
- 1git把一个分支上的某次修改同步到另一个分支上,并解决git cherry-pick 冲突_git 修改两个分支 同内容
- 2linux下载/解压ImageNet-1k数据集_imagenet1k下载
- 3【MySQL】20. 使用C语言链接
- 4JavaScript实现数组对应位置插入另一个数组_js 数组指定位置插入
- 5Java面试题目和答案【终极篇】
- 6BFS - C语言链表实现(简单易懂)_bfs c语言实现
- 7前端术语总结_前端页面的术语有哪些
- 8RabbitMQ --- 消息可靠性_rabbitmq消息可靠性
- 9微服务技术栈SpringCloud+RabbitMQ+Docker+Redis+搜索+分布式(五):分布式搜索 ES-下
- 10用Git远程仓库实现多人协同开发_git merge 远程仓库
redis进阶入门主从复制与哨兵集群
赞
踩
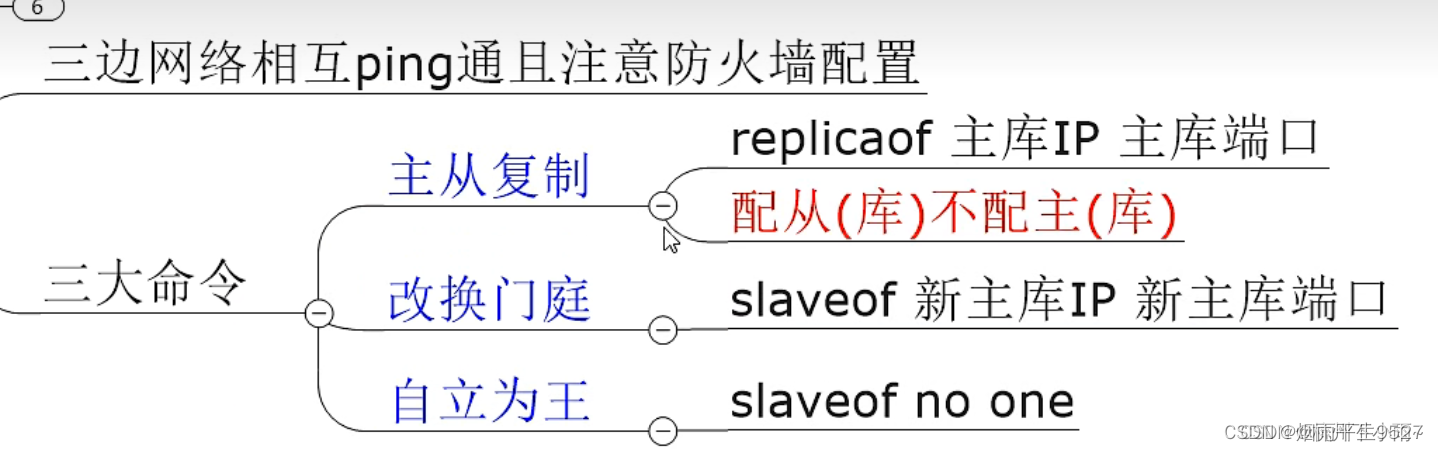
一、主从复制
1.1背景
一般来说,要将 Redis用于工程项目中,只使用一台 Redist是万万不能的,原因如下:
- 从结构上,单个 Redist服务器会发生单点故障,井且一台服务器需要处理所有的请求负載,压力较大
- 从容量上,单个 Redis服务器内存容量有限就算一台 Redis服务器内存容量为266,也不能将所有内存用作 Redis?存储内存一般来说,单台 Redist最大使用内存不应该超过206
电商网站上的商品,一般都是一次上传,无数次浏览的,说专业点也就是”多读少写”。
对于这种场景,我们可以使如下这种架构主从复制,息指将一台Reds3服的数据,复制他的Reds眼努,前者称为主节点 master/leade,后者称为从节点( slave/ follower);数据的复制是单向的,只能由主节点到从节点。 Master以写为主,Save以读为主。
默认情况下,每台Redis服务器都是主节点,一个主节点可以有0个或者多个从节点,但每个从节点只能由一个主节点
主从复制,读写分离! 80% 的情况下都是在进行读操作!减缓服务器的压力!架构中经常使用! 一主二从!
1.2 作用#
主从复制的作用主要包括:
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余的方式。
- 故障恢复:当主节点故障时,从节点可以暂时替代主节点提供服务,是一种服务冗余的方式
- 负载均衡:在主从复制的基础上,配合读写分离,由主节点进行写操作,从节点进行读操作,分担服务器的负载;尤其是在多读少写的场景下,通过多个从节点分担负载,提高并发量。
- 高可用基石:主从复制还是哨兵和集群能够实施的基础。
1.3环境配置
只配置从库,不配置主库!
查看当前库的信息
- slaveof 主库ip 主库端口 # 配置主从
- Info replication # 查看信息
- 127.0.0.1:6379> info replication
- # 复制信息
- 角色:master // 表示实例的角色,这里是主服务器
- 已连接从服务器数:0 // 已连接的从服务器实例数
- 主服务器故障转移状态:no-failover // 表示当前是否正在进行故障转移
- 主服务器复制ID:c52bb664e09e9e76e9c995fdd15215578e38250f // 当前复制连接的ID
- 第二复制ID:0000000000000000000000000000000000000000 // 第二个复制ID
- 主服务器复制偏移量:0 // 主服务器的复制偏移量
- 第二复制偏移量:-1 // 第二个复制偏移量
- 复制日志活跃状态:0 // 表示复制日志是否活跃
- 复制日志大小:1048576 // 复制日志的大小
- 复制日志第一个字节偏移量:0 // 复制日志中第一个字节的偏移量
- 复制日志历史长度:0 // 复制日志中数据的总长度
复制3个配置文件,然后修改对应的信息
- 端口
- pid名字
- log文件名
- dump.rdb名字
启动单机多服务集群:
1.4一主二从配置#
默认情况下,每台Redis服务器都是主节点;我们一般情况下只用配置从机就好了!
认老大!一主(79)二从(80,81)
使用SLAVEOF host port就可以为从机配置主机了。
说明
SLAVEOF host 6379找谁当自己的老大!role:slave# 当前角色是从机master_host:127.0.0.1# 可以的看到主机的信息connected_slaves:1# 多了从机的配置slave0:ip=127.0.0.1,port=6380,state=online,offset=42,lag=1# 多了从机的配置
在主机设置值,在从机都可以取到!从机不能写值!
使用规则#
- 从机只能读,不能写,主机可读可写但是多用于写。
- .当主机断电宕机后,默认情况下从机的角色不会发生变化 ,集群中只是失去了写操作,当主机恢复以后,又会连接上从机恢复原状。
- 当从机断电宕机后,若不是使用配置文件配置的从机,再次启动后作为主机是无法获取之前主机的数据的,若此时重新配置称为从机,又可以获取到主机的所有数据。这里就要提到一个同步原理。
第二条中提到,默认情况下,主机故障后,不会出现新的主机,有两种方式可以产生新的主机:
- 从机手动执行命令slaveof no one,这样执行以后从机会独立出来成为一个主机
- 使用哨兵模式(自动选举)
复制原理
Slave 启动成功连接到 master 后会发送一个sync同步命令
Master 接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
增量复制:Master 继续将新的所有收集到的修改命令依次传给slave,完成同步
但是只要是重新连接master,一次完全同步(全量复制)将被自动执行! 我们的数据一定可以在从机中看到!
1.5层层链路
上一个Slave 可以是下一个slave 和 Master,Slave 同样可以接收其他 slaves 的连接和同步请求,那么该 slave 作为了链条中下一个的master,可以有效减轻 master 的写压力!
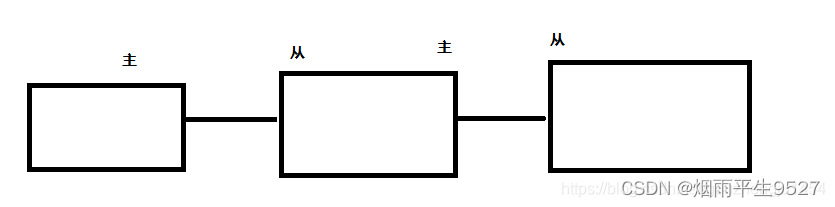
写入问题:6380对上是从机,对下是主机,但是仍然不能写入。
1.6反客为主
使用 SLAVEOF no one 命令升级为 master
- 127.0.0.1:6381> SLAVEOF no one
- OK
- 127.0.0.1:6381> info replication
- # Replication
- role:master
- connected_slaves:0
- master_failover_state:no-failover
- master_replid:f4029b340ab6291cf553d6e14e74524bf6fccb48
- master_replid2:cbfda3355c0b49c7d2e3c86a1ebfe97358916d53
- master_repl_offset:9226
- second_repl_offset:9227
- repl_backlog_active:1
- repl_backlog_size:1048576
- repl_backlog_first_byte_offset:1
- repl_backlog_histlen:9226
- 127.0.0.1:6381>

1.7痛点
1、复制延时,信号衰减
由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
2、复制延时,信号衰减
由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
二、哨兵
2.1介绍
主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。Redis从2.8开始正式提供了Sentinel(哨兵) 架构来解决这个问题。、
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库。
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
2.2哨兵模式概述
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。

-
哨兵巡查监控后台master主机是否故障,如果故障了根据投票数自动将某一个从库转换为新主库,继续对外服务,俗称无人值守运维
-
作用
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
-
哨兵的四个功能
- 主从监控
- 监控主从redis库运行是否正常
- 消息通知
- 哨兵可以将故障转移的结果发送到客户端
- 故障转移
- 如果master异常,则会进行主从切换,将其中一个slave作为新master
- 配置中心
- 客户端通过连接哨兵来获得当前Redis服务的主节点地址
- 主从监控
- 然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。

2.3客观下线
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。 当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。这样对于客户端而言,一切都是透明的。
2.4配置
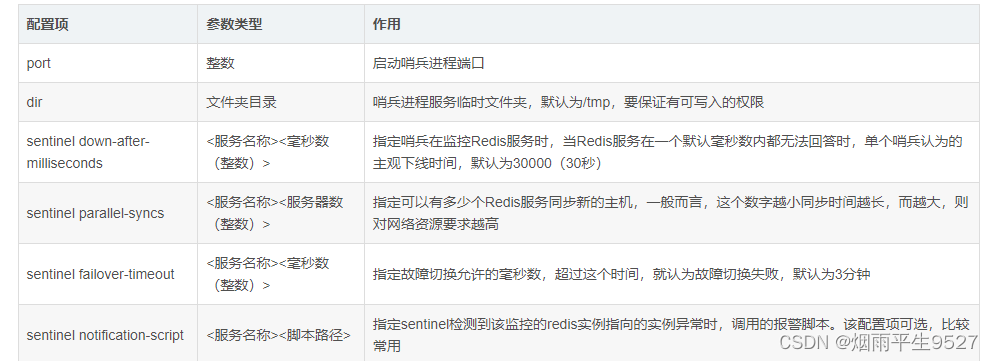
配置哨兵配置文件 sentinel.conf
- bind 服务监听地址,用于客户端连接
- daemonize 是否以后台daemon方式运行
- protected-mode 安全保护模式
- port 端口
- logfile 日志文件路径
- pidfile pid日志路径
- dir 工作目录
- sentiel monitor
- 设置要监控的master
- quorm 表示最少有几个哨兵认可客观下线,同意故障迁移的法定票数
- 网络是不可靠的,有时候一个sentinel会因为网络堵塞而误以为一个master redis已经死掉了,在sentinel集群环境下需要多个sentinel互相沟通来确认某个master是否真的死了,quorum这个参数是进行客观下线的一个依据,意思是至少有quorum个sentinel认为这个master有故障,才会对这个master进行下线以及故障转移。因为有的时候,某个sentinel节点可能因为自身网络原因,导致无法连接master,而此时master并没有出现故障,所以,这就需要多个sentinel都一致认为该master有问题,才可以进行下一步操作,这就保证了公平性和高可用。
- sentiel auth-pass 通过密码连接master
哨兵配置
- bind 0.0.0.0
- daemonize yes
- protected-mode no
- port 26379
- logfile "/myredis/sentinel26379.log"
- pidfile /var/run/redis-sentinel26379.pid
- dir /myredis
- sentinel monitor mymaster 192.168.111.169 6379 2
- sentinel auth-pass mymaster 111111

配置测试
1、调整结构,6379带着80、81
2、自定义的 /myredis 目录下新建 sentinel.conf 文件,名字千万不要错
3、配置哨兵,填写内容
- sentinel monitor 被监控主机名字 127.0.0.1 6379 1
- 上面最后一个数字1,表示主机挂掉后slave投票看让谁接替成为主机,得票数多少后成为主机
4、启动哨兵
- Redis-sentinel /myredis/sentinel.conf
- 上述目录依照各自的实际情况配置,可能目录不同
5、正常主从演示
6、原有的Master 挂了
7、投票新选
8、重新主从继续开工,info replication 查查看
2.5哨兵模式的优缺点
优点
1. 哨兵集群模式是基于主从模式的,所有主从的优点,哨兵模式同样具有。
2. 主从可以切换,故障可以转移,系统可用性更好。
3. 哨兵模式是主从模式的升级,系统更健壮,可用性更高。
缺点
1. Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
2. 实现哨兵模式的配置也不简单,甚至可以说有些繁琐
2.6超级兵的选择原则Raft
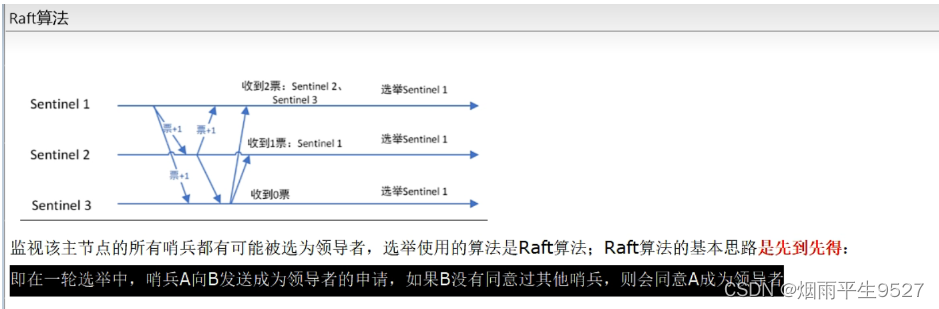
2.7master选举

2.8哨兵使用建议
- 节点数量为奇数,起步三个。
- 各个节点配置相同。
- 如果哨兵部署在Docker应该注意端口映射。
- 哨兵+主从复制在主从切换的过程中不可避免的产生数据丢失。
所以我们引入集群。
三、集群
3.1介绍
-
由于数据量过大,单个Master复制集难以承担,因此需要对多个复制集进行集群,形成水平扩展每个复制集只负责存储整个数据集的一部分,这就是Redis的集群,其作用是提供在多个Redis节点间共享数据的程序集。

- Redis集群支持多个Master,每个Master又可以挂载多个Slave
- 读写分离
- 支持海量数据的高可用
- 支持海量数据的读写存储操作
- 由于Cluster自带Sentinel的故障转移机制,内置了高可用的支持,无需再去使用哨兵功能
- 客户端和Redis的节点连接,不再需要连接集群中所有节点,只需连接集群中的任意一个可用节点即可
- 槽位slot负责分配到各个物理服务节点,由对应的集群来负责维护节点、插槽和数据之间的关系
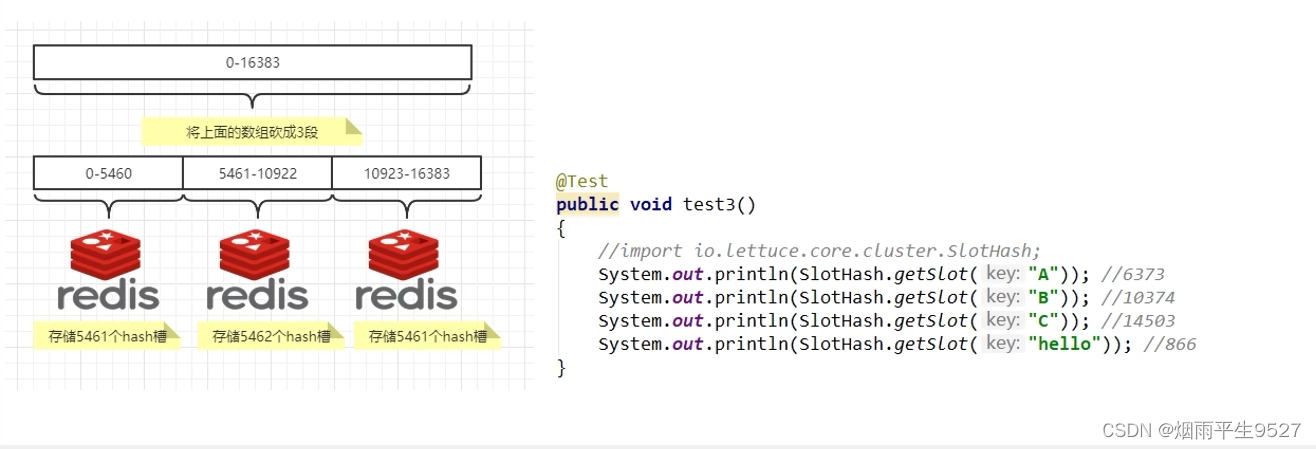
3.2槽位
redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放入那个槽中。每个节点负责一部分的hash槽。
如果集群中有3个节点,那么: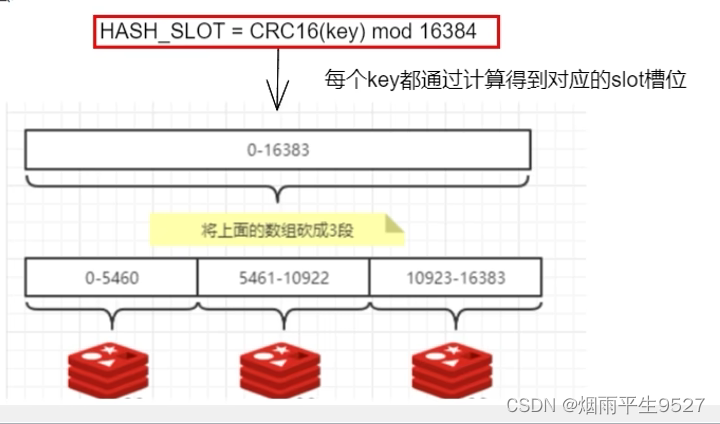
3.3分片
使用redis集群时我们会将存储的数据集分散到每台机器上,这就是分片。集群中的每个redis实例都被认为是整个数据的一个分片。为了找到给定的key的分片,我们将对key进行CRC16算法处理并对总分片数量取模。
槽位和分片的优势:方便扩缩容和数据分派查找。
3.4Redis集群分布式存储
Redis集群分布式存储有大概有3种解决方法
- 哈希取余分区
- 一致性哈希算法分区
- 哈希槽分区
哈希取余分区
hash(key) % N个机器台数,计算出哈希值,用来决定数据映射到哪一个节点上。
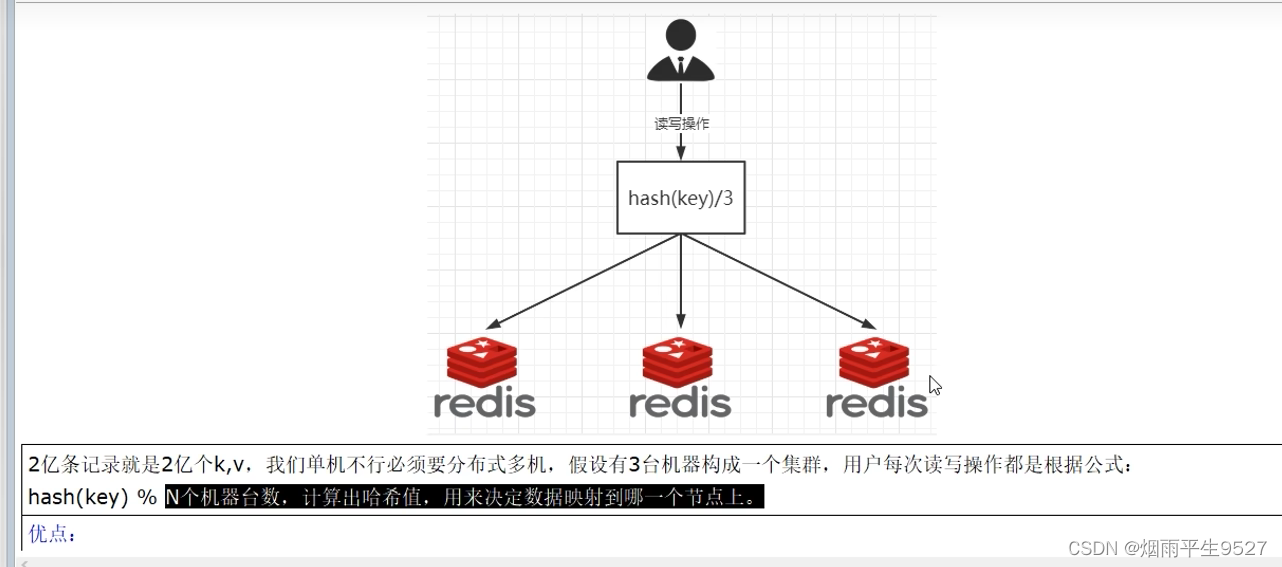
优点:
- 简单粗暴,直接有效,只需要预估好数据规划节点例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡+分而治之的作用。
缺点:
- 如果需要弹性扩容或故障停机的情况下,原来的取模公式就会发生变化,Hash(key)/3会变成Hash(key) /?。此时地址经过取余运算的结果将发生很大变化,根据公式获取的服务器也会变得不可控。
- 某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。
一致性哈希算法分区
提出一致性Hash解决方案。目的是当服务器个数发生变动时,尽量减少影响客户端到服务器的映射关系
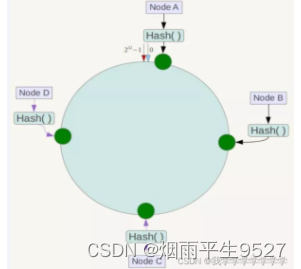
1.算法构建一致性哈希环
一致性Hash算法是对2^32取模,简单来说, 一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1,
2.服务器IP节点映射
将集群中各个IP节点映射到环上的某一个位置。将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。假如4个节点NodeA、B、C、D,经过IP地址的哈希函数计算(hash(ip)),使用IP地址哈希后在环空间的位置如下:
③、key落到服务器的落键规则‘
当我们需要存储一个kv键值对时,首先计算key的hash值,hash(key),将这个key使用相同的函数Hash计算出哈希值并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。
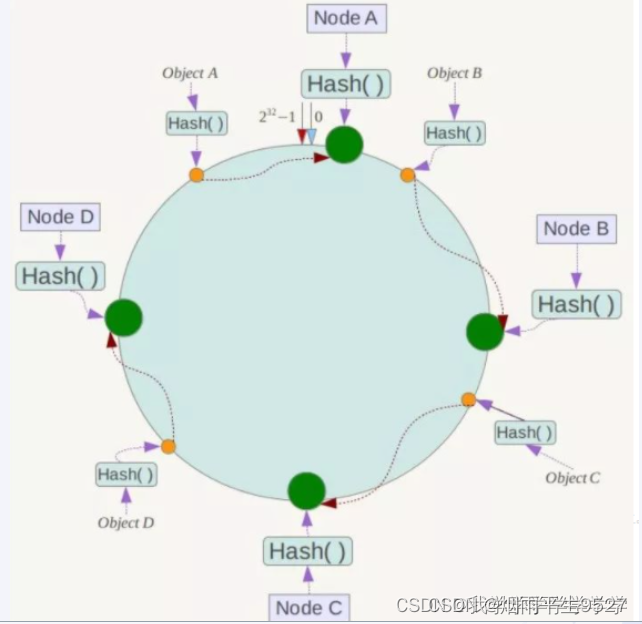
优点
-
一致性哈希算法的容错性
-
一致性哈希算法的扩展性
缺点
-
一致性哈希算法的数据倾斜问题
- 一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,例如系统中只有两台服务器:
哈希槽分区
①为什么要有哈希槽分区
哈希槽分区的出现就是为了解决一致性哈希算法分区的数据倾斜问题。哈希槽实质就是一个数组,数组[0,2^14 -1]形成hash slot空间。
②解决均匀分配
解决均匀分配的问题,在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动。哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配
③多少个hash槽
一个集群只能有16384个槽,编号0-16383(0-2^14-1)。这些槽会分配给集群中的所有主节点,分配策略没有要求。
集群会记录节点和槽的对应关系,解决了节点和槽的关系后,接下来就需要对key求哈希值,然后对16384取模,余数是几key就落入对应的槽里。HASH_SLOT = CRC16(key) mod 16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。
redis集群不保证强一致性,这就意味着在特定的条件下,redis集群可能会丢失一些被系统收到的写入请求命令。
3.5主从分步
CLUSTER NODES 命令类似于 INFO replication
- 127.0.0.1:6379> CLUSTER NODES
- 4a6a56ea1aa80cf7ba4e32cbc35cf8901e16485c 127.0.0.1:6382@16382 slave 1aa080e1ed7cd0f8d7c871ac274b0f7b01db8b42 0 1677650172000 2 connected
- 212579596bef87a4cd4dd35b6a6f15a2a78a069d 127.0.0.1:6379@16379 myself,master - 0 1677650171000 1 connected 0-5460
- e1c3fcd46f3fd4da0bbca08c2fc3ad06d1cf2f5a 127.0.0.1:6384@16384 slave 212579596bef87a4cd4dd35b6a6f15a2a78a069d 0 1677650171616 1 connected
- 74c5b67bf568bf1b5e487d3a5c6673edc7b05842 127.0.0.1:6383@16383 slave 942c3eb2894912308f166c1035167ec70f6cceb2 0 1677650171000 3 connected
- 1aa080e1ed7cd0f8d7c871ac274b0f7b01db8b42 127.0.0.1:6380@16380 master - 0 1677650172000 2 connected 5461-10922
- 942c3eb2894912308f166c1035167ec70f6cceb2 127.0.0.1:6381@16381 master - 0 1677650172657 3 connected 10923-16383
- 127.0.0.1:6379>
- [root@localhost redis-cluster]
CLUSTER INFO 某一个节点信息
使用 -c 路由
- [root@localhost redis-cluster]# redis-cli -p 6379 -a 123456 -c
- Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
- 127.0.0.1:6379> set k1 v1
- -> Redirected to slot [12706] located at 127.0.0.1:6381
- OK
- 127.0.0.1:6381>
CLUSTER KEYSLOT 命令查看某个key属于某个slot
- 127.0.0.1:6379> CLUSTER KEYSLOT k1
- (integer) 12706
- 127.0.0.1:6379> CLUSTER KEYSLOT k2
- (integer) 449
- 127.0.0.1:6379> CLUSTER KEYSLOT k3
- (integer) 4576
- 127.0.0.1:6379>
手动调整主从关系
代码cluster failover
原来的集群master宕机了,slave升级为master,当原来的master重新恢复正常后,身份变成了slave,如果此时想要恢复成以前的主从关系,就要手动执行cluster failover
3.6集群扩容
口诀:加主,分配,加从
第一步:新建两个配置文件,端口号改为6385和6386,启动服务
第二步:加入集群
redis-cli -a 123456 --cluster add-node 192.168.111.187:6387 192.168.111.185:6381
相当于6385通过6379(介绍人)加入集群(组织)。
第三步:重新分配 slot, 16384 / 4 = 4096
redis-cli -a 123456 --cluster reshard 127.0.0.1:6379
第四步:给6385添加 slave 6386
redis-cli -a 123456 --cluster add-node 127.0.0.1:6386 127.0.0.1:6385 --cluster-slave --cluster-master-id 49356d9d1c0c8fd1dc7b0d3a29371f032f5b1afa
–cluster check 检查集群命令
3.7集群缩容
口诀:删从,重分配,删主。
第一步:删除从节点 6386
- [root@localhost redis-cluster]# redis-cli -a 123456 --cluster del-node 127.0.0.1:6386 3ef2ce807bdd74f767033e1fb33c5c4f3d28ea60
- Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
- >>> Removing node 3ef2ce807bdd74f767033e1fb33c5c4f3d28ea60 from cluster 127.0.0.1:6386
- >>> Sending CLUSTER FORGET messages to the cluster...
- >>> Sending CLUSTER RESET SOFT to the deleted node.
- [root@localhost redis-cluster]#
第二步:重新分配槽位
redis-cli -a 123456 --cluster reshard 127.0.0.1:6379
第三步:删除节点
redis-cli -a 123456 --cluster del-node 127.0.0.1:6385 49356d9d1c0c8fd1dc7b0d3a29371f032f5b1afa
第四步:check
- 127.0.0.1:6379 (21257959...) -> 1 keys | 8192 slots | 1 slaves.
- 127.0.0.1:6381 (942c3eb2...) -> 1 keys | 4096 slots | 1 slaves.
- 127.0.0.1:6380 (1aa080e1...) -> 0 keys | 4096 slots | 1 slaves.
3.8总结
不在一个slot下的多key操作支持不好,通识占位符
- [root@localhost redis-cluster]# redis-cli -a 123456 -p 6379 -c
- Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
- 127.0.0.1:6379> mget k1 k2
- (error) CROSSSLOT Keys in request don't hash to the same slot
- 127.0.0.1:6379> mset k1{z} v1 k2{z} v2 k3{z} v3
- -> Redirected to slot [8157] located at 127.0.0.1:6380
- OK
- 127.0.0.1:6380> mget k1{z} k2{z} k3{z}
- 1) "v1"
- 2) "v2"
- 3) "v3"
- 127.0.0.1:6380>
不在同一个 slot 无法使用 mset mget,可以使用{}定义一个组的概念,使 key 中{}相同内容的放到一个slot 中。
slot(槽)常用配置和命令:
配置文件参数:cluster-require-full-coverage yes :要求集群完整性设置为yes,否则设置为no。
命令1:CLUSTER COUNTKEYSINSLOT slotNum :统计某个 slot key 的数量
key会落到那个 slot。
命令2:CLUSTER KEYSLOT key :计算key会落到哪一个slot。
四、Redis缓存穿透和雪崩
4.1缓存穿透(即查询不到)#
缓存穿透 (查不到)
概念
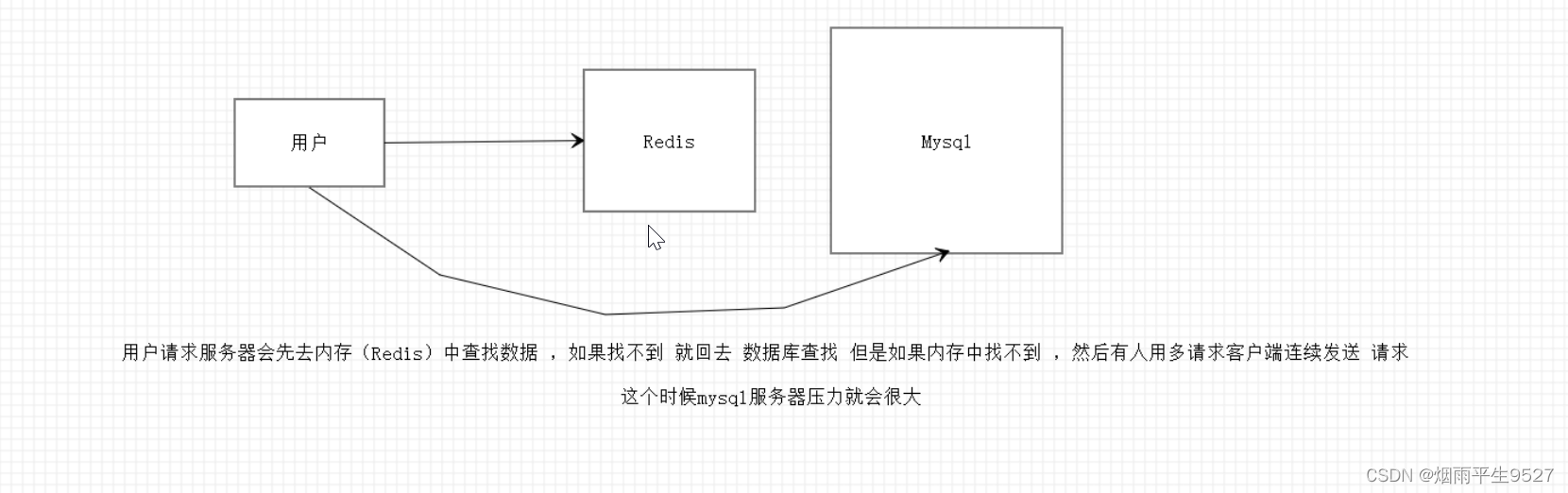
在默认情况下,用户请求数据时,会先在缓存(Redis)中查找,若没找到即缓存未命中,再在数据库中进行查找,数量少可能问题不大,可是一旦大量的请求数据(例如秒杀场景)缓存都没有命中的话,就会全部转移到数据库上,造成数据库极大的压力,就有可能导致数据库崩溃。网络安全中也有人恶意使用这种手段进行攻击被称为洪水攻击。
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
这里需要注意和缓存击穿的区别,缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
4.2解决方案
布隆过滤器
布隆过滤器是一种数据结构,对所有可能查询的参数以Hash的形式存储,以便快速确定是否存在这个值,在控制层先进行拦截校验,校验不通过直接打回,减轻了存储系统的压力。
那这个布隆过滤器是如何解决redis中的缓存穿透呢?很简单首先也是对所有可能查询的参数以hash形式存储,当用户想要查询的时候,使用布隆过滤器发现不在集合中,就直接丢弃,不再对持久层查询。

缓存空对象
一次请求若在缓存和数据库中都没找到,就在缓存中方一个空对象用于处理后续这个请求。
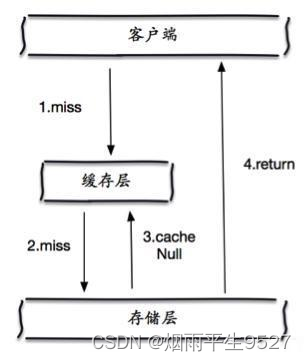
当存储层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据源;
这样做有一个缺陷:存储空对象也需要空间,大量的空对象会耗费一定的空间,存储效率并不高。解决这个缺陷的方式就是设置较短过期时间
即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
4.3缓存击穿(即量太大,缓存过期)#
概述
相较于缓存穿透,缓存击穿的目的性更强,一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到DB,造成瞬时DB请求量大、压力骤增。这就是缓存被击穿,只是针对其中某个key的缓存不可用而导致击穿,但是其他的key依然可以使用缓存响应。
比如热搜排行上,一个热点新闻被同时大量访问就可能导致缓存击穿。
解决方案
- 设置热点数据永远不过期
- 接口限流与熔断,降级
- 加互斥锁
分布式锁:使用分布式锁,保证对于每个key同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限,因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁,因此对分布式锁的考验很大。
重要的接口一定要做好限流策略,防止用户恶意刷接口,同时要降级准备,当接口中的某些 服务 不可用时候,进行熔断,失败快速返回机制。
4.4缓存雪崩#
大量的key设置了相同的过期时间,导致在缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。
缓存雪崩,是指在某一个时间段,缓存集中过期失效。Redis 宕机!
产生雪崩的原因之一,比如在写本文的时候,马上就要到双十二零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
(1)redis高可用
这个思想的含义是,既然redis有可能挂掉,那我多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。
(2)限流降级
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
(3)数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。

