
热门标签
热门文章
- 1RabbitMQ知识点整理_rabbitmq知识点总结
- 2Python 植物大战僵尸
- 3在Echarts区域的任何位置精准触发事件_echarts getzr
- 4使用PyCharm创造现代艺术(一)_pycharm画散点图
- 5前端利器,6 款开源 Web 性能优化辅助工具推荐_前端优化加载速率软件有哪些
- 6python多进程之间共享内存_python 共享内存
- 7Android审计平台,Android系统安全审计方法研究
- 8RabbitMQ 简单测试_com.rabbitmq.client.possibleauthenticationfailuree
- 9git强制推送分支到远程
- 10三人表决器_数电小实验之三人表决器
当前位置: article > 正文
使用 vllm 本地部署 cohere 的 command-r
作者:很楠不爱3 | 2024-04-30 23:17:18
赞
踩
使用 vllm 本地部署 cohere 的 command-r
0. 引言
此文章主要介绍使用 使用 vllm 本地部署 cohere 的 command-r。
1. 安装 vllm
conda create -n myvllm python=3.11 -y
conda activate myvllm
- 1
- 2
安装 Ray 和 Vllm,
pip install ray vllm
- 1
安装 flash-attention,
git clone https://github.com/Dao-AILab/flash-attention; cd flash-attention
pip install flash-attn --no-build-isolation
- 1
- 2
2. 本地部署 cohere 的 command-r
eval "$(conda shell.bash hook)"
conda activate myvllm
CUDA_VISIBLE_DEVICES=3,2,1,0
python -m vllm.entrypoints.openai.api_server --trust-remote-code --served-model-name gpt-4 --model CohereForAI/c4ai-command-r-v01 --gpu-memory-utilization 0.98 --tensor-parallel-size 4 --port 8000
- 1
- 2
- 3
- 4
3. 使用 cohere 的 command-r
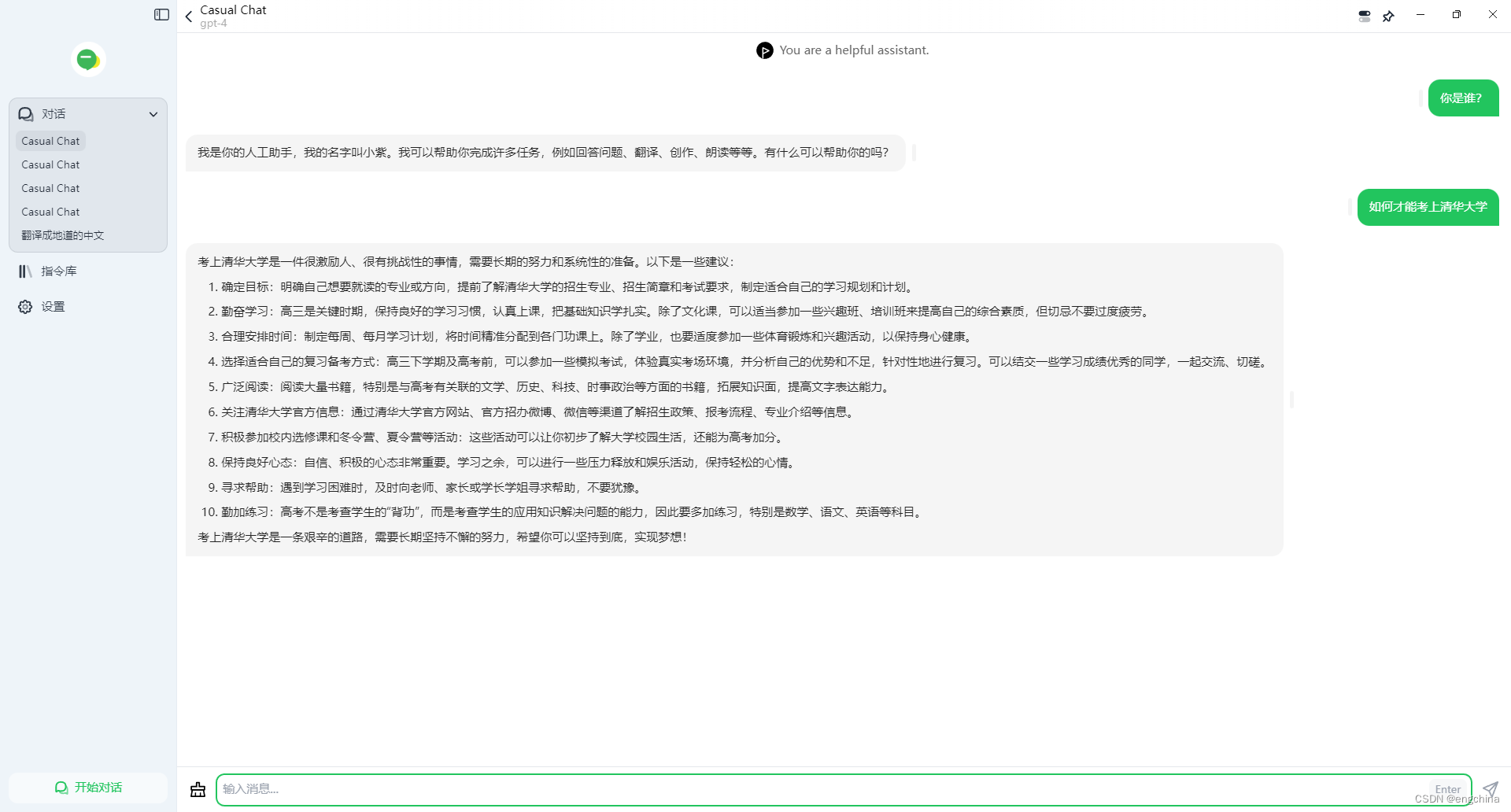
完结!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/很楠不爱3/article/detail/515784
推荐阅读
相关标签

