
- 1Code Review 工具_code review工具
- 2HTTP网络协议,接口请求的内容类型 content-type(2024-04-27)
- 3Oracle-客户端连接报错ORA-12545问题
- 4用机器学习实现情感分析_基于机器学习的情感分析
- 5仿真流程专题----随机振动分析_随机振动仿真分析
- 6哈希表&位图&topk&一致性哈希算法_布隆过滤器 topk
- 7Hadoop实战——MapReduce实现主播的播放量等数据的统计及TopN排序(第二篇)_mapreduce项目实战案例
- 8YOLOv5训练和推理_yolov5推理
- 9移动安全Android逆向系列:Dalvik概念&破解实例_dalvikvm
- 10linux 离线安装rabbitMQ Erlang_离线安装erlang
YAKE!无监督关键字抽取算法解读_yake算法
赞
踩
本周任务如下,接续上周的关键字抽取任务,前面一两周主要学习了RAKE、TF-IDF、TextRank算法,详细见https://blog.csdn.net/qq_45041871/article/details/126658189。本周发现还有一个无监督的关键字抽取算法比较经典,所以在扩展一下。这个算法就是YAKE!,在2018年提出,论文A Text Feature Based Automatic Keyword Extraction Method for Single Documents,该论文获得2018年ECIR的最佳短论文奖。
YAKE
RAKE遵循由启发式方法支持的无监督方法,该方法可以在短时间内轻松扩展到不同的集合、域和语言。该文章的主要有两个贡献:(1)作者提出了一种无监督关键字抽取方法叫做YAKE!,YAKE是基于文本统计的特征的方法,从单个文档中抽取关键词(单词和多词短语),并且不需要依赖文档集合;(2)YAKE可能适用于没有现成方法的领域和语言,因为它既不需要训练语料库,也不依赖任何外部来源(如WordNet)或语言工具(如NER或PoS标记器)。
YAKE的四个主要流程:文本预处理——>特征提取——>单个词权重计算——>候选关键字的生成,其中最为关键的莫过于特征提取过程。
文本预处理
其实就是对文档进行分词,按照一些标点符号和特殊字符进行分词。
特征提取
作者选用了5种常见的特征,Casing、Word Position、Word Frequency、Word Relatedness to Context、 Word DifSentence。
Casing:特别关注以大写字母开头的任何单词(不包括句子开头的字母)或任何首字母缩略词(即,该单词的所有字母都是大写),前提是这些单词往往更相关。我们不计算它们两次,只考虑它们中的最大值。
W
C
a
s
e
=
m
a
x
(
T
F
(
U
(
w
)
)
,
T
F
(
A
(
w
)
)
)
l
o
g
2
(
T
F
(
w
)
)
W_{Case}=\frac{max(TF(U(w)),TF(A(w)))}{log_2(TF(w))}
WCase=log2(TF(w))max(TF(U(w)),TF(A(w)))
T
F
(
U
(
w
)
)
TF(U(w))
TF(U(w))是候选词
w
w
w以大写字母开头的次数,
T
F
(
A
(
w
)
)
TF(A(w))
TF(A(w))是候选词
w
w
w被标记为首字母缩略词的次数,而
T
F
(
w
)
TF(w)
TF(w)是
w
w
w的频率。
Word Position:考虑单词出现的句子位置可能是关键词提取过程的一个重要特征,因为文档(尤其是科学和新闻出版物)的早期部分往往包含大量相关关键词。
W
P
o
s
i
t
i
o
n
=
l
o
g
2
(
l
o
g
2
(
2
+
M
e
d
i
a
n
(
S
e
n
w
)
)
)
W_{Position}=log_2(log_2(2+Median(Sen_w)))
WPosition=log2(log2(2+Median(Senw)))
S
e
n
w
Sen_w
Senw表示单词
w
w
w出现在句子集的位置,
M
i
d
i
a
n
Midian
Midian是中值函数。结果是一个递增函数,当单词位于文档末尾时,值趋于平稳增加,这意味着单词出现在文档开头的频率越高,其
W
p
o
s
i
t
i
o
n
W_{position}
Wposition值越小。相反,更经常位于文档末尾的单词(可能不太相关)将被赋予更高的
W
p
o
s
i
t
i
o
n
W_{position}
Wposition值。注意,等式中考虑值2,以保证
W
p
o
s
i
t
i
o
n
>
0
W_{position}>0
Wposition>0。
Word Frequency: 该特征指示文档中单词
w
w
w的频率。它反映了一种理念,即频率越高,单词越重要。为了防止长文档中出现偏向高频的情况,单词
w
w
w的
T
F
TF
TF值除以频率均值
M
e
a
n
T
F
Mean TF
MeanTF。我们的目的是对所有高于平均值的单词进行评分(由标准偏差给出的分散度平衡)。
W
F
r
e
q
=
T
F
(
w
)
M
e
a
n
T
F
+
1
∗
σ
W_{Freq}=\frac{TF(w)}{Mean TF +1*\sigma}
WFreq=MeanTF+1∗σTF(w)
Word Relatedness to Context:
W
r
e
l
W_{rel}
Wrel量化了一个词与停止词特征相似的程度。为了计算这个度量,我们借助于出现在候选词左侧(和右侧)大小为
n
n
n的窗口中的不同项的数量。与候选词(两侧)同时出现的不同词的数量越多,候选词可能就越无意义。
W
R
e
l
=
(
0.5
+
(
(
W
L
∗
T
F
(
w
)
M
a
x
T
F
)
+
P
L
)
)
+
(
0.5
+
(
(
W
R
∗
T
F
(
w
)
M
a
x
T
F
)
+
P
R
)
)
W_{Rel}=(0.5+((WL*\frac{TF(w)}{Max TF})+PL))+(0.5+((WR*\frac{TF(w)}{MaxTF})+PR))
WRel=(0.5+((WL∗MaxTFTF(w))+PL))+(0.5+((WR∗MaxTFTF(w))+PR))
更准确地说,
W
L
[
W
R
]
WL[WR]
WL[WR]测量与候选词(在左[右]侧)共同出现的不同词的数量与它共同出现的词的数量之间的比率。
T
F
(
w
)
TF(w)
TF(w)是单词相对于所有单词中的最大频率(
M
a
x
T
F
MaxTF
MaxTF)的频率,
P
L
[
P
R
]
PL[PR]
PL[PR]测量与候选单词(在左[右]侧)共同出现的不同单词的数量与
M
a
x
T
F
MaxTF
MaxTF之间的比率。实际上,候选词越不重要,该特征的得分就越高。因此,类似的停止词很容易获得更高的分数。
Word DifSentence:量化候选词在不同句子中出现的频率。一个词在越多句子中出现,相对显得更加重要。
W
D
i
f
S
e
n
t
e
n
c
e
=
S
F
(
w
)
#
S
e
n
t
e
n
c
e
s
W_{DifSentence}=\frac{SF(w)}{\#Sentences}
WDifSentence=#SentencesSF(w)
其中,
S
F
(
w
)
SF(w)
SF(w)单词
w
w
w出现的句子频率,也就是单词
w
w
w出现的句子数。
#
S
e
n
t
e
n
c
e
s
\#Sentences
#Sentences是文档中句子的总数。
计算每个单词的权重
结合上面五个评估指标,作者提出了一种联合计算指标,用来代表每个单词的重要性程度,该值越小,则表现的越重要。
S
(
w
)
=
W
R
e
l
∗
W
P
o
s
i
t
i
o
n
W
C
a
s
e
+
W
F
r
e
q
W
R
e
l
+
W
D
i
f
S
e
n
t
e
n
c
e
W
R
e
l
S(w)=\frac{W_{Rel}*W_{Position}}{W_{Case}+\frac{W_{Freq}}{W_{Rel}}+\frac{W_{DifSentence}}{W_{Rel}}}
S(w)=WCase+WRelWFreq+WRelWDifSentenceWRel∗WPosition
候选词列表生成
因为候选关键词可以是单词也可以词组,所以作者设置了滑动窗口大小为1、2、3来设定关键词序列。另外,作者不考虑以停用词开头和结尾的连续序列。同样重要的是,对于候选关键词没有要求必须具有最小频率或句子频率。,这意味着,我们可以将一个关键字视为重要或不重要的依次出现或者多次出现。然后,每个候选关键字将为分配一个最终形式的
S
(
k
w
)
S(kw)
S(kw),这样分数越小,关键词就越有意义。
S
(
k
w
)
=
∏
w
∈
k
w
S
(
w
)
T
F
(
k
w
)
∗
(
1
+
∑
w
∈
k
w
S
(
w
)
)
S(kw)=\frac{\prod_{w\in{kw}}S(w)}{TF(kw)*(1+\sum_{w\in{kw}}S(w))}
S(kw)=TF(kw)∗(1+∑w∈kwS(w))∏w∈kwS(w)
S
(
k
w
)
S(kw)
S(kw)是最大尺度为3的候选词的得分。
评估
评估数据集:SemEval2010 、500N-KPCrowd-v1.1、 WICC、Schutz2008。
实验参数设置:最大滑动窗口设置为3、使用停用词预料、Levenshtein阈值设置为0.8。
对比模型:TextRank、RAKE、SingleRank、TF-IDF。
评价指标:precision、recall、F1。
实验结果如下表所是:
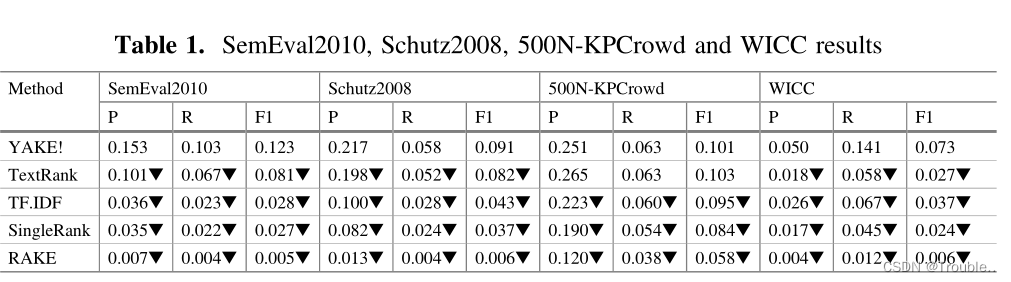
实验
可以参考作者的开源代码:YAKE!实现
Reference
[1] 面向特定问题的开源算法管理和推荐(十二)_郭德纲闭门弟子的博客-CSDN博客
[2] Campos R , Mangaravite V , Pasquali A , et al. YAKE! Keyword Extraction from Single Documents using Multiple Local Features[J]. Information Sciences, 2020, 509:257-289.
[3] Pasi G , Piwowarski B , Azzopardi L , et al. [Lecture Notes in Computer Science] Advances in Information Retrieval Volume 10772 || A Text Feature Based Automatic Keyword Extraction Method for Single Documents[J]. 2018
[4] http://bit.ly/YakeDemoECIR2018
[5] http://www.hlt.utdallas.edu/~saidul/code.html
[6] https://github.com/zelandiya/RAKE-tutorial
[7] https://pypi.python.org/pypi/yake
[8] Yet Another Keyword Extractor (Yake)代码解读 - 知乎 (zhihu.com)

