
- 1数字支付中的5G技术:未来会有哪些新的变化_5g支付
- 22024年最新接口自动化测试:Postman实战教程_postman接口自动化,墙都不扶就服你
- 3AI视频风格转换动漫风:Stable Diffusion+TemporalKit_stable diffusion中temporalkit
- 4微信小程序读取NFC-MifareClassic1K卡-M1卡详解_微信小程序支持的nfc卡片有哪些
- 52024年最新远程控制软件
- 6联邦学习之路_跨设备联邦学习
- 7如何降低海康、大华等网络摄像头调用的高延迟问题(一):海康威视网络摄像头的python sdk使用(opencv读取sdk流)_python低延迟播放网络视频流
- 8Communication-Efficient On-Device Machine Learning: Federated Distillation and Augmentation 论文笔记_fedfa: federated learning with feature anchors to
- 9个人怎么做独立站Shopify商店!Shopify建站教程详解!(实操干货)_shopify独立站
- 10Java重点原理精炼(免费版)
牛客论坛项目总结
赞
踩
目录
10.redis的key怎么设计(怎样存储的点赞、关注、缓存用户数据)?
15 什么是ElasticSearch,存储原理,功能,特点
1.请简要介绍一下你的项目?
这个项目的整体结构来源于牛客网,主要使用了Springboot、Mybatis、MySQL、Redis、Kafka、等工具。主要实现了用户的注册、登录、发帖、点赞、系统通知、按热度排序、搜索等功能。另外引入了redis数据库来提升网站的整体性能,实现了用户凭证的存取、点赞关注的功能。基于 Kafka 实现了系统通知:当用户获得点赞、评论后得到通知。利用定时任务定期计算帖子的分数,并在页面上展现热帖排行榜。
1.如何实现项目的注册问题
 我们对每一个请求的开发都是由Dao——>sevice——controller层。在插入数据前,会对数据进行空值验证,对账号邮箱进行重复性验证,使用map来存储错误信息,如果controller层拿到的map为空就说明注册成功,进行后续的激活处理。在插入数据时,会对密码进行加盐处理后,在使用MD5算法进行加密,然后存储到数据库,最开始的数据Status设为0,表示无效,需要进行激活处理。
我们对每一个请求的开发都是由Dao——>sevice——controller层。在插入数据前,会对数据进行空值验证,对账号邮箱进行重复性验证,使用map来存储错误信息,如果controller层拿到的map为空就说明注册成功,进行后续的激活处理。在插入数据时,会对密码进行加盐处理后,在使用MD5算法进行加密,然后存储到数据库,最开始的数据Status设为0,表示无效,需要进行激活处理。
2.项目如何实现用户唯一性检验
在创建MySQL表时,使用unqiue关键字保证用户名username字段的唯一性。另外,在注册用户时进行重复性验证,如果已经用户已经存在,不能进行注册。
3.登录状态保存在哪
保存在用户凭证表,包括用户id,用户凭证,用户状态和过期时间,对于用户凭证表是0有效1无效。在登录时验证账号密码是否为空,或者密码是否错误等,如果没有错误就生成登录凭证。
4.用户登陆上之后怎么显示登录页面
用户在登录后会以ticket名称为key,以及实际的ticket为value创建一个cookie存入浏览器,之后服务端根据用户凭证在用户凭证表中查询user信息封装在模板中然后返回给浏览器。代码和流程如下图所示
这个过程是每一个用户登录都会存在的,所以我们需要拦截器来处理。同时对于服务端来说,同时可能会有大量的浏览器请求,所以这里还涉及到线程安全问题。
5.拦截器(Interceptor)
目的:让未登录用户不能访问某些页面
原理:在方法前标注自定义注解,拦截所有的请求,只处理带有该注解的方法。
拦截器:1.自定义拦截器 2.配置拦截器
首先验证用户(preHandle方法),如果用户存在,则在本次请求中持有用户,放进hostHolder里
经过controller后,返回到拦截器,拦截器再将用户信息存入model。
自定义拦截器需要实现HandlerInterceptor,然后重写preHandle(controller前执行),postHandle(controller后执行),以及afterCompletion(模板解析后执行)
配置拦截器:需要实现WebMvcConfigurer接口,然后重写addInterceptors方法,排除拦截静态页面。
6.ThreadLocal(线程安全)
从上面的代码可以看出,ThreadLocal set赋值的时候首先会获取当前线程thread,并获取thread线程中的ThreadLocalMap属性。如果map属性不为空,则直接更新value值,如果map为空,则实例化threadLocalMap,并将value值初始化
ThreadLocalMap是ThreadLocal的内部静态类,而它的构成主要是用Entry来保存数据 ,而且还是继承的弱引用。在Entry内部使用ThreadLocal作为key,使用我们设置的value作为value。
通过当前线程对象的getMap()方法获取ThreadMap对象 然后将当前ThreadLocal对象作为key值存入map 这能保证线程内的资源共享而不同线程之间独立
7.md5原理知道吗?安全吗?可逆吗?
可以将MD5算法看作一台机器,计算机的任何内容(字符串,图片,视频等)被丢进去都将输出一个长度为128比特的MD5值。
因此在我们这个项目中,会将用户密码进行加盐处理(密码末尾加随机的字符串)然后再进行MD5加密存入数据库。
MD5是否可逆:不可逆,原因是MD5是一种散列函数,使用的是hash算法,在计算过程中原文的部分信息是丢失了的。
8.项目哪块用到AOP了?(面向切面编程)
项目中统一处理日志时,用到了AOP。如果我们在每个业务组件中都记录日志,那么会产生非常多的重复代码。如果我们采用OOP的思想,将记录日志的功能封装成一个bean去调用,那么会产生耦合度高等问题。因为记录日志本身不属于业务需求,它属于系统需求,所以我们不应该将业务需求和系统需求耦合在一起,这个时候我们就需要用AOP来处理。AOP解决统一处理系统需求的方式是将代码定义到一个额外的bean,叫切面组件Aspect,这个组件在程序运行之前就需要被框架织入到某些连接点。切面组件的pointcut声明织入到哪个位置,通知Advice方法声明切面要处理什么样的逻辑。
9.项目中redis怎么用的
缓存点赞和关注:
1)、Redis缓存用户点赞数用String类型,以用户ID为key,点赞时,自增,取消赞时,自减;
缓存实体点赞数,set类型,用户给实体点赞时添加进列表,取消赞时则移除,最后用size统计;
2)、缓存粉丝列表,使用zset,存入粉丝的id和关注的时间戳,使用zCard获得粉丝数量。利用reverseRange的时间戳反向排序,按关注时间加载粉丝列表。
优化登录:
1)、使用Redis缓存用户信息。将user缓存到Redis中,获取user时,先从Redis获取。取不到时,则从数据库中查询,再缓存到Redis中。因为很多界面都要用到user信息,并发时,频繁的访问数据库,会导致数据库崩溃。变更数据库时,先更新数据库,再清空缓存;
2)、使用Redis缓存验证码 。原本添加到session中,减轻服务器压力。将验证码存到Redis中,方便查询检验;
-验证码需要频繁的访问与刷新,对性能要求很高;
-验证码不需要永久存储,通常在很短的时间内就会失效;
-分布式部署时,存在session共享问题;
3)、登录凭证:原本添加到MySQL中,为减轻每次登录都去查询数据库的压力,将登录凭证ticket缓存在Redis中,防止每次都要进行数据库的查询,提高并发能力。退出登录时,原本要修改数据库中的登录凭证,现在只需要修改Redis即可。
10.redis的key怎么设计(怎样存储的点赞、关注、缓存用户数据)?
redis的key是String类型的,编写了一个工具类来生成redis的key。key由多个单词拼接而成,中间采用冒号隔开,有的单词是固定的,有些单词是动态的。
点赞使用set类型存储,key为点赞对象,set中保存点赞人的ID
关注使用zSet类型存储,key为被关注者,set保存关注者以及关注时间为score
缓存用户数据使用Value类型,key为用userID得到的key,value为user对象(设置过期时间,且数据修改时需要清除缓存)
验证码是与user相关的,但是这里我们不能直接传入userId,因为还未登录,我们不知道用户是谁。这里传入了一个字符串owner,这是在用户访问登录页面的时候,给他发一个凭证(随机字符串),存到cookie里,用的时候从cookie内将这个owner取出来,在得到rediskey,然后获取验证码,与输入的验证码进行对比。
11.缓存点赞数如何实现
帖子和评论的赞一起存,统称为实体的赞。还需要统计用户的赞(用户的帖子和评论收到的赞的总和)。因为如果统计用户所有帖子和评论的赞得到用户获得的赞太麻烦,所以这里以用户ID采用rediskey工具拼接为key记录点赞数量(这就会涉及到事务操作。用户的帖子或者评论的点赞数增加了对应的用户的赞要增加)。
具体实现:使用redis来存储点赞数,首先需要构造redis的key,
点赞使用set类型存储,key为点赞对象,set中保存点赞人的ID
点赞的时候需要判断用户是否已经点赞:通过redistemplate.opsforSet().ismember方法 如果已经点过赞了就要把点赞记录删除 否则添加数据。 这里用到了事务操作 重写了execute方法
项目中的redis在存储用户信息时,是只读模式。
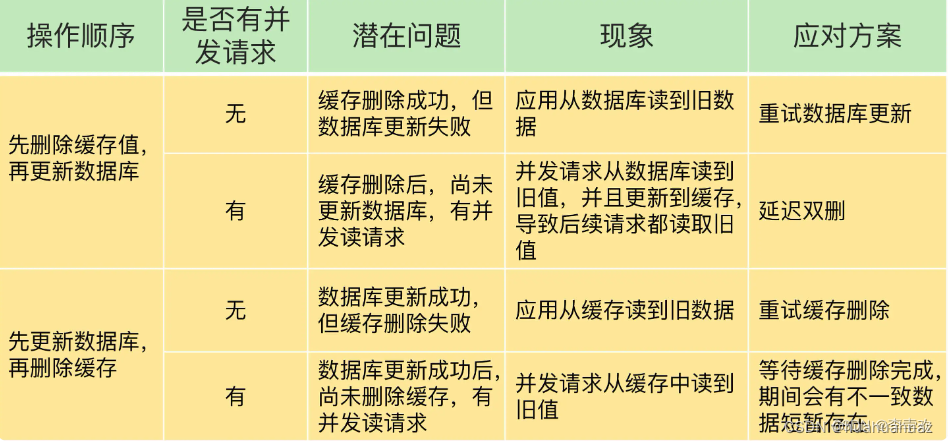
12.如何解决缓存和数据库的数据不一致问题?
缓存和数据库的数据不一致一般是由两个原因导致的,提供了相应的解决方案。
删除缓存值或更新数据库失败而导致数据不一致,可以使用重试机制确保删除或更新操作成功。
在删除缓存值、更新数据库的这两步操作中,有其他线程的并发读操作,导致其他线程读取到旧值,应对方案是延迟双删。
重试机制:具体来说,可以把要删除的缓存值或者是要更新的数据库值暂存到消息队列中。当应用没有能够成功地删除缓存值或者是更新数据库值时,可以从消息队列中重新读取这些值,然后再次进行删除或更新。如果能够成功地删除或更新,我们就要把这些值从消息队列中去除,以免重复操作,此时,我们也可以保证数据库和缓存的数据一致了。否则的话,我们还需要再次进行重试。如果重试超过的一定次数,还是没有成功,我们就需要向业务层发送报错信息了 。
延迟双删: 一般应用于先删除缓存,再更新数据库的多线程并发访问的情况。这是因为,先更新数据库值,再删除缓存值的情况下,如果线程 A 删除了数据库中的值,但还没来得及删除缓存值,线程 B 就开始读取数据了,那么此时,线程 B 查询缓存时,发现缓存命中,就会直接从缓存中读取旧值。不过,在这种情况下,如果其他线程并发读缓存的请求不多,那么,就不会有很多请求读取到旧值。而且,线程 A 一般也会很快删除缓存值,这样一来,其他线程再次读取时,就会发生缓存缺失,进而从数据库中读取最新值。所以,这种情况对业务的影响较小。
总结如图:
13 kafka消息模型和常见术语?
kafka入门
Apache Kafka是一个分布式流平台。一个分布式的流平台应该包含3点关键的能力:
·kafka特点
-高吞吐量:处理TB级的海量数据
-消息持久化:持久化,将数据存储到硬盘上,而不仅仅存储在内存中,长久保存消息,存到硬盘中的读取速度远远小于内存,读写硬盘的效率高低取决于读取硬盘的方式,硬盘的顺序读写的效率是很高的,kafka保证对硬盘消息的读写都是顺序的;
-高可靠性:kafka是分布式部署,一台服务器挂了,还有别的,有容错机制
-高拓展性:集群的服务器不够时,可以扩展服务器,只需简单的配置
·kafka术语
消息模型:发布-订阅模型,消费者订阅了某一主题(topic)后,生产者采用类似广播的方式,将消息通过主题传递给所有的订阅者。
Topic:主题,类似于文件夹,用来存放不同的数据。
Partition:主题分区,同一主题的不同分区可以存放在不同的Broker上面,保证并发能力和负载均衡。
Offset:消息在Partition中的存放位置。
Broker:可以理解为kafka集群里面的一台或多台服务器,它本身是没有复制的,上面可能运行着topic1的leader, topic2的follower等等。
14、项目哪里用到了kafka?
当有点赞,评论,关注请求时,会发送系统通知点赞,评论,关注的对象。在处理系统信息时,使用到了Kafka,具体来说,先定义了生产者类和消费者类,其中生产者被点赞/评论/关注功能对应的Controller使用,产生消息。而消费者负责消息(message)到来时,把消息存到数据库内。
14 消息队列放到内存还是磁盘?放磁盘为什么还这么快?
Kafka的消息是保存或缓存在磁盘上的,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间,但是实际上,Kafka的特性之一就是高吞吐率。
从数据写入和读取两方面分析,为什么Kafka速度这么快
写入数据:磁盘读写的快慢取决于你怎么使用它,也就是顺序读写或者随机读写。在顺序读写的情况下,磁盘的顺序读写速度和内存持平。因为硬盘是机械结构,每次读写都会寻址->写入,其中寻址是一个“机械动作”,它是最耗时的。所以硬盘最讨厌随机I/O,最喜欢顺序I/O。为了提高读写硬盘的速度,Kafka就是使用顺序I/O。
即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。所以Kafka的数据并不是实时的写入硬盘 ,它充分利用了现代操作系统分页存储来利用内存提高I/O效率。
读取数据:实现了零拷贝
15 什么是ElasticSearch,存储原理,功能,特点
概念:ES是一个基于lucene构建的,分布式的,RESTful的开源全文搜索引擎。
存储原理:数据按照Index – Type – Document – 字段四级存储,其中Index对应数据库,Type对应表,Document为搜索的原子单位,包含一个或多个容器,基于JSON表示。字段是指JSON中的每一项组成,类似于数据库中的行/列。Mapping是文档分析过滤后的结果,根据用户自定义,将某些文字过滤掉,类似于表结构定义DDL??。同时ES也和分布式数据库一样,支持shard的replication。
功能:
1、分布式的搜索引擎和数据分析引擎
2、全文检索,结构化检索,数据分析。
3、对海量数据进行近实时的处理
特点:
1、可以作为分布式集群处理PB级别的数据,也可单机使用。
2、不是特有技术,而是将分布式+全文搜索(lucene) + 数据分析合并在一起。
3、操作简单,作为传统数据库的补充,提供了数据库所不具备的很多功能。
16 项目中哪里使用到了ES,如何使用
在进行帖子搜索时,使用到了ES。可用Repository和Template两种方式,由于Repository搜索到的结果(直接返回的post类,方便)没有高亮标签(why),所以使用了template方式重写了mapResults函数,获得了带有高亮标签的post。
使用消息队列(kafka)的方式,实现发帖/删帖后ES数据库的自动更新。
搜索:定义SearchQuery,确定搜素内容,排序方式,高亮等。接着使用elasticTemplate.queryForPage方法,需要重写mapResults函数,得到高亮数据。
17 TrieTree前缀树介绍一下(敏感词过滤)
前缀树 是一种多叉树的树形数据结构,在项目中用于对敏感词进行过滤。
构造前缀树:第一层就存所有敏感词的第一个字符
前缀树特点是:1.根节点不包含任何信息 除了根节点的每个节点只包含一个字符,2.从根节点到某一个节点经过的路径,字符所连接的字符串就是这个节点所对应的字符串 3.每个节点的所有子节点包含的字符不同
过滤敏感词算法:
三个指针,一个指向树根(node),另两个指针(begin和position),都指向文本首,其中一个一直向后移动(begin),另一个跟着动,发现不是敏感词,就说明以begin开头的字符不可能组成敏感词,将其存入StringBuilder,begin后移,然后再返回至begin。若是敏感词,则替换,并另两个指针都后移,树指针指向根节点。
18.怎样统计网站UA和DAU
使用Redis的高级数据结构:
HyperLogLog:超级日志,统计独立整数个数。统计UA(独立访问)时,以日期为 rediskey ,将客户端IP add 到HyperLogLog中(redisTemplate.opsForHyperLogLog().add(redisKey, i);)
Bitmap:位图,比如365天的签到,只需要365/8个字节的大小。统计DAU(日活跃用户)时,以日期为 rediskey ,以用户ID作为位(在数据中的位置),用 or 操作,既可以方便的统计一段时间内的注册用户访问人数。

