
Hadoop集群完全分布式搭建_hadoop分布式集群搭建
赞
踩
本人也只是hadoop学习的一个萌新,在这段时间内因为课程的需要,安装了一下hadoop集群,里面遇到了一些问题,找到了一些解决办法,如果文章内有什么错误,欢迎大家与我交流,下面就开始搭建hadoop集群吧!
搭建环境为win10,虚拟机为VM16.2.4,操作系统为CentOS-6.7,JDK版本为1.8.0,hadoop版本为2.7.4,
链接:https://pan.baidu.com/s/1Z-BrajyX2KXruxMdC4bbBg
提取码:1247
文件下载之后下面开始进行正式的安装!
一、vm安装
因为我的电脑已经有了vm,卸载安装有点麻烦,下面的vm安装演示将在win11操作系统之下进行演示。
选择云盘中的VM虚拟机,双击点击安装

进入如下界面:
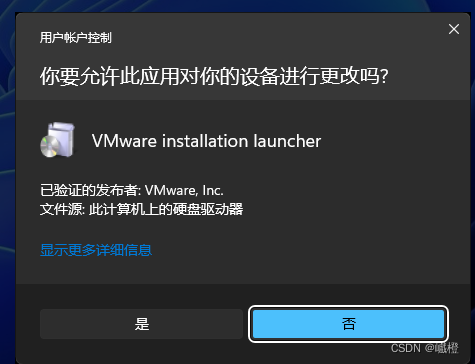
选择“是”,进入下面的这个界面
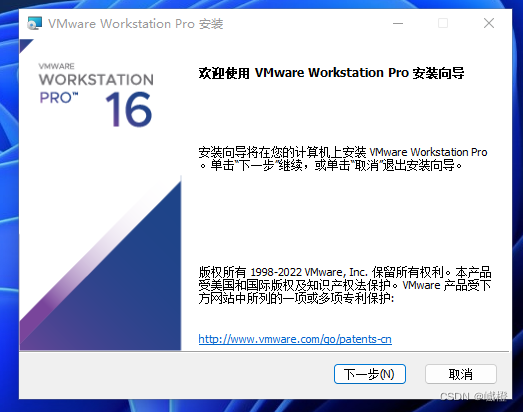
点击“下一步”进入如下界面
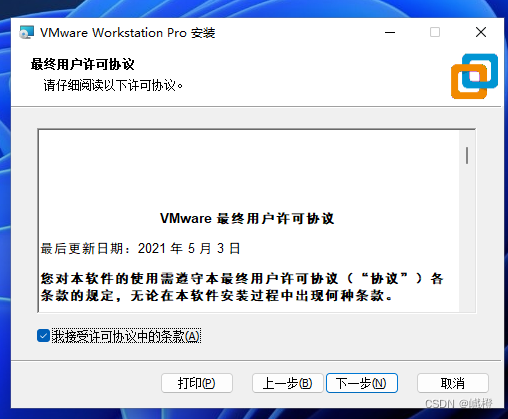
勾选“我接受许可协议中的条款”,点击“下一步”进入下一个界面
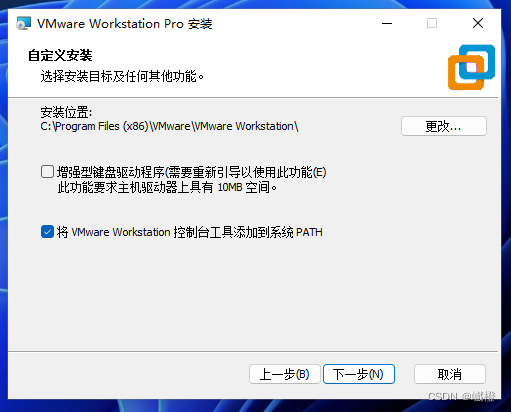
这个“安装位置”建议修改一下,最好别放到C盘了,修改结束之后继续点击“下一步”
还是“下一步”
点击“下一步”之后,点击“安装”
等待一下下
后面这个许可证可以在百度上搜一下,看看有没有能用的(应该是能够搜到的)
到这里,基本VM虚拟机安装的应该差不多了,下面开始进行第二部分,也就是hadoop集群的搭建了
二、hadoop集群搭建
本次搭建的hadoop集群为完全分布式搭建,共三台虚拟机:hadoop01、hadoop02、hadoop03.其中的hadoop01为主节点,hadoop02、hadoop03为从节点。
个人是比较推荐在一个盘中创建一个专门的hadoop文件夹,用然后在hadoop文件夹下创三个文件夹,命名为hadoop01、hadoop02、hadoop03(这样比较方面找到虚拟机的位置),当然不这么干也可以,只要能搭的起来就是好搭。现在开始进行搭建!
1、虚拟机的创建
点击“创建虚拟机选项”,出现如下界面:
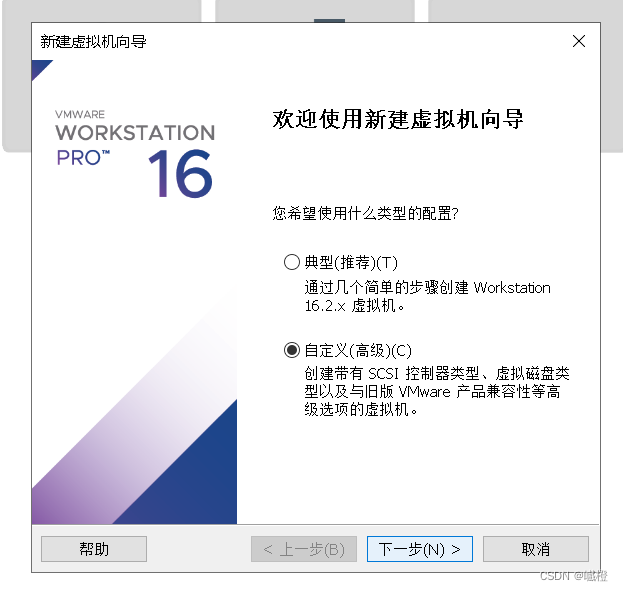
选择“自定义(高级)”,点击“下一步”
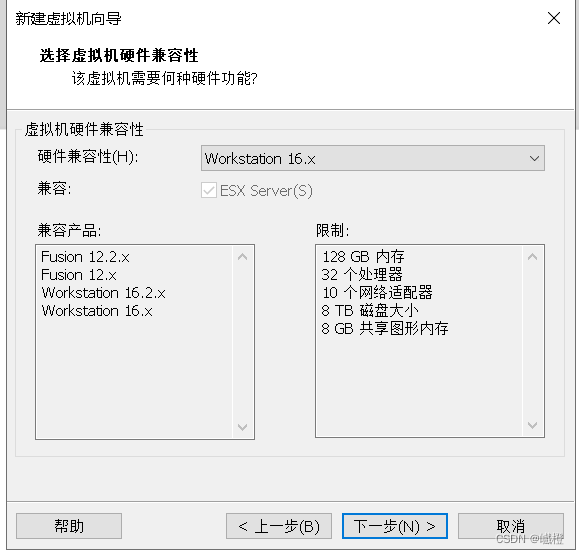
这边我将“硬件兼容性”修改为16.X了(主要是我之前都是这么做的,选其他的不知道会不会出现一些问题),点击“下一步”
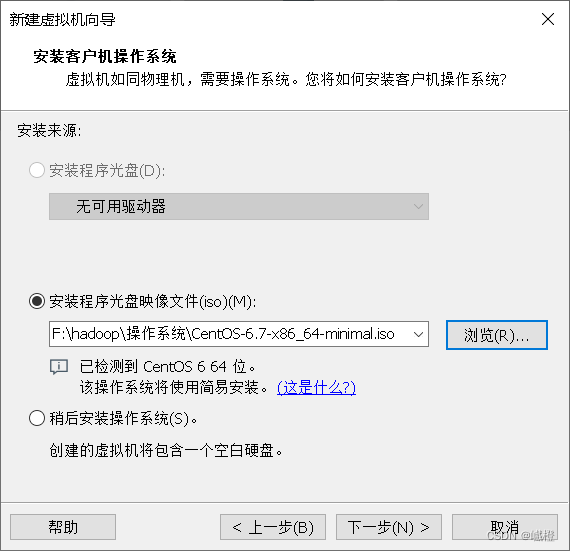
勾选“安装程序光盘映像文件”,点击“浏览”选择iso,选择的iso就是刚刚通过云盘下载里面的iso了,对应选择就可以了,然后接着点击“下一步”
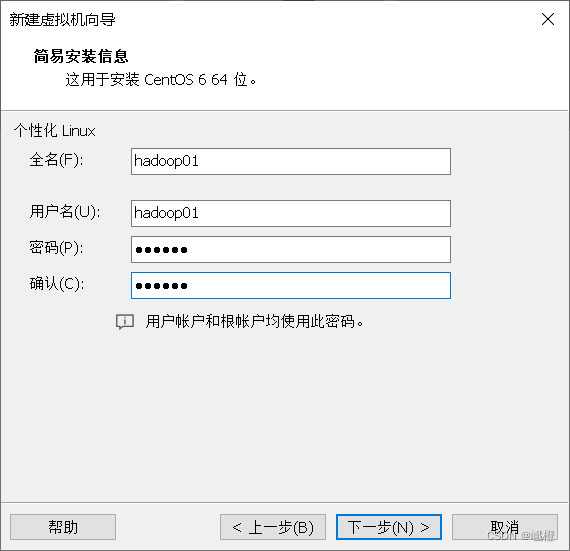
emmm…这个呢,基本上就是看自己了,别给密码设的嘎嘎难就行了(当然我肯定是不会说我的密码是123456的),配置结束后点击“下一步”
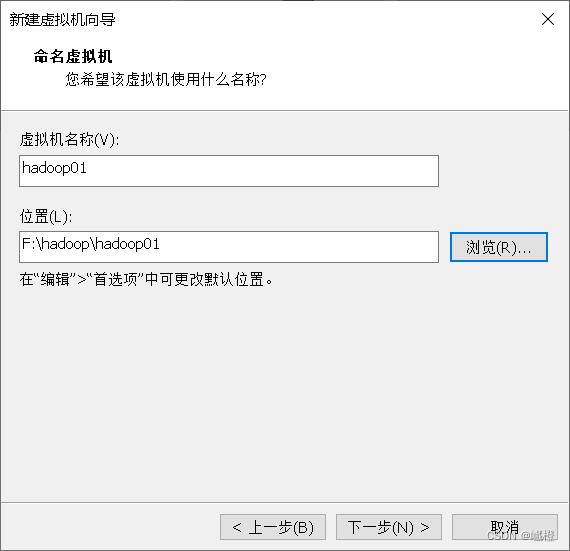
这个是自己修改的,hadoop01就叫hadoop01吧,感觉好记一点,然后下面的“位置”,默认在C盘,可以跟我一样给它放到刚刚创的hadoop文件夹下的hadoop01文件夹下,配置完成后点击“下一步”
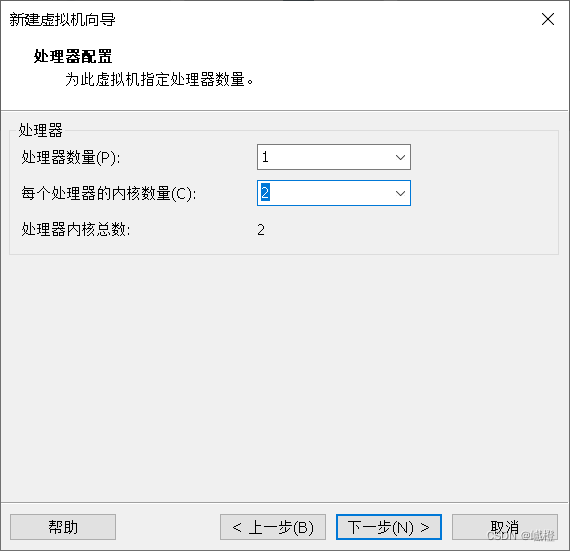
把“每个处理器内核数量”修改为2,然后点击“下一步”
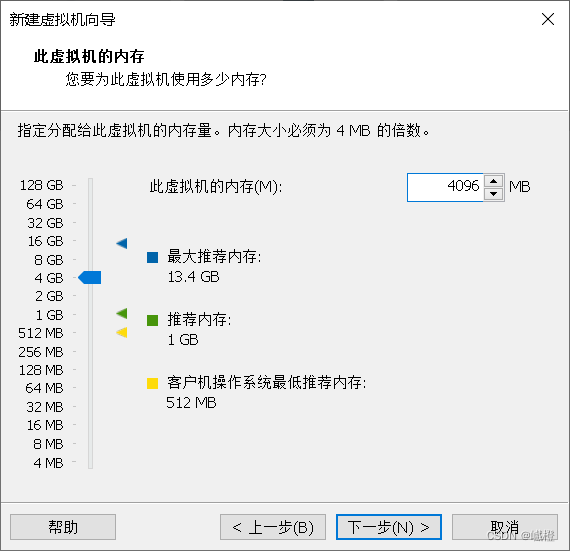
我的电脑的内存是16g,16g的推荐主节点4g,两个从节点各3g,我这边配置的hadoop01的内存为4g,配置完成之后点击“下一步”
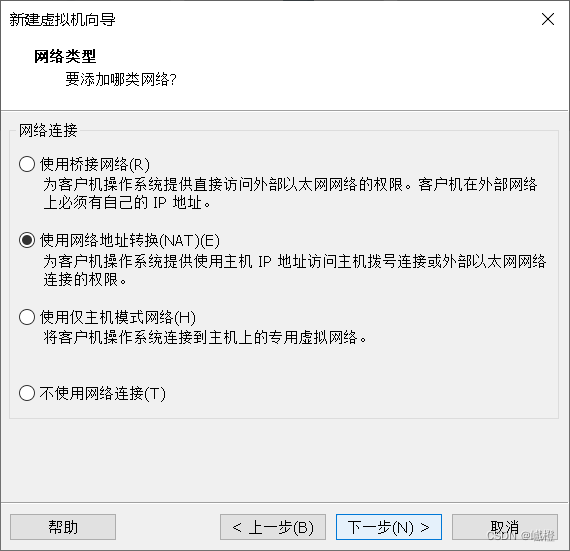
接着“下一步”
还是“下一步”
“下一步”
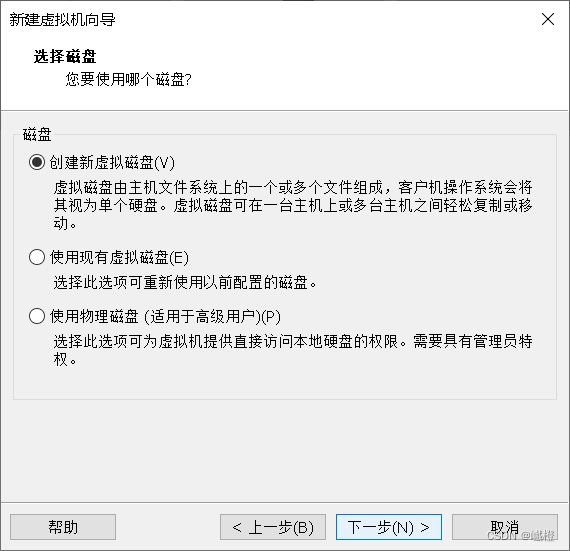
“下一步”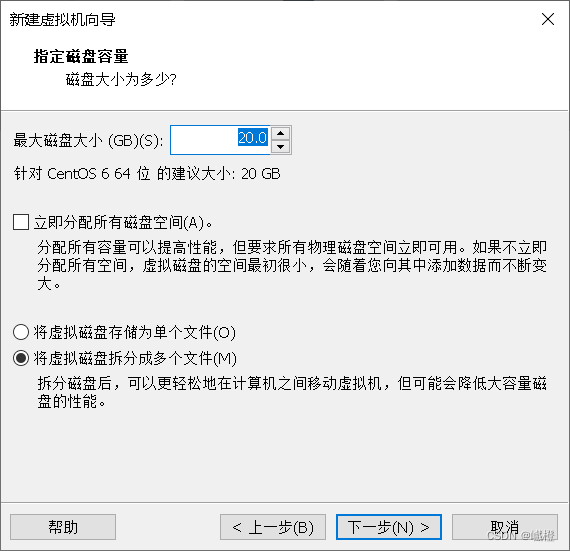
默认配置就好了,接着“下一步”
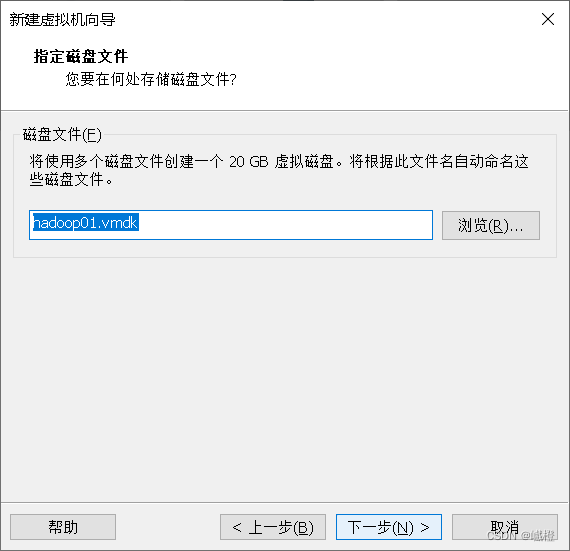
“下一步”
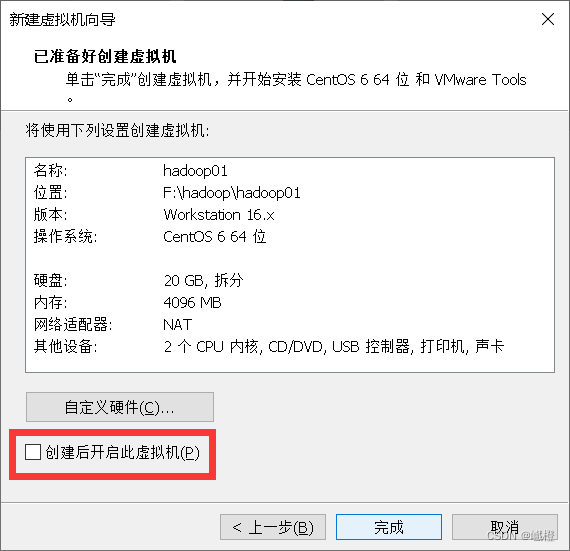
这边把“创建后开启此虚拟机”给关掉,然后点击“完成”,这样我们就有了第一台虚拟机了!
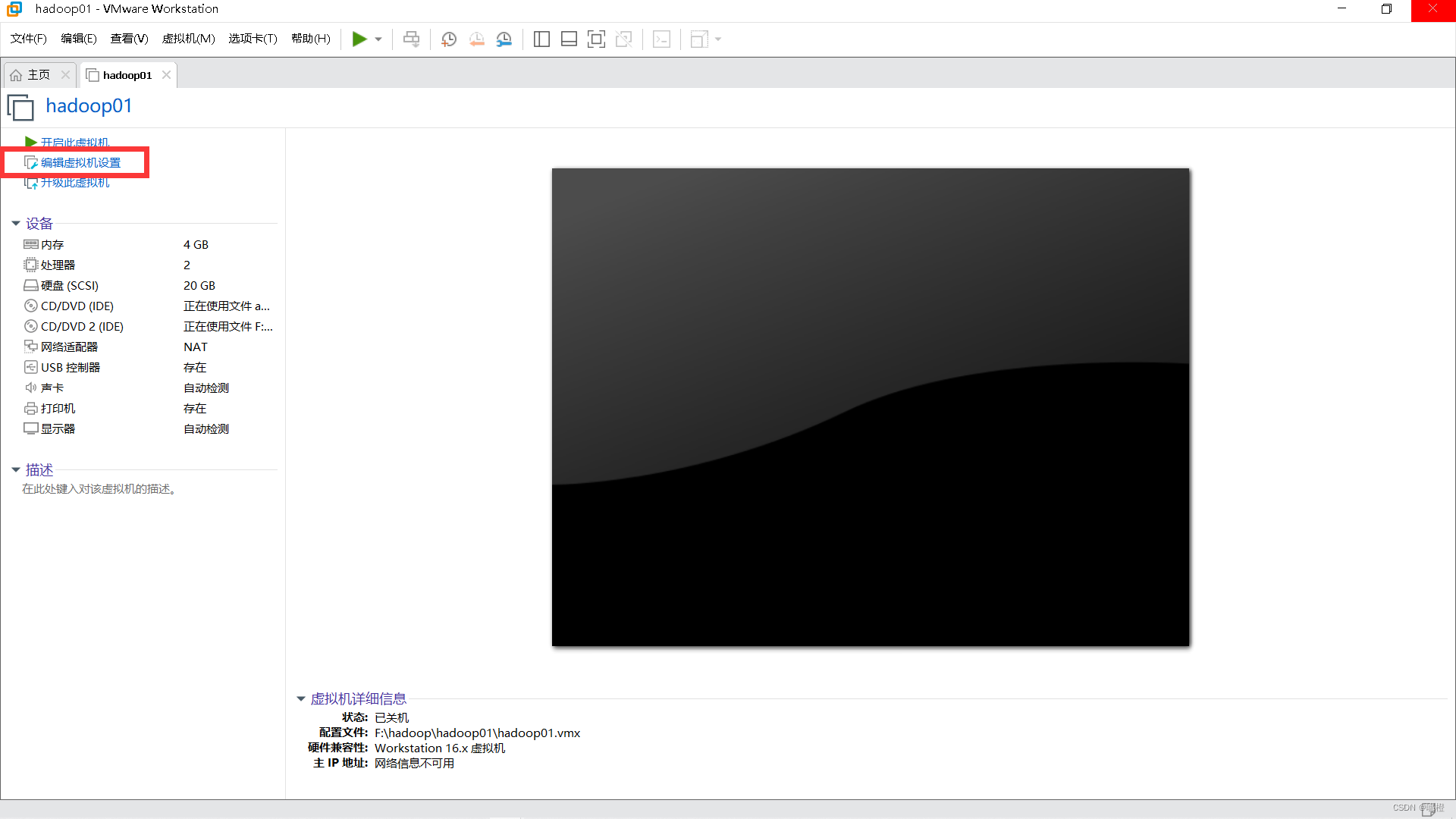
点击“编辑此虚拟机”(画了框框应该可以看见的吧)
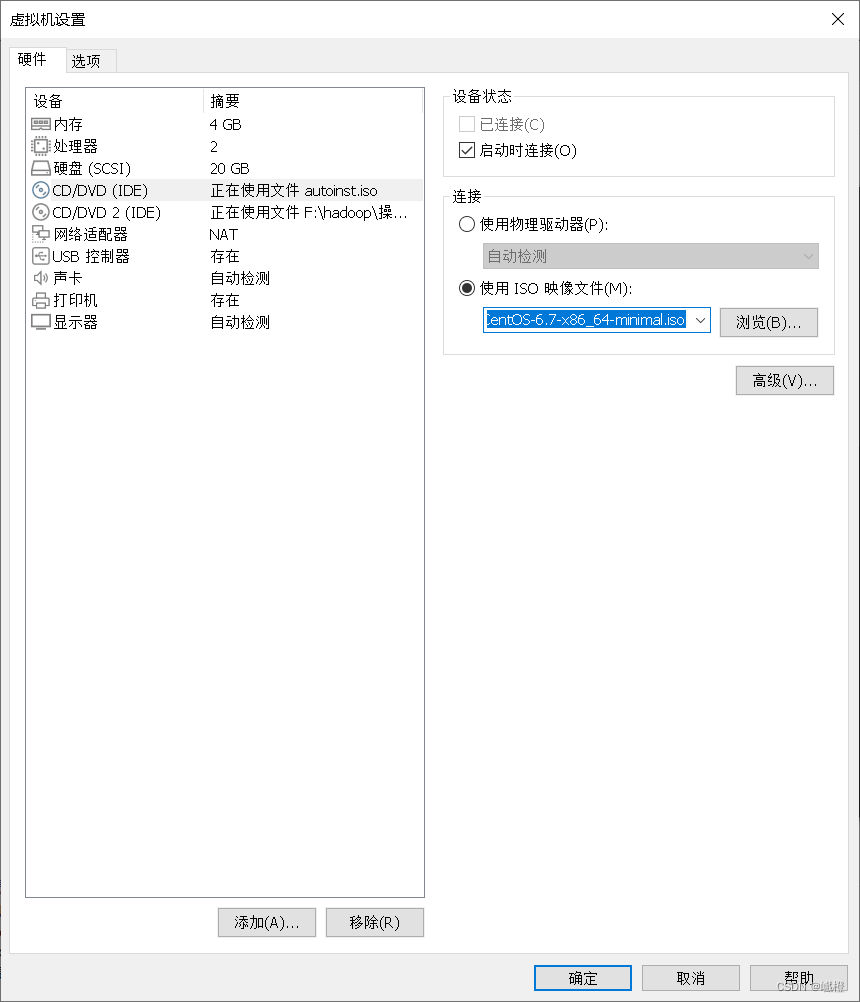
选择“CD/DVD”,将“使用iso映像文件”修改成云盘下载的那个CentOS文件,点击“确定”就可以了!现在让我们打开虚拟机
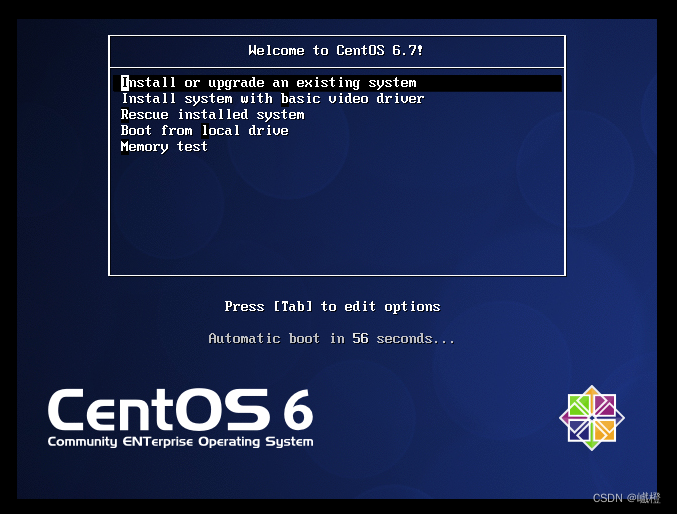
敲击“ENTER"(也就是回车),当然你得先点击一下虚拟机,宿主机的鼠标光标消失了才算是操作虚拟机,虚拟机返回宿主机为Ctrl+Alt
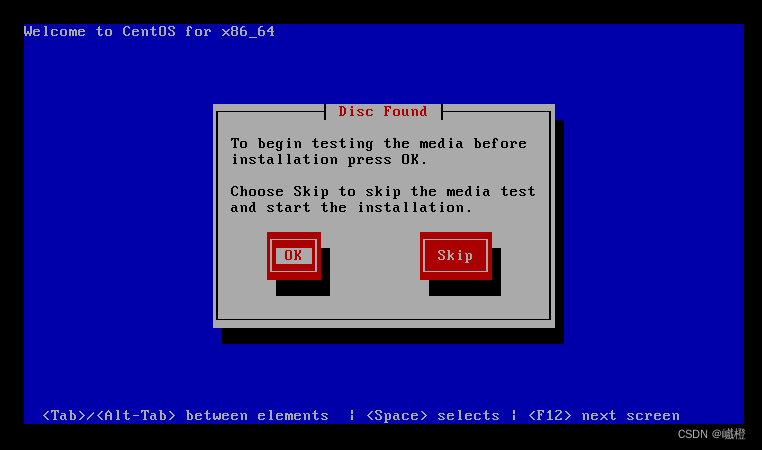
经过一丢丢时间的等待之后,出现这个界面,选择“Skip”(tap键是切换,空格键是选择),两次都选“Skip”,一顿阿巴巴之后,出现以下界面

一如既往的“next”
将语言选择为“中文”,点击“next”
这边直接“下一步”
“下一步”
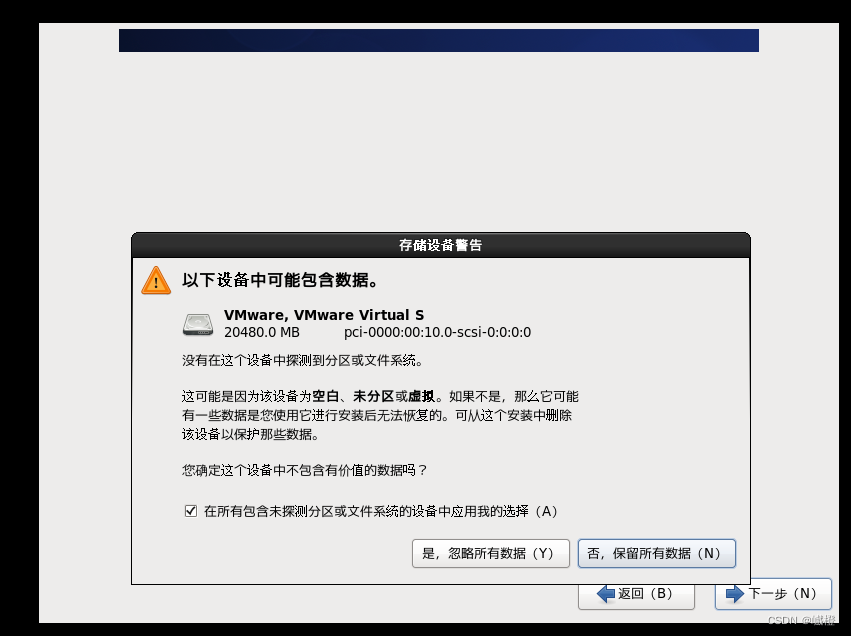
这里选择“是,忽略所有数据”,然后进入下一个页面
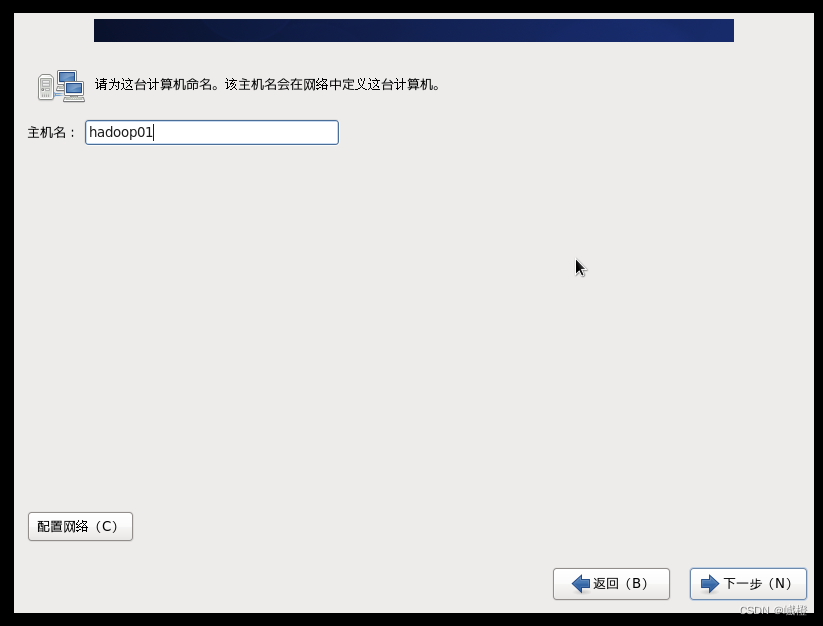
主机名就修改成“hadoop01”吧,当然也有地方是叫master,这些都没啥大事,能记住就行了。点击“下一步”
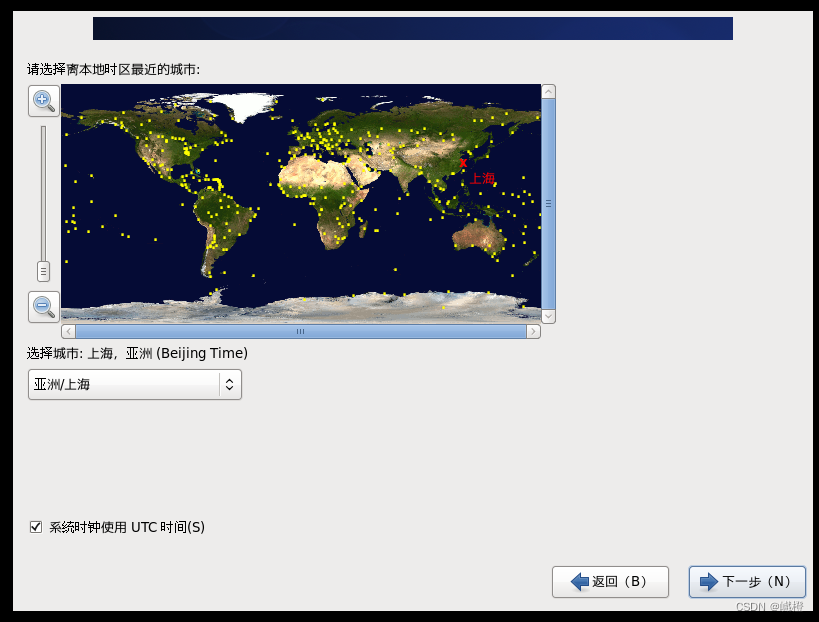
接着点击“下一步”
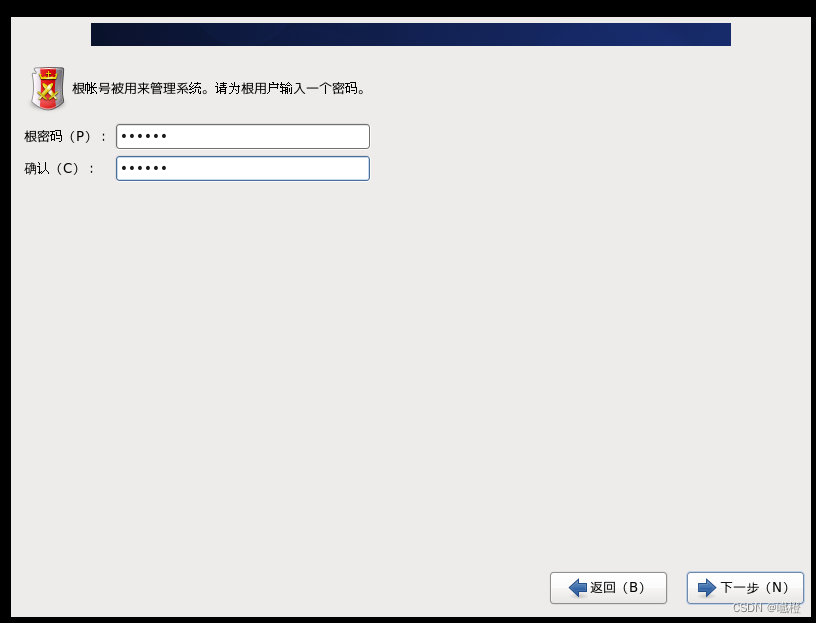
“根密码”就是看个人了,别复杂到自己记不住就行了,推荐简单一些
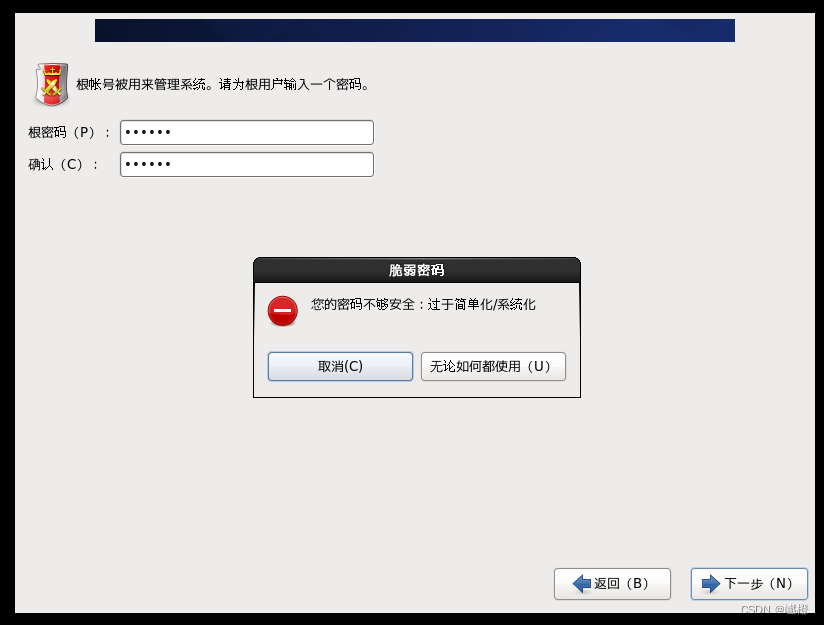
这个是密码比较简单弹出来的窗口,不能惯着它,选“无论如何都使用”,当然密码复杂得到一批的,就没有这步了
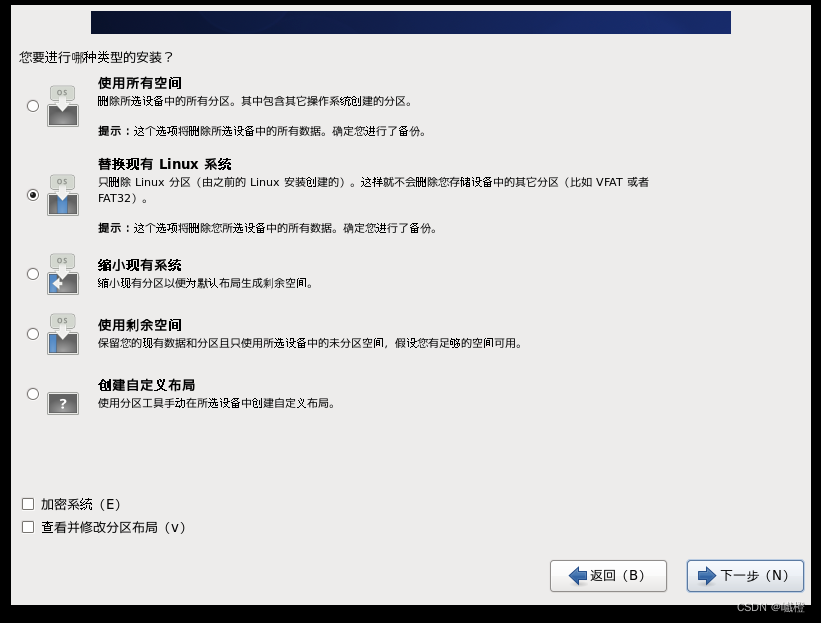
“下一步”
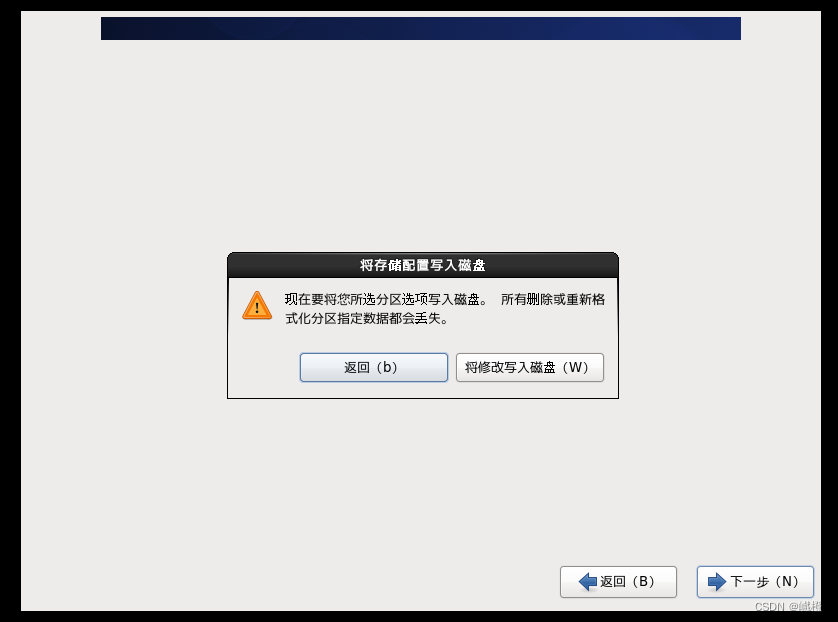
选择“将修改写入磁盘”,然后就是等待了
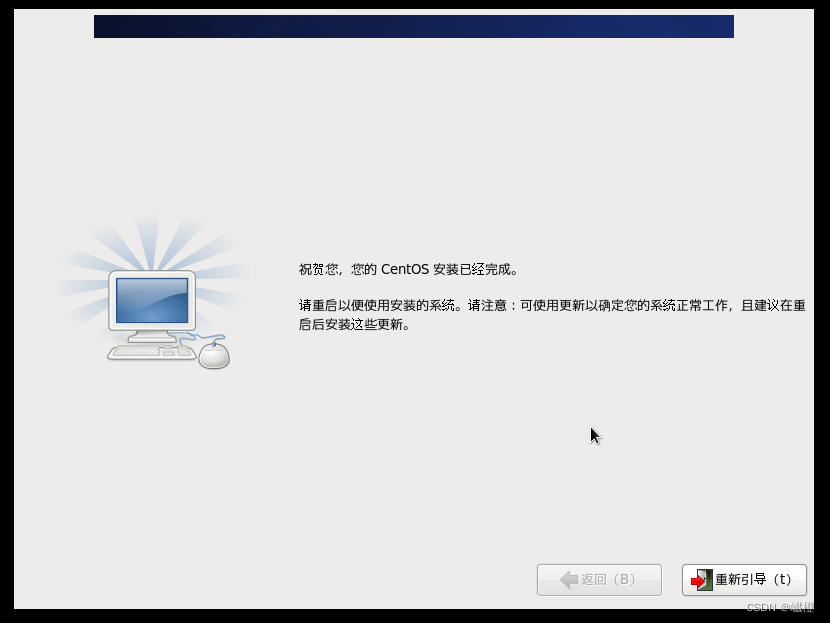
点击“重新引导”
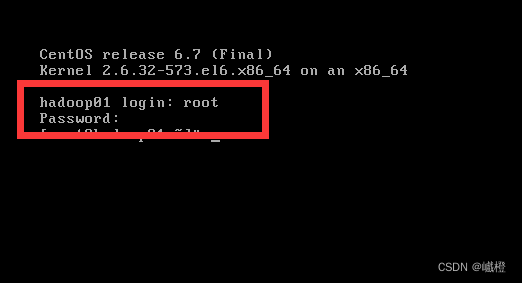
里面的login就是输入root,下面那个password就是你刚刚设置的密码(输密码的时候是看不到反应的,不要以为是键盘坏了),到这里,第一台虚拟机算是装好了(虽然还没有配置网络)
参照上述方法,再整两台出来(不推荐克隆,需要修改的一些东西,还不如重新整两台)
好了,这样三台虚拟机就齐活了
2、网络配置
在第一步里面已经有了三台虚拟机了,但是这哥三个还连不了网,下面开始对这哥三的网络进行配置
首先点vm的左上方的“编辑按钮”
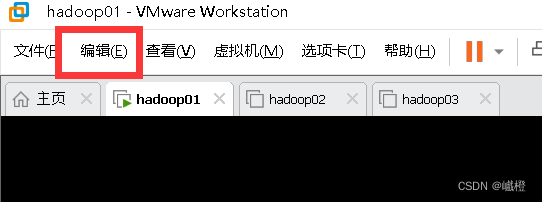
然后点击“虚拟网络编辑器”,点开“NAT”,看一下子网地址,如192.168.XXX.0,这个xxx就是接下来要用到的。

打开hadoop01,然后登陆root用户,执行代码:vi /etc/hosts进入如下界面
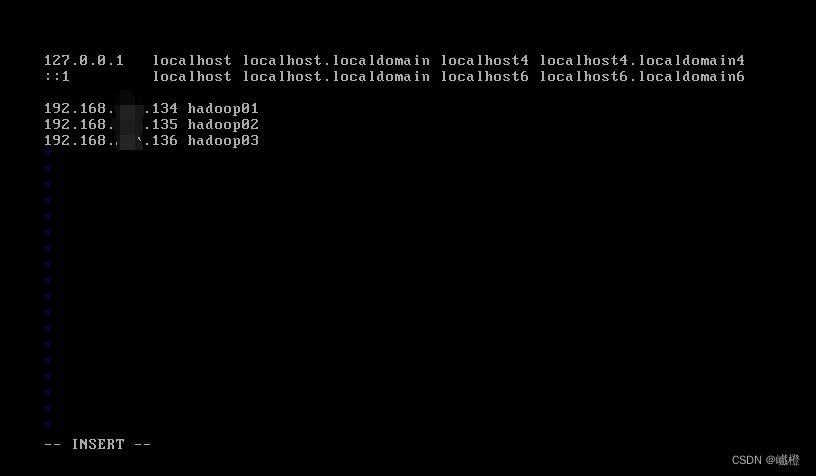
将三台虚拟机的ip加入进去,被我抹去的地方就是上面所说的XXX,根据自己的电脑进行调整,其中我对hadoop01的最后三位设置为134,hadoop02为135,hadoop03为136,总而言之,合理即可。
CentOS里面点击键盘“i”键进入“insert”模式,点击“ESC”退出“insert”模式,然后接着就是“shift+冒号键”,输入wq之后敲击回车进行保存,如果不想保存,直接q即可,加“!”则表示强制。
执行代码vi /etc/sysconfig/network-scripts/ifcfg-eth0之后,点击“i”进入insert模式,编辑内容如下:
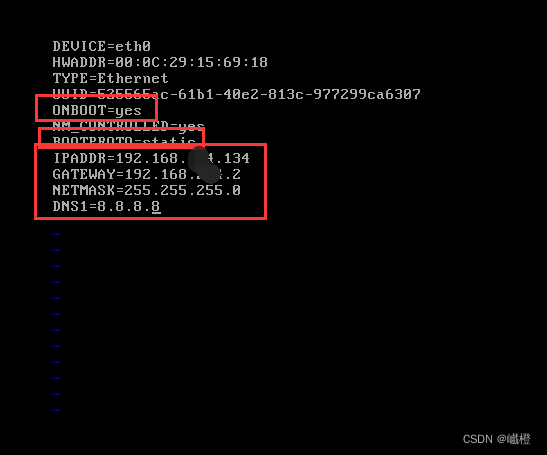
- 将ONBOOT修改为yes
- 将BOOTPROPO修改为static
- 添加IPADDR=192.168.xxx.134
- 添加GATEWAY=192.168.xxx.2
- 添加NETMASK=255.255.255.0
- 添加DNS1=8.8.8.8
所有字母都不能出错,否则会有很多问题!
配置完成之后保存,执行代码service network restart重启网卡,然后执行代码ping www.baidu.com结果如下:
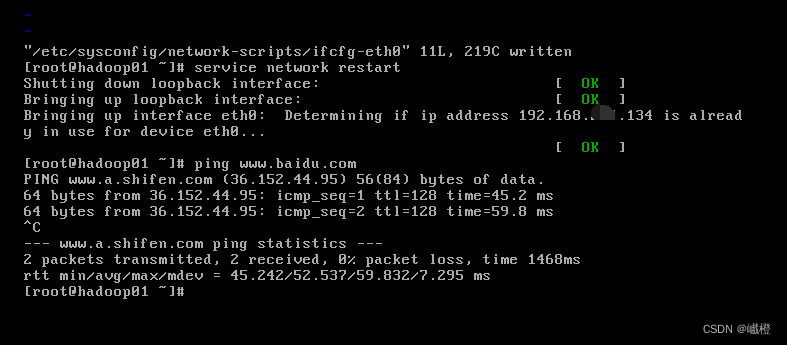
! 如果配置完成,但是还是无法ping百度的话,可以尝试
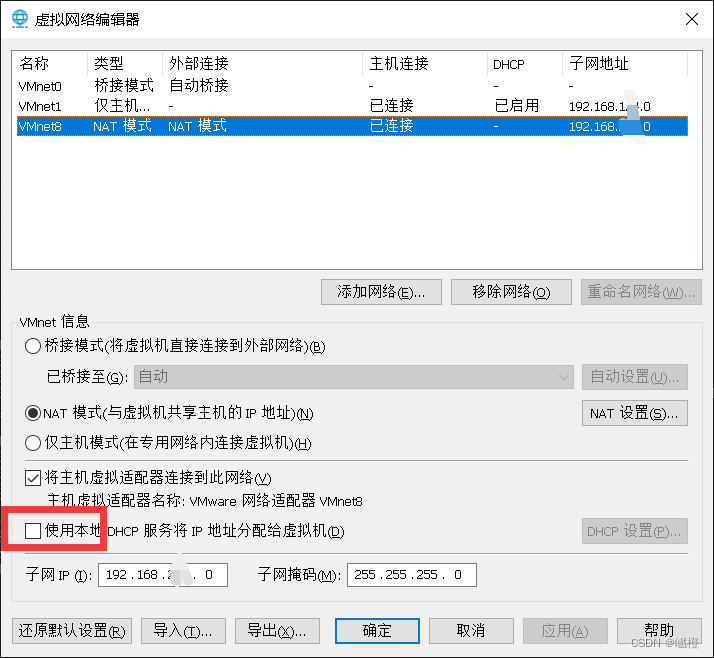
将这个勾选取消,注意是在NAT模式下!,然后“确定”
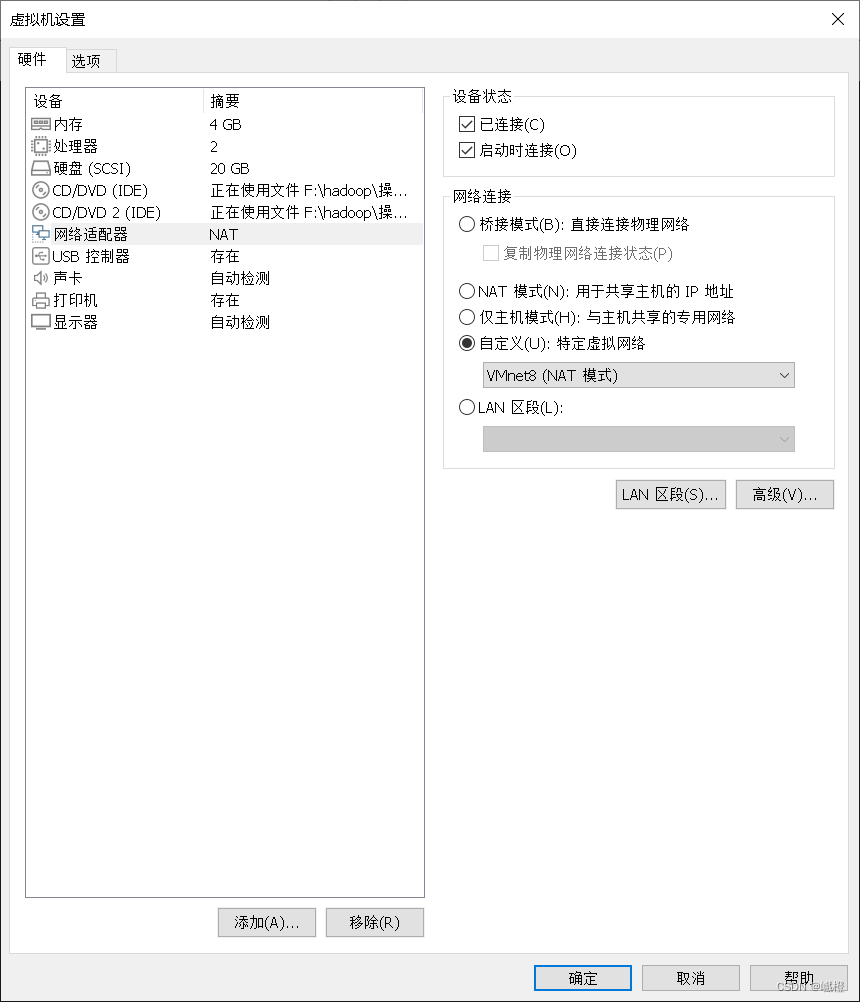
点击“网络适配器”,自定义,选择VMnet8(NAT模式)保存之后,重启虚拟机reboot!
如果在执行重启网卡服务的时候报错,则可尝试检查MAC地址是否匹配,
执行代码vi /etc/sysconfig/network-scripts/ifcfg-eth0

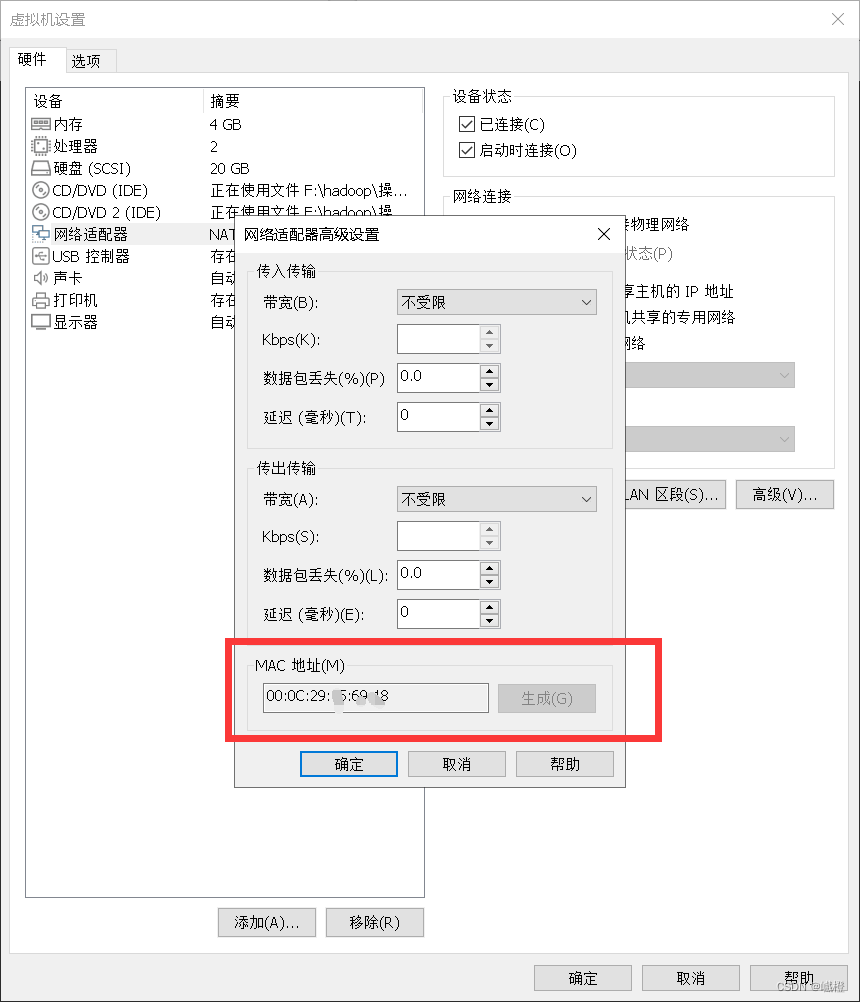
对比是否一致,如果不一致,则修改HWADDR(克隆可能会遇到这种情况)
现在就可以开始配置剩下两台虚拟机了!确保三台都可以ping通百度即可。
3、ssh配置
因为CentOS6是有ssh的,所以就不去检测这,检测那的了,直接在宿主机上操作三台虚拟机,ssh是需要三台虚拟机都联网且都是打开的。
ssh使用的是Xshell,在那个下载的文档中就有,这边就不介绍咋装了。首先打开Xshell,点击“新建”,这个里面的“名称”随意,推荐就是主机名,“主机”就是虚拟机的IP地址,确认无误之后,点击“连接”(确定也可以,大不了再多点几下)
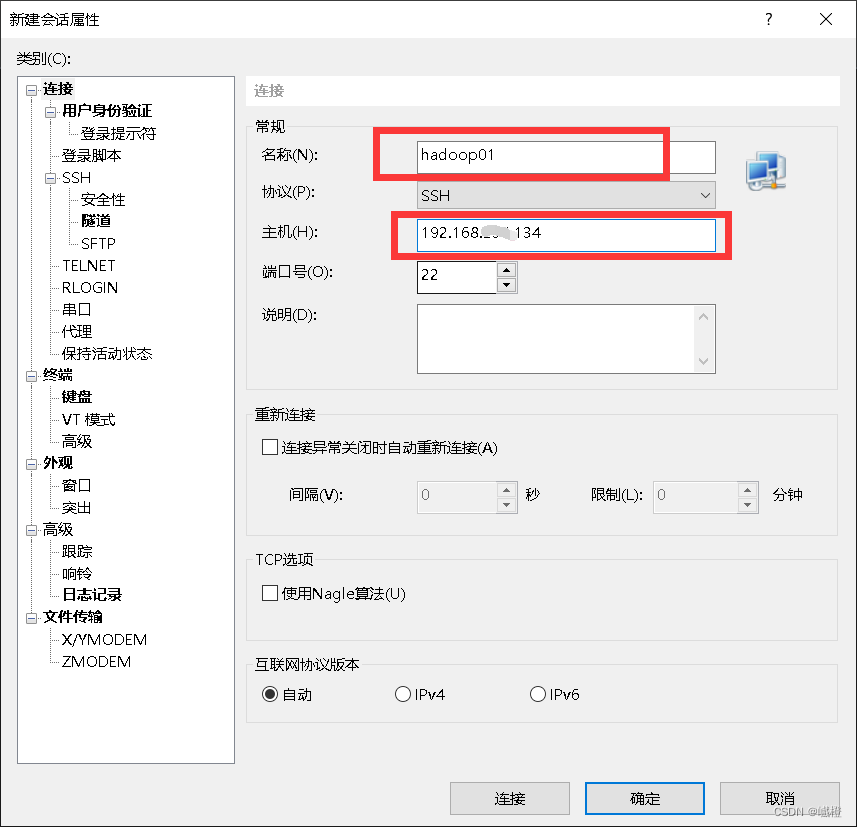
点击“接受并保存”
用户名输入“root”,勾选“记住用户名”
输入密码之后,勾选“记住密码”,点击“确定”
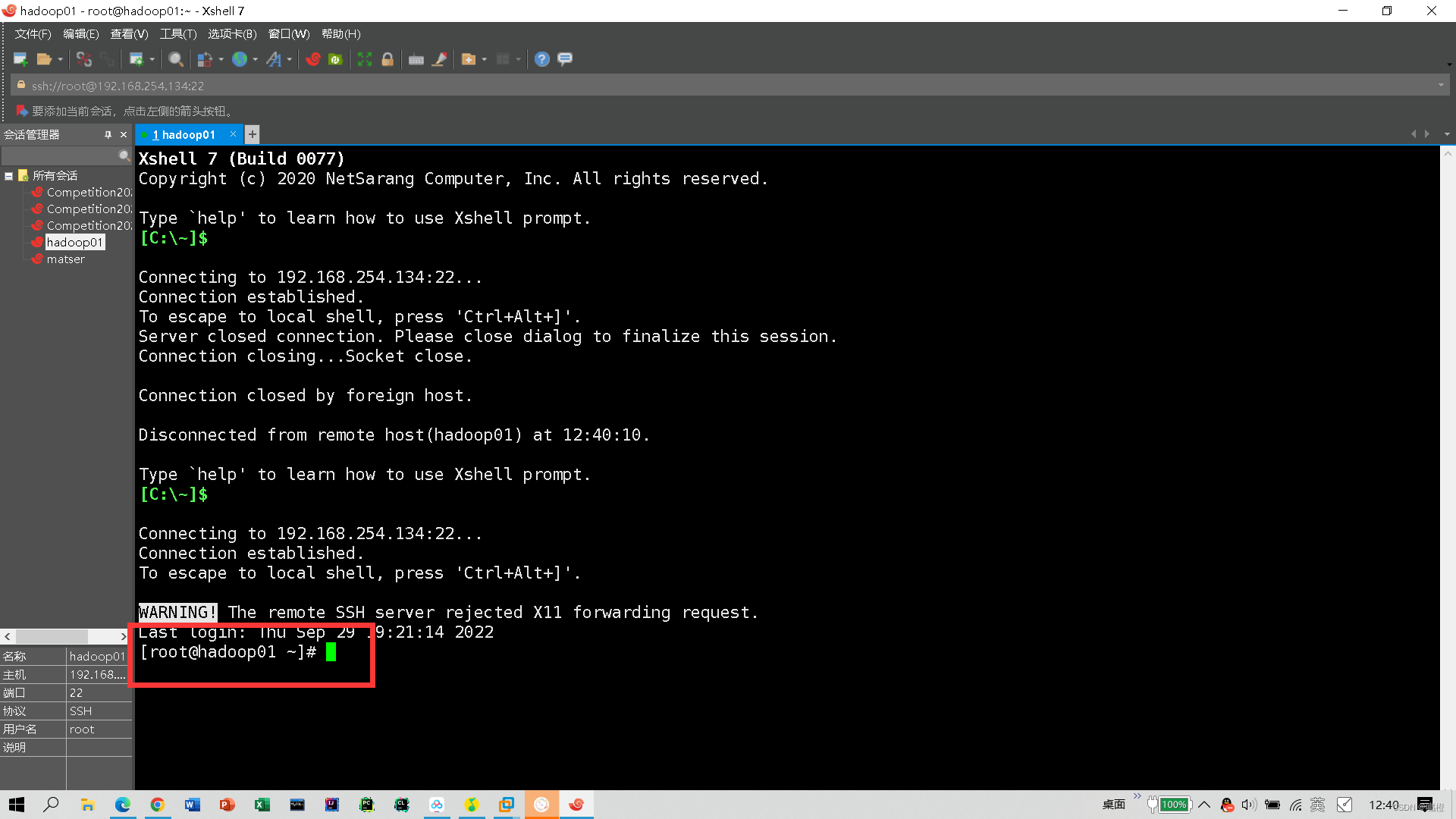
这样就算是连接成功了,用相同方法连接hadoop02、hadoop03.下面开始进行免密配置:
在hadoop01上输入ssh-keygen -t rsa连续按四下回车
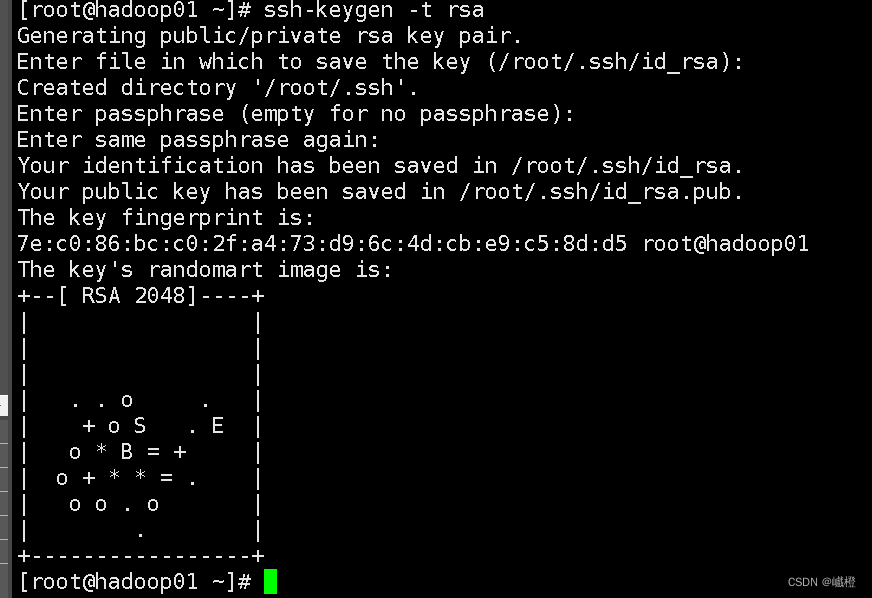
接下来执行代码
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
- 1
- 2
- 3
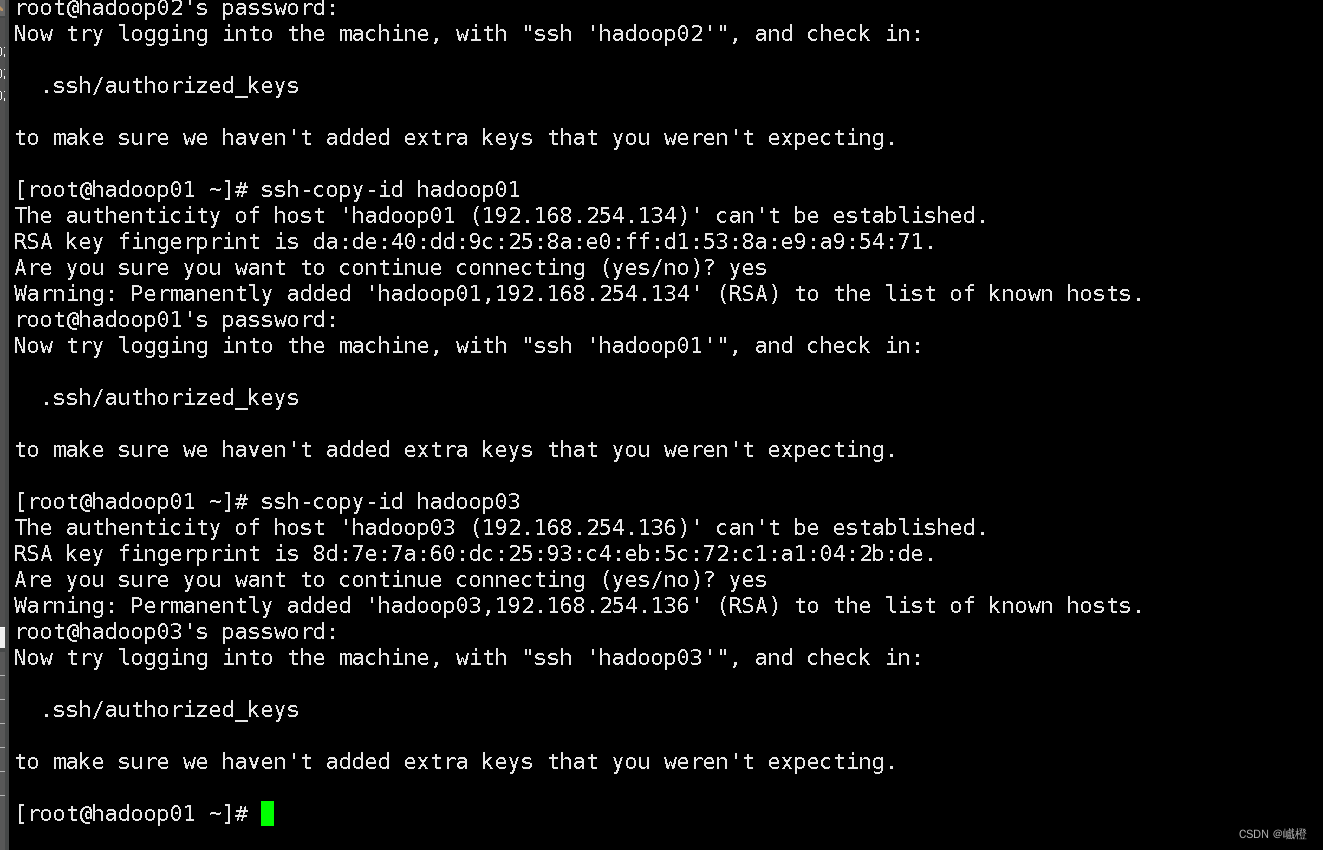
在输入“yes/no”的地方,选择“yes”,之后输入该虚拟机的密码即可完成免密配置。
4、hadoop集群搭建
(一)JDK和hadoop的安装
(1)yum镜像配置
执行如下代码:
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
vi /etc/yum.repos.d/CentOS-Base.repo
- 1
- 2
在CentOS-Base.repo中添加如下内容(镜像修改为aliyun):
[base] name=CentOS-6.10 enabled=1 failovermethod=priority baseurl=http://mirrors.aliyun.com/centos-vault/6.10/os/$basearch/ gpgcheck=1 gpgkey=http://mirrors.aliyun.com/centos-vault/RPM-GPG-KEY-CentOS-6 [updates] name=CentOS-6.10 enabled=1 failovermethod=priority baseurl=http://mirrors.aliyun.com/centos-vault/6.10/updates/$basearch/ gpgcheck=1 gpgkey=http://mirrors.aliyun.com/centos-vault/RPM-GPG-KEY-CentOS-6 [extras] name=CentOS-6.10 enabled=1 failovermethod=priority baseurl=http://mirrors.aliyun.com/centos-vault/6.10/extras/$basearch/ gpgcheck=1 gpgkey=http://mirrors.aliyun.com/centos-vault/RPM-GPG-KEY-CentOS-6

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
注意:粘贴之前先进入insert模式!
(2)上传压缩包rz
执行代码yum install lrzsz -y
在先执行cd /再执行mkdir export创建export文件夹,再执行代码cd export进入export文件夹,再通过代码mkdir servers创建servers文件夹,最后通过cd servers进入servers文件夹,执行代码rz(如果乱码,可执行rz -be),上传的文件就是jdk
执行代码tar -zxvf jdk-8u161-linux-x64.tar.gz解压安装包
执行代码vi /etc/profile在末尾添加jdk的环境变量配置
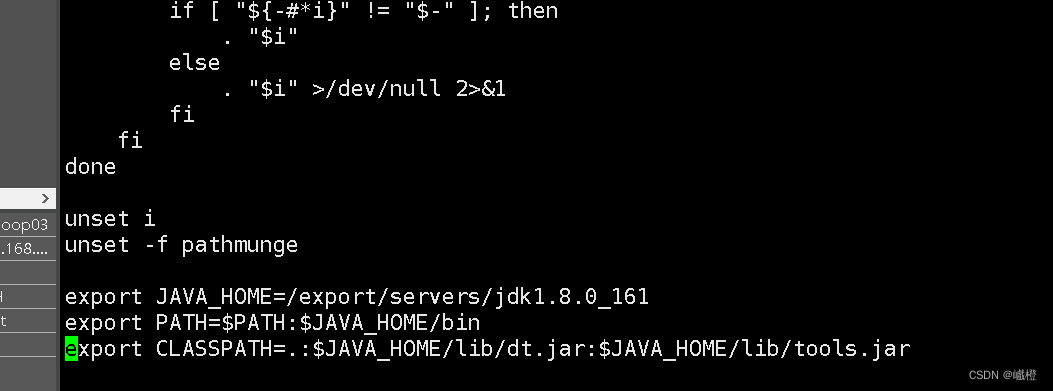
环境变量:
export JAVA_HOME=/export/servers/jdk1.8.0_161
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
- 1
- 2
- 3
保存退出之后执行source /etc/profile保存环境变量,执行java -version检查是否配置成功

执行rz上传hadoop-2.7.4的压缩包(servers)目录下,执行tar -zxvf hadoop-2.7.4.tar.gz进行解压
执行vi /etc/profile,在Java环境变量配置下面添加hadoop环境变量配置
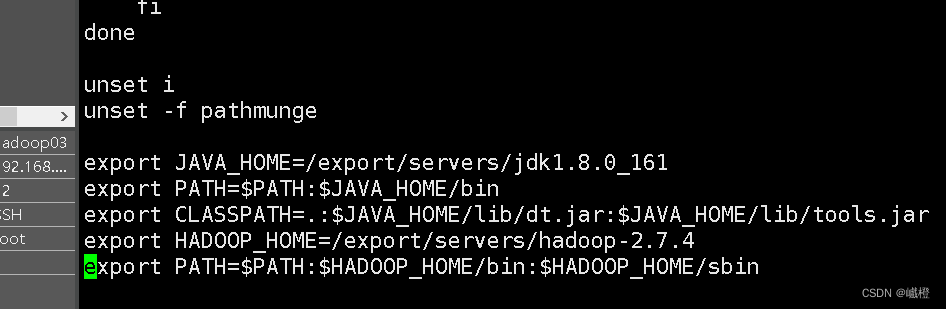
环境变量配置
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 1
- 2
执行source /etc/profile保存环境变量配置,执行hadoop version检查一下是否安装成功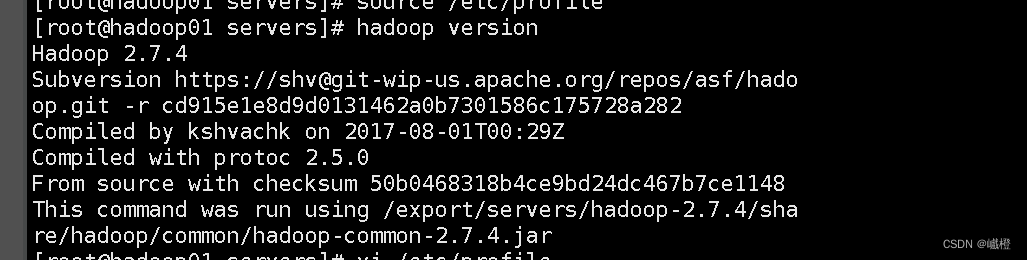
(二)hadoop结点配置
(1)配置文件
执行vi /export/servers/hadoop-2.7.4/etc/hadoop/hadoop-env.sh
修改export JAVA_HOME 为jdk的位置,然后保存退出

执行cd /export/servers/hadoop-2.7.4/etc/hadoop/
执行vi core-site.xml修改里面的内容为
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!--用于设置Hadoop的文件系统,由URL指定--> <!--指定namenode的地址--> <property> <name>fs.defaultFS</name> <!--用于指定namenode地址在hadoop01机器上--> <value>hdfs://hadoop01:9000</value> </property> <!--配置hadoop的临时目录,默认/tmp/hadoop-${user.name}--> <!--用来指定使用hadoop时产生文件的存放目录--> <property> <name>hadoop.tmp.dir</name> <value>/export/servers/hadoop-2.7.4/tmp</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
执行vi hdfs-site.xml,修改里面的内容为
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!--指定hdfs保存数据的副本数量--> <!--指定HDFS副本的数量--> <property> <name>dfs.replication</name> <value>3</value> </property> <!--指定hdfs中datanode的存储位置--> <!--secondary namenode所在主机的IP和端口--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop02:50090</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
执行cp mapred-site.xml.template mapred-site.xml
执行vi mapred-site.xml,修改内容为
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!--告诉hadoop以后MR(Map/Reduce)运行在YARN上--> <!--指定MapReduce运行时框架,这里指定在YARN上,默认是local--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
执行vi yarn-site.xml,修改内容为
<?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <!--指定YARN集群的管理者(ResourceManager)的地址--> <!--指定Yarn的老大(ResourceManager)的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop01</value> </property> <!--nomenodeManager获取数据的方式是shuffle--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>2048</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>1024</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>4</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42

每次执行完要输入wq对内容进行保存
执行vi slaves进入slaves的编辑,编辑内容如下(slaves在hadoop目录之下)
输入以上内容之后wq进行保存
(2)分发给子节点
scp -r /export/ hadoop02:/
scp -r /export/ hadoop03:/
scp /etc/profile hadoop02:/etc/profile
scp /etc/profile hadoop03:/etc/profile
- 1
- 2
- 3
- 4
 执行完这两个操作之后,需通过
执行完这两个操作之后,需通过ssh hadoop02 和ssh hadoop03分别进入hadoop02和hadoop03执行source /etc/profile操作
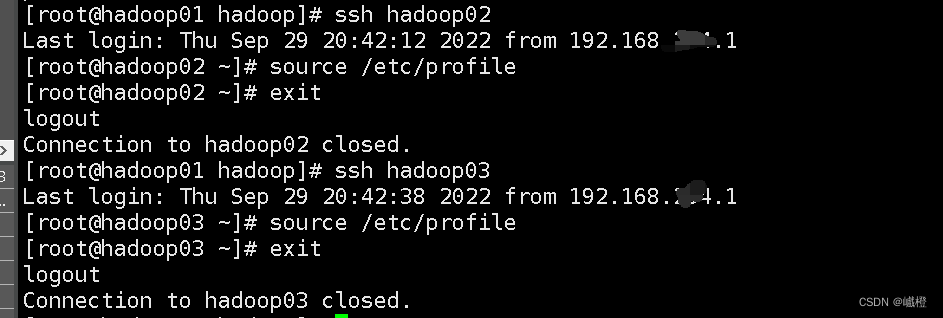
当然也可以使用Java -version和hadoop version验证一下有没有配置好(当然我验证了一下我自己配置的)
(3)hadoop集群测试
在主节点执行hadoop namenode -format对hadoop集群进行格式化(格式化次数不可太多)
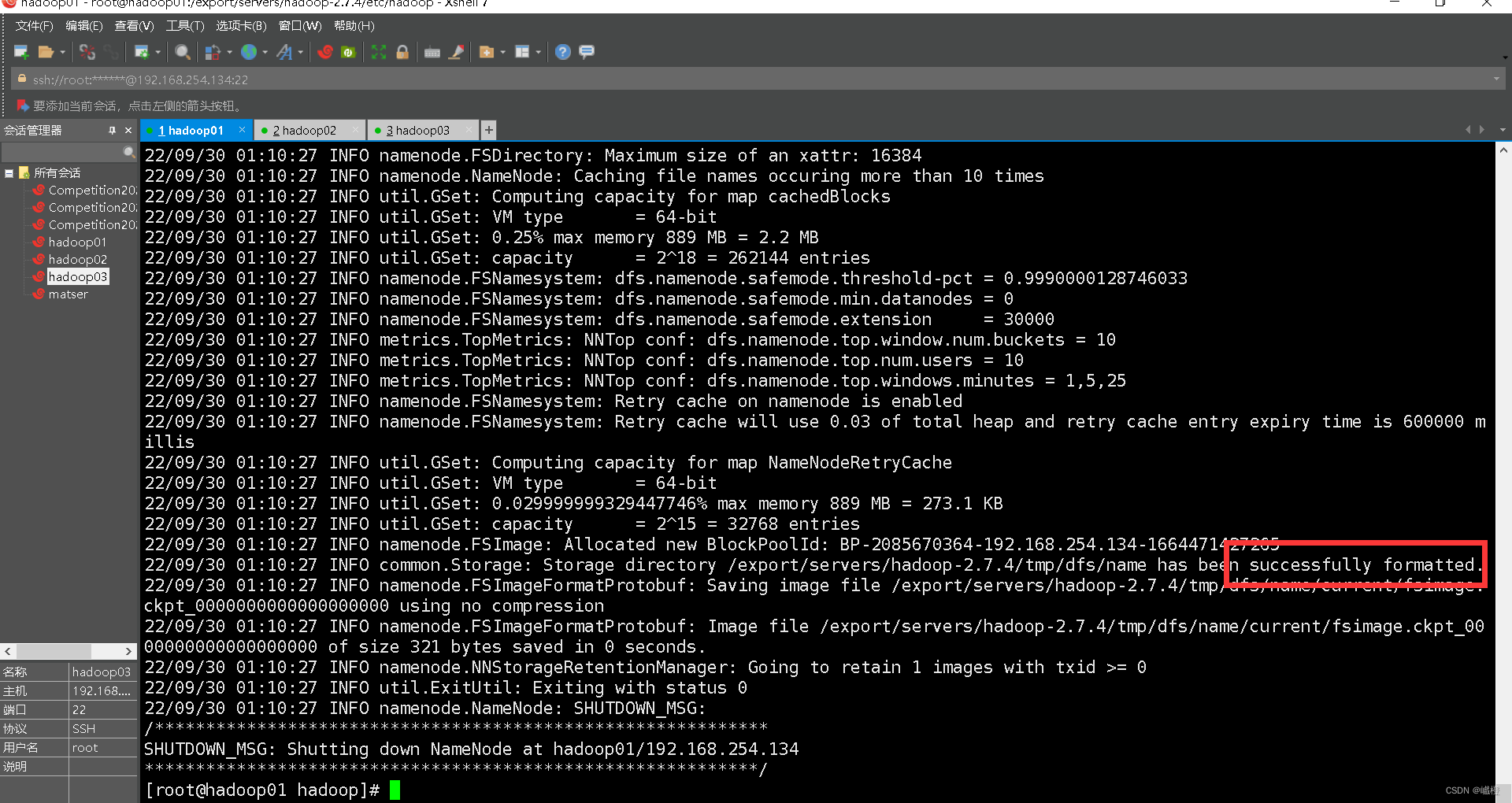
出现了“successfully formatted”说明格式化成功了
接下来启动hadoop,一键启动代码start-all.sh
在主节点(hadoop01)执行jps
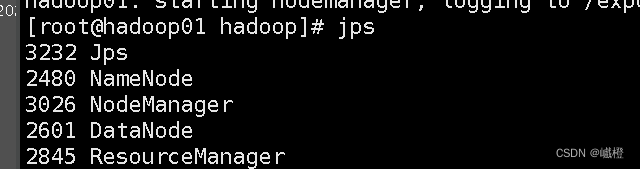
在子节点(hadoop02)执行jps
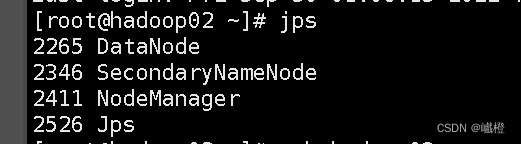
在子节点(hadoop03)执行jps

出现以上内容则说明配置成功,最后执行
service iptables stop #关闭防火墙
chkconfig iptables off #关闭开机启动(所有节点)
- 1
- 2
现在就可以在宿主机浏览器用主节点ip地址+50070/8088访问hadoop集群了
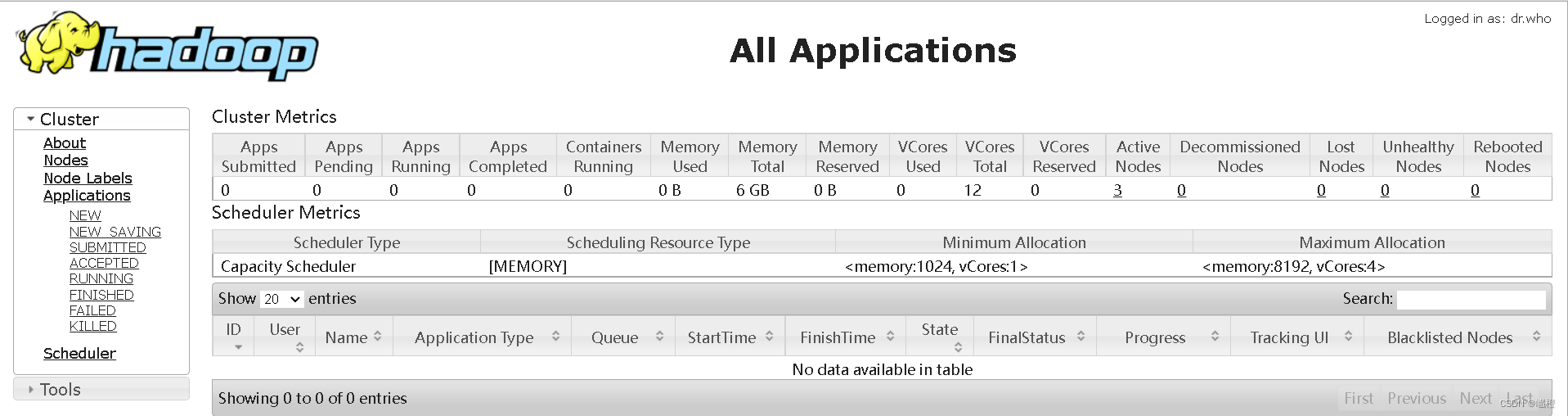
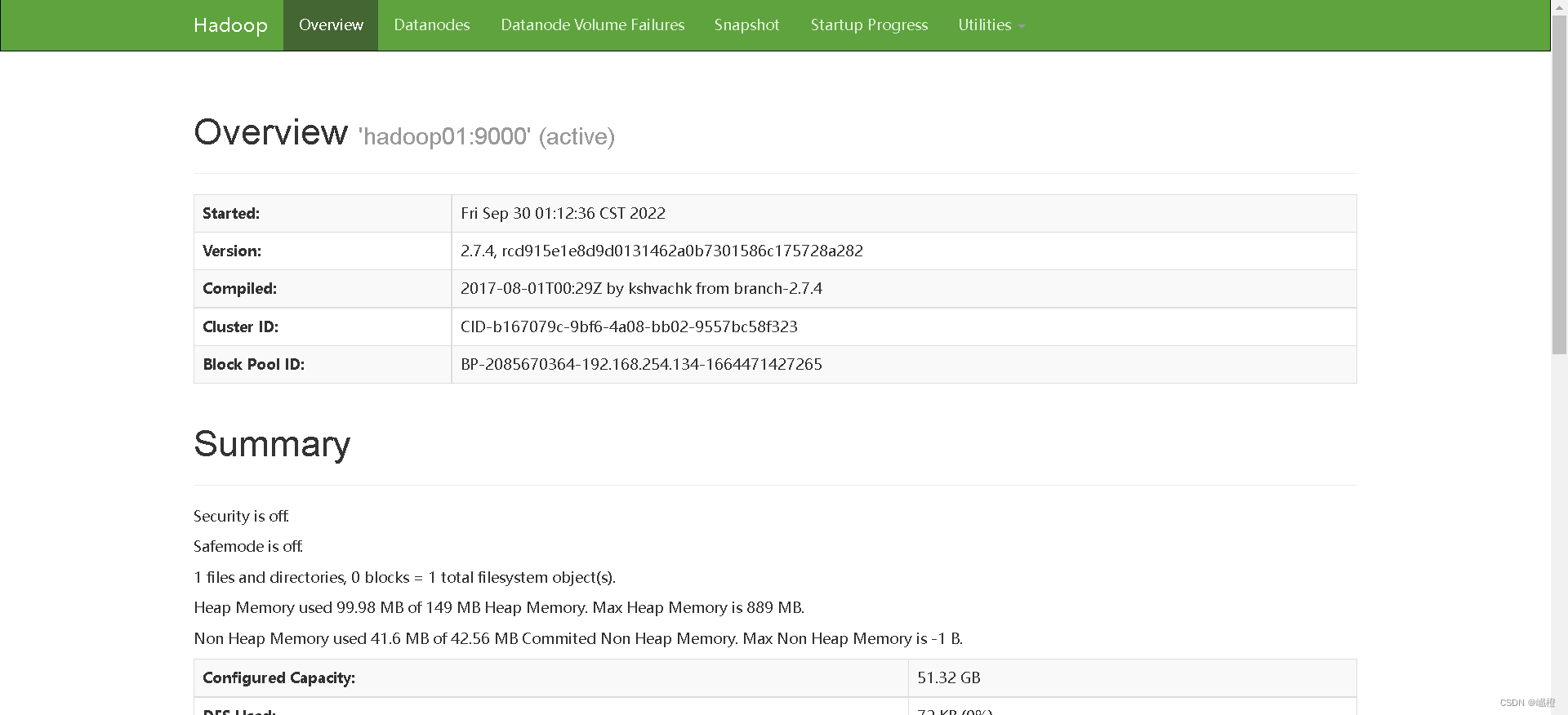
最后执行stop-all.sh关闭集群
到此Hadoop集群就搭建好了!
配置过程中会遇到的一些问题
1、Java和hadoop配置不成功
解决办法:可以试着将/export/servers/jdk1.8.0_161修改为/root/export/servers/jdk1.8.0_161,将/export/servers/hadoop-2.7.4修改为/root/export/servers/hadoop-2.7.4(根据自己的路径配置即可)
大概率是环境变量配置错误了。
2、rz上传之后无法解压
解决办法:我遇到的无法解压就是没有.gz后缀,可以试着在宿主机中打开拓展名显示,试着再次上传,确保有.gz后缀。
3、hadoop集群启动之后没有namenode
解决办法:停止集群之后,进入hadoop-2.7.4路径之下的tmp文件夹(cd /export/servers/hadoop-2.7.4/tmp/),执行rm -rf *删除所有内容(三个节点都要进行),执行完之后,重新在主节点进行格式化。
4、找不到start-all.sh指令
解决办法:进入hadoop-2.7.4路径下的sbin文件夹(cd /export/servers/hadoop-2.7.4/sbin)执行操作sh start-all.sh即可进行。
5、scp分发文件不太正确
解决办法:给hadoop02和hadoop03的不正确文件夹删除,重新分发。
6、hadoop集群格式化失败
解决办法:根据其第一个报错内容开始寻找原因,大概率是配置文件有错,如若显示“没有文件”,则cd至目录或者环境检查一下。
7、hadoop集群启动之后子节点没有datanode
解决办法,停止集群之后,进入hadoop-2.7.4路径之下的tmp文件夹(cd /export/servers/hadoop-2.7.4/tmp/),执行rm -rf *删除所有内容(两个个节点都要进行),执行完之后,重新在主节点进行格式化,在输入y/n的时候,输入n

