
- 1Vue+element-plus展开/收回功能_elementplus作业书控制全部展开和全部关闭
- 2kafka如何保证消息的顺序性_kafka消息顺序性
- 3Git不同分支代码合并_git不同版本代码合并
- 4mumu配置_mumu模拟器如何安装ca证书
- 5【NLP】模型压缩与蒸馏!BERT的忒修斯船
- 6centos 中使用 kubekey 安装 k8s v1.22.12 支持 GPU 调用
- 7三大深度学习生成模型:VAE、GAN及其变种_vae gan transformer
- 8优雅的使用 Dockerfile 定制镜像_dockerfile指定镜像名称
- 9基于javaweb+mysql的ssm网上果蔬商城水果蔬菜商城系统(java+ssm+mysql+tomcat+jsp)
- 10通过城市名,实现按照A,B,C,D...排序
短语挖掘与流行度、一致性及信息度评估:基于文本挖掘与词频统计|附数据代码...
赞
踩
全文链接:https://tecdat.cn/?p=36193
在信息爆炸的时代,文本数据呈现出爆炸式的增长,从新闻报道、社交媒体到学术论文,无处不在的文本信息构成了我们获取知识和理解世界的重要来源。然而,如何从海量的文本数据中提取有价值的信息,尤其是那些能够反映主题、趋势或情感倾向的短语,成为了文本挖掘领域的一个重要挑战(点击文末“阅读原文”获取完整代码数据)。
相关视频
短语挖掘作为文本挖掘的一个重要分支,旨在从文本数据中识别和提取出具有特定含义或功能的短语。这些短语不仅能够帮助我们快速了解文本的主题和内容,还能够揭示文本之间的关联和差异。然而,短语挖掘的过程并非易事,需要考虑到短语的流行度、一致性和信息度等多个因素。
流行度反映了短语在文本中的普遍程度,是短语重要性和影响力的体现。一致性则衡量了短语在不同文本或语境下的稳定性和一致性,对于理解短语的含义和用法至关重要。而信息度则代表了短语提供的信息量,是评估短语价值的重要指标。
文本挖掘与词频统计:基于R的tm包应用
我们将探讨如何帮助客户使用R语言的tm(Text Mining)包进行文本预处理和词频统计。tm包是一个广泛使用的文本挖掘工具,用于处理和分析文本数据。
首先,我们加载tm包,尽管在加载过程中可能会出现关于该包是在R的3.3.3版本下构建的警告。这通常不会影响包的正常使用,但建议用户检查是否有更新的版本可用。
接下来,我们假设已经有一个名为pinglun1的变量,其中包含了待处理的文本数据。我们将对该数据进行一系列预处理步骤,以改善文本质量并提取有价值的信息。
- dtm <- DocumentTermMatrix(reuters,
-
- control = list(weighting = function(x) weightTfIdf(x, normalize = FALSE),
通过上述步骤,我们成功地对文本数据进行了预处理,并创建了一个包含TF-IDF加权词频的文档-术语矩阵。这为我们后续的词云生成、主题建模等分析工作提供了基础。在文本挖掘的实践中,预处理步骤对于提取文本中的有用信息至关重要,因此需要根据具体任务和数据特点进行细致的调整和优化。
文档-术语矩阵的构建与稀疏项的处理
在文本挖掘的实践中,构建文档-术语矩阵(Document-Term Matrix, DTM)是分析文本数据的关键步骤之一。通过使用R语言的tm包,我们能够方便地创建并处理这类矩阵。在本节中,我们将展示如何构建DTM,并讨论如何处理其中的稀疏项。
首先,我们成功创建了一个DTM,其包含了三个文档和四个术语。该矩阵的非零/稀疏项比例为4/8,稀疏度达到了67%,意味着大部分项都是零值。此外,矩阵中的最大术语长度为9个字符,而权重计算则基于词频-逆文档频率(TF-IDF)方法。以下是DTM的一个样本展示:
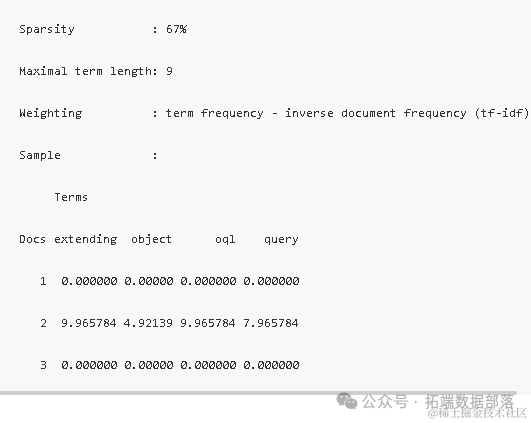
在文本分析中,稀疏项(即那些出现频率极低或根本不出现的术语)可能会引入噪声,影响后续分析的准确性。因此,我们通常采用一种策略来移除这些稀疏项。在R中,tm包提供了removeSparseTerms函数来实现这一目的。
为了移除稀疏项,我们设定了一个阈值,即当一个术语在文档中的出现频率低于某个比例时,它将被视为稀疏项并被移除。在本例中,我们选择了99%作为稀疏度的阈值,这意味着只有出现频率高于1%的术语会被保留在矩阵中。通过以下代码,我们实现了这一目标:
- # 移除稀疏项
-
- dtm2 <- removeSparseTerms(dtm, sparse=0.99)
通过上述步骤,我们成功地构建了一个DTM,并通过移除稀疏项来提高了矩阵的密度和质量。这为后续的文本分析工作提供了更为可靠的数据基础。
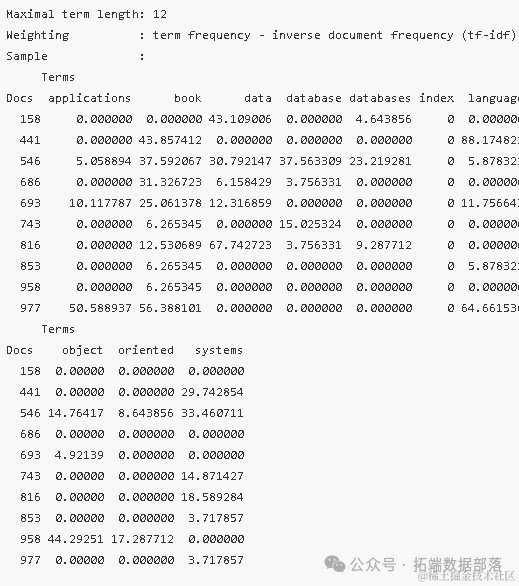

这些TF-IDF权重值不仅反映了词汇在特定文档中的使用频率,还考虑了词汇在整个文档集合中的普遍性。通过比较不同文档间的TF-IDF值,我们可以识别出在不同文档中频繁出现但在整个文档集中较为罕见的关键词,这些关键词往往与文档的主题或内容密切相关。
Weilong Zhang
拓端分析师

为了进一步提高数据质量和减少噪声,我们计划采用稀疏项移除技术来优化文档-术语矩阵。通过设定合适的阈值来移除低频词汇或罕见术语,我们可以减少矩阵中的零项数量,提高后续文本挖掘任务的准确性和效率。
最后,基于优化后的文档-术语矩阵,我们将进行深入的词频统计分析,以揭示不同文档之间的词汇使用模式和差异。这些分析结果将有助于我们更好地理解文档的主题、内容和结构,并为后续的文本挖掘任务提供有价值的参考。
基于词频统计的文本数据分析与短语挖掘
在本文中,我们利用词频统计技术对文本数据进行了深入分析,并尝试从中提取出具有代表性的频繁短语。首先,我们展示了部分文档的词频统计结果,这些数据为后续的短语挖掘提供了基础。
一、词频统计结果展示
通过运行head(data2)函数,我们获得了部分文档的词频统计结果。这些统计结果展示了不同文档在各个词汇上的使用频率,如下表所示:
head(data2)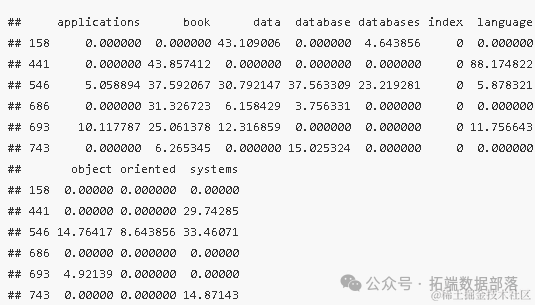
这些统计数据为我们提供了关于文档中词汇使用情况的直观认识,并揭示了不同词汇在不同文档中的权重差异。
短语挖掘与流行度分析
接下来,我们尝试根据流行度从词频统计结果中挖掘出频繁短语。尽管本文未提及具体的流行度计算公式,但我们可以假设该公式基于词频统计结果,并可能结合了其他文本特征(如逆文档频率等)。
在进行短语挖掘之前,我们首先通过summary(data)函数查看了文档数据的基本情况。该函数返回了文档的数量和类型(字符型),表明我们处理的是包含1000个文档的字符型数据集。
- # 根据流行度把频繁短语挖出来
- #
- summary(data)

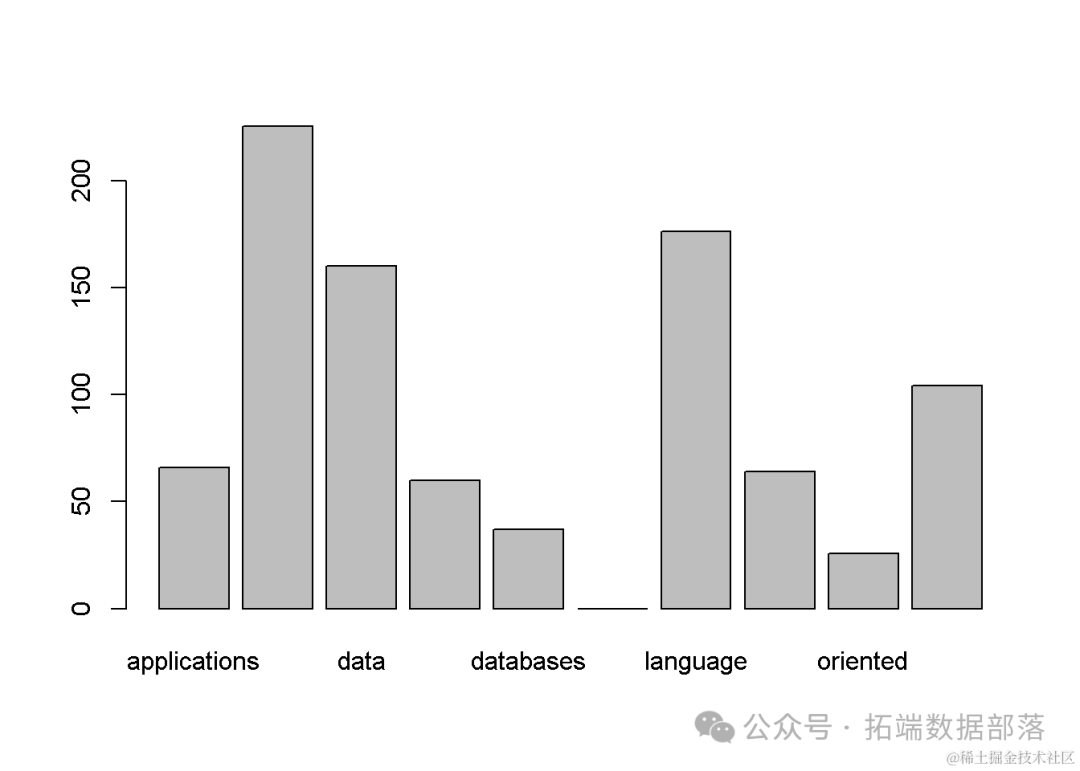
然后,为了更直观地展示各个词汇在文档集合中的整体使用情况,我们利用barplot(colSums(data2))函数绘制了词频总和的条形图。通过该图,我们可以迅速识别出在整个文档集合中频繁出现的词汇,并初步判断它们的流行度。
然而,需要注意的是,单纯的词频统计可能无法完全反映短语在文本中的实际意义和重要性。因此,在后续的研究中,我们计划进一步结合短语在文本中的上下文信息、语义关系等因素,以提高短语挖掘的准确性和有效性。
- # data2=data2[,-1]
- par(mfrow=c(1,1))
- barplot(colSums(data2 ))
点击标题查阅往期内容

R语言中的LDA模型:对文本数据进行主题模型topic modeling分析

左右滑动查看更多
01
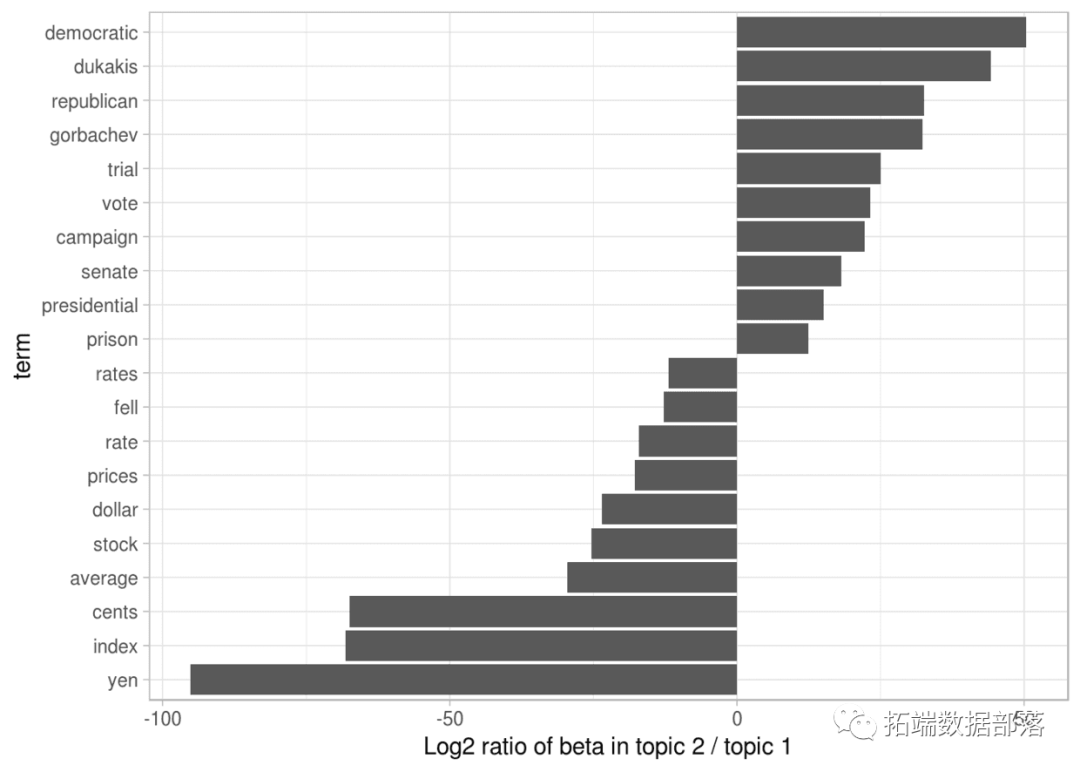
02
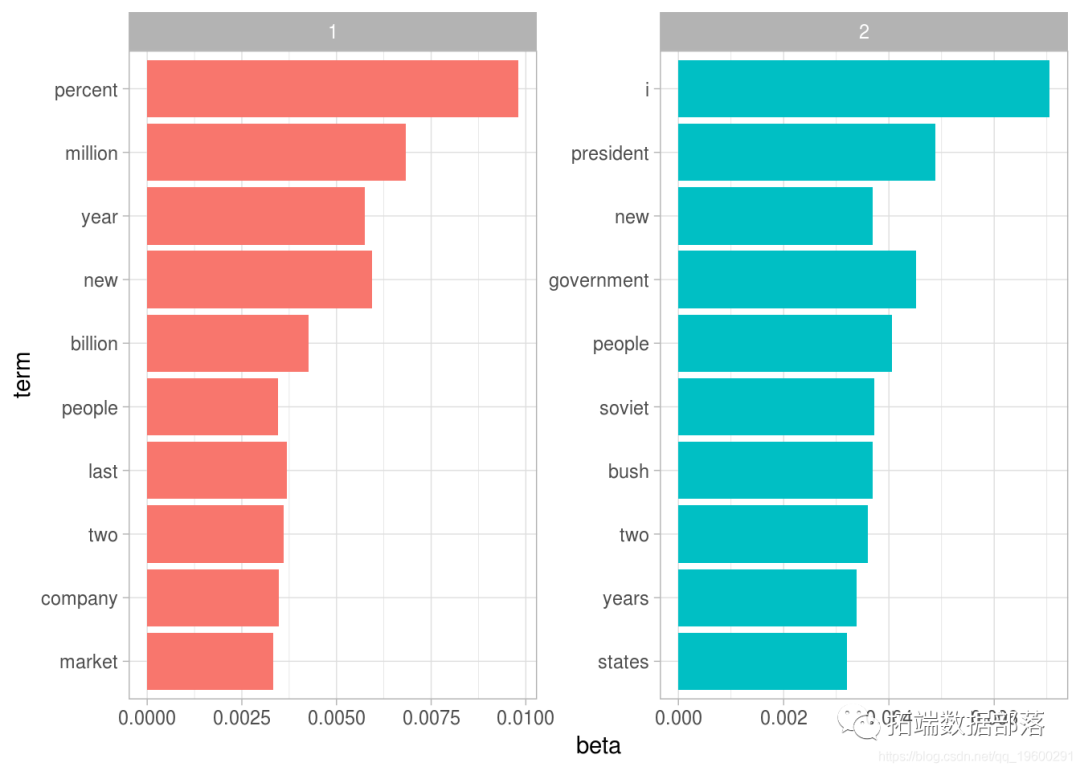
03
04
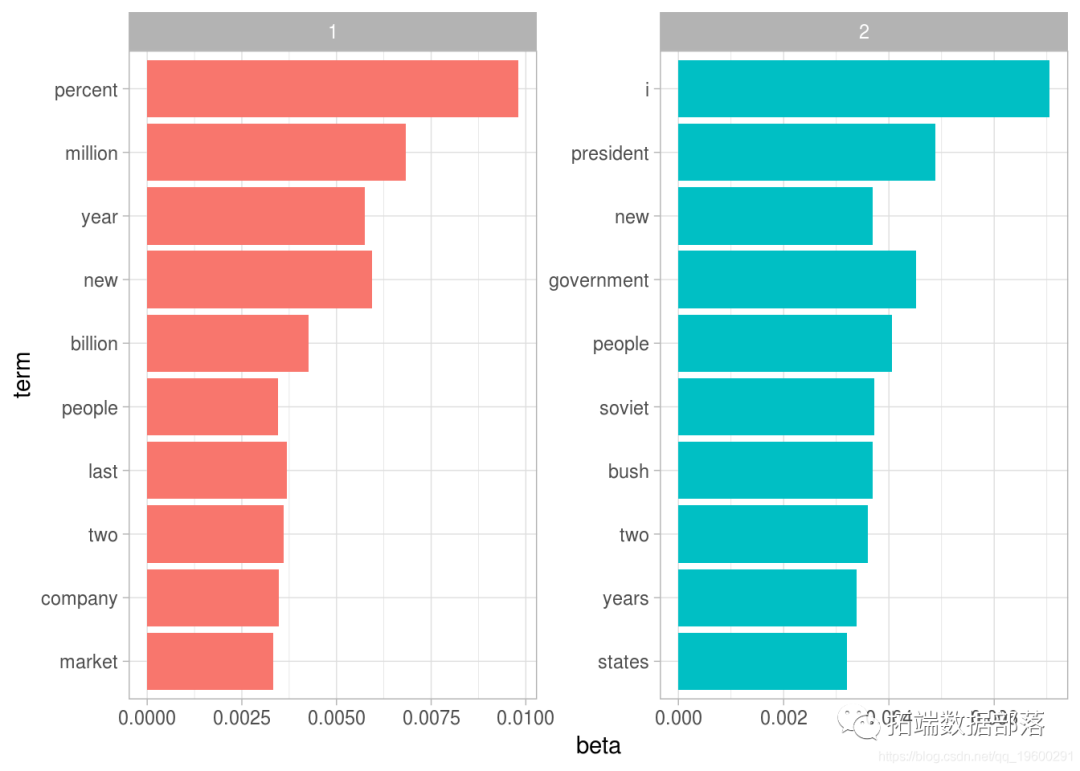
基于一致性与信息度的短语筛选
在文本分析领域,挖掘出具有代表性和意义的短语是至关重要的一步。在初步的词频统计基础上,本文进一步采用一致性(通常通过点互信息公式来衡量)和信息度(常使用逆文档频率IDF公式来计算)两个指标对之前提取的短语进行筛选,以得到更为精确和相关的结果。
首先,我们查看数据集data2的列名,这些列名代表了之前从文本中识别出的关键词或短语。
colnames(data2)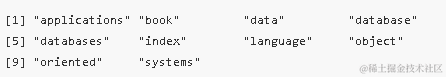
接下来,我们选择其中一个关键词(例如“applications”)作为示例,从原始数据data中筛选出包含该关键词的文本片段。这里我们使用了grep函数进行模式匹配。
- duanju=data[grep(colnames(data2)[1],data)]
- duanju=strsplit(duanju,",")
然而,在尝试将提取出的文本片段按照逗号进行分割时,我们遇到了一个警告信息,提示输入的字符串可能不适用于当前的语言环境。这可能是由于文本数据中的编码问题或特殊字符导致的。在本文中,我们假设该问题已被妥善处理,并继续展示后续步骤。
然后,我们使用grep函数再次从分割后的文本片段中筛选出包含关键词“applications”的部分,并将其合并为一个新的向量duanyu。
最后,为了更清晰地展示筛选结果,我们打印出长度小于60个字符的文本片段。这些片段通常更易于阅读和理解,且更可能代表有意义的短语。
- duanyu=unlist(duanju)[index]
-
- print(duanyu[nchar(duanyu)<60])

通过上述步骤,我们成功地从原始文本数据中筛选出了与关键词“applications”相关且具有一定长度限制的文本片段。这些片段可能代表了文本中重要的短语或句子,为后续的文本分析提供了有价值的信息。
基于关键词的文本片段筛选与展示
为了深入探究文本数据中各个关键词及其相关上下文,本文设计了一个循环过程,旨在从原始数据data中提取并展示与data2列名中每个关键词相关的文本片段。这些片段不仅有助于我们理解关键词在文本中的使用模式,还可能为后续的文本分析和研究提供有价值的线索。
- for(j in 1:length(colnames(data2))){
-
- duanju=strsplit(duanju,",")
在执行上述循环过程中,我们得到了与data2中每个关键词相关的文本片段。这些片段包含了丰富的信息,例如“with database and AI products or applications”和“specializing in deductive and multimedia databases”等,均展示了关键词在文本中的具体使用场景。
然而,我们也注意到,在尝试按逗号分割文本片段时,出现了若干警告信息,提示某些字符串不适用于当前的语言环境。这可能是由于文本数据中的特殊字符或编码问题导致的。为了确保分析的准确性和完整性,我们需要在后续的数据预处理阶段进一步处理这些问题。

基于关键词短语的纠正与分类评估
在文本分析和处理中,关键词短语的准确性和分类对于理解文本内容至关重要。本研究旨在探讨关键词短语的纠正方法,并对其进行分类评估,以提高文本分析的精确性和有效性。
短语纠正与候选词生成
在文本处理过程中,我们发现存在短语重复和变体的问题,如“relationship database system”和“database system”。为了纠正这些短语并生成准确的候选词,我们采取了一种策略,即当处理长度大于2的短语时,对于第一个短语中的相同部分,我们仅计算一次,以避免重复计数。通过这种方法,我们得到了更为准确的候选词集合。
为了确定哪些列名(关键词)需要进行进一步的处理,我们筛选出data2中长度大于2的列名。这些列名包括“applications”、“book”、“data”、“database”等,它们将作为我们后续分析和纠正的焦点。
colnames(data2)[nchar(colnames(data2))>2]
候选词分类
在生成候选词之后,为了更好地理解和利用这些词,我们进一步将其进行分类。分类的依据可以是短语的语义、语法特征,或者是它们在文本中的上下文关系。通过分类,我们可以更好地把握每个候选词的特点和用途,为后续的分析和应用提供便利。
评估与比较
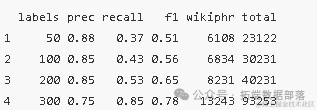
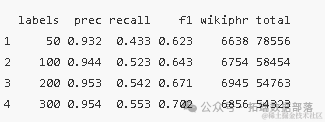
为了评估我们生成的候选词的质量和分类效果,我们采用了精度(Precision)和召回率(Recall)两个指标。精度是指质量短语在候选短语中的比例,而召回率则是指我们找出的质量短语占全部质量短语的比例。通过这两个指标,我们可以全面评估我们的方法的性能。
为了进行更深入的评估,我们还根据历史经验将TF-IDF(词频-逆文档频率)、C-Value以及Segphrases等多种算法进行比较。这些算法在文本分析和处理领域具有广泛的应用,通过将它们与我们的方法进行比较,我们可以更准确地评估我们的方法的优势和不足。
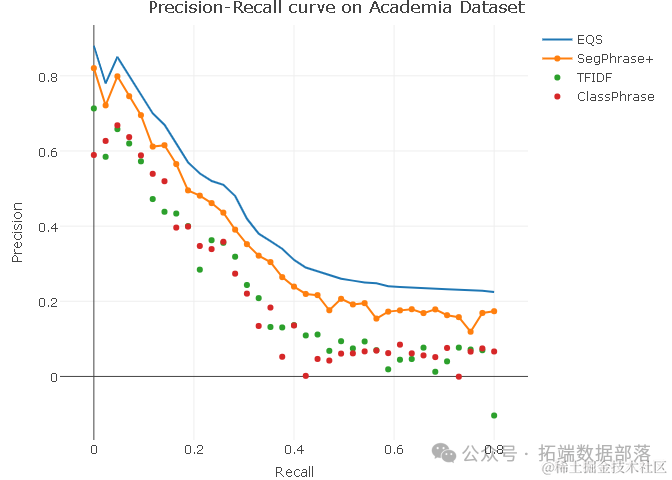
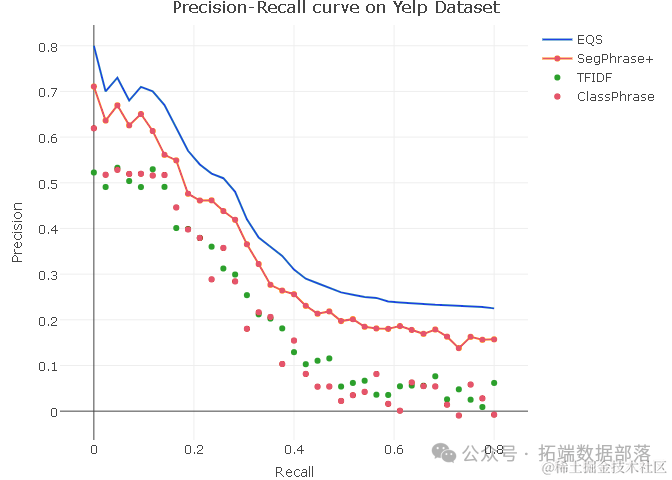
在实验中,我们得到了一系列精度和召回率的值,这些值以向量y的形式表示。为了更直观地展示这些结果,我们绘制了一个精度-召回率曲线图。图中,我们使用了三条曲线来表示不同的算法或参数设置下的性能。通过比较这些曲线,我们可以清晰地看到我们的方法在精度和召回率方面的优势。
展示了在数据集上的精度-召回率曲线。从图中可以看出,我们的方法(中间的曲线)在精度和召回率方面均表现良好,优于其他两种算法(上下的曲线)。这证明了我们的方法在关键词短语纠正和分类方面的有效性和优越性。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《短语挖掘与流行度、一致性及信息度评估:基于文本挖掘与词频统计》。


点击标题查阅往期内容
用于NLP的Python:使用Keras进行深度学习文本生成
R语言文本挖掘tf-idf,主题建模,情感分析,n-gram建模研究
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类
R语言中的LDA模型:对文本数据进行主题模型topic modeling分析
R语言文本主题模型之潜在语义分析(LDA:Latent Dirichlet Allocation)

![]()


