
- 1el-table的各个属性5.17_el-table属性
- 2Dependency ‘org.springframework.cloud:spring-cloud-starter-config:‘ not found_dependency 'org.springframework.cloud:spring-cloud
- 3Windows的cmd运行编译器(cmd运行c/c++、python等)_windows cmd python
- 42023如果纯做业务测试的话,在测试行业有出路吗?_业务测试是不是最简单的
- 5MAC 安装PHP及环境配置 保姆级别_formula.jws.json: update failed, falling back to c
- 6xcode通过链接ssh 链接git_xcode 配置ssh
- 7fastapi响应数据处理_fastapi中間件修改響應
- 8一篇文章带你入门文件上传漏洞_如何利用文件上传漏洞
- 9c语言中输入一个字符串直到遇到回车为止,C语言程序设计实践第四章.pptx
- 10“BS,“ “PL,“ 和 “CF“ 是财务报告中常用的缩写,它们分别代表财务报表的不同部分_bs pl
YOLOv9目标识别——详细记录训练环境配置与训练自己的数据集_yolov9训练自己的数据集
赞
踩
前言
YOLOv9引入了一种全新的计算机视觉模型架构,相比目前流行的YOLO模型(如YOLOv8、YOLOv7和YOLOv5),在MS COCO数据集上取得了更高的mAP(平均精度均值)。
YOLOv9是由Chien-Yao Wang、I-Hau Yeh和Hong-Yuan Mark Liao开发的计算机视觉模型。这些研究人员还对YOLOv4、YOLOR和YOLOv7等流行的模型架构进行了研究。YOLOv9引入了两种新的架构:YOLOv9和GELAN。这两种架构都可以通过YOLOv9 Python库进行使用。
使用YOLOv9模型,可以训练出目标检测模型,但不支持分割、分类等任务类型。YOLOv9有四种不同参数数量的模型,按参数个数排序为:v9-S、v9-M、v9-C、v9-E。目前v9-S和v9-M的权重尚不可用。其中,最小的模型在MS COCO数据集的验证集上达到了46.8%的AP,而最大的模型则达到了55.6%。这为目标检测性能提供了一个新的先进水平。下面的图表展示了来自YOLOv9研究团队的研究结果。
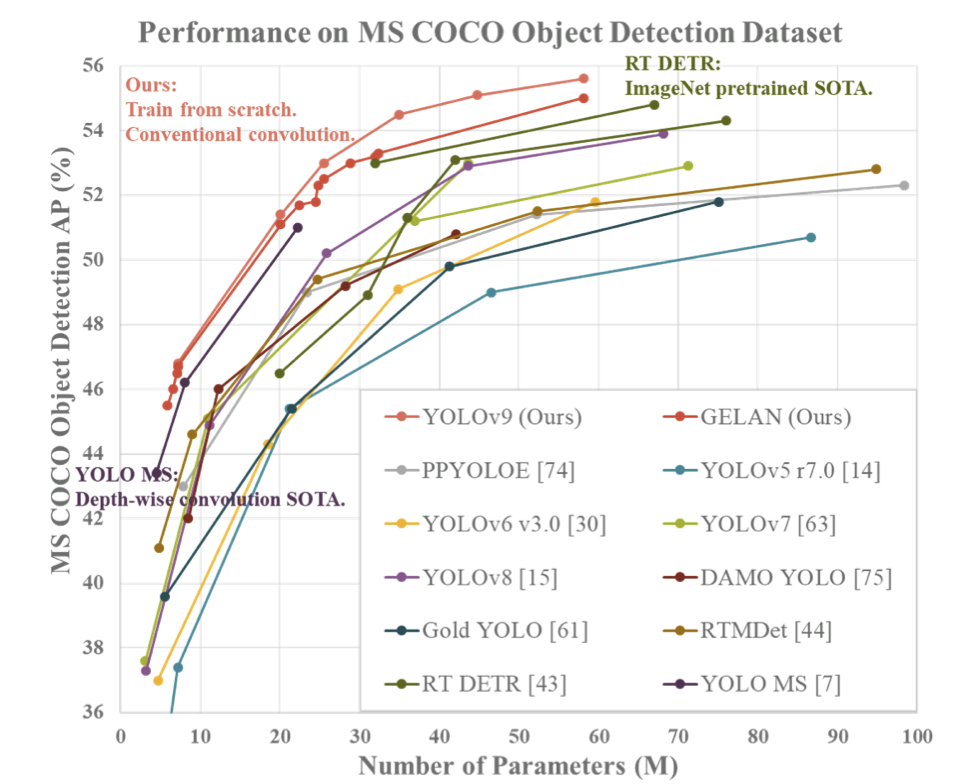
算法解读
1. YOLOv9算法改进:
YOLOv9通过从可逆函数的角度对现有的CNN架构进行理论分析,提出了一些改进:
-
PGI和辅助可逆分支设计: YOLOv9的作者在分析现有CNN架构时,提出了可逆函数的概念,并设计了PGI和辅助可逆分支。这些改进在实践中取得了显著的成果。
-
解决深度监督的问题: YOLOv9的PGI解决了深度监督仅适用于极深的神经网络架构的问题,从而使得新的轻量级架构也能够获得良好的应用效果。
-
GELAN设计: YOLOv9中引入的GELAN仅使用传统卷积技术,却能实现比基于最先进技术的深度可分卷积设计更高的参数使用率。同时,GELAN展现出轻量级、快速和精确的巨大优势。
-
性能提升: 基于PGI和GELAN的改进,YOLOv9在MS COCO数据集上的性能在各个方面都明显超过了现有的实时目标检测器。
2. PGI(可编程梯度信息):
PGI主要由以下三个组成部分组成:
-
主分支: 主要用于网络的前向推理过程,不需要额外的推理成本。
-
辅助可逆分支: 用于解决由于神经网络加深而导致的信息瓶颈问题。辅助可逆分支采用可逆架构,提供可靠的梯度信息用于参数更新。
-
多级辅助信息: 插入在主分支和辅助监督之间的特征金字塔层次结构中,用于聚合包含所有目标对象的梯度信息,并传递给主分支进行参数更新。
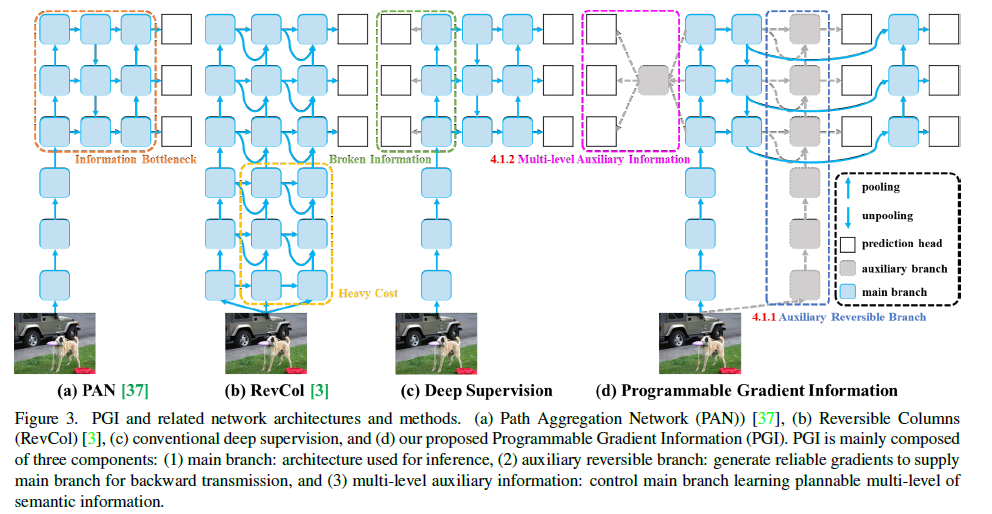
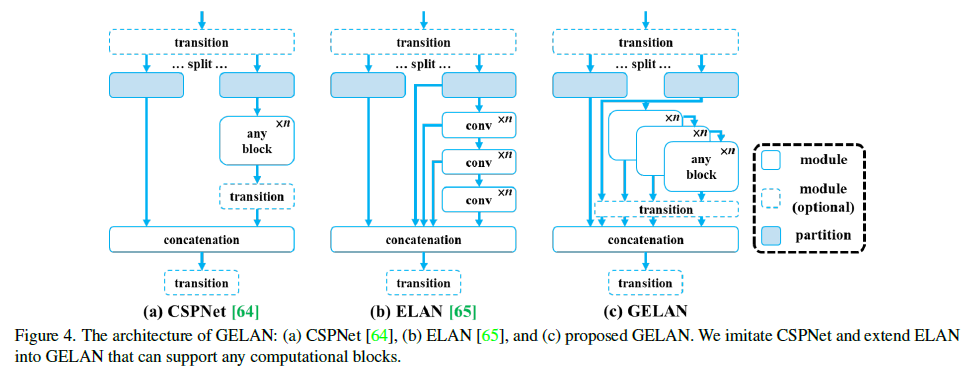
3.GELAN模块
YOLOv9引入了一种新的网络架构——GELAN,它结合了两种神经网络架构,即具有梯度路径规划的CSPNet和ELAN。GELAN被设计成一种通用的、高效的层聚合网络,综合考虑了轻量级、推理速度和准确度。
GELAN的整体架构如下图所示。相较于原始的ELAN,GELAN对ELAN的能力进行了泛化。原始的ELAN仅使用卷积层的堆叠,而GELAN则可以使用任何计算块作为其基础模块。这使得GELAN更加灵活,能够适应不同的网络设计需求,并且不局限于特定类型的计算块。
4. 损失函数与样本匹配

根据上述代码,可以看到以下内容:
-
样本匹配仍然使用了TaskAlign样本匹配,与YOLOv8、YOLOE、YOLOv6等算法保持一致。
-
分类损失使用了二元交叉熵(BCE)损失。
-
回归损失则结合了DFL(Distance Focal Loss)损失和CIoU(Complete Intersection over Union)损失。
5. 模型结构

环境安装
我这里训练环境是win10, gpu是3080,cuda 11.7 ,cudnn8.5 , 是Anacoda装的虚拟环境训练的。
环境安装:
conda create -n yolov9 python=3.10
activate ylolv9
- 1
- 2
源码下载
git clone https://github.com/WongKinYiu/yolov9.git
cd yolov9
pip install -r requirements.txt
- 1
- 2
- 3
模型训练
数据准备
YOLOv9遵循YOLOv5-YOLOv8的训练数据构建方式,数据标注与数据转换部分,如果不理解可以参考我之前关于yolov8训练时数据处理部分:YOLOV8实例分割——详细记录环境配置、自定义数据处理到模型训练与部署, 我这里使用安全帽佩带数据集来训练模型。

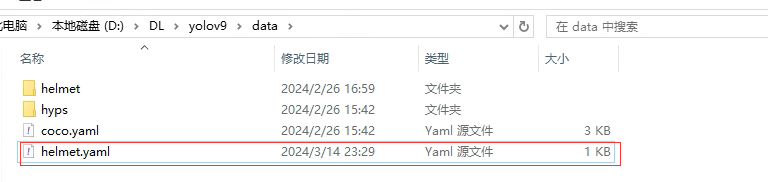
构建数据集
新增加一个helmet.yaml文件放到yolov9/data目录下。
文件内容如下:
path: D:/DL/yolov9/data
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
#val: images/test # test images (optional)
# Classes
names:
0: person
1: head
2: helmet
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
构建YOLOv9-c模型配置文件
找到yolov9/models/detect/yolov9-c.yaml文件,更改里面的内容:
# YOLOv9
# 参数
nc: 3 # 类别数
depth_multiple: 1.0 # 模型深度倍数
width_multiple: 1.0 # 层通道数倍数
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()
# 锚点
anchors: 3
# 其他配置...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
下载预训练的模型
可以手动模型,模型yolov9 git有开源:https://github.com/WongKinYiu/yolov9.git,下载需要使用的模型,我这里是目标检测,我下载了yolov9-c.pt这个模型,放到yolov9根目录下:

模型训练:
python3 train_dual.py --weights=./yolov9-c.pt --cfg=./models/detect/yolov9-c.yaml --data=./data/helmet.yaml --epoch=100 --batch-size=16 --imgsz=640 --hyp=data/hyps/hyp.scratch-high.yaml
- 1
如果一切顺利就开始在训练了:
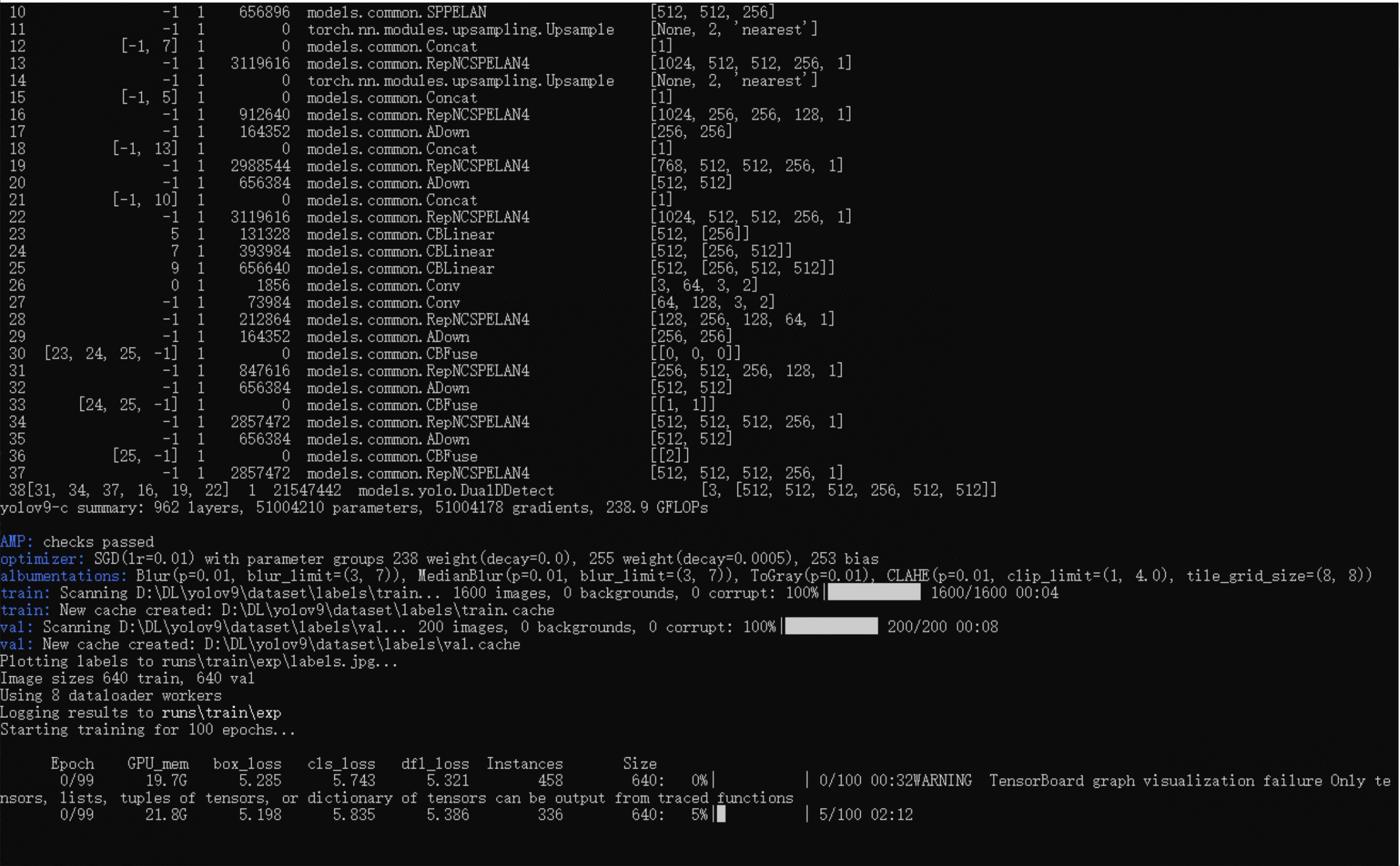
在训练过程中,可以在yolov9/run目录下看到当前数据和状态:
推理测试
python detect_dual.py --source './data/images/test.jpg' --img 640 --device 0 --weights 'runs/train/exp/best.pt' --name yolov9_c_640_detect
- 1


