
- 1Sigmoid、Relu、Tanh激活函数
- 2中国联通侯迎龙详解5G边缘计算平台v3.0:兼容异构算力 应对复杂业务挑战
- 3NLP《GPT》_nlp gpt
- 4浅谈高并发-前端优化
- 57步搞定数据清洗-Python数据清洗指南_python数据获取与清洗
- 6MySQL 8:GROUP BY 问题解决 —— 怎么关闭ONLY_FULL_GROUP_BY (详细教程)
- 7AB升级之odex文件首次开机处理_android ro.cp_system_other_odex
- 8kali中的kalitools首页讲解_kali tools
- 9各种神经网络优化算法:从梯度下降,随机梯度下架,批量随机梯度下架,Adagrad,AdaDelta,Adam_神经网络 传统梯度下降 随机梯度下降
- 10小祁的c++大乱斗
详解flink exactly-once和两阶段提交_flink是如何保证exactly-once语义
赞
踩
以下是我们常见的三种 flink 处理语义:
最多一次(At-most-Once):用户的数据只会被处理一次,不管成功还是失败,不会重试也不会重发。
至少一次(At-least-Once):系统会保证数据或事件至少被处理一次。如果中间发生错误或者丢失,那么会从源头重新发送一条然后进入处理系统,所以同一个事件或者消息会被处理多次。
精确一次(Exactly-Once):表示每一条数据只会被精确地处理一次,不多也不少。
Flink 支持“端到端的精确一次”语义。
在这里我解释一下“端到端(End to End)的精确一次”,它指的是 Flink 应用从 Source 端开始到 Sink 端结束,数据必须经过的起始点和结束点。Flink 借助 Flink 提供的分布式快照和两阶段提交才能实现外部系统(必须)支持“精确一次”语义。
也分为三个阶段:
- Source 端:数据从上一阶段进入到 Flink 时,需要保证消息精准一次消费。
- Flink 内部端:这个我们已经了解,利用 Checkpoint 机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性。
- Sink 端:将处理完的数据发送到下一阶段时,需要保证数据能够准确无误发送到下一阶段。
在 Flink 1.4 版本之前,精准一次处理只限于 Flink 应用内,也就是所有的 Operator 完全由 Flink 状态保存并管理的才能实现精确一次处理。但 Flink 处理完数据后大多需要将结果发送到外部系统,比如 Sink 到 Kafka 中,这个过程中 Flink 并不保证精准一次处理。
在 Flink 1.4 版本正式引入了一个里程碑式的功能:两阶段提交 Sink,即 TwoPhaseCommitSinkFunction 函数。该 SinkFunction 提取并封装了两阶段提交协议中的公共逻辑,自此 Flink 搭配特定 Source 和 Sink(如 Kafka 0.11 版)实现精确一次处理语义(英文简称:EOS,即 Exactly-Once Semantics)。
两阶段搭配特定的 source 和 sink(特别是 0.11 版本 Kafka)使得“精确一次处理语义”成为可能。
在 Flink 中两阶段提交的实现方法被封装到了 TwoPhaseCommitSinkFunction 这个抽象类中,我们只需要实现其中的beginTransaction、preCommit、commit、abort 四个方法就可以实现“Exactly-once”的处理语义,实现的方式我们可以在官网中查到:
BeginTransaction,在开启事务之前,我们在目标文件系统的临时目录中创建一个临时文件,后面在处理数据时将数据写入此文件;
PreCommit,在预提交阶段,刷写(flush)文件,然后关闭文件,之后就不能写入到文件了,我们还将为属于下一个检查点的任何后续写入启动新事务;
Commit,在提交阶段,我们将预提交的文件原子性移动到真正的目标目录中,请注意,这会增加输出数据可见性的延迟;
Abort,在中止阶段,我们删除临时文件。
端到端精准一次处理语义(EOS)
以下内容适用于 Flink 1.4 及之后版本
对于 Source 端:Source 端的精准一次处理比较简单,毕竟数据是落到 Flink 中,所以 Flink 只需要保存消费数据的偏移量即可, 如消费 Kafka 中的数据,Flink 将 Kafka Consumer 作为 Source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性。
对于 Sink 端:Sink 端是最复杂的,因为数据是落地到其他系统上的,数据一旦离开 Flink 之后,Flink 就监控不到这些数据了,所以精准一次处理语义必须也要应用于 Flink 写入数据的外部系统,故这些外部系统必须提供一种手段允许提交或回滚这些写入操作,同时还要保证与 Flink Checkpoint 能够协调使用(Kafka 0.11 版本已经实现精确一次处理语义)。
我们以 Flink 与 Kafka 组合为例,Flink 从 Kafka 中读数据,处理完的数据在写入 Kafka 中。
为什么以Kafka为例,第一个原因是目前大多数的 Flink 系统读写数据都是与 Kafka 系统进行的。第二个原因,也是最重要的原因 Kafka 0.11 版本正式发布了对于事务的支持,这是与Kafka交互的Flink应用要实现端到端精准一次语义的必要条件。
当然,Flink 支持这种精准一次处理语义并不只是限于与 Kafka 的结合,可以使用任何 Source/Sink,只要它们提供了必要的协调机制。
两阶段提交协议(2PC)
两阶段提交协议(Two-Phase Commit,2PC)是很常用的解决分布式事务问题的方式,它可以保证在分布式事务中,要么所有参与进程都提交事务,要么都取消,即实现 ACID 中的 A (原子性)。
在数据一致性的环境下,其代表的含义是:要么所有备份数据同时更改某个数值,要么都不改,以此来达到数据的强一致性。
两阶段提交协议中有两个重要角色,协调者(Coordinator)和参与者(Participant),其中协调者只有一个,起到分布式事务的协调管理作用,参与者有多个。
顾名思义,两阶段提交将提交过程划分为连续的两个阶段:表决阶段(Voting)和提交阶段(Commit)。
两阶段提交协议过程如下图所示:
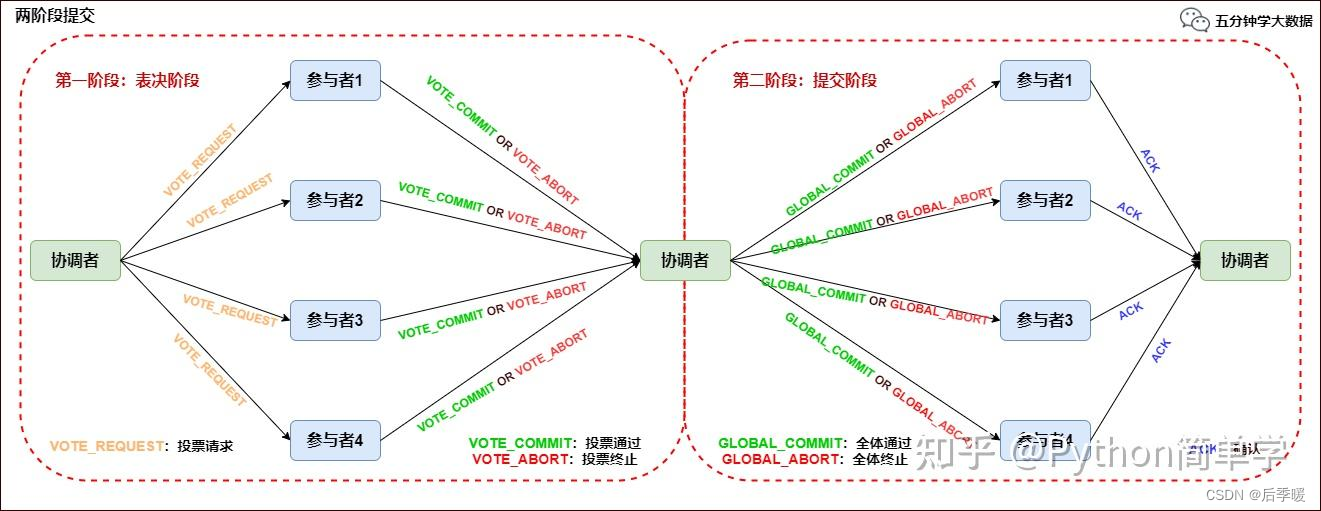
第一阶段:表决阶段
- 协调者向所有参与者发送一个 VOTE_REQUEST 消息。
- 当参与者接收到 VOTE_REQUEST 消息,向协调者发送 VOTE_COMMIT 消息作为回应,告诉协调者自己已经做好准备提交准备,如果参与者没有准备好或遇到其他故障,就返回一个 VOTE_ABORT 消息,告诉协调者目前无法提交事务。
第二阶段:提交阶段
- 协调者收集来自各个参与者的表决消息。如果所有参与者一致认为可以提交事务,那么协调者决定事务的最终提交,在此情形下协调者向所有参与者发送一个 GLOBAL_COMMIT 消息,通知参与者进行本地提交;如果所有参与者中有任意一个返回消息是 VOTE_ABORT,协调者就会取消事务,向所有参与者广播一条 GLOBAL_ABORT 消息通知所有的参与者取消事务。
- 每个提交了表决信息的参与者等候协调者返回消息,如果参与者接收到一个 GLOBAL_COMMIT 消息,那么参与者提交本地事务,否则如果接收到 GLOBAL_ABORT 消息,则参与者取消本地事务。
两阶段提交协议在 Flink 中的应用
Flink 的两阶段提交思路:
我们从 Flink 程序启动到消费 Kafka 数据,最后到 Flink 将数据 Sink 到 Kafka 为止,来分析 Flink 的精准一次处理。
- 当 Checkpoint 启动时,JobManager 会将检查点分界线(checkpoint battier)注入数据流,checkpoint barrier 会在算子间传递下去,如下如所示:

- Source 端:Flink Kafka Source 负责保存 Kafka 消费 offset,当 Chckpoint 成功时 Flink 负责提交这些写入,否则就终止取消掉它们,当 Chckpoint 完成位移保存,它会将 checkpoint barrier(检查点分界线) 传给下一个 Operator,然后每个算子会对当前的状态做个快照,保存到状态后端(State Backend)。
对于 Source 任务而言,就会把当前的 offset 作为状态保存起来。下次从 Checkpoint 恢复时,Source 任务可以重新提交偏移量,从上次保存的位置开始重新消费数据,如下图所示:

- Slink 端:从 Source 端开始,每个内部的 transform 任务遇到 checkpoint barrier(检查点分界线)时,都会把状态存到 Checkpoint 里。数据处理完毕到 Sink 端时,Sink 任务首先把数据写入外部 Kafka,这些数据都属于预提交的事务(还不能被消费),此时的 Pre-commit 预提交阶段下 Data Sink 在保存状态到状态后端的同时还必须预提交它的外部事务,如下图所示:

- 当所有算子任务的快照完成(所有创建的快照都被视为是 Checkpoint 的一部分),也就是这次的 Checkpoint 完成时,JobManager 会向所有任务发通知,确认这次 Checkpoint 完成,此时 Pre-commit 预提交阶段才算完成。才正式到两阶段提交协议的第二个阶段:commit 阶段。该阶段中 JobManager 会为应用中每个 Operator 发起 Checkpoint 已完成的回调逻辑。
本例中的 Data Source 和窗口操作无外部状态,因此在该阶段,这两个 Opeartor 无需执行任何逻辑,但是 Data Sink 是有外部状态的,此时我们必须提交外部事务,当 Sink 任务收到确认通知,就会正式提交之前的事务,Kafka 中未确认的数据就改为“已确认”,数据就真正可以被消费了,如下图所示:

注:Flink 由 JobManager 协调各个 TaskManager 进行 Checkpoint 存储,Checkpoint 保存在 StateBackend(状态后端) 中,默认 StateBackend 是内存级的,也可以改为文件级的进行持久化保存。
最后,一张图总结下 Flink 的 EOS:

两阶段提交的问题:
- 性能问题:无论是在第一阶段的过程中,还是在第二阶段,所有的参与者资源和协调者资源都是被锁住的,只有当所有节点准备完毕,事务协调者才会通知进行全局提交,参与者进行本地事务提交后才会释放资源。这样的过程会比较漫长,对性能影响比较大。
- 单节点故障:由于协调者的重要性,一旦协调者发生故障。参与者会一直阻塞下去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作。(虽然协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)。

