
知识蒸馏
赞
踩
目录
《Distilling the Knowledge in a Neural Network 》 2015
《Learning Metrics from Teachers: Compact Networks for Image Embedding》2019 CVPR
《Relational Knowledge Distillation》2019 CVPR
一 引言
1.1 深度学习的优点
特征学习代替特征工程:深度学习通过从数据中自己学习出有效的特征表示,代替以往机器学习中繁琐的人工特征工程过程,举例来说,对于图片的猫狗识别问题,机器学习需要人工的设计、提取出猫的特征、狗的特征输入到机器学习模型中才能进行进一步的分类,这个过程非常依赖人的经验和领域知识,而深度学习模型会自己直接从猫狗图片中学习出猫和狗的有效特征表示。
端到端学习代替多模块学习:在一些任务中,传统机器学习方法需要将一个任务的输入和输出之间,人为的分割成多个子模块,也就是分割成多个阶段,每个子模块分开进行训练学习,比如对于一个自然语言理解问题,一般需要切分成分词、词性标注、句法分析、语法分析等多个模块,而端到端学习不进行模块和阶段的划分,直接优化任务的总体目标,中间过程不需要人为干预,训练数据呈现 输入-输出 对的形式,不再需要额外的信息。
1.2 深度学习的缺点
依赖数据量规模:深度学习要想发挥出理想的效果,需要大规模的数据,当数据量偏少时可能还不如传统的机器学习方法。
模型体积过大:深度学习要想从数据中学习出更有效的特征表示,一般会通过加深模型层数的方法,随着残差连接和多种正则化方法的提出,训练更深层的模型变为可能,这也导致了深度学习模型的体积变的越来越大,无法部署在那些资源受限的设备上,往往只是理论上能达到最优,但是无法真正进行落地使用。
可解释性差:在深度学习的眼中,万事万物都是向量(更准确的说叫张量),外界对象需要被表示为向量才能输入到模型中进行进一步的处理,在深度学习中把将外界对象表示为向量这个过程叫做嵌入,比如将一个词语表示为向量叫做词嵌入,但是表示成向量之后,它的解释性就很差,比如用 [0.3,0.4,9.2] 这个向量表示‘我’这个词,你就不知道这几个数字究竟表示什么意义。
二 什么是知识蒸馏
2.1 模型压缩
模型压缩在不降低或者只是轻微降低原模型准确率的同时,大幅缩小原模型的体积,使其可以真正进行线上部署,常用的模型压缩方法包括
-
参数裁剪:删除掉原模型中一些无用的参数,缩小模型的体积
-
精度转换:降低原模型中参数的存储精度
-
神经网络结构搜索:寻找原模型中真正对最终结果起作用的网络层,删除掉影响不大的网络层,降低模型的体积。
2.2 什么是学习
赫尔伯特.西蒙曾经给学习下过定义:“如果一个系统能够通过执行某个过程改进它的性能,这就是学习。”
具体到深度学习的过程,也就是训练的过程,就是神经网络根据损失函数的约束,从输入的数据中发掘信息,从信息中再获取到对于最终任务起关键性作用的知识。
这些学习到的知识以参数的形式固化在神经网络中,当我们将数据输入到训练完毕的神经网络中,可以获取到神经网络关于数据形成的知识。
2.3 什么是知识蒸馏
知识蒸馏也是一种模型压缩方法,参数裁剪、精度转换、神经网络结构搜索这些模型压缩方法会破坏原模型的结构,也就是会损坏原模型从数据中学习到的知识,而知识蒸馏通过蒸馏的手段保护原模型中学习到的知识,然后将这些知识迁移到压缩模型中,使压缩模型虽然相比原模型体积要小的多,但是也可以学习到相同的知识。
2.4 知识蒸馏的一般流程
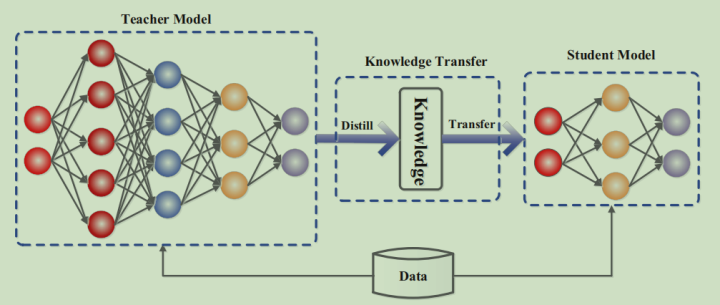
类比人类的学习过程,在知识蒸馏中称要进行压缩的模型为教师神经网络(Teacher Model),压缩之后的模型为学生神经网络(Student Model),一般情况下,教师神经网络的体积要远大于学生神经网络。
一般的知识蒸馏过程为
-
首先利用数据集训练教师神经网络,让教师神经网络充分学习数据中包含的知识
-
然后在利用数据集训练学生神经网络时,通过蒸馏方法将教师神经网络中已经学习到的知识提取出来,指导学生神经网络的训练,这样学生神经网络相当于从教师神经网络那里获取到了关于数据集的先验信息。
也就是在知识蒸馏中,教师神经网络是预先在数据集上进行过训练的,然后在学生神经网络的训练过程中利用自身学习到的知识对其进行指导,帮助提高学生神经网络的准确率。
使用知识蒸馏要解决的关键问题是
-
如何发掘教师神经网络中包含的知识
-
如何将教师神经网络中的知识通过蒸馏无损的迁移到学生神经网络中,也就是蒸馏方法的设计
-
如何设计学生神经网络的结构
三 知识蒸馏的分类
3.1 模型结构的种类
深度学习中虽然模型众多,但是其结构可以归为四种
-
前馈神经网络:也叫多层感知机,MLP,前馈神经网络由 线性变换+非线性激活 组成,通过线性变换将输入空间中的数据变换到特征空间,利用非线性激活函数无限逼近真实的判别函数。
-
卷积神经网络:CNN,卷积神经网络是连接受限的前馈神经网络,适合处理具有局部相关性的数据,比如图像
-
循环神经网络:RNN,循环神经网络会携带网络处理过程中产生的历史信息进行接下来的处理,适合处理那些具有时序性特征的数据
-
Transformer:带有注意力机制的前馈神经网络,利用注意力机制获取数据中的关键信息,可以利用有限的计算资源处理更重要的信息。
综上,多种网络结构其实可以统一看成前馈神经网络。
3.2 知识的分类
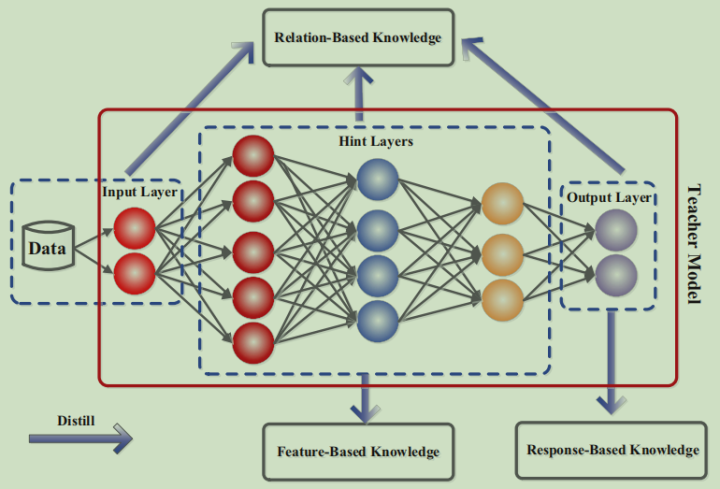
在知识蒸馏中,将教师神经网络中的知识分为三种
-
输出层知识:图中的Response-based Knowledge,是教师神经网络最后一层的输出,这个输出未经过Softmax层转换为概率,一般称为Logits,关于Logits的具体介绍可见Logits
-
中间层知识:图中的Feature-Based Knowledge,指的是教师神经网络中间网络层的输出、包含的参数
-
关系型知识:图中的Relation-Based Knowledge,将教师神经网络不同层知识之间的关系作为一种知识,也叫结构型知识。
3.3 如何蒸馏


四 输出层知识蒸馏
《Distilling the Knowledge in a Neural Network 》 2015
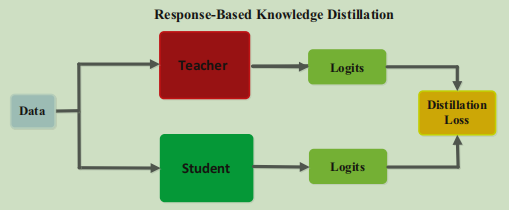
Hinton2015年在这篇文章中首次提出知识蒸馏的概念和方法,并在MNIST手写体数字识别数据集上验证了方法的有效性。
假设我们现在的任务是利用神经网络识别 1~5 的手写体数字图片,也就是将一张手写体数字图片输入到神经网络中,神经网络要判断出这张图片中的数字究竟是几。

但是这些数字的大小相差太大,类似于归一化,先想办法在不改变它们原有分布的情况下,改变这些数值的大小,使其具有可比性,Hinton在这里引入了一个称为'温度'的参数,对Logtis进行平滑处理,知识蒸馏这个词语也是来自于这个过程,具体平滑公式是


蒸馏过程为

五 中间层知识蒸馏
《Learning Metrics from Teachers: Compact Networks for Image Embedding》2019 CVPR
可以将神经网络看作是一个解决问题的过程,最后神经网络的输出结果就是神经网络对问题的解,而中间的网络层就是解决问题的步骤,既然可以让学生神经网络直接学习教师神经网络输出的问题结果,也可以利用蒸馏损失函数让学生神经网络学习教师神经网络的解题过程,也就是学习教师神经网络中间层的知识。
这篇论文中的中间层知识蒸馏过程如下图
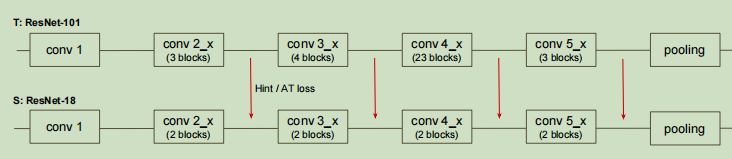
首先利用数据集训练教师神经网络,然后在学生神经网络训练的过程中,将数据同样输入到教师神经网络中,获取教师神经网络每个中间网络层输出的特征图,同样获取学生神经网络的特征图,然后定义中间层蒸馏损失函数为
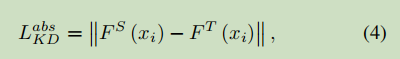

中间层知识蒸馏的一般流程为
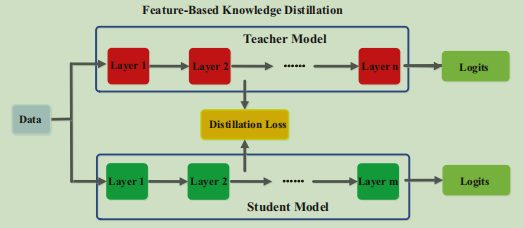
首先训练教师神经网络,然后获取教师神经网络中间层的知识,在训练学生神经网络时获取教师神经网络、学生神经网络中间层的知识,利用蒸馏损失函数进行中间层知识蒸馏。
六 关系层知识蒸馏
《Relational Knowledge Distillation》2019 CVPR
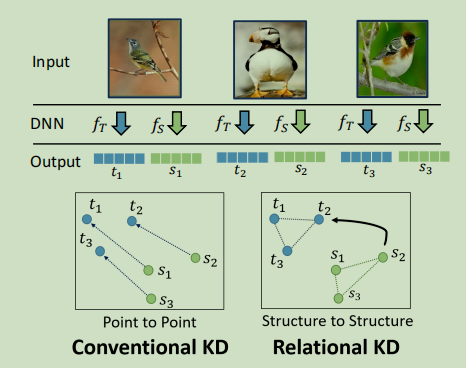
普通的知识蒸馏(上图中左侧的Conventional KD)中学生神经网络学习到的是一对一的教师神经网络产生的知识,而在关系层知识蒸馏(上图中右侧Relational KD)中学生神经网络学习的是知识之间的结构关系(Structure Knowledge),增强知识蒸馏的泛化性。
在这篇文章中,作者提出的关系层知识蒸馏过程如下
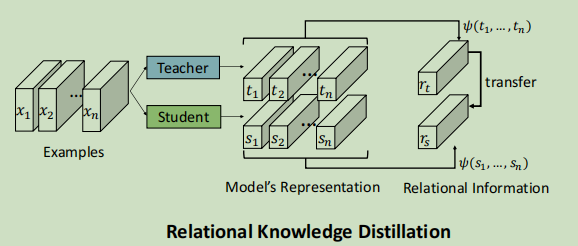

在这篇文章中,作者每次选择两个样本进行关系型知识蒸馏,定义关系抽取函数为
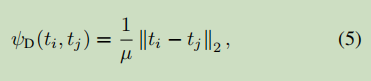
其中的 u 是一个正则化因子定义为
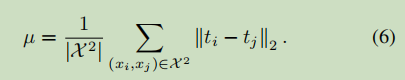
在本文中使用的衡量相似性函数为
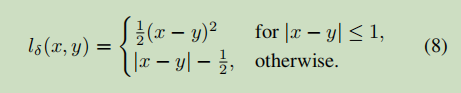
最终关系型蒸馏损失函数定义为
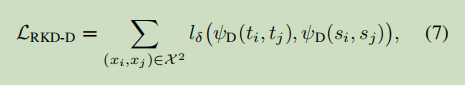
七 其它知识蒸馏方法
7.1 多教师知识蒸馏
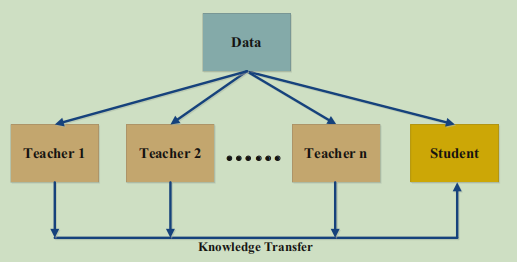
相当于是一种模型集成的方法,利用知识蒸馏将多个教师神经网络中的知识迁移到学生神经网络中,让学生神经网络在多个不同的特征空间中进行学习,可以大幅提高学生神经网络的准确率。
7.2 融合图神经网络的知识蒸馏
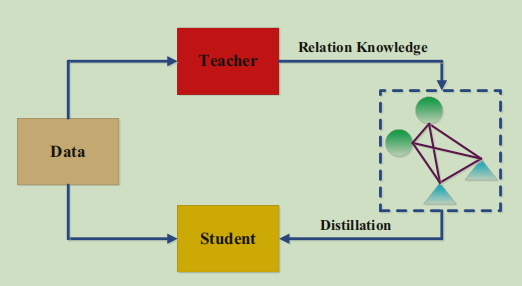
将教师神经网络中的知识构建成图,然后利用图神经网络中的方法获取其中的关系型知识,进行关系层的知识蒸馏。
7.3 结合多模态的知识蒸馏
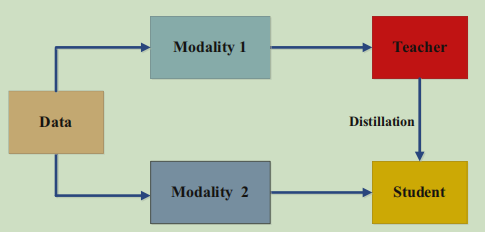
数据集是一个多模态的数据集,比如包含声音、图像、文本,在A模态上训练教师神经网络,然后在利用B模态训练学生神经网络的时候利用知识蒸馏,相当于一种多模态融合方法。
八 知识蒸馏代码的编写
知识蒸馏代码编写中,教师神经网络按照普通的深度学习流程在数据集上进行训练即可,重点在于神经网络中知识的获取和蒸馏损失函数的编写,拿PyTorch举例
8.1 如何获取到神经网络中的知识
利用hook机制获取神经网络中的知识,hook机制能够使我们获取神经网络中指定层在前向传递过程中的输出,也就是相应的知识
- import torch
-
-
- # 获取模型中的知识
- class GetFeatures:
-
- # 指定想要获取知识的模型和相应的网络层
- def __init__(self, model, layer_num):
- # 获取到的知识
- self.features = None
- # 注入hook
- self.hook = model[layer_num].register_forward_hook(self.hook_fn)
-
- # hook函数
- def hook_fn(self, module, input, output):
- # 获取模型相应网络层的输出
- self.features = output.cuda()
-
- # 移除hook
- def remove(self):
- self.hook.remove()
-
-



