
- 1【超细完整版】C# 获取WebService所有方法并调用 【调用篇】
- 2修改jupyter notebook默认路径_jupyter notebook修改默认打开位置
- 3Linux之管道符/重定向_centos中管道符重定向等
- 4Git常见问题解决方法_git输入命令没反应
- 5【盖楼抽奖】华为开发者学堂推出HarmonyOS官方课程专区,分享心得赢超值好礼_harmonyos马克杯
- 6LangChain使用调研_langchain是什么
- 7Mac 免费模拟器推荐适配m1芯片_mac 模拟器
- 8如何处理后端接口返回的文件流_后端返回文件流
- 9SOCKS5代理、代理IP、HTTP与网络安全的深层探寻
- 10Swiper插件的基本使用方法和案例_new swiper
【论文精读】SalBiNet360: Saliency Prediction on 360° Images with Local-Global Bifurcated Deep Network_icmesalient360
赞
踩
这是我精读的第一篇IEEE2020论文,我认为这一篇论文非常有意义,因为它是目前为止最先进显著性预测模型,在理解论文过程中,我查阅了许多相关资料,其中一些放在文章最后的补充概念部分,这对理解SalBiNet360的原理非常重要。另外,如果翻译过程中有什么不妥之处,欢迎在评论区留言指正。
英文名称:SalBiNet360: Saliency Prediction on 360° Images with Local-Global Bifurcated Deep Network
中文名称:基于局部-全局二叉式深度网络的360°全景图显著性预测
论文会议:2020 IEEE Conference on Virtual Reality and 3D User Interfaces (VR)
论文地址:https://ieeexplore.ieee.org/abstract/document/9089519
摘要
随着虚拟现实应用的发展,在360°全景图上预测人类的视觉注意对理解用户的行为至关重要。基于360°全景图全局和局部视觉显著性的特点,论文提出了一个用于360°全景图显著性检测的框架(SalBiNet360)。在全局深度子网络中,利用多个多尺度的上下文模块和一个多级解码器来整合网络中层和深层的特征。在局部深层子网络中,只利用一个多尺度上下文模块和一个单级解码器来减少局部显著性特征的冗余。最后利用线性组合方法,结合全局和局部显著图的特点,生成最终的融合显著图。在两个公开数据集上进行的定性和定量实验表明,SalBiNet360的性能优于当前最先进的方法,特别是能够更好地预测低显著性区域和图像左右边界附近的区域。
关键词: 360°度全景图,SalBiNet360,虚拟现实 (VR)
关于视觉注意及视觉显著性检测见本文最后的补充概念
1 引言
360°全景图在VR技术中扮演着至关重要的角色。与2D图像不同,360°全景图允许观察者从各个方向观察场景,因此其特性吸引了研究者更多的兴趣。此外,预测观察者在360°图像上的视觉注意力,可以帮助研究人员了解观察者佩戴VR设备时的行为,它还可以应用在计算机视觉的各个方面,如图像压缩和图像裁剪。
显著性模型是在人类没有明确意图的情况下,观察图像所注意的物体或区域。随着神经网络的兴起和发展,对传统二维图像上的显著性预测模型进行了深入的研究。许多优秀的模型已经出现,并建立了大量的数据集,如MIT Saliency Benchmark(一个显著性预测框架)。然而,到目前为止,关于360°全景图的显著性预测的研究还比较少,尤其是以神经网络为框架的研究。一般情况下,我们通常会通过ERP投影的方式将360°全景图投射到一个平面上,但这种投影方式会使360°全景图对应球面的两个极点被转换为上界和下界,从而导致图像过度变形。
关于ERP投影见本文最后的补充概念
如果将传统二维图像上的显著性预测模型直接应用于ERP图像上,效果将不理想。图1©显示了在传统二维图像上,由显著性模型预测的全局ERP显著图。与ground truth(图1(b))相比,全局显著图大致预测了显著性区域(赤道区域)。但是对于其它低显著性的区域(观察者不太关注的区域),传统模型无法预测它们。
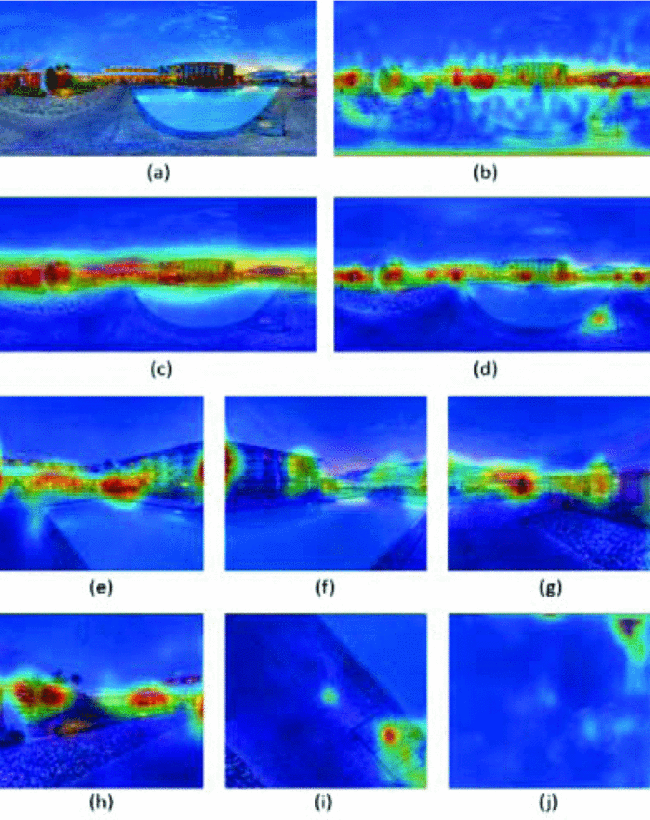
图1:(a)ERP图像,(b)ground truth显著图,©(d)分别是全局和局部的显著图,(e)-(j)通过立方体投影的直线显著图。
为了解决这个问题,利用立方体投影将360°全景图投射到立方体的六个面,每个面的视场角(FOV)为90°,显示六个方向的景物,而且比ERP图像失真小,这些立方体图被命名为rectilinear images,我将其译为直线图像。图1(e)-(j)说明了这六张直线显著图,而图1(d)则说明了由这些直线显著图重新投影出来的局部显著图。与全局显著图相比,局部显著图可以精细地预测显著性区域,即使是一些显著性较低的区域也可以预测。(这里全局和局部特征我理解为:如果从整张ERP图片提取特征就是全局特征,如果从立方体投影的六个面分别提取特征,再重新投影到一张图上,那么得到的就是局部特征)
关于立方体投影及视场角(FOV)见本文最后的补充概念
然而,在预测缺乏全局性的直线显著图时,模型增强了低显著性区域,甚至一些不被人类关注的区域也被错误地预测出来。在图1(i)和图1(j)中,除了云层和坑洞,几乎没有什么物体,它们显然是突出的。所以在局部显著性图(图 1(d))中,这两类物体很容易被预测出来。但是预测整幅图像时,在其它物体的存在下,云层和坑洞就显得不那么突出了。因此,模型对云层和坑洞的敏感度较低,所以,在缺乏全局性的直线图像中,模型对低显著性的区域是很敏感的。
为了解决上述问题,作者提出了一种基于360全景图的全局和局部显著性预测的新框架(SalBiNet360)。这是一个包含全局和局部显著性预测子网络的(二叉式)深度网络框架。在全局深度子网络中,我们利用多个多尺度的上下文模块从网络的中层和深层提取上下文特征,然后,这些特征由一个多级解码器整合,预测全局显著性图。对于局部深层子网络,为了降低网络对一些低显著性区域的敏感性,只利用一个多尺度上下文模块,然后利用单级解码器来还原图像的分辨率,生成直线显著图。最后,将多张直线显著图重新投影成局部显著图(如图1(d)),利用线性组合策略将全局显著图与局部显著图融合。综上所述,我们做出了以下贡献:
- 本文提出了一种全新的二叉式深度网络,该网络有两个子网络,分别预测360°全景图的全局和局部显著性特征,通过线性组合将全局显著图和局部显著图融合生成最终的显著图。
- 提出了一种新的多尺度上下文模块,以提取360°全景图多尺度的上下文特征。
- 采用全局子网络中的多级解码器,以减小不同层网络的判别特征之间的差距。
- 在两个公开可用的数据集上进行的广泛实验说明,所提出的SalBiNet360优于经过测试的最先进的方法。
2 相关工作
到目前为止,大多数360°全景图的显著性预测模型都是在传统二维图像模型基础上改进的(所谓的传统二维图像模型是指用二维图形训练和测试的模型),主要有三个研究方向,分别是赤道偏移、凝视位置的数据映射和投影变换。
赤道偏移。当观察者观看VR全景图像时,他们往往会更多地关注赤道附近的内容,这被命名为赤道偏移。Battisti等人利用这一特性,将360°全景图划分为多个区域,每个区域赋予它们不同的显著性权重,区域越靠近图像的赤道,权重越大。Ding等人从图像层面细化到像素层面,利用高斯分布模型来模拟赤道偏差,从而提高了精度。但他们都只是基于360°全景图的全局属性设计模型,并没有考虑到局部的显著性。
凝视位置的数据映射。一些显著性预测方法,是基于凝视位置的数据映射,就是利用观察者的凝视位置数据来建立显著图。这类方法将观察者有限的注视位置扩展为一般的显著图。Upenik等人利用头部运动轨迹来预测显著性,根据头部角度速度来确定观察者观察图像某些区域时所花费的时间。Abreu等人根据观察者的固定时间来区分观察者的视觉注意(即根据观察者看某一部分区域的大概时间来区分显著性区域)。
对于投影变换,最常用的方法是ERP投影。为了解决ERP图像的边界失真问题,Lebreton等人将几个不同经度边界的ERP投影的显著图均匀地整合在一起,从而得到最终的显著图。但是,他们没有解决图像上下边界附近发生严重失真的问题。Startsev等人将360°全景图投射到ERP图像和反ERP图像上,然后对这两幅图像进行预测,并将其融合,解决了等ERP图像左右边界不连续的问题。此外,他们还单独预测了图像上下边界附近的显著性。但是他们直接使用了预训练的显著性模型,而不是通过360°全景图来训练它们,所以这些模型无法提取360°全景图的具体特征。而球面投影则是将360°全景图投射到球面上,使图像具有连续性,图像上的景物不易失真,可以提高模型的精度。但是,应用这些模型预测立体空间中的图像是复杂的。Bogdanova等人提出了一个基于球面投影的显著模型,构建球形金字塔模块,从而输出球面显著图。
除以上几种投影变换方法外,还有立方体、八面体、正金字塔投影等。立方体投影是比较常用的,Maugey等人提出了双立方体投影法,以解决立方体投影中的边界畸变和不连续问题。该方法将360°全景图投影到两个水平和垂直相差45°的立方体上,然后通过旋转将两个显著图融合。虽然它可以精细地预测局部的显著图,但由于直线图像缺乏全局性,导致一些低显著性的区域被错误地预测。Chao等人提出的SalGAN360在上述方法基础上扩展到多立方投影,也分别预测了全局和局部的显著图。但是,它始终利用SalGAN预测全局和局部的显著性特征,而没有考虑到360°全景图的全局和局部属性,以提高网络。
本文根据360°全景图的全局和局部属性,将提出的网络分为两个不同的深度子网络,分别预测全局和局部的显著性特征,通过融合得到最终的显著图。
3 方法
在本节中,构建了包含全局和局部深度子网络的二叉式网络(SalBiNet360)。在全局深度子网络中,生成了一个全局的显著图,可以检测所有方向的视觉注意力。在局部深度子网络中,生成了一个以精细方式检测视觉注意力的局部显著图。最后,通过与全局和局部显著图的线性组合,生成融合的显著图。
3.1 SalBiNet360机制
3.1.1 Framework
所提出的模型框架如图2所示,它利用ResNet50作为骨架。ResNet50有四个卷积块(输入层还有一个卷积)。对于一个输入图像,在第四个卷积块中,分辨率降低了32倍。这里从网络中第二个卷积块的最后一层开始,我们将网络分成两个深度子网络,其中一个子网络预测全局的显著性,而另一个子网络预测局部的显著性。这两个子网络都有ResNet50最后两个卷积块。图2蓝色的方块就是ResNet50的convBlock块,一个convBlock包含多个卷积操作,若想对ResNet50有更深的理解,ResNet残差网络及变体详解,相信会让你有所收获。
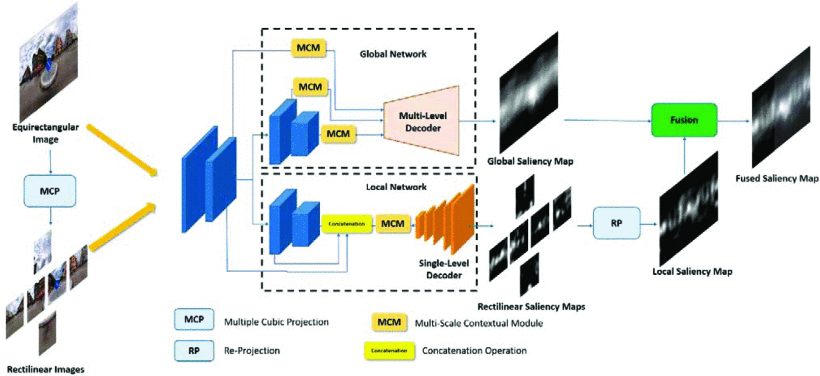
图2:SalBiNet360的框架。该网络分为全局和局部深度子网络,分别用来预测360°图像的全局和局部显著性特征。
在全局显著性预测中,将整个ERP图像纳入全局子网络,输出全局显著性图。一般来说,神经网络的第一个卷积块会提取一些低级特征,如形状、纹理、轮廓等,但这些特征对显著性预测的贡献较小。此外,不同尺度的卷积层可以保留精细的上下文信息,尤其是中间*的特征图的尺度相对较大,这使得更多的全局信息得以保留。因此,将最后三个卷积块的特征被提取出来,分别输入到三个相同的多尺度上下文模块(MCM)中,然后生成三个不同层次的特征图。之后,采用多级解码器对三个特征图进行整合,生成全局显著图。
在局部显著性预测中,首先通过立方体投影将360°全景图投射到立方体的六个面上,每个面的FOV为90°,可以得到多个直线图像。然后,把这些直线图像输入到局部子网络,局部子网络输出相应的直线显著图。最后,ResNet50的后三个卷积块的特征也在局部子网络中被提取出来。如果在局部子网络中加入多个多尺度的上下文模块(就像全局子网络的架构一样),会增加局部显著图的冗余度。在图3中,沟渠和灯具是ground truths中显著性较低的对象,与只有一个多尺度上下文模块的局部子网络相比,有多个多尺度上下文模块的局部子网络会错误地将这些显著性较低的对象预测为高显著性的对象。

图3:具有一个和多个多尺度上下文模块的地面真相和局部显著图的视觉比较。("MCM"表示多尺度上下文模块)
因此,与全局子网络中的操作不同,局部子网络的最后三个卷积块中的特征图是连在一起的,只是输入到一个多尺度的上下文模块中。之后,采用卷积-上采样操作的单级解码器,将多尺度上下文模块输出的结果恢复到与输入的分辨率一样的大小。然后,利用重投影法将这些直线显著图重新投影成多个ERP显著图,通过使用平均法将所有的ERP显著图重叠,得到局部显著图。
最后,将全局和局部的显著图进行线性组合融合,得到融合的显著图。多尺度上下文模块和多级解码器的具体内容将在3.2节和3.3节中介绍。
3.1.2 预训练
在没有360°全景图的大型数据集的情况下,SalBiNet360必须由SALICON进行预训练(SALICON是一个显著性检测数据集)。该数据集包含20 000张二维图像以及相应的显著图,其中10,000张用于训练,5,000张用于验证,5 000张用于测试。将二维图像放入模型中,相应地同时生成两张预测的二维显著图,一个是来自全局子网络,另一个是来自局部子网络。然后利用 ground truth的显著图,根据二元交叉熵损失来监督这两个子网络的训练。
3.1.3 微调
在使用SALICON预训练模型后,将全局和局部深度子网络进行联合微调。做法是将训练的直线图像分别放入模型中,相应地同时生成两个预测的直线显著图,一个是来自全局子网络,另一个是来自局部子网络。在360°全景图显著性预测模型中,经常使用皮尔逊相关系数(Pearson’s Correlation Coefficient,简称CC) 和归一化扫描路径显著性(Normalized Scanpath Saliency,简称NSS)这两个指标来衡量模型的有效性。因此,在二元交叉熵中加入这两个指标来优化模型训练的过程。对于全局子网络,损失可以定义如下:
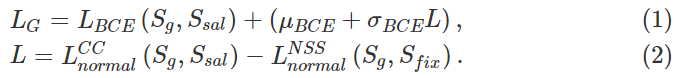
其中,ܵ S g S_g Sg、 S s a l S_{sal} Ssal、 S f i x S_{fix} Sfix 分别是全局子网络预测的直线显著图、ground truth的直线显著图和二元直线定点图, μ B C E \mu_{BCE} μBCE和 σ B C E \sigma_{BCE} σBCE表示SalBiNet360对预测的二维图像计算出的 L B C E L_{BCE} LBCE的平均值和标准差, L B C E L_{BCE} LBCE表示二元交叉熵损失, L n o r m a l L_{normal} Lnormal是CC和NSS的归一化函数。
L B C E L_{BCE} LBCE定义如下:

其中N为像素数,j为像素坐标。
L n o r m a l L_{normal} Lnormal定义如下:
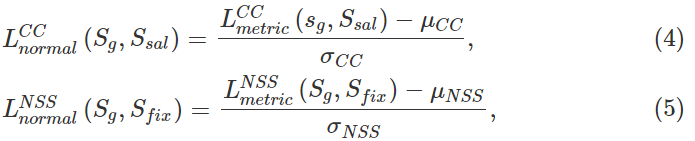
其中 L m e t r i c C C L^{CC}_{metric} LmetricCC是CC的评价指标, L m e t r i c N S S L^{NSS}_{metric} LmetricNSS是NSS的评价指标。 μ C C \mu_{CC} μCC、 σ C C \sigma_{CC} σCC、 μ N S S \mu_{NSS} μNSS、 σ N S S \sigma_{NSS} σNSS表示SalBiNet360对预测的二维图像计算的这两个指标(即CC和NSS)的平均值和标准差。
对于局部子网络来说, l o s s L L lossL_L lossLL与全局子网络中的损失相同,只是用局部子网络预测的直线显著图 S l S_l Sl代替了 S g S_g Sg。因此,SalBiNet360的总损失定义为:

在微调步骤中,我们首先固定Resnet50网络的权重。然后,我们对SalBiNet360中其他部分的权重进行微调。最后,随机初始化两个解码器的最后两个卷积层的权重(我认为这两个卷积层的权重占比很小,虽然进行随机初始化了,也影响不了整个模型的性能,也提高了模型的鲁棒性)。这样在微调的过程中就可以充分提取360°全景图的特征。
3.1.4 测试
在测试步骤中,预测局部显著性时,首先将直线图像放入模型中,在局部子网络中生成直线显著图(忽略全局子网络中的输出)。然后,将直线显著图重新投影为ERP格式,得到局部显著图图。
在预测全局显著性特征时,将ERP图像放入模型中,模型直接在全局子网络中生成全局显著图(忽略局部子网络中的输出)。虽然网络是由失真较小的直线图像进行微调,但在预测全局显著性时,由于赤道附近的区域失真较小,所以模型在等ERP图像的赤道附近区域可以很好地预测。另外,利用Fused Saliency Method(FSM,融合显著性方法)作为后处理方法,解决了360°全景图左右边界不连续的问题,在这个方法中四个全局显著图分别赋予0.25的权重。
最后,将全局和局部显著图进行线性组合融合,得到融合后的显著图。

其中, α \alpha α和 β \beta β分别是全局和局部显著图的权重,且 α \alpha α+ β \beta β=1
我第一次看到FSM方法,非常疑惑,作者文中并没有过多的解释,我查阅了其引用的论文,才理解了具体用到的方法,见本文最后的补充概念。
3.2 多尺度上下文模块
当360°全景图通过ERP投影到一个平面上时,图像上不同尺度的上下文信息是不同的。如图 4 所示,360°全景图比传统的二维图像尺寸大得多,可以捕捉到更多的场景信息,在此基础上,设计了多尺度的上下文模块,有效地提取不同尺度的上下文特征。
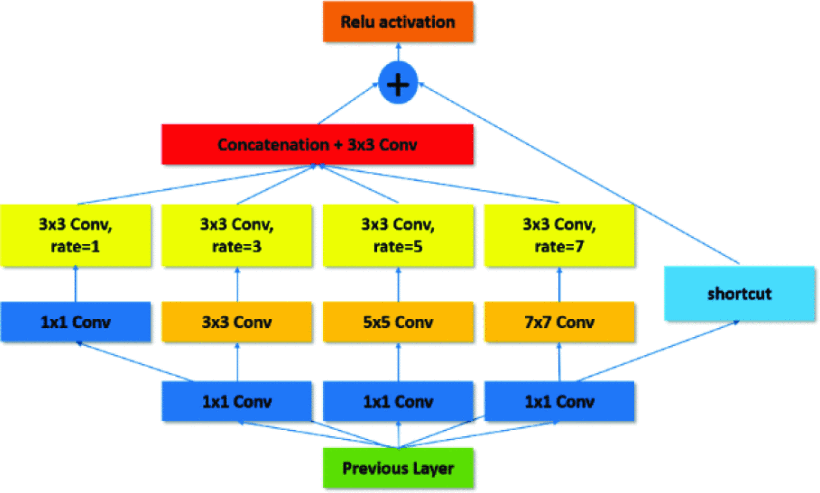
图4:多尺度上下文模块的架构。
如图4所示,所提出的多尺度上下文模块共包含四个分支{ b n b_n bn,n=1,2,3,4}。每个分支都有不同大小的卷积核,可以在不同尺度的360°全景图上进一步提取更多的上下文特征。最初,在每个分支中利用1X1卷积层来减少特征图的通道数。对于݊n>1的分支,我们分别增加一个卷积层,其内核大小为(2n-1)x(2n-1),然后,在四个分支中分别增加一个3x3卷积层,再将每个分支的特征图Concatenate,再做一次3x3卷积操作。最后,将提取的判别特征与原始特征通过shortcut与Relu激活函数结合,从而得到不同尺度的判别特征。
3.3 多层解码器
在全局子网络中,利用多尺度的上下文模块,得到三个判别性特征图{ f i f_i fi,i=2,3,4}。为了缩小这些特征之间的差距,采用多级解码器。如图5所示,在这个解码器中有四层(c=1,2,3,4), f i c f_i^c fic示 c 层中的第 i 个特征图, f i f_i fi在第二层中更新了以下内容公式:
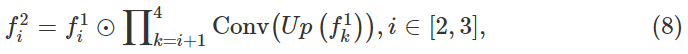
其中Up是对特征图进行因子为 2 k − 2 2^{k-2} 2k−2的上采样操作,Conv是3X3卷积层。 圈表示元素化的乘积(点积)。
我认为这里每一层的特征图从2开始是应该方便些公式,如上面的 2 k − 2 2^{k-2} 2k−2,k从2开始,第一幅特征图上采样因子就是2
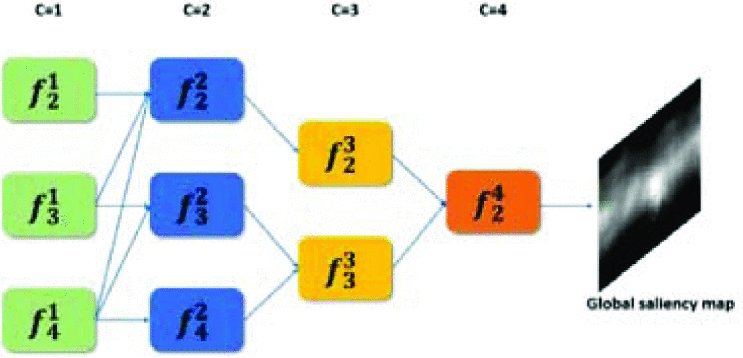
图5:多级解码器的架构。图中顶部的"c"表示第c层。
对于 f 4 2 f_4^2 f42,作者设置 f 4 2 f_4^2 f42 = f 4 1 f_4^1 f41,对于 f 2 3 f_2^3 f23,作者设置 f 2 3 f_2^3 f23= f 2 2 f_2^2 f22(即这些位置的特征图采用一样的上采样和卷积操作)。至于 f 3 3 f_3^3 f33 和 f 2 4 f_2^4 f24,作者采用upsampling-convolution-concatenation策略来整合多个特征,公式如下:
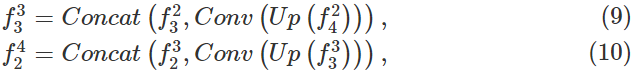
其中,Up为上采样因子为2的操作,Conv是3x3卷积层,Concat是两个特征图的通道连接。最终,通过对 f 2 4 f_2^4 f24使用upsampling-convolution策略,解码器生成与输入的ERP图像大小相同的全局显著图。
至于单层解码器,主要由5个3×3卷积层和1个填充层以及5个系数为2的双线性上采样层组成(就是图2的那五个橙色方块)。
4 实验
4.1 实验配置
4.1.1评估数据集
SalBiNet360是在两个公开的数据集上进行评估的:Salient360! 和Grand Challenge
Salient360! 是国际会议ICME2017的360°全景图显著性预测挑战赛数据集,由65张360°全景图组成,观察者的头部和眼部运动被记录下来,其中40张图像用于训练,25张用于测试。
VR Saliency是虚拟现实全景图显著性预测数据集,由22张图像组成,观察者的头部动作被记录下来。
两个数据集中的图像都由室内和室外场景内容组成。
4.1.2 评价指标
SalBiNet360的性能是通过四个常用的指标来评估的:KL、CC、NSS、AUC。KL和CC评价的是两个显著图之间的显著性密度分布(主要是面向局部信息的),NSS和AUC评价的是显著图和二元定点图之间的眼动位置分布(主要是面向全局信息的)。
关于KL、CC、NSS、AUC四个指标,作者并没有详细介绍,我查阅了许多资料,大致知道其具体的衡量标准,见见本文最后的补充概念部分。
Salient360! 数据集的性能是在KL、CC、NSS和AUC上评估的,而对于VR Saliency数据集,只采用CC来评估性能,如下所述。在下面的小节中,每个实验的最佳结果以红色粗体显示。
4.1.3 实施细节
网络结构 。在全局子网络中,对于多尺度上下文模块,每个分支的特征图通道减少到32个。在局部子网中,经过多尺度上下文模块的处理,特征图的通道减少到256个。
微调与测试。Salient360!数据集中40幅训练图像分为30幅用于微调,10幅用于验证。在立方体投影中,立方体在水平和垂直方向上每45°旋转一次,可以得到2×2=4种旋转方式。因此,每幅360°全景图有4×6=24幅直线图像,完全可以生成30×24=720幅直线图像用于微调,10×24=240幅用于验证。在测试SalBiNet360模型时,为了使重新投影后的局部显著图更加平滑,每隔10度旋转一个立方体,因此会产生9×9×6×25=12150张整线图像(每次转10度,即水平方向9次,垂直方向9次,一次360°全景图有6张直线图像,Salient360!共25张360全景测试图)。当预测全局显著性时,预测25个ERP图像得到全局显著图。当预测局部显著性时,预测12150张直线图像,并重新投影为25张局部显著性图。最后,通过融合这些全局和局部的显著图,可以得到25个融合的显著图。
对于VR Saliency,根据其实验设置,用SALICON数据集预训练模型后直接测试22张360°全景图。同样,立方体也是每10°旋转一次,就会产生9x9x6x22=10692个直线图像。预测全局和局部的显著图和Salient360!中的一样。
在预训练和微调步骤中,所提出的模型均采用Adam优化器进行训练,初始学习率为 1 0 − 4 10^{-4} 10−4,batch size为10。此外,当损失下降到一定程度时,学习率会下降10%。SalBiNet360基于PyTorch框架,部署在GeForce GTX1080Ti GPU上。源代码可在https://github.com/githubcbob/SalBiNet360(访问404,可能是作者删了,哈哈)
4.2 SalBiNet360的分析
4.2.1 融合策略中权重的选择
在融合全局与局部显著图时,我们做了多组全局和局部权重选择的实验。表1说明了在测试步骤中,两个数据集上不同权重的融合结果。可以看出,随着 α \alpha α的增加( β \beta β减少),SalBiNet360的指标得分在两个数据集上都出现了先增加后减少的现象。当全局权重 α \alpha α设置为0.55时Salient360!表现最佳, α \alpha α在上设置为0.50时VR Saliency表现最佳。因此,在下面的实验中,我们在Salient360!上的融合策略中设置 α \alpha α=0.55( β \beta β=0.45),在VR Saliency上设置 α \alpha α=0.50( β \beta β=0.50)。
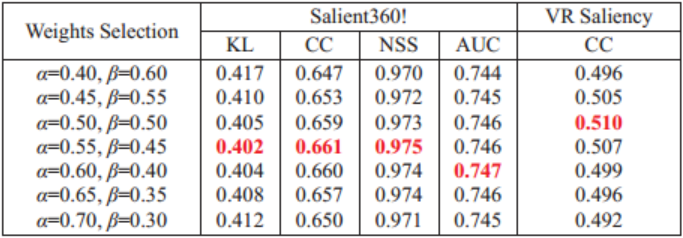
表1:两个数据集上不同权重选择的比较。
4.2.2 多尺度上下文模块的有效性
在下面的实验中,将SalBiNet360的两个子网络中的多尺度上下文模块全部去掉,以测试多尺度上下文模块对显著性预测的影响。表2显示了SalBiNet360在有上下文模块和无上下文模块的两个数据集上测试的量化结果。显然,带有多尺度上下文模块的SalBiNet360的性能优于不带有多尺度上下文模块的SalBiNet360,这说明带有多尺度上下文模块的SalBiNet360能够有效地预测360°图像上的显著性。

表2:SalBiNet360在两个数据集上有无上下文多尺度模块("MCM"表示多尺度上下文模块)的比较。
4.2.3 全局、局部和融合显著性预测的表现
为了研究全局、局部和融合的显著性预测对SalBiNet360整体性能的影响,我们分别在两个数据集上做了两个子网络和融合策略的显著性预测实验。从表3中可以看出,全局显著性在NSS和AUC上的表现都优于局部显著性,而局部显著性在KL和CC上的表现都优于全局显著性。这说明全局显著图对图像凝视点(gaze points)的识别能力优于局部显著图,而局部显著图在减少显著性信息的丢失上效果更好。此外,融合后的显著图在NSS和AUC上都优于全局图和局部图,而在其他两个指标上略逊于局部图。

表3:全局、局部和融合的显著性在两个数据集上的比较。
图6和图7通过箱形图说明了全局、局部和融合显著性在两个数据集上的得分分布。很明显,在Salient360!数据集上,融合显著性在KL和CC上的得分分布与局部显著性相似,NSS和AUC的得分分布与全局显著性相似。但在VR Saliency上,融合显著性的得分分布普遍大于全局和局部显著性的得分分布。

图6:全局、局部和融合显著性在Salient 360上的得分分布对比
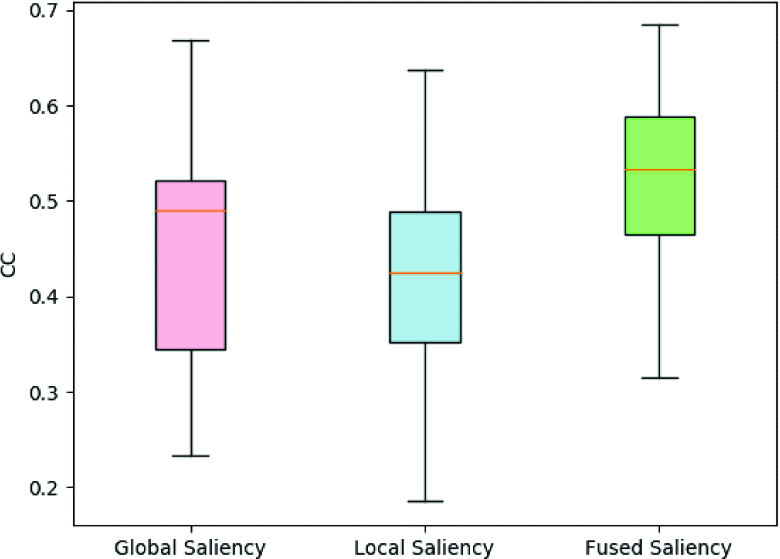
图7:全局、局部和融合显著性在VR Saliency上的得分分布对比
图8和图9显示了全局、局部和融合的显著图在两个数据集上的一些可视化结果。可以观察到全局子网络预测的显著性区域大致集中在图像的赤道部分,局部显著性预测可以精细地预测一些显著对象,如阶梯。但是,由于缺乏全局性,某些物体被错误地预测为高显著性(如坐具和树木)。结合全局和局部显著图的特性,融合后的显著图可以恰到好处地预测这些显著性区域,从而提高SalBiNet360的预测质量。在VR Saliency上,融合的显著图的效果稍差(因为模型没有进行微调就直接测试,主要是由于其数据集很少,只有22张图片),但融合的显著图也可以削弱一些物体的显著性。
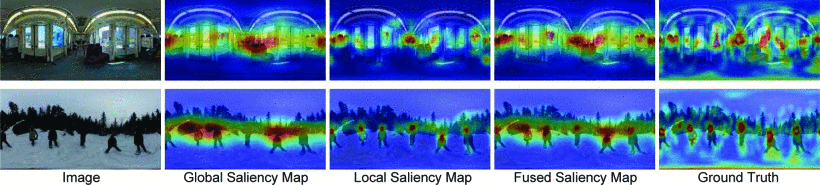
图8:Salient 360上的全局、局部、融合的显著图和ground truths 的视觉对比

图9:VR Saliency上的全局、局部、融合的显著图和ground truths 的视觉对比
4.3 与最新技术的比较
表4显示了SalBiNet360与现有的7种经过测试的最先进的显著性模型在Salient360!上的量化结果,包括GBVS360、SalNet360、Maugey、Startsev、SJTU、CDSR和SalGAN360。很明显,SalBiNet360在大多数情况下优于所有其他方法。只有SalGAN360获得了与SalBiNet360相同的AUC分数。值得注意的是,与CC、NSS和AUC相比,SalBiNet360在KL方面有明显的提高,这说明SalBiNet360在减少显著性密度分布的信息损失方面效果更好。表5是VR Saliency中的量化比较。比较的三种模型(EB、SalNet+EB、ML-Net+EB)的性能结果,可以看出,SalBiNet360得到的性能最好。
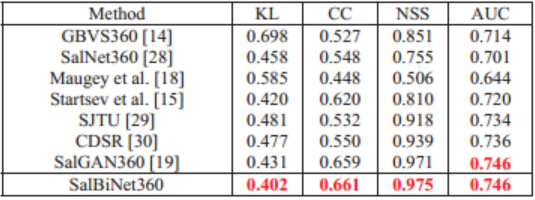
表4:不同方法在Salient360!上的比较。
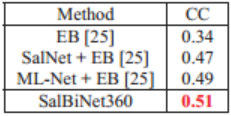
表5:不同方法在VR Saliency上的比较。
Salient360!上一些案例的视觉对比如图10所示。与SalGAN360相比,SalBiNet360不仅可以精细预测图像赤道附近的显著性区域,还可以预测一些SalGAN360忽略的低显著性区域(如树木和地板)。此外,SalBiNet360还可以预测图像左右边界附近的显著性区域,从而减少了显著性密度分布中的信息损失。这与表4中SalBiNet360在KL得分上有所提高的结果是一致的。这一现象可以解释为利用多尺度的上下文模块从多个尺度中提取上下文特征,包括边界的特征。
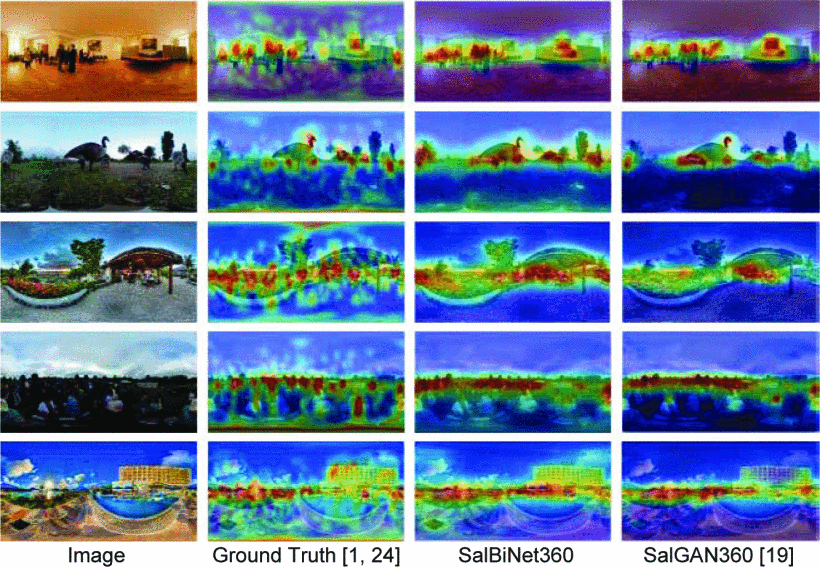
图10:SalBiNet360和最先进的模型在Salient360!的视觉对比
图11是SalBiNet360在VR Saliency上的视觉效果。在不对网络进行微调的情况下,SalBiNet360只能大概的做到预测一些显著性区域。但图像左右边界附近的显著性区域还是可以预测的。 它证明了SalBiNet360能够有效地解决等角ERP图像左右边界的不连续视觉信息问题。

图11:SalBiNet360对VR Saliency的视觉效果
4.4 讨论
在两个360°全景图数据集上的大量实验表明,提出的SalBiNet360实现了具有竞争力的性能。它是一个包含全局和局部显著性预测子网络的二叉式深度网络。该网络仅通过直线图像进行联合微调。如果将这两个子网络作为两个独立的分支分别进行微调,则可能会浪费很多时间。
在缺乏大的360°图像saliency数据集的情况下,必须利用失真较小的直线图像和相应的ground truths来微调模型,这样可以忽略ERP图像上下边界的尺度和严重失真。显然,在测试步骤中,由于等角图像的赤道附近失真较小,全局子网络可以很好地预测赤道附近的显著性(如图8、9中的"全局显著性图")。但是,两极的预测效果并不好。因此,需要将其与局部显著性相结合,以弥补全局显著性的不足。
与表4和表5中的其他模型相比,SalBiNet360构建了两个子网络,分别适合预测360°图像的全局和局部显著性。全局子网络可以大致预测360°全景图的赤道附近和左右边界的显著性区域,而局部子网络可以精细地预测一些显著性高的区域和观察者不太关注的区域,从而弥补了全局显著性的劣势。SalBiNet360的分叉架构可以应用于其他利用360°全景图的全局和局部显著性的显著性模型。
5 总结
本文提出了一种全新的360°全景图的显著性预测框架,命名为SalBiNet360。所提出的框架在ResNet50的第二个卷积块之后分为两个深度子网络,这两个子网络分别预测全局和局部的显著图。在全局深度子网络中,上下文特征从网络的中层和深层中提取,并由三个多尺度的上下文模块和一个多层次的解码器进行整合。而在局部深度子网络中,为了减少图像低显著性区域的冗余,只利用一个多尺度的上下文模块和一个单层解码器来生成局部显著图。最后,通过线性组合融合全局和局部显著图,生成最终的显著图。在两个可用的数据集上进行了广泛的实验表明,SalBiNet360的性能优于已测试的最先进的方法。
补充概念
为了更好的理解本文,我查阅了许多资料,补充了文章中的作者所提到一些术语和概念:
(1)视觉显著性检测(Visual saliency detection)指通过智能算法模拟人的视觉特点,提取图像中的显著区域***(***即人类感兴趣的区域)。
(2)视觉注意机制(Visual Attention Mechanism,VA),即面对一个场景时,人类自动地对感兴趣区域进行处理而选择性地忽略不感兴趣区域,这些人们感兴趣区域被称之为显著性区域。如下图所示,当看到这幅图像时,图中的四个人最能引起人的注意,而其它区域(如地面)就不会引起人们注意。

来源:https://www.cnblogs.com/ariel-dreamland/p/8919541.html
(3)ERP全称equirectangular projection,又可以称为equidistant cylindrical projection,中文译为等距柱状投影。这种投影方式将经线映射为恒定间距的垂直线,将纬线映射为恒定间距的水平线,映射关系相对简单,但既不是等面积的也不是保角的,引入了相当大的失真。下图是一幅用ERP方式投影的360全景图,长宽比为2:1,可以明显看出,两极区域拉伸严重,造成了极大的冗余,增加了编码负担。

来源:https://blog.csdn.net/lin453701006/article/details/71173090
(4)立方体投影就是将360°全景图被投影到各面都是正方形的六面体上(面积未保持不变),经线和纬线都是直线,在纬度 +45° 和 -45° 之间,东南西北方向是准确的,但常规方向不准确。在极面上,由中心确定的方向是真实的。在纬度 +45° 到 -45° 之间,比例尺是正确的。如下图所示:
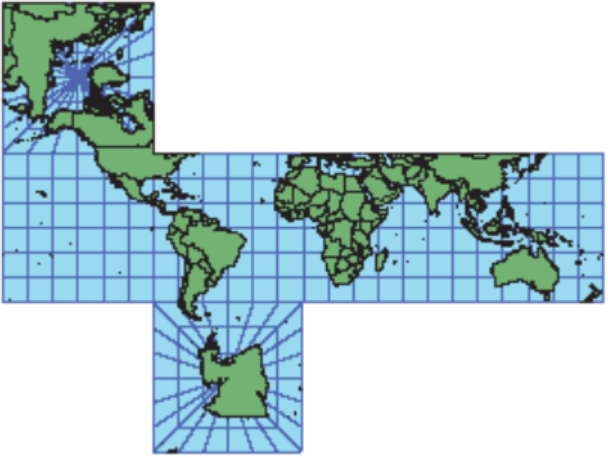
来源:https://desktop.arcgis.com/zh-cn/arcmap/10.7/map/projections/cube.htm
(5)视场角(FOV)。在光学仪器中,以光学仪器的镜头为顶点,以被测目标的物像可通过镜头的最大范围的两条边缘构成的夹角,称为视场角。如下图。 视场角的大小决定了光学仪器的视野范围,视场角越大,视野就越大。通俗地说,目标物体超过这个角就不会被收在镜头里,就只能看到局部物体。
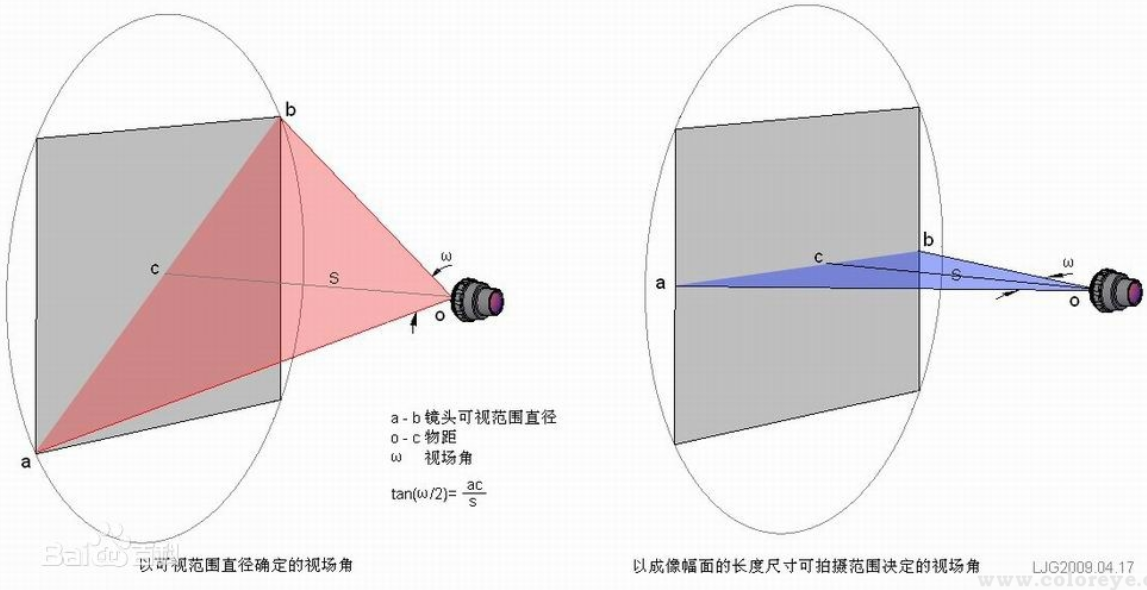
来源:http://www.colorspace.com.cn/kb/2013/02/24/fov/
(6)Fused Saliency Maps(FSM,融合显著性方法)。其作者认为(引用论文的作者),在传统情况下,摄影师倾向于将感兴趣的对象定格在赤道近旁,对于边界的区域其实是不敏感的,因此,使用传统图像训练显著性模型很可能不包含这些区域的特征,尤其是基于深度神经网络的模型。为了解决显著性模型的中心先验限制,提出了Fused Saliency Maps(FSM)方法,该方法过程如下:
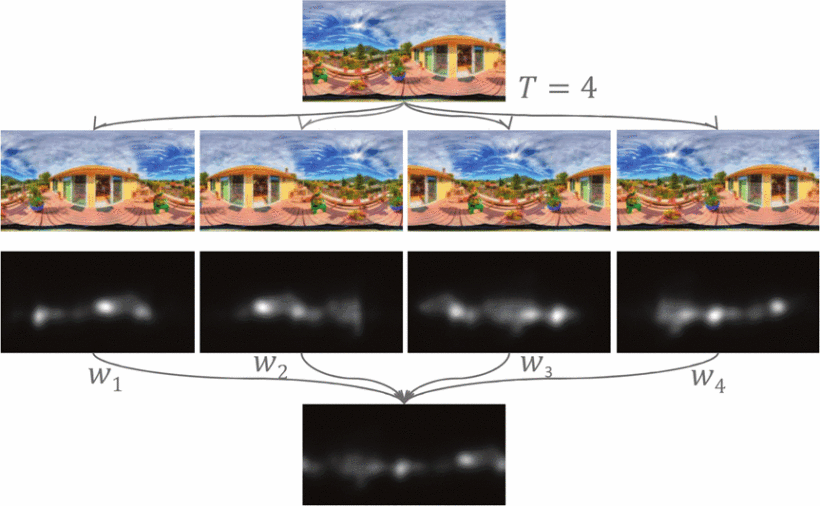
- 首先,输入ODI图像(omnidirectional images,全向图像,球面投影产生的图像)。
- 将其随机翻译成不同的版本,具体做法是将里面的场景、物体随机移动、随机拼接,这里的T即翻译的版本数,可根据实际情况设置。
- 用相应的显著性模型预测这T幅图像的显著性图
- 采用线性组合的方式将3产生的T幅显著性图融合,其中 W 1 W_1 W1、 W 2 W_2 W2、 W 3 W_3 W3、 W 4 W_4 W4为这4幅图的权重。
FSM方法可以解决全景图左右边界不连续的问题。
来源:Look around you: Saliency maps for omnidirectional images in VR applications. Ninth International Conference on Quality of Multimedia Experience (QoMEX). IEEE, 1-6, 2017
(7)Kullback-Leibler Divergence,简称KL散度,通常用来衡量两个分布之间的距离, KL散度越小说明,两个分布之间的距离越小,该模型检测性能越好。
(8)Pearson’s Correlation Coefficient(CC)是指皮尔逊相关系数,用来评价预测的眼关注点显著图和ground truth之间的线性相关性,其值越大,相关性越强,算法性能越好,值为正表示正相关,值为负表示负相关。下面是其一个公式(CC有很多变种):
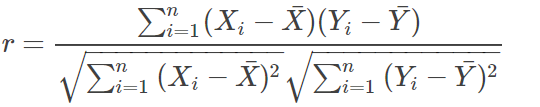
(9)Normalized Scanpath Saliency (NSS)是指标准化扫描路径显着性,用来评价预测的人眼凝视位置与ground truth之间的差异性,NSS越大说明差异越小,模型性能越好。
(10)Area Under Curve(AUC),显示了模型预测人眼注视点的能力大小,最理想的预测对应的score是1,AUC越大说明算法检测性能越好。
参考:https://www.cnblogs.com/hSheng/archive/2012/12/05/2803424.html

