
- 1gitea设置SSH连接,显示Permission denied (publickey)_gitea ssh 没有权限
- 2HDMI设计5--GT Transceiver的总体架构整理_gth 实现 hdmi
- 3Stable Diffusion 3技术报告出炉:揭露Sora同款架构细节
- 4【自然语言处理】基于句子嵌入的文本摘要算法实现_grucell生成句子嵌入
- 5【hadoop大数据】HBase 安装_datasophon修改hbase组件版本
- 6第59天-服务攻防-中间件安全&CVE 复现&IIS&Apache&Tomcat&Nginx_if-none-match: "2d-432a5e4a73a80
- 7使用Labelimg标注出现错误:ValueError: not enough values to unpack (expected 5, got 1)
- 8STM32学习笔记【江科协】【4-1】OLED调试工具_oled屏幕江科大
- 9RabbitMQ windows 管理工具_rabbitmq management plugin
- 10超详细YOLOv8图像分类全程概述:环境、训练、验证与预测详解_yolov8分类
Spark安装部署说明(单机)_vmware安装spark单机版
赞
踩
0.环境说明
硬件环境:VMWare虚拟机,内存2GB
操作系统:Ubuntu12.04 32位操作系统 (64位操作系统的话更好,但是虚拟机还是32位吧)
准备安装软件:JDK1.7 , Hadoop2.6.0, Scala2.10.4, Spark1.2.0
1.安装JDK
(1) 下载JDK1.7(建议1.7) ,名为jdk-7u79-linux-i586.tar.gz,下载地址http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
(2) 将下载的jdk-7u79-linux-i586.tar.gz复制到/usr/local目录
进入文件所在目录,cp jdk-7u79-linux-i586.tar.gz /usr/local
(3) 解压缩
# tar zxvf jdk-7u79-linux-i586.tar.gz,
得到jdk1.7.0_79文件夹,为其创建快捷方式:
# ln –s jdk1.7.0_79 java- 1
(4) 修改配置文件~/.bashrc,添加环境变量:
# sudo gedit ~/.bashrc //打开文件- 1
向该文件末尾添加如下语句并保存:
export JAVA_HOME=/usr/local/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH- 1
- 2
- 3
- 4
关闭,控制台输入
# source ~/.bashrc激活环境变量- 1
输入 java –version验证是否配置正确
2 配置ssh无密码登陆
(1)安装ssh-server
# apt-get install openssh-server- 1
(2)控制台输入
# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys- 1
- 2
(3)验证ssh,# ssh localhost,如果能直接进入即可(第一次输入需要新建,输入y)
输入exit可退出
3 安装hadoop2.6.0
(1) 下载hadoop-2.6.0.tar.gz。Hadoop2.6.0本身是通过64位JDK编译的,如果操作系统和JDK均为64位,可官网直接下载
32位操作系统也能使用
(2) 将下载的hadoop-2.6.0.tar.gz复制到/usr/local目录
进入文件所在目录,cphadoop-2.6.0.tar.gz /usr/local
(3) 解压缩
# tar zxvf hadoop-2.6.0.tar.gz,- 1
得到hadoop-2.6.0文件夹
(4) 进入hadoop-2.6.0文件夹的etc/hadoop进行配置,配置以下文件:hadoop-env.sh ; core-site.xml;hdfs-site.xml;mapred-site.xml
hadoop-env.sh 找到
# The java implementation to use.
export JAVA_HOME=${JAVA_HOME}- 1
- 2
修改为
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/local/java- 1
- 2
- 3
core-site.xml 删除里面所有,写入
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.6.0/tmp</value>
</property>
</configuration>
hdfs-site.xml删除里面所有,写入
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop-2.6.0/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop-2.6.0/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
注:dfs.replication一定是1,因为我们是单机版本的,正常情况下是3
mapred-site.xml 好像一开始没这个文件,新建(直接输入sudo gedit mapred-site.xml即可,或者touch mapred-site.xml),写入
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
(5) 关闭防火墙(防火墙可能会影响到hadoop工作,但是单机版本应该不影响)
# sudo ufw disable- 1
(6) 创建以下文件夹(在(3)中配置的一些地址)
mkdir /usr/local/hadoop-2.6.0/tmp
mkdir /usr/local/hadoop-2.6.0/hdfs
mkdir /usr/local/hadoop-2.6.0/hdfs/name
mkdir /usr/local/hadoop-2.6.0/hdfs/data
(7) 启动hadoop (在hadoop文件夹目录)
1) 格式化namenode
# bin/hdfs namenode –format- 1
2) 启动相应进程
# sbin/start-all.sh- 1
3)输入jps可看到进程
4)浏览器输入localhost:8088可出现以下UI界面
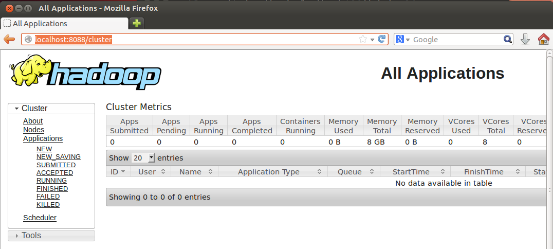
4. 安装scala
(1) 下载下载scala-2.10.4.tgz,地址http://www.scala-lang.org/download/2.10.4.html
(2) 拷贝到/usr/local文件夹并解压
# cp scala-2.10.4.tgz /usr/local
# tar zxvf scala-2.10.4.tgz- 1
- 2
(3) 配置环境变量,文件~/.bashrc
# sudo gedit ~/.bashrc- 1
加入以下配置并保存:
export SCALA_HOME=/usr/local/scala-2.10.4
export PATH=$JAVA_HOME/bin$HADOOP_HOME/bin:$HIVE_HOME/bin:$SCALA_HOME/bin:$PATH
# source ~/.bashrc激活配置- 1
- 2
- 3
(4)控制台输入scala验证是否配置成功
输入exit可退出
5.安装spark-1.2.0-bin-hadoop2.4
(1)下载spark-1.2.0-bin-hadoop2.4.tgz,解压到/usr/local/spark-1.2.0-bin-hadoop2.4。
下载地址http://spark.apache.org/downloads.html
(2) 配置环境变量,文件~/.bashrc
# sudo gedit ~/.bashrc- 1
加入以下配置并保存:
export SPARK_HOME=/usr/local/spark-1.2.0-bin-hadoop2.4
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$HIVE_HOME/bin:$PATH
# source ~/.bashrc激活配置- 1
- 2
- 3
(3) 配置spark
进入spark目录的conf文件夹,输入
# cd $SPARK_HOME/conf
# cp spark-env.sh.template spark-env.sh 复制配置文件
# sudo gedit spark-env.sh 文件末尾加入
export JAVA_HOME=/usr/local/java
export SCALA_HOME=/usr/local/scala-2.10.4
export HADOOP_CONF_DIR=/usr/local/hadoop-2.6.0/etc/Hadoop
保存
(4) 进入spark目录启动spark
# sbin/start-all.sh- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输入jps可看到进程
(5)在浏览器中输入localhost:8080可看到spark的ui界面
结束spark进程:
Spark目录下sbin/stop-all.sh
结束hadoop进程:
Hadoop目录下sbin/stop-all.sh


