
- 1git拉取项目代码显示不是maven项目_git拉下来的项目没有变成maven项目
- 2目标人脸检测与识别(计算机视觉)
- 3数据结构与算法——希尔排序_本关要求实现希尔排序的功能。相关知识希尔排序基本思想:将整个无序序列分割
- 4三流安全工程师的渗透测试记录,网络安全系列学习进阶视频
- 5c盘中temp可以删除吗?appdata\local\temp可以删除吗?_appdata local temp
- 6【SQL管理】-Flyway数据库版本管理利器从入门到入味_flyway checksum
- 7ORACLE12C 问题 - 远程访问显示 ORA-12541:TNS:无监听程序_oracle12c客户端没有监听程序
- 8【滑动、点选等交互验证和人机识别对抗升级?下一代验证方式能保证用户体验吗?】
- 9MySQL GIS 空间数据库功能详解学习_mysql空间数据库
- 10Spark高可用集群搭建_spark 高可用
Python 库 lxml 通过 xpath、CSS 解析 HTML / XML、scrapy 内置 ( xpath、re、css )、LinkExtractor_driver获取父节点的属性
赞
踩
python使用xpath(超详细):https://www.cnblogs.com/mxjhaima/p/13775844.html
W3school Xpath 教程:https://www.w3school.com.cn/xpath/index.asp
简书:Xpath高级用法:https://www.jianshu.com/p/1575db75670f
XPath 是 XML 的路径语言,主要查找 XML(标准通用标记语言的子集)文档中某部分位置。
XPath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。 XPath 同样也支持HTML。
XPath 是一门小型的查询语言。python 中 lxml库 使用的是 Xpath 语法,是效率比较高的解析方法。lxml 用法源自 lxml python 官方文档:http://lxml.de/index.html
1、Python 使用 XPath
etree 会修复 HTML 文本节点
使用步骤
step1:安装 lxml 库 :pip3 install lxml
step2:from lxml import etree #etree全称:ElementTree 元素树
step3:selector = etree.HTML(网页源代码)
step4:selector.xpath(一段神奇的符号)
lxml 提供如下方式输入文本:
- fromstring():解析字符串
- HTML():解析HTML对象
- XML():解析XML对象
- parse():解析文件类型对象
- from lxml import etree
-
- root_node = etree.XML('<root><a><b/></a></root>')
- print(etree.tostring(root_node))
- print(etree.tostring(root_node, xml_declaration=True))
- print(etree.tostring(root_node, xml_declaration=True, encoding='utf-8'))
示例:处理非标准的 html
lxml 自动修复标签属性两侧缺失的引号,并闭合标签。
- import lxml.html
-
- test_html = "<ul class=country> <li>Area <li id=aa>Population</ul>"
- tree = lxml.html.fromstring(test_html)
- print(f'type(tree) ---> {type(tree)}')
- # pretty_print: 优化输出,输出换行符
- # fixed_html = lxml.html.tostring(tree, pretty_print=True)
- fixed_html = lxml.html.tostring(tree) # 转换为字节
- print(f'type(fixed_html) ---> {type(fixed_html)}')
- print(fixed_html)
示例:lxml 使用 Xpath:
Xpath 菜鸟教程:http://www.runoob.com/xpath/xpath-tutorial.html
- import re
- import requests
- import lxml.html
- from lxml import etree
- from pprint import pprint
-
-
- def func_1():
- html = '''
- <div id="content">
- <ul id="useful">
- <li>有效信息1</li>
- <li>有效信息2</li>
- <li>有效信息3</li>
- </ul>
- <ul id="useless">
- <li>无效信息1</li>
- <li>无效信息2</li>
- <li>无效信息3</li>
- </ul>
- </div>
- <div id="url">
- <a href="http://cighao.com">陈浩的博客</a>
- <a href="http://cighao.com.photo" title="陈浩的相册">点我打开</a>
- </div>
- '''
- selector = etree.HTML(html)
-
- # 提取 li 中的有效信息123
- content = selector.xpath('//ul[@id="useful"]/li/text()')
- for each in content:
- print(each)
-
- # 提取 a 中的属性
- link = selector.xpath('//a/@href')
- for each in link:
- print(each)
-
- title = selector.xpath('//a/@title')
- for each in title:
- print(each)
-
-
- if __name__ == '__main__':
- func_1()
- func_2()
-

示例:lxml 使用 CSS
CSS 选择器:https://www.runoob.com/cssref/css-selectors.html
- import lxml.html
- import requests
- from fake_useragent import UserAgent
-
- ua = UserAgent()
- header = {
- "User-Agent": ua.random
- }
- html = requests.get("http://www.baidu.com/", headers=header)
- html = html.content.decode("utf8")
- print(html)
- tree = lxml.html.fromstring(html)
- mnav = tree.cssselect('div#head .mnav')
-
- # 输出文本内容
- # area = td.text_content()
- for i in mnav:
- print(i.text)
示例:lxml 读取 文件
from lxml import etree
# 指定解析器HTMLParser会根据文件修复HTML文件中缺失的如声明信息
html = etree.parse('test.html', etree.HTMLParser())
result = etree.tostring(html) # 解析成字节
result_list = etree.tostringlist(html) # 解析成列表
- from lxml import etree
-
- s_html = etree.parse('hello.html')
- print(type(s_html))
- result = s_html.xpath('//li')
- print(result)
- print(len(result))
- print(type(result))
- print(type(result[0]))
- # 解释:etree.parse 的类型是 ElementTree,通过调用 xpath 以后,
- # 得到了一个列表,包含了 5 个 <li> 元素,每个元素都是 Element 类型
所有文本
#方法1:过滤标签,返回全部文本: s_html.xpath('string()')
#方法2:以标签为间隔,返回 list:s_html.xpath('//text()')
使用第三方包 cssselect
安装 cssselect:pip install cssselect
选择所有标签 :*
选择<a>标签:a
选择所有 class="link"的元素: .link
选择class="link" 的 <a>标签: a.link
选择 id= "home" 的 <a>标签: a#home
选择父元素为 <a>标签的所有 <span>子标签: a > span
选择<a>标签内部的所有 <span>标签: a span
选择 title 属性为 "Home" 的所有<a>标签: a[title=Home]
scrapy 内置的 xpath、css、re
:https://www.cnblogs.com/regit/p/9629263.html
- import scrapy
-
-
- class JobboleSpider(scrapy.Spider):
- name = 'jobbole'
- allowed_domains = ['blog.jobbole.com']
- start_urls = ['http://blog.jobbole.com/']
-
- def parse(self, response):
- re_selector = response.xpath('//*[@id="post-110287"]/div[1]/h1/text()')
几个 CSS 选择器
response.css(".entry-header h1").extract()
response.css(".entry-header h1::text").extract()[0]response.css("p.entry-meta-hide-on-mobile::text").extract()[0].strip().replace(" ·","")
response.css(".vote-post-up h10::text").extract()[0]
response.css(".bookmark-btn::text").re('.*?(\d+).*')
response.css(".bookmark-btn::text").re('.*?(\d+).*')[0]
正则 ( re、re_first )
scrapy 的 response 对象不能直接调用 re 和 re_first 方法。可以先调用 xpath或者css方法,再使用正则进行匹配
response.css(".bookmark-btn::text").re('.*?(\d+).*')[0]
response.xpath('.').re_first('正则表达式')
直接 使用 Selector
Selector 不一定非要在 Scrapy 中使用,也可以独立使用。使用 Selector 这个类来构建一个选择器对象,然后调用它的相关方法(如xpath css等)来提取数据。
示例:构建 Selector 对象来提取数据:
- from scrapy import Selector
-
- body = '<html><head><title>hello world</title></head></html>'
- selector = Selector(text=body)
- title = selector.xpath('//title/text()').extract_first()
- print(title)
普通的请求变成 scrapy 的 response
scrapy 的 response 有一个属性 selector,调用 response.selector 返回的内容就相当于用 response 的 text 构造了一个 Selectr 对象。通过这个 Selector 对象就可以调用 xpath、css 等解析方法提取数据。
Scrapy 提供了两个实用的快捷方法:response.xpath 和 response.css,二者的功能完全等同于 response.selector.xpath 和 response.selector.css。为了省事可以统一直接调用 response.xpath 和 response.css
TextResponse:向基类 Response 添加编码能力 ,这意味着仅用于二进制数据,例如图像,声音或任何媒体文件。
- encoding(string) - 是一个字符串,包含用于此响应的编码。如果你创建一个TextResponse具有unicode主体的对象,它将使用这个编码进行编码(记住body属性总是一个字符串)。如果encoding是None(默认值),则将在响应标头和正文中查找编码。 TextResponse除了标准对象之外,对象还支持以下属性Response
- text - 响应体,如unicode。
- body_as_unicode() - 同样text,但可用作方法。保留此方法以实现向后兼容; 请喜欢response.text
其他的 xxxRespose 都最终继承 Respose,可以通过查看源码了解对应 xxxResponse的使用。
- import requests
- from scrapy.http import HtmlResponse
-
-
- def func_1():
- url = 'https://www.gushiwen.cn/'
- resp = requests.get(url)
- resp.encoding = 'utf-8'
- response = HtmlResponse(url=resp.url, body=resp.text, encoding=resp.encoding)
-
- tag_a_list = response.xpath('//div[@class="right"]//div[@class="sons"]//a')
- list(map(lambda x=None: print(x), tag_a_list.extract()))
-
- for tag_a in tag_a_list:
- text = tag_a.xpath("./text()").extract_first()
- href = tag_a.xpath("./@href").extract_first()
- print(f'{text} ---> {href}')
-
- tag_a_list = response.css('div[class="right"] div[class="sons"] a')
- list(map(lambda x=None: print(x), tag_a_list.extract()))
- # print(response.css('').re())
-
-
- if __name__ == '__main__':
- func_1()
LinkExtractor 提取链接
Link Extractors 文档
- :http://doc.scrapy.org/en/latest/topics/link-extractors.html
- :https://www.osgeo.cn/scrapy/topics/link-extractors.html
链接提取器( Link Extractors ) 的目的就是从 scrapy.http.Response 中提取链接。
导入包:scrapy.linkextractors import LinkExtractor
类定义:class scrapy.linkextractors.lxmlhtml.LxmlLinkExtractor(allow=(), deny=(), allow_domains=(), deny_domains=(), deny_extensions=None, restrict_xpaths=(), restrict_css=(), tags=('a', 'area'), attrs=('href',), canonicalize=False, unique=True, process_value=None, strip=True)
参数 解释:
- allow (str or list): 一个正则表达式(或正则表达式列表),(绝对)urls 必须匹配才能提取。如果没有给出(或为空),它将匹配所有链接。
- deny (str or list): 一个正则表达式(或正则表达式列表),(绝对)urls 必须匹配才能排除(即不提取)。它优先于 allow 参数。如果没有给出(或为空),它不会排除任何链接。,可以 和 allow 配合一起用,前后夹击,参数和 allow 一样。
- allow_domains (str or list):允许 的 域名 或者 域名列表。即 会被提取的链接的 domains。其实这个和 spider 类里的 allowdomains 是一个作用,即 抓取哪个域名下的网站。
- deny_domains (str or list):拒绝 的 域名 或者 域名列表。即 不会被提取链接的 domains。和 allowdomains 相反,即 拒绝哪个域名下的网站。
- deny_extensions( list ):包含在提取链接时应该忽略的扩展的单个值或字符串列表。即不允许的扩展名。如果没有给出(默认 是 None),它将默认为 IGNORED_EXTENSIONS 在 scrapy.linkextractors 包中定义的 列表 。(参考: http://www.xuebuyuan.com/296698.html)
- restrict_xpaths (str or list):一个XPath(或XPath的列表),它定义了从Response哪些区域中来提取链接。即 在网页哪个区域里提取链接,可以用 xpath 表达式和 css 表达式这个功能是划定提取链接的位置,让提取更加精准。如果给出,只有那些XPath选择的文本将被扫描链接。参见下面的例子。即 使用 xpath表达式,和allow共同作用过滤链接。
- restrict_css (str or list):一个CSS选择器(或选择器列表),用于定义响应中应提取链接的区域。同 restrict_xpaths。
- tags( str 或 list ):提取链接时要考虑的 标签或标签列表。默认为('a', 'area')。即 默认提取a标签和area标签中的链接
- attrs( list ):在查找要提取的链接时应该考虑的属性或属性列表(仅适用于参数中指定的那些标签tags )。默认为('href',)。即 默认提取 tags 里的 href 属性,也就是 url 链接。
- canonicalize( boolean ):规范化每个提取的 url ( 使用w3lib.url.canonicalize_url)。默认为False。注意,canonicalize_url用于重复检查;它可以更改服务器端可见的URL,因此对于具有规范化URL和原始URL的请求,响应可能不同。如果使用LinkExtractor跟踪链接,则保持默认的canonicalize=False更为可靠。
- unique( boolean ):是否对提取的链接进行过滤。即 这个地址是否要唯一,默认true,重复收集相同的地址没有意义。
- process_value ( callable ) – 它接收来自扫描标签和属性提取每个值,可以修改该值,并返回一个新的,或返回 None 完全忽略链接的功能。如果没有给出,process_value 默认是 lambda x: x。其实就是:接受一个函数,可以立即对提取到的地址做加工,这个作用比较强大。比如,提取用 js 写的链接:
例如,从这段代码中提取链接: <a href="javascript:goToPage('../other/page.html'); return false">Link text</a>你可以使用下面的这个
process_value函数:
- strip :把 提取 的 地址 前后多余的空格删除,很有必要。whether to strip whitespaces from extracted attributes. According to HTML5 standard, leading and trailing whitespaces must be stripped from
hrefattributes of<a>,<area>and many other elements,srcattribute of<img>,<iframe>elements, etc., so LinkExtractor strips space chars by default. Setstrip=Falseto turn it off (e.g. if you’re extracting urls from elements or attributes which allow leading/trailing whitespaces).
示例:
- import requests
- from scrapy.http import HtmlResponse
- from scrapy.linkextractors import LinkExtractor
-
-
- def main():
- __resp = requests.get('https://so.gushiwen.cn/shiwens/')
- if 200 == __resp.status_code:
- resp = HtmlResponse(url=__resp.url, body=__resp.text, encoding=__resp.encoding)
- """
- LinkExtractor 初始化函数 __init__ 的参数
- def __init__(
- self,
- allow=(),
- deny=(),
- allow_domains=(),
- deny_domains=(),
- restrict_xpaths=(),
- tags=("a", "area"),
- attrs=("href",),
- canonicalize=False,
- unique=True,
- process_value=None,
- deny_extensions=None,
- restrict_css=(),
- strip=True,
- restrict_text=None,
- ):
- """
- le = LinkExtractor(
- restrict_xpaths=('//div[@id="right1"]', '//div[@id="right3"]')
- )
- links = le.extract_links(resp)
- list(map(lambda x=None: print(x), links))
- list(map(lambda x=None: print(f'{x.text.strip()} ---> {x.url}'), links))
- pass
-
-
- if __name__ == '__main__':
- main()
- pass
scrapy 的常用 ImagesPipeline 重写实现:https://www.jianshu.com/p/cd05763d49e8
使用 Scrapy 自带的 ImagesPipeline下载图片,并对其进行分类:https://www.cnblogs.com/Kctrina/p/9523553.html
使用 FilesPipeline 和 ImagesPipeline:https://www.jianshu.com/p/a412c0277f8a
Rule 和 Link Extractors 多用于全站的爬取
爬取规则(Crawling rules):http://doc.scrapy.org/en/latest/topics/spiders.html#crawling-rules
Rule 是在定义抽取链接的规则:class scrapy.contrib.spiders.Rule(link_extractor,callback=None,cb_kwargs=None,follow=None,process_links=None,process_request=None)
参数解释:
- link_extractor:是一个 Link Extractor 对象。其定义了如何从爬取到的 页面(即 response) 提取链接的方式。
- callback:是一个 callable 或 string(该Spider中同名的函数将会被调用)。从 link_extractor 中每获取到链接时将会调用该函数。该回调函数接收一个 response 作为其第一个参数,并返回一个包含 Item 以及 Request 对象(或者这两者的子类)的列表。
- cb_kwargs:包含传递给回调函数的参数(keyword argument)的字典。
- follow:是一个 boolean 值,指定了根据该规则从 response 提取的链接 是否 需要跟进。如果 callback 为 None,follow 默认设置 True,否则默认 False。当 follow 为 True 时:爬虫会从获取的 response 中 取出符合规则的 url,再次进行爬取,如果这次爬取的 response 中还存在符合规则的 url,则再次爬取,无限循环,直到不存在符合规则的 url。 当 follow 为 False 时:爬虫只从 start_urls 的 response 中取出符合规则的 url,并请求。
- process_links:是一个callable或string(该Spider中同名的函数将会被调用)。从link_extrator中获取到链接列表时将会调用该函数。该方法主要是用来过滤。
- process_request:是一个callable或string(该spider中同名的函数都将会被调用)。该规则提取到的每个request时都会调用该函数。该函数必须返回一个request或者None。用来过滤request。
官网示例:
- import scrapy
- from scrapy.spiders import CrawlSpider, Rule
- from scrapy.linkextractors import LinkExtractor
-
- class MySpider(CrawlSpider):
- name = 'example.com'
- allowed_domains = ['example.com']
- start_urls = ['http://www.example.com']
-
- rules = (
- # Extract links matching 'category.php' (but not matching 'subsection.php')
- # and follow links from them (since no callback means follow=True by default).
- Rule(LinkExtractor(allow=('category\.php', ), deny=('subsection\.php', ))),
-
- # Extract links matching 'item.php' and parse them with the spider's method parse_item
- Rule(LinkExtractor(allow=('item\.php', )), callback='parse_item'),
- )
-
- def parse_item(self, response):
- self.logger.info('Hi, this is an item page! %s', response.url)
- item = scrapy.Item()
- item['id'] = response.xpath('//td[@id="item_id"]/text()').re(r'ID: (\d+)')
- item['name'] = response.xpath('//td[@id="item_name"]/text()').get()
- item['description'] = response.xpath('//td[@id="item_description"]/text()').get()
- item['link_text'] = response.meta['link_text']
- url = response.xpath('//td[@id="additional_data"]/@href').get()
- return response.follow(url, self.parse_additional_page, cb_kwargs=dict(item=item))
-
- def parse_additional_page(self, response, item):
- item['additional_data'] = response.xpath('//p[@id="additional_data"]/text()').get()
- return item
示例:
- # -*- coding: utf-8 -*-
-
- import os
- import requests
- from pathlib import Path
- from scrapy.spiders import CrawlSpider, Rule
- from scrapy.linkextractors import LinkExtractor
-
-
- class MMSpider(CrawlSpider):
- name = 'mm_spider'
- allowed_domains = ['www.521609.com']
- start_urls = ['http://www.521609.com']
- # start_urls = ['http://www.521609.com/xiaoyuanmeinv/10464_5.html']
-
- # 自定义配置。自定义配置会覆盖 setting.py 中配置,即 优先级 大于 setting.py 中配置
- custom_settings = {
- 'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
- 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36',
- # 'LOG_FILE': 'MMSpider.log',
- # 'LOG_LEVEL': 'DEBUG'
- 'LOG_ENABLED': False, # 关闭 scrapy 中的 debug 打印
- 'LOG_LEVEL': 'INFO'
- }
-
- rules = (
- # 匹配 包含 xiaohua/ 和 meinv/ 所有 URL
- Rule(LinkExtractor(allow=(r'xiaohua/\d+_?\d+', r'meinv/\d+_?\d+')), callback='parse_img', follow=True),
- Rule(LinkExtractor(allow=(r'xiaohua/', 'meinv/')), follow=True)
- )
-
- # def parse(self, response):
- # print(response.url)
- # super(MMSpider, self).parse(response)
- # pass
-
- def parse_img(self, response):
- spider_name = self.name
- current_url = response.url
- print(f'current_url:{current_url}')
-
- mm_name = response.xpath('//div[@class="title"]/h2/text()').extract_first()
- link_extractor = LinkExtractor(
- allow='uploads/allimg', # 匹配的 URL
- deny=r'(lp\.jpg)$', # 排除的 URL。这里排除掉 以 lp.jpg 结尾 的 缩略图 URL
- tags=('img',), # 要提取链接的 标签
- attrs=('src',), # 提取的连接
- restrict_xpaths='//div[@class="picbox"]', # 在 xpath 指定区域 匹配
- deny_extensions='' # 禁用扩展。默认会把 .jpg 扩展名的URL后缀过滤掉,这里禁用。
- )
- all_links = link_extractor.extract_links(response)
-
- # 可以使用自定义的 item,也可以直接使用 Python 的 dict,
- # 因为 item 本身就是一个 python类型的 dict
- # img_item = MMItem()
- img_item = dict()
- image_urls_list = list()
-
- for link in all_links:
- print(f'\t{mm_name}:{link.url}')
- image_urls_list.append(link.url)
- else:
- img_item['img_name'] = mm_name
- img_item['image_urls'] = image_urls_list
- # yield img_item
- print(f'\t{img_item}')
- for img_url in image_urls_list:
- file_name = img_url.split('/')[-1].split('.')[0]
- dir_path = f'./{mm_name}'
- if not Path(dir_path).is_dir():
- os.mkdir(dir_path)
- file_path = f'./{mm_name}/{file_name}.jpg'
- r = requests.get(url=img_url)
- if 200 == r.status_code:
- with open(file_path, 'wb') as f:
- f.write(r.content)
- else:
- print(f'status_code:{r.status_code}')
- pass
-
-
- if __name__ == '__main__':
- from scrapy import cmdline
- cmdline.execute('scrapy crawl mm_spider'.split())
- pass
- CrawlSpider 除了从 Spider类 继承过来的属性外,还提供了一个新的属性 rules 来提供跟进链接(link)的方便机制,这个机制更适合从爬取的网页中获取 link 并继续爬取的工作。
- rules 包含一个或多个 Rule 对象的集合。每个 Rule 对爬取网站的动作定义了特定规则。如果多个 Rule 匹配了相同的链接,则根据他们在本属性中被定义的顺序,第一个会被使用。所以:规则的顺序可以决定获取的数据,应该把 精确匹配的规则放在前面,越模糊的规则放在后面。
- CrawlSpider 也提供了一个可复写的方法:parse_start_url(response) 当 start_url 的请求返回时,该方法被调用。该方法分析最初的返回值并必须返回一个 Item 对象或一个 Request 对象或者一个可迭代的包含二者的对象
注意:当编写 CrawlSpider 爬虫 的 规则 时,不要使用 parse 作为回调函数。 由于 CrawlSpider 使用 parse 方法来实现其逻辑,如果覆盖了 parse 方法,CrawlSpider 将会运行失败。
2、Python 解析 XML
来源:https://www.cnblogs.com/deadwood-2016/p/8116863.html
Python 使用 XPath 解析 XML文档 :http://www.jingfengshuo.com/archives/1414.html
在 XML 解析方面,Python 贯彻了自己“开箱即用”(batteries included)的原则。在自带的标准库中,Python提供了大量可以用于处理XML语言的包和工具,数量之多,甚至让Python编程新手无从选择。
本文将介绍深入解读利用Python语言解析XML文件的几种方式,并以笔者推荐使用的ElementTree模块为例,演示具体使用方法和场景。
什么是 XML?
XML是可扩展标记语言(Extensible Markup Language)的缩写,其中的 标记(markup)是关键部分。您可以创建内容,然后使用限定标记标记它,从而使每个单词、短语或块成为可识别、可分类的信息。
标记语言从早期的私有公司和政府制定形式逐渐演变成标准通用标记语言(Standard Generalized Markup Language,SGML)、超文本标记语言(Hypertext Markup Language,HTML),并且最终演变成 XML。XML有以下几个特点。
- XML的设计宗旨是传输数据,而非显示数据。
- XML标签没有被预定义。您需要自行定义标签。
- XML被设计为具有自我描述性。
- XML是W3C的推荐标准。
目前,XML在Web中起到的作用不会亚于一直作为Web基石的HTML。 XML无所不在。XML是各种应用程序之间进行数据传输的最常用的工具,并且在信息存储和描述领域变得越来越流行。因此,学会如何解析XML文件,对于Web开发来说是十分重要的。
xml.etree.ElementTree(以下简称ET)是一个轻量级、Pythonic的API,同时还有一个高效的C语言实现,即 xml.etree.cElementTree。
利用 ElementTree 解析 XML
Python标准库中,提供了ET的两种实现。一个是纯Python实现的xml.etree.ElementTree,另一个是速度更快的C语言实现xml.etree.cElementTree。请记住始终使用C语言实现,因为它的速度要快很多,而且内存消耗也要少很多。如果你所使用的Python版本中没有cElementTree所需的加速模块,你可以这样导入模块:
- try:
- import xml.etree.cElementTree as ET
- except ImportError:
- import xml.etree.ElementTree as ET
如果某个API存在不同的实现,上面是常见的导入方式。当然,很可能你直接导入第一个模块时,并不会出现问题。请注意,自Python 3.3之后,就不用采用上面的导入方法,因为ElemenTree模块会自动优先使用C加速器,如果不存在C实现,则会使用Python实现。因此,使用Python 3.3+的朋友,只需要import xml.etree.ElementTree即可。
1、将XML文档解析为树(tree)
我们先从基础讲起。XML是一种结构化、层级化的数据格式,最适合体现XML的数据结构就是树。ET提供了两个对象:ElementTree将整个XML文档转化为树,Element则代表着树上的单个节点。对整个XML文档的交互(读取,写入,查找需要的元素),一般是在ElementTree层面进行的。对单个XML元素及其子元素,则是在Element层面进行的。下面我们举例介绍主要使用方法。
我们使用下面的XML文档,作为演示数据:
- <?xml version="1.0"?>
- <doc>
- <branch name="codingpy.com" hash="1cdf045c">
- text,source
- </branch>
- <branch name="release01" hash="f200013e">
- <sub-branch name="subrelease01">
- xml,sgml
- </sub-branch>
- </branch>
- <branch name="invalid">
- </branch>
- </doc>
接下来,我们加载这个文档,并进行解析:
- >>> import xml.etree.ElementTree as ET
- >>> tree = ET.ElementTree(file='doc1.xml')
然后,我们获取根元素(root element):
- >>> tree.getroot()
- <Element 'doc' at 0x11eb780>
正如之前所讲的,根元素(root)是一个Element对象。我们看看根元素都有哪些属性:
- >>> root = tree.getroot()
- >>> root.tag, root.attrib
- ('doc', {})
没错,根元素并没有属性。与其他Element对象一样,根元素也具备遍历其直接子元素的接口:
- >>> for child_of_root in root:
- ... print child_of_root.tag, child_of_root.attrib
- ...
- branch {'hash': '1cdf045c', 'name': 'codingpy.com'}
- branch {'hash': 'f200013e', 'name': 'release01'}
- branch {'name': 'invalid'}
我们还可以通过索引值来访问特定的子元素:
- >>> root[0].tag, root[0].text
- ('branch', '\n text,source\n ')
2、查找需要的元素
从上面的示例中,可以明显发现我们能够通过简单的递归方法(对每一个元素,递归式访问其所有子元素)获取树中的所有元素。但是,由于这是十分常见的工作,ET提供了一些简便的实现方法。
Element对象有一个iter方法,可以对某个元素对象之下所有的子元素进行深度优先遍历(DFS)。ElementTree对象同样也有这个方法。下面是查找XML文档中所有元素的最简单方法:
- >>> for elem in tree.iter():
- ... print elem.tag, elem.attrib
- ...
- doc {}
- branch {'hash': '1cdf045c', 'name': 'codingpy.com'}
- branch {'hash': 'f200013e', 'name': 'release01'}
- sub-branch {'name': 'subrelease01'}
- branch {'name': 'invalid'}
在此基础上,我们可以对树进行任意遍历——遍历所有元素,查找出自己感兴趣的属性。但是ET可以让这个工作更加简便、快捷。iter方法可以接受tag名称,然后遍历所有具备所提供tag的元素:
- >>> for elem in tree.iter(tag='branch'):
- ... print elem.tag, elem.attrib
- ...
- branch {'hash': '1cdf045c', 'name': 'codingpy.com'}
- branch {'hash': 'f200013e', 'name': 'release01'}
- branch {'name': 'invalid'}
3、支持通过 XPath 查找元素
使用XPath查找感兴趣的元素,更加方便。Element对象中有一些find方法可以接受Xpath路径作为参数,find方法会返回第一个匹配的子元素,findall以列表的形式返回所有匹配的子元素, iterfind则返回一个所有匹配元素的迭代器(iterator)。ElementTree对象也具备这些方法,相应地它的查找是从根节点开始的。
下面是一个使用XPath查找元素的示例:
- >>> for elem in tree.iterfind('branch/sub-branch'):
- ... print elem.tag, elem.attrib
- ...
- sub-branch {'name': 'subrelease01'}
上面的代码返回了branch元素之下所有tag为sub-branch的元素。接下来查找所有具备某个name属性的branch元素:
- >>> for elem in tree.iterfind('branch[@name="release01"]'):
- ... print elem.tag, elem.attrib
- ...
- branch {'hash': 'f200013e', 'name': 'release01'}
4、构建 XML 文档
利用ET,很容易就可以完成XML文档构建,并写入保存为文件。ElementTree对象的write方法就可以实现这个需求。
一般来说,有两种主要使用场景。一是你先读取一个XML文档,进行修改,然后再将修改写入文档,二是从头创建一个新XML文档。
修改文档的话,可以通过调整Element对象来实现。请看下面的例子:
- >>> root = tree.getroot()
- >>> del root[2]
- >>> root[0].set('foo', 'bar')
- >>> for subelem in root:
- ... print subelem.tag, subelem.attrib
- ...
- branch {'foo': 'bar', 'hash': '1cdf045c', 'name': 'codingpy.com'}
- branch {'hash': 'f200013e', 'name': 'release01'}
在上面的代码中,我们删除了root元素的第三个子元素,为第一个子元素增加了新属性。这个树可以重新写入至文件中。最终的XML文档应该是下面这样的:
- >>> import sys
- >>> tree.write(sys.stdout)
- <doc>
- <branch foo="bar" hash="1cdf045c" name="codingpy.com">
- text,source
- </branch>
- <branch hash="f200013e" name="release01">
- <sub-branch name="subrelease01">
- xml,sgml
- </sub-branch>
- </branch>
- </doc>
请注意,文档中元素的属性顺序与原文档不同。这是因为ET是以字典的形式保存属性的,而字典是一个无序的数据结构。当然,XML也不关注属性的顺序。
从头构建一个完整的文档也很容易。ET模块提供了一个SubElement工厂函数,让创建元素的过程变得很简单:
- >>> a = ET.Element('elem')
- >>> c = ET.SubElement(a, 'child1')
- >>> c.text = "some text"
- >>> d = ET.SubElement(a, 'child2')
- >>> b = ET.Element('elem_b')
- >>> root = ET.Element('root')
- >>> root.extend((a, b))
- >>> tree = ET.ElementTree(root)
- >>> tree.write(sys.stdout)
- <root><elem><child1>some text</child1><child2 /></elem><elem_b /></root>
5、利用 iterparse 解析XML流
XML文档通常都会比较大,如何直接将文档读入内存的话,那么进行解析时就会出现问题。这也就是为什么不建议使用DOM,而是SAX API的理由之一。
我们上面谈到,ET可以将XML文档加载为保存在内存里的树(in-memory tree),然后再进行处理。但是在解析大文件时,这应该也会出现和DOM一样的内存消耗大的问题吧?没错,的确有这个问题。为了解决这个问题,ET提供了一个类似SAX的特殊工具——iterparse,可以循序地解析XML。
接下来,笔者为大家展示如何使用iterparse,并与标准的树解析方式进行对比。我们使用一个自动生成的XML文档,下面是该文档的开头部分:
- <?xml version="1.0" standalone="yes"?>
- <site>
- <regions>
- <africa>
- <item id="item0">
- <location>United States</location> <!-- Counting locations -->
- <quantity>1</quantity>
- <name>duteous nine eighteen </name>
- <payment>Creditcard</payment>
- <description>
- <parlist>
- [...]
我们来统计一下文档中出现了多少个文本值为Zimbabwe的location元素。下面是使用ET.parse的标准方法:
- tree = ET.parse(sys.argv[2])
-
- count = 0
- for elem in tree.iter(tag='location'):
- if elem.text == 'Zimbabwe':
- count += 1
-
- print count
上面的代码会将全部元素载入内存,逐一解析。当解析一个约100MB的XML文档时,运行上面脚本的Python进程的内存使用峰值为约560MB,总运行时间问2.9秒。
请注意,我们其实不需要讲整个树加载到内存里。只要检测出文本为相应值得location元素即可。其他数据都可以废弃。这时,我们就可以用上 iterparse 方法了:
- count = 0
- for event, elem in ET.iterparse(sys.argv[2]):
- if event == 'end':
- if elem.tag == 'location' and elem.text == 'Zimbabwe':
- count += 1
- elem.clear() # 将元素废弃
-
- print count
上面的 for 循环会遍历 iterparse 事件,首先检查事件是否为 end,然后判断元素的 tag 是否为 location,以及其文本值是否符合目标值。另外,调用 elem.clear() 非常关键:因为 iterparse 仍然会生成一个树,只是循序生成的而已。废弃掉不需要的元素,就相当于废弃了整个树,释放出系统分配的内存。
当利用上面这个脚本解析同一个文件时,内存使用峰值只有 7MB,运行时间为 2.5 秒。速度提升的原因,是我们这里只在树被构建时,遍历一次。而使用 parse 的标准方法是先完成整个树的构建后,才再次遍历查找所需要的元素。
iterparse 的性能与 SAX 相当,但是其 API 却更加有用:iterparse 会循序地构建树;而利用 SAX 时,你还得自己完成树的构建工作。
示例:
- #!/usr/bin/python3
- # -*- coding: utf-8 -*-
- # @Author :
- # @File : test_1.py
- # @Software : PyCharm
- # @description : XXX
-
-
- """
- Element是 XML处理的核心类,
- Element对象可以直观的理解为 XML的节点,大部分 XML节点的处理都是围绕该类进行的。
- 这部分包括三个内容:节点的操作、节点属性的操作、节点内文本的操作。
- """
-
- from lxml import etree
- import lxml.html as HTML
-
- # 1.创建element
- root = etree.Element('root')
- print(root, root.tag)
-
- # 2.添加子节点
- child1 = etree.SubElement(root, 'child1')
- child2 = etree.SubElement(root, 'child2')
-
- # 3.删除子节点
- # root.remove(child2)
-
- # 4.删除所有子节点
- # root.clear()
-
- # 5.以列表的方式操作子节点
- print(len(root))
- print(root.index(child1)) # 索引号
- root.insert(0, etree.Element('child3')) # 按位置插入
- root.append(etree.Element('child4')) # 尾部添加
-
- # 6.获取父节点
- print(child1.getparent().tag)
- # print root[0].getparent().tag #用列表获取子节点,再获取父节点
- '''以上都是节点操作'''
-
- # 7.创建属性
- # root.set('hello', 'dahu') #set(属性名,属性值)
- # root.set('hi', 'qing')
-
- # 8.获取属性
- # print(root.get('hello')) #get方法
- # print root.keys(),root.values(),root.items() #参考字典的操作
- # print root.attrib #直接拿到属性存放的字典,节点的attrib,就是该节点的属性
- '''以上是属性的操作'''
-
- # 9.text和tail属性
- # root.text = 'Hello, World!'
- # print root.text
-
- # 10.test,tail 和 text 的结合
- html = etree.Element('html')
- html.text = 'html.text'
- body = etree.SubElement(html, 'body')
- body.text = 'wo ai ni'
- child = etree.SubElement(body, 'child')
- child.text = 'child.text' # 一般情况下,如果一个节点的text没有内容,就只有</>符号,如果有内容,才会<>,</>都有
- child.tail = 'tails' # tail是在标签后面追加文本
- print(etree.tostring(html))
- # print(etree.tostring(html, method='text')) # 只输出text和tail这种文本文档,输出的内容连在一起,不实用
-
- # 11.Xpath方式
- # print(html.xpath('string()')) #这个和上面的方法一样,只返回文本的text和tail
- print(html.xpath('//text()')) # 这个比较好,按各个文本值存放在列表里面
- tt = html.xpath('//text()')
- print(tt[0].getparent().tag) # 这个可以,首先我可以找到存放每个节点的text的列表,然后我再根据text找相应的节点
- # for i in tt:
- # print i,i.getparent().tag,'\t',
-
- # 12.判断文本类型
- print(tt[0].is_text, tt[-1].is_tail) # 判断是普通text文本,还是tail文本
- '''以上都是文本的操作'''
-
- # 13.字符串解析,fromstring方式
- xml_data = '<html>html.text<body>wo ai ni<child>child.text</child>tails</body></html>'
- root1 = etree.fromstring(xml_data) # fromstring,字面意思,直接来源字符串
- # print root1.tag
- # print etree.tostring(root1)
-
- # 14.xml方式
- root2 = etree.XML(xml_data) # 和fromstring基本一样,
- print(etree.tostring(root2))
-
- # 15.文件类型解析
- '''
- - a file name/path
- - a file object
- - a file-like object
- - a URL using the HTTP or FTP protocol
- '''
- tree = etree.parse('text.html') # 文件解析成元素树
- root3 = tree.getroot() # 获取元素树的根节点
- print(etree.tostring(root3, pretty_print=True))
-
- parser = etree.XMLParser(remove_blank_text=True) # 去除xml文件里的空行
- root = etree.XML("<root> <a/> <b> </b> </root>", parser)
- print(etree.tostring(root))
-
- # 16.html方式
- xml_data1 = '<root>data</root>'
- root4 = etree.HTML(xml_data1)
- print(etree.tostring(root4)) # HTML方法,如果没有<html>和<body>标签,会自动补上
- # 注意,如果是需要补全的html格式:这样处理哦
- with open("quotes-1.html", 'r') as f:
- a = HTML.document_fromstring(f.read().decode("utf-8"))
-
- for i in a.xpath('//div[@class="quote"]/span[@class="text"]/text()'):
- print(i)
-
- # 17.输出内容,输出xml格式
- print(etree.tostring(root))
- print(etree.tostring(root, xml_declaration=True, pretty_print=True, encoding='utf-8')) # 指定xml声明和编码
- '''以上是文件IO操作'''
-
- # 18.findall方法
- root = etree.XML("<root><a x='123'>aText<b/><c/><b/></a></root>")
- print(root.findall('a')[0].text) # findall操作返回列表
- print(root.find('.//a').text) # find操作就相当与找到了这个元素节点,返回匹配到的第一个元素
- print(root.find('a').text)
- print([b.text for b in root.findall('.//a')]) # 配合列表解析,相当帅气!
- print(root.findall('.//a[@x]')[0].tag) # 根据属性查询
- '''以上是搜索和定位操作'''
- print(etree.iselement(root))
- print(root[0] is root[1].getprevious()) # 子节点之间的顺序
- print(root[1] is root[0].getnext())
- '''其他技能'''
- # 遍历元素数
- root = etree.Element("root")
- etree.SubElement(root, "child").text = "Child 1"
- etree.SubElement(root, "child").text = "Child 2"
- etree.SubElement(root, "another").text = "Child 3"
- etree.SubElement(root[0], "childson").text = "son 1"
- # for i in root.iter(): #深度遍历
- # for i in root.iter('child'): #只迭代目标值
- # print i.tag,i.text
- # print etree.tostring(root,pretty_print=True)
简单的创建和遍历
- from lxml import etree
-
-
- # 创建
- root = etree.Element('root')
- # 添加子元素,并为子节点添加属性
- root.append(etree.Element('child',interesting='sss'))
- # 另一种添加子元素的方法
- body = etree.SubElement(root,'body')
- body.text = 'TEXT' # 设置值
- body.set('class','dd') # 设置属性
- //
- # 输出整个节点
- print(etree.tostring(root, encoding='UTF-8', pretty_print=True))
- //
- //
- # 创建,添加子节点、文本、注释
- root = etree.Element('root')
- etree.SubElement(root, 'child').text = 'Child 1'
- etree.SubElement(root, 'child').text = 'Child 2'
- etree.SubElement(root, 'child').text = 'Child 3'
- root.append(etree.Entity('#234'))
- root.append(etree.Comment('some comment')) # 添加注释
- # 为第三个节点添加一个br
- br = etree.SubElement(root.getchildren()[2],'br')
- br.tail = 'TAIL'
- for element in root.iter(): # 也可以指定只遍历是Element的,root.iter(tag=etree.Element)
- if isinstance(element.tag, str):
- print('%s - %s' % (element.tag, element.text))
- else:
- print('SPECIAL: %s - %s' % (element, element.text))
对 HTML / XML 的解析
- # 先导入相关模块
- from lxml import etree
- from io import StringIO, BytesIO
- # 对html具有修复标签补全的功能
- broken_html = '<html><head><title>test<body><h1 class="hh">page title</h3>'
- parser = etree.HTMLParser()
- tree = etree.parse(StringIO(broken_html), parser) # 或者直接使用 html = etree.HTML(broken_html)
- print(etree.tostring(tree, pretty_print=True, method="html"))
- #
- #
- #用xpath获取h1
- h1 = tree.xpath('//h1') # 返回的是一个数组
- # 获取第一个的tag
- print(h1[0].tag)
- # 获取第一个的class属性
- print(h1[0].get('class'))
- # 获取第一个的文本内容
- print(h1[0].text)
- # 获取所有的属性的key,value的列表
- print(h1[0].keys(),h1[0].values())
Element 类
Element 是 XML 处理的核心类,Element 对象可以直观的理解为XML的节点,大部分XML节点的处理都是围绕该类进行的。
这部分包括三个内容:
- 节点的操作
- 节点属性的操作
- 节点内文本的操作
节点操作
1、创建Element对象
直接使用Element方法,参数即节点名称。
root = etree.Element(‘root’)
print(root)2、获取节点名称
使用tag属性,获取节点的名称。
print(root.tag)
root3、输出XML内容
使用tostring方法输出XML内容(后文还会有补充介绍),参数为Element对象。
print(etree.tostring(root))
b’’
4、添加子节点
使用SubElement方法创建子节点,第一个参数为父节点(Element对象),第二个参数为子节点名称。
child1 = etree.SubElement(root, ‘child1’)
child2 = etree.SubElement(root, ‘child2’)
child3 = etree.SubElement(root, ‘child3’)
5、删除子节点
使用remove方法删除指定节点,参数为Element对象。clear方法清空所有节点。
root.remove(child1) # 删除指定子节点
print(etree.tostring(root))
b’’
root.clear() # 清除所有子节点
print(etree.tostring(root))
b’’
6、以列表的方式操作子节点
可以将Element对象的子节点视为列表进行各种操作:
child = root[0] # 下标访问
print(child.tag)
child1
print(len(root)) # 子节点数量
3
root.index(child2) # 获取索引号
1
for child in root: # 遍历
… print(child.tag)
child1
child2
child3
root.insert(0, etree.Element(‘child0’)) # 插入
start = root[:1] # 切片
end = root[-1:]
print(start[0].tag)
child0
print(end[0].tag)
child3
root.append( etree.Element(‘child4’) ) # 尾部添加
print(etree.tostring(root))
b’’
其实前面讲到的删除子节点的两个方法remove和clear也和列表相似。7、获取父节点
使用getparent方法可以获取父节点。
print(child1.getparent().tag)
root
属性操作
属性是以key-value的方式存储的,就像字典一样
1、创建属性
可以在创建Element对象时同步创建属性,第二个参数即为属性名和属性值:
root = etree.Element(‘root’, interesting=’totally’)
print(etree.tostring(root))
b’’
也可以使用set方法给已有的Element对象添加属性,两个参数分别为属性名和属性值:root.set(‘hello’, ‘Huhu’)
print(etree.tostring(root))
b’’
2、获取属性
属性是以key-value的方式存储的,就像字典一样。直接看例子get方法获得某一个属性值
print(root.get(‘interesting’))
totally
keys方法获取所有的属性名
sorted(root.keys())
[‘hello’, ‘interesting’]items方法获取所有的键值对
for name, value in sorted(root.items()):
… print(‘%s = %r’ % (name, value))
hello = ‘Huhu’
interesting = ‘totally’
也可以用attrib属性一次拿到所有的属性及属性值存于字典中:
attributes = root.attrib
print(attributes)
{‘interesting’: ‘totally’, ‘hello’: ‘Huhu’}attributes[‘good’] = ‘Bye’ # 字典的修改影响节点
print(root.get(‘good’))
Bye
文本操作
可以使用text和tail属性、或XPath的方式来访问文本内容。
1、text 和 tail 属性
一般情况,可以用Element的text属性访问标签的文本。
root = etree.Element(‘root’)
root.text = ‘Hello, World!’
print(root.text)
Hello, World!
print(etree.tostring(root))
b’Hello, World!’Element类提供了tail属性支持单一标签的文本获取。
html = etree.Element(‘html’)
body = etree.SubElement(html, ‘body’)
body.text = ‘Text’
print(etree.tostring(html))
b’Text’
br = etree.SubElement(body, ‘br’)
print(etree.tostring(html))
b’Text’
tail仅在该标签后面追加文本
br.tail = ‘Tail’
print(etree.tostring(br))
b’
Tail’
print(etree.tostring(html))
b’Text
Tail’
tostring方法增加method参数,过滤单一标签,输出全部文本
print(etree.tostring(html, method=’text’))
b’TextTail’
2、XPath方式
方式一:过滤单一标签,返回文本
print(html.xpath(‘string()’))
TextTail
方式二:返回列表,以单一标签为分隔
print(html.xpath(‘//text()’))
[‘Text’, ‘Tail’]
方法二获得的列表,每个元素都会带上它所属节点及文本类型信息,如下:
texts = html.xpath(‘//text()’))
print(texts[0])
Text
所属节点
parent = texts[0].getparent()
print(parent.tag)
body
print(texts[1], texts[1].getparent().tag)
Tail br文本类型:是普通文本还是tail文本
print(texts[0].is_text)
True
print(texts[1].is_text)
False
print(texts[1].is_tail)
True
XML 文件 解析、输出
将 XML 文件解析为Element对象,以及如何将Element对象输出为XML文件。
1、文件解析
文件解析常用的有fromstring、XML 和 HTML 三个方法。接受的参数都是字符串。
xml_data = ‘data’
fromstring方法
root1 = etree.fromstring(xml_data)
print(root1.tag)
root
print(etree.tostring(root1))
b’data’XML方法,与fromstring方法基本一样
root2 = etree.XML(xml_data)
print(root2.tag)
root
print(etree.tostring(root2))
b’data’
HTML方法,如果没有和标签,会自动补上
root3 = etree.HTML(xml_data)
print(root3.tag)
html
print(etree.tostring(root3))
b’data’
2、输出
输出其实就是前面一直在用的tostring方法了,这里补充xml_declaration和encoding两个参数,前者是XML声明,后者是指定编码。
root = etree.XML(‘‘)
print(etree.tostring(root))
b’’
XML声明
print(etree.tostring(root, xml_declaration=True))
b”
指定编码print(etree.tostring(root, encoding=’iso-8859-1’))
b”查找第一个b标签
print(root.find(‘b’))
None
print(root.find(‘a’).tag)
a查找所有b标签,返回Element对象组成的列表
[ b.tag for b in root.findall(‘.//b’) ]
[‘b’, ‘b’]
根据属性查询
print(root.findall(‘.//a[@x]’)[0].tag)
a
print(root.findall(‘.//a[@y]’))
[]
3、XPath 语法
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
根节点在xpath中可以用 “//” 来啊表示
读取 文本 解析节点 ( etree 会修复 HTML 文本节点 )
- #!/usr/bin/python3
- # -*- coding: utf-8 -*-
- # @Author :
- # @File : test.py
- # @Software : PyCharm
- # @description : XXX
-
-
- from lxml import etree
-
- text = '''
- <div>
- <ul>
- <li class="item-0"><a href="link1.html">第一个</a></li>
- <li class="item-1"><a href="link2.html">second item</a></li>
- <li class="item-0"><a href="link5.html">a属性</a>
- </ul>
- </div>
- '''
-
- html = etree.HTML(text) # 初始化生成一个XPath解析对象
- result = etree.tostring(html, encoding='utf-8') # 解析对象输出代码
- print(type(html))
- print(type(result))
- print(result.decode('utf-8'))
-
-
- '''
- 执行结果:
- <class 'lxml.etree._Element'>
- <class 'bytes'>
- <html><body><div>
- <ul>
- <li class="item-0"><a href="link1.html">第一个</a></li>
- <li class="item-1"><a href="link2.html">second item</a></li>
- <li class="item-0"><a href="link5.html">a属性</a>
- </li></ul>
- </div>
- </body></html>
- '''
读取 HTML文件 进行解析
- from lxml import etree
-
- html = etree.parse('test.html', etree.HTMLParser()) # 指定解析器HTMLParser会根据文件修复HTML文件中缺失的如声明信息
- result = etree.tostring(html) # 解析成字节
- # result=etree.tostringlist(html) #解析成列表
- print(type(html))
- print(type(result))
- print(result)
节点关系 ( 父、子、同胞、先辈、后代 )
(1)父(Parent):每个元素以及属性都有一个父。在下面的例子中,book 元素是 title、author、year 以及 price 元素的父:
- <book>
- <title>Harry Potter</title>
- <author>J K. Rowling</author>
- <year>2005</year>
- <price>29.99</price>
- </book>
(2)子(Children):元素节点可有零个、一个或多个子。在下面的例子中,title、author、year 以及 price 元素都是 book 元素的子:
- <book>
- <title>Harry Potter</title>
- <author>J K. Rowling</author>
- <year>2005</year>
- <price>29.99</price>
- </book>
(3)同胞(Sibling):拥有相同的父的节点。在下面的例子中,title、author、year 以及 price 元素都是同胞:
- <book>
- <title>Harry Potter</title>
- <author>J K. Rowling</author>
- <year>2005</year>
- <price>29.99</price>
- </book>
(4)先辈(Ancestor):某节点的父、父的父,等等。在下面的例子中,title 元素的先辈是 book 元素和 bookstore 元素:
- <bookstore>
-
- <book>
- <title>Harry Potter</title>
- <author>J K. Rowling</author>
- <year>2005</year>
- <price>29.99</price>
- </book>
-
- </bookstore>
(5)后代(Descendant):某个节点的子,子的子,等等。在下面的例子中,bookstore 的后代是 book、title、author、year 以及 price 元素:
- <bookstore>
-
- <book>
- <title>Harry Potter</title>
- <author>J K. Rowling</author>
- <year>2005</year>
- <price>29.99</price>
- </book>
-
- </bookstore>
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
常用路径表达式
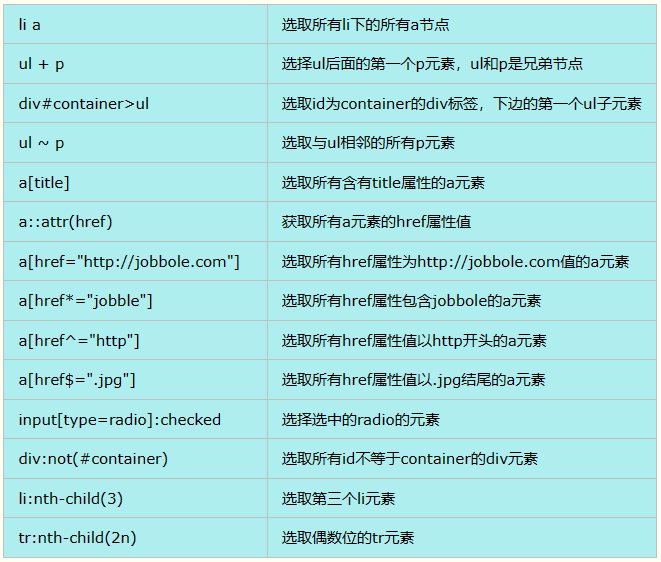
| 表达式 | 描述 |
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符,选择所有元素节点与元素名 |
| @* | 选取所有属性 |
| [@attrib] | 选取具有给定属性的所有元素 |
| [@attrib='value'] | 选取给定属性具有给定值的所有元素 |
| [tag] | 选取所有具有指定元素的直接子节点 |
| [tag='text'] | 选取所有具有指定元素并且文本内容是text节点 |
示例:一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。谓语被嵌在方括号中。
示例:列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=’eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
XPath 运算符
下面列出了可用在 XPath 表达式中的运算符:( 此表参考来源:XPath 运算符)
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| | | 计算两个节点集 | //book | //cd | 返回所有拥有 book 和 cd 元素的节点集 |
| + | 加法 | 6 + 4 | 10 |
| – | 减法 | 6 – 4 | 2 |
| * | 乘法 | 6 * 4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | price=9.80 | 如果 price 是 9.80,则返回 true。如果 price 是 9.90,则返回 false。 |
| != | 不等于 | price!=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| < | 小于 | price<9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| <= | 小于或等于 | price<=9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| > | 大于 | price>9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| >= | 大于或等于 | price>=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.70,则返回 false。 |
| or | 或 | price=9.80 or price=9.70 | 如果 price 是 9.80,则返回 true。如果 price 是 9.50,则返回 false。 |
| and | 与 | price>9.00 and price<9.90 | 如果 price 是 9.80,则返回 true。如果 price 是 8.50,则返回 false。 |
| mod | 计算除法的余数 | 5 mod 2 | 1 |
XPath 函数、高级用法
1.使用 contains() 和 and
//div[starts-with(@id,'res')]//table[1]//tr//td[2]//a//span[contains(.,'_Test') and contains(.,'KPI')]
//div[contains(@id,'in')] ,表示选择id中包含有’in’的div节点
2.text():
由于一个节点的文本值不属于属性,比如“<a class=”baidu“ href=”http://www.baidu.com“>baidu</a>”,
所以,用text()函数来匹配节点://a[text()='baidu']
//span[@id='idHeaderTitleCell' and contains(text(),'QuickStart')]
3.last():
前面已介绍
4. 使用starts-with()
//div[starts-with(@id,'in')] ,表示选择以’in’开头的id属性的div节点
//div[starts-with(@id,'res')]//table//tr//td[2]//table//tr//td//a//span[contains(.,'Developer Tutorial')]
5.not()函数,表示否定。not()函数通常与返回值为true or false的函数组合起来用,
比如contains(),starts-with()等,但有一种特别情况请注意一下:
我们要匹配出input节点含有id属性的,写法为://input[@id],
如果我们要匹配出input节点不含用id属性的,则为://input[not(@id)]
//input[@name=‘identity’ and not(contains(@class,‘a’))] ,表示匹配出name为identity并且class的值中不包含a的input节点。
6.使用descendant
//div[starts-with(@id,'res')]//table[1]//tr//td[2]//a//span[contains(.,'QuickStart')]/../../../descendant::img
7.使用ancestor
//div[starts-with(@id,'res')]//table[1]//tr//td[2]//a//span[contains(.,'QuickStart')]/ancestor::div[starts-with(@id,'res')]//table[2]//descendant::a[2]
span标签class属性包含selectable字符串
//span[contains(@class, 'selectable')]匹配猫眼 座位数
//div[@class='seats-wrapper']//span[contains(@class,'seat') and not(contains(@class,'empty'))]
等价于
//div[@class='seats-wrapper']//span[not(contains(//span[contains(@class, 'seat')]/@class, 'empty'))]./@data-val
//div[contains(@class, "show-list") and @data-index="{0}"]
.//div[@class="show-date"]//span[contains(@class, "date-item")]/text()
.//div[contains(@class, "plist-container")][1]//tbody//tr xpath 中下标是从 1 开始的
substring-before(substring-after(//script[contains(text(), '/apps/feedlist')]/text(), 'html":"'), '"})')
//div[text()="hello"]/p/text()
//a[@class="movie-name"][1]/text()
string(//a[@class="movie-name"][1])
1. 获取父节点属性
首先选中 href 属性为 link4.html的a节点,然后再获取其父节点,然后再获取其class属性
result1 = response.xpath('//a[@href="link4.html"]/../@class')
我们也可以通过parent::来获取父节点
result2 = response.xpath('//a[@href="link4.html"]/parent::*/@class')
注意: //a表示html中的所有a节点,他们的href属性有多个,这里[]的作用是属性匹配,找到a的href属性为link4.html的节点
2. 获取节点内部文本
获取class为item-1的li节点文本,
result3 = response.xpath('//li[@class="item-0"]/a/text()')
返回结果为:['first item', 'fifth item']
3. 属性获取
获取所有li节点下的所有a节点的href属性
result4 = response.xpath('//li/a/@href')
返回结果为:['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']
4. 按序选择
result = response.xpath('//li[1]/a/text()') #选取第一个li节点
result = response.xpath('//li[last()]/a/text()') #选取最后一个li节点
result = response.xpath('//li[position()<3]/a/text()') #选取位置小于3的li节点,也就是1和2的节点
result = response.xpath('//li[last()-2]/a/text()') #选取倒数第三个节点
5. 节点轴选择
1)返回第一个li节点的所有祖先节点,包括html,body,div和ul
result = response.xpath('//li[1]/ancestor::*')
2)返回第一个li节点的<div>祖先节点
result = response.xpath('//li[1]/ancestor::div')
3)返回第一个li节点的所有属性值
result = response.xpath('//li[1]/attribute::*')
4)首先返回第一个li节点的所有子节点,然后加上限定条件,选组href属性为link1.html的a节点
result = response.xpath('//li[1]/child::a[@href="link1.html"]')
5)返回第一个li节点的所有子孙节点,然后加上只要span节点的条件
result = response.xpath('//li[1]/descendant::span')
6)following轴可获得当前节点之后的所有节点,虽然使用了*匹配,但是又加了索引选择,所以只获取第2个后续节点,也就是第2个<li>节点中的<a>节点
result = response.xpath('//li[1]/following::*[2]')
7)following-sibling可获取当前节点之后的所有同级节点,也就是后面所有的<li>节点
result = response.xpath('//li[1]/following-sibling::*')
6. 属性多值匹配
<li class="li li-first"><a href="link.html">first item</a></li>
result5 = response.xpath('//li[@class="li"]/a/text()')
返回值为空,因为这里HTML文本中li节点为class属性有2个值li和li-first,如果还用之前的属性匹配就不行了,需要用contain()函数
正确方法如下
result5 = response.xpath('//li[contains(@class, "li")]/a/text()')
contains()方法中,第一个参数为属性名,第二个参数传入属性值,只要此属性名包含所传入的属性值就可完成匹配
7. 多属性匹配,这里说一下不用框架的时候,xpath的常规用法
有时候我们需要多个属性来确定一个节点,那么就需要同时匹配多个属性,可用and来连接
from lxml import etree
text = '''
<li class = "li li-first" name="item"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
result6 = html.xpath('//li[contains(@class, "li") and @name="item"]/a/text()')
print(result)
这里的li节点有class和name两个属性,需要用and操作符相连,然后置于中括号内进行条件筛选
xpath 学习笔记
1.依靠自己的属性,文本定位
//td[text()='Data Import']
//div[contains(@class,'cux-rightArrowIcon-on')]
//a[text()='马上注册']
//input[@type='radio' and @value='1'] 多条件
//span[@name='bruce'][text()='bruce1'][1] 多条件
//span[@id='bruce1' or text()='bruce2'] 找出多个
//span[text()='bruce1' and text()='bruce2'] 找出多个
2.依靠父节点定位
//div[@class='x-grid-col-name x-grid-cell-inner']/div
//div[@id='dynamicGridTestInstanceformclearuxformdiv']/div
//div[@id='test']/input
3.依靠子节点定位
//div[div[@id='navigation']]
//div[div[@name='listType']]
//div[p[@name='testname']]
4.混合型
//div[div[@name='listType']]//img
//td[a//font[contains(text(),'seleleium2从零开始 视屏')]]//input[@type='checkbox']
5.进阶部分
//input[@id='123']/following-sibling::input 找下一个兄弟节点
//input[@id='123']/preceding-sibling::span 上一个兄弟节点
//input[starts-with(@id,'123')] 以什么开头
//span[not(contains(text(),'xpath'))] 不包含xpath字段的span
6.索引
//div/input[2]
//div[@id='position']/span[3]
//div[@id='position']/span[position()=3]
//div[@id='position']/span[position()>3]
//div[@id='position']/span[position()<3]
//div[@id='position']/span[last()]
//div[@id='position']/span[last()-1]
7.substring 截取判断
<div data-for="result" id="swfEveryCookieWrap"></div>
//*[substring(@id,4,5)='Every']/@id 截取该属性 定位3,取长度5的字符
//*[substring(@id,4)='EveryCookieWrap'] 截取该属性从定位3 到最后的字符
//*[substring-before(@id,'C')='swfEvery']/@id 属性 'C'之前的字符匹配
//*[substring-after(@id,'C')='ookieWrap']/@id 属性'C之后的字符匹配
8.通配符*
//span[@*='bruce']
//*[@name='bruce']
9.轴
//div[span[text()='+++current node']]/parent::div 找父节点
//div[span[text()='+++current node']]/ancestor::div 找祖先节点
10.孙子节点
//div[span[text()='current note']]/descendant::div/span[text()='123']
//div[span[text()='current note']]//div/span[text()='123'] 两个表达的意思一样
11.following pre
https://www.baidu.com/s?wd=xpath
//span[@class="fk fk_cur"]/../following::a 往下的所有a
//span[@class="fk fk_cur"]/../preceding::a[1] 往上的所有a
xpath提取多个标签下的text在写爬虫的时候,经常会使用xpath进行数据的提取,对于如下的代码:
<div id="test1">大家好!</div>
使用xpath提取是非常方便的。假设网页的源代码在selector中:
data = selector.xpath('//div[@id="test1"]/text()').extract()[0]
就可以把“大家好!”提取到data变量中去。
然而如果遇到下面这段代码呢?
<div id="test2">美女,<font color=red>你的微信是多少?</font><div>
如果使用:
data = selector.xpath('//div[@id="test2"]/text()').extract()[0]
只能提取到“美女,”;
如果使用:
data = selector.xpath('//div[@id="test2"]/font/text()').extract()[0]
又只能提取到“你的微信是多少?”
可是我本意是想把“美女,你的微信是多少?”这一整个句子提取出来。
<div id="test3">我左青龙,<span id="tiger">右白虎,
<ul>上朱雀,<li>下玄武。</li></ul>老牛在当中,</span>龙头在胸口。
<div>
而且内部的标签还不固定,如果我有一百段这样类似的html代码,
又如何使用xpath表达式,以最快最方便的方式提取出来?
使用xpath的string(.)
以第三段代码为例:
data = selector.xpath('//div[@id="test3"]')
info = data.xpath('string(.)').extract()[0]
这样,就可以把“我左青龙,右白虎,上朱雀,下玄武。老牛在当中,龙头在胸口”整个句子提取出来,
赋值给info变量。
root.xpath('/bookstore/book[1]')
root.xpath('/bookstore/book[last()]')
root.xpath('/bookstore/book[last()-1]')
root.xpath('/bookstore/book[position()<3]')
root.xpath('//title[@lang]')
root.xpath("//title[@lang='eng']")
root.xpath("/bookstore/book[price>35.00]")
root.xpath("/bookstore/book[price>35.00]/title")root.xpath('/bookstore/*')
root.xpath('//*')
root.xpath('//title[@*]')
root.xpath('node()')
root.xpath('//node()')root.xpath('//book/title|//book/price')
root.xpath('//title|//price')
root.xpath('/bookstore/book/title|//price')//a[@href="link2.html"]/../@class
//a[@href="link2.html"]/parent::*/@class
//li[@class="aaa" and @name="fore"]/a/text()
//li[contains(@class,"aaa") and @name="fore"]/a/text()
//li[contains(@class,"aaa")]/a/text()
//li[1][contains(@class,"aaa")]/a/text()
//li[last()][contains(@class,"aaa")]/a/text()
//li[position()>2 and position()<4][contains(@class,"aaa")]/a/text()
//li[last()-2][contains(@class,"aaa")]/a/text()
//li[1]/ancestor::* # 获取所有祖先节点
//li[1]/ancestor::div # 获取div祖先节点
//li[1]/attribute::* # 获取所有属性值
//li[1]/child::* # 获取所有直接子节点
//li[1]/descendant::a # 获取所有子孙节点的a节点
//li[1]/following::* # 获取当前子节之后的所有节点
//li[1]/following-sibling::* # 获取当前节点的所有同级节点
示例:豆瓣 爬虫
- # -*- coding: utf-8 -*-
- # @Author :
- # @File : douban_api.py
- # @Software: PyCharm
- # @description : XXX
-
-
- import re
- import json
- import datetime
- import requests
- from lxml import etree
- import urllib3
-
-
- urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
-
-
- class DBSpider(object):
-
- def __init__(self):
- self.custom_headers = {
- 'Host': 'movie.douban.com',
- 'Connection': 'keep-alive',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
- '(KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36',
- 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,'
- 'image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
- },
-
- # self.proxies = {
- # 'http': '127.0.0.1:8080',
- # 'https': '127.0.0.1:8080'
- # }
-
- self.s = requests.session()
- self.s.verify = False
- self.s.headers = self.custom_headers
- # self.s.proxies = self.proxies
-
- def __del__(self):
- pass
-
- def api_artists_info(self, artists_id=None):
- ret_val = None
- if artists_id:
- url = f'https://movie.douban.com/celebrity/{artists_id}/'
- try:
- r = self.s.get(url)
- if 200 == r.status_code:
- response = etree.HTML(r.text)
-
- artists_name = response.xpath('//h1/text()')
- artists_name = artists_name[0] if len(artists_name) else ''
-
- chinese_name = re.findall(r'([\u4e00-\u9fa5·]+)', artists_name)
- chinese_name = chinese_name[0] if len(chinese_name) else ''
-
- english_name = artists_name.replace(chinese_name, '').strip()
-
- pic = response.xpath('//div[@id="headline"]//div[@class="pic"]//img/@src')
- pic = pic[0] if len(pic) else ''
-
- sex = response.xpath('//div[@class="info"]//span[contains(text(), "性别")]/../text()')
- sex = ''.join(sex).replace('\n', '').replace(':', '').strip() if len(sex) else ''
-
- constellation = response.xpath('//div[@class="info"]//span[contains(text(), "星座")]/../text()')
- constellation = ''.join(constellation).replace('\n', '').replace(':', '').strip() if len(constellation) else ''
-
- birthday = response.xpath('//div[@class="info"]//span[contains(text(), "日期")]/../text()')
- birthday = ''.join(birthday).replace('\n', '').replace(':', '').strip() if len(birthday) else ''
-
- place = response.xpath('//div[@class="info"]//span[contains(text(), "出生地")]/../text()')
- place = ''.join(place).replace('\n', '').replace(':', '').strip() if len(place) else ''
-
- occupation = response.xpath('//div[@class="info"]//span[contains(text(), "职业")]/../text()')
- occupation = ''.join(occupation).replace('\n', '').replace(':', '').strip() if len(occupation) else ''
-
- desc = ''.join([x for x in response.xpath('//span[@class="all hidden"]/text()')])
-
- artists_info = dict(
- artistsId=artists_id,
- homePage=f'https://movie.douban.com/celebrity/{artists_id}',
- sex=sex,
- constellation=constellation,
- chineseName=chinese_name,
- foreignName=english_name,
- posterAddre=pic,
- # posterAddreOSS=Images.imgages_data(pic, 'movie/douban'),
- birthDate=birthday,
- birthAddre=place,
- desc=desc,
- occupation=occupation,
- showCount='',
- fetchTime=str(datetime.datetime.now()),
- )
- # print(json.dumps(artists_info, ensure_ascii=False, indent=4))
- ret_val = artists_info
- else:
- print(f'status code : {r.status_code}')
- except BaseException as e:
- print(e)
- return ret_val
-
- def test(self):
- pass
-
-
- if __name__ == '__main__':
- douban = DBSpider()
- # temp_uid = '1044707'
- # temp_uid = '1386515'
- # temp_uid = '1052358'
- temp_uid = '1052357'
- user_info = douban.api_artists_info(temp_uid)
- print(json.dumps(user_info, ensure_ascii=False, indent=4))
- pass
示例:解析 古文网
打印 诗经 所对应的 URL
- #!/usr/bin/python3
- # -*- coding: utf-8 -*-
- # @Author :
- # @File : shijing.py
- # @Software : PyCharm
- # @description : XXX
-
-
- import json
- import traceback
- import requests
- from lxml import etree
-
- """
- step1: 安装 lxml 库。
- step2: from lxml import etree
- step3: selector = etree.HTML(网页源代码)
- step4: selector.xpath(一段神奇的符号)
- """
-
-
- def parse():
- url = 'https://www.gushiwen.org/guwen/shijing.aspx'
- r = requests.get(url)
- if r.status_code == 200:
- selector = etree.HTML(r.text)
- s_all_type_content = selector.xpath('//div[@class="sons"]/div[@class="typecont"]')
- print(len(s_all_type_content))
-
- article_list = list()
- for s_type_content in s_all_type_content:
- book_m1 = s_type_content.xpath('.//strong/text()')[0].encode('utf-8').decode('utf-8')
- s_all_links = s_type_content.xpath('.//span/a')
- article_dict = dict()
- for s_link in s_all_links:
- link_name = s_link.xpath('./text()')[0].encode('utf-8').decode('utf-8')
- try:
- link_href = s_link.xpath('./@href')[0].encode('utf-8').decode('utf-8')
- except BaseException as e:
- link_href = None
- article_dict[link_name] = link_href
- temp = dict()
- temp[book_m1] = article_dict
- article_list.append(temp)
- print(json.dumps(article_list, ensure_ascii=False, indent=4))
-
- else:
- print(r.status_code)
-
-
- if __name__ == '__main__':
- parse()
- pass
-
-
CSS 选择器 --- cssSelector 定位方式详解
CSS 语法
CSS 选择器 参考手册:http://www.w3school.com.cn/cssref/css_selectors.asp
CSS 选择器 :http://www.runoob.com/cssref/css-selectors.html
| 选择器 | 示例 | 示例说明 | CSS |
|---|---|---|---|
| .class | .intro | 选择所有class="intro"的元素 | 1 |
| #id | #firstname | 选择所有id="firstname"的元素 | 1 |
| * | * | 选择所有元素 | 2 |
| element | p | 选择所有<p>元素 | 1 |
| element,element | div,p | 选择所有<div>元素和<p>元素 | 1 |
| element element | div p | 选择<div>元素内的所有<p>元素 | 1 |
| element>element | div>p | 选择所有父级是 <div> 元素的 <p> 元素 | 2 |
| element+element | div+p | 选择所有紧接着<div>元素之后的<p>元素 | 2 |
| [attribute] | [target] | 选择所有带有target属性元素 | 2 |
| [attribute=value] | [target=-blank] | 选择所有使用target="-blank"的元素 | 2 |
| [attribute~=value] | [title~=flower] | 选择标题属性包含单词"flower"的所有元素 | 2 |
| [attribute|=language] | [lang|=en] | 选择 lang 属性以 en 为开头的所有元素 | 2 |
| :link | a:link | 选择所有未访问链接 | 1 |
| :visited | a:visited | 选择所有访问过的链接 | 1 |
| :active | a:active | 选择活动链接 | 1 |
| :hover | a:hover | 选择鼠标在链接上面时 | 1 |
| :focus | input:focus | 选择具有焦点的输入元素 | 2 |
| :first-letter | p:first-letter | 选择每一个<P>元素的第一个字母 | 1 |
| :first-line | p:first-line | 选择每一个<P>元素的第一行 | 1 |
| :first-child | p:first-child | 指定只有当<p>元素是其父级的第一个子级的样式。 | 2 |
| :before | p:before | 在每个<p>元素之前插入内容 | 2 |
| :after | p:after | 在每个<p>元素之后插入内容 | 2 |
| :lang(language) | p:lang(it) | 选择一个lang属性的起始值="it"的所有<p>元素 | 2 |
| element1~element2 | p~ul | 选择p元素之后的每一个ul元素 | 3 |
| [attribute^=value] | a[src^="https"] | 选择每一个src属性的值以"https"开头的元素 | 3 |
| [attribute$=value] | a[src$=".pdf"] | 选择每一个src属性的值以".pdf"结尾的元素 | 3 |
| [attribute*=value] | a[src*="runoob"] | 选择每一个src属性的值包含子字符串"runoob"的元素 | 3 |
| :first-of-type | p:first-of-type | 选择每个p元素是其父级的第一个p元素 | 3 |
| :last-of-type | p:last-of-type | 选择每个p元素是其父级的最后一个p元素 | 3 |
| :only-of-type | p:only-of-type | 选择每个p元素是其父级的唯一p元素 | 3 |
| :only-child | p:only-child | 选择每个p元素是其父级的唯一子元素 | 3 |
| :nth-child(n) | p:nth-child(2) | 选择每个p元素是其父级的第二个子元素 | 3 |
| :nth-last-child(n) | p:nth-last-child(2) | 选择每个p元素的是其父级的第二个子元素,从最后一个子项计数 | 3 |
| :nth-of-type(n) | p:nth-of-type(2) | 选择每个p元素是其父级的第二个p元素 | 3 |
| :nth-last-of-type(n) | p:nth-last-of-type(2) | 选择每个p元素的是其父级的第二个p元素,从最后一个子项计数 | 3 |
| :last-child | p:last-child | 选择每个p元素是其父级的最后一个子级。 | 3 |
| :root | :root | 选择文档的根元素 | 3 |
| :empty | p:empty | 选择每个没有任何子级的p元素(包括文本节点) | 3 |
| :target | #news:target | 选择当前活动的#news元素(包含该锚名称的点击的URL) | 3 |
| :enabled | input:enabled | 选择每一个已启用的输入元素 | 3 |
| :disabled | input:disabled | 选择每一个禁用的输入元素 | 3 |
| :checked | input:checked | 选择每个选中的输入元素 | 3 |
| :not(selector) | :not(p) | 选择每个并非p元素的元素 | 3 |
| ::selection | ::selection | 匹配元素中被用户选中或处于高亮状态的部分 | 3 |
| :out-of-range | :out-of-range | 匹配值在指定区间之外的input元素 | 3 |
| :in-range | :in-range | 匹配值在指定区间之内的input元素 | 3 |
| :read-write | :read-write | 用于匹配可读及可写的元素 | 3 |
| :read-only | :read-only | 用于匹配设置 "readonly"(只读) 属性的元素 | 3 |
| :optional | :optional | 用于匹配可选的输入元素 | 3 |
| :required | :required | 用于匹配设置了 "required" 属性的元素 | 3 |
| :valid | :valid | 用于匹配输入值为合法的元素 | 3 |
| :invalid | :invalid | 用于匹配输入值为非法的元素 | 3 |
基本 css 选择器
CSS 选择器中,最常用的选择器 如下:
| 选择器 | 描述 | 举例 |
| * | 通配选择器,选择所有的元素 | * |
| <type> | 选择特定类型的元素,支持基本HTML标签 | h1 |
| .<class> | 选择具有特定class的元素。 | .class1 |
| <type>.<class> | 特定类型和特定class的交集。(直接将多个选择器连着一起表示交集) | h1.class1 |
| #<id> | 选择具有特定id属性值的元素 | #id1 |
属性选择器
除了最基本的核心选择器外,还有可以 基于属性 的 属性选择器:
| 选择器 | 描述 | 举例 |
| [attr] | 选取定义attr属性的元素,即使该属性没有值 | [placeholder] |
| [attr="val"] | 选取attr属性等于val的元素 | [placeholder="请输入关键词"] |
| [attr^="val"] | 选取attr属性开头为val的元素 | [placeholder^="请输入"] |
| [attr$="val"] | 选取attr属性结尾为val的元素 | [placeholder$="关键词"] |
| [attr*="val"] | 选取attr属性包含val的元素 | [placeholder*="入关"] |
| [attr~="val"] | 选取attr属性包含多个空格分隔的属性,其中一个等于val的元素 | [placeholder~="关键词"] |
| [attr|="val"] | 选取attr属性等于val的元素或第一个属性值等于val的元素 | [placeholder|="关键词"] |
<p class="important warning">This paragraph is a very important warning.</p>
selenium举例: (By.CSS_SELECTOR,'p[class="import warning"]')
属性与属性的值需要完全匹配,如上面用p[class='impprtant']就定位不到;
部分属性匹配:(By.CSS_SELECTOR,'p[class~="import warning"]');
子串匹配&特定属性匹配:
[class^="def"]:选择 class 属性值以 "def" 开头的所有元素
[class$="def"]:选择 class 属性值以 "def" 结尾的所有元素
[class*="def"]:选择class 属性值中包含子串 "def" 的所有元素
[class|="def"]:选择class 属性值等于"def"或以"def-"开头的元素(这个是特定属性匹配)
关系选择器
有一些选择器是基于层级之间的关系,这类选择器称之为关系选择器。
| 选择器 | 描述 | 举例 |
| <selector> <selector> | 第二个选择器为第一个选择器的后代元素,选取第二个选择器匹配结果 | .class1 h1 |
| <selector> > <selector> | 第二个选择器为第一个选择器的直接子元素,选取第二个选择器匹配结果 | .class1 > * |
| <selector> + <selector> | 第二个选择器为第一个选择器的兄弟元素,选取第二个选择器的下一兄弟元素 | .class1 + [lang] |
| <selector> ~ <selector> | 第二个选择器为第一个选择器的兄弟元素,选取第二个选择器的全部兄弟元素 | .class1 ~ [lang] |
选择 某个元素 的 后代的元素:
selenium举例:(By.CSS_SELECTOR,‘div button’)
div元素的所有的后代元素中标签为button元素,不管嵌套有多深
选择 某个元素 的 子代元素:
selenium举例:(By.CSS_SELECTOR,‘div > button’)
div元素的所有的子代元素中标签为button元素(>符号前后的空格可有可无)
一个元素不好定位时,它的兄长元素很起眼,可以借助兄长来扬名,因此不妨称之为 "弟弟选择器".
即选择某个元素的弟弟元素(先为兄,后为弟):
selenium举例: (By.CSS_SELECTOR,'button + li')
button与li属于同一父元素,且button与li相邻,选择button下标签为li的元素
联合选择器与反选择器
利用 联合选择器与反选择器,可以实现 与和或 的关系。
| 选择器 | 描述 | 举例 |
| <selector>,<selector> | 属于第一个选择器的元素或者是属于第二个选择器的元素 | h1, h2 |
| :not(<selector>) | 不属于选择器选中的元素 | :not(html) |
伪元素和伪类选择器
CSS选择器支持了 伪元素和伪类选择器。
| :active | 鼠标点击的元素 |
| :checked | 处于选中状态的元素 |
| :default | 选取默认值的元素 |
| :disabled | 选取处于禁用状态的元素 |
| :empty | 选取没有任何内容的元素 |
| :enabled | 选取处于可用状态的元素 |
| :first-child | 选取元素的第一个子元素 |
| :first-letter | 选取文本的第一个字母 |
| :first-line | 选取文本的第一行 |
| :focus | 选取得到焦点的元素 |
| :hover | 选取鼠标悬停的元素 |
| :in-range | 选取范围之内的元素 |
| :out-of-range | 选取范围之外的元素 |
| :lang(<language>) | 选取lang属性为language的元素 |
| :last-child | 选取元素的最后一个子元素 |
CSS选择器的常见语法


高阶:


Selenium 之 CSS Selector 定位详解
:https://www.bbsmax.com/A/MyJxLGE1Jn/
1. 根据 标签 定位 tagName (定位的是一组,多个元素)
find_element_by_css_selector("div")
2. 根据 id属性 定位 ( 注意:id 使用 # 表示)
find_element_by_css_selector("#eleid")
find_element_by_css_selector("div#eleid")
3. 根据 className 属性 定位(注意:class 属性 使用 . )
两种方式:前面加上 tag 名称。也可以不加。如果不加 tag 名称时,点不能省略。
find_element_by_css_selector('.class_value')
find_element_by_css_selector("div.eleclass")
find_element_by_css_selector('tag_name.class_value')
有的 class_value 比较长,而且中间有空格时,不能把空格原样写进去,那样不能识别。
这时,空格用点代替,前面要加上 tag_name。
driver.find_element_by_css_selector('div.panel.panel-email').click()
# <p class="important warning">This paragraph is a very important warning.</p>
driver.find_element_by_css_selector('.important')
driver.find_element_by_css_selector('.important.warning')
4. 根据 标签 属性 定位
两种方式,可以在前面加上 tag 名称,也可以不加。
find_element_by_css_selector("[attri_name='attri_value']")
find_element_by_css_selector("input[type='password']").send_keys('密码')
find_element_by_css_selector("[type='password']").send_keys('密码')
4.1 精确 匹配:
find_element_by_css_selector("div[name=elename]") #属性名=属性值,精确值匹配
find_element_by_css_selector("a[href]") #是否存在该属性,判断a元素是否存在href属性
注意:如果 class属性值 里带空格,用.来代替空格
4.2 模糊 匹配
find_element_by_css_selector("div[name^=elename]") #从起始位置开始匹配
find_element_by_css_selector("div[name$=name2]") #从结尾匹配
find_element_by_css_selector("div[name*=name1]") #从中间匹配,包含
4.3 多属性 匹配
find_element_by_css_selector("div[type='eletype][value='elevalue']") #同时有多属性
find_element_by_css_selector("div.eleclsss[name='namevalue'] #选择class属性为eleclass并且name为namevalue的div节点
find_element_by_css_selector("div[name='elename'][type='eletype']:nth-of-type(1) #选择name为elename并且type为eletype的第1个div节点
5. 定位 子元素 (A>B)
find_element_by_css_selector("div#eleid>input") #选择id为eleid的div下的所有input节点
find_element_by_css_selector("div#eleid>input:nth-of-type(4) #选择id为eleid的div下的第4个input节点
find_element_by_css_selector("div#eleid>nth-child(1)") #选择id为eleid的div下的第一个子节点
6. 定位 后代元素 (A空格B)
find_element_by_css_selector("div#eleid input") #选择id为eleid的div下的所有的子孙后代的 input 节点
find_element_by_css_selector("div#eleid>input:nth-of-type(4)+label #选择id为eleid的div下的第4个input节点的相邻的label节点
find_element_by_css_selector("div#eleid>input:nth-of-type(4)~label #选择id为eleid的div下的第4个input节点之后中的所有label节点
7. 不是 ( 否 )
find_element_by_css_selector("div#eleid>*.not(input)") #选择id为eleid的div下的子节点中不为input 的所有子节点
find_element_by_css_selector("div:not([type='eletype'])") #选择div节点中type不为eletype的所有节点
8. 包含
find_element_by_css_selector("li:contains('Goa')") # <li>Goat</li>
find_element_by_css_selector("li:not(contains('Goa'))) # <li>Cat</li>
9. by index
find_element_by_css_selector("li:nth(5)")
10. 路径 法
两种方式,可以在前面加上 tag 名称,也可以不加。注意它的层级关系使用大于号">"。
find_element_by_css_selector("form#loginForm>ul>input[type='password']").send_keys('密码')

