
热门标签
热门文章
- 1系列一:HIDS初识
- 2JavaScript 如何手动触发窗口滚动事件_js 捕获scrollevent事件,手动实现滚动
- 3梅尔倒谱系数MFCC由浅入深(超详细)
- 4【HarmonyOS4.0】第二篇-鸿蒙开发介绍_harmoneyos 4.0 有文档吗
- 5MySQL查询原理简述_mysql 查询原理
- 6区块链概述
- 7MNE从头创建raw结构_mne.io.rawarray
- 8Vscode:Import “numpy“ could not be resolvedPylancere(portMissingImports)_import "numpy" could not be resolved
- 9使用SQLite删除Mac OS X 中launchpad里的快捷方式
- 10HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
当前位置: article > 正文
Salient object detection 显著图检测
作者:很楠不爱3 | 2024-03-18 03:22:38
赞
踩
Salient object detection 显著图检测
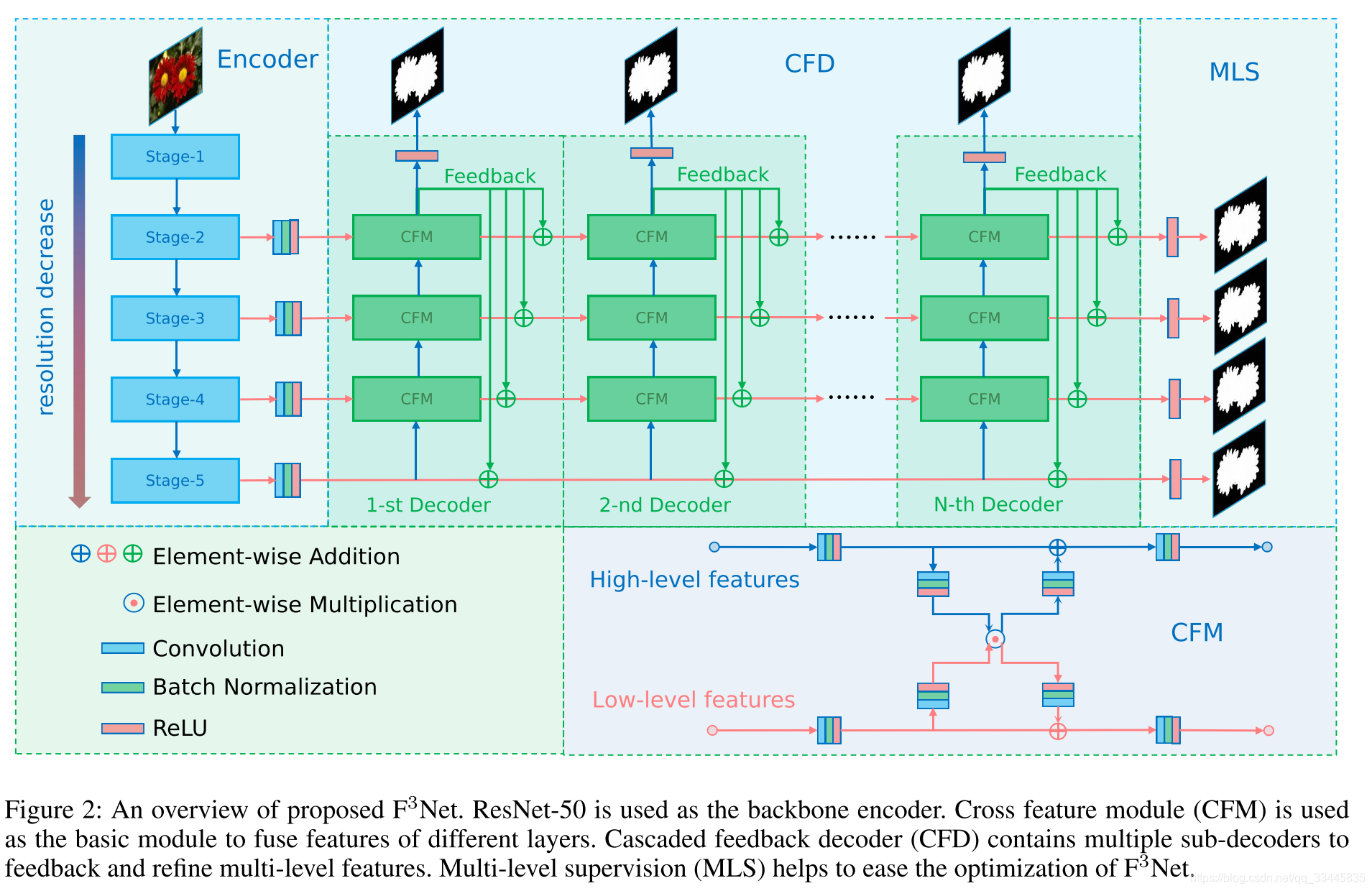
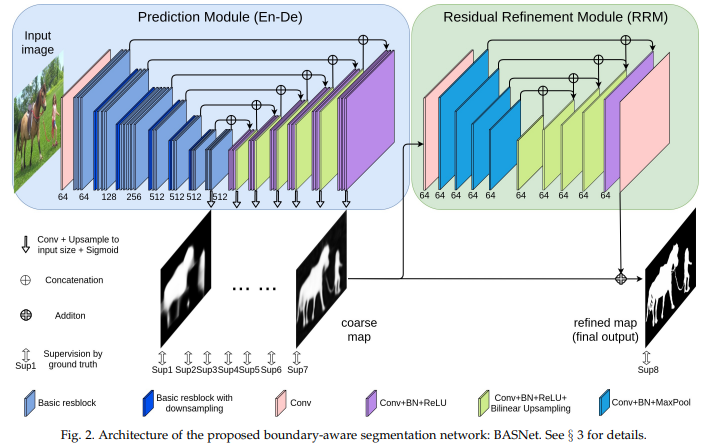

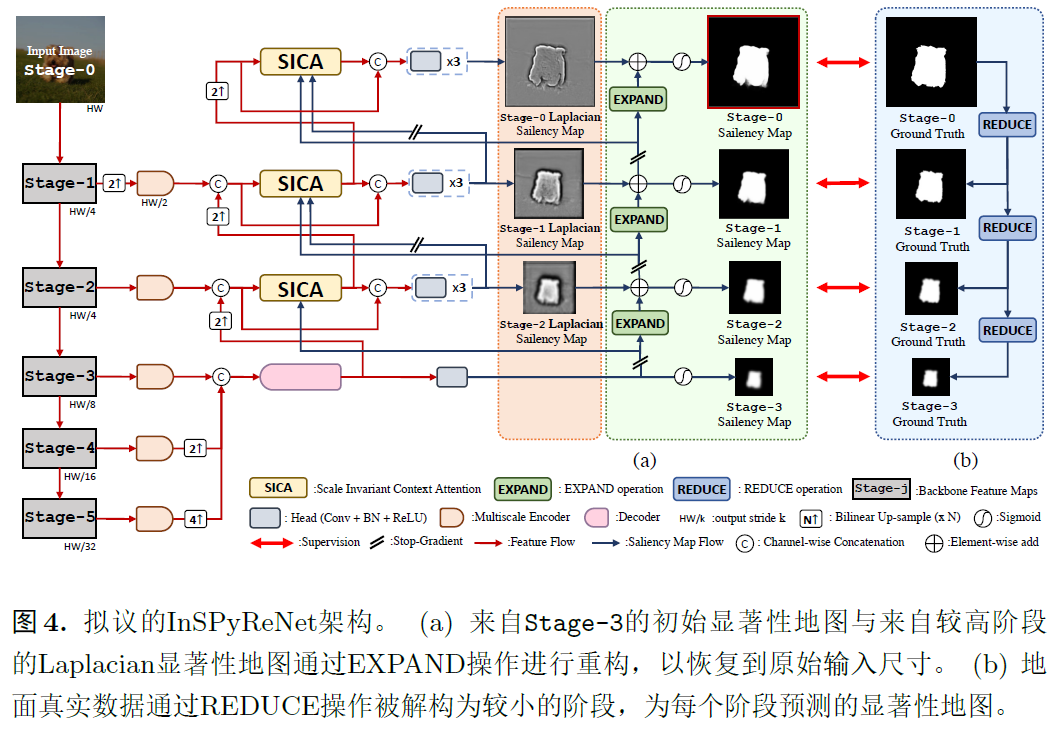
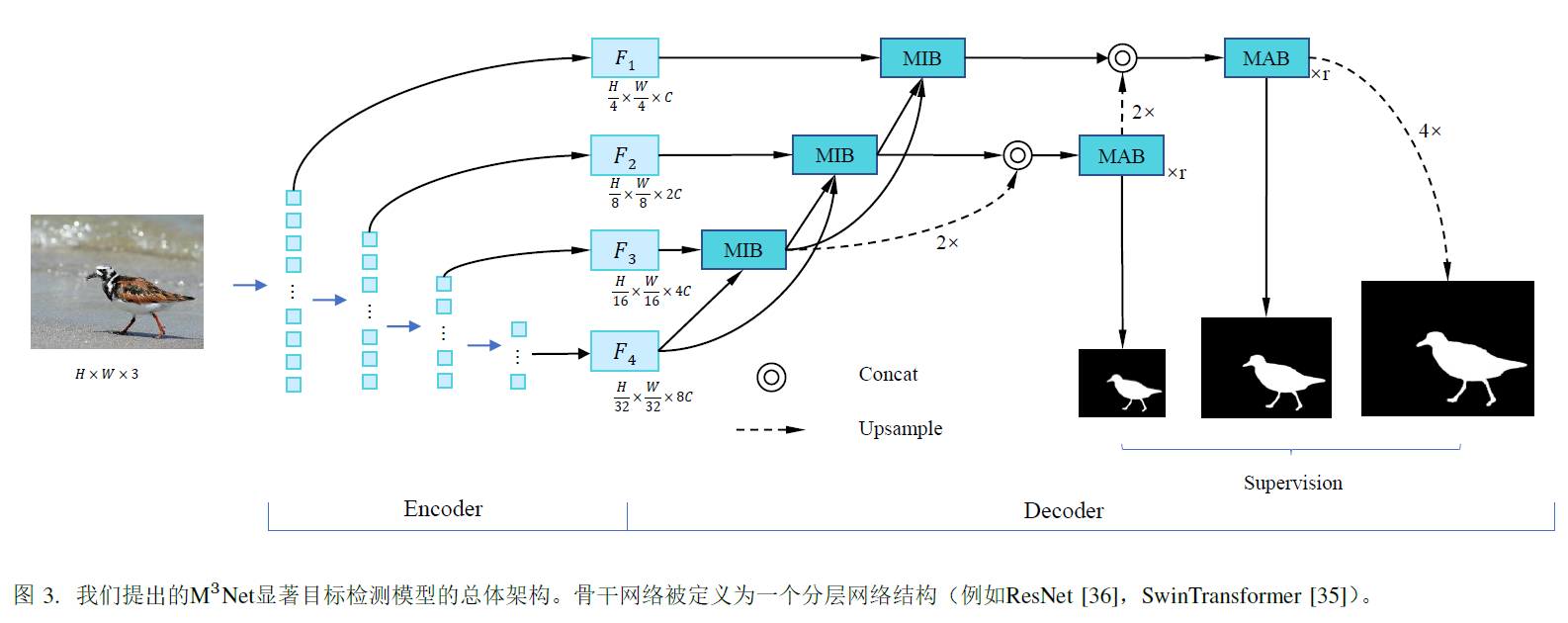
6.Tracer

7.RMFormer

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/很楠不爱3/article/detail/260016
推荐阅读
相关标签

