
- 1基于OpenCV的驾驶疲劳检测与预警系统设计
- 2@JsonFormat @DataTimeFormat 时间格式 入参 时间 日期 转换 Date_@datetimeformat(pattern = "yyyy-mm-dd")
- 3在STM32F407上跑OpenHarmony鸿蒙操作系统_openharmony开发4g物联网stm32f407
- 4瑞吉外卖项目 基于spring Boot+mybatis-plus开发 超详细笔记,有源码链接_瑞吉外卖是基于什么开发的
- 5基于huggingface加载openai/clip-vit-large-patch14-336视觉模型demo_clip-vit-large-patch14-336怎么加载训练分类代码
- 6实现1V1音视频实时互动直播系统 十二、第七节 WebRTC客户端的实现_webrtc 实现监考系统
- 7scss是什么?安装使用的步骤是?有哪几大特性?_mode安装scss
- 8Graphpad Prism9.5.1 安装教程 (含Win/Mac版)_graphpad安装
- 9【HarmonyOS】鸿蒙开发之Slider组件——第3.5章
- 10Android DropBoxManager服务分析_subject: broadcast of intent { act=android.intent.
零样本视频生成无压力,基于飞桨框架实现Text2Video-Zero核心代码及依赖库
赞
踩


 项目背景
项目背景
继 AI 绘画之后,短视频行业正迎来 AI 智能创作的新浪潮。AI 智能创作正在各个方面为创作者和用户带来新的体验和价值。AI 动漫视频、AI 瞬息宇宙、AI 视频风格化等诸多创作功能不仅为视频内容创作提供了全新灵感,而且大大降低了用户创作的门槛,提高了视频生产效率。
然而,现有的文本-视频生成方法需要极其高昂的计算资源和超大规模的文本-视频数据集(如:CogVideo、Gen-1),对大多数用户来说,成本较高。此外,很多时候单纯使用文本提示生成视频,生成的内容较为抽象,不一定符合用户的需求。因此,在某些情况下,用户需要提供参考视频,并通过文本提示来引导模型进行文本视频生成。与之对应,Text2Video-Zero 可以通过运动动力学(motion dynamics)、帧间注意力机制(frame-level self-attention)等技术手段对原始的文本-图像模型进行修改,使其可以完成文本-视频任务,且不需任何训练,是一种十分理想的文本-视频生成方法。
本项目基于飞桨框架实现了 Text2Video-Zero 的核心代码及依赖库,并通过 PPDiffusers 的文本-图像生成模型实现了文本-视频生成、文本-视频编辑、姿态引导的文本-视频生成、边缘引导的文本-视频生成、深度图引导的文本-视频生成、边缘引导和 Dreambooth 定制的文本-视频生成在内的全部视频生成模块,并将该成果开源在 AI Studio 上。该实现对丰富飞桨 AIGC 生态具有极大的意义。
大模型专区 Text2Video-Zero-零样本文本到视频生成(上)
https://aistudio.baidu.com/aistudio/projectdetail/6212799
大模型专区 Text2Video-Zero-零样本文本到视频生成(下)
https://aistudio.baidu.com/aistudio/projectdetail/6389526
 模型原理
模型原理
Text2Video-Zero 以随机采样潜在编码 为起点,使用预训练的 Stable Diffusion 模型(SD),通过 DDIM 反向传播 步来获得 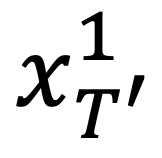 。对于每一帧 k,作者使用变形函数将
。对于每一帧 k,作者使用变形函数将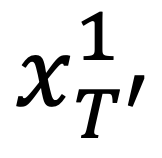 变换为
变换为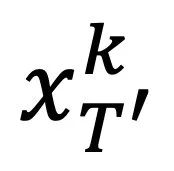 ,从而获得特定的运动场结果。通过使用运动动力学对潜在编码进行增强,模型可以确定全局场景和相机运动,从而实现背景和全局场景的时间一致性。
,从而获得特定的运动场结果。通过使用运动动力学对潜在编码进行增强,模型可以确定全局场景和相机运动,从而实现背景和全局场景的时间一致性。
之后,作者使用 DDPM 前向传播对潜在编码 , k=1,…,m 进行传递。这里,概率 DDPM 方法可以实现更大自由度的物体运动。然后将潜在编码传递到使用帧间注意力机制修改后的 SD 模型中,帧间注意力机制使用第一帧的 key 和 value 来生成整个视频序列的图像。通过帧间注意力机制,前景物体的身份和外观可以在视频序列中保留。不仅如此,作者还对生成的视频序列使用了背景平滑技术。具体来说,作者使用显著目标检测来获得每一帧 k 中暗示了前景像素的掩码 ,并使用第一帧变换到第 k 帧的潜在编码 和潜在编码 来进一步提高掩码 中背景部分的时间一致性。该方法的整体架构图如下:
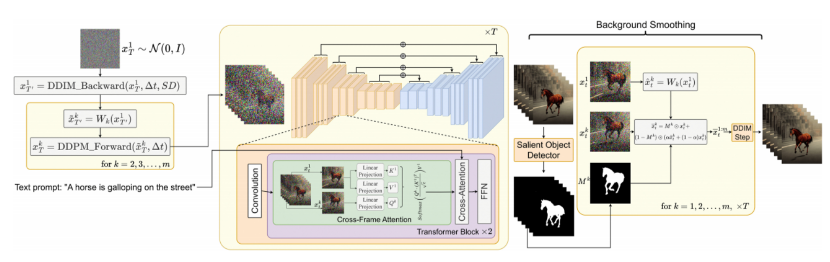
图1 Text2Video-Zero 模型的整体架构图
由于 Text2Video-Zero 是一种通过对文本-图像模型进行零样本微调来生成视频的 AIGC 模型。因此,本项目会涉及到很多预训练的文本-图像生成模型,包括 Stable Diffusion V1.5、Instruct-Pix2Pix 、ControlNet 和张一乔老师(AI Studio昵称为笠雨聆月)的诺艾尔 Dreambooth 模型。其中,Stable Diffusion V1.5 模型用于文本-视频生成,Instruct-Pix2Pix 模型用于文本-视频编辑,ControlNet 模型用于姿态引导的文本-视频生成,边缘引导的文本-视频生成和深度图引导的文本-视频生成,诺艾尔 Dreambooth 模型用于边缘引导和 Dreambooth 定制的文本视频生成。所有开源模型附在文章最后,在此也对所有开源贡献者表示衷心感谢。
运动动力学核心代码
- 1def create_motion_field(self, motion_field_strength_x, motion_field_strength_y, frame_ids, video_length, latents):
- 2 reference_flow = paddle.zeros(
- 3 (video_length-1, 2, 512, 512), dtype=latents.dtype)
- 4 for fr_idx, frame_id in enumerate(frame_ids):
- 5 reference_flow[fr_idx, 0, :,
- 6 :] = motion_field_strength_x*(frame_id)
- 7 reference_flow[fr_idx, 1, :,
- 8 :] = motion_field_strength_y*(frame_id)
- 9 return reference_flow
- 10
- 11def create_motion_field_and_warp_latents(self, motion_field_strength_x, motion_field_strength_y, frame_ids, video_length, latents):
- 12 motion_field = self.create_motion_field(motion_field_strength_x=motion_field_strength_x,
- 13 motion_field_strength_y=motion_field_strength_y, latents=latents,
- 14 video_length=video_length, frame_ids=frame_ids)
- 15 for idx, latent in enumerate(latents):
- 16 out = self.warp_latents_independently(
- 17 latent[None], motion_field)
- 18 out = out.squeeze(0)
- 19 latents[idx]=out
- 20 return motion_field, latents
- 21
- 22x_t0_k = x_t0_1[:, :, :1, :, :].tile([1, 1, video_length-1, 1, 1])
- 23reference_flow, x_t0_k = self.create_motion_field_and_warp_latents(
- 24 motion_field_strength_x=motion_field_strength_x, motion_field_strength_y=motion_field_strength_y, latents=x_t0_k, video_length=video_length, frame_ids=frame_ids[1:])
- 25if t1 > t0:
- 26 x_t1_k = self.DDPM_forward(
- 27 x0=x_t0_k, t0=t0, tMax=t1, shape=shape, text_embeddings=text_embeddings, generator=generator)
- 28else:
- 29 x_t1_k = x_t0_k
- 30if x_t1_1 is None:
- 31 raise Exception
- 32x_t1 = paddle.concat([x_t1_1, x_t1_k], axis=2).clone().detach()
- 33ddim_res = self.DDIM_backward(num_inference_steps=num_inference_steps, timesteps=timesteps, skip_t=t1, t0=-1, t1=-1,
- 34 do_classifier_free_guidance=do_classifier_free_guidance,
- 35 null_embs=null_embs, text_embeddings=text_embeddings, latents_local=x_t1, latents_dtype=dtype,
- 36 guidance_scale=guidance_scale,
- 37 guidance_stop_step=guidance_stop_step, callback=callback, callback_steps=callback_steps, extra_step_kwargs=extra_step_kwargs, num_warmup_steps=num_warmup_steps)
- 38x0 = ddim_res["x0"].detach()

帧间注意力机制核心代码
- 1class CrossFrameAttnProcessor:
- 2 def __init__(self, unet_chunk_size=2):
- 3 self.unet_chunk_size = unet_chunk_size
- 4
- 5 def __call__(
- 6 self,
- 7 attn,
- 8 hidden_states,
- 9 encoder_hidden_states=None,
- 10 attention_mask=None):
- 11 batch_size, sequence_length, _ = hidden_states.shape
- 12 attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
- 13 query = attn.to_q(hidden_states)
- 14 is_cross_attention = encoder_hidden_states is not None
- 15 if encoder_hidden_states is None:
- 16 encoder_hidden_states = hidden_states
- 17 elif attn.cross_attention_norm:
- 18 encoder_hidden_states = attn.norm_cross(encoder_hidden_states)
- 19 key = attn.to_k(encoder_hidden_states)
- 20 value = attn.to_v(encoder_hidden_states)
- 21 if not is_cross_attention:
- 22 video_length = key.shape[0] // self.unet_chunk_size
- 23 former_frame_index = [0] * video_length
- 24 f = video_length
- 25 b_f, d, c = key.shape
- 26 b = b_f//f
- 27 key = key.reshape([b,f, d, c])
- 28 key = paddle.gather(key, paddle.to_tensor(former_frame_index), axis=1)
- 29 key = key.reshape([-1,d,c])
- 30 b_f, d, c = value.shape
- 31 b = b_f//f
- 32 value = value.reshape([b,f,d,c])
- 33 value = paddle.gather(value, paddle.to_tensor(former_frame_index), axis=1)
- 34 value = value.reshape([-1,d,c])
- 35 query = head_to_batch_dim(query,attn.heads)
- 36 key = head_to_batch_dim(key,attn.heads)
- 37 value = head_to_batch_dim(value,attn.heads)
- 38 attention_probs = attn.get_attention_scores(query, key, attention_mask)
- 39 hidden_states = paddle.bmm(attention_probs, value)
- 40 hidden_states = batch_to_head_dim(hidden_states, attn.heads)
- 41 hidden_states = attn.to_out[0](hidden_states)
- 42 hidden_states = attn.to_out[1](hidden_states)
- 43 return hidden_states

开发环境与实现过程

PPDiffusers 介绍
PPDiffusers 是一款支持多种模态(如文本图像跨模态、图像、语音)扩散模型(Diffusion Model)训练和推理的国产化工具箱。依托于飞桨框架和 PaddleNLP 自然语言处理开发库,PPDiffusers 提供了超过50种 SOTA 扩散模型 Pipelines 集合,支持文图生成(Text-to-Image Generation)、文本引导的图像编辑(Text-Guided Image Inpainting)、文本引导的图像变换(Image-to-Image Text-Guided Generation)、文本条件视频生成(Text-to-Video Generation)、超分(Super Resolution)在内的10余项任务,覆盖文本、图像、视频、音频等多种模态。
2023年06月20日,飞桨正式发布 PPDiffusers 0.16.1 版本,新增 T2I-Adapter,支持训练与推理;ControlNet 升级,支持 reference only 推理;新增 WebUI Stable Diffusion Pipeline,支持通过 prompt 的方式动态加载lora、textual_inversion 权重;新增 Stable Diffusion HiresFix Pipeline,支持高分辨率修复;新增关键点控制生成任务评价指标 COCO eval;新增多种模态扩散模型 Pipelines,包括视频生成(Text-to-Video-Synth、Text-to-Video-Zero)、音频生成(AudioLDM、Spectrogram Diffusion);新增文图生成模型 IF。
GitHub链接
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/ppdiffusers

安装指令
PPDiffusers 的安装指令如下:
- 1!pip install --user ftfy regex
- 2!pip install --user --upgrade ppdiffusers
在此基础上,也可选择其他环境安装:
- 1!pip install decord
- 2!pip install omegaconf
- 3!pip install --user scikit-image
 实现效果
实现效果

文本-视频生成效果
根据用户输入的文本提示词生成相应视频。

推理代码:
- 1model = Model(device = "cuda", dtype = paddle.float16)
- 2paddle.seed(1234)
- 3prompt = "An astronaut dancing in Antarctica"
- 4video_length = 2
- 5params = {"t0": 44, "t1": 47 , "motion_field_strength_x" : 12, "motion_field_strength_y" : 12, "video_length": video_length }
- 6output_dir = "/home/aistudio/work/Text2Video-Zero_paddle/output/text_to_video"
- 7save_format = "gif"
- 8out_path = '{}/{}.{}'.format(output_dir,prompt,save_format)
- 9fps = 4
- 10chunk_size = 4
- 11model_path = "/home/aistudio/stable-diffusion-v1-5/runwayml/stable-diffusion-v1-5"
- 12model.process_text2video(prompt, model_name = model_path, fps = fps,save_path = out_path,save_format=save_format,chunk_size= chunk_size ,is_gradio = False, **params)
最终呈现的效果如图2所示:

图2 文本视频生成效果

文本-视频编辑效果
根据用户输入的文本提示词对视频进行编辑。

推理代码:
- 1model = Model(device = "cuda", dtype = paddle.float16)
- 2paddle.seed(1234)
- 3prompt = "make it Van Gogh Starry Night style"
- 4video_path = '__assets__/pix2pix video/camel.mp4'
- 5output_dir = "/home/aistudio/work/Text2Video-Zero_paddle/output/video_instruct_pix2pix"
- 6save_format = "gif"
- 7out_path = '{}/{}.{}'.format(output_dir,prompt,save_format)
- 8chunk_size = 8
- 9model_path = "/home/aistudio/instruct_Pix2Pix/timbrooks/instruct-pix2pix"
- 10model.process_pix2pix(video_path, prompt=prompt, resolution=384,model_path = model_path,chunk_size= chunk_size ,save_path=out_path,save_format=save_format,is_gradio = False)
最终呈现的效果如图3所示:

图3 文本视频编辑效果

文本-视频编辑效果
根据用户输入的文本提示和运动姿态生成相应视频。
推理代码如下:
- 1model = Model(device = "cuda", dtype = paddle.float16)
- 2paddle.seed(1234)
- 3prompt = "an astronaut dancing in outer space"
- 4motion_video_path = '/home/aistudio/work/Text2Video-Zero_paddle/__assets__/text_to_video_pose_control/dance5_corr.mp4'
- 5output_dir = "/home/aistudio/work/Text2Video-Zero_paddle/output/text_to_video_pose_control"
- 6save_format = "gif"
- 7out_path = '{}/{}.{}'.format(output_dir,prompt,save_format)
- 8stable_diffision_path="/home/aistudio/stable-diffusion-v1-5/runwayml/stable-diffusion-v1-5"
- 9controlnet_path="/home/aistudio/controlnet/ppdiffusers/lllyasviel/sd-controlnet-openpose"
- 10model.process_controlnet_pose( motion_video_path, prompt=prompt, save_path=out_path,save_format=save_format,\
- 11chunk_size= 24, resolution=384,model_path_list=[stable_diffision_path,controlnet_path])
最终呈现的效果如图4所示:

图4姿态引导的文本-视频生成效果

边缘引导的文本-视频生成

推理代码如下:
- 1model = Model(device = "cuda", dtype = paddle.float16)
- 2paddle.seed(1234)
- 3prompt = 'oil painting of a deer, a high-quality, detailed, and professional photo'
- 4video_path = '/home/aistudio/work/Text2Video-Zero_paddle/__assets__/text_to_video_edge_control/deer.mp4'
- 5output_dir = "/home/aistudio/work/Text2Video-Zero_paddle/output/text_to_video_edge_control"
- 6save_format = "gif"
- 7out_path = '{}/{}.{}'.format(output_dir,prompt,save_format)
- 8stable_diffision_path="/home/aistudio/stable-diffusion-v1-5/runwayml/stable-diffusion-v1-5"
- 9controlnet_path="/home/aistudio/controlnet/ppdiffusers/lllyasviel/sd-controlnet-canny"
- 10model.process_controlnet_canny(video_path, prompt=prompt, save_path=out_path,save_format=save_format,\
- 11chunk_size= 16, resolution=384,model_path_list=[stable_diffision_path,controlnet_path])
最终呈现的效果如图5所示:
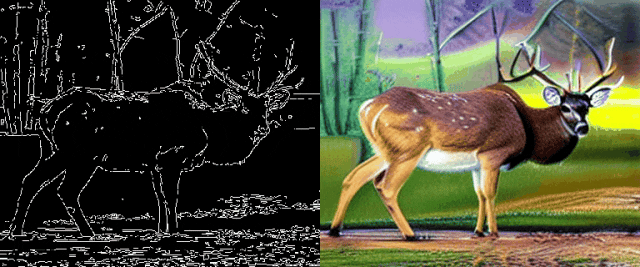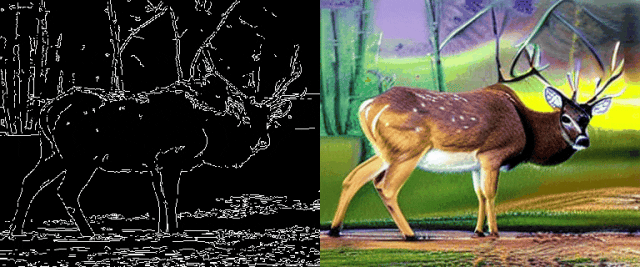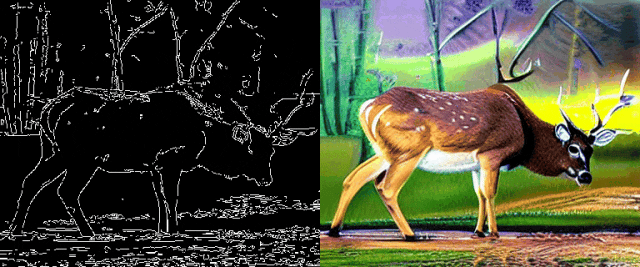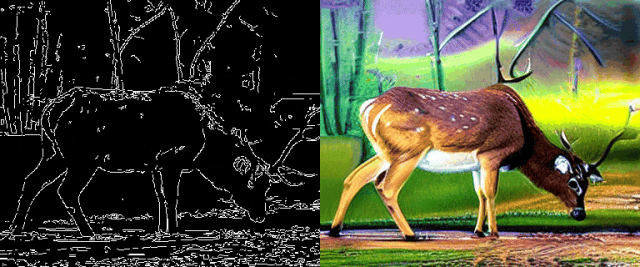 图5边缘引导的文本-视频生成效果
图5边缘引导的文本-视频生成效果

深度图引导的文本-视频生成
根据用户输入的文本提示和深度图生成相应视频。

推理代码如下:
- 1model = Model(device = "cuda", dtype = paddle.float16)
- 2paddle.seed(1234)
- 3prompt = 'a santa claus, a high-quality, detailed, and professional photo'
- 4video_path = '/home/aistudio/work/Text2Video-Zero_paddle/__assets__/text_to_video_depth_control/santa.mp4'
- 5output_dir = "/home/aistudio/work/Text2Video-Zero_paddle/output/text_to_video_depth_control"
- 6save_format = "gif"
- 7out_path = '{}/{}.{}'.format(output_dir,prompt,save_format)
- 8stable_diffision_path="/home/aistudio/stable-diffusion-v1-5/runwayml/stable-diffusion-v1-5"
- 9controlnet_path="/home/aistudio/controlnet/ppdiffusers/lllyasviel/sd-controlnet-depth"
- 10model.process_controlnet_depth(video_path, prompt=prompt, save_path=out_path,save_format = save_format,\
- 11chunk_size= 16, resolution=384,model_path_list=[stable_diffision_path,controlnet_path])
最终呈现的效果如图6所示:

图6 深度图引导的文本-视频生成效果

边缘引导和 Dreambooth 定制的文本-视频生成
根据用户输入的文本提示、图像边缘和 Dreambooth 定制化模型生成相应视频。
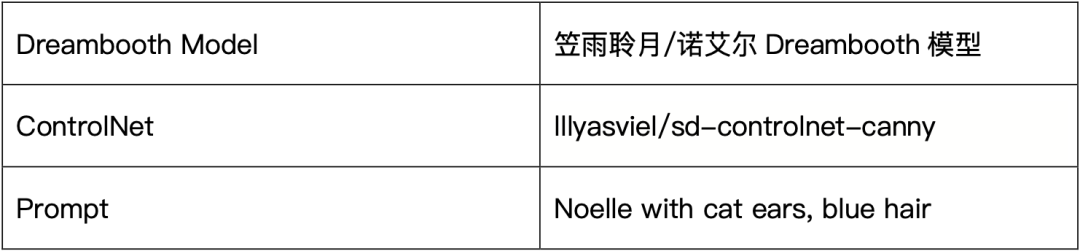
推理代码如下所示:
- 1model = Model(device = "cuda", dtype = paddle.float16)
- 2paddle.seed(1234)
- 3prompt = "Noelle with cat ears, blue hair"
- 4video_path = '/home/aistudio/work/Text2Video-Zero_paddle/__assets__/text_to_video_dreambooth/woman1.mp4'
- 5output_dir = "/home/aistudio/work/Text2Video-Zero_paddle/output/text_to_video_dreambooth"
- 6save_format = "gif"
- 7out_path = '{}/{}.{}'.format(output_dir,prompt,save_format)
- 8dreambooth_model_path= '/home/aistudio/dream_outputs'
- 9controlnet_path="/home/aistudio/controlnet/ppdiffusers/lllyasviel/sd-controlnet-canny"
- 10model.process_controlnet_canny_db(dreambooth_model_path, video_path, prompt=prompt, save_path=out_path,\
- 11 save_format=save_format,chunk_size= 16, resolution=384, model_path_list=[controlnet_path])
最终呈现的效果如图7所示:

图7 边缘引导和 Dreambooth specialization 定制的文本-视频生成

结语
以上是本项目对 Text2Video-Zero 官方项目的全部实现。现有的文本-视频生成方法大多用于为用户提供灵感,很难为用户提供定制化视频生成服务。通过运动动力学、帧间注意力机制等技术手段对原始的文本-图像模型进行修改,Text2Video-Zero 很好地解决了上述问题,可以基于用户提供的文本提示、待编辑视频、运动姿态、边缘图像、深度图像和 Dreambooth 模型进行文本视频生成。该方法在无需训练的情况下,对主流的文本-图像生成模型进行微调,这意味着用户只需要训练出相应的文本-图像生成模型,就可以进行定制化的文本-视频生成,展现了 Text2Video-Zero 在文本-视频生成领域巨大的潜力。
欢迎更多感兴趣的开发者参与到飞桨文本-视频生成生态的建设中,并依托百度飞桨AI技术开发出更多有趣的应用。
参考文献
[1] https://github.com/Picsart-AI-Research/Text2Video-Zero
[2] https://github.com/showlab/Tune-A-Video
[3] https://github.com/PaddlePaddle/PaddleNLP/tree/develop/ppdiffusers
[4] https://aistudio.baidu.com/aistudio/projectdetail/5972296
[5] https://aistudio.baidu.com/aistudio/projectdetail/5912535
往期推荐

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~

