
- 1Python实现的一个简单的GAN(生成对抗网络)例子
- 2异地远程访问本地SQL Server数据库【无公网IP内网穿透】_异地装了一台服务器,如何看是否可以访问数据库
- 3minio对象存储
- 4机器学习毕设题目有哪些_毕业后,我才知道计算机毕设该这样做
- 5微信小程序引入echarts折线图在ios真机上无法上下滑动的问题_echarts图表ios上滑动不了怎么解决
- 6charles对iOS手机的https进行抓包(图文教程)_ios charles
- 7入门javascript_现代javascript代理入门
- 8使用maven创建Flink项目_mvn创建flink项目
- 9vs 2022 如何拉取gitlab项目_vs2022 gitlab
- 10基于Python的云南旅游景点分析_python旅游景点预测
Finetuner+:为企业实现大模型微调和私有化部署_私有布置大模型
赞
踩

如 ChatGPT、GPT4 这样的大型语言模型就像是你为公司请的一个牛人顾问,他在 OpenAI、Google 等大公司被预训练了不少的行业内专业知识,所以加入你的公司后,你只需要输入 Prompt 给他, 介绍一些业务上的背景知识,他就能马上上手干活了。然而,由于这个顾问专家不是你们公司所独有的,最重要的是你们之前没有签订任何数据安全协议,他既不能保证数据安全,也不能保证内容受控不外流。
此外,由于它们都是公有的大型语言模型,可以作为一个基础模型来帮助解决一些基本问题,但是当您需要更好地应对特定领域的问题时,比如法律领域内的专业案例分析时,它的回答就不够理想了。尤其对于变化快、专业词汇复杂的领域时,这类大模型的回答就会显得不够令人满意了,甚至常有事实性错误发生。
随着这些大型语言模型、文本图像生成模型在各行各业的应用越来越广泛,我们如何在既享有公有的 ChatGPT 知识和能力的基础上,再微调训练出一个 私有化部署的、数据安全的、更擅长特定行业应用的 ChatGPT 或 Midjourney,让它能更好地服务企业自己或客户使用呢?
而这就是我们推出 Finetuner+ 的原因:让通用的大模型转变为客户所在行业的专家。我们将根据客户的数据和需求,对这类通用大型语言模型进行定制化微调,让它更适合解决客户所在行业的问题。并且将微调权重完全保留在客户组织的基础设施内。也就是说,微调后的模型将完全部署在企业的内网里,从而大大降低了数据泄露的风险。

Finetuner+ 如何微调大模型
Finetuner+ 拥有一套完善的功能体系,涵盖了模型微调的各个环节。无论是数据预处理、模型训练、还是模型评估,Finetuner+ 都能够提供专业的支持,用户无需编写复杂的代码,只需提供需求和数据,即可获得一个私有化的大型语言模型或文本图片生成模型。企业只需要关注模型需要在哪些场景里落地和使用。
我们使用到的技术包括但不限于:
1. 无监督的二阶预训练
对于目前流行的大模型,由于缺乏中文语料,在很多行业特定领域内的表现仍有很多不足。我们将利用客户的所在领域的中文语料,采用无监督学习的方式,将根据客户的具体需求和任务设计特定的微调方法和策略,让模型专注学习特定领域的知识,以确保模型在处理该领域的中文任务时能够达到最佳的效果。
2. 指令微调
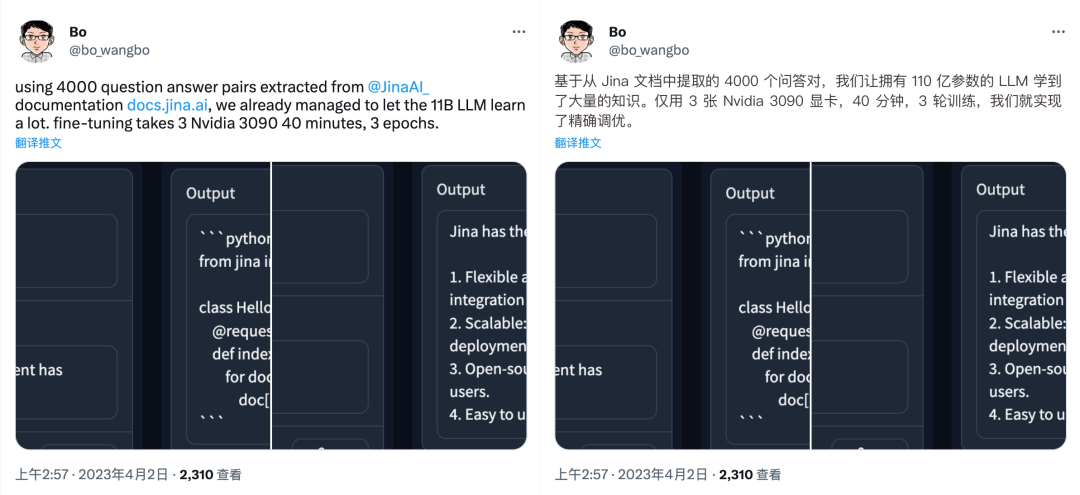
如图,我们进行了一项实验证明,基于 Jina 文档中提取的 4,000 个问答对,我们让拥有 110 亿参数的大型语言模型学习到了大量知识,仅用 3 张 Nvidia 3090 显卡,40 分钟,3 轮训练,我们就实现了精准微调。微调结果表明了大型语言模型在学习知识方面的出色表现,同时证明了我们的微调技术设计和执行的可靠性和有效性。


3. 高效参数微调
通过新增少量参数(近似一个小模型的参数量)并保持原有模型预训练参数不变,我们能有效调整模型以学习新任务,并大幅降低了训练计算和存储成本。同时,可插拔的 Adapter (适配器)能够为不同任务提供灵活性,同时保留大模型的原有能力。
4. 基于人类反馈的强化学习
通过结合强化学习技术,让模型根据人类反馈打分进行学习和调整。在训练过程中,人类评估者对模型生成的输出进行评分,模型根据这些评分调整参数以提高性能。让模型更好地适应特定任务和场景,并增强其与人类交互的能力,从而生成更高质量的结果。
5. 检索增强
基于检索增强的微调技术是一种结合外部知识库的大模型微调方法。它由检索组件和大型语言模型组成。它先从知识库中检索与问题相关的信息,然后将这些信息作为输入来生成回答。它能够适应新的信息,实现更准确、深入的回答,并且在需要特定知识的任务上表现得更好。除上述技术之外,我们还采用了很多针对于文本到图像生成模型的前沿微调技术,我们将针对客户的具体案例和需求,选择采用最合适的微调技术。
Finetuner+ 如何确保您的数据安全
近日,三星被曝光芯片机密代码遭 ChatGPT 泄露,引入不到 20 天就发生 3 起事故。都是由于内部软件工程师将公司的机密代码、会议内容等输入到 ChatGPT 中,导致公司机密信息泄露。之后三星采取行动,限制了员工对 ChatGPT 的 Prompt(提示词)输入长度。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

