
- 1利用Webrtc-streamer展示rstp视频流_webrtcstreamer
- 2python快速使用(二)python面向过程编程_python支持面向过程编程模式吗
- 3【漏洞复现】致远OA wpsAssistServlet接口存在任意文件上传漏洞_致远oa-wpsassistservlet-post-文件读取
- 4Github项目分享——CS-Notes_csnote
- 5kafka入门篇-使用_kafka.scala
- 6SpringCloud和SpringBoot版本对应关系_springboot和springcloud版本对应关系
- 7【python】网络爬虫基础
- 8基于Mapbox展示GDAL处理的3D行政区划展示实践_map.loadimage 使用fill-extrusion会有位移
- 9告别紧张,轻松应对!公众演讲的实用技巧
- 10Linux操作系统介绍及版本_linux版本
多模态视觉大模型:清华开源CogAgent,重塑GUI Agent领域_清华新ai模型
赞
踩
引言
人工智能技术正以前所未有的速度发展,多模态学习作为AI领域的一个重要分支,正在不断突破技术限制。清华大学最新开源的CogAgent模型,在多模态AI研究中展现了独特的视觉GUI Agent功能和高分辨率处理能力,代表了AI领域的一大进步。
-
Huggingface模型下载:https://huggingface.co/THUDM/cogagent-chat-hf
-
AI快站模型免费加速下载:https://aifasthub.com/models/THUDM/cogagent-chat-hf
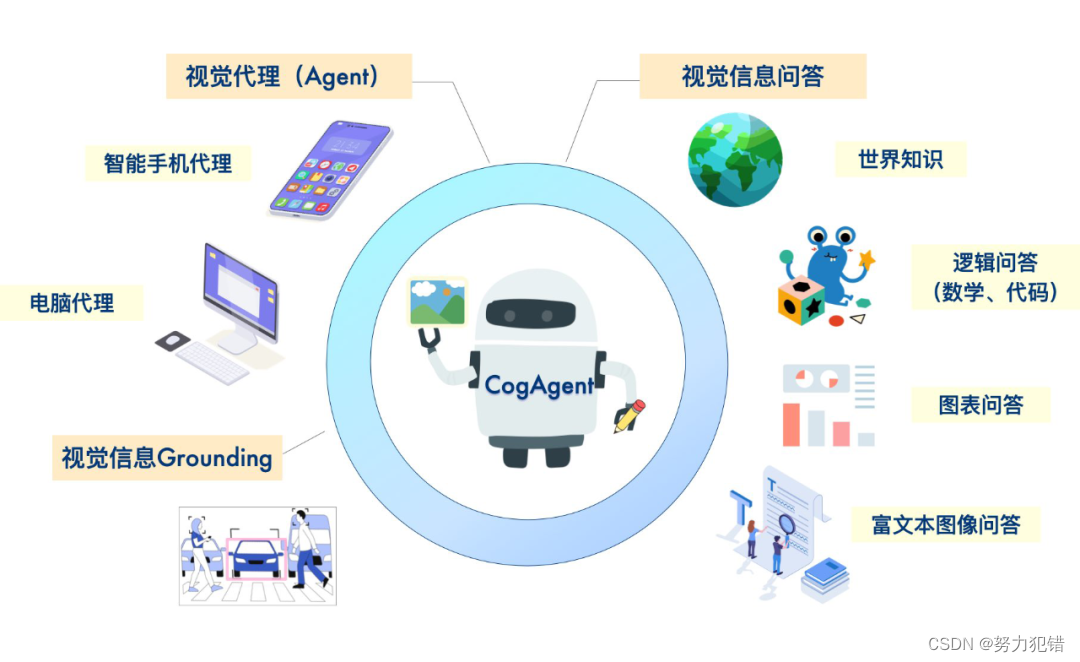
多模态AI的新突破:视觉GUI Agent
CogAgent模型的独特之处在于其视觉GUI Agent的能力,它使用视觉模态而非传统的文本模态对GUI界面进行感知。这种方法更符合人类的直觉交互方式,即通过视觉感知并做出决策。传统的基于语言的Agent,如LLM,受限于其输入形式,无法直接处理非文本信息。CogAgent的视觉GUI Agent则突破了这一限制,能够直接解析和响应GUI环境。多模态大模型CogAgent,可以实现基于视觉的GUI Agent。下图展现了其工作路径与能力。
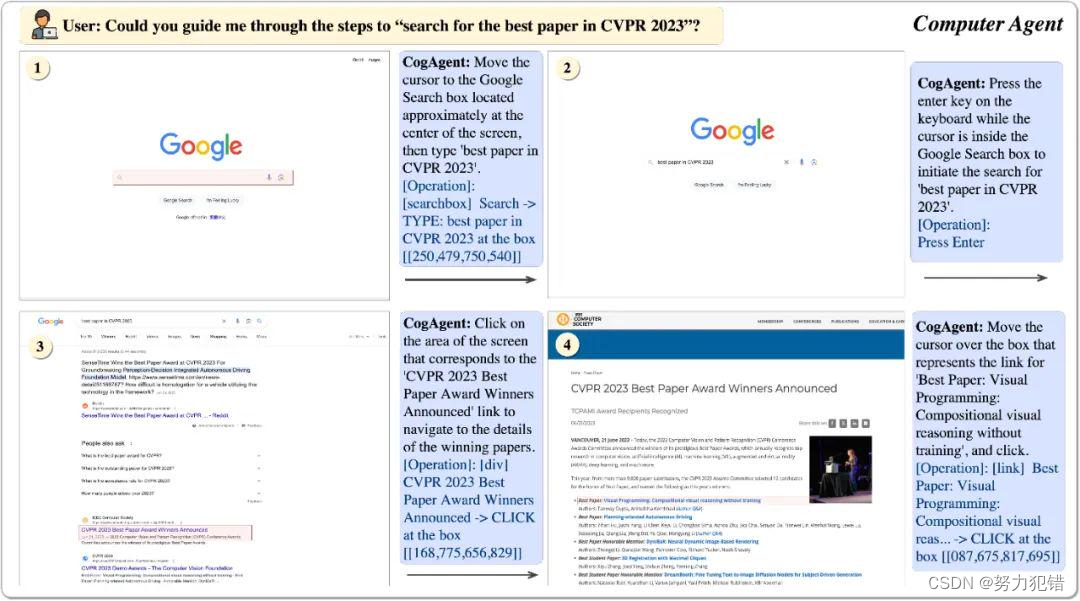
CogAgent模型同时接受当前GUI截图(图像形式)和用户操作目标(文本形式,例如“search for the best paper in CVPR 2023”)作为输入,就能预测详细的动作,和对应操作元素的位置坐标。
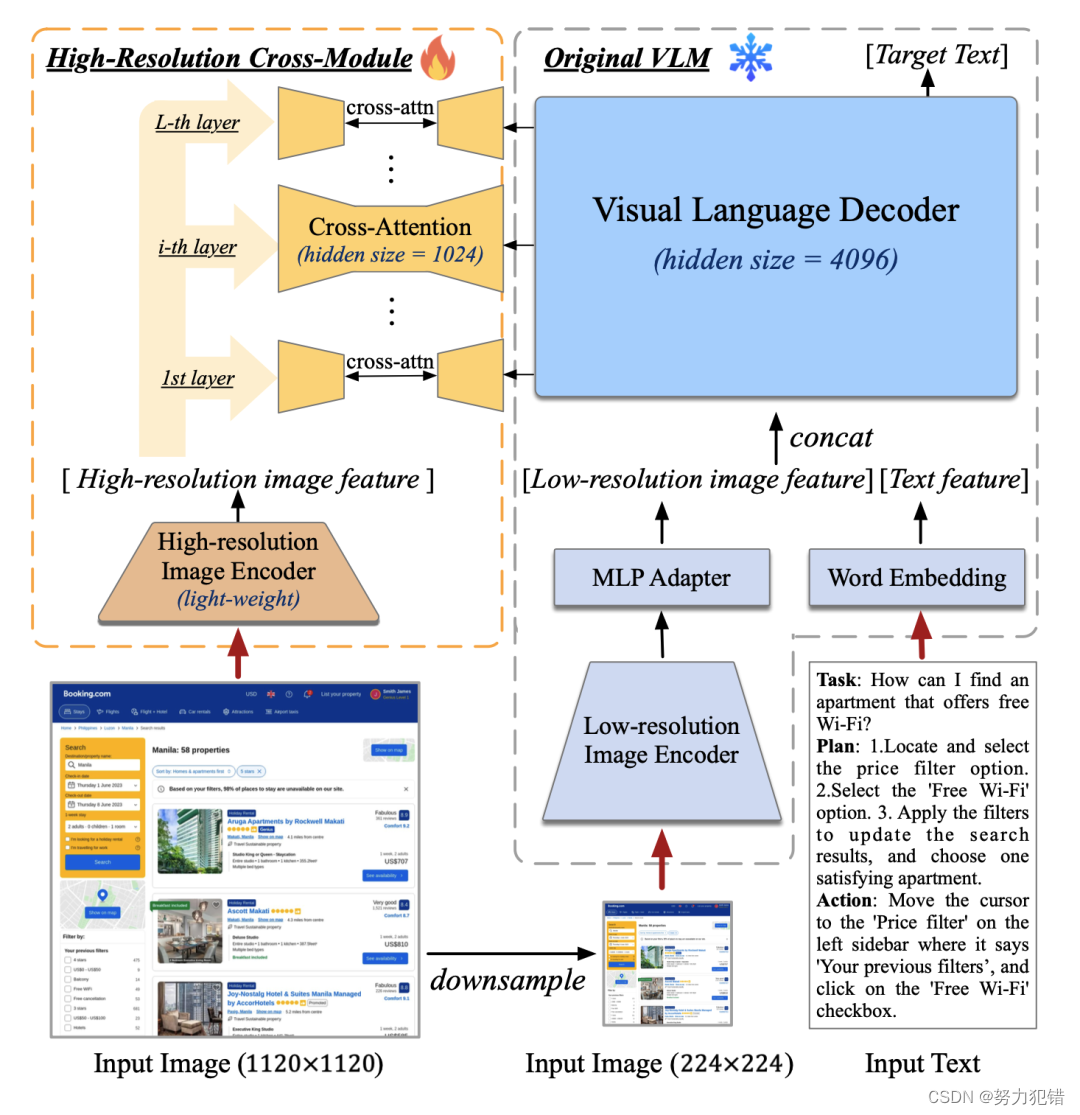
模型结构的创新
在模型结构上,CogAgent采用了独特的“高分辨率交叉注意力模块”,这是一个轻量级的模块,结合了高分辨率小图像编码器和原有的VLM(视觉语言模型)。通过这种设计,CogAgent能够在保持较低计算成本的同时,有效处理高分辨率图像。
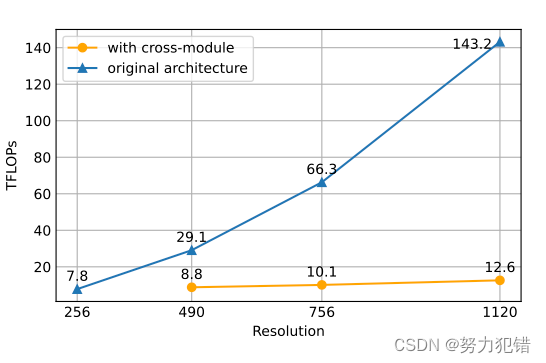
高分辨率图像处理能力
CogAgent在视觉处理方面也实现了显著的提升。模型能够处理高达1120×1120的图像,这在以往的多模态模型中是非常罕见的。这种高分辨率的图像处理能力,使得CogAgent能够更精准地解析复杂的GUI界面,为更高效的交互决策提供支持。
实验与应用成果
在多项实验中,CogAgent展示了其优越的性能。在9个经典图像理解榜单上,CogAgent均取得了领先成绩。此外,在电脑和手机GUI Agent的应用场景中,CogAgent的表现也远超传统的基于LLM的Agent。
-
在网页Agent数据集Mind2Web上的性能
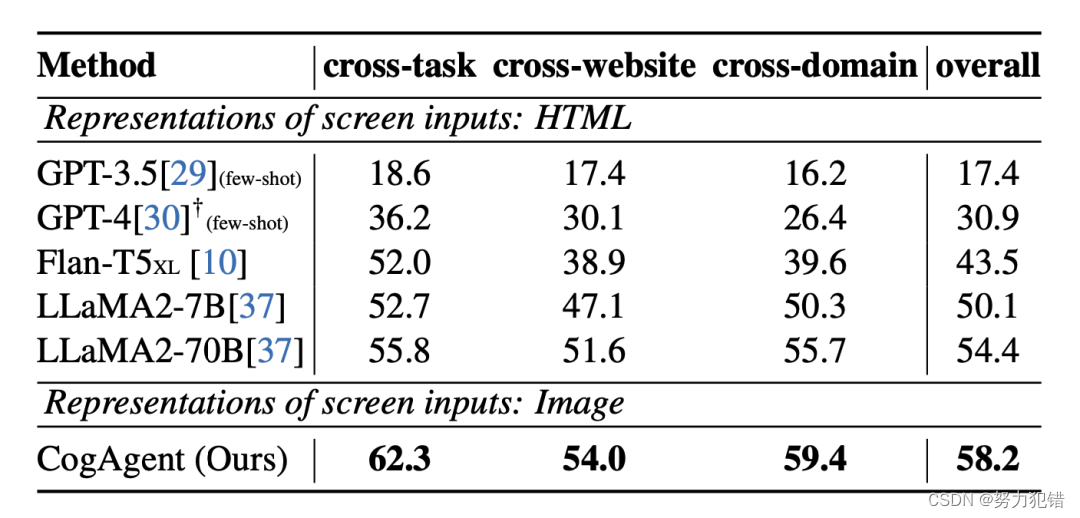
-
在手机Agent数据集AITW上的性能
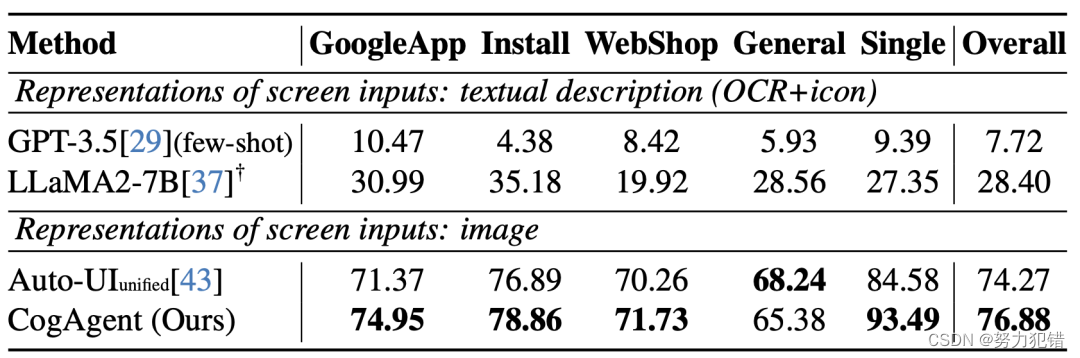
-
在多模态大模型通用榜单MM-VET,POPE上的结果
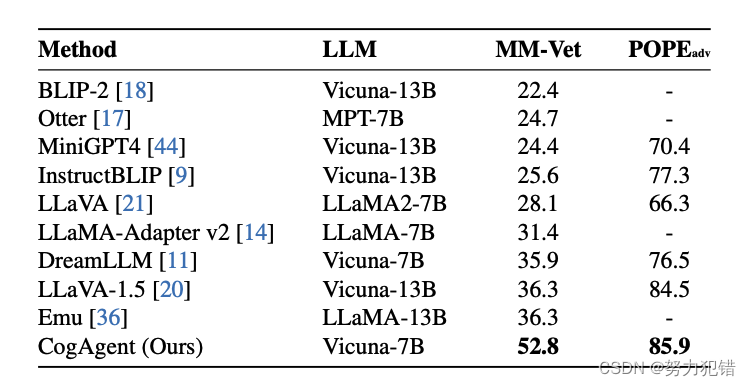
-
展示一个《原神》场景的实例
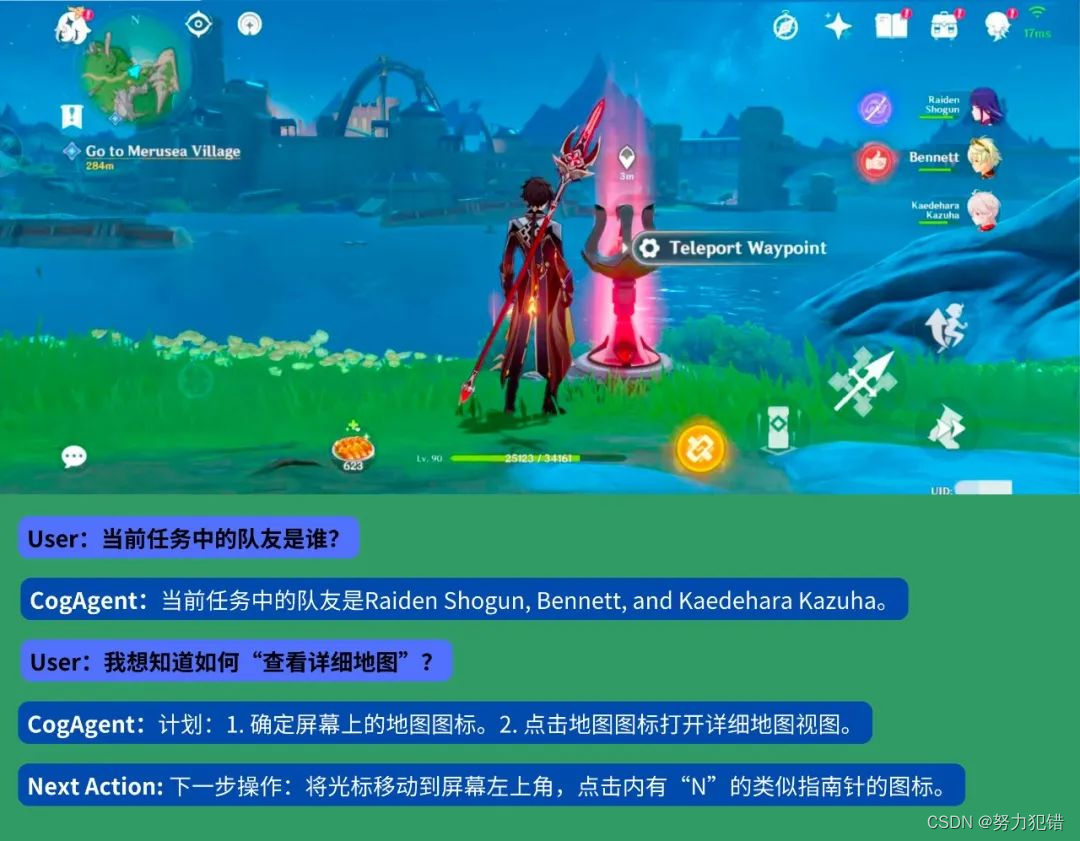
开源与社区贡献
为了促进多模态AI的发展,清华大学将CogAgent-18B模型开源,并提供了网页版Demo。这一举措无疑将加速多模态AI技术的发展,推动其在更广泛领域的应用。
结论
CogAgent的推出,不仅在技术上实现了重大突破,更为多模态AI的研究和应用提供了新的方向。清华大学在多模态AI领域的这一贡献,将会为未来的AI研究和应用带来深远的影响。
模型下载
Huggingface模型下载
https://huggingface.co/THUDM/cogagent-chat-hf
AI快站模型免费加速下载
https://aifasthub.com/models/THUDM/cogagent-chat-hf

