
热门标签
热门文章
- 1类中静态容器对象如何初始化_c++类中静态容器如何初始化
- 2女文科生“弃文从理”转行做测试员,我是怎么做到工资涨了4倍的_文科转理科薪资大涨案例
- 3jeecgboot前台表格加载以及添加的执行流程_jeecglistmixin
- 4通过串口中断的方式进行ASR-01S模块与STM32通信(问题与解决)_lu-asr01与stm32如何通信
- 5《Redis-Windows平台下Redis安装配置及使用》_redis windows配置
- 6torch-scatter、torch-sparse、torch-cluster、torch-spline-conv安装失败问题解决_torch-sparse不支持1.7
- 7技术速递|为 .NET iOS 和 .NET MAUI 应用程序添加 Apple 隐私清单支持_ios 给动态sdk手动添加隐私清单
- 8SadTalker-Video-Lip-Sync: 创新的视频唇语同步技术
- 9微信小程序云开发--云存储的使用(一)_微信小程序 调用云盘怎么用
- 10达梦数据库使用图形化界面建简单模式、表、列、外键及索引_达梦数据库创建外键
当前位置: article > 正文
【深度学习】YOLOv5,烟雾和火焰,目标检测,防火检测,森林火焰检测
作者:很楠不爱3 | 2024-04-24 10:24:47
赞
踩
【深度学习】YOLOv5,烟雾和火焰,目标检测,防火检测,森林火焰检测
数据收集和数据标注
搜集数据集2w张。
pip install labelme
labelme
然后标注矩形框和类别。
下载数据请看这里:
https://qq742971636.blog.csdn.net/article/details/137999662
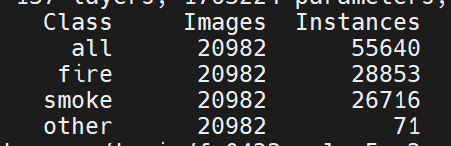
三个标签,各个标签的数量:
火焰框28852个
烟雾框26716个
其他红旗71个框
查看标注好的数据的脚本
输入图片路径和标签路径可以一张一张浏览照片:
import os import cv2 import numpy as np # 图像和标签文件夹路径 image_folder = r'F:\BaiduNetdiskDownload\fireandsmoke_last\fireandsmoke_last\images_choose' label_folder = r'F:\BaiduNetdiskDownload\fireandsmoke_last\fireandsmoke_last\labels' # 定义类别颜色(这里假设有两个类别,你可以根据实际情况扩展) class_colors = [(0, 255, 0), (0, 0, 255), (255, 0, 0)] class_name = ['fire', 'smoke'] # 获取文件夹中的所有图像文件 image_files = [f for f in os.listdir(image_folder) if f.endswith('.jpg') or f.endswith('.png')] # 遍历图像文件 for image_file in image_files: image_path = os.path.join(image_folder, image_file) label_path = os.path.join(label_folder, os.path.splitext(image_file)[0] + '.txt') # 检查是否存在标签文件 if os.path.exists(label_path): # 读取图像 image = cv2.imread(image_path) # 读取标签内容 with open(label_path, 'r') as file: lines = file.readlines() class_id_all = [] # 遍历标签行 for line in lines: values = line.split() class_id = int(values[0]) x_center = float(values[1]) * image.shape[1] y_center = float(values[2]) * image.shape[0] width = float(values[3]) * image.shape[1] height = float(values[4]) * image.shape[0] # 计算边界框的左上角和右下角坐标 x1 = int(x_center - width / 2) y1 = int(y_center - height / 2) x2 = int(x_center + width / 2) y2 = int(y_center + height / 2) # 获取当前类别的颜色 color = class_colors[class_id] # 在图像上绘制矩形框和类别标签数字 cv2.rectangle(image, (x1, y1), (x2, y2), color, 2) cv2.putText(image, class_name[class_id], (x1, y1 + 15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2) class_id_all.append(class_id) # if 2 not in class_id_all: # continue # 等比缩放到最长边为800 max_size = 800 if image.shape[0] > image.shape[1]: scale = max_size / image.shape[0] else: scale = max_size / image.shape[1] image = cv2.resize(image, (int(image.shape[1] * scale), int(image.shape[0] * scale))) # 显示图像 cv2.imshow('Image', image) # 等待按键输入,按下任意键跳到下一张图 cv2.waitKey(0) cv2.destroyAllWindows()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
比如:


下载yolov5
下载yolov5
git clone https://github.com/ultralytics/yolov5.git
cd yolov5/
- 1
- 2
创建环境:
conda create -n py310_yolov5 python=3.10 -y
conda activate py310_yolov5
- 1
- 2
- 3
装一个可以用的torch:
# CUDA 11.8
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=11.8 -c pytorch -c nvidia
- 1
- 2
- 3
- 4
取消这2个:
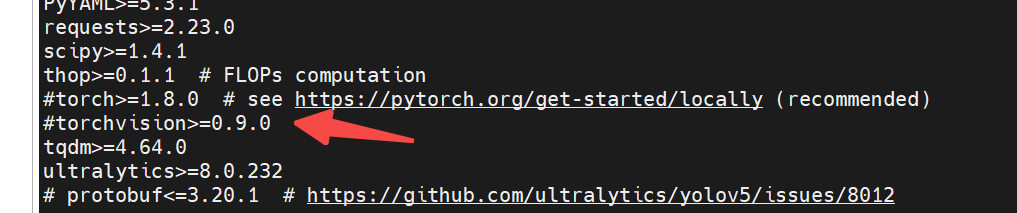
然后安装一些别的包:
pip install -r requirements.txt # install
- 1
随后更多内容参考官网这里的训练指导:
https://docs.ultralytics.com/zh/yolov5/tutorials/train_custom_data/#before-you-start
创建 dataset.yaml
创建文件:
cd yolov5/data
cp coco128.yaml fire_smoke.yaml
- 1
- 2
- 3
将fire_smoke.yaml修改为这样:
path: /ssd/xiedong/fireandsmoke_last/
train: images
val: images
test: # test images (optional)
# Classes
names:
0: fire
1: smoke
2: other
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
训练参数
使用python train.py --help查看训练参数:
# python train.py --help 警告 ⚠️ Ultralytics 设置已重置为默认值。这可能是由于您的设置存在问题或最近 Ultralytics 包更新导致的。 使用 'yolo settings' 命令或查看 '/home/xiedong/.config/Ultralytics/settings.yaml' 文件来查看设置。 使用 'yolo settings key=value' 命令来更新设置,例如 'yolo settings runs_dir=path/to/dir'。更多帮助请参考 https://docs.ultralytics.com/quickstart/#ultralytics-settings。 用法: train.py [-h] [--weights WEIGHTS] [--cfg CFG] [--data DATA] [--hyp HYP] [--epochs EPOCHS] [--batch-size BATCH_SIZE] [--imgsz IMGSZ] [--rect] [--resume [RESUME]] [--nosave] [--noval] [--noautoanchor] [--noplots] [--evolve [EVOLVE]] [--evolve_population EVOLVE_POPULATION] [--resume_evolve RESUME_EVOLVE] [--bucket BUCKET] [--cache [CACHE]] [--image-weights] [--device DEVICE] [--multi-scale] [--single-cls] [--optimizer {SGD,Adam,AdamW}] [--sync-bn] [--workers WORKERS] [--project PROJECT] [--name NAME] [--exist-ok] [--quad] [--cos-lr] [--label-smoothing LABEL_SMOOTHING] [--patience PATIENCE] [--freeze FREEZE [FREEZE ...]] [--save-period SAVE_PERIOD] [--seed SEED] [--local_rank LOCAL_RANK] [--entity ENTITY] [--upload_dataset [UPLOAD_DATASET]] [--bbox_interval BBOX_INTERVAL] [--artifact_alias ARTIFACT_ALIAS] [--ndjson-console] [--ndjson-file] 选项: -h, --help 显示帮助信息并退出 --weights WEIGHTS 初始权重路径 --cfg CFG 模型配置文件路径 --data DATA 数据集配置文件路径 --hyp HYP 超参数路径 --epochs EPOCHS 总训练轮数 --batch-size BATCH_SIZE 所有 GPU 的总批量大小,-1 表示自动批处理 --imgsz IMGSZ, --img IMGSZ, --img-size IMGSZ 训练、验证图像大小(像素) --rect 矩形训练 --resume [RESUME] 恢复最近的训练 --nosave 仅保存最终检查点 --noval 仅验证最终轮次 --noautoanchor 禁用 AutoAnchor --noplots 不保存绘图文件 --evolve [EVOLVE] 为 x 代演进超参数 --evolve_population EVOLVE_POPULATION 加载种群的位置 --resume_evolve RESUME_EVOLVE 从上一代演进恢复 --bucket BUCKET gsutil 存储桶 --cache [CACHE] 图像缓存 ram/disk --image-weights 在训练时使用加权图像选择 --device DEVICE cuda 设备,例如 0 或 0,1,2,3 或 cpu --multi-scale 图像大小变化范围为 +/- 50% --single-cls 将多类数据作为单类训练 --optimizer {SGD,Adam,AdamW} 优化器 --sync-bn 使用 SyncBatchNorm,仅在 DDP 模式下可用 --workers WORKERS 最大数据加载器工作进程数(每个 DDP 模式中的 RANK) --project PROJECT 保存到项目/名称 --name NAME 保存到项目/名称 --exist-ok 存在的项目/名称正常,不增加 --quad 四通道数据加载器 --cos-lr 余弦学习率调度器 --label-smoothing LABEL_SMOOTHING 标签平滑 epsilon --patience PATIENCE EarlyStopping 耐心(未改善的轮次) --freeze FREEZE [FREEZE ...] 冻结层:backbone=10, first3=0 1 2 --save-period SAVE_PERIOD 每 x 轮保存检查点(如果 < 1 则禁用) --seed SEED 全局训练种子 --local_rank LOCAL_RANK 自动 DDP 多 GPU 参数,不要修改 --entity ENTITY 实体 --upload_dataset [UPLOAD_DATASET] 上传数据,"val" 选项 --bbox_interval BBOX_INTERVAL 设置边界框图像记录间隔 --artifact_alias ARTIFACT_ALIAS 要使用的数据集 artifact 版本 --ndjson-console 将 ndjson 记录到控制台 --ndjson-file 将 ndjson 记录到文件
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
开始训练
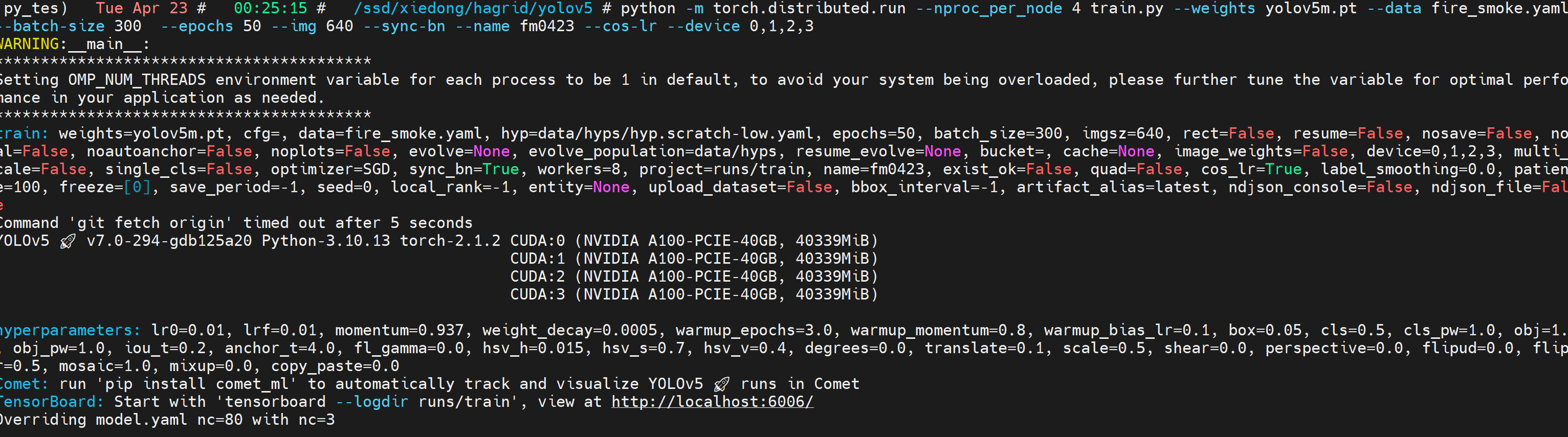
多卡训练:
python -m torch.distributed.run --nproc_per_node 4 train.py --weights yolov5m.pt --data fire_smoke.yaml --batch-size 300 --epochs 50 --img 640 --sync-bn --name fm0423 --cos-lr --device 0,1,2,3
- 1
- 2
正常启动训练:
少量图片损坏不用管:
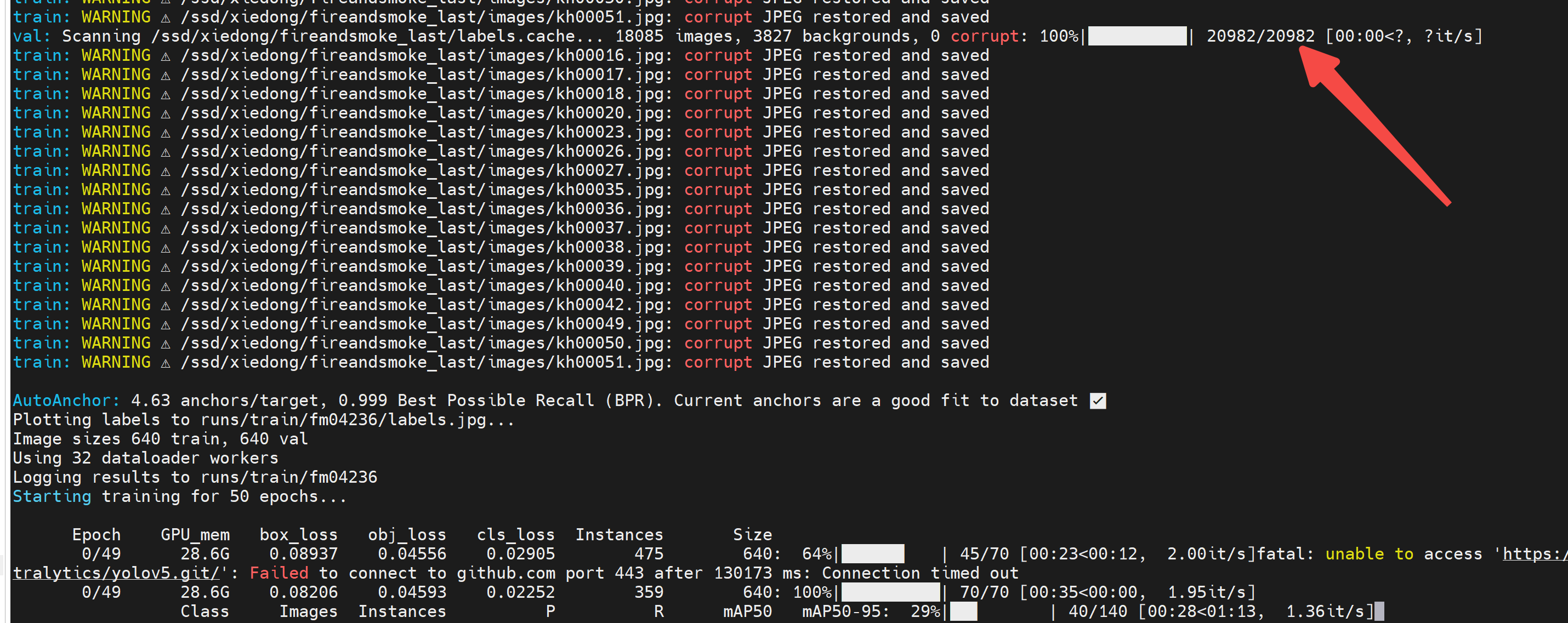
我的数据集很难,是野外数据,可见刚开始指标并不好:

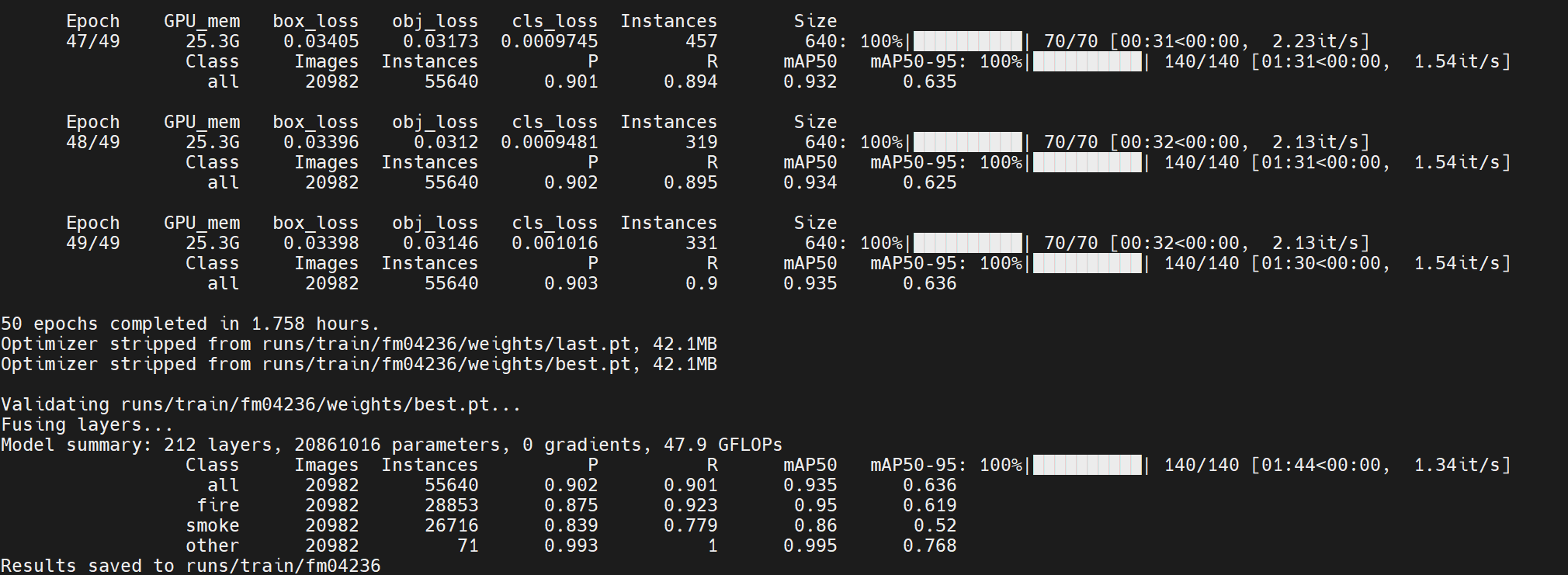
训练结束:
yolov5n训练
多卡训练:
python -m torch.distributed.run --nproc_per_node 4 train.py --weights yolov5n.pt --data fire_smoke.yaml --batch-size 1200 --epochs 50 --img 640 --sync-bn --name fm0423_yolov5n_ --cos-lr --device 0,1,2,3
- 1
- 2
模型太小,yolov5n的效果欠佳了:

训练后的权重下载
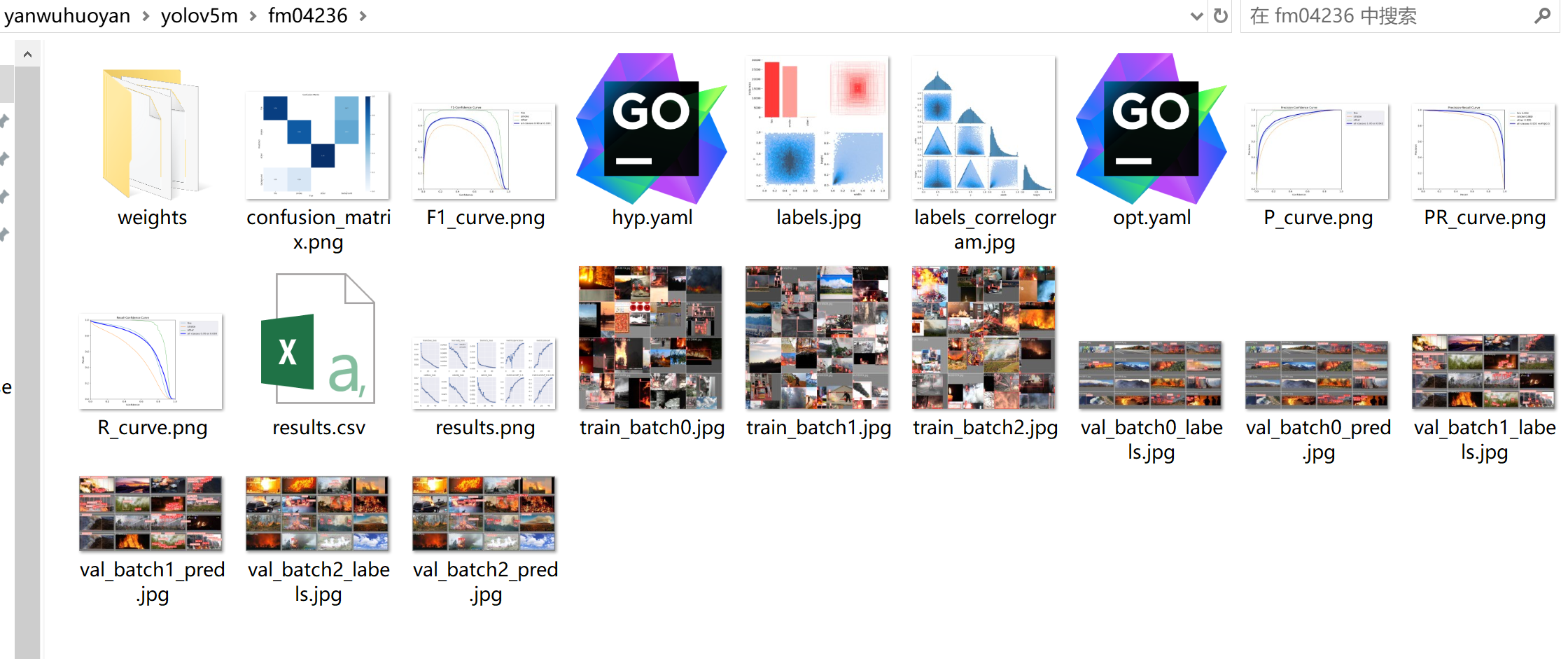
yolov5m的训练结果文件:
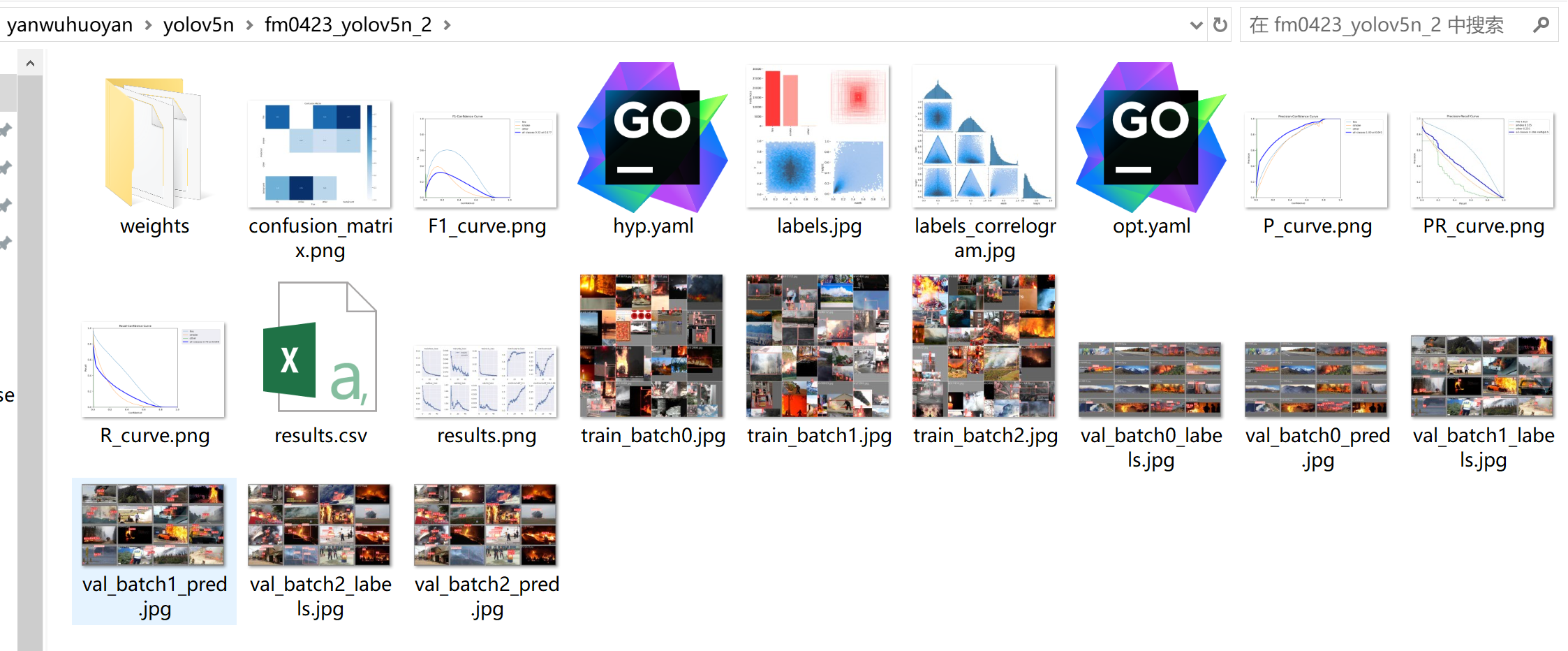
yolov5n的训练结果文件:
权重下载请看这里:
https://docs.qq.com/sheet/DUEdqZ2lmbmR6UVdU?tab=BB08J2
- 1
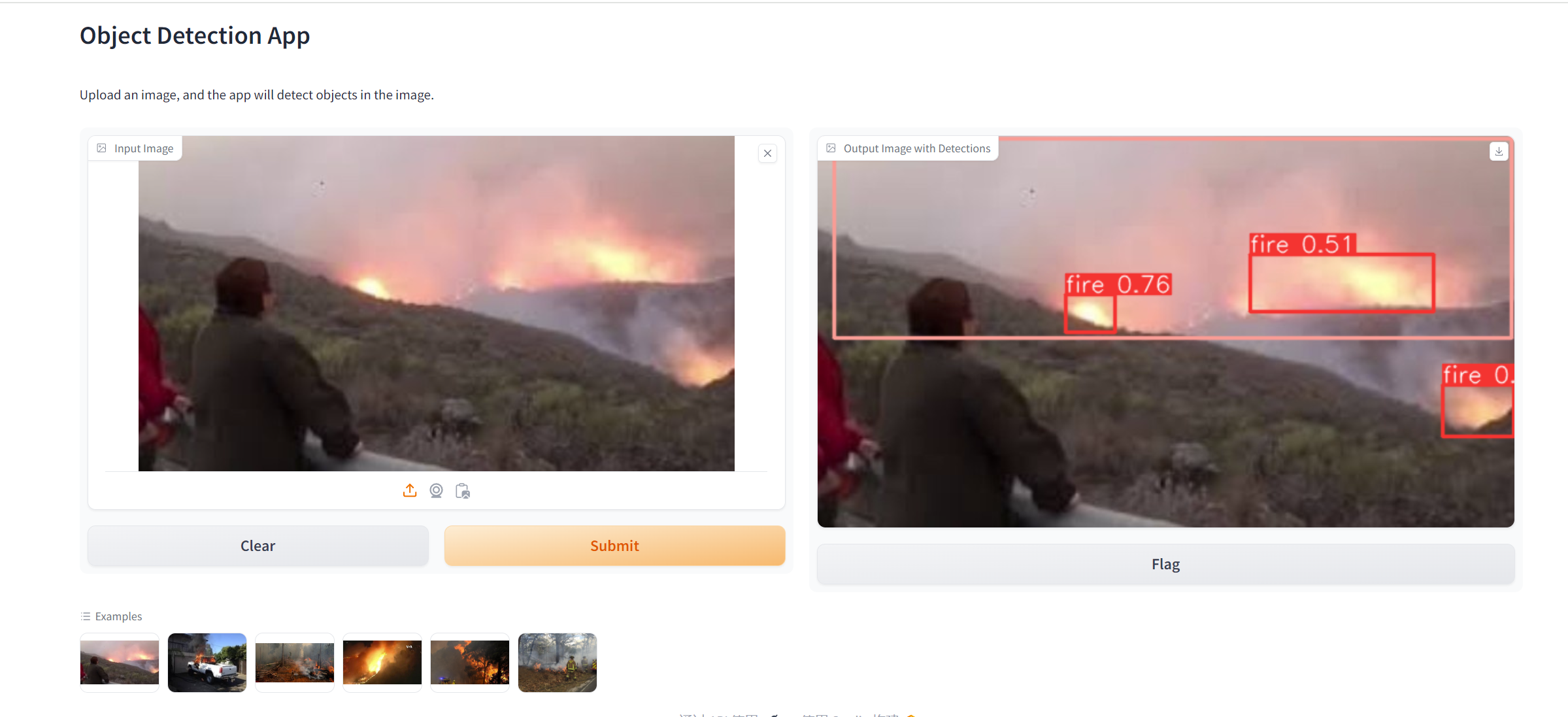
gradio部署
import gradio as gr import time import torch from PIL import Image def detect_objects(img): time1 = time.time() # Run inference results = model(img) time2 = time.time() print(f"Time taken for inference: {time2 - time1:.2f} seconds") # Print JSON print(results.pandas().xyxy[0].to_json(orient="records")) results.render() im_pil = Image.fromarray(results.ims[0]) return im_pil # Model loading model = torch.hub.load('/data/xiedong/eff_train/yolov5-master', 'custom', path='./best.pt', source='local', device='cuda:0', force_reload=True) inputs = gr.Image(label="Input Image", type="pil") outputs = gr.Image(label="Output Image with Detections", type="pil") title = "Object Detection App" description = "Upload an image, and the app will detect objects in the image." # examples = ["ok.jpg"] # 当前目录的jpg文件 import os files = os.listdir() examples = [f for f in files if f.endswith(".jpg")] gr.Interface(detect_objects, inputs, outputs, title=title, description=description, examples=examples).launch( server_name="0.0.0.0", server_port=7873)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
部署后打开网页即可尝试:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/很楠不爱3/article/detail/478911
推荐阅读
相关标签

