
- 1java 前端加密后端解密_前端登陆加密和后端解密
- 2NLP的学习笔记(1)_基于统计方法的哲学基础的理性主义方法
- 3OpenStack介绍(及资源)
- 4python使用requests模块下载文件并获取进度提示
- 5C++从入门到精通——auto的使用
- 6激活函数小结:ReLU、ELU、Swish、GELU等_swigelu
- 7[机器学习] 第二章 模型评估与选择 1.ROC、AUC、Precision、Recall、F1_score_怎样在真阳率限制的情况下选择模型
- 8Linux——线程概念与线程的创建
- 9【证明】期望风险最小化等价于后验概率最大化_期望风险最小化 后验概率最大化
- 10osg 倾斜数据纹理_高科技构筑逼真效果——无人机倾斜摄影技术在实景三维建模的应用及展望...
【ChatGLM】手把手教你云服务器部署ChatGLM聊天网站,不限次数调用。_chatglm官网
赞
踩
一,演示
私人部署地址:http://ilovechatgpt.cn。
免费使用!无限调用!速度还蛮快呢。
二,ChatGLM介绍
官方地址:https://github.com/THUDM/ChatGLM-6B
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,由基于清华大学 KEG 实验室与智谱 AI 于 2023 年联合训练,可以针对用户的问题和要求提供适当的答复和支持。
它基于 General Language Model 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(具体的部署条件看下章)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
特点:
- 开源
- 支持中文(国内很少有支持中文的开源模型)
- 低成本部署(兼容CPU)
- 具有记忆功能
三,部署条件
经过测试,推荐还是GPU部署,CPU运行的话运行时占用的资源更多,并且速度实在太慢了,自己单独使用的话也不能忍受这么慢的速度。GPU的生成速度才能满足使用的体验。
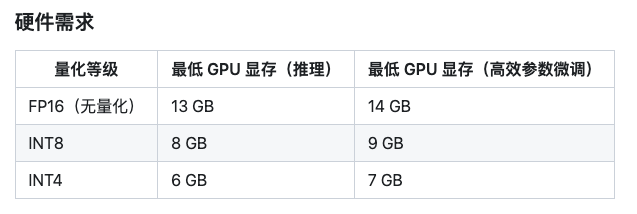
内存不够启动项目的话,进程会被自动kill掉。而且模型启动后占用的现存是远远低于需要的现存的,比如说,我用GPU部署的无量化的ChatGLM2-6B模型,正常来说需要13GB显存,但我完全启动后,只占用了4GB。
四,手把手教你搭建
1. 安装git
# centos 操作系统
yum install git
# ubuntu 操作系统
apt-get update
apt install git
- 1
- 2
- 3
- 4
- 5
2. 克隆地址到本地
git clone https://github.com/THUDM/ChatGLM-6B
# 进入项目文件夹
cd ChatGLM-6B
- 1
- 2
- 3
实在很慢的话,直接去gitee上面搜ChatGLM-6B,找最新的,有很多人把它搬到gitee作为镜像项目。
3. 进入项目,克隆模型文件
模型文件的作用是作为训练集,项目能够本地加载该模型文件并将其用于预测新的自然语言文本。模型文件决定我们能有怎么样的输出结果。
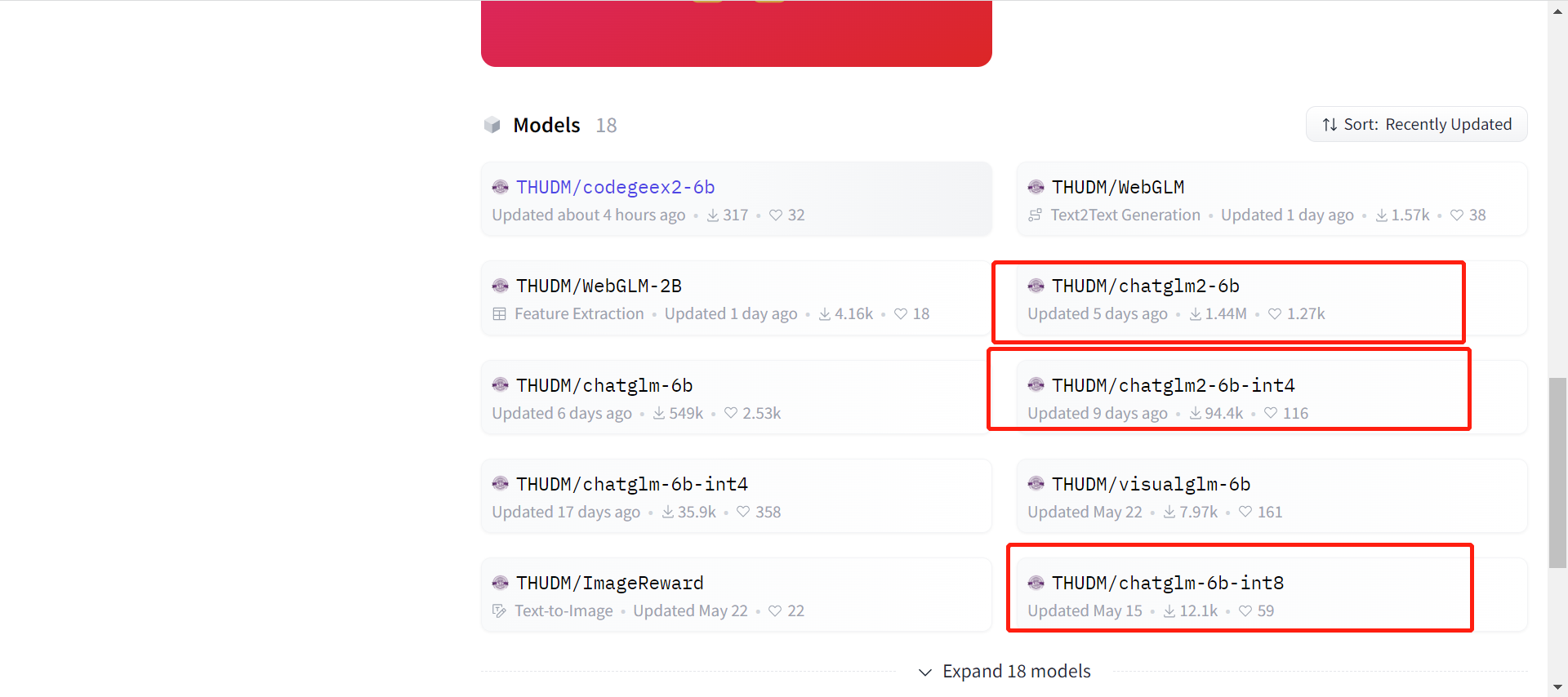
可以根据上面部署条件的需求,来选择项目。我这里以 chatglm2-6b 来部署。
# 注意!后面一定要加上.git。
git clone https://huggingface.co/THUDM/chatglm2-6b.git
- 1
- 2
路径下就会有ChatGLM2-6B的文件夹,我们进入到里面
cd chatglm2-6b
- 1
你会发现模型很大,但是一下子就clone完了,是因为大文件是存储到lfs上面的,需要我们用到git的lfs工具来进行下载。当然,你也可以手动下载后,然后拷贝到服务器上,不过太麻烦,不推荐。
4. git lfs工具安装(已安装的话跳过)
centos安装命令
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.rpm.sh | sudo bash
sudo yum install git-lfs
git lfs install
- 1
- 2
- 3
- 4
- 5
ubuntu安装命令
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
git lfs install
- 1
- 2
- 3
- 4
- 5
5. 克隆模型大文件
git lfs pull
- 1
模型文件都很大,下载时间很久,我建议在晚上的时候,使用如下命令,这样睡一觉,全部都已经下载好了。
# nohup 让程序后台运行,使其不受终端会话的影响而持续运行
nohup git lfs pull &
- 1
- 2
6. 运行web_demo.py
我建议把模型文件夹名字换成model,毕竟容易理解
# 进入到项目文件夹内部
cd ChatGLM-6B
# 改模型名字
mv chatglm2-6b model
- 1
- 2
- 3
- 4
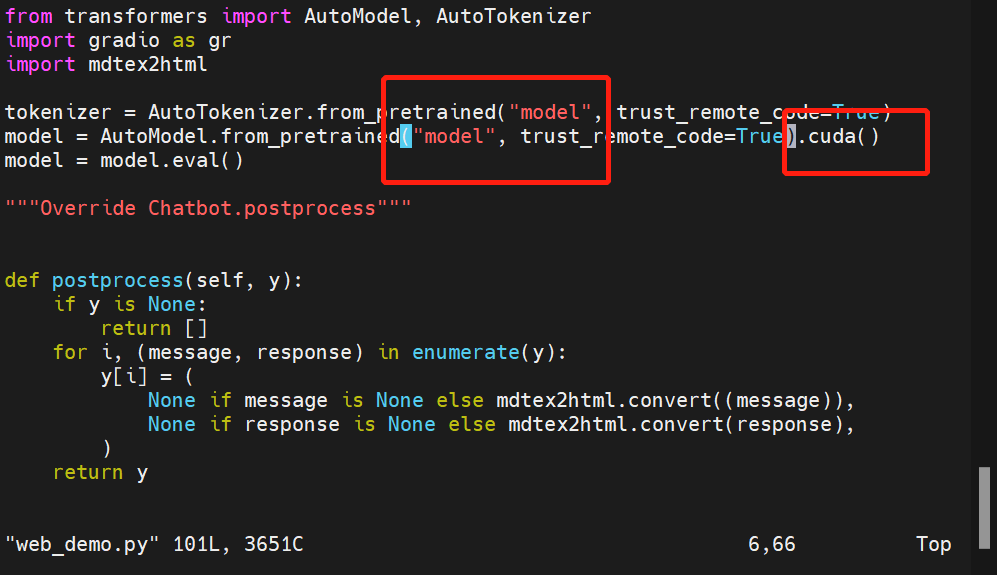
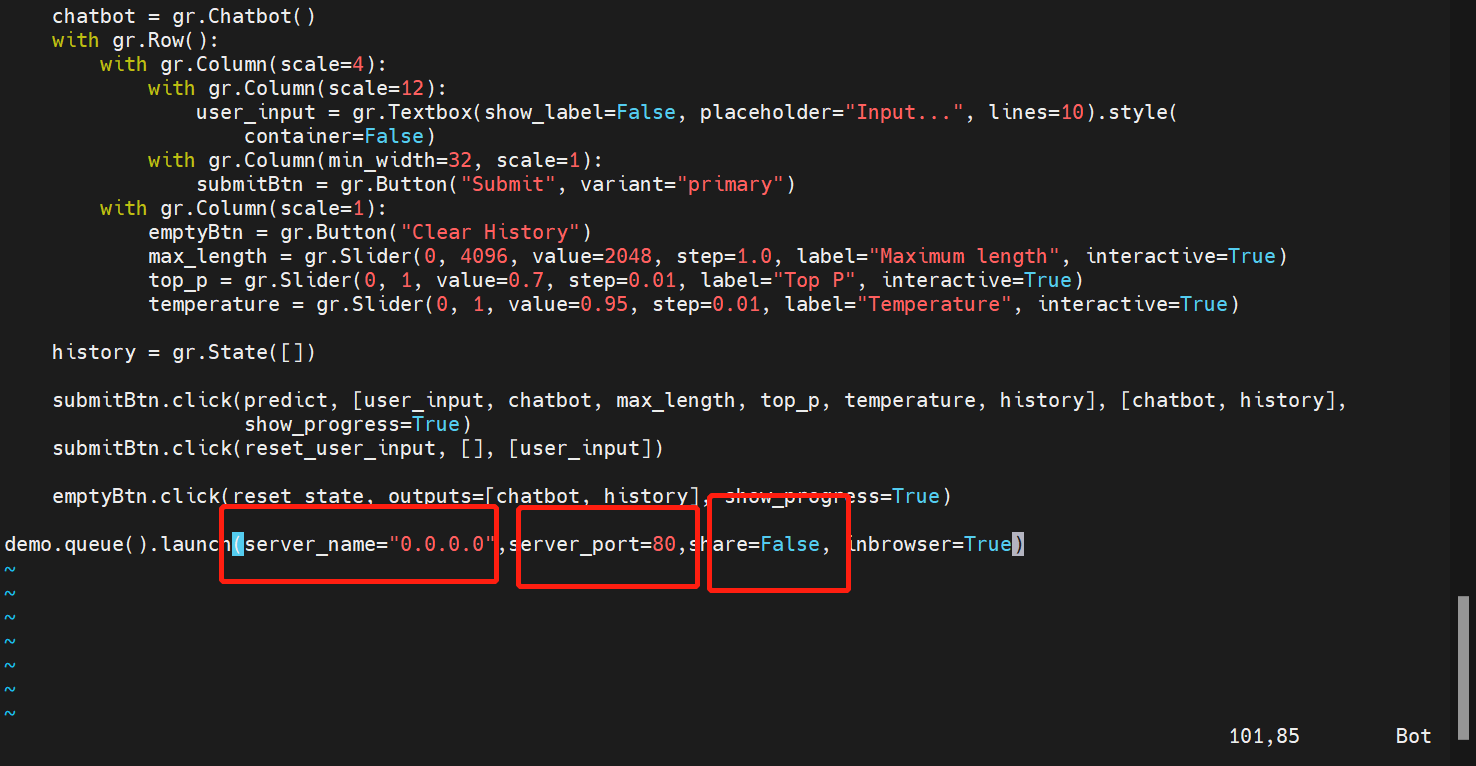
修改官方样例代码
vim web_demo.py
- 1
model为模型路径,也就是刚刚改的。
.cuda() 意味用GPU运行,如果没有GPU,换成 .float() 用CPU运行就可以
- server_name参数指定能够访问的ip,默认不写的话是只能本地127.0.0.1访问
- server_port参数指定web服务端口
- share代表是否让huggingface给你生成一个公网地址,别人能通过该公网地址直接访问。默认只能使用72小时。
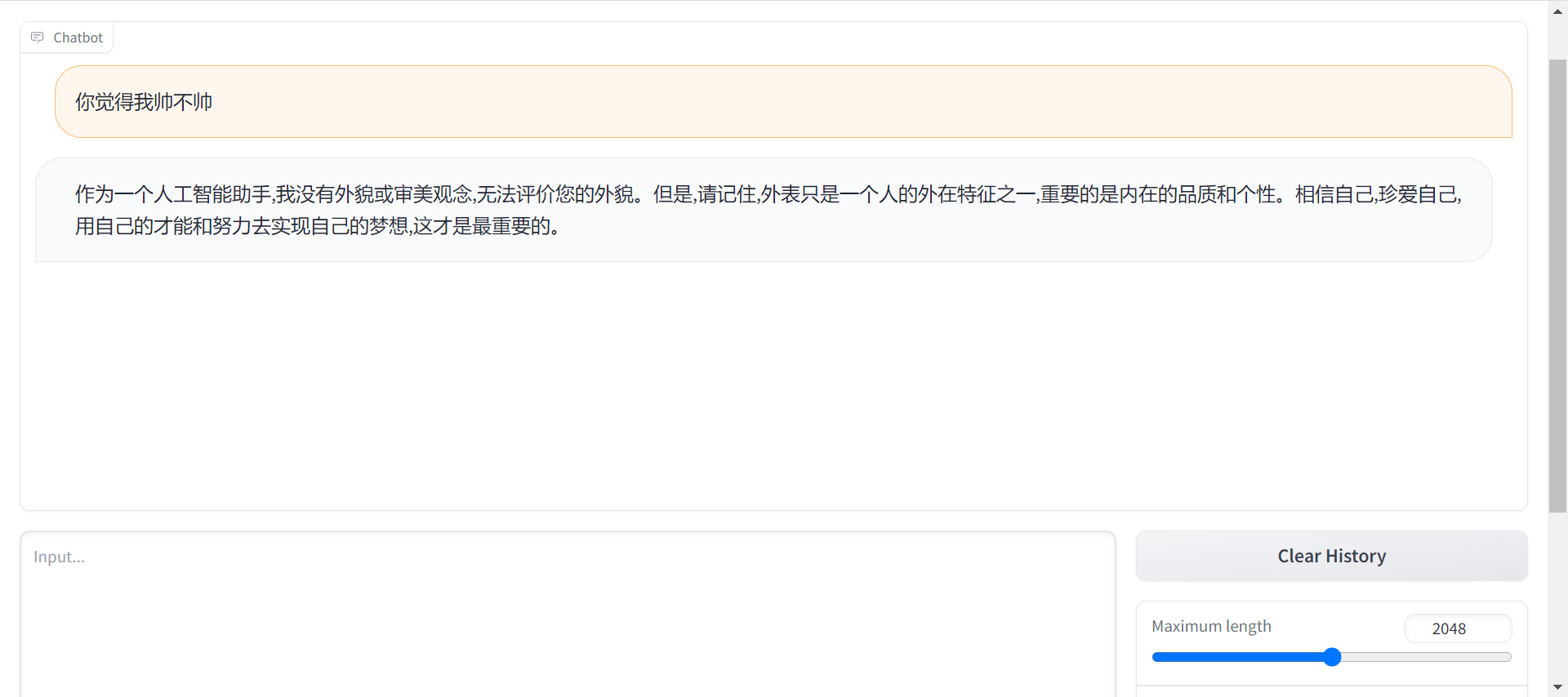
7. 结果
五,补充
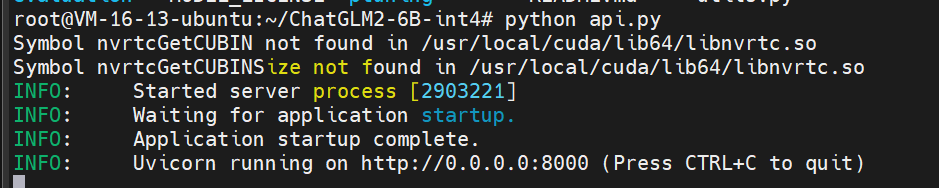
还可以通过命令行窗口交互,运行python cli_demo.py文件
nohup python cli_demo.py &
- 1

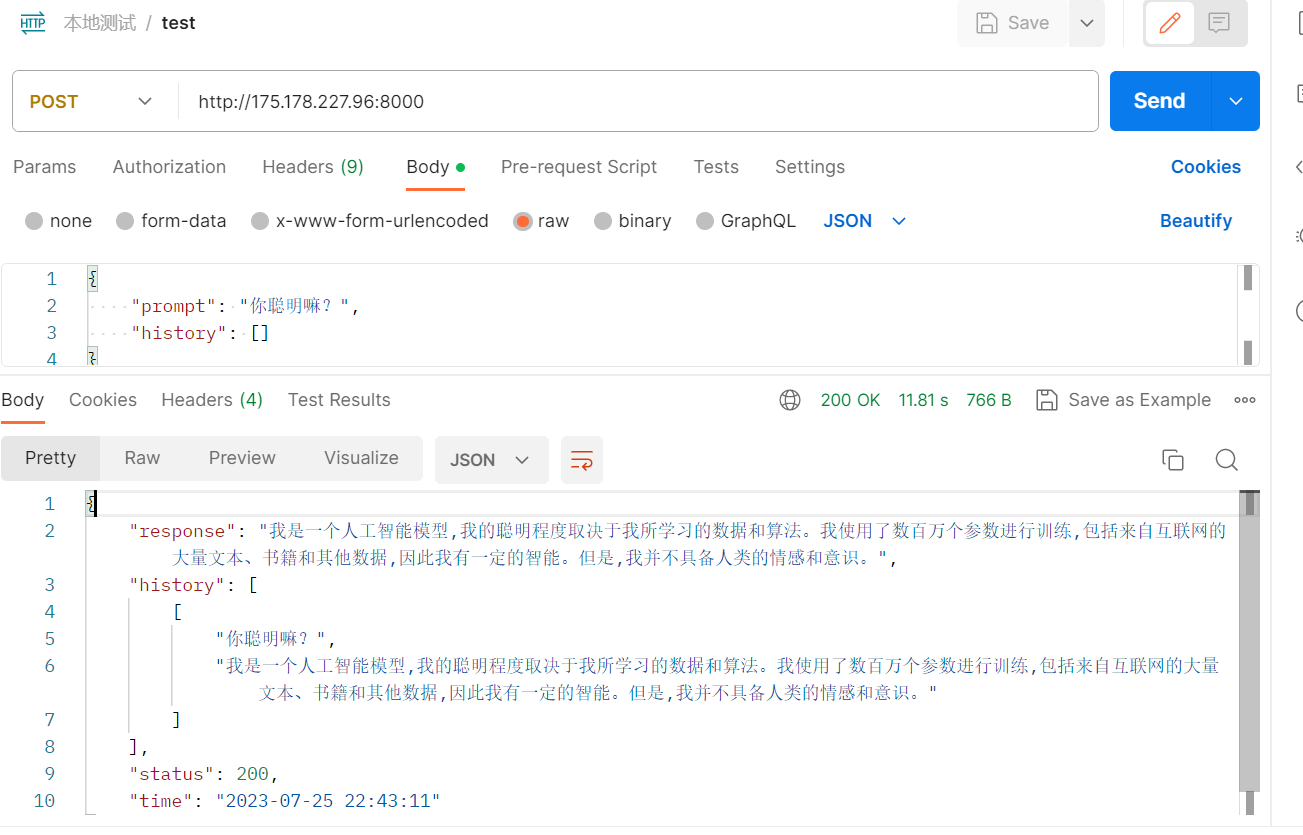
通过模型生成post接口,供其余后台应用直接调用
nohup python api.py &
- 1
欢迎关注我的公众号!
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

