
- 1批量添加数据的方法_columnmappings.add
- 2STM32平台下夏普GP2Y1010AU0F灰尘传感器使用及源码
- 3数据结构(C语言版) 第 三 章 栈与队列 知识梳理 + 作业习题详解_以下运算实现在链栈上的进栈,请在空白处用请适当句子予以填充。 void push(lstack
- 4[Git] 两种方法合并多个commit为一个_goalnd 合并commit
- 5【整理总结】几十个程序员硬核工具_程序员代码笔记软件
- 6使用AI大模型生成代码比对: js 去掉字符串末尾的点号 (天工AI, 通义千问, 文心一言)_ai 代码比对
- 7处理Git将本地大文件上传到公共区域失败
- 8php使用imagemagick处理图片圆角_php imagemagick圆角图片
- 9flume出现org.apache.hadoop.fs.UnsupportedFileSystemException: No FileSystem for scheme “hdfs“
- 10k8s + docker + Jenkins使用Pipeline部署SpringBoot项目时Jenkins错误集锦_hudson.plugins.git.gitexception: failed to fetch f
STM32CubeIDE开发(三十一), stm32人工智能开发应用实践(Cube.AI).篇一_cubeai
赞
踩
目录
一、cube.AI简介及cubeIDE集成
1.1 cube.AI介绍
cube.AI准确来说是STM32Cube.AI,它是ST公司的打造的STM32Cube生态体系的扩展包X-CUBE-AI,专用于帮助开发者实现人工智能开发。确切地说,是将基于各种人工智能开发框架训练出来的算法模型,统一转换为c语言支持的源码模型,然后将c模型与STM32的硬件产品结合,实现人工智能模型可直接部署在前端或边缘端设备,实现人工智能就地计算。关于cube.AI 的各种信息可以从ST官网上查看和下载其相关资料:X-CUBE-AI - STM32CubeMX的AI扩展包 - STMicroelectronics
cube.AI 以插件形式支持ST相关开发平台如cubeIDE、cubeMX、keil等,整体开发过程分为三个主要部分,1)收集及治理数据,2)训练及验证模型,3)c模型生成及前端或边缘端部署,如下图所示:
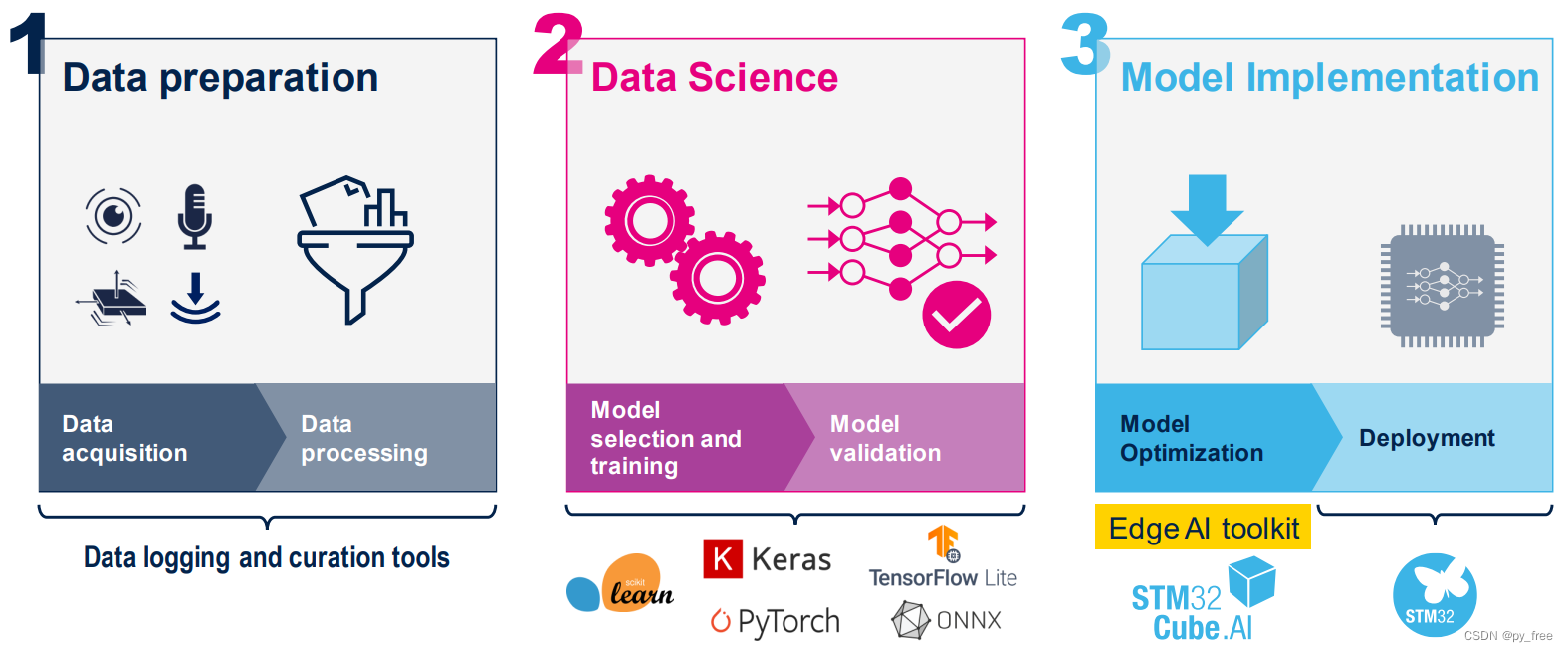
目前cube.AI支持各种深度学习框架的训练模型,如Keras和TensorFlow™ Lite,并支持可导出为ONNX标准格式的所有框架,如PyTorch™、Microsoft® Cognitive Toolkit、MATLAB®等,然后通过 cube.MX可视化配置界面导入这些深度学习框架导出的训练模型来配置及生成c模型,进而部署在STM32芯片上。
1.2 cube.AI与cubeIDE集成与安装
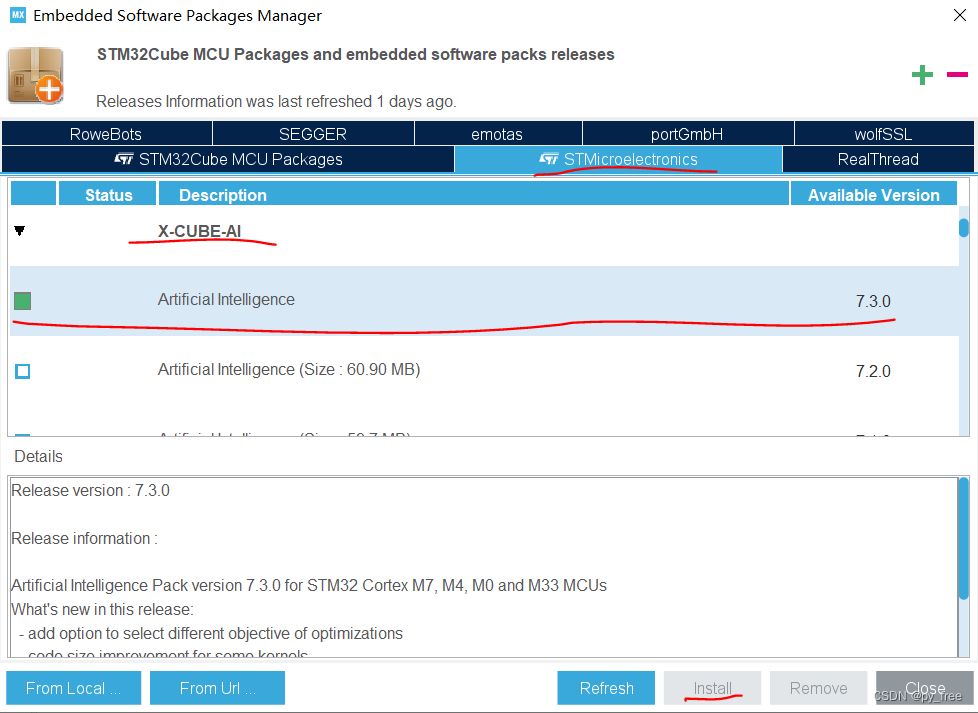
在cubeIDE的帮助菜单栏,选择嵌入式软件包管理项(Embedded Software Packages Manager)进入X-CUBE-AI扩展包安装页面。选择X-CUBE-AI需要的版本进行安装即可,如下图所示,安装完成后,该版本前面方框呈绿色标记。
1.3 cube.AI支持硬件平台
得益于ST公司不断的优化及迭代X-CUBE-AI扩展包,神经网络模型生成c模型后得以使用更小的算力资源和几乎无损的算法精度,因此使其能部署到STM32绝大多数的芯片上,目前其支持的MCU及MPU型号如下图所示。

1.4 cube.AI应用的好处
将神经网络边缘化部署后,减少延迟、节约能源、提高云利用率,并通过大限度地减少互联网上的数据交换来保护隐私,而结合X-CUBE-AI使得神经网络部署在边缘端端的便捷、灵活、低成本,微机智能成为更多产品的选择。
二、FP-AI-SENSING1
2.1 FP-AI-SENSING1简介
FP-AI-SENSING1是ST公司提供的STM32Cube.AI示例,可通过BLE(低功耗蓝牙)将物联网节点连接到智能手机,并使用STBLESensor应用程序,配置设备,实现数据采集,使得用于训练神经网络模型的数据更贴近实际使用场景,具有更好的训练效果和精度。
FP-AI-SENSING1软件包更多介绍及信息请参考ST官网:
FP-AI-SENSING1 - 具有基于声音和运动感应的人工智能(AI)应用的超低功耗IoT节点的STM32Cube功能包 - STMicroelectronics
在FP-AI-SENSING1案例页面,下载源码包及其数据手册。
2.2 FP-AI-SENSING1软件包支持硬件平台
ST公司为FP-AI-SENSING1示例运行提供了硬件平台,支持开发者快速学习了解FP-AI-SENSING1示例,从而了解Cube.AI的开发过程。

三、FP-AI-SENSING1部署
3.1 B-L475E-IOT01A开发板
本文采用ST公司的B-L475E-IOT01A开发板,打开CubeMX工具,选择Start my project from ST Board,搜索B-L475E-IOT01A,如下图所示,可以在1、2、3页面下载开发板相关的原理框图、文档及案例、说明手册。
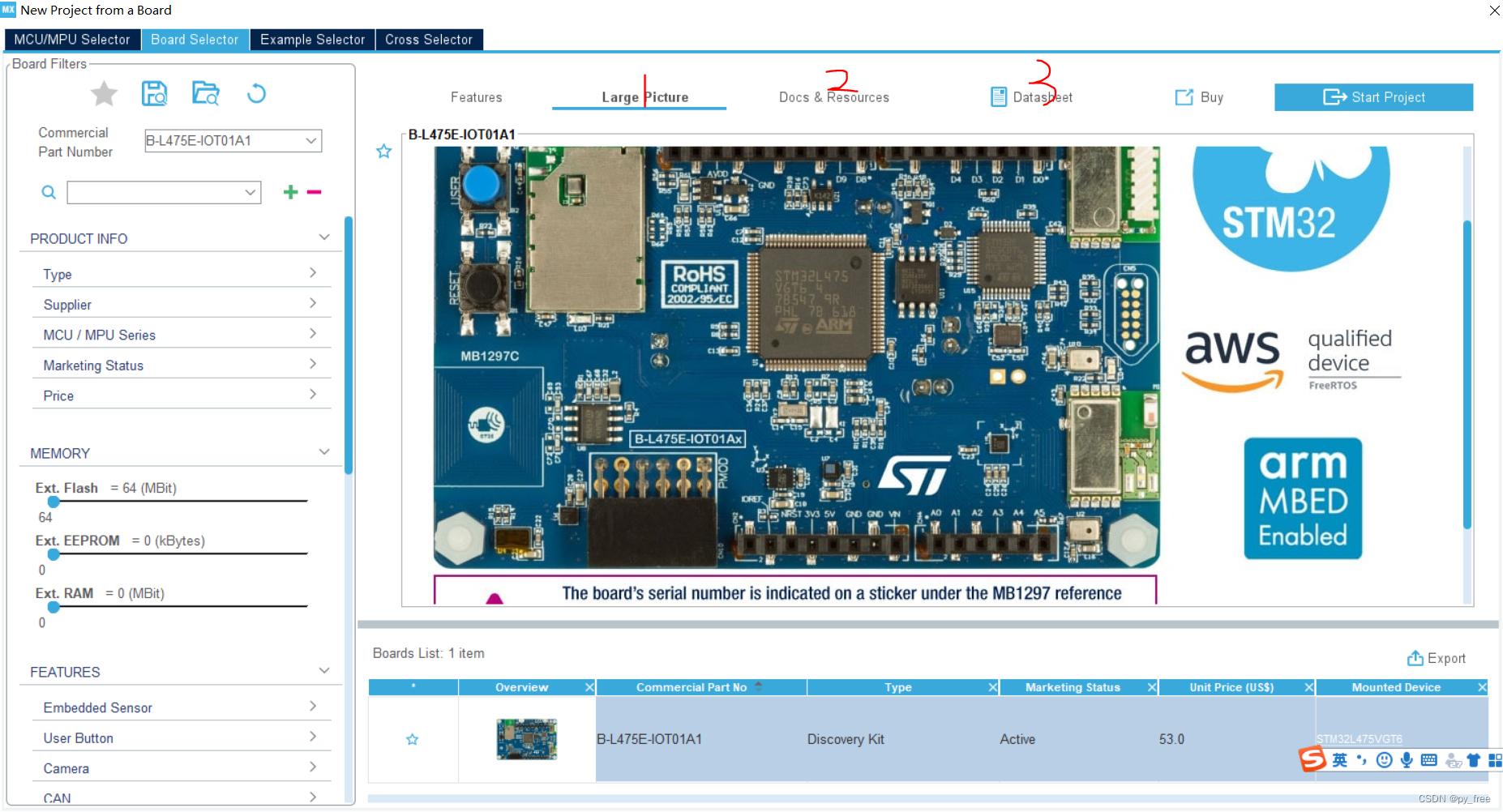
3.2 FP-AI-SENSING1软件包下载及配置
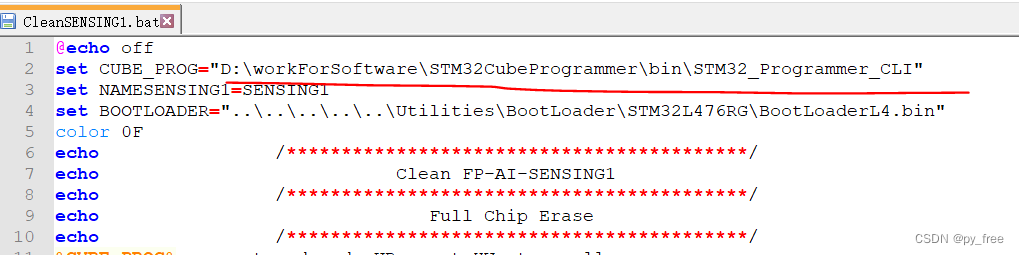
下载FP-AI-SENSING1软件包后,解压下载的源码包:en.fp-ai-sensing1.zip,进入“STM32CubeFunctionPack_SENSING1_V4.0.3\Projects\B-L475E-IOT01A\Applications\SENSING1\STM32CubeIDE”目录,用文本编辑工具打开“CleanSENSING1.bat”,(linux系统的,采用CleanSENSING1.sh文件)。
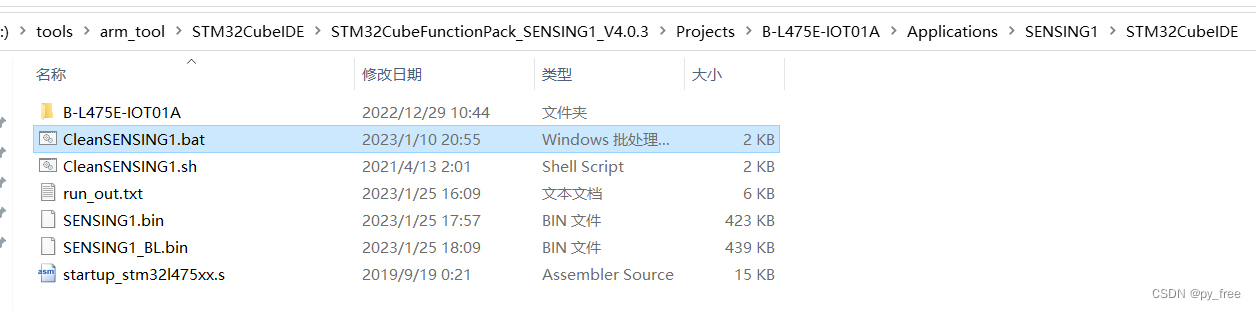
CleanSENSING1.bat运行依赖STM32cube生态的另一个开发工具:STM32CubeProgrammer,该工具可以帮助开发者读取、写入和验证设备内存等。
STM32CubeProg - 用于STM32产品编程的STM32CubeProgrammer软件 - STMicroelectronics
在STM32CubeProgrammer工具下载页面,下载该工具及说明手册:
下载并安装STM32CubeProgrammer工具,例如本文安装目录为:D:\workForSoftware\STM32CubeProgrammer
修改CleanSENSING1.bat依赖工具“STM32CubeProgrammer”的路径:
3.3 固件烧录
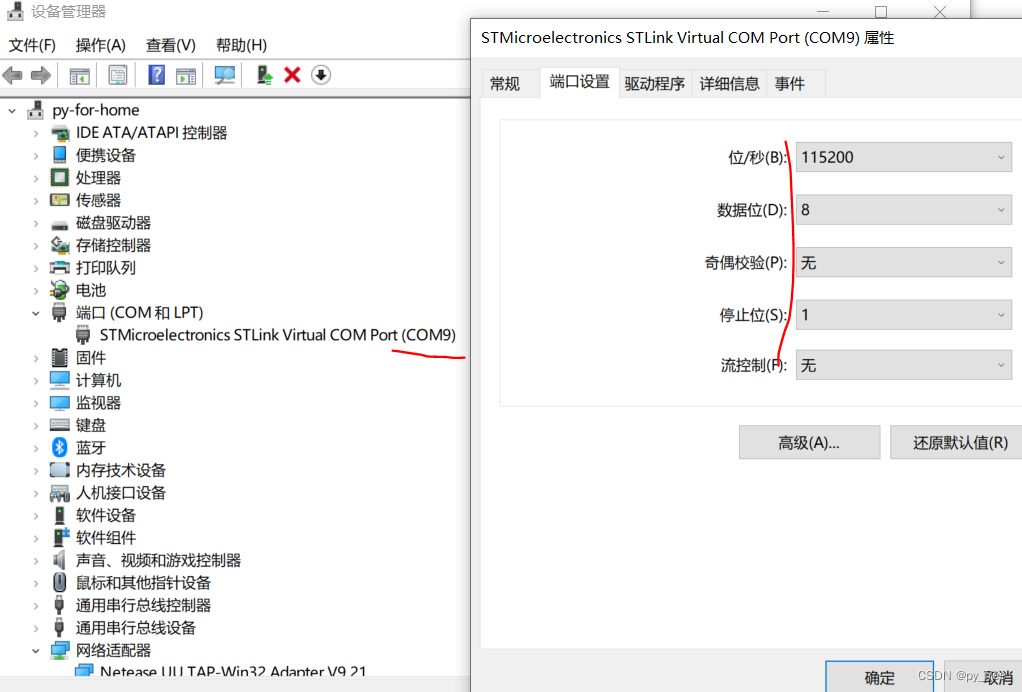
将B-L475E-IOT01A开发板用Micro USB连接到电脑上,

连接之后,驱动会自动安装,进入设备管理页面,确认串口编号和配置串口参数。
右键CleanSENSING1.bat文件以管理员身份运行,将在开发板安装引导加载程序和更新固件。
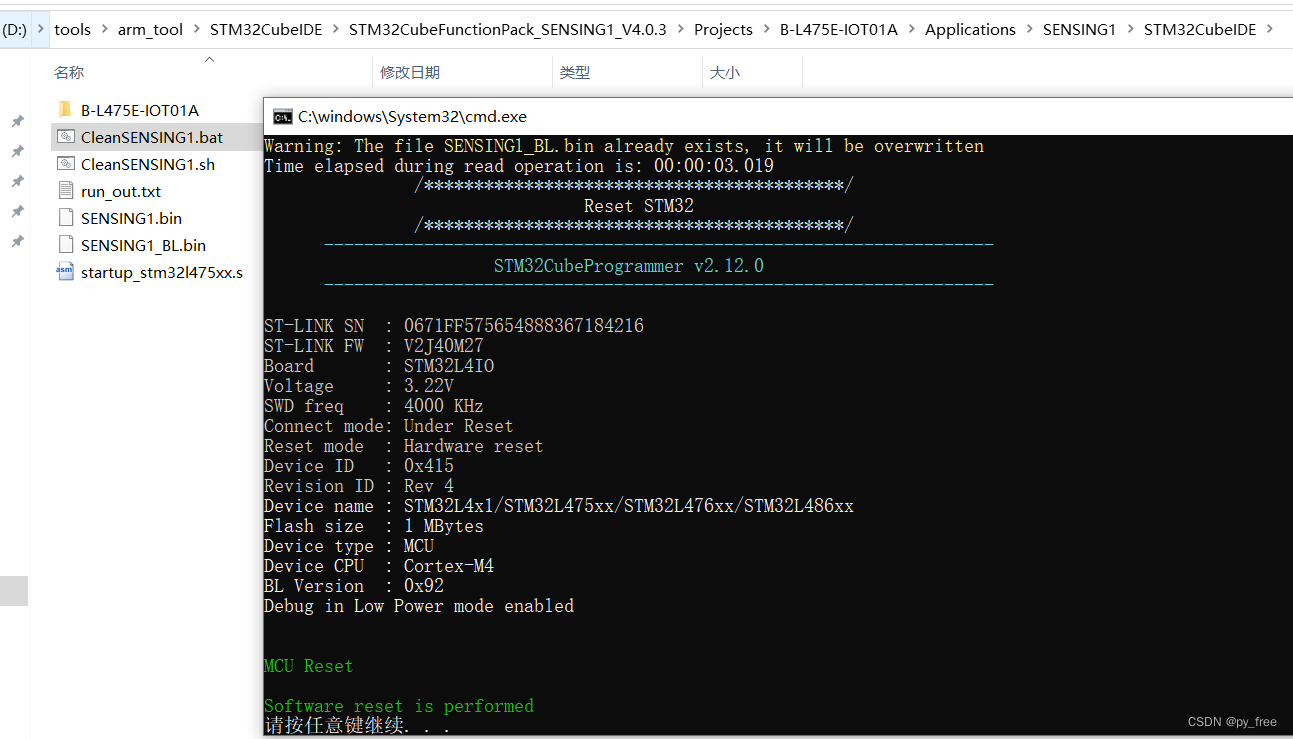
该脚本可以对B-L475E-IOT01A开发板实现以下操作,
•完全闪存擦除
•在右侧闪存区域加载BootLoader
•在右侧闪存区域加载程序(编译后)
•重置电路板
3.4 FP-AI-SENSING1示例工程部署
在该目录下,进入“B-L475E-IOT01A”目录,用CubeIDE打开.project,打开FP-AI-SENSING1工程。
打开该工程后如下图所示,用户可调整源码在User目录,关于本工程信息请查看readme.txt文件。
在main.c函数中找到Init_BlueNRG_Stack函数,该函数可以设置BLE(低功耗蓝牙)的服务名,
- static void Init_BlueNRG_Stack(void)
- {
- char BoardName[8];
- uint16_t service_handle, dev_name_char_handle, appearance_char_handle;
- int ret;
-
- for(int i=0; i<7; i++) {
- BoardName[i]= NodeName[i+1];
- }
该函数采用默认的BLE名称,该默认名称定义在SENSING1.h设置,例如:IAI_403

现在调整BLE名称为AI_Test
- static void Init_BlueNRG_Stack(void)
- {
- // char BoardName[8];
- char BoardName[8] = {'A','I','_','T','e','s','t'};
- uint16_t service_handle, dev_name_char_handle, appearance_char_handle;
- int ret;
-
- for(int i=0; i<7; i++) {
- // BoardName[i]= NodeName[i+1];
- NodeName[i+1] = BoardName[i];
- }
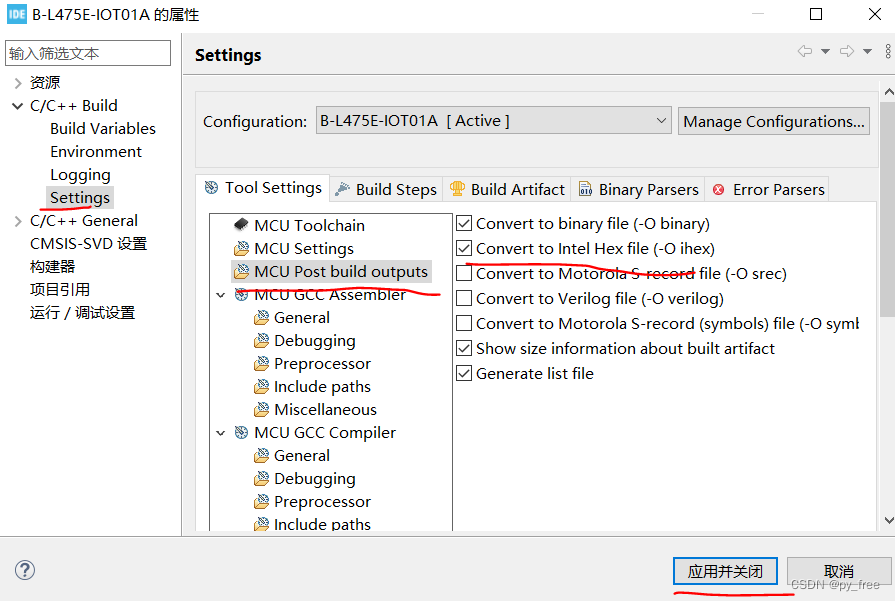
配置工程输出格式支持如下:
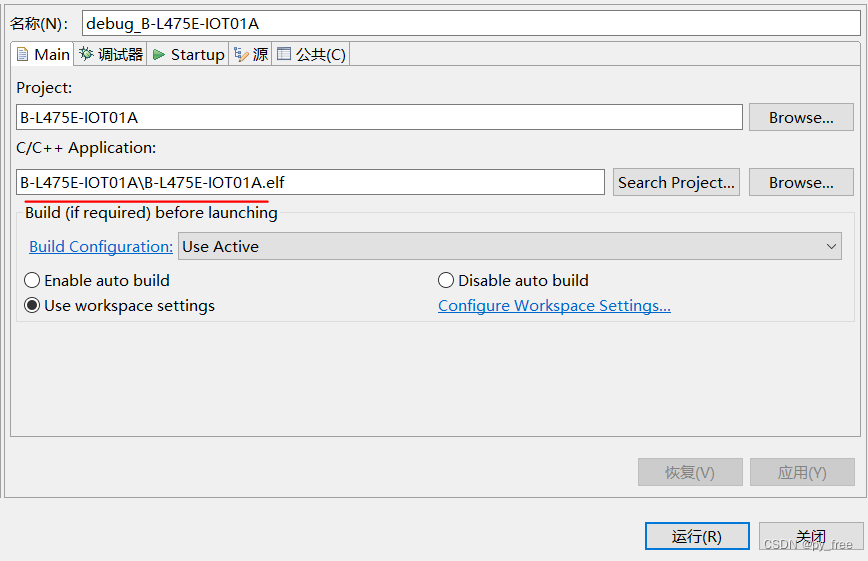
配置运行设置如下:
然后编译及下载程序:

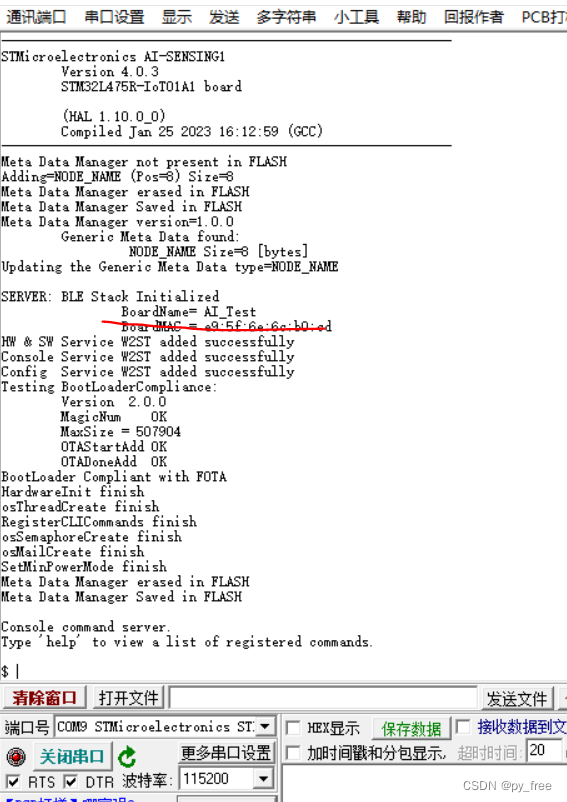
打开串口工具,连接上对于串口,点击开发板上的重置按钮(黑色按钮),串口日志输出如下,日志显示BLE模块启动成功:
四、数据采集
4.1 STBLE-Sensor软件下载安装
确保手机支持低功耗蓝牙通信,进入ST的BLE传感器应用下载页面,
STBLESensor - 用于安卓和iOS的BLE传感器应用 - STMicroelectronics
下载对应的手机应用程序:

4.2 STBLESensor配置数据采集
本文用的是华为手机及android系统,安装完成APP后启动进入界面(当前版本是4.14),点击搜索,得到AI_Test蓝牙服务名。
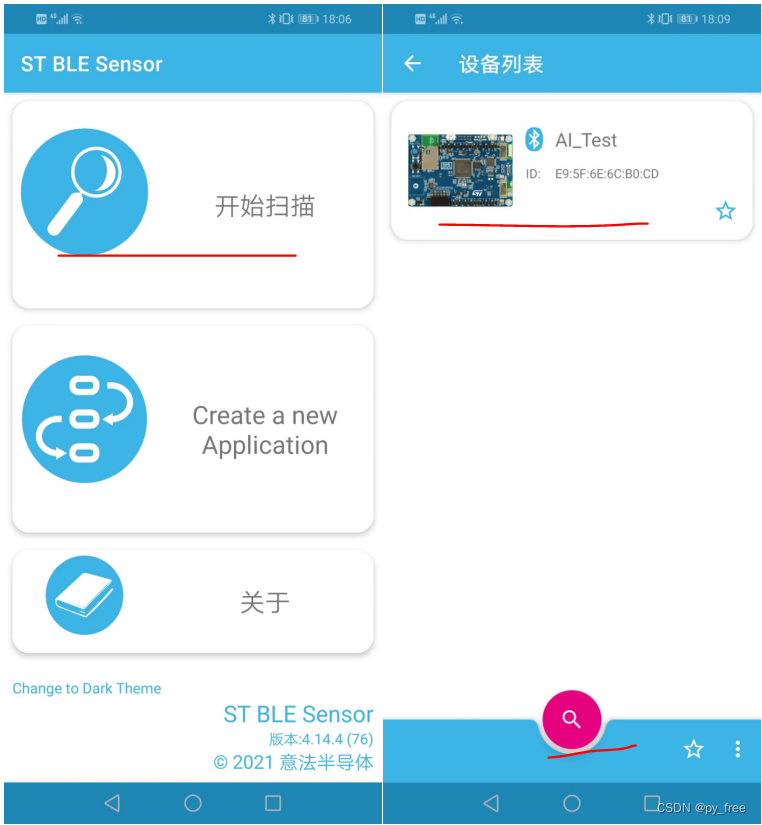
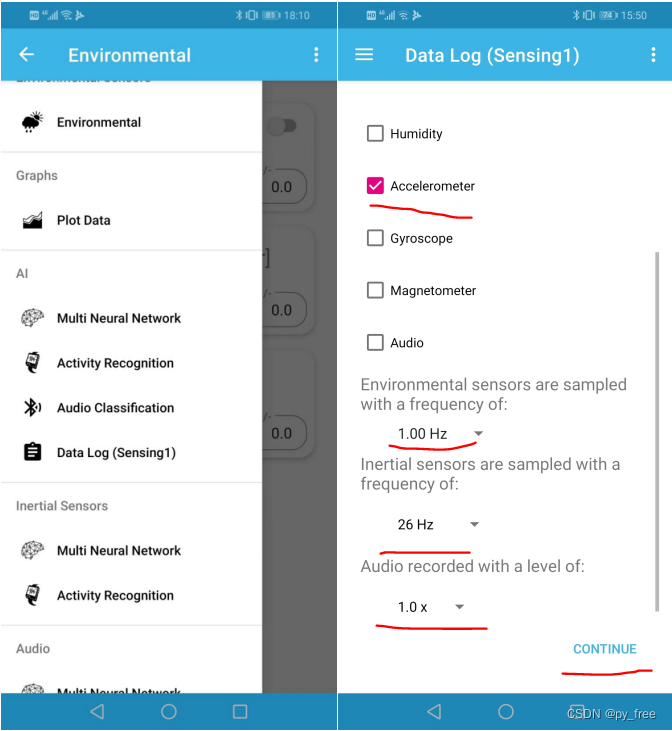
选择AI_Test蓝牙服务后,进入页面,(android)在左上角菜单下拉菜单选择,Data Log(sensing1),进入数据采集页面,选择Accelerometer(三轴加速度计),并设置参数为1.0Hz、26Hz、1.0X。
在数据记录操作页面,先新建标签,例如Jogging(慢跑),Walking(走了),Stationary(静立)等等。
1)开启数据采集记录时:先打开标签,再点击START LOGGING按钮开启
2)关闭数据采集记录时,先点击START LOGGING按钮关闭,再关闭标签。
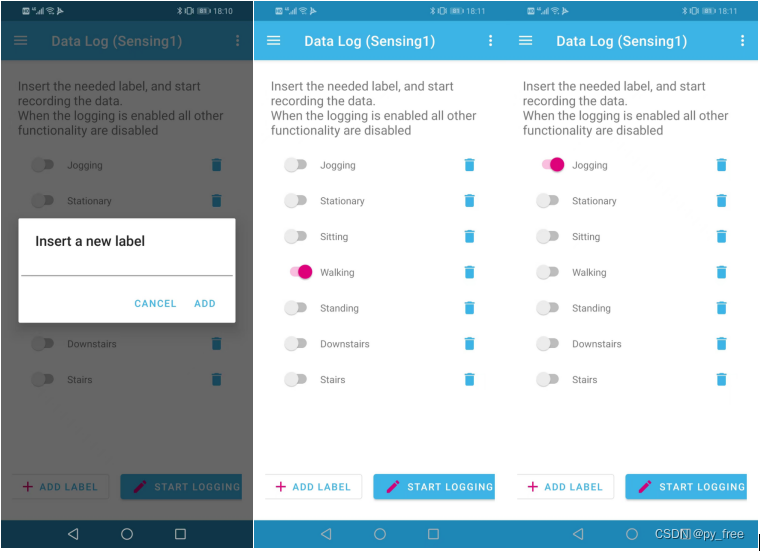
例如,本文按上述操作记录了Walking、Jogging两次数据记录,将生成两个.csv文件。
五、数据治理及模型训练
5.1 从开发板取出采集记录数据文件
断掉开发板与电脑的USB连接,在开发板背面将在1-2跳线帽拔掉,插入5-6跳线,然后USB连接从ST-LINK连接转到USB-OTG接口接线,如下图(1->2)。

开发板重新上电后,保持按下user按钮(蓝色),同时按下reset按钮(黑色),然后先松开reset按钮,在松开user按钮,激活USB-OTG。

USB-OTG激活后,开发板将作为一个U盘显示在电脑上,里面有刚才数据采集保存的CSV文件。
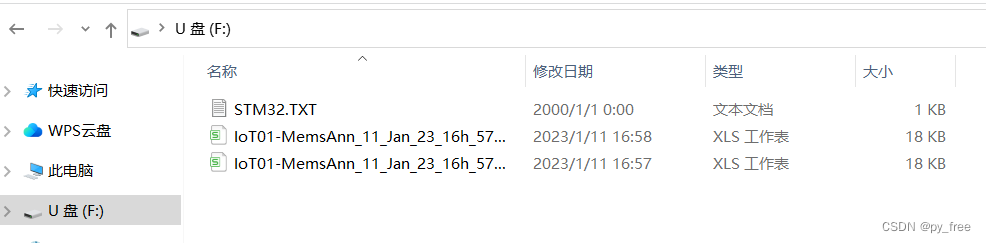
在“STM32CubeFunctionPack_SENSING1_V4.0.3\Utilities\AI_Ressources\Training Scripts\HAR”目录创建一个文件目录Log_data,将该文件拷贝到该目录下:

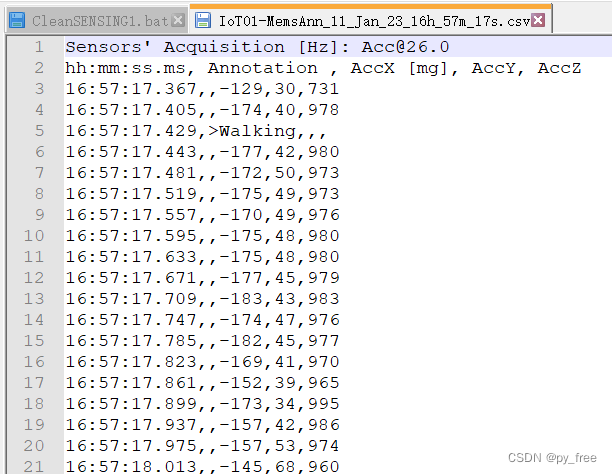
该CSV记录数据格式如下,时间、行为、三个传感数值:
5.2 神经网络模型训练
“Training Scripts\HAR ”是官方提供的一个人类行为姿态识别训练项目,默认是采用,采用Keras前端+tensorflow后端实现。先安装tensorflow、Keras等支持。
本文安装如下:
- #已安装python3.6
- pip3 install tensorflow==1.14 -i https://pypi.tuna.tsinghua.edu.cn/simple
-
- ERROR: tensorboard 1.14.0 has requirement setuptools>=41.0.0, but you'll have setuptools 28.8.0 which is incompatible.
- python3 -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple
- pip3 install keras==2.2.4 -i https://pypi.tuna.tsinghua.edu.cn/simple
根据HAR 项目的readme.txt通过pip install -r requirements.txt命令安装requirements.txt文件制定的相关模块,但本文是采用常用命令逐个安装各个模块的“pip3 install 模块名==版本 -i 源”
- numpy==1.16.4
- argparse
- os
- logging
- warnings
- datetime
- pandas==0.25.1
- scipy==1.3.1
- matplotlib==3.1.1
- mpl_toolkits
- sklearn-learn==0.21.3
- keras==2.2.4
- tensorflow==1.14.0
- tqdm==4.36.1
- keras-tqdm==2.0.1
完成安装后,进入datasets目录,打开ReplaceWithWISDMDataset.txt文件,根据其提供的网址去下载
下载WISDM实验室的数据集支持。
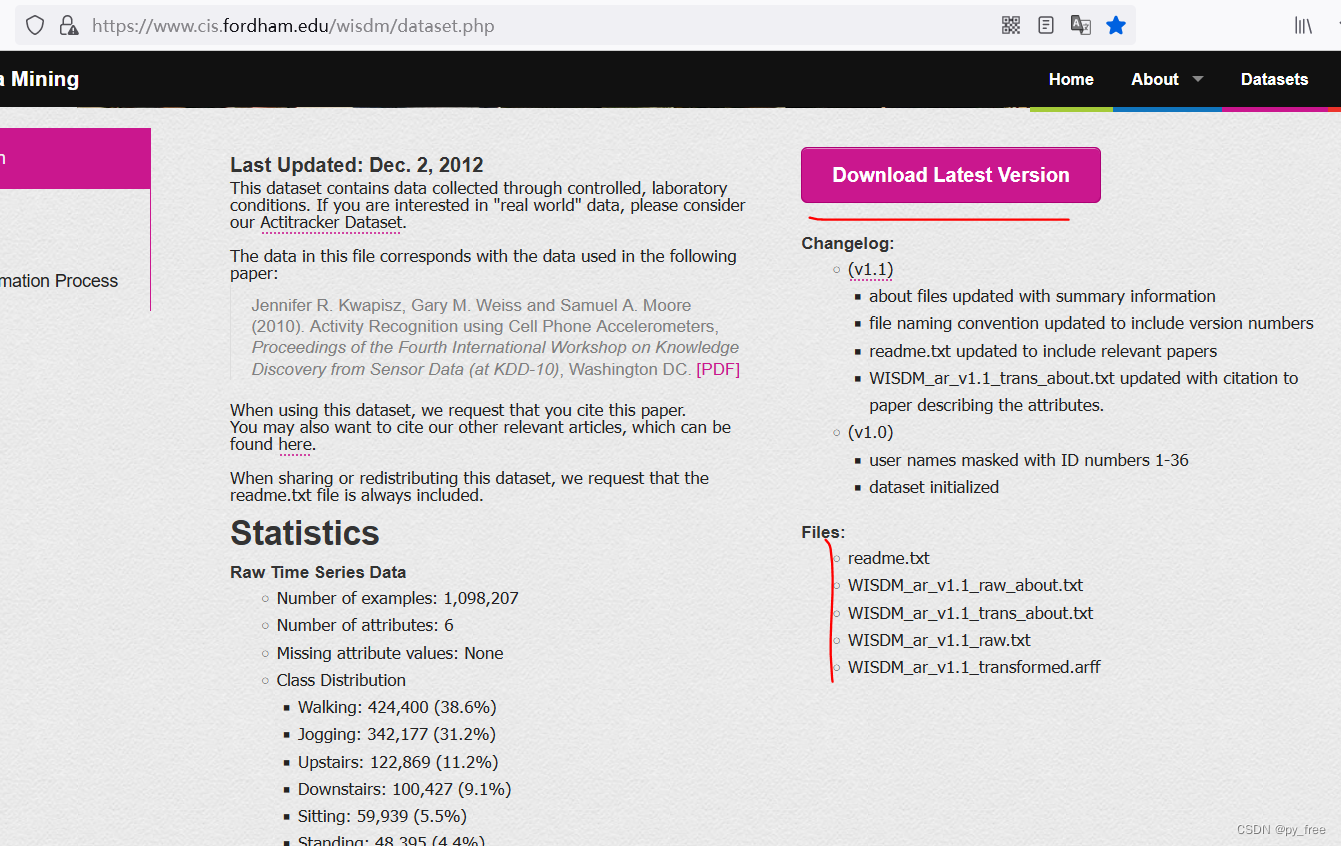
下载文件如下,将这些文件拷贝到datasets目录下覆盖。

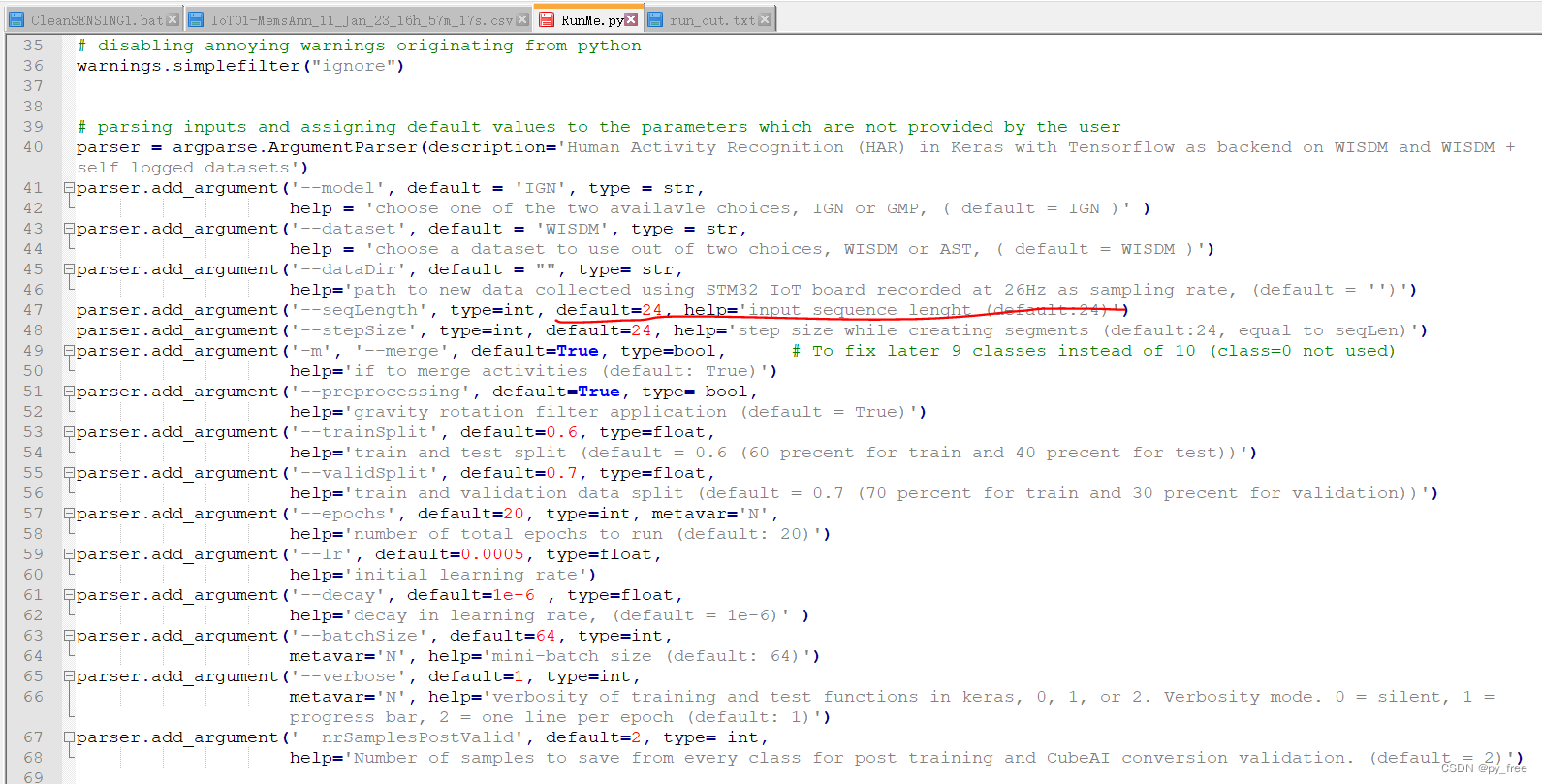
打开RunMe.py文件,可以看到关于各个运行参数的设置:
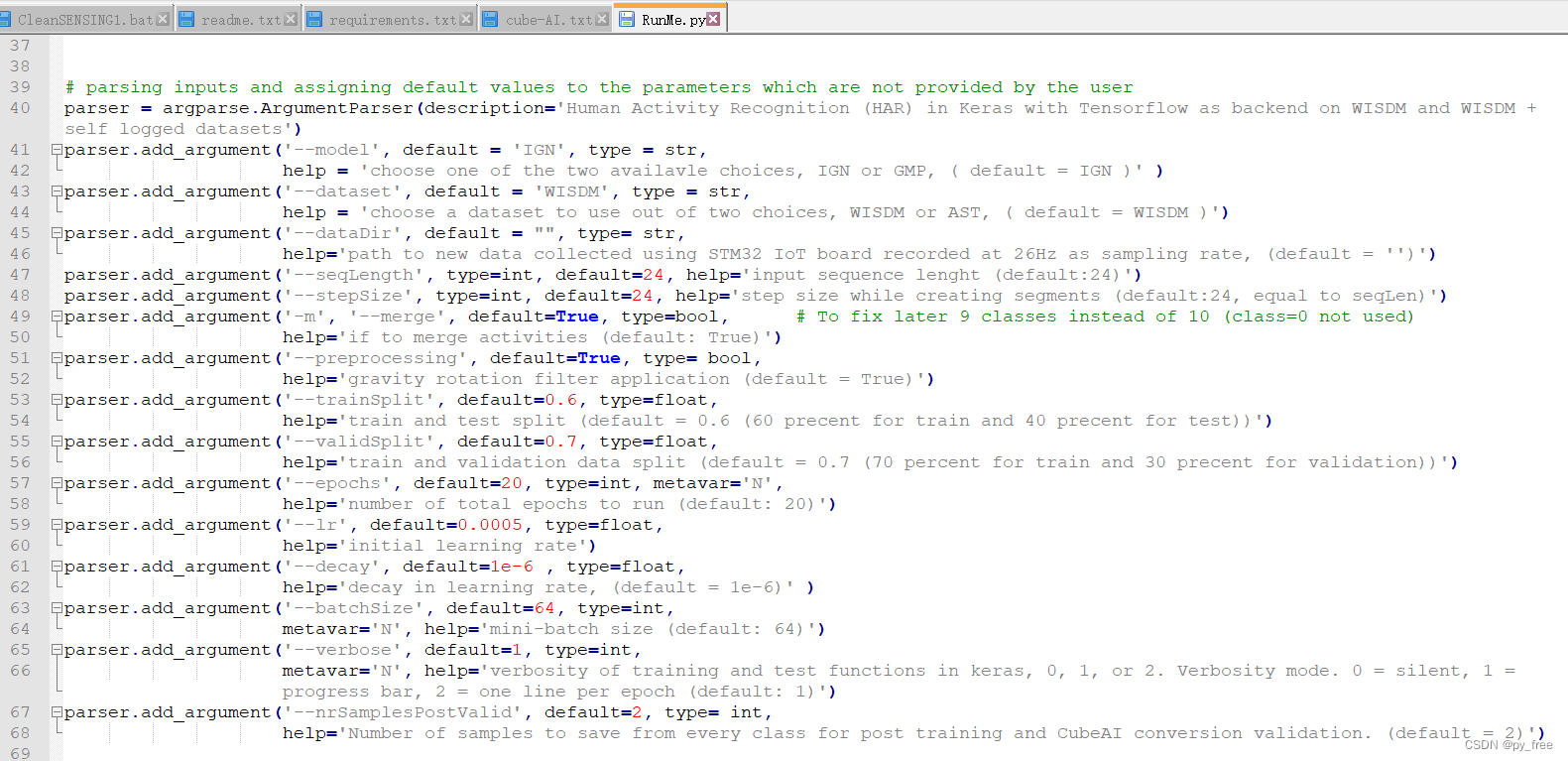
运行python3 .\RunMe.py -h命令,查看运行参数含义,其中:--dataset使用的是前面下载的WISDM实验室的数据集来训练模型,而--dataDir是指定采用自行采集的数据集训练模型:
- PS D:\tools\arm_tool\STM32CubeIDE\STM32CubeFunctionPack_SENSING1_V4.0.3\Utilities\AI_Ressources\Training Scripts\HAR> python3 .\RunMe.py -h
- Using TensorFlow backend.
- usage: RunMe.py [-h] [--model MODEL] [--dataset DATASET] [--dataDir DATADIR]
- [--seqLength SEQLENGTH] [--stepSize STEPSIZE] [-m MERGE]
- [--preprocessing PREPROCESSING] [--trainSplit TRAINSPLIT]
- [--validSplit VALIDSPLIT] [--epochs N] [--lr LR]
- [--decay DECAY] [--batchSize N] [--verbose N]
- [--nrSamplesPostValid NRSAMPLESPOSTVALID]
-
- Human Activity Recognition (HAR) in Keras with Tensorflow as backend on WISDM
- and WISDM + self logged datasets
-
- optional arguments:
- -h, --help show this help message and exit
- --model MODEL choose one of the two availavle choices, IGN or GMP, (
- default = IGN )
- --dataset DATASET choose a dataset to use out of two choices, WISDM or
- AST, ( default = WISDM )
- --dataDir DATADIR path to new data collected using STM32 IoT board
- recorded at 26Hz as sampling rate, (default = )
- --seqLength SEQLENGTH
- input sequence lenght (default:24)
- --stepSize STEPSIZE step size while creating segments (default:24, equal
- to seqLen)
- -m MERGE, --merge MERGE
- if to merge activities (default: True)
- --preprocessing PREPROCESSING
- gravity rotation filter application (default = True)
- --trainSplit TRAINSPLIT
- train and test split (default = 0.6 (60 precent for
- train and 40 precent for test))
- --validSplit VALIDSPLIT
- train and validation data split (default = 0.7 (70
- percent for train and 30 precent for validation))
- --epochs N number of total epochs to run (default: 20)
- --lr LR initial learning rate
- --decay DECAY decay in learning rate, (default = 1e-6)
- --batchSize N mini-batch size (default: 64)
- --verbose N verbosity of training and test functions in keras, 0,
- 1, or 2. Verbosity mode. 0 = silent, 1 = progress bar,
- 2 = one line per epoch (default: 1)
- --nrSamplesPostValid NRSAMPLESPOSTVALID
- Number of samples to save from every class for post
- training and CubeAI conversion validation. (default =
- 2)
- PS D:\tools\arm_tool\STM32CubeIDE\STM32CubeFunctionPack_SENSING1_V4.0.3\Utilities\AI_Ressources\Training Scripts\HAR>
在RunMe.py文件后面加入下面语句:
- #保存Cube.AI支持的数据集格式,用于后续验证测试使用
- testx_f=resultDirName+"testx.npy"
- testy_f=resultDirName+"testy.npy"
-
- np.save(testx_f,TestX)
- np.save(testy_f,TestY)
打开命令工具,输入命令python3 .\RunMe.py --dataDir=Log_data ,可以根据实际需要进行参数设置,本文先采用默认参数训练模型,输出日志如下,这显然是一个分类问题,分类为Jogging 、Stationary 、Stairs 、Walking,有卷积层、池化层、2全连接层、压平层、Dropout层等。
- PS D:\tools\arm_tool\STM32CubeIDE\STM32CubeFunctionPack_SENSING1_V4.0.3\Utilities\AI_Ressources\Training Scripts\HAR> python3 .\RunMe.py --dataDir=Log_data
- Using TensorFlow backend.
- Running HAR on WISDM dataset, with following variables
- merge = True
- modelName = IGN,
- segmentLength = 24
- stepSize = 24
- preprocessing = True
- trainTestSplit = 0.6
- trainValidationSplit = 0.7
- nEpochs = 20
- learningRate = 0.0005
- decay =1e-06
- batchSize = 64
- verbosity = 1
- dataDir = Log_data
- nrSamplesPostValid = 2
- Segmenting Train data
- Segments built : 100%|███████████████████████████████████████████████████| 27456/27456 [00:28<00:00, 953.24 segments/s]
- Segmenting Test data
- Segments built : 100%|██████████████████████████████████████████████████| 18304/18304 [00:14<00:00, 1282.96 segments/s]
- Segmentation finished!
- preparing data file from all the files in directory Log_data
- parsing data from IoT01-MemsAnn_11_Jan_23_16h_57m_17s.csv
- parsing data from IoT01-MemsAnn_11_Jan_23_16h_57m_53s.csv
- Segmenting the AI logged Train data
- Segments built : 100%|████████████████████████████████████████████████████████| 25/25 [00:00<00:00, 3133.35 segments/s]
- Segmenting the AI logged Test data
- Segments built : 100%|████████████████████████████████████████████████████████| 17/17 [00:00<00:00, 2852.35 segments/s]
- Segmentation finished!
- _________________________________________________________________
- Layer (type) Output Shape Param #
- =================================================================
- conv2d_1 (Conv2D) (None, 9, 3, 24) 408
- _________________________________________________________________
- max_pooling2d_1 (MaxPooling2 (None, 3, 3, 24) 0
- _________________________________________________________________
- flatten_1 (Flatten) (None, 216) 0
- _________________________________________________________________
- dense_1 (Dense) (None, 12) 2604
- _________________________________________________________________
- dropout_1 (Dropout) (None, 12) 0
- _________________________________________________________________
- dense_2 (Dense) (None, 4) 52
- =================================================================
- Total params: 3,064
- Trainable params: 3,064
- Non-trainable params: 0
- _________________________________________________________________
- Train on 19263 samples, validate on 8216 samples
- Epoch 1/20
- 2023-01-24 14:41:03.484083: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
- 19263/19263 [==============================] - 3s 167us/step - loss: 1.1442 - acc: 0.5430 - val_loss: 0.6674 - val_acc: 0.7372
- Epoch 2/20
- 19263/19263 [==============================] - 1s 40us/step - loss: 0.7173 - acc: 0.7089 - val_loss: 0.5126 - val_acc: 0.7928
- Epoch 3/20
- 19263/19263 [==============================] - 1s 40us/step - loss: 0.5954 - acc: 0.7522 - val_loss: 0.4470 - val_acc: 0.8051
- Epoch 4/20
- 19263/19263 [==============================] - 1s 39us/step - loss: 0.5288 - acc: 0.7810 - val_loss: 0.4174 - val_acc: 0.8335
- Epoch 5/20
- 19263/19263 [==============================] - 1s 36us/step - loss: 0.4925 - acc: 0.7994 - val_loss: 0.3897 - val_acc: 0.8477
- Epoch 6/20
- 19263/19263 [==============================] - 1s 35us/step - loss: 0.4647 - acc: 0.8173 - val_loss: 0.3607 - val_acc: 0.8647
- Epoch 7/20
- 19263/19263 [==============================] - 1s 37us/step - loss: 0.4404 - acc: 0.8301 - val_loss: 0.3493 - val_acc: 0.8777
- Epoch 8/20
- 19263/19263 [==============================] - 1s 38us/step - loss: 0.4200 - acc: 0.8419 - val_loss: 0.3271 - val_acc: 0.8827
- Epoch 9/20
- 19263/19263 [==============================] - 1s 38us/step - loss: 0.3992 - acc: 0.8537 - val_loss: 0.3163 - val_acc: 0.8890
- Epoch 10/20
- 19263/19263 [==============================] - 1s 40us/step - loss: 0.3878 - acc: 0.8576 - val_loss: 0.3039 - val_acc: 0.8991
- Epoch 11/20
- 19263/19263 [==============================] - 1s 40us/step - loss: 0.3799 - acc: 0.8667 - val_loss: 0.2983 - val_acc: 0.8985
- Epoch 12/20
- 19263/19263 [==============================] - 1s 40us/step - loss: 0.3662 - acc: 0.8736 - val_loss: 0.2922 - val_acc: 0.9007
- Epoch 13/20
- 19263/19263 [==============================] - 1s 36us/step - loss: 0.3613 - acc: 0.8760 - val_loss: 0.2837 - val_acc: 0.9051
- Epoch 14/20
- 19263/19263 [==============================] - 1s 40us/step - loss: 0.3574 - acc: 0.8775 - val_loss: 0.2910 - val_acc: 0.8985
- Epoch 15/20
- 19263/19263 [==============================] - 1s 39us/step - loss: 0.3513 - acc: 0.8796 - val_loss: 0.2814 - val_acc: 0.9080
- Epoch 16/20
- 19263/19263 [==============================] - 1s 38us/step - loss: 0.3482 - acc: 0.8816 - val_loss: 0.2737 - val_acc: 0.9116
- Epoch 17/20
- 19263/19263 [==============================] - 1s 35us/step - loss: 0.3362 - acc: 0.8875 - val_loss: 0.2742 - val_acc: 0.9114
- Epoch 18/20
- 19263/19263 [==============================] - 1s 38us/step - loss: 0.3325 - acc: 0.8892 - val_loss: 0.2661 - val_acc: 0.9137
- Epoch 19/20
- 19263/19263 [==============================] - 1s 40us/step - loss: 0.3257 - acc: 0.8927 - val_loss: 0.2621 - val_acc: 0.9161
- Epoch 20/20
- 19263/19263 [==============================] - 1s 37us/step - loss: 0.3249 - acc: 0.8918 - val_loss: 0.2613 - val_acc: 0.9188
- 12806/12806 [==============================] - 0s 25us/step
- Accuracy for each class is given below.
- Jogging : 97.28 %
- Stationary : 98.77 %
- Stairs : 66.33 %
- Walking : 87.49 %
- PS D:\tools\arm_tool\STM32CubeIDE\STM32CubeFunctionPack_SENSING1_V4.0.3\Utilities\AI_Ressources\Training Scripts\HAR>
训练模型及相关输出信息在results目录下,每次训练输出依据时间生成一个独立目录,由于是keras训练模型,因此输出训练模型是一个名为*.h5格式文件,例如har_IGN.h5:

六、 cube.AI将训练模型转换为c语言模型
6.1 创建cube.AI支持的STM32工程
在CubeIDE中新建一个STM32项目,在cubeMX中选择以开发板形式创建
创建一个B-L475E-IOT01A_cube.ai工程名的STM32工程,如下图。
完成创建后,双击.ioc文件打开cube.MX配置界面。
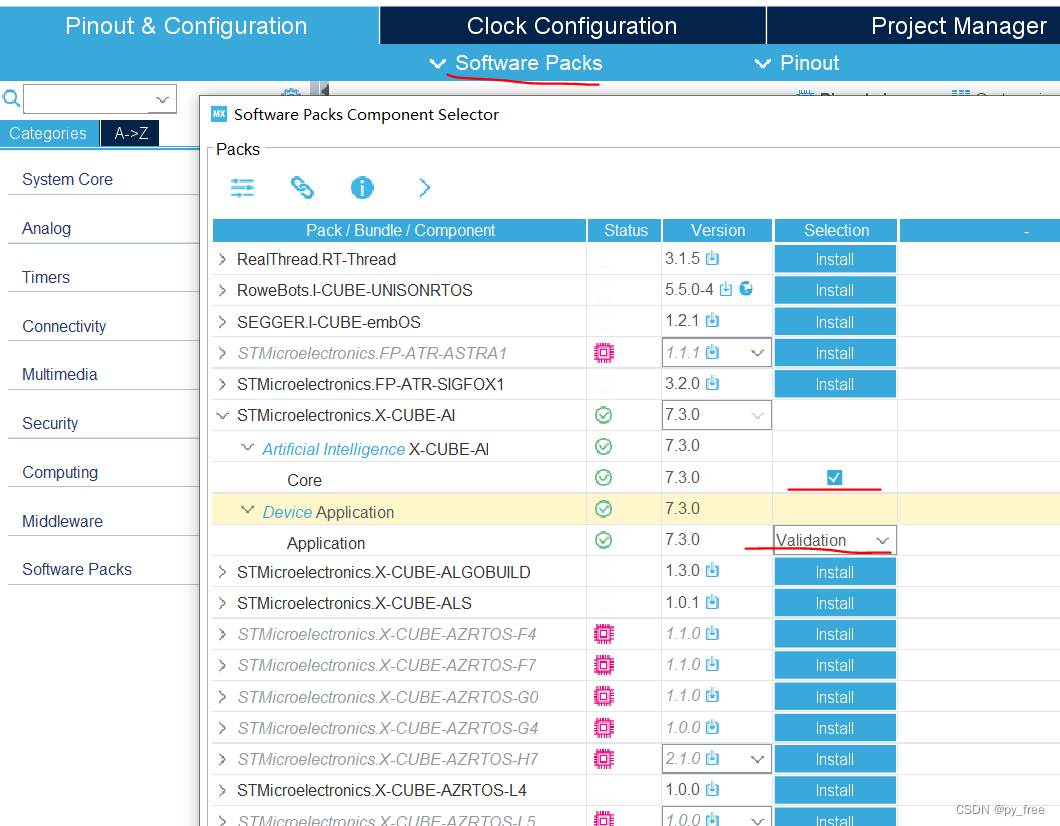
6.2 cube.AI神经网络配置
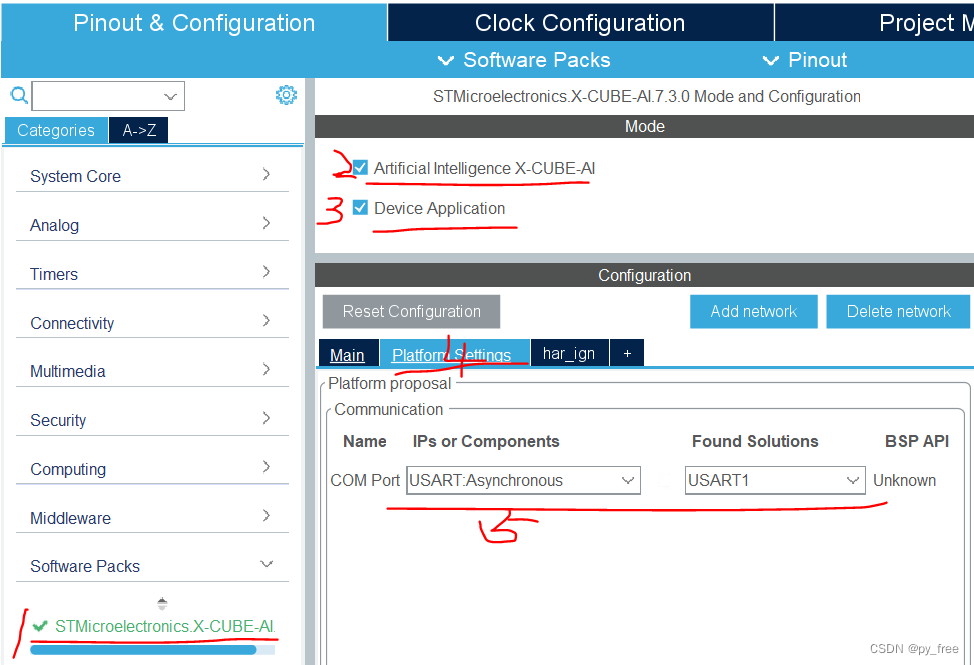
选择X-CUBE-AI包支持,回到主页面后,会多出software Packs栏及多出STMicroelectronics .X-CUBE-AI选项,进入该页面,勾选下图标识的2、3 项,在5中选择采用哪个串口支持程序及调试。
知识点,在X-CUBE-AI配置选项页面,停靠时,会出现说明框,快捷键“CTRL+D”会进一步出现X-CUBE-AI相关文档,
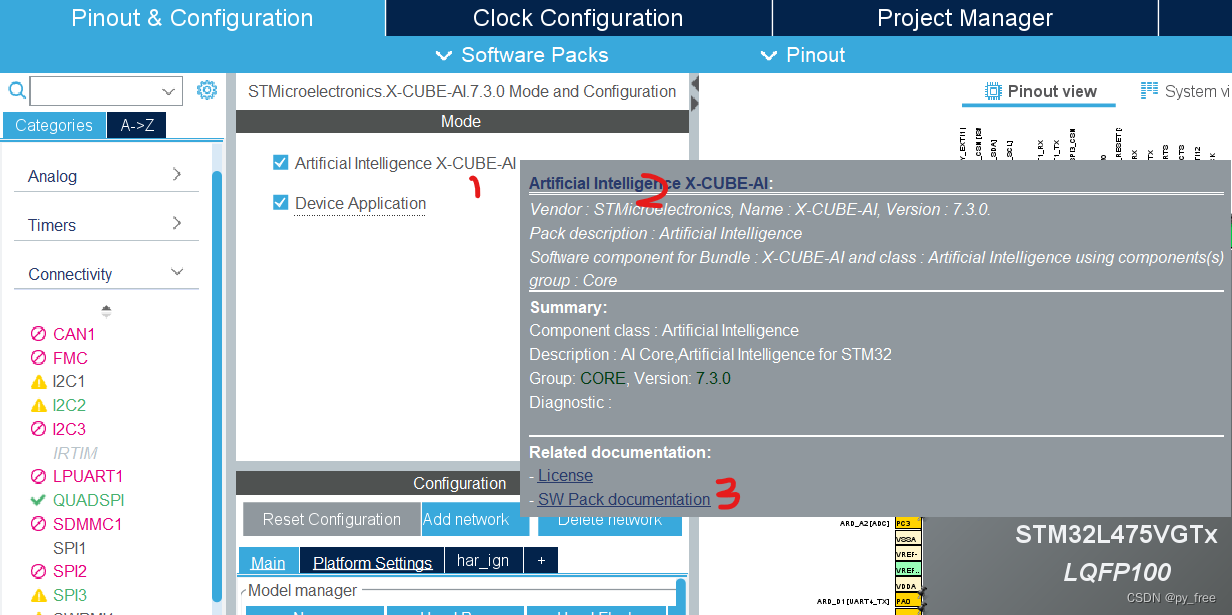
有详细的文档资料:
或者也可以从cube.AI安装目录直接进入,例如:D:\workForSoftware\STM32CubeMX\Repository\Packs\STMicroelectronics\X-CUBE-AI\7.3.0\Documentation
另外,需要注意,开启X-CUBE-AI支持后,其依赖CRC功能,会自动开启CRC。
6.3 模型分析与PC端验证
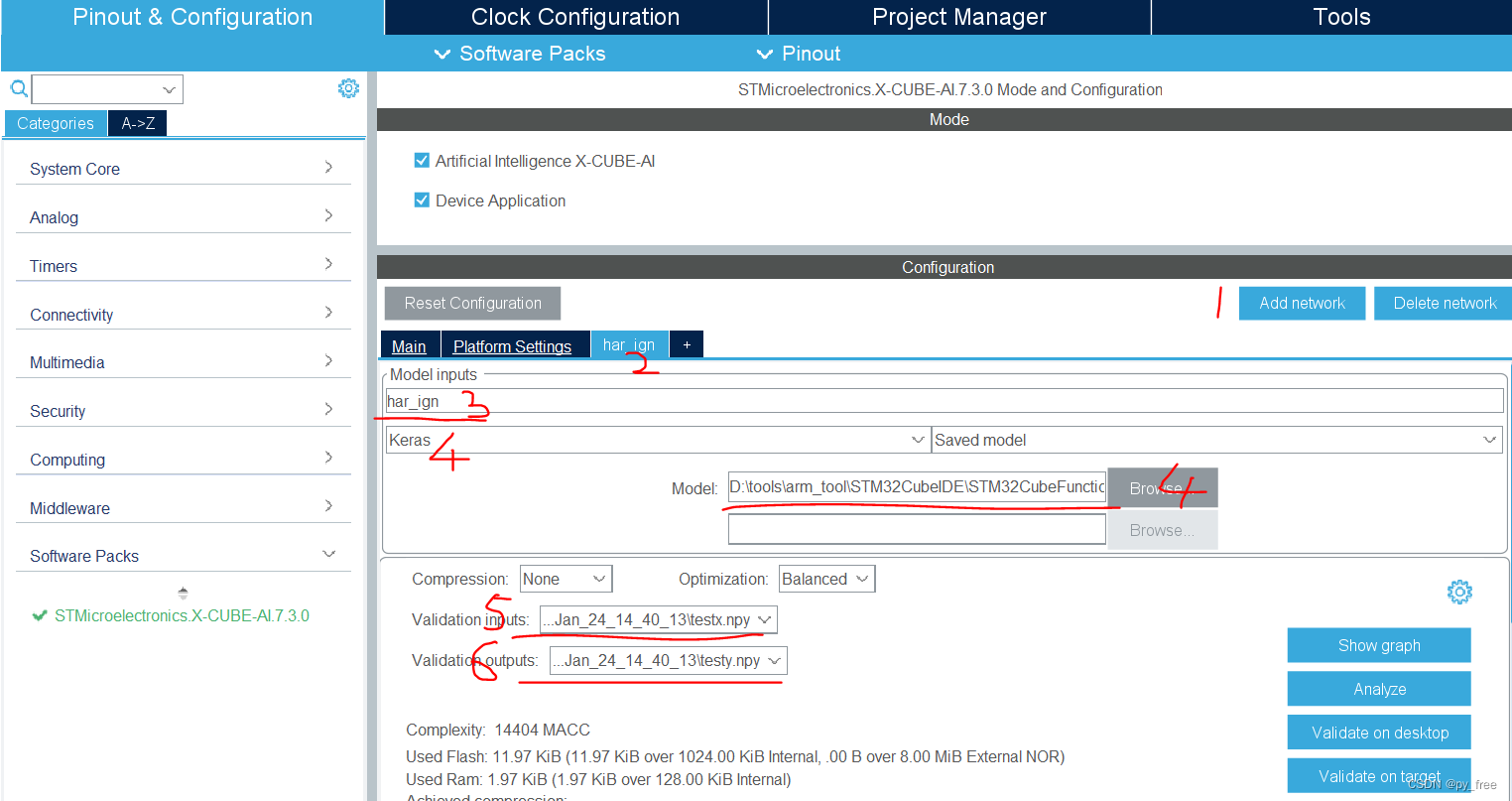
添加(add network)神经网络如下,在3中可以修改神经网络模型名称,在4中选择支持框架及选择模型文件,例如“STM32CubeFunctionPack_SENSING1_V4.0.3\Utilities\AI_Ressources\Training Scripts\HAR\results\2023_Jan_24_14_40_13\har_IGN.h5”,在5、6中,可以选择随机数据进行模型研制,也可以选择生成的研制数据进行验证(前面训练模型时,在RunMe.py文件后面加入语句,输出testx.npy、testy.npy文件):
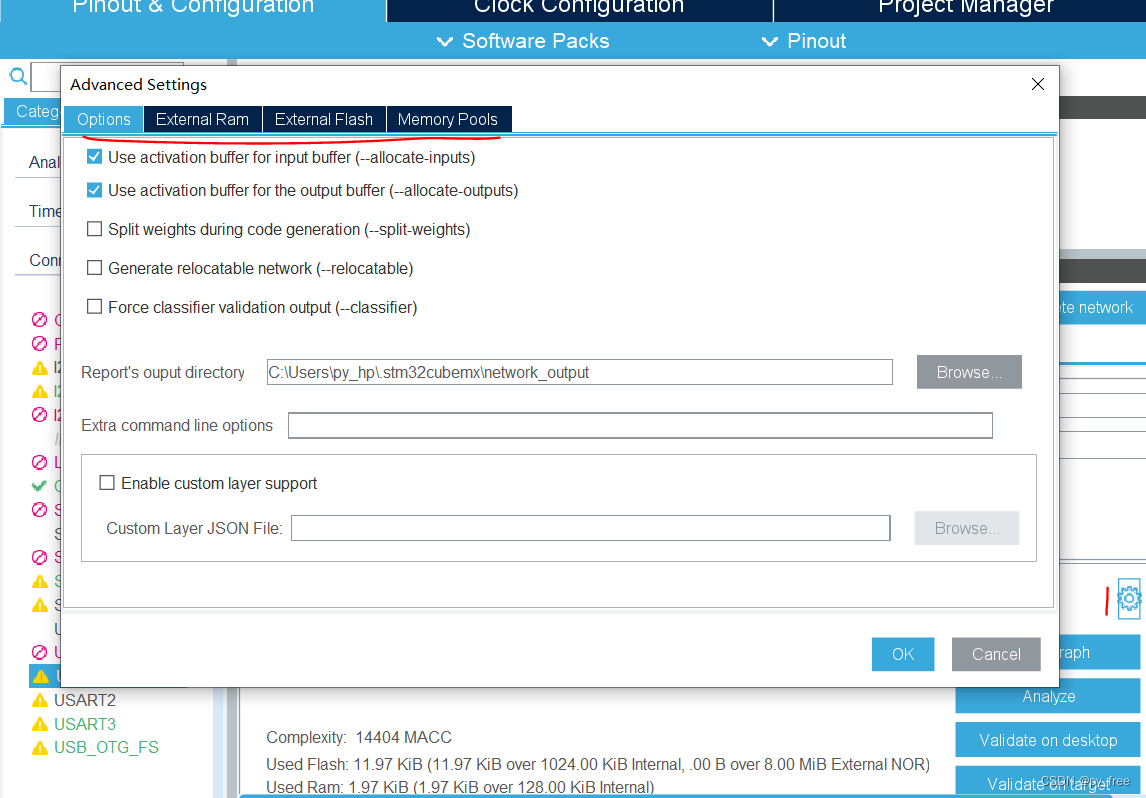
可以点击设置按钮进入,在该页面下可以对神经网络进行更多设置和更详细信息查看,主要是以模型优化为主,本文先保持默认。
点击分析按钮(Analyze),输出该模型相关信息及部署模型需要的计算资源(ram、flash等):
-
- Analyzing model
- D:/workForSoftware/STM32CubeMX/Repository/Packs/STMicroelectronics/X-CUBE-AI/7.3.0/Utilities/windows/stm32ai analyze --name har_ign -m D:/tools/arm_tool/STM32CubeIDE/STM32CubeFunctionPack_SENSING1_V4.0.3/Utilities/AI_Ressources/Training Scripts/HAR/results/2023_Jan_11_17_50_03/har_IGN.h5 --type keras --compression none --verbosity 1 --workspace C:\Users\py_hp\AppData\Local\Temp\mxAI_workspace465785871649500151581099545474794 --output C:\Users\py_hp\.stm32cubemx\network_output --allocate-inputs --allocate-outputs
- Neural Network Tools for STM32AI v1.6.0 (STM.ai v7.3.0-RC5)
-
- Exec/report summary (analyze)
- ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
- model file : D:\tools\arm_tool\STM32CubeIDE\STM32CubeFunctionPack_SENSING1_V4.0.3\Utilities\AI_Ressources\Training Scripts\HAR\results\2023_Jan_11_17_50_03\har_IGN.h5
- type : keras
- c_name : har_ign
- compression : none
- options : allocate-inputs, allocate-outputs
- optimization : balanced
- target/series : generic
- workspace dir : C:\Users\py_hp\AppData\Local\Temp\mxAI_workspace465785871649500151581099545474794
- output dir : C:\Users\py_hp\.stm32cubemx\network_output
- model_fmt : float
- model_name : har_IGN
- model_hash : ff0080dbe395a3d8fd3f63243d2326d5
- params # : 3,064 items (11.97 KiB)
- ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
- input 1/1 : 'input_0' (domain:activations/**default**)
- : 72 items, 288 B, ai_float, float, (1,24,3,1)
- output 1/1 : 'dense_2' (domain:activations/**default**)
- : 4 items, 16 B, ai_float, float, (1,1,1,4)
- macc : 14,404
- weights (ro) : 12,256 B (11.97 KiB) (1 segment)
- activations (rw) : 2,016 B (1.97 KiB) (1 segment) *
- ram (total) : 2,016 B (1.97 KiB) = 2,016 + 0 + 0
- ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
- (*) 'input'/'output' buffers can be used from the activations buffer
-
- Model name - har_IGN ['input_0'] ['dense_2']
- ------------------------------------------------------------------------------------------------------
- id layer (original) oshape param/size macc connected to
- ------------------------------------------------------------------------------------------------------
- 0 input_0 (None) [b:None,h:24,w:3,c:1]
- conv2d_1_conv2d (Conv2D) [b:None,h:9,w:3,c:24] 408/1,632 10,392 input_0
- conv2d_1 (Conv2D) [b:None,h:9,w:3,c:24] 648 conv2d_1_conv2d
- ------------------------------------------------------------------------------------------------------
- 1 max_pooling2d_1 (MaxPooling2D) [b:None,h:3,w:3,c:24] 648 conv2d_1
- ------------------------------------------------------------------------------------------------------
- 2 flatten_1 (Flatten) [b:None,c:216] max_pooling2d_1
- ------------------------------------------------------------------------------------------------------
- 3 dense_1_dense (Dense) [b:None,c:12] 2,604/10,416 2,604 flatten_1
- ------------------------------------------------------------------------------------------------------
- 5 dense_2_dense (Dense) [b:None,c:4] 52/208 52 dense_1_dense
- dense_2 (Dense) [b:None,c:4] 60 dense_2_dense
- ------------------------------------------------------------------------------------------------------
- model/c-model: macc=14,404/14,404 weights=12,256/12,256 activations=--/2,016 io=--/0
-
- Number of operations per c-layer
- -----------------------------------------------------------------------------------
- c_id m_id name (type) #op (type)
- -----------------------------------------------------------------------------------
- 0 1 conv2d_1_conv2d (optimized_conv2d) 11,688 (smul_f32_f32)
- 1 3 dense_1_dense (dense) 2,604 (smul_f32_f32)
- 2 5 dense_2_dense (dense) 52 (smul_f32_f32)
- 3 5 dense_2 (nl) 60 (op_f32_f32)
- -----------------------------------------------------------------------------------
- total 14,404
-
- Number of operation types
- ---------------------------------------------
- smul_f32_f32 14,344 99.6%
- op_f32_f32 60 0.4%
-
- Complexity report (model)
- ------------------------------------------------------------------------------------
- m_id name c_macc c_rom c_id
- ------------------------------------------------------------------------------------
- 1 max_pooling2d_1 |||||||||||||||| 81.1% ||| 13.3% [0]
- 3 dense_1_dense |||| 18.1% |||||||||||||||| 85.0% [1]
- 5 dense_2_dense | 0.8% | 1.7% [2, 3]
- ------------------------------------------------------------------------------------
- macc=14,404 weights=12,256 act=2,016 ram_io=0
- Creating txt report file C:\Users\py_hp\.stm32cubemx\network_output\har_ign_analyze_report.txt
- elapsed time (analyze): 7.692s
- Getting Flash and Ram size used by the library
- Model file: har_IGN.h5
- Total Flash: 29880 B (29.18 KiB)
- Weights: 12256 B (11.97 KiB)
- Library: 17624 B (17.21 KiB)
- Total Ram: 4000 B (3.91 KiB)
- Activations: 2016 B (1.97 KiB)
- Library: 1984 B (1.94 KiB)
- Input: 288 B (included in Activations)
- Output: 16 B (included in Activations)
- Done
- Analyze complete on AI model
点击PC桌面验证按钮(validation on desktop),对训练模型进行验证,主要是验证原始模型和转为c语言支持的模型时,验证前后计算资源、模型精度等差异情况,验证数据就是我们刚指定的testx.npy、testy.npy文件。
-
- Starting AI validation on desktop with custom dataset : D:\tools\arm_tool\STM32CubeIDE\STM32CubeFunctionPack_SENSING1_V4.0.3\Utilities\AI_Ressources\Training Scripts\HAR\results\2023_Jan_24_14_40_13\testx.npy...
- D:/workForSoftware/STM32CubeMX/Repository/Packs/STMicroelectronics/X-CUBE-AI/7.3.0/Utilities/windows/stm32ai validate --name har_ign -m D:/tools/arm_tool/STM32CubeIDE/STM32CubeFunctionPack_SENSING1_V4.0.3/Utilities/AI_Ressources/Training Scripts/HAR/results/2023_Jan_11_17_50_03/har_IGN.h5 --type keras --compression none --verbosity 1 --workspace C:\Users\py_hp\AppData\Local\Temp\mxAI_workspace46601041973700012072836595678733048 --output C:\Users\py_hp\.stm32cubemx\network_output --allocate-inputs --allocate-outputs --valoutput D:/tools/arm_tool/STM32CubeIDE/STM32CubeFunctionPack_SENSING1_V4.0.3/Utilities/AI_Ressources/Training Scripts/HAR/results/2023_Jan_24_14_40_13/testy.npy --valinput D:/tools/arm_tool/STM32CubeIDE/STM32CubeFunctionPack_SENSING1_V4.0.3/Utilities/AI_Ressources/Training Scripts/HAR/results/2023_Jan_24_14_40_13/testx.npy
- Neural Network Tools for STM32AI v1.6.0 (STM.ai v7.3.0-RC5)
- Copying the AI runtime files to the user workspace: C:\Users\py_hp\AppData\Local\Temp\mxAI_workspace46601041973700012072836595678733048\inspector_har_ign\workspace
-
- Exec/report summary (validate)
- ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
- model file : D:\tools\arm_tool\STM32CubeIDE\STM32CubeFunctionPack_SENSING1_V4.0.3\Utilities\AI_Ressources\Training Scripts\HAR\results\2023_Jan_11_17_50_03\har_IGN.h5
- type : keras
- c_name : har_ign
- compression : none
- options : allocate-inputs, allocate-outputs
- optimization : balanced
- target/series : generic
- workspace dir : C:\Users\py_hp\AppData\Local\Temp\mxAI_workspace46601041973700012072836595678733048
- output dir : C:\Users\py_hp\.stm32cubemx\network_output
- vinput files : D:\tools\arm_tool\STM32CubeIDE\STM32CubeFunctionPack_SENSING1_V4.0.3\Utilities\AI_Ressources\Training Scripts\HAR\results\2023_Jan_24_14_40_13\testx.npy
- voutput files : D:\tools\arm_tool\STM32CubeIDE\STM32CubeFunctionPack_SENSING1_V4.0.3\Utilities\AI_Ressources\Training Scripts\HAR\results\2023_Jan_24_14_40_13\testy.npy
- model_fmt : float
- model_name : har_IGN
- model_hash : ff0080dbe395a3d8fd3f63243d2326d5
- params # : 3,064 items (11.97 KiB)
- ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
- input 1/1 : 'input_0' (domain:activations/**default**)
- : 72 items, 288 B, ai_float, float, (1,24,3,1)
- output 1/1 : 'dense_2' (domain:activations/**default**)
- : 4 items, 16 B, ai_float, float, (1,1,1,4)
- macc : 14,404
- weights (ro) : 12,256 B (11.97 KiB) (1 segment)
- activations (rw) : 2,016 B (1.97 KiB) (1 segment) *
- ram (total) : 2,016 B (1.97 KiB) = 2,016 + 0 + 0
- ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
- (*) 'input'/'output' buffers can be used from the activations buffer
- Setting validation data...
- loading file: D:\tools\arm_tool\STM32CubeIDE\STM32CubeFunctionPack_SENSING1_V4.0.3\Utilities\AI_Ressources\Training Scripts\HAR\results\2023_Jan_24_14_40_13\testx.npy
- - samples are reshaped: (12806, 24, 3, 1) -> (12806, 24, 3, 1)
- loading file: D:\tools\arm_tool\STM32CubeIDE\STM32CubeFunctionPack_SENSING1_V4.0.3\Utilities\AI_Ressources\Training Scripts\HAR\results\2023_Jan_24_14_40_13\testy.npy
- - samples are reshaped: (12806, 4) -> (12806, 1, 1, 4)
- I[1]: (12806, 24, 3, 1)/float32, min/max=[-26.319, 32.844], mean/std=[0.075, 5.034], input_0
- O[1]: (12806, 1, 1, 4)/float32, min/max=[0.000, 1.000], mean/std=[0.250, 0.433], dense_2
- Running the STM AI c-model (AI RUNNER)...(name=har_ign, mode=x86)
- X86 shared lib (C:\Users\py_hp\AppData\Local\Temp\mxAI_workspace46601041973700012072836595678733048\inspector_har_ign\workspace\lib\libai_har_ign.dll) ['har_ign']
- Summary "har_ign" - ['har_ign']
- --------------------------------------------------------------------------------
- inputs/outputs : 1/1
- input_1 : (1,24,3,1), float32, 288 bytes, in activations buffer
- output_1 : (1,1,1,4), float32, 16 bytes, in activations buffer
- n_nodes : 4
- compile_datetime : Jan 25 2023 22:55:51 (Wed Jan 25 22:55:47 2023)
- activations : 2016
- weights : 12256
- macc : 14404
- --------------------------------------------------------------------------------
- runtime : STM.AI 7.3.0 (Tools 7.3.0)
- capabilities : ['IO_ONLY', 'PER_LAYER', 'PER_LAYER_WITH_DATA']
- device : AMD64 Intel64 Family 6 Model 158 Stepping 9, GenuineIntel (Windows)
- --------------------------------------------------------------------------------
- STM.IO: 0%| | 0/12806 [00:00<?, ?it/s]
- STM.IO: 11%|█ | 1424/12806 [00:00<00:00, 14136.31it/s]
- STM.IO: 14%|█▍ | 1849/12806 [00:00<00:04, 2293.62it/s]
- STM.IO: 17%|█▋ | 2170/12806 [00:00<00:05, 1774.74it/s]
- STM.IO: 19%|█▉ | 2429/12806 [00:01<00:06, 1520.26it/s]
- STM.IO: 21%|██ | 2645/12806 [00:01<00:07, 1348.30it/s]
- STM.IO: 22%|██▏ | 2828/12806 [00:01<00:07, 1291.67it/s]
- STM.IO: 23%|██▎ | 2992/12806 [00:01<00:07, 1245.52it/s]
- STM.IO: 25%|██▍ | 3141/12806 [00:01<00:08, 1194.67it/s]
- STM.IO: 26%|██▌ | 3278/12806 [00:01<00:08, 1107.82it/s]
- STM.IO: 27%|██▋ | 3407/12806 [00:02<00:08, 1154.55it/s]
- STM.IO: 28%|██▊ | 3548/12806 [00:02<00:07, 1218.70it/s]
- STM.IO: 29%|██▊ | 3678/12806 [00:02<00:07, 1175.60it/s]
- STM.IO: 30%|██▉ | 3811/12806 [00:02<00:07, 1215.67it/s]
- STM.IO: 31%|███ | 3938/12806 [00:02<00:07, 1139.58it/s]
- STM.IO: 32%|███▏ | 4075/12806 [00:02<00:07, 1197.83it/s]
- STM.IO: 33%|███▎ | 4199/12806 [00:02<00:07, 1207.70it/s]
- STM.IO: 34%|███▍ | 4323/12806 [00:02<00:07, 1078.59it/s]
- STM.IO: 35%|███▍ | 4451/12806 [00:02<00:07, 1129.92it/s]
- STM.IO: 36%|███▌ | 4590/12806 [00:03<00:06, 1194.76it/s]
- STM.IO: 37%|███▋ | 4718/12806 [00:03<00:06, 1216.59it/s]
- STM.IO: 38%|███▊ | 4843/12806 [00:03<00:06, 1195.77it/s]
- STM.IO: 39%|███▉ | 4965/12806 [00:03<00:06, 1159.48it/s]
- STM.IO: 40%|███▉ | 5083/12806 [00:03<00:06, 1116.81it/s]
- STM.IO: 41%|████ | 5197/12806 [00:03<00:06, 1095.57it/s]
- STM.IO: 41%|████▏ | 5308/12806 [00:03<00:06, 1078.25it/s]
- STM.IO: 42%|████▏ | 5433/12806 [00:03<00:06, 1122.47it/s]
- STM.IO: 43%|████▎ | 5547/12806 [00:03<00:06, 1056.59it/s]
- STM.IO: 44%|████▍ | 5655/12806 [00:04<00:06, 1055.01it/s]
- STM.IO: 45%|████▍ | 5762/12806 [00:04<00:06, 1035.74it/s]
- STM.IO: 46%|████▌ | 5867/12806 [00:04<00:06, 1022.60it/s]
- STM.IO: 47%|████▋ | 5981/12806 [00:04<00:06, 1053.06it/s]
- STM.IO: 48%|████▊ | 6098/12806 [00:04<00:06, 1083.31it/s]
- STM.IO: 48%|████▊ | 6208/12806 [00:04<00:06, 1025.35it/s]
- STM.IO: 49%|████▉ | 6312/12806 [00:04<00:06, 952.27it/s]
- STM.IO: 50%|█████ | 6410/12806 [00:04<00:07, 910.42it/s]
- STM.IO: 51%|█████ | 6509/12806 [00:04<00:06, 930.92it/s]
- STM.IO: 52%|█████▏ | 6620/12806 [00:04<00:06, 976.37it/s]
- STM.IO: 52%|█████▏ | 6720/12806 [00:05<00:06, 926.81it/s]
- STM.IO: 53%|█████▎ | 6818/12806 [00:05<00:06, 940.17it/s]
- STM.IO: 54%|█████▍ | 6914/12806 [00:05<00:06, 930.36it/s]
- STM.IO: 55%|█████▍ | 7008/12806 [00:05<00:06, 852.84it/s]
- STM.IO: 55%|█████▌ | 7106/12806 [00:05<00:06, 885.63it/s]
- STM.IO: 56%|█████▌ | 7197/12806 [00:05<00:06, 805.83it/s]
- STM.IO: 57%|█████▋ | 7299/12806 [00:05<00:06, 858.49it/s]
- STM.IO: 58%|█████▊ | 7388/12806 [00:05<00:07, 744.49it/s]
- STM.IO: 58%|█████▊ | 7473/12806 [00:06<00:07, 755.34it/s]
- STM.IO: 59%|█████▉ | 7560/12806 [00:06<00:06, 785.88it/s]
- STM.IO: 60%|█████▉ | 7642/12806 [00:06<00:06, 782.78it/s]
- STM.IO: 60%|██████ | 7723/12806 [00:06<00:06, 768.90it/s]
- STM.IO: 61%|██████ | 7825/12806 [00:06<00:06, 828.66it/s]
- STM.IO: 62%|██████▏ | 7937/12806 [00:06<00:05, 897.30it/s]
- STM.IO: 63%|██████▎ | 8033/12806 [00:06<00:05, 913.23it/s]
- STM.IO: 63%|██████▎ | 8127/12806 [00:06<00:05, 913.79it/s]
- STM.IO: 64%|██████▍ | 8254/12806 [00:06<00:04, 994.44it/s]
- STM.IO: 65%|██████▌ | 8358/12806 [00:06<00:04, 1005.50it/s]
- STM.IO: 66%|██████▌ | 8466/12806 [00:07<00:04, 1024.62it/s]
- STM.IO: 67%|██████▋ | 8579/12806 [00:07<00:04, 1052.03it/s]
- STM.IO: 68%|██████▊ | 8712/12806 [00:07<00:03, 1111.93it/s]
- STM.IO: 69%|██████▉ | 8826/12806 [00:07<00:03, 1044.19it/s]
- STM.IO: 70%|██████▉ | 8933/12806 [00:07<00:03, 1005.29it/s]
- STM.IO: 71%|███████ | 9036/12806 [00:07<00:03, 1010.21it/s]
- STM.IO: 71%|███████▏ | 9150/12806 [00:07<00:03, 1043.83it/s]
- STM.IO: 72%|███████▏ | 9277/12806 [00:07<00:03, 1100.57it/s]
- STM.IO: 73%|███████▎ | 9404/12806 [00:07<00:02, 1144.16it/s]
- STM.IO: 74%|███████▍ | 9521/12806 [00:08<00:02, 1135.98it/s]
- STM.IO: 75%|███████▌ | 9648/12806 [00:08<00:02, 1170.75it/s]
- STM.IO: 76%|███████▋ | 9780/12806 [00:08<00:02, 1209.41it/s]
- STM.IO: 77%|███████▋ | 9903/12806 [00:08<00:02, 1184.92it/s]
- STM.IO: 78%|███████▊ | 10032/12806 [00:08<00:02, 1212.12it/s]
- STM.IO: 79%|███████▉ | 10155/12806 [00:08<00:02, 1214.79it/s]
- STM.IO: 80%|████████ | 10278/12806 [00:08<00:02, 1096.01it/s]
- STM.IO: 81%|████████ | 10391/12806 [00:08<00:02, 1100.40it/s]
- STM.IO: 82%|████████▏ | 10506/12806 [00:08<00:02, 1112.34it/s]
- STM.IO: 83%|████████▎ | 10619/12806 [00:09<00:02, 1035.66it/s]
- STM.IO: 84%|████████▎ | 10725/12806 [00:09<00:02, 914.43it/s]
- STM.IO: 84%|████████▍ | 10821/12806 [00:09<00:02, 889.74it/s]
- STM.IO: 85%|████████▌ | 10920/12806 [00:09<00:02, 915.76it/s]
- STM.IO: 86%|████████▌ | 11014/12806 [00:09<00:02, 819.91it/s]
- STM.IO: 87%|████████▋ | 11100/12806 [00:09<00:02, 738.28it/s]
- STM.IO: 87%|████████▋ | 11178/12806 [00:09<00:02, 740.24it/s]
- STM.IO: 88%|████████▊ | 11255/12806 [00:09<00:02, 657.58it/s]
- STM.IO: 89%|████████▊ | 11364/12806 [00:10<00:02, 702.16it/s]
- STM.IO: 89%|████████▉ | 11455/12806 [00:10<00:01, 752.49it/s]
- STM.IO: 90%|█████████ | 11548/12806 [00:10<00:01, 794.66it/s]
- STM.IO: 91%|█████████ | 11631/12806 [00:10<00:01, 796.56it/s]
- STM.IO: 92%|█████████▏| 11748/12806 [00:10<00:01, 879.46it/s]
- STM.IO: 93%|█████████▎| 11853/12806 [00:10<00:01, 922.73it/s]
- STM.IO: 93%|█████████▎| 11949/12806 [00:10<00:00, 895.23it/s]
- STM.IO: 94%|█████████▍| 12049/12806 [00:10<00:00, 922.41it/s]
- STM.IO: 95%|█████████▍| 12163/12806 [00:10<00:00, 976.60it/s]
- STM.IO: 96%|█████████▌| 12280/12806 [00:10<00:00, 1025.50it/s]
- STM.IO: 97%|█████████▋| 12412/12806 [00:11<00:00, 1096.80it/s]
- STM.IO: 98%|█████████▊| 12525/12806 [00:11<00:00, 1072.91it/s]
- STM.IO: 99%|█████████▉| 12663/12806 [00:11<00:00, 1147.57it/s]
- STM.IO: 100%|█████████▉| 12781/12806 [00:11<00:00, 1118.51it/s]
- Results for 12806 inference(s) - average per inference
- device : AMD64 Intel64 Family 6 Model 158 Stepping 9, GenuineIntel (Windows)
- duration : 0.057ms
- c_nodes : 4
- c_id m_id desc output ms %
- -------------------------------------------------------------------------------
- 0 1 Conv2dPool (0x109) (1,3,3,24)/float32/864B 0.049 86.5%
- 1 3 Dense (0x104) (1,1,1,12)/float32/48B 0.005 9.1%
- 2 5 Dense (0x104) (1,1,1,4)/float32/16B 0.001 1.8%
- 3 5 NL (0x107) (1,1,1,4)/float32/16B 0.001 2.5%
- -------------------------------------------------------------------------------
- 0.057 ms
- NOTE: duration and exec time per layer is just an indication. They are dependent of the HOST-machine work-load.
- Running the Keras model...
- Saving validation data...
- output directory: C:\Users\py_hp\.stm32cubemx\network_output
- creating C:\Users\py_hp\.stm32cubemx\network_output\har_ign_val_io.npz
- m_outputs_1: (12806, 1, 1, 4)/float32, min/max=[0.000, 1.000], mean/std=[0.250, 0.376], dense_2
- c_outputs_1: (12806, 1, 1, 4)/float32, min/max=[0.000, 1.000], mean/std=[0.250, 0.376], dense_2
- Computing the metrics...
- Accuracy report #1 for the generated x86 C-model
- ----------------------------------------------------------------------------------------------------
- notes: - computed against the provided ground truth values
- - 12806 samples (4 items per sample)
- acc=86.72%, rmse=0.224433631, mae=0.096160948, l2r=0.496649474, nse=73.14%
- 4 classes (12806 samples)
- ----------------------------
- C0 3678 . 62 41
- C1 . 1124 14 .
- C2 254 10 1806 662
- C3 66 . 592 4497
- Accuracy report #1 for the reference model
- ----------------------------------------------------------------------------------------------------
- notes: - computed against the provided ground truth values
- - 12806 samples (4 items per sample)
- acc=86.72%, rmse=0.224433631, mae=0.096160948, l2r=0.496649474, nse=73.14%
- 4 classes (12806 samples)
- ----------------------------
- C0 3678 . 62 41
- C1 . 1124 14 .
- C2 254 10 1806 662
- C3 66 . 592 4497
- Cross accuracy report #1 (reference vs C-model)
- ----------------------------------------------------------------------------------------------------
- notes: - the output of the reference model is used as ground truth/reference value
- - 12806 samples (4 items per sample)
- acc=100.00%, rmse=0.000000063, mae=0.000000024, l2r=0.000000139, nse=100.00%
- 4 classes (12806 samples)
- ----------------------------
- C0 3998 . . .
- C1 . 1134 . .
- C2 . . 2474 .
- C3 . . . 5200
-
- Evaluation report (summary)
- ----------------------------------------------------------------------------------------------------------------------------------------------------------
- Output acc rmse mae l2r mean std nse tensor
- ----------------------------------------------------------------------------------------------------------------------------------------------------------
- x86 c-model #1 86.72% 0.224433631 0.096160948 0.496649474 -0.000000000 0.224435821 0.731362987 dense_2, ai_float, (1,1,1,4), m_id=[5]
- original model #1 86.72% 0.224433631 0.096160948 0.496649474 -0.000000001 0.224435821 0.731362987 dense_2, ai_float, (1,1,1,4), m_id=[5]
- X-cross #1 100.00% 0.000000063 0.000000024 0.000000139 0.000000000 0.000000063 1.000000000 dense_2, ai_float, (1,1,1,4), m_id=[5]
- ----------------------------------------------------------------------------------------------------------------------------------------------------------
-
- rmse : Root Mean Squared Error
- mae : Mean Absolute Error
- l2r : L2 relative error
- nse : Nash-Sutcliffe efficiency criteria
- Creating txt report file C:\Users\py_hp\.stm32cubemx\network_output\har_ign_validate_report.txt
- elapsed time (validate): 26.458s
- Validation
6.4 c语言神经网络模型生成及源码输出
将开发板重新选择ST-LINK连接(5-6跳线帽拔出,插入1-2跳线中)
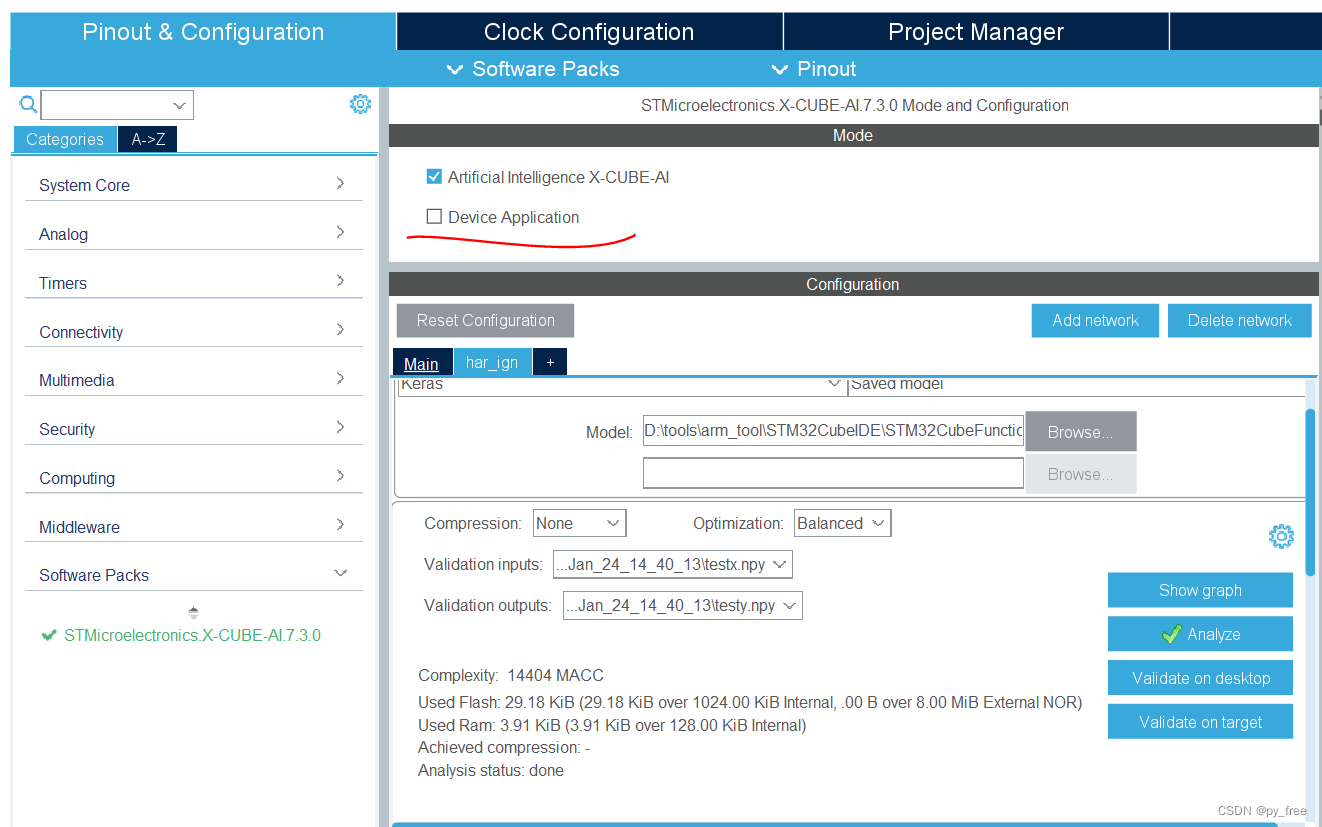
为了后续源码讲解方便,只生产c语言的神经网络模型源码,不输出应用示例程序(有个弊端就是在新建程序加载到开发板后,validation on target功能无法使用),如下图所示。
配置输出工程

七、c语言神经网络模型使用
7.1 C语言神经网络模型源文件
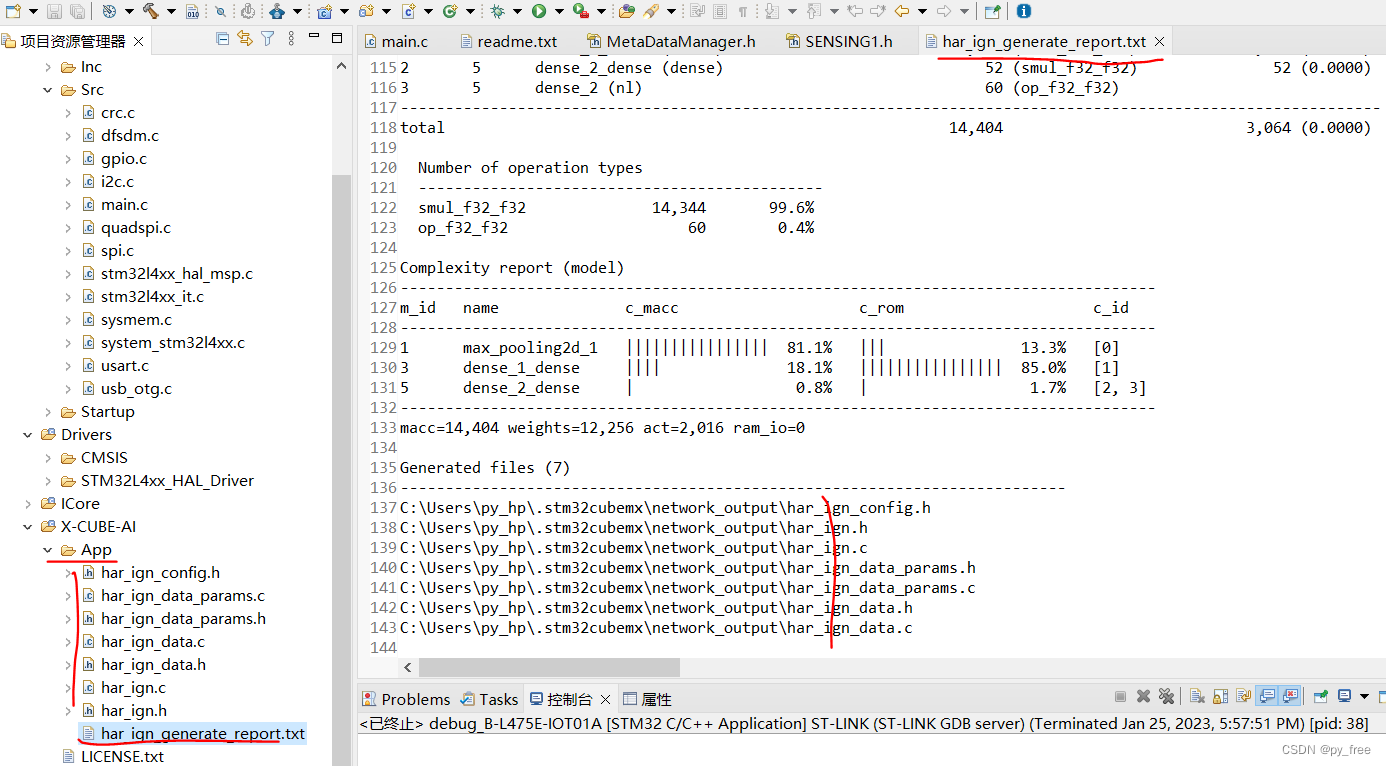
在cubeMX配置神经网络模型时,指明了名称是har_ign,会生成如下文件har_ign.h/c、har_ign_data.h/c、har_ign_data_params.h/c、har_ign_config.h这些源码文件就是转换后的c语言神经网络模型,提供了一系列的API,这些API通过调用cube.AI软件包的内置功能,工程实现了神经网络计算功能:

其中har_ign_generate_report.txt文件是生成c语言神经网络模型的过程记录。
7.2 串口功能自定义实现
由于本文没有选择生成配套的应用程序代码,因此串口功能还需要自己实现,因此我移植了串口功能代码,在工程目录下,创建了ICore源目录,并创建print、usart子目录,分别在两个子目录加入print.h/c和usart.h/c源码。

print.h如下:
- #ifndef INC_RETARGET_H_
- #define INC_RETARGET_H_
-
- #include "stm32l4xx_hal.h"
- #include "stdio.h"//用于printf函数串口重映射
- #include <sys/stat.h>
-
- void ResetPrintInit(UART_HandleTypeDef *huart);
-
- int _isatty(int fd);
- int _write(int fd, char* ptr, int len);
- int _close(int fd);
- int _lseek(int fd, int ptr, int dir);
- int _read(int fd, char* ptr, int len);
- int _fstat(int fd, struct stat* st);
-
- #endif /* INC_RETARGET_H_ */
print.c如下:
- #include <_ansi.h>
- #include <_syslist.h>
- #include <errno.h>
- #include <sys/time.h>
- #include <sys/times.h>
- #include <limits.h>
- #include <signal.h>
- #include <stdint.h>
- #include <stdio.h>
-
- #include "print.h"
-
- #if !defined(OS_USE_SEMIHOSTING)
- #define STDIN_FILENO 0
- #define STDOUT_FILENO 1
- #define STDERR_FILENO 2
-
- UART_HandleTypeDef *gHuart;
-
- void ResetPrintInit(UART_HandleTypeDef *huart) {
- gHuart = huart;
- /* Disable I/O buffering for STDOUT stream, so that
- * chars are sent out as soon as they are printed. */
- setvbuf(stdout, NULL, _IONBF, 0);
- }
- int _isatty(int fd) {
- if (fd >= STDIN_FILENO && fd <= STDERR_FILENO)
- return 1;
- errno = EBADF;
- return 0;
- }
- int _write(int fd, char* ptr, int len) {
- HAL_StatusTypeDef hstatus;
- if (fd == STDOUT_FILENO || fd == STDERR_FILENO) {
- hstatus = HAL_UART_Transmit(gHuart, (uint8_t *) ptr, len, HAL_MAX_DELAY);
- if (hstatus == HAL_OK)
- return len;
- else
- return EIO;
- }
- errno = EBADF;
- return -1;
- }
- int _close(int fd) {
- if (fd >= STDIN_FILENO && fd <= STDERR_FILENO)
- return 0;
- errno = EBADF;
- return -1;
- }
- int _lseek(int fd, int ptr, int dir) {
- (void) fd;
- (void) ptr;
- (void) dir;
- errno = EBADF;
- return -1;
- }
- int _read(int fd, char* ptr, int len) {
- HAL_StatusTypeDef hstatus;
- if (fd == STDIN_FILENO) {
- hstatus = HAL_UART_Receive(gHuart, (uint8_t *) ptr, 1, HAL_MAX_DELAY);
- if (hstatus == HAL_OK)
- return 1;
- else
- return EIO;
- }
- errno = EBADF;
- return -1;
- }
- int _fstat(int fd, struct stat* st) {
- if (fd >= STDIN_FILENO && fd <= STDERR_FILENO) {
- st->st_mode = S_IFCHR;
- return 0;
- }
- errno = EBADF;
- return 0;
- }
-
- #endif //#if !defined(OS_USE_SEMIHOSTING)
usart.h
- #ifndef INC_USART_H_
- #define INC_USART_H_
-
- #include "stm32l4xx_hal.h" //HAL库文件声明
- #include <string.h>//用于字符串处理的库
- #include "../print/print.h"//用于printf函数串口重映射
-
- extern UART_HandleTypeDef huart1;//声明LPUSART的HAL库结构体
-
- #define USART_REC_LEN 256//定义LPUSART最大接收字节数
-
- extern uint8_t USART_RX_BUF[USART_REC_LEN];//接收缓冲,最大USART_REC_LEN个字节.末字节为换行符
- extern uint16_t USART_RX_STA;//接收状态标记
- extern uint8_t USART_NewData;//当前串口中断接收的1个字节数据的缓存
-
-
- void HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart);//串口中断回调函数声明
-
- #endif /* INC_USART_H_ */
usart.c如下:
- #include "usart.h"
-
- uint8_t USART_RX_BUF[USART_REC_LEN];//接收缓冲,最大USART_REC_LEN个字节.末字节为换行符
- /*
- * bit15:接收到回车(0x0d)时设置HLPUSART_RX_STA|=0x8000;
- * bit14:接收溢出标志,数据超出缓存长度时,设置HLPUSART_RX_STA|=0x4000;
- * bit13:预留
- * bit12:预留
- * bit11~0:接收到的有效字节数目(0~4095)
- */
- uint16_t USART_RX_STA=0;接收状态标记//bit15:接收完成标志,bit14:接收到回车(0x0d),bit13~0:接收到的有效字节数目
- uint8_t USART_NewData;//当前串口中断接收的1个字节数据的缓存
-
- void HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart)//串口中断回调函数
- {
- if(huart ==&huart1)//判断中断来源(串口1:USB转串口)
- {
- if(USART_NewData==0x0d){//回车标记
- USART_RX_STA|=0x8000;//标记接到回车
- }else{
- if((USART_RX_STA&0X0FFF)<USART_REC_LEN){
- USART_RX_BUF[USART_RX_STA&0X0FFF]=USART_NewData; //将收到的数据放入数组
- USART_RX_STA++; //数据长度计数加1
- }else{
- USART_RX_STA|=0x4000;//数据超出缓存长度,标记溢出
- }
- }
- HAL_UART_Receive_IT(&huart1,(uint8_t *)&USART_NewData,1); //再开启接收中断
- }
- }
7.3 c语言神经网络模型API使用
先不管底层机理,本文给下面代码,看看如何实现这些API调用的,在main.c文件中,通过aiInit函数,实现har_ign模型初始化,并打印模型相关信息。在主函数循环体中,通过串口输入信息,获得数据生成因子,调用acquire_and_process_data进行输入数据生成,然后调用aiRun,并传入生成数据及输出缓存,进行神经网络模型调用。然后调用post_process打印输出信息。
- /* USER CODE END Header */
- /* Includes ------------------------------------------------------------------*/
- #include "main.h"
- #include "crc.h"
- #include "dfsdm.h"
- #include "i2c.h"
- #include "quadspi.h"
- #include "spi.h"
- #include "usart.h"
- #include "usb_otg.h"
- #include "gpio.h"
-
- /* Private includes ----------------------------------------------------------*/
- /* USER CODE BEGIN Includes */
- #include "../../ICore/print/print.h"
- #include "../../ICore/usart/usart.h"
- #include "../../X-CUBE-AI/app/har_ign.h"
- #include "../../X-CUBE-AI/app/har_ign_data.h"
- /* USER CODE END Includes */
-
- /* Private typedef -----------------------------------------------------------*/
- /* USER CODE BEGIN PTD */
-
- /* USER CODE END PTD */
-
- /* Private define ------------------------------------------------------------*/
- /* USER CODE BEGIN PD */
- /* USER CODE END PD */
-
- /* Private macro -------------------------------------------------------------*/
- /* USER CODE BEGIN PM */
-
- /* USER CODE END PM */
-
- /* Private variables ---------------------------------------------------------*/
-
- /* USER CODE BEGIN PV */
-
- /* USER CODE END PV */
-
- /* Private function prototypes -----------------------------------------------*/
- void SystemClock_Config(void);
- /* USER CODE BEGIN PFP */
-
- /* USER CODE END PFP */
-
- /* Private user code ---------------------------------------------------------*/
- /* USER CODE BEGIN 0 */
- /* Global handle to reference the instantiated C-model */
- static ai_handle network = AI_HANDLE_NULL;
-
- /* Global c-array to handle the activations buffer */
- AI_ALIGNED(32)
- static ai_u8 activations[AI_HAR_IGN_DATA_ACTIVATIONS_SIZE];
-
- /* Array to store the data of the input tensor */
- AI_ALIGNED(32)
- static ai_float in_data[AI_HAR_IGN_IN_1_SIZE];
- /* or static ai_u8 in_data[AI_HAR_IGN_IN_1_SIZE_BYTES]; */
-
- /* c-array to store the data of the output tensor */
- AI_ALIGNED(32)
- static ai_float out_data[AI_HAR_IGN_OUT_1_SIZE];
- /* static ai_u8 out_data[AI_HAR_IGN_OUT_1_SIZE_BYTES]; */
-
- /* Array of pointer to manage the model's input/output tensors */
- static ai_buffer *ai_input;
- static ai_buffer *ai_output;
- static ai_buffer_format fmt_input;
- static ai_buffer_format fmt_output;
-
- void buf_print(void)
- {
- printf("in_data:");
- for (int i=0; i<AI_HAR_IGN_IN_1_SIZE; i++)
- {
- printf("%f ",((ai_float*)in_data)[i]);
- }
- printf("\n");
- printf("out_data:");
- for (int i=0; i<AI_HAR_IGN_OUT_1_SIZE; i++)
- {
- printf("%f ",((ai_float*)out_data)[i]);
- }
- printf("\n");
- }
-
- void aiPrintBufInfo(const ai_buffer *buffer)
- {
- printf("(%lu, %lu, %lu, %lu)", AI_BUFFER_SHAPE_ELEM(buffer, AI_SHAPE_BATCH),
- AI_BUFFER_SHAPE_ELEM(buffer, AI_SHAPE_HEIGHT),
- AI_BUFFER_SHAPE_ELEM(buffer, AI_SHAPE_WIDTH),
- AI_BUFFER_SHAPE_ELEM(buffer, AI_SHAPE_CHANNEL));
- printf(" buffer_size:%d ", (int)AI_BUFFER_SIZE(buffer));
- }
-
- void aiPrintDataType(const ai_buffer_format fmt)
- {
- if (AI_BUFFER_FMT_GET_TYPE(fmt) == AI_BUFFER_FMT_TYPE_FLOAT)
- printf("float%d ", (int)AI_BUFFER_FMT_GET_BITS(fmt));
- else if (AI_BUFFER_FMT_GET_TYPE(fmt) == AI_BUFFER_FMT_TYPE_BOOL) {
- printf("bool%d ", (int)AI_BUFFER_FMT_GET_BITS(fmt));
- } else { /* integer type */
- printf("%s%d ", AI_BUFFER_FMT_GET_SIGN(fmt)?"i":"u",
- (int)AI_BUFFER_FMT_GET_BITS(fmt));
- }
- }
-
- void aiPrintDataInfo(const ai_buffer *buffer,const ai_buffer_format fmt)
- {
- if (buffer->data)
- printf(" @0x%X/%d \n",
- (int)buffer->data,
- (int)AI_BUFFER_BYTE_SIZE(AI_BUFFER_SIZE(buffer), fmt)
- );
- else
- printf(" (User Domain)/%d \n",
- (int)AI_BUFFER_BYTE_SIZE(AI_BUFFER_SIZE(buffer), fmt)
- );
- }
-
- void aiPrintNetworkInfo(const ai_network_report report)
- {
- printf("Model name : %s\n", report.model_name);
- printf(" model signature : %s\n", report.model_signature);
- printf(" model datetime : %s\r\n", report.model_datetime);
- printf(" compile datetime : %s\r\n", report.compile_datetime);
- printf(" runtime version : %d.%d.%d\r\n",
- report.runtime_version.major,
- report.runtime_version.minor,
- report.runtime_version.micro);
- if (report.tool_revision[0])
- printf(" Tool revision : %s\r\n", (report.tool_revision[0])?report.tool_revision:"");
- printf(" tools version : %d.%d.%d\r\n",
- report.tool_version.major,
- report.tool_version.minor,
- report.tool_version.micro);
- printf(" complexity : %lu MACC\r\n", (unsigned long)report.n_macc);
- printf(" c-nodes : %d\r\n", (int)report.n_nodes);
-
- printf(" map_activations : %d\r\n", report.map_activations.size);
- for (int idx=0; idx<report.map_activations.size;idx++) {
- const ai_buffer *buffer = &report.map_activations.buffer[idx];
- printf(" [%d] ", idx);
- aiPrintBufInfo(buffer);
- printf("\r\n");
- }
-
- printf(" map_weights : %d\r\n", report.map_weights.size);
- for (int idx=0; idx<report.map_weights.size;idx++) {
- const ai_buffer *buffer = &report.map_weights.buffer[idx];
- printf(" [%d] ", idx);
- aiPrintBufInfo(buffer);
- printf("\r\n");
- }
- }
-
- /*
- * Bootstrap
- */
- int aiInit(void) {
- ai_error err;
-
- /* Create and initialize the c-model */
- const ai_handle acts[] = { activations };
- err = ai_har_ign_create_and_init(&network, acts, NULL);
- if (err.type != AI_ERROR_NONE) {
- printf("ai_error_type:%d,ai_error_code:%d\r\n",err.type,err.code);
- };
-
- ai_network_report report;
- if (ai_har_ign_get_report(network, &report) != true) {
- printf("ai get report error\n");
- return -1;
- }
-
- aiPrintNetworkInfo(report);
-
- /* Reteive pointers to the model's input/output tensors */
- ai_input = ai_har_ign_inputs_get(network, NULL);
- ai_output = ai_har_ign_outputs_get(network, NULL);
- //
- fmt_input = AI_BUFFER_FORMAT(ai_input);
- fmt_output = AI_BUFFER_FORMAT(ai_output);
-
- printf(" n_inputs/n_outputs : %u/%u\r\n", report.n_inputs,
- report.n_outputs);
- printf("input :");
- aiPrintBufInfo(ai_input);
- aiPrintDataType(fmt_input);
- aiPrintDataInfo(ai_input, fmt_input);
- //
- printf("output :");
- aiPrintBufInfo(ai_output);
- aiPrintDataType(fmt_output);
- aiPrintDataInfo(ai_output, fmt_output);
- return 0;
- }
-
- int acquire_and_process_data(void *in_data,int factor)
- {
- printf("in_data:");
- for (int i=0; i<AI_HAR_IGN_IN_1_SIZE; i++)
- {
- switch(i%3){
- case 0:
- ((ai_float*)in_data)[i] = -175+(ai_float)(i*factor*1.2)/10.0;
- break;
- case 1:
- ((ai_float*)in_data)[i] = 50+(ai_float)(i*factor*0.6)/100.0;
- break;
- case 2:
- ((ai_float*)in_data)[i] = 975-(ai_float)(i*factor*1.8)/100.0;
- break;
- default:
- break;
- }
- printf("%f ",((ai_float*)in_data)[i]);
- }
- printf("\n");
- return 0;
- }
- /*
- * Run inference
- */
- int aiRun(const void *in_data, void *out_data) {
- ai_i32 n_batch;
- ai_error err;
-
- /* 1 - Update IO handlers with the data payload */
- ai_input[0].data = AI_HANDLE_PTR(in_data);
- ai_output[0].data = AI_HANDLE_PTR(out_data);
-
- /* 2 - Perform the inference */
- n_batch = ai_har_ign_run(network, &ai_input[0], &ai_output[0]);
- if (n_batch != 1) {
- err = ai_har_ign_get_error(network);
- printf("ai_error_type:%d,ai_error_code:%d\r\n",err.type,err.code);
- };
-
- return 0;
- }
-
- int post_process(void *out_data)
- {
- printf("out_data:");
- for (int i=0; i<AI_HAR_IGN_OUT_1_SIZE; i++)
- {
- printf("%f ",((ai_float*)out_data)[i]);
- }
- printf("\n");
- return 0;
- }
- /* USER CODE END 0 */
-
- /**
- * @brief The application entry point.
- * @retval int
- */
- int main(void)
- {
- /* USER CODE BEGIN 1 */
-
- /* USER CODE END 1 */
-
- /* MCU Configuration--------------------------------------------------------*/
-
- /* Reset of all peripherals, Initializes the Flash interface and the Systick. */
- HAL_Init();
-
- /* USER CODE BEGIN Init */
-
- /* USER CODE END Init */
-
- /* Configure the system clock */
- SystemClock_Config();
-
- /* USER CODE BEGIN SysInit */
-
- /* USER CODE END SysInit */
-
- /* Initialize all configured peripherals */
- MX_GPIO_Init();
- MX_DFSDM1_Init();
- MX_I2C2_Init();
- MX_QUADSPI_Init();
- MX_SPI3_Init();
- MX_USART1_UART_Init();
- MX_USART3_UART_Init();
- MX_USB_OTG_FS_PCD_Init();
- MX_CRC_Init();
- /* USER CODE BEGIN 2 */
- ResetPrintInit(&huart1);
- HAL_UART_Receive_IT(&huart1,(uint8_t *)&USART_NewData, 1); //再开启接收中断
- USART_RX_STA = 0;
- aiInit();
- uint8_t factor = 1;
- buf_print();
- /* USER CODE END 2 */
-
- /* Infinite loop */
- /* USER CODE BEGIN WHILE */
- while (1)
- {
- if(USART_RX_STA&0xC000){//溢出或换行,重新开始
- printf("uart1:%.*s\r\n",USART_RX_STA&0X0FFF, USART_RX_BUF);
- if(strstr((const char*)USART_RX_BUF,(const char*)"test"))
- {
- factor = ((uint8_t)USART_RX_BUF[4]-0x30);
- printf("factor:%d\n",factor);
- acquire_and_process_data(in_data,factor);
- aiRun(in_data, out_data);
- post_process(out_data);
- }
- USART_RX_STA=0;//接收错误,重新开始
- HAL_Delay(100);//等待
- }
- /* USER CODE END WHILE */
-
- /* USER CODE BEGIN 3 */
- }
- /* USER CODE END 3 */
- }
- //其他生产代码
- .......
7.4 编译及程序运行测试
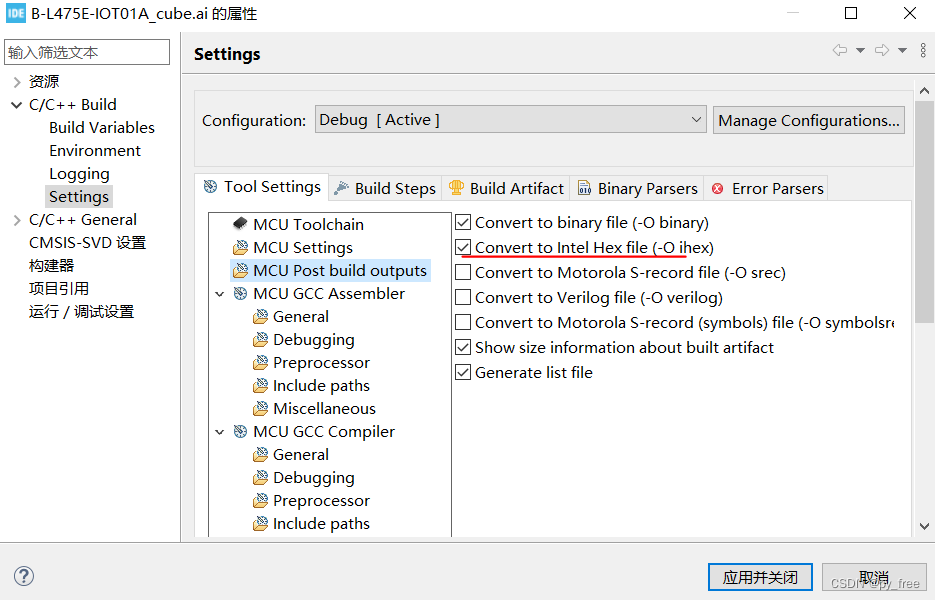
配置工程输出文件格式支持,并设置运行配置:
编译及下载程序:

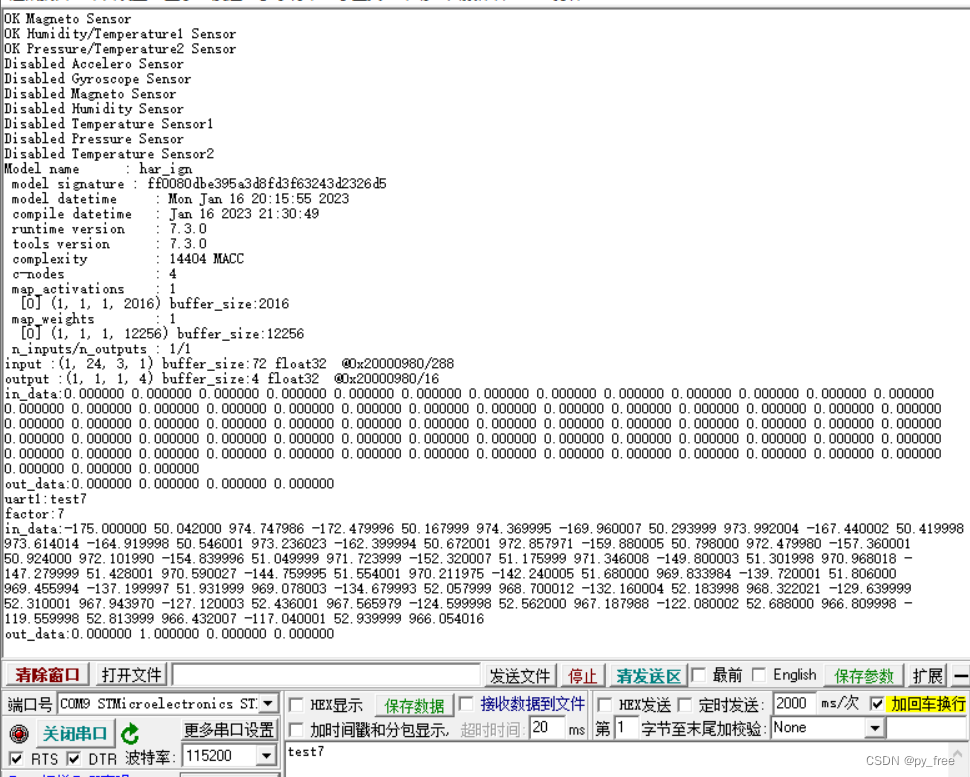
打开串口助手,查看日志输出,发送信息,例如test7,即7作为因子生成输入数据,然后看输出结果。
7.5 补充说明
目前只能说是采用cubeIDE+cube.AI+keras的STM32嵌入式人工智能开发走通了流程,但是串口反馈回来的日志信息是不合理的,因为在数据采集时我们只采集了传感器的三个数值,但在训练模型时,默认的数据输入量是24,显然是不合理的,因此需要还需要重新分析官方提供的HAR训练模型的项目,使得模型训练与采集数据匹配起来,请阅读篇二。
但考虑到官方提供的HAR训练模型的工程项目还是过于复杂,不助于学习和了解cube.AI的真正用法,因此后面将抛弃官方提供的HAR训练模型的项目,自行撰写一个训练模型项目+实际采集数据生成神经网络模型,是的数据输入和输出匹配,并将采用传感器实时采集到的数据进行计算评估,请阅读偏三。


