
- 1java计算机毕业设计基于安卓Android的音乐论坛APP(源码+系统+mysql数据库+Lw文档)_android音乐app项目源码
- 2DICOM之DCMTK开源库类
- 3Android多线程_android多线程应用程序中,出现多个线程同时访问共享变量的现android应用程序中,子线程的信
- 4奶茶点餐|奶茶店自助点餐系统|基于微信小程序的饮品点单系统的设计与实现(源码+数据库+文档)_奶茶店微信小程序的源代码运行结果图片
- 5使用cloudflare为你的WordPress网站加速!_wordpress使用cloudflare dns网站打不开
- 6【随笔】深度学习的数据增强还分在线和离线?_数据增强策略能同时进行在线增强和离线增强吗
- 7工业互联网+安全生产背景下 “云+边+端”协同智能视频分析系统该如何搭建_工业互联网协同智能感知
- 8鸿蒙Harmony应用开发—ArkTS声明式开发(容器组件:UIExtensionComponent (系统接口))
- 9python selenuim TypeError: WebDriver.__init__() got an unexpected keyword argument ‘chrome_options‘
- 10解决使用lambda表达式BigDecimal运算符不能被识别的问题_lamda表达式进行decical运算不行
CNN卷积神经网络学习笔记(特征提取)_cnn特征提取
赞
踩
一、CNN卷积神经网络可以干的事情:
检测任务

分类和检索:

超分辨率重构:

字体识别、人脸识别、医学任务、自动驾驶任务等
总结:特征提取相关
二、卷积神经网络的整体架构:
(1)输入层
H*W*C的三维数据
(2)卷积层(提取特征)
权重参数矩阵 filterW
当前区域数据 :将输入数据划分成小区域,对每个区域进行特征提取
滑动窗口步长:
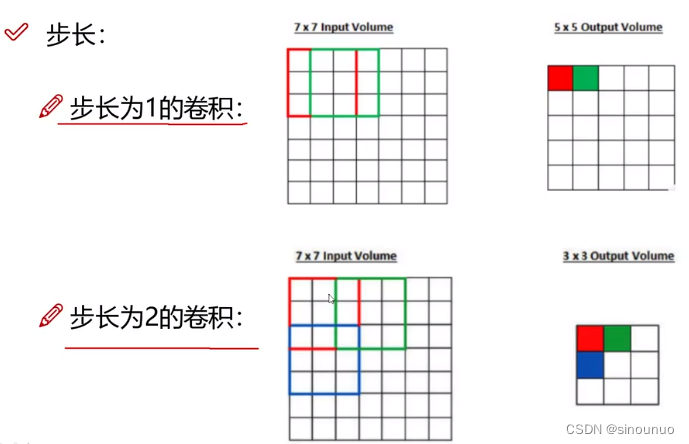
卷积核尺寸:
H*W,一般是3*3
边缘填充:
边缘的点被提取次数少,所以给边界padding一圈之后,让边缘点提取次数增多,一定程度上弥补了边界特征缺失的问题。一般都padding0,让增加值对结果不产生影响。
偏置项
在权重矩阵和区域计算内积之后,加上偏置项才是最后的特征图数据
卷积核个数:
有几个卷积核,就得到几个特征图

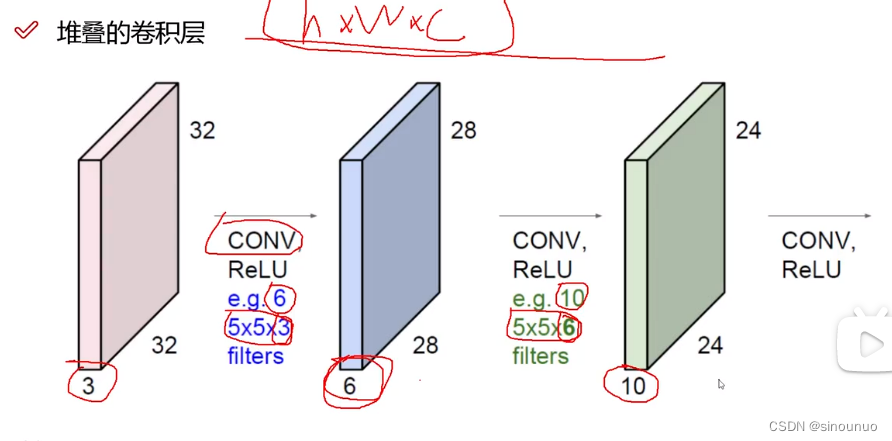

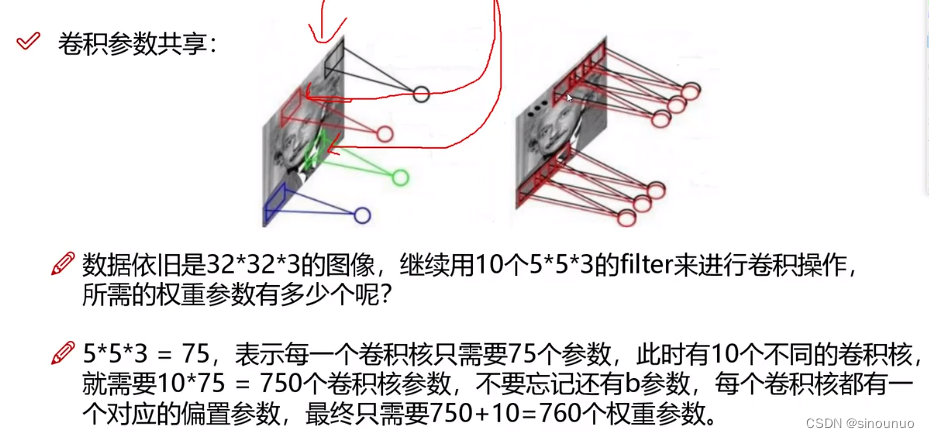
用同样一组卷积核对每个区域进行特征提取
对每个通道进行卷积,最后结果加和
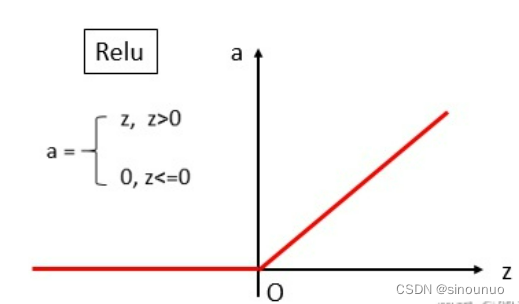
(3)Relu:
relu函数是常见的激活函数中的一种,表达形式如下:
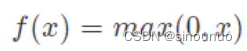
Relu其实就是个取最大值的函数。
如果不用激活函数,在这种情况下每一层输出都是上层输入的线性函数。容易验证,无论神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。因此引入非线性函数作为激活函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入。
引入ReLu的原因
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现 梯度消失 的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练。
第三,ReLu会使一部分神经元的输出为0,这样就造成了 网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
Relu函数的优势
1、没有饱和区,不存在梯度消失问题,防止梯度弥散;
2、稀疏性;
3、没有复杂的指数运算,计算简单、效率提高;
4、实际收敛速度较快,比 Sigmoid/tanh 快很多;
5、比 Sigmoid 更符合生物学神经激活机制。
(4)池化层(压缩,下采样)
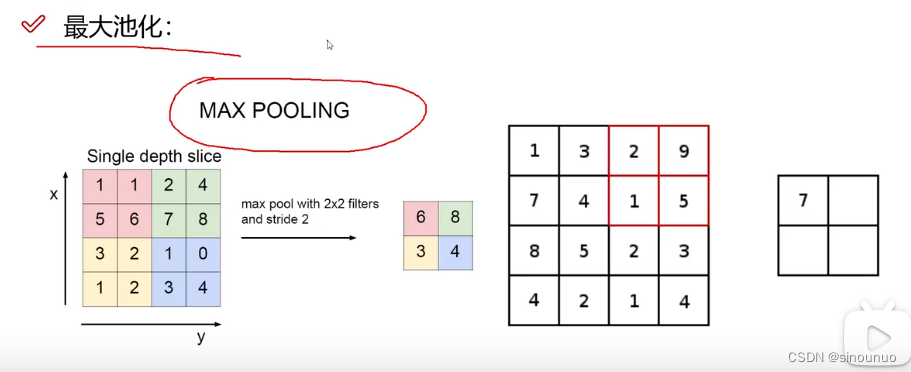
最大池化的效果一般都比平均池化的效果好,所以现在一般都使用最大池化
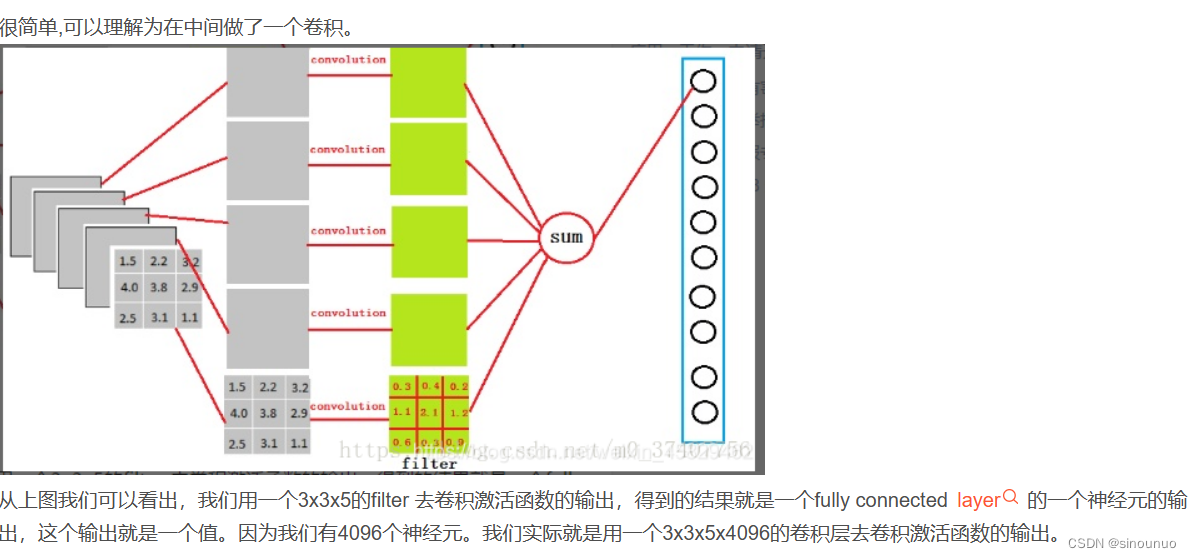
(5)全连接层
全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”(下面会讲到这个分布式特征)映射到样本标记空间的作用。在实际使用中,全连接层可由卷积操作实现:
对前层是全连接的全连接层可以转化为卷积核为1x1的卷积;而前层是卷积层的全连接层可以转化为卷积核为hw的全局卷积,hw分别为前层卷积结果的高和宽。
全连接的核心操作就是矩阵向量乘积 y = Wx
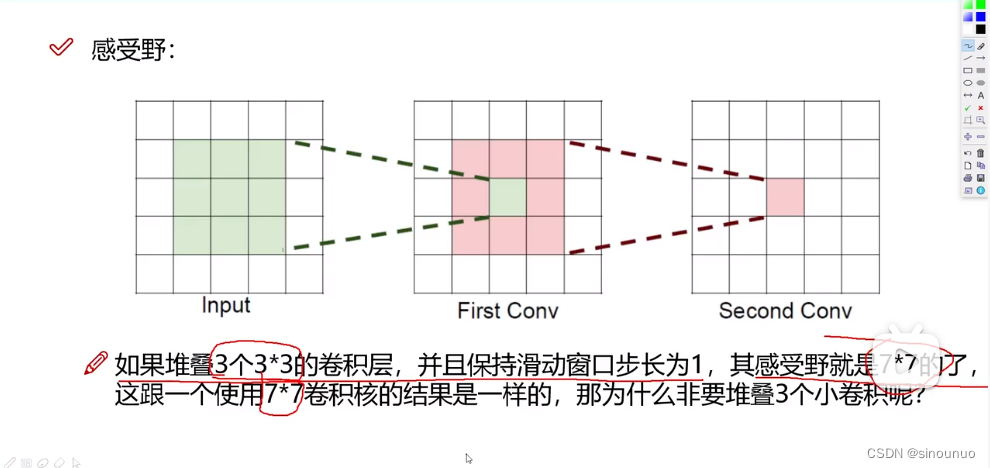
(6)感受野

三、几个经典的卷积神经网络:
(1)VGG-16
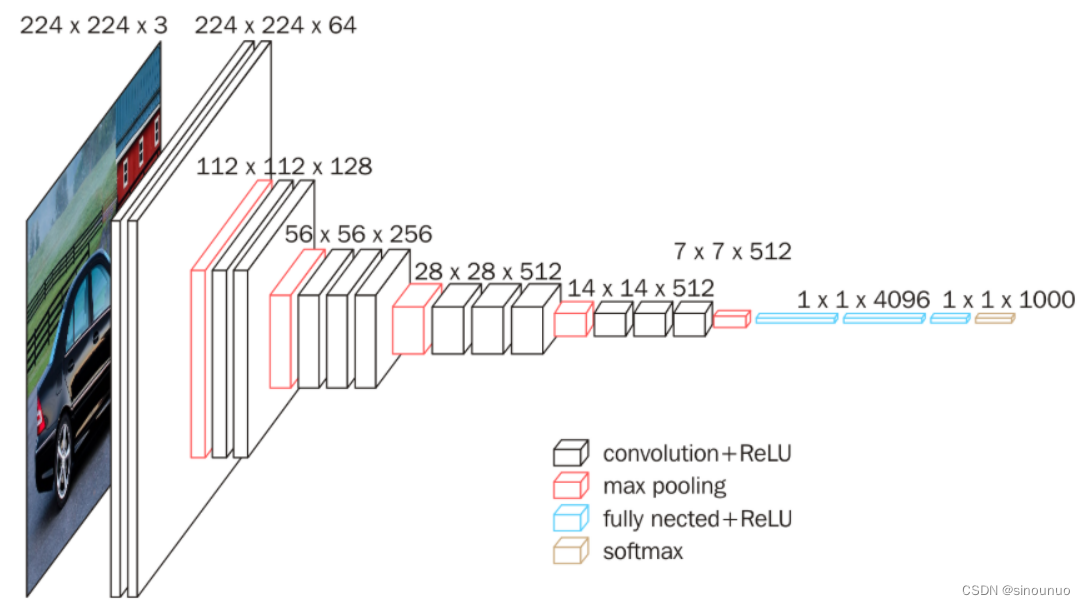
vgg16总共有16层,13个卷积层和3个全连接层,第一次经过64个卷积核的两次卷积后,采用一次pooling,第二次经过两次128个卷积核卷积后,再采用pooling,再重复两次三个512个卷积核卷积后,再pooling,最后经过三次全连接。
VGG16的卷积核
conv3-xxx:卷积层全部都是3*3的卷积核,用上图中conv3-xxx表示,xxx表示通道数。其步长为1,用padding=same填充。池化层的池化核为2*2
设置padding的属性值是 SAME ,则表示【输出层尺寸 = 输入层尺寸】
input(224x224 RGB image) :指的是输入图片大小为224*244的彩色图像,通道为3,即224*224*3;
maxpool :是指最大池化,在vgg16中,pooling采用的是2*2的最大池化方法;
FC-4096 :指的是全连接层中有4096个节点,同样地,FC-1000为该层全连接层有1000个节点;
padding:指的是对矩阵在外边填充n圈,padding=1即填充1圈,5X5大小的矩阵,填充一圈后变成7X7大小;
最后补充,vgg16每层卷积的滑动步长stride=1,padding=1,卷积核大小为333;
卷积计算
1)输入图像尺寸为224x224x3,经64个通道为3的3x3的卷积核,步长为1,padding=same填充,卷积两次,再经ReLU激活,输出的尺寸大小为224x224x64
2)经max pooling(最大化池化),滤波器为2x2,步长为2,图像尺寸减半,池化后的尺寸变为112x112x64
3)经128个3x3的卷积核,两次卷积,ReLU激活,尺寸变为112x112x128
4)max pooling池化,尺寸变为56x56x128
5)经256个3x3的卷积核,三次卷积,ReLU激活,尺寸变为56x56x256
6)max pooling池化,尺寸变为28x28x256
7)经512个3x3的卷积核,三次卷积,ReLU激活,尺寸变为28x28x512
8)max pooling池化,尺寸变为14x14x512
9)经512个3x3的卷积核,三次卷积,ReLU,尺寸变为14x14x512
10)max pooling池化,尺寸变为7x7x512
11)然后Flatten(),将数据拉平成向量,变成一维51277=25088。
11)再经过两层1x1x4096,一层1x1x1000的全连接层(共三层),经ReLU激活
12)最后通过softmax输出1000个预测结果
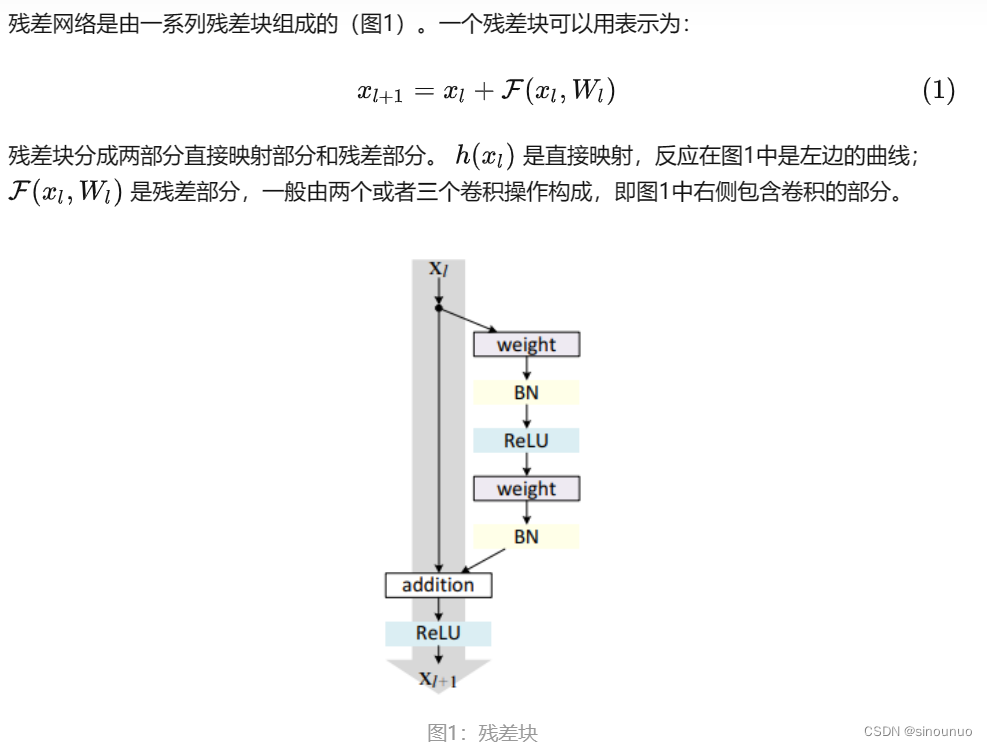
(2)Resnet:

四、安装pytorch:
安装PyTorch详细过程_pytorch安装_MC云鸷骚峰的博客-CSDN博客
按照上述过程安装pytorch
Pytorch安装完成后Pycharm如何配置环境并测试Pytorch_supreluc的博客-CSDN博客
之后在按照上述过程配置好pycharm的环境

