
今日arXiv最热大模型论文:大模型也来看球,还能判断是否犯规
赞
踩
在足球世界,裁判的哨声可谓“千金难买”,因为它能直接决定俱乐部的钱包是鼓是瘪。但球场变化莫测,非常考验裁判的水平。
2022年卡塔尔世界杯上,半自动越位识别技术(SAOT)闪亮登场,通过12台摄像机,每秒50次追踪球员的29个数据点,精确绘制出越位线,辅助裁判做越位判别,以防错判和漏判。

除此之外,有学者开始研究让大模型来“看球”,通过视频判断球员是否违规并给出相应的解释。
这个模型叫做X-VARS,在足球领域SoccerNet-XFoul数据集上进行了训练与验证。这个数据集包含了超过22k个视频-问题-答案三元组,涵盖了最基本的裁判问题。超过70名专业裁判为数据集提供了详尽的标注和决策解释,确保了数据的质量和准确性。
经过验证,X-VARS在SoccerNet-MVFoul数据集上取得了最先进的性能,X-VARS生成的决策解释水平竟与人类裁判相当。一起来看看是否真的有这么厉害。

论文标题:
X-VARS: Introducing Explainability in Football Refereeing with Multi-Modal Large Language Models
论文链接:
https://arxiv.org/pdf/2404.06332.pdf
SoccerNet-XFoul数据集构建
SoccerNet-XFoul,是一个专门设计用于犯规视频识别和解释的数据集。它包含高质量的视频文本对,超过10k个视频剪辑和22k个问题,由70多名经验丰富的裁判进标注。
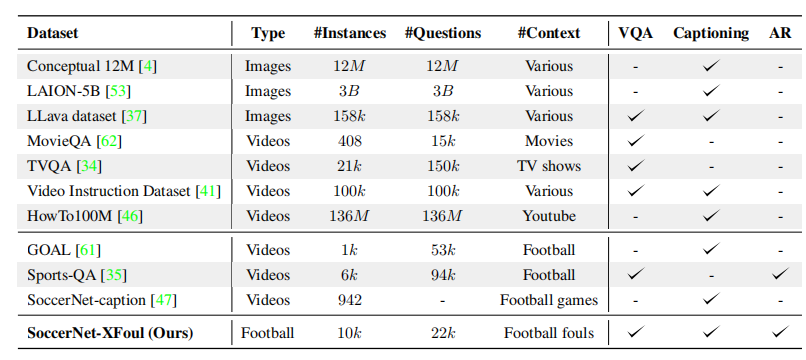
与其他体育数据集相比,如下图所示,SoccerNet-XFoul是体育领域中最大的数据集,涵盖了复杂问题,并且是唯一专注于裁判问题的数据集。
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4):
https://hiclaude3.com
1. 确定问题
作者首先确定了裁判在比赛中必须面对的最基础、最复杂和对比赛产生影响的决定的4个关键问题:
-
“这是犯规吗?为什么?” ;
-
“你会给出什么牌?为什么?”;
-
“防守者是否阻止了有希望的进攻或进球机会?” ;
-
“裁判是否可以给予优势?”。
要回答这四个问题,模型需要深入理解比赛规则,以及理解行为发生的背景。必须考虑诸如意图、犯规位置、比赛动态和接触强度等因素。问题的答案不仅仅是视觉的,模型还必须对潜在的未来结果进行预测。例如,在评估裁判是否应该给予优势时,模型需要评估进攻方是否更有利于继续比赛而不是获得任意球。
标注者
为确保答案质量,作者精选了经验丰富的裁判进行标注。这些裁判平均执裁了655场正式比赛,经验丰富。他们可以灵活评估视频剪辑,随时暂停避免疲劳。标注者可选择德语、法语、英语或西班牙语作答,确保语言无障碍。答案经ChatGPT-3.5翻译后再由人类裁判审核,保证翻译准确。
主观性
裁判在判决时也带有很强的主观性,如下图所示,两位裁判都认为视频中的行为是犯规的。但一位裁判认为犯规强度较低,不会出示牌,而另一位标注员认为铲球速度很快且鲁莽,会出示黄牌。

由于裁判工作中存在这种固有的主观性,数据集会收集同一行为的多个答案,而不是为每个问题收集单一的决定和解释。这种多个决定和解释实际上帮助模型学习人类裁判采用的一系列有效解释和推理策略。这可以提高 AI 模型的鲁棒性,使其能够在模糊或主观情况下做出明智的决策。
为确保同一行为得到多次评估,我们随机分配视频剪辑给标注者。最终,每个行为平均拥有1.5个相同问题的答案,丰富了模型的学习资源。
数据集统计
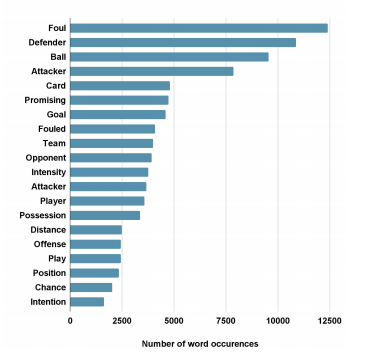
该数据集包含10k个视频剪辑,其中包含超过22k个裁判生成的问题和答案。下图显示了裁判标注者解释中最常见单词的分布。最常用的单词是用于描述两名球员之间对抗的特定术语,从描述性术语如defender或card到评估犯规时要考虑的关键术语如intention或intensity。每个答案的单词数量范围从1到66,总共超过540k个单词,平均每个答案近25个单词,单词分布存在显著不平衡。
方法
架构
本文的目标任务是识别是否犯规,并提供了关于其决策过程的解释。主要架构如下图所示:
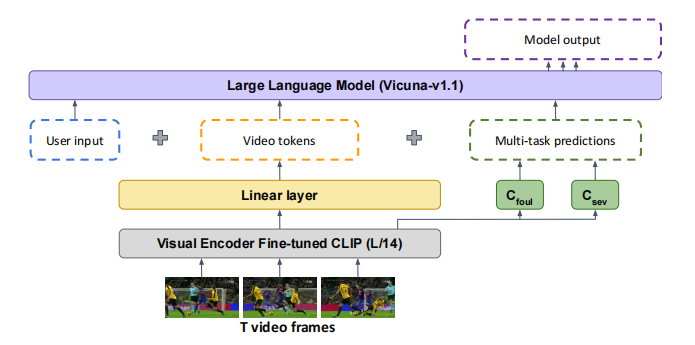
使用多模态模型Video-ChatGPT作为基础模型,能够理解和生成关于视频的详细对话。首先输入一个视频剪辑视频,其中 T、H、W 和 C 分别是视频的帧数、高度、宽度和通道维度,以供 CLIP ViT-L/14 模型 使用。
![]()
通过上述公式获得相应的帧特征向量和隐藏状态.其中通过将 和 相乘获得的tokens数量, 是 CLIP 的 patch 大小,是输出层的维度,是隐藏状态的维度。然后沿时间维度对隐藏状态进行平均池化,以获得时间特征 ,并沿空间维度进行池化以获得视频级空间表示
。最后将两者连接起来以获得时空特征。
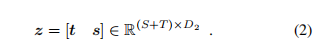
在将视频特征 输入LLM之前,通过应用线性投影层将其投影到与文本嵌入相同的特征空间中。
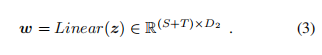
使用表示一系列视觉标记。特征向量也沿时间维度进行平均池化,以获得单个视频级表示。视频级特征表示通过两个分类头和C_{sev}传递,以获得犯规类型(即铲球、拉扯、推搡、站立铲球、肘击、假摔、挑战或高腿)并确定是否犯规,以及相应的严重程度(即无犯规、犯规+无牌、犯规+黄牌或犯规+红牌),预测结果为:

为了在LLM中获得高性能,关键在于找到LLM能够理解的提示。鉴于使用的是VideoChatGPT骨干,作者精心设计了以下查询作为提示,以优化模型性能:
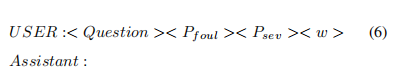
其中代表从视频-问题-答案三元组的训练集中随机抽取的一个问题, < >和< >是从经过微调的CLIP获得的关于犯规类型和严重程度识别任务的两个预测, < >是投影的时空特征。
两阶段训练方法
作者第一阶段对CLIP进行微调,进行多任务分类以学习关于足球和裁判的先验知识。第二步是微调投影层和几层LLM,以增强模型在特定领域的生成能力。
-
阶段1微调CLIP以融入足球专业知识。虽然CLIP擅长泛化到各类图像任务,但在识别细粒度动作或事件方面仍显不足。这类动作的识别需综合考虑时间维度,而非仅依赖静态图像。例如,评估足球犯规的严重程度需考虑动作强度和速度,这无法通过单张图像准确判断。由于CLIP未针对足球数据训练,不同情景的足球视频片段可能产生相似特征,使得LLM难以区分动作。因此,作者在SoccerNet-MVFoul数据集上微调CLIP,以学习足球相关知识。训练过程中,最小化两个任务的交叉熵损失之和,鉴于损失量级相近,直接相加而不进行缩放或加权。
-
阶段2涉及特征对齐和端到端训练。保持微调后的CLIP权重不变,仅对线性投影层和LLM进行训练。采用VideoChatGPT的预训练投影层权重作为起点进一步微调这个投影层,确保足球片段的时空特征能够与词嵌入处于同一维度空间,实现特征的有效对齐。在训练过程中,使用CLIP的预测标签<>和<>的groundtruth标签<>和<>进行替换,因为CLIP的预测可能存在噪音,导致混淆。为确保模型能够充分利用视频信息,采用了端到端的训练策略,使模型能够在整个流程中学习到最佳的特征表示和文本生成方式。
实验
人类评估
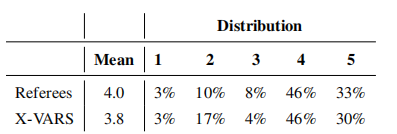
作者邀请了20名足球裁判对X-VARS模型回答的质量进行评估。这些裁判并不知道这些解释是由人类裁判还是由X-VARS系统生成的,确保了评估的公正性和客观性。
每位裁判随机评估了20个视频片段,每个片段时长为5秒,且评估过程不受时间限制。裁判们主要关注解释的质量,判断其是否与视频内容保持一致,以及决定和解释是否符合《比赛规则》。裁判们根据1到5的评分标准对每个解释进行打分,其中5分代表“非常同意”,1分代表“非常不同意”。
下表显示了结果,X-VARS 的表现与人类裁判类似,只有极小的分数差异。
定性评估
下图展示了使用X-VARS模型判决的过程:

在图(a)中X-VARS能够准确回答用户的问题,与真实情况基本一致,图(b)展示了犯规情况的主观性。X-VARS将犯规解释为中等强度,而人类裁判将其解释为低强度,没有机会触球。
结论
本文邀请70多名经验丰富的裁判员标注了一个犯规视频识别和解释的数据集——SoccerNet-XFoul。还提出了一个多模态LLM:X-VARS,从裁判的角度理解足球视频。X-VARS不仅具备视频描述、问题回答、动作识别等多种功能,更能根据视频内容展开有意义的对话,判断足球运动员是否犯规,并给出合理且专业的理由。
这一研究不仅展示了多模态大语言模型在足球视频理解领域的巨大潜力,更为未来的研究提供了新的思路与方向。我们期待着X-VARS在足球领域发挥更大的作用,为比赛的公正性和透明度贡献更多力量。



