
- 1双积分型ADC工作原理_双积分ad转换器工作原理简述
- 2SpringBoot远程过程调用RPC(WebClient、HTTP Interface客户端)_spring boot 访问外部接口 webclient
- 3百度艾尼(ERNIE)常见问题汇总及解答_ernie ner
- 4每天一个设计模式之过滤器模式(Filter/Criteria Pattern)_c# 过滤器模式 设计模式
- 5【双曲几何学 02】什么是极点和极线?_极点极线
- 6浪潮服务器远程安装Ubuntu系统_浪潮服务器kvm装系统教程
- 72024年泰迪杯数据挖掘B题详细思路代码文章教程_泰迪杯2024数据
- 8【2024-03-24】小红书春招笔试三道编程题解
- 9基于AD9833的信号发生器_ad9833引脚图
- 10BetaFlight飞控启动&运行过程简介_betaflight spi
python之pandas库,快速学习
赞
踩
目录
(1)series:一维数据机构,可以保存任何类型的数据结构,相当于一列。
(1)DataFrame:是一个矩阵的数据类型,既有行索引,也有列索引。
(2)DataFrame:可以更改行索引(columns)和列索引(index)。
(1)to_excel:写入excel文件会创建一个新的文件。
(2)ExcelWriter:会在一个工作表中创建一个新的工作薄。
(2)选择多列数据:df[[’列1’,'列2']],通过列名组成的列表选择多列数据
(3)df[1:3],按行位置选取连续的行(切片),前闭后开
(1)单条件查询:单列布尔选择: df[(df['列’]==条件)],选取某列满足一定条件的行
(2)多条件查询:df[(df['列1’]-=条件)&(df['列2']>条件)],选取多列满足一定条件的行
(1)选择单行/多行数据: df.loc[’行号’]、df.loc[['行号’],['列名']】]
(3)loc切片(选择连续的多行多列): df.loc[’行1':'行2','列1':'列2'],通过切片选取连续的行列组合,冒号前后留空代表开口
(4)iloc索引器中只能使用原始索引(位置信息),不能使用自定义索引。
(2)sort_index()函数:在指定轴上根据索引值对数据进行排序,默认使用行索引升序排序。
一、pandas的两种数据结构
1.pandas导入
![]()
2.Series
(1)series:一维数据机构,可以保存任何类型的数据结构,相当于一列。
例如:存放列表类型

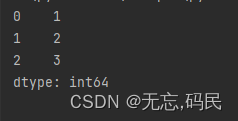
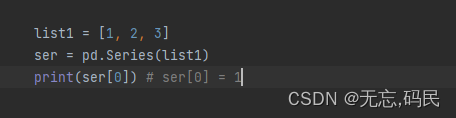
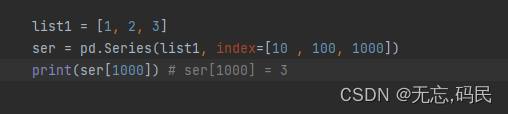
(2)series默认索引从0开始。也通过可以指定索引。
未指定索引前:
指定索引后:
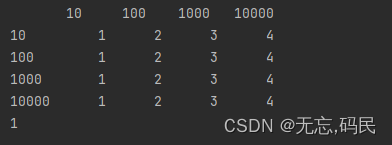
3.DataFrame
(1)DataFrame:是一个矩阵的数据类型,既有行索引,也有列索引。


(2)DataFrame:可以更改行索引(columns)和列索引(index)。

(3)DataFrame的基本函数

1、rename()
columns:修改行名
index:修改列名
inplace=True :是否在原数据中进行修改,默认为False。 

2、insert()
loc:插入第几列
column:插入的列名
value:插入的值
allow_duplicates:是否允许列名重复,默认为Flase。


3、drop()
labels:单个标签或标签列表。
axis:{0或'index',1或'columns'},是从索引还是列中删除标签,默认0,从行索引中删除。
index:单个标签或标签列表: columns = labels 等效于 labels,axis=1。
inplace:默认为False,返回新的DataFrame,True表示直接在原数据上删除。

4、head() 和 tail()


二、pandas操作Excel
1.写入Excel文件
(1)to_excel:写入excel文件会创建一个新的文件。


(2)ExcelWriter:会在一个工作表中创建一个新的工作薄。
mode填入值: w 代表重写
a 代表追加


pandas支持多种读写:CSV, JSON,HTMl,Local clipboard,Text File,Excel等
2.读取Excel文件
(1)read_excel
sheet_name:读取的表名
converters:修改类型

set_option(pat, value)
pat:
display.max_rows :设置DataFrame显示最大行数,pd.set_option('display.max_rows', None)显示所有行。
display.max_columns:设置DataFrame显示最大列数。
display.max_colwidth:设置DataFrame显示最大列宽。
display.precision:设置显示小数点后的位数。
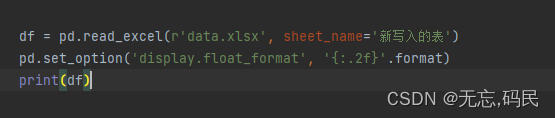
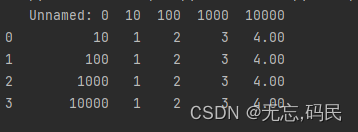
display.float_format:设置浮点数的显示格式。
例如:保留两位小数

三、pandas数据查询
1.直接查询
(1)选择单列数据:df['列’]


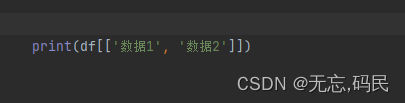
(2)选择多列数据:df[[’列1’,'列2']],通过列名组成的列表选择多列数据

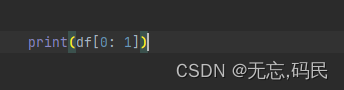
(3)df[1:3],按行位置选取连续的行(切片),前闭后开

2.条件查询
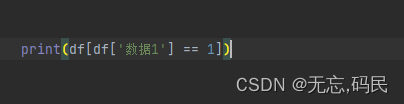
(1)单条件查询:单列布尔选择: df[(df['列’]==条件)],选取某列满足一定条件的行

(2)多条件查询:df[(df['列1’]-=条件)&(df['列2']>条件)],选取多列满足一定条件的行

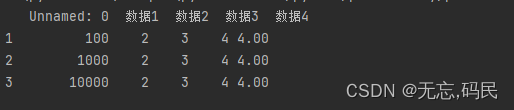
3.索引器查询
(1)选择单行/多行数据: df.loc[’行号’]、df.loc[['行号’],['列名']】]


(2)选择多行多列数据: df.loc[['行1','行2'],['列1','列2']],通过两个列表选取行列组合;loc布尔选择: df.loc[(df['列']>条件)],按条件选取单列(多列)满足一定条件的行
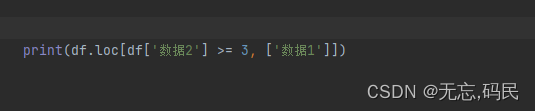

(3)loc切片(选择连续的多行多列): df.loc[’行1':'行2','列1':'列2'],通过切片选取连续的行列组合,冒号前后留空代表开口

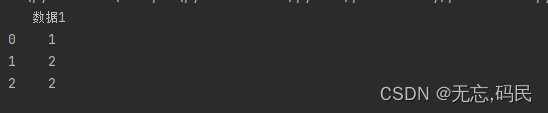
(4)iloc索引器中只能使用原始索引(位置信息),不能使用自定义索引。


四、数据处理

1.缺失值处理
(1)isna():检测缺失值

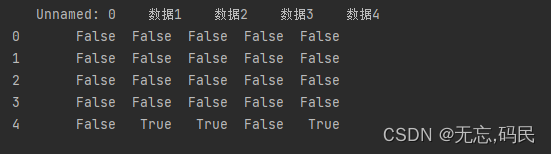
(2)dropna():删除缺失的值
axis:默认axis=0,表示删除包含缺失值的行,axis=1,表示删除包含缺失值的列
how:默认how='any',表示删除含有缺失值的所有行或列,how='all',表示删除全为缺失值的行或列
thresh:int,保留含有int个非空值的行、列
subset:对特定列进行缺失值删除

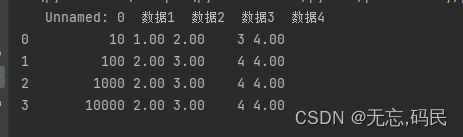
(3)fillna():使用指定的方法填充NA/NaN值
value:用于填充的值:数值、字符串、变量、字典、series、DataFrame,不能使用列表
method:填充方法:{'backfill','bfill','pad', 'ffill',None},默认为None,指定填充值,pad/ffill表示用前一个非缺失值填充,backfil1/bfill表示用后一个非缺失值填充
axis:填充缺失值所沿的轴,默认为None
limit:限制填充次数

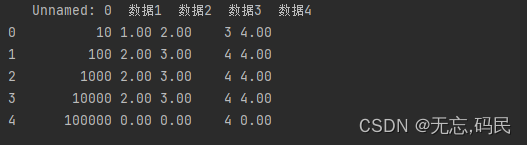
2.重复值处理
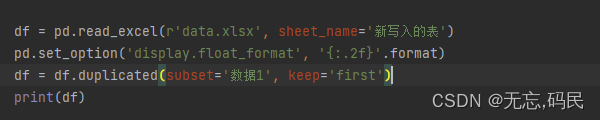
(1)duplicated():用于查找重复项
subset:列名,默认使用所有列
keep: keep='first':保留第一个重复值(默认值)
keep='last':保留最后一个重复值
keep=False:将所有重复值都删除

(2)drop_duplicated():删除重复值
ignore_index:重建索引,默认为False


3.其他异常处理
(1)replace():将所有数据转换为字符串,使用replace()函数进行替换


(2)astype():将pandas对象转换为指定的数据类型
dtype:数据类型:使用numpy.dtype或Python类型将整个pandas对布尔值,默认为True,表示返回一个副本
copy:布尔值,默认为True,表示返回一个副本
errors:针对数据类型转换无效引发异常的处理,默认为'raise',表示允许引发异常,errors='ignore’抑制异常,错误时返回原始对象


五、数据分析
1.描述性统计分析
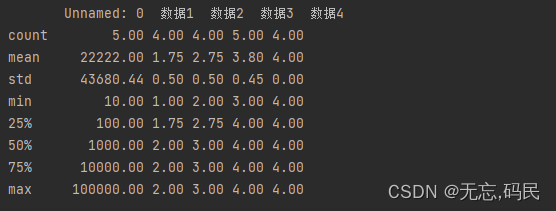
(1)count()
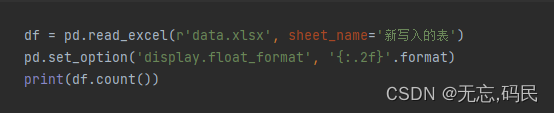

(2)discribe()
percentiles:百分位数,介于0-1之间,默认[25%,50%,75%]
include:包含在结果中的数据类型,默认所有数值列
exclude:排除在结果中的数据类型,默认不排除任何内容
datetime_is_numeric:是否将datetime dtypes视为数字,默认为False

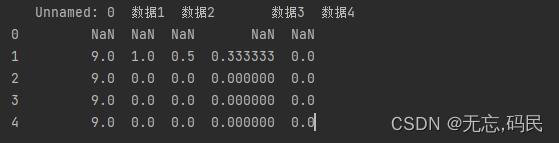
(3)pct_change():当前元素与先前元素之间的百分比变化,默认计算与前一行的百分比变化,适用于财务报表的环比分析
periods:计算周期,默认为1
fill_method:填充空值的方法,默认'pad',表示用前一个非缺失值填充,bfill用后一个非缺失值填充,None不填充
limit:限制填充次数
axis:计算方向,{0或'index',1或'columns'},默认axis=0

2.累计统计
(1)cumsum () 累计总和

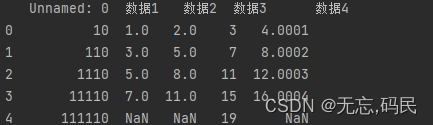
(2)cumprod() 累计乘积

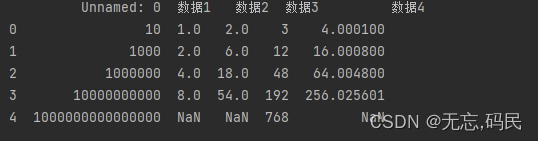
(3)cummax () 累计最大值


(4)cummin() 累计最小值
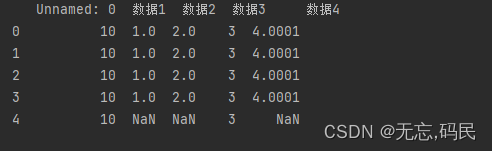
3.数据排序
(1)sort_values()函数语法
by:axis轴上的某个索引或索引列表,按什么排序
axis:要排序的轴,{0或'index',1或'columns'},默认0,按照指定列数据排序
ascending:排序方式,默认为True,代表升序排序,False代表降序排序
inplace:默认为False,True表示直接在原数据上排序
ignore_index:是否重建索引,默认为False
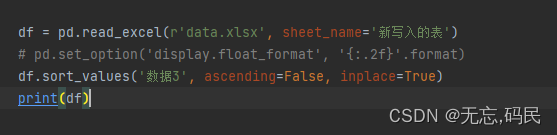
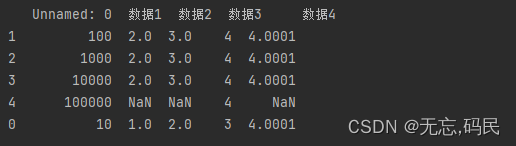
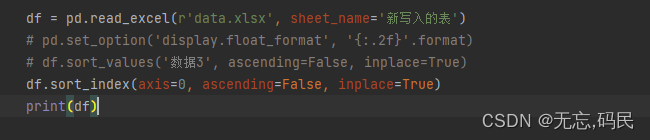
(2)sort_index()函数:在指定轴上根据索引值对数据进行排序,默认使用行索引升序排序。
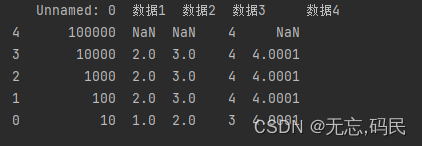
六、数据表的相互连接
1.merge()函数
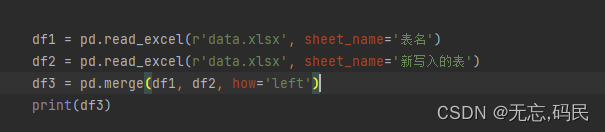
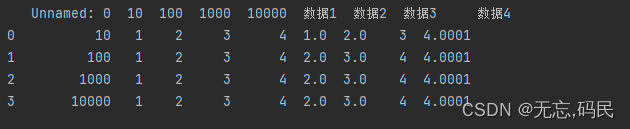
merge()函数:具有表连接功能,类似于Excel中的vlookup函数,可以根据一个或多个键(列值)将不同DataFrame连接起来
merge()表连接方式有inner、left、 right、outer,默认inner,空值用NaN填充
inner:内连接,取交集
outer:外连接,取并集
left:左连接,左侧取全部,右侧取部分
right:右连接,右侧取全部,左侧取部分
1.concat()函数
concat()函数:沿特定轴连接两个或两个以上的DataFrame,既可实现纵向合并也可实现横向合并,行列索引均可重复


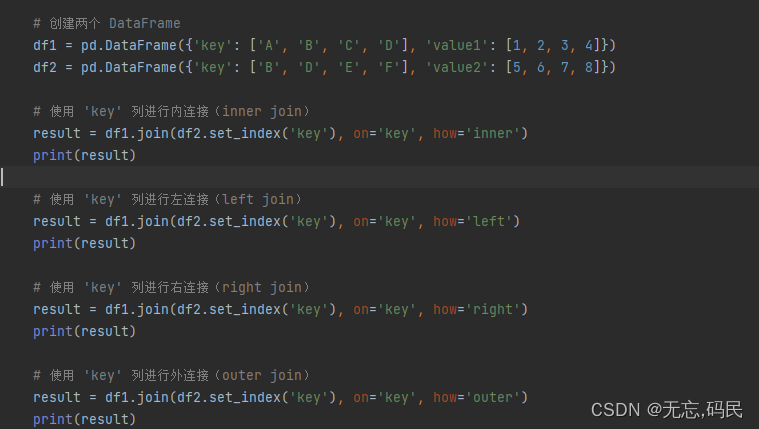
1.join()函数
join()函数:连接另一个DataFrame的列(横向连接),与merge()函数功能类似,区别在于两者适用的场景有所不同

1.append()函数
append()函数:向DataFrame对象中添加新的行(纵向合并),如果添加的列名不在DataFrame对象中,将会被当作新的列进行添加

七、分组聚合
1.groupby()
数据分组,即根据一个或多个DataFrame列名进行分组。
by:分类的依据,DataFrame列名
axis:默认axis=0:纵向分割,axis=1:横向分割
level:默认为True:返回以组标签为索引的对象,as_index=False:不以组标签为索引
sort:默认为True:按组键排序,设置为False可以提高性能


2.agg()
具有自定义聚合功能,允许在一次计算中,自定义多种聚合方式


八、数据透视
1.pivot_table
pivot_table()函数:类似于Excel中的数据透视表功能,是一种可以对数据动态排布并且分类汇总的表格格式,pivot_table可以将普通列转换为行索引、列索引及元素值,进行各种汇总计算。

2.转换轴
stack():将数据的列索引转换为行索引,默认转换最内层的索引
unstack():将数据的行索引转换为列索引,默认转换最内层的索引

