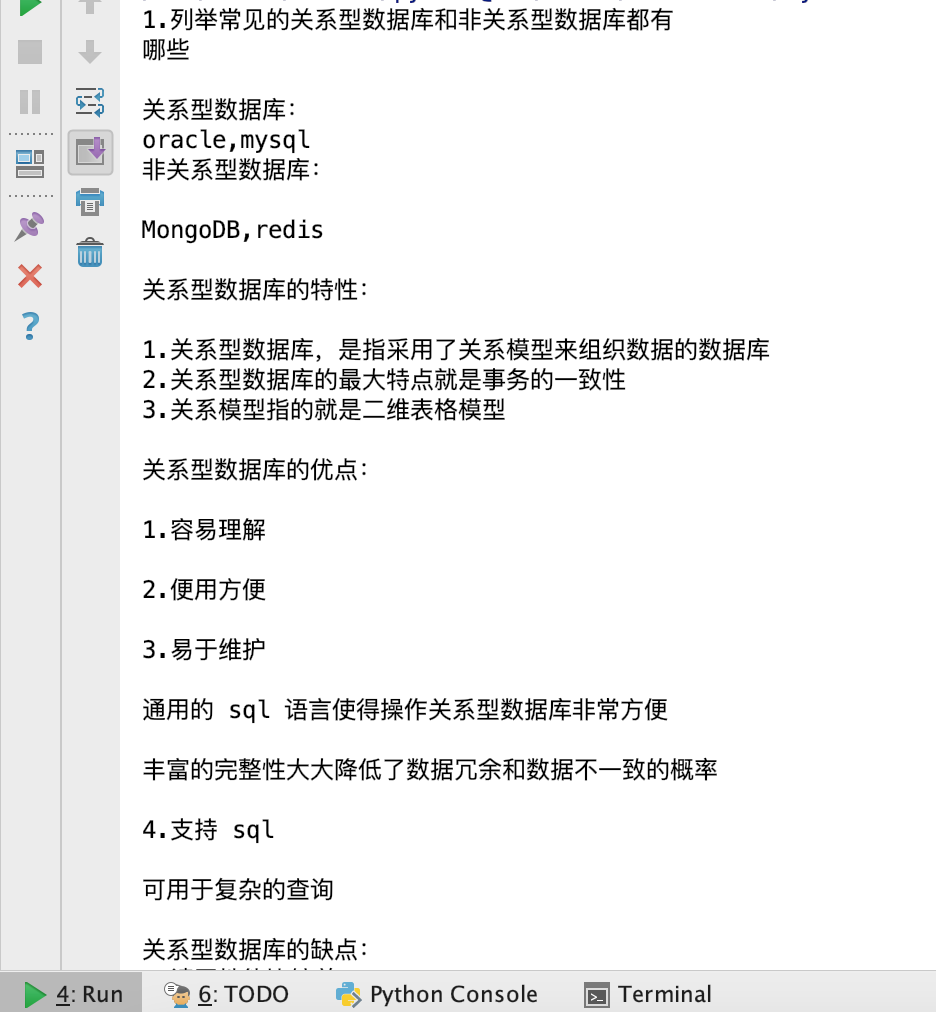
处理结果

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/很楠不爱3/article/detail/249907
推荐阅读
相关标签

