
热门标签
热门文章
- 1【python】调整图像大小_自定义调整、等高宽调整
- 2Python中函数的详解_def func( ): print('hello') 问:type(func),type(func
- 3队列的顺序存储结构_队列的顺序存储结构源代码
- 4linux-----------串口设置缓冲器的大小_xmit_fifo_size
- 5让模型畅所欲言不再Say No丨专访Dolphin开源模型作者Eric Hartford
- 6散列表(哈希表)
- 7Flink Task、Sub-Task、task slot和parallelism_flink subtask
- 8Spark MLlib快速入门(1)逻辑回归、Kmeans、决策树、Pipeline、交叉验证_sparkmlib入门
- 9OpenCV如何模板匹配(59)
- 10大语言模型与知识图谱的融合在心理学领域的应用_语言模型与知识图谱在心理学领域的应用
当前位置: article > 正文
强化学习方法归纳_基于价值的强化学习方法
作者:很楠不爱3 | 2024-05-08 09:53:02
赞
踩
基于价值的强化学习方法
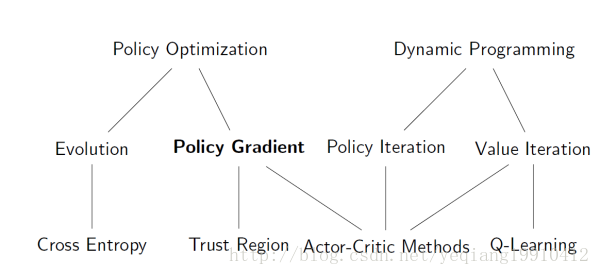
图1 强化学习算法的分类
强化学习方法主要包括:基于价值的方法,如Q-learning,DQN;基于策略搜索的方法(Policy Gradient);以及两者的结合行为-评判模型(actor-critic)等。
一、强化学习算法基本思想
Q-learning一般针对离散空间,采用值迭代方法。以value推policy。Q-learning通过计算每一个状态动作的价值,然后选择价值最大的动作执行.
Policy Gradient针对连续场景,直接在策略空间求解,泛化更好,直推policy。不通过分析奖励值, 直接输出行为的方法.
注:对比起以值为基础的方法,Policy Gradients 直接输出动作的最大好处就是, 它能在一个连续区间内挑选动作, 而基于值的, 比如 Q-learning, 它如果在无穷多的动作中计算价值, 从而选择行为, 这, 它可吃不消.
actor-critic可以看作是一个共轭,互相作用,策略也更稳定。
二、策略梯度方法(Policy-G
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/很楠不爱3/article/detail/554012
推荐阅读
相关标签

