
- 1二部图最大权匹配_SIGIR 2019 开源论文:基于图神经网络的协同过滤算法
- 2Stable Video Diffusion(SVD)视频生成模型发布 1.1版_下载stable-video-diffusion-img2vid-xt-1-1
- 3视频生成Sora的从零复现:从Latte、Open-Sora 1.0到StreamingT2V_open-sora 详解
- 4自然语言处理入门读物_自然语言处理入门何晗pdf
- 5【论文笔记】Learning Rich Features for Image Manipulation Detection(CVPR2018)
- 6chatgpt是目前最厉害的人工智能问答AI,没有之一!_openai发布chatgpt,丰富的知识,流畅的回答,再次引起全球轰动
- 7腾讯开源视频生成新工具,论文还没发先上代码的那种
- 8基于C#分步式聊天系统的在线视频直播系统 之 数据库操作基类 - 通用于Windows及Linux的Mono环境_c# 直播源码
- 9springboot + junit + mockito真香, 可 springboot 是创建 @MockBean/@SpyBean 代理对象的呢?
- 10基于Python的网上求职招聘系统设计与实现(Django框架) 研究背景与意义、国内外研究现状_招聘管理系统的国外现状具体的研究数据
PyTorch框架学习笔记_pytorch学习笔记
赞
踩
@LOVELWY
第一章:基本数据:Tensor
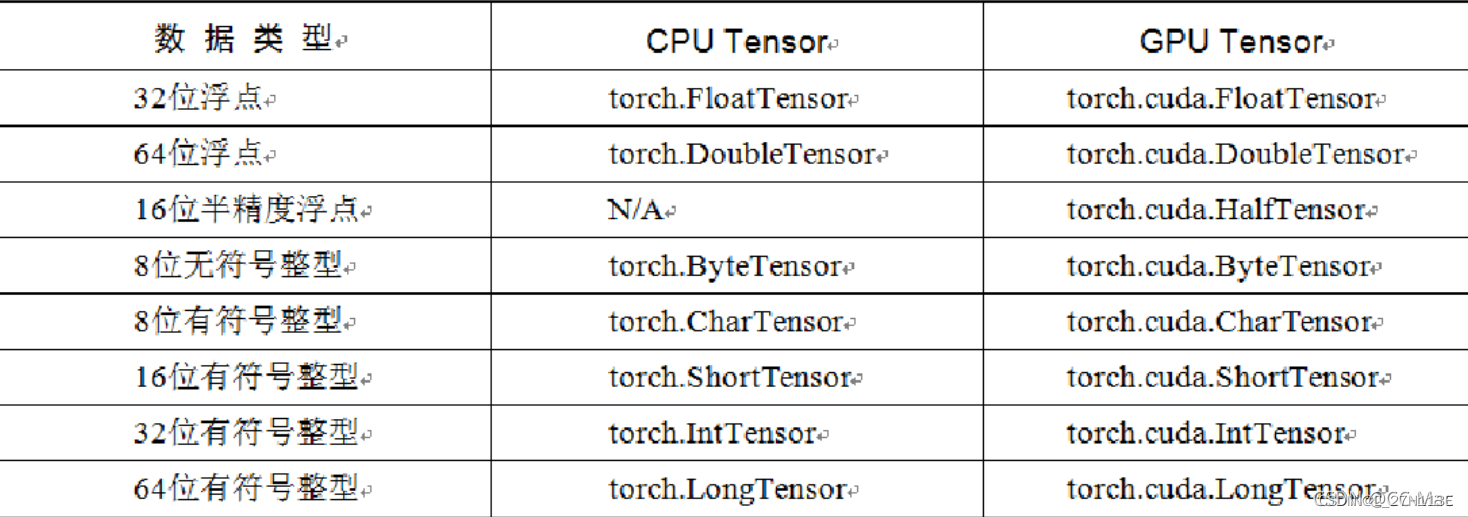
Tensor,即张量,是Pytorch中基本操作对象,可以看作是包含单一数据类型元素的多维矩阵。分为CPU Tensor和GPU Tensor,Tensor支持GPU的加速。
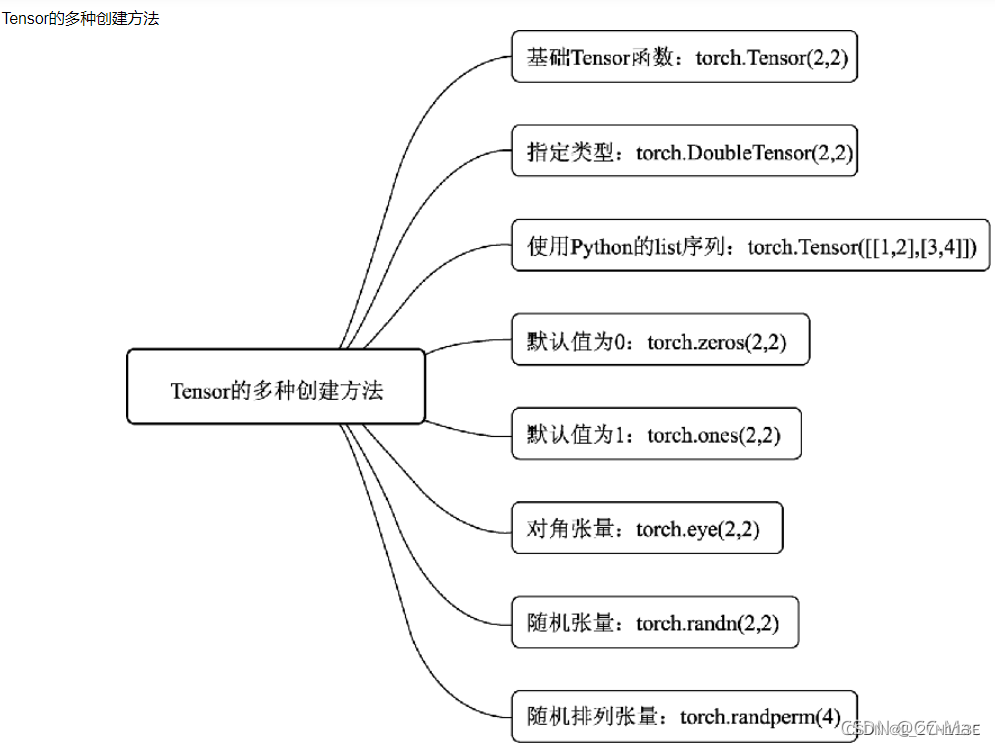
1.1创建Tensor
1.1.1torch.range
torch.range用于生成数据类型为浮点型且起始范围和结束范围的Tensor,参数分别为起始值、结束值和步长。
torch.tensor(起始值,结束值,步长)
- 1
1.2Tensor的运算
1.2.1torch.abs
输入参数(Tensor类型),输出绝对值。
import torch
a=torch.Tensor([-1,-2])
b=torch.abs(a)
print(b)
- 1
- 2
- 3
- 4
得到:
{【1,2】}
- 1
1.2.2torch.add
将参数传递到torch.add后返回输入参数的求和结果作为输出,输入参数既可以全部是Tensor数据类型的变量,也可以一个是Tensor数据类型的变量,另一个是标量。
1.2.3torch.clamp
torch.clamp是对输入参数按照自定义的范围进行裁剪,最后将参数裁剪的结果作为输出,所以输入参数一共有三个,分别是需要进行裁剪的Tensor数据类型的变量、裁剪的上上边界和裁剪的下边界,具体的裁剪过程是:使用变量中的每个元素分别和裁剪的上边界及裁剪的下边界的值进行比较,如果元素的值小于裁剪的下边界的值,该元素被重写成裁剪的下边界的值;同理,如果元素的值大于裁剪的上边界的值,该元素就被重写成裁剪的上边界的值。
1.2.4torch.div
除法,参与运算的参数可以全部是Tensor数据类型的变量,也可以是Tensor数据类型的变量和标量的组合。
1.2.5torch.pow
幂运算,参与运算的参数可以全部是Tensor数据类型的变量,也可以是Tensor数据类型的变量和标量的组合。
1.2.6torch.mm
矩阵乘法。
1.2.7torch.mv
矩阵和向量乘法,被传入的第1个参数代表矩阵,第2个参数代表向量,顺序不能颠倒。
第二章:神经网络工具箱torch.nn
torch.autograd库虽然实现了自动求导与梯度反向传播,但如果我们要完成一个模型的训练,仍需要手写参数的自动更新、训练过程的控制等,还是不够便利。为此,PyTorch进一步提供了集成度更高的模块化接口torch.nn,该接口构建于Autograd之上,提供了网络模组、优化器和初始化策略等一系列功能。
2.1nn.Module类
nn.Module是PyTorch提供的神经网络类,并在类中实现了网络各层的定义及前向计算与反向传播机制。在实际使用时,如果想要实现某个神经网络,只需继承nn.Module,在初始化中定义模型结构与参数,在函数forward()中编写网络前向过程即可。
1.nn.Parameter函数
2.forward()函数与反向传播
3.多个Module的嵌套
4.nn.Module与nn.functional库
5.nn.Sequential()模块
#这里用torch.nn实现一个MLP from torch import nn class MLP(nn.Module): def __init__(self, in_dim, hid_dim1, hid_dim2, out_dim): super(MLP, self).__init__() self.layer = nn.Sequential( nn.Linear(in_dim, hid_dim1), nn.ReLU(), nn.Linear(hid_dim1, hid_dim2), nn.ReLU(), nn.Linear(hid_dim2, out_dim), nn.ReLU() ) def forward(self, x): x = self.layer(x) return x

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
2.2搭建简易神经网络
使用Torch搭建一个简易的神经网络
设置输入节点为1000,隐藏层的节点为100,输出层的节点为10
输入100个具有1000个特征的数据,经过隐藏层后变成100个具有10个分类结果的特征,然后将得到的结果后向传播
import torch batch_n = 100#一个批次输入数据的数量 hidden_layer = 100 input_data = 1000#每个数据的特征为1000 output_data = 10 x = torch.randn(batch_n,input_data) y = torch.randn(batch_n,output_data) w1 = torch.randn(input_data,hidden_layer) w2 = torch.randn(hidden_layer,output_data) epoch_n = 20 lr = 1e-6 for epoch in range(epoch_n): h1=x.mm(w1)#(100,1000)*(1000,100)-->100*100 print(h1.shape) h1=h1.clamp(min=0) y_pred = h1.mm(w2) loss = (y_pred-y).pow(2).sum() print("epoch:{},loss:{:.4f}".format(epoch,loss)) grad_y_pred = 2*(y_pred-y) grad_w2 = h1.t().mm(grad_y_pred) grad_h = grad_y_pred.clone() grad_h = grad_h.mm(w2.t()) grad_h.clamp_(min=0)#将小于0的值全部赋值为0,相当于sigmoid grad_w1 = x.t().mm(grad_h) w1 = w1 -lr*grad_w1 w2 = w2 -lr*grad_w2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
结果显示:
torch.Size([100, 100]) epoch:0,loss:112145.7578 torch.Size([100, 100]) epoch:1,loss:110014.8203 torch.Size([100, 100]) epoch:2,loss:107948.0156 torch.Size([100, 100]) epoch:3,loss:105938.6719 torch.Size([100, 100]) epoch:4,loss:103985.1406 torch.Size([100, 100]) epoch:5,loss:102084.9609 torch.Size([100, 100]) epoch:6,loss:100236.9844 torch.Size([100, 100]) epoch:7,loss:98443.3359 torch.Size([100, 100]) epoch:8,loss:96699.5938 torch.Size([100, 100]) epoch:9,loss:95002.5234 torch.Size([100, 100]) epoch:10,loss:93349.7969 torch.Size([100, 100]) epoch:11,loss:91739.8438 torch.Size([100, 100]) epoch:12,loss:90171.6875 torch.Size([100, 100]) epoch:13,loss:88643.1094 torch.Size([100, 100]) epoch:14,loss:87152.6406 torch.Size([100, 100]) epoch:15,loss:85699.4297 torch.Size([100, 100]) epoch:16,loss:84282.2500 torch.Size([100, 100]) epoch:17,loss:82899.9062 torch.Size([100, 100]) epoch:18,loss:81550.3984 torch.Size([100, 100]) epoch:19,loss:80231.1484
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
2.3torch实现一个完整的神经网络
2.3.1torch.autograd和Variable
torch.autograd包的主要功能就是完成神经网络后向传播中的链式求导,手动去写这些求导程序会导致重复造轮子的现象。
自动梯度的功能过程大致为:先通过输入的Tensor数据类型的变量在神经网络的前向传播过程中生成一张计算图,然后根据这个计算图和输出结果精确计算出每一个参数需要更新的梯度,并通过完成后向传播完成对参数的梯度更新。
完成自动梯度需要用到的torch.autograd包中的Variable类对我们定义的Tensor数据类型变量进行封装,在封装后,计算图中的各个节点就是一个Variable对象,这样才能应用自动梯度的功能。
下面我们使用autograd实现一个二层结构的神经网络模型
import torch from torch.autograd import Variable batch_n = 100#一个批次输入数据的数量 hidden_layer = 100 input_data = 1000#每个数据的特征为1000 output_data = 10 x = Variable(torch.randn(batch_n,input_data),requires_grad=False) y = Variable(torch.randn(batch_n,output_data),requires_grad=False) #用Variable对Tensor数据类型变量进行封装的操作。requires_grad如果是False,表示该变量在进行自动梯度计算的过程中不会保留梯度值。 w1 = Variable(torch.randn(input_data,hidden_layer),requires_grad=True) w2 = Variable(torch.randn(hidden_layer,output_data),requires_grad=True) #学习率和迭代次数 epoch_n=50 lr=1e-6 for epoch in range(epoch_n): h1=x.mm(w1)#(100,1000)*(1000,100)-->100*100 print(h1.shape) h1=h1.clamp(min=0) y_pred = h1.mm(w2) #y_pred = x.mm(w1).clamp(min=0).mm(w2) loss = (y_pred-y).pow(2).sum() print("epoch:{},loss:{:.4f}".format(epoch,loss.data)) # grad_y_pred = 2*(y_pred-y) # grad_w2 = h1.t().mm(grad_y_pred) loss.backward()#后向传播 # grad_h = grad_y_pred.clone() # grad_h = grad_h.mm(w2.t()) # grad_h.clamp_(min=0)#将小于0的值全部赋值为0,相当于sigmoid # grad_w1 = x.t().mm(grad_h) w1.data -= lr*w1.grad.data w2.data -= lr*w2.grad.data w1.grad.data.zero_() w2.grad.data.zero_() # w1 = w1 -lr*grad_w1 # w2 = w2 -lr*grad_w2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
2.3.2Variable-Pytorch中的数据类型
实际上,Variable和Tensor没有太大的区别,但是,属于不同的数据类型,Variable对象具有更多的属性。
1.Variable变量具备自动求导的功能。
2.Variable类型的变量会被放到一个计算图中,Variable类型的变量具有三个属性:data、grad、grad_fn:
data:取出Variable中的Tensor数值
grad:是variable的反向传播梯度,也就是求导的操作
grad_fn:是指得到这个Variable所要进行的操作。
2.3.3自定义传播函数
其实除了可以采用自动梯度方法,我们还可以通过构建一个继承了torch.nn.Module的新类,来完成对前向传播函数和后向传播函数的重写。在这个新类中,我们使用forward作为前向传播函数的关键字,使用backward作为后向传播函数的关键字。
下面我们进行自定义传播函数:
import torch from torch.autograd import Variable batch_n = 64#一个批次输入数据的数量 hidden_layer = 100 input_data = 1000#每个数据的特征为1000 output_data = 10 class Model(torch.nn.Module):#完成类继承的操作 def __init__(self): super(Model,self).__init__()#类的初始化 def forward(self,input,w1,w2): x = torch.mm(input,w1) x = torch.clamp(x,min = 0) x = torch.mm(x,w2) return x def backward(self): pass model = Model() x = Variable(torch.randn(batch_n,input_data),requires_grad=False) y = Variable(torch.randn(batch_n,output_data),requires_grad=False) #用Variable对Tensor数据类型变量进行封装的操作。requires_grad如果是F,表示该变量在进行自动梯度计算的过程中不会保留梯度值。 w1 = Variable(torch.randn(input_data,hidden_layer),requires_grad=True) w2 = Variable(torch.randn(hidden_layer,output_data),requires_grad=True) epoch_n=30 for epoch in range(epoch_n): y_pred = model(x,w1,w2) loss = (y_pred-y).pow(2).sum() print("epoch:{},loss:{:.4f}".format(epoch,loss.data)) loss.backward() w1.data -= lr*w1.grad.data w2.data -= lr*w2.grad.data w1.grad.data.zero_() w2.grad.data.zero_()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
2.4torch.nn
2.4.1torch.nn.Sequential
torch.nn.Sequential类是torch.nn中的一种序列容器,通过在容器中嵌套各种实现神经网络模型的搭建,最主要的是,参数会按照我们定义好的序列自动传递下去。
import torch from torch.autograd import Variable batch_n = 100#一个批次输入数据的数量 hidden_layer = 100 input_data = 1000#每个数据的特征为1000 output_data = 10 x = Variable(torch.randn(batch_n,input_data),requires_grad=False) y = Variable(torch.randn(batch_n,output_data),requires_grad=False) #用Variable对Tensor数据类型变量进行封装的操作。requires_grad如果是F,表示该变量在进行自动梯度计算的过程中不会保留梯度值。 models = torch.nn.Sequential( torch.nn.Linear(input_data,hidden_layer), torch.nn.ReLU(), torch.nn.Linear(hidden_layer,output_data) ) #torch.nn.Sequential括号内就是我们搭建的神经网络模型的具体结构,Linear完成从隐藏层到输出层的线性变换,再用ReLU激活函数激活 #torch.nn.Sequential类是torch.nn中的一种序列容器,通过在容器中嵌套各种实现神经网络模型的搭建, #最主要的是,参数会按照我们定义好的序列自动传递下去。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2.4.2torch.nn.Linear
torch.nn.Linear类用于定义模型的线性层,即完成前面提到的不同的层之间的线性变换。 线性层接受的参数有3个:分别是输入特征数、输出特征数、是否使用偏置,默认为True,使用torch.nn.Linear类,会自动生成对应维度的权重参数和偏置,对于生成的权重参数和偏置,我们的模型默认使用一种比之前的简单随机方式更好的参数初始化方式。
2.4.3torch.nn.ReLU
torch.nn.ReLU属于非线性激活分类,在定义时默认不需要传入参数。当然,在torch.nn包中还有许多非线性激活函数类可供选择,比如PReLU、LeaKyReLU、Tanh、Sigmoid、Softmax等。
2.4.4torch.nn.MSELoss
torch.nn.MSELoss类使用均方误差函数对损失值进行计算,定义类的对象时不用传入任何参数,但在使用实例时需要输入两个维度一样的参数方可进行计算。
import torch
from torch.autograd import Variable
loss_f = torch.nn.MSELoss()
x = Variable(torch.randn(100,100))
y = Variable(torch.randn(100,100))
loss = loss_f(x,y)
loss.data
#tensor(1.9529)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.4.5torch.nn.L1Loss
torch.nn.L1Loss类使用平均绝对误差函数对损失值进行计算,定义类的对象时不用传入任何参数,但在使用实例时需要输入两个维度一样的参数方可进行计算。
2.4.6torch.nn.CrossEntropyLoss
torch.nn.CrossEntropyLoss类用于计算交叉熵,定义类的对象时不用传入任何参数,但在使用实例时需要输入两个满足交叉熵的计算条件的参数。
2.5使用损失函数的神经网络
import torch from torch.autograd import Variable import torch from torch.autograd import Variable loss_fn = torch.nn.MSELoss() x = Variable(torch.randn(100,100)) y = Variable(torch.randn(100,100)) loss = loss_fn(x,y) batch_n = 100#一个批次输入数据的数量 hidden_layer = 100 input_data = 1000#每个数据的特征为1000 output_data = 10 x = Variable(torch.randn(batch_n,input_data),requires_grad=False) y = Variable(torch.randn(batch_n,output_data),requires_grad=False) #用Variable对Tensor数据类型变量进行封装的操作。requires_grad如果是F,表示该变量在进行自动梯度计算的过程中不会保留梯度值。 models = torch.nn.Sequential( torch.nn.Linear(input_data,hidden_layer), torch.nn.ReLU(), torch.nn.Linear(hidden_layer,output_data) ) #torch.nn.Sequential括号内就是我们搭建的神经网络模型的具体结构,Linear完成从隐藏层到输出层的线性变换,再用ReLU激活函数激活 #torch.nn.Sequential类是torch.nn中的一种序列容器,通过在容器中嵌套各种实现神经网络模型的搭建, #最主要的是,参数会按照我们定义好的序列自动传递下去。 for epoch in range(epoch_n): y_pred = models(x) loss = loss_fn(y_pred,y) if epoch%1000 == 0: print("epoch:{},loss:{:.4f}".format(epoch,loss.data)) models.zero_grad() loss.backward() for param in models.parameters(): param.data -= param.grad.data*lr
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
2.6torch.optim
import torch from torch.autograd import Variable torch.optim包提供非常多的可实现参数自动优化的类,如SGD、AdaGrad、RMSProp、Adam等 使用自动优化的类实现神经网络: batch_n = 100#一个批次输入数据的数量 hidden_layer = 100 input_data = 1000#每个数据的特征为1000 output_data = 10 x = Variable(torch.randn(batch_n,input_data),requires_grad=False) y = Variable(torch.randn(batch_n,output_data),requires_grad=False) #用Variable对Tensor数据类型变量进行封装的操作。requires_grad如果是F,表示该变量在进行自动梯度计算的过程中不会保留梯度值。 models = torch.nn.Sequential( torch.nn.Linear(input_data,hidden_layer), torch.nn.ReLU(), torch.nn.Linear(hidden_layer,output_data) ) #torch.nn.Sequential括号内就是我们搭建的神经网络模型的具体结构,Linear完成从隐藏层到输出层的线性变换,再用ReLU激活函数激活 #torch.nn.Sequential类是torch.nn中的一种序列容器,通过在容器中嵌套各种实现神经网络模型的搭建, #最主要的是,参数会按照我们定义好的序列自动传递下去。 # loss_fn = torch.nn.MSELoss() # x = Variable(torch.randn(100,100)) # y = Variable(torch.randn(100,100)) # loss = loss_fn(x,y) epoch_n=10000 lr=1e-4 loss_fn = torch.nn.MSELoss() optimzer = torch.optim.Adam(models.parameters(),lr=lr) #使用torch.optim.Adam类作为我们模型参数的优化函数,这里输入的是:被优化的参数和学习率的初始值。 #因为我们需要优化的是模型中的全部参数,所以传递的参数是models.parameters() #进行,模型训练的代码如下: for epoch in range(epoch_n): y_pred = models(x) loss = loss_fn(y_pred,y) print("Epoch:{},Loss:{:.4f}".format(epoch,loss.data)) optimzer.zero_grad()#将模型参数的梯度归0 loss.backward() optimzer.step()#使用计算得到的梯度值对各个节点的参数进行梯度更新。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
第三章:搭建神经网络实现手写数据集
3.1torchvision
torchvision是PyTorch中专门用来处理图像的库。这个库中有四个大类:
torchvision.datasets
torchvision.models
torchvision.transforms
torchvision.utils
3.1.1torchvision.datasets
torchvision.datasets可以实现对一些数据集的下载和加载如MNIST可以用torchvision.datasets.MNIST COCO、ImageNet、CIFCAR等都可用这个方法下载和载入。
这里用torchvision.datasets加载MNIST数据集:
data_train = datasets.MNIST(root="./data/",
transform=transform,
train = True,
download = True)
data_test = datasets.MNIST(root="./data/",
transform = transform,
train = False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.1.2torchvision.models
torchvision.models 中为我们提供了已经训练好的模型,让我们可以加载之后,直接使用。
torchvision.models模块的子模块中包含以下模型结构。如:
AlexNet
VGG
ResNet
SqueezeNet
DenseNet等
import torchvision.models as models
resnet18 = models.resnet18()
alexnet = models.alexnet()
squeezenet = models.squeezenet1_0()
densenet = models.densenet_161()
- 1
- 2
- 3
- 4
- 5
- 6
也可以通过使用 pretrained=True 来加载一个别人预训练好的模型:
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
- 1
- 2
- 3
- 4
3.1.3torchvision.transforms
torchvision.transforms 是 PyTorch 中的一个图像预处理工具包,其中包含了许多常用的图像变换操作,如缩放、旋转、裁剪等。它可以非常方便地对图像数据进行预处理,使其适合用于训练或测试深度学习模型。
torch.transforms中有大量数据变换类,如:
3.1.3.1torchvision.transforms.Resize
用于对载入的图片数据按照我们需求的大小进行缩放。传递的参数可以是一个整型数据,也可以是一个类似于(h,w)的序列。h代表高度,w代表宽度,如果输入的是整型数据那么h和w都等于这个数。
3.1.3.2torchvision.transforms.Scale
用于对载入的图片数据按照我们需求的大小进行缩放。和Resize类似。
3.1.3.3torchvision.transforms.CenterCrop
用于对载入的图片以图片中心为参考点,按照我们需要的大小进行裁剪。传递给这个类的参数可以是一个整型数据,也可以是一个类似于(h,w)的序列。
3.1.3.4torchvision.transforms.RandomCrop
用于对载入的图片按照我们需要的大小进行随机裁剪。传递给这个类的参数可以是一个整型数据,也可以是一个类似于(h,w)的序列。
3.1.3.5torchvision.transforms.RAndomHorizontalFilp
用于对载入的图片按随机概率进行水平翻转。我们通过传递给这个类的自定义随机概率,如果没有定义,则使用默认的概率为0.5
3.1.3.6torchvision.transforms.RandomVerticalFilp
用于对载入的图片按随机概率进行垂直翻转。我们通过传递给这个类的自定义随机概率,如果没有定义,则使用默认的概率为0.5
3.1.3.7torchvision.transforms.ToTensor
用于对载入的图片数据进行类型转换,将之前构成PIL图片数据转换为Tensor数据类型的变量,让PyTorch能够对其进行计算和处理。
3.1.3.8torchvision.transforms.ToPILImage
用于对Tensor变量的数据转换成PIL图片数据,主要为方便图片显示。
这里使用transforms对MNIST数据集进行操作:
#torchvision.transforms: 常用的图片变换,例如裁剪、旋转等;
transform=transforms.Compose(
[transforms.ToTensor(),#将PILImage转换为张量
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))#将[0, 1]归一化到[-1, 1]
#前面的(0.5,0.5,0.5) 是 R G B 三个通道上的均值, 后面(0.5, 0.5, 0.5)是三个通道的标准差
])
#上述代码我们可以将transforms.Compose()看作一种容器,它能够同时对多种数据变换进行组合。
#传入的参数是一个列表,列表中的元素就是对载入数据进行的变换操作。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.1.4torchvision.utils
关于torchvision.utils我们介绍一种用来对数据进行装载的类:torch.utils.data.DataLoader和
torch.utils.data.DataLoader类中, dataset参数指定我们载入的数据集的名称,batch_size参数设置每个包中图片的数量, shuffle设置为True代表在装载的过程会将数据随机打乱顺序并进行打包。
data_loader_train=torch.utils.data.DataLoader(dataset=data_train,
batch_size=64,#每个batch载入的图片数量,默认为1,这里设置为64
shuffle=True,
#num_workers=2#载入训练数据所需的子任务数
)
data_loader_test=torch.utils.data.DataLoader(dataset=data_test,
batch_size=64,
shuffle=True)
#num_workers=2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
还有torchvision.utils.make_grid将一个批次的图片构造成网格模式的图片。
#预览
#在尝试过多次之后,发现错误并不是这一句引发的,而是因为图片格式是灰度图只有一个channel,需要变成RGB图才可以,所以将其中一行做了修改:
images,labels = next(iter(data_loader_train))
# dataiter = iter(data_loader_train) #随机从训练数据中取一些数据
# images, labels = dataiter.next()
img = torchvision.utils.make_grid(images)
img = img.numpy().transpose(1,2,0)
std = [0.5,0.5,0.5]
mean = [0.5,0.5,0.5]
img = img*std+mean
print([labels[i] for i in range(64)])
plt.imshow(img)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这里,iter和next获取一个批次的图片数据和其对应的图片标签, 再使用torchvision.utils.make_grid将一个批次的图片构造成网格模式 经过torchvision.utils.make_grid后图片维度变为channel,h,w三维, 因为要用matplotlib将图片显示,我们要使用的数据要是数组且维度为(height,weight,channel)即色彩通道在最后 因此我们需要用numpy和transpose完成原始数据类型的转换和数据维度的交换。
3.2模型搭建和参数优化
实现卷积神经网络模型搭建:
import math import torch import torch.nn as nn class Model(nn.Module): def __init__(self): super(Model, self).__init__() #构建卷积层之后的全连接层以及分类器 self.conv1 = nn.Sequential( nn.Conv2d(3,64,kernel_size=3,stride=1,padding=1), nn.ReLU(), nn.Conv2d(64,128,kernel_size=3,stride=1,padding=1), nn.ReLU(), nn.MaxPool2d(stride=2,kernel_size=2) ) self.dense = torch.nn.Sequential( nn.Linear(14*14*128,1024), nn.ReLU(), nn.Dropout(p=0.5), nn.Linear(1024,10) ) def forward(self,x): x=self.conv1(x) x=x.view(-1,14*14*128) x=self.dense(x) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
3.2.1torch.nn.Conv2d
用于搭建卷积神经网络的卷积层,主要参数是:
输入通道数、输出通道数、卷积核大小、卷积核移动步长和paddingde值(用于对边界像素的填充)
3.2.2torch.nn.MaxPool2d
实现卷积神经网络的最大池化层,主要参数是:
池化窗口的大小,池化窗口移动步长和paddingde值
3.3.3torch.nn.Dropout
用于防止卷积神经网络在训练过程中发生过拟合,原理是以一定的随机概率将卷积神经网络模型的部分参数归零,以达到减少相邻两层神经连接的目的
3.3参数优化
model = Model()
cost = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
print(model)
- 1
- 2
- 3
- 4
- 5

3.4模型训练
n_epochs = 5 for epoch in range(n_epochs): running_loss = 0.0 running_correct = 0 print("Epoch {}/{}".format(epoch,n_epochs)) print("-"*10) for data in data_loader_train: X_train,y_train = data X_train,y_train = Variable(X_train),Variable(y_train) outputs = model(X_train) _,pred=torch.max(outputs.data,1) optimizer.zero_grad() loss = cost(outputs,y_train) loss.backward() optimizer.step() running_loss += loss.data running_correct += torch.sum(pred == y_train.data) testing_correct = 0 for data in data_loader_test: X_test,y_test = data X_test,y_test = Variable(X_test),Variable(y_test) outputs = model(X_test) _,pred=torch.max(outputs.data,1) testing_correct += torch.sum(pred == y_test.data) print("Loss is:{:4f},Train Accuracy is:{:.4f}%,Test Accuracy is:{:.4f}".format(running_loss/len(data_train),100*running_correct/len(data_train) ,100*testing_correct/len(data_test)))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30

3.5模型验证
为了验证我们训练的模型是不是真的已知结果显示的一样准确,则最好的方法就是随机选取一部分测试集中的图片,用训练好的模型进行预测,看看和真实值有多大的偏差,并对结果进行可视化。测试代码如下:
data_loader_test = torch.utils.data.DataLoader(dataset=data_test, batch_size = 4, shuffle = True) X_test,y_test = next(iter(data_loader_test)) inputs = Variable(X_test) pred = model(inputs) _,pred = torch.max(pred,1) print("Predict Label is:",[i for i in pred.data]) print("Real Label is:",[i for i in y_test]) img = torchvision.utils.make_grid(X_test) img = img.numpy().transpose(1,2,0) std = [0.5,0.5,0.5] mean = [0.5,0.5,0.5] img = img*std+mean plt.imshow(img)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

第四章:完整代码
import torch import torchvision from torchvision import datasets,transforms from torch.autograd import Variable import numpy as np import matplotlib.pyplot as plt #torchvision.transforms: 常用的图片变换,例如裁剪、旋转等; # transform=transforms.Compose( # [transforms.ToTensor(),#将PILImage转换为张量 # transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))#将[0, 1]归一化到[-1, 1] # #前面的(0.5,0.5,0.5) 是 R G B 三个通道上的均值, 后面(0.5, 0.5, 0.5)是三个通道的标准差 # ]) transform = transforms.Compose([ transforms.ToTensor(), transforms.Lambda(lambda x: x.repeat(3,1,1)), transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)) ]) # 修改的位置 data_train = datasets.MNIST(root="./data/", transform=transform, train = True, download = True) data_test = datasets.MNIST(root="./data/", transform = transform, train = False) data_loader_train=torch.utils.data.DataLoader(dataset=data_train, batch_size=64,#每个batch载入的图片数量,默认为1,这里设置为64 shuffle=True, #num_workers=2#载入训练数据所需的子任务数 ) data_loader_test=torch.utils.data.DataLoader(dataset=data_test, batch_size=64, shuffle=True) #num_workers=2) #预览 #在尝试过多次之后,发现错误并不是这一句引发的,而是因为图片格式是灰度图只有一个channel,需要变成RGB图才可以,所以将其中一行做了修改: images,labels = next(iter(data_loader_train)) # dataiter = iter(data_loader_train) #随机从训练数据中取一些数据 # images, labels = dataiter.next() img = torchvision.utils.make_grid(images) img = img.numpy().transpose(1,2,0) std = [0.5,0.5,0.5] mean = [0.5,0.5,0.5] img = img*std+mean print([labels[i] for i in range(64)]) plt.imshow(img) import math import torch import torch.nn as nn class Model(nn.Module): def __init__(self): super(Model, self).__init__() #构建卷积层之后的全连接层以及分类器 self.conv1 = nn.Sequential( nn.Conv2d(3,64,kernel_size=3,stride=1,padding=1), nn.ReLU(), nn.Conv2d(64,128,kernel_size=3,stride=1,padding=1), nn.ReLU(), nn.MaxPool2d(stride=2,kernel_size=2) ) self.dense = torch.nn.Sequential( nn.Linear(14*14*128,1024), nn.ReLU(), nn.Dropout(p=0.5), nn.Linear(1024,10) ) def forward(self,x): x=self.conv1(x) x=x.view(-1,14*14*128) x=self.dense(x) return x model = Model() cost = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters()) print(model) n_epochs = 5 for epoch in range(n_epochs): running_loss = 0.0 running_correct = 0 print("Epoch {}/{}".format(epoch,n_epochs)) print("-"*10) for data in data_loader_train: X_train,y_train = data X_train,y_train = Variable(X_train),Variable(y_train) outputs = model(X_train) _,pred=torch.max(outputs.data,1) optimizer.zero_grad() loss = cost(outputs,y_train) loss.backward() optimizer.step() running_loss += loss.data running_correct += torch.sum(pred == y_train.data) testing_correct = 0 for data in data_loader_test: X_test,y_test = data X_test,y_test = Variable(X_test),Variable(y_test) outputs = model(X_test) _,pred=torch.max(outputs.data,1) testing_correct += torch.sum(pred == y_test.data) print("Loss is:{:4f},Train Accuracy is:{:.4f}%,Test Accuracy is:{:.4f}".format(running_loss/len(data_train),100*running_correct/len(data_train) ,100*testing_correct/len(data_test))) data_loader_test = torch.utils.data.DataLoader(dataset=data_test, batch_size = 4, shuffle = True) X_test,y_test = next(iter(data_loader_test)) inputs = Variable(X_test) pred = model(inputs) _,pred = torch.max(pred,1) print("Predict Label is:",[i for i in pred.data]) print("Real Label is:",[i for i in y_test]) img = torchvision.utils.make_grid(X_test) img = img.numpy().transpose(1,2,0) std = [0.5,0.5,0.5] mean = [0.5,0.5,0.5] img = img*std+mean plt.imshow(img)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134

