
- 1项目中常用的 .env 文件原理源码分析_dify的.env文件
- 2【初阶数据结构】——单链表详解(C描述)_写出单链表数据元素类型为整数类型存储结构的c语言描述
- 3CMD设置代理 注册表设置IE代理_ie代理设置 cmd
- 4Windows系统安装Android SDK_android-sdk-windows
- 5关于从数据库读取来的数据,怎么引入Vue 组件_vue3数据库读取出来的地址怎么引入
- 6oracle 同一张表同时insert多条数据 mysql 同一张表同时insert多条数据
- 7李沐-动手学习深度学习v2_李沐动手学深度学习v2文字版
- 8Vue项目改index.html不生效的解决方法_vue2把访问index.html移到路径为public目录下
- 9八、SpringCloud-RabbitMQ + Spring AMQP 消息队列_rabbitmq 版本控制
- 10hadoop的50070端口不能访问网页的解决方法_hadoop01:50070
索引+删除成本+mysql_【Mysql源码分析】MySQL为什么有时候会选错索引及成本计算...
赞
踩
前言
在一次Mysql分享中提到过,会将相关的一些知识点整理成相应的文章。由于前段时间忙的不可开交,一直没有时间去整理这些相关内容。但是必定说出来的话,就要去落实。本章内容主要以实践为主,最好是跟着动手实践。这样才能逐步掌握其中奥秘。那么我们开始吧!!!
1.安装数据库
在做这个实践之前,我们要先安装一下mysql数据库,这边是通过源码的形式进行安装。方便后续的调试跟踪。
1.1通过git下载mysql源码:#cd /Users/edz/Desktop/src-source/mysql-server/
#git clone https://github.com/mysql/mysql-server.git
#cd mysql-server
#git checkout 5.6.48
当前使用版本为5.6.48,所以我们切到5.6.48版本。
1.2编译mysql源码:#cd /Users/edz/Desktop/src-source/mysql-server/BUILD
#cmake .. -DCMAKE_INSTALL_PREFIX=/usr/local/mysql5.6.48 -DMYSQL_DATADIR=/usr/local/mysql5.6.48/data -DSYSCONFDIR=/usr/local/mysql5.6.48/etc -DWITH_MYISAM_STORAGE_ENGINE=1 -DWITH_INNOBASE_STORAGE_ENGINE=1 -DWITH_MEMORY_STORAGE_ENGINE=1 -DWITH_READLINE=1 -DMYSQL_UNIX_ADDR=/tmp/mysqld.sock -DMYSQL_TCP_PORT=3306 -DENABLED_LOCAL_INFILE=1 -DWITH_PARTITION_STORAGE_ENGINE=1 -DEXTRA_CHARSETS=all -DDEFAULT_CHARSET=utf8 -DDEFAULT_COLLATION=utf8_general_ci -DWITH_DEBUG=1 -DWITH_UNIT_TESTS=off
#make
#make install
没有指定mysql安装目录时,在mac系统下默认会安装在/usr/local/mysql目录中。
implicit instantiation of undefined template 'std::basic_stringstream 错误解决:#include <sstream> //直接引入头即可
1.3编译my.cnf内容[mysqld]
datadir=/usr/local/mysql5.6.48/data
socket=/usr/local/mysql5.6.48/data/mysql.sock
explicit_defaults_for_timestamp=true
lower_case_table_names=1
symbolic-links=0
[mysqld_safe]
log-error=/data/logs/mariadb.log
pid-file=/data/mysql/mariadb.pid
my.conf内容我存在/usr/local/mysql/my.cnf
1.4初始化数据库#cd /usr/local/mysql5.6.48/
#./scripts/mysql_install_db --defaults-file=/usr/local/mysql5.6.48/etc/my.cnf --user=root --basedir=/usr/local/mysql
初始化数据库过程主要是初始化一些基本数据过程。
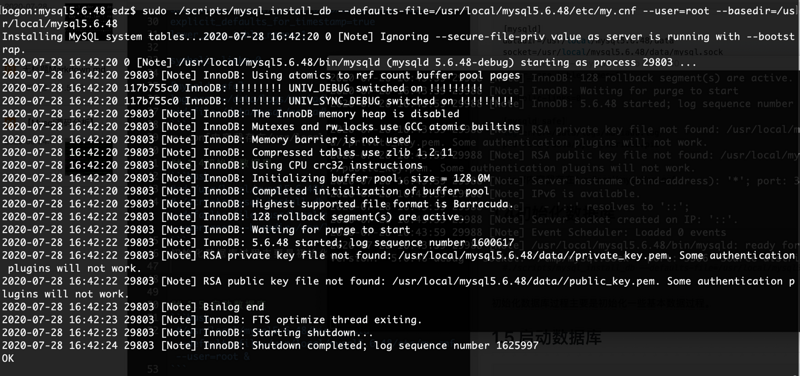
1.5 启动数据库#/usr/local/mysql5.6.48/bin/mysqld --defaults-file=/usr/local/mysql5.6.48/etc/my.cnf --user=root &
需要启动数据库服务,可以使用命令“ps aux |grep mysqld”,看一下是否启动成功。
1.6 连接数据库#/usr/local/mysql5.6.48/bin/mysql --socket=/usr/local/mysql5.6.48/data/mysql.sock -u root -h 127.0.0.1 --port 3306 -p
输入自己数据库的密码即可,连接到终端。5.6默认情况是没有设置的,mysql5.7会默认设置。
1.7 小节内容
以上的安装只针对于mysql5.6,如果是mysql5.7以上版本,需要支持boost。mysql版本也会细分为boost版本和非boost版本,非boost版本的需要连带下载boost一块编译。但是我们通过通过-DDOWNLOAD_BOOST参数自动下载并编译。
2.实践
不知道你有没有碰到过这种情况,一条本来可以执行得很快的语句,却由于 MySQL 选错了索引,而导致执行速度变得很慢?我们可以一起来看一个小实验,看一下我们Mysql5.6中的bug。
2.1 创建表实践
创建表语句:-- 创建数据库
create database t1;
use t1;
-- 新建一张demo1表
create table demo1(id int auto_increment primary key, a int, b int, c int, v varchar(1000), key iabc(a,b,c), key ic(c)) engine = innodb;
-- 插入demo1表数据
insert into demo1 select null,null,null,null,null;
insert into demo1 select null,null,null,null,null from demo1;
insert into demo1 select null,null,null,null,null from demo1;
insert into demo1 select null,null,null,null,null from demo1;
insert into demo1 select null,null,null,null,null from demo1;
insert into demo1 select null,null,null,null,null from demo1;
-- 更新demo1表数据
update demo1 set a=id/2, b=id/4, c=6-id/8, v=repeat('a',1000);
-- 查看使用索引情况1
explain select id from demo1 where a<3 and b in (1, 13) and c>=3 order by c desc limit 2;
-- 查看使用索引情况2
explain select id from demo1 force index (iabc) where a<3 and b in (1, 13) and c>=3 order by c desc limit 2;
执行以上语句后,对比一下“查看使用索引情况1” 与 “查看使用索引情况2”执行结果。
查看使用索引情况1:

查看使用索引情况2:

同样的语句,使用同样的索引,但是使用了force index之后选择的执行后影响的行数是不一样的。如果数据量大的话,实际的执行性能也会差别很大。使用range scan显然要优于index scan的全扫描。
2.问题分析
在分析这个问题前,我们可以通过一个optimizer_trace进行分析,optimizer_trace主要用于语句的优化器跟踪,可以分析一些语句的问题。
2.1 optimizer_trace参数介绍QUERY: 跟踪语句的文本。
TRACE: 跟踪,JSON格式。
MISSING_BYTES_BEYOND_MAX_MEM_SIZE: 每个记住的跟踪都是一个字符串,随着优化的进行扩展并将其附加数据。该optimizer_trace_max_mem_size 变量设置所有当前记忆的跟踪所使用的内存总量的限制。如果达到此限制,则当前跟踪不会扩展(因此是不完整的),并且该MISSING_BYTES_BEYOND_MAX_MEM_SIZE列显示该跟踪丢失的字节数。
INSUFFICIENT_PRIVILEGES: 如果跟踪的查询使用SQL SECURITY值为的 视图或存储的例程 DEFINER,则可能是拒绝了除定义者之外的其他用户查看查询的跟踪。在这种情况下,跟踪显示为空,INSUFFICIENT_PRIVILEGES值为1。否则,值为0。
我们可以通过一下sql进行optimizer_trace :-- 设置optimizer_trace最大内存
SET OPTIMIZER_TRACE_MAX_MEM_SIZE=268435456;
-- 设置开启optimizer_trace
SET optimizer_trace="enabled=on";
select id from demo1 where a<3 and b in (1, 13) and c>=3 order by c desc limit 2;
-- 查看optimizer_trace信息
select * from INFORMATION_SCHEMA.OPTIMIZER_TRACE\G;
2.2 分析原因
以下为“查看使用索引情况1”的sql语句optimizer_trace信息:TRACE: {
"steps": [
{
"join_preparation": {
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `demo1`.`id` AS `id` from `demo1` where ((`demo1`.`a` < 3) and (`demo1`.`b` in (1,13)) and (`demo1`.`c` >= 3)) order by `demo1`.`c` desc limit 2"
}
]
}
},
{
"join_optimization": {
"select#": 1,
"steps": [
{
"condition_processing": {
"condition": "WHERE",
"original_condition": "((`demo1`.`a` < 3) and (`demo1`.`b` in (1,13)) and (`demo1`.`c` >= 3))",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "((`demo1`.`a` < 3) and (`demo1`.`b` in (1,13)) and (`demo1`.`c` >= 3))"
},
{
"transformation": "constant_propagation",
"resulting_condition": "((`demo1`.`a` < 3) and (`demo1`.`b` in (1,13)) and (`demo1`.`c` >= 3))"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "((`demo1`.`a` < 3) and (`demo1`.`b` in (1,13)) and (`demo1`.`c` >= 3))"
}
]
}
},
{
"table_dependencies": [
{
"table": "`demo1`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
]
}
]
},
{
"ref_optimizer_key_uses": [
]
},
{
"rows_estimation": [
{
"table": "`demo1`",
"range_analysis": {
"table_scan": {
"rows": 32,
"cost": 12.5
},
"potential_range_indices": [
{
"index": "PRIMARY",
"usable": false,
"cause": "not_applicable"
},
{
"index": "iabc",
"usable": true,
"key_parts": [
"a",
"b",
"c",
"id"
]
},
{
"index": "ic",
"usable": true,
"key_parts": [
"c",
"id"
]
}
],
"best_covering_index_scan": {
"index": "iabc",
"cost": 7.4718,
"chosen": true
},
"setup_range_conditions": [
],
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
},
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "iabc",
"ranges": [
"NULL < a < 3"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": true,
"rows": 3,
"cost": 1.6146,
"chosen": true
},
{
"index": "ic",
"ranges": [
"3 <= c"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 17,
"cost": 21.41,
"chosen": false,
"cause": "cost"
}
],
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
}
},
"chosen_range_access_summary": {
"range_access_plan": {
"type": "range_scan",
"index": "iabc",
"rows": 3,
"ranges": [
"NULL < a < 3"
]
},
"rows_for_plan": 3,
"cost_for_plan": 1.6146,
"chosen": true
}
}
}
]
},
{
"considered_execution_plans": [
{
"plan_prefix": [
],
"table": "`demo1`",
"best_access_path": {
"considered_access_paths": [
{
"access_type": "range",
"rows": 3,
"cost": 2.2146,
"chosen": true
}
]
},
"cost_for_plan": 2.2146,
"rows_for_plan": 3,
"chosen": true
}
]
},
{
"attaching_conditions_to_tables": {
"original_condition": "((`demo1`.`a` < 3) and (`demo1`.`b` in (1,13)) and (`demo1`.`c` >= 3))",
"attached_conditions_computation": [
{
"table": "`demo1`",
"rechecking_index_usage": {
"recheck_reason": "low_limit",
"limit": 2,
"row_estimate": 3,
"range_analysis": {
"table_scan": {
"rows": 32,
"cost": 40.4
},
"potential_range_indices": [
{
"index": "PRIMARY",
"usable": false,
"cause": "not_applicable"
},
{
"index": "iabc",
"usable": false,
"cause": "not_applicable"
},
{
"index": "ic",
"usable": true,
"key_parts": [
"c",
"id"
]
}
],
"best_covering_index_scan": {
"index": "iabc",
"cost": 7.4718,
"chosen": true
},
"setup_range_conditions": [
],
"group_index_range": {
"chosen": false,
"cause": "cannot_do_reverse_ordering"
},
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "ic",
"ranges": [
"3 <= c"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 17,
"cost": 21.41,
"chosen": false,
"cause": "cost"
}
]
}
}
}
}
],
"attached_conditions_summary": [
{
"table": "`demo1`",
"attached": "((`demo1`.`a` < 3) and (`demo1`.`b` in (1,13)) and (`demo1`.`c` >= 3))"
}
]
}
},
{
"clause_processing": {
"clause": "ORDER BY",
"original_clause": "`demo1`.`c` desc",
"items": [
{
"item": "`demo1`.`c`"
}
],
"resulting_clause_is_simple": true,
"resulting_clause": "`demo1`.`c` desc"
}
},
{
"refine_plan": [
{
"table": "`demo1`",
"access_type": "index_scan"
}
]
},
{
"reconsidering_access_paths_for_index_ordering": {
"clause": "ORDER BY",
"index_order_summary": {
"table": "`demo1`",
"index_provides_order": false,
"order_direction": "undefined",
"index": "unknown",
"plan_changed": false
}
}
}
]
}
},
{
"join_execution": {
"select#": 1,
"steps": [
{
"filesort_information": [
{
"direction": "desc",
"table": "`demo1`",
"field": "c"
}
],
"filesort_priority_queue_optimization": {
"limit": 2,
"rows_estimate": 2656,
"row_size": 22,
"memory_available": 262144,
"chosen": true
},
"filesort_execution": [
],
"filesort_summary": {
"rows": 3,
"examined_rows": 32,
"number_of_tmp_files": 0,
"sort_buffer_size": 90,
"sort_mode": "<sort_key, additional_fields>"
}
}
]
}
}
]
}
join_preparation段落
join_preparation段落展示了准备阶段的执行过程。
join_optimization段落
join_optimization展示优化阶段的执行过程,是分析OPTIMIZER TRACE的重点。这段内容超级长,而且分了好多步骤,不妨按照步骤逐段分析:
condition_processing
该段用来做条件处理,主要对WHERE条件进行优化处理。
其中:condition:优化对象类型。WHERE条件句或者是HAVING条件句
original_condition:优化前的原始语句
steps:主要包括三步,分别是quality_propagation(等值条件句转换),constant_propagation(常量条件句转换),trivial_condition_removal(无效条件移除的转换)transformation:转换类型句
resulting_condition:转换之后的结果输出
substitute_generated_columns
substitute_generated_columns用于替换虚拟生成列
table_dependencies
table_dependencies段分析表之间的依赖关系
其中:table:涉及的表名,如果有别名,也会展示出来
row_may_be_null:行是否可能为NULL,这里是指JOIN操作之后,这张表里的数据是不是可能为NULL。如果语句中使用了LEFT JOIN,则后一张表的row_may_be_null会显示为true
map_bit:表的映射编号,从0开始递增
depends_on_map_bits:依赖的映射表。主要是当使用STRAIGHT_JOIN强行控制连接顺序或者LEFT JOIN/RIGHT JOIN有顺序差别时,会在depends_on_map_bits中展示前置表的map_bit值。
ref_optimizer_key_uses
列出所有可用的ref类型的索引。如果使用了组合索引的多个部分(例如本例,用到了index(from_date, to_date) 的多列索引),则会在ref_optimizer_key_uses下列出多个元素,每个元素中会列出ref使用的索引及对应值。
rows_estimation
顾名思义,用于估算需要扫描的记录数。
其中:table:表名
range_analysis:table_scan:如果全表扫描的话,需要扫描多少行(row,2838216),以及需要的代价(cost,286799)
potential_range_indexes:列出表中所有的索引并分析其是否可用。如果不可用的话,会列出不可用的原因是什么;如果可用会列出索引中可用的字段;
best_covering_index_scan: 如果有覆盖索引,列出覆盖索引情况
setup_range_conditions:如果有可下推的条件,则带条件考虑范围查询
group_index_range:当使用了GROUP BY或DISTINCT时,是否有合适的索引可用。当未使用GROUP BY或DISTINCT时,会显示chosen=false, cause=not_group_by_or_distinct;如使用了GROUP BY或DISTINCT,但是多表查询时,会显示chosen=false,cause =not_single_table。其他情况下会尝试分析可用的索引(potential_group_range_indexes)并计算对应的扫描行数及其所需代价
skip_scan_range:是否使用了skip scan
analyzing_range_alternatives:分析各个索引的使用成本range_scan_alternatives:range扫描分析index:索引名
ranges:range扫描的条件范围
index_dives_for_eq_ranges:是否使用了index dive,该值会被参数eq_range_index_dive_limit变量值影响。
rowid_ordered:该range扫描的结果集是否根据PK值进行排序
using_mrr:是否使用了mrr
index_only:表示是否使用了覆盖索引
rows:扫描的行数
cost:索引的使用成本
chosen:表示是否使用了该索引
analyzing_roworder_intersect:分析是否使用了索引合并(index merge),如果未使用,会在cause中展示原因;如果使用了索引合并,会在该部分展示索引合并的代价。
chosen_range_access_summary:在前一个步骤中分析了各类索引使用的方法及代价,得出了一定的中间结果之后,在summary阶段汇总前一阶段的中间结果确认最后的方案range_access_plan:range扫描最终选择的执行计划。type:展示执行计划的type,如果使用了索引合并,则会显示index_roworder_intersect
index:索引名
rows:扫描的行数
ranges:range扫描的条件范围
rows_for_plan:该执行计划的扫描行数
cost_for_plan:该执行计划的执行代价
chosen:是否选择该执行计划
considered_execution_plans
负责对比各可行计划的开销,并选择相对最优的执行计划。
其中:plan_prefix:当前计划的前置执行计划。
table:涉及的表名,如果有别名,也会展示出来
best_access_path:通过对比considered_access_paths,选择一个最优的访问路径considered_access_paths:当前考虑的访问路径access_type:使用索引的方式,可参考explain中的type字段
index:索引
rows:行数
cost:开销成本
chosen:是否选用这种执行路径
condition_filtering_pct:类似于explain的filtered列,是一个估算值
rows_for_plan:执行计划最终的扫描行数,由considered_access_paths.rows 乘以 condition_filtering_pct计算获得。
cost_for_plan:执行计划的代价,由considered_access_paths.cost相加获得
chosen:是否选择了该执行计划
attaching_conditions_to_tables
基于considered_execution_plans中选择的执行计划,改造原有where条件,并针对表增加适当的附加条件,以便于单表数据的筛选。
其中:original_condition:原始的条件语句
attached_conditions_computation:使用启发式算法计算已使用的索引,如果已使用的索引的访问类型是ref,则计算用range能否使用组合索引中更多的列,如果可以,则用range的方式替换ref。
attached_conditions_summary:附加之后的情况汇总table:表名
attached:附加的条件或原语句中能直接下推给单表筛选的条件。
finalizing_table_conditions
最终的、经过优化后的表条件。
refine_plan
改善执行计划。table:表名及别名
join_execution
join_execution段落展示了执行阶段的执行过程。
3.源码分析
源码主要针对成本计算部分,我们可以来看一下具体有几个计算成本。rows_estimation->range_analysis->table_scan->cost: 12.5 全表扫描成本。
best_covering_index_scan->cost: 7.4718 覆盖索引成本。
considered_execution_plans->cost_for_plan: 2.2146 执行计划的代价,由considered_access_paths.cost相加获得。
除了以上的还有一些其他的,我们本文只会讲这几个。其余的可以参照源码方式进行获取。
3.1 全表扫描成本计算
根据2.2小节中OPTIMIZER_TRACE的输出,我们可以看rows_estimation,是用来计算一个表在不同的访问路径下(全表扫描、索引扫描、范围扫描等),数据库所要付出的代价。
可以通过lldb下一个test_quick_select断点:(lldb)b test_quick_select
然后执行打开一个新终端执行“查看使用索引情况1”的sql,断点进入跟踪到下图:
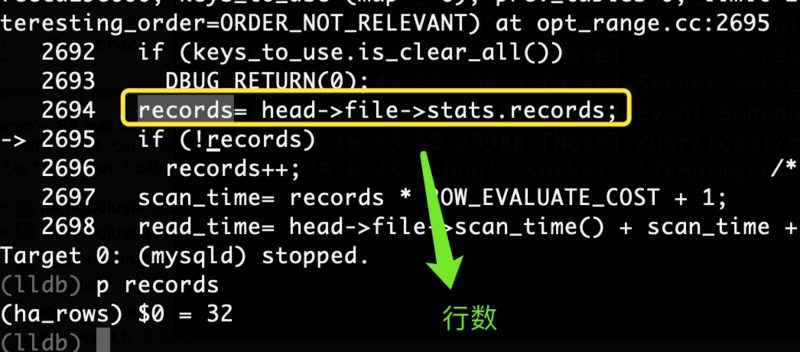
可以看到我们计算扫描成本使用到了行数,继续跟踪到下图:
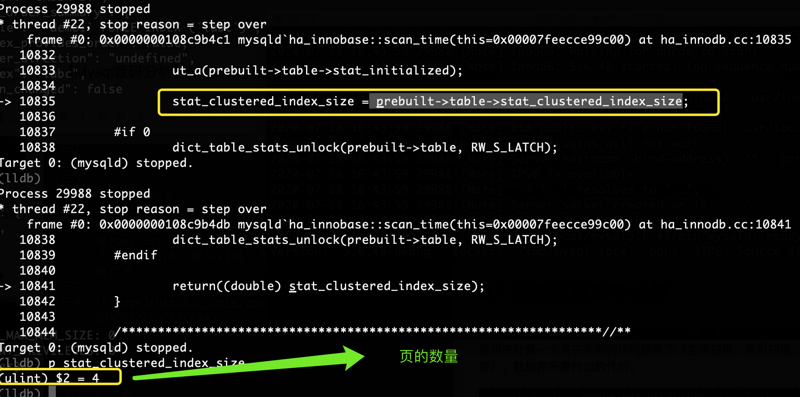
可以看到我们跟中到ha_innobase::scan_time函数,发现我们是在innodb引擎中处理的。发现其实不同到引擎计算规则会有差异。
下图为table_scan的计算成本:
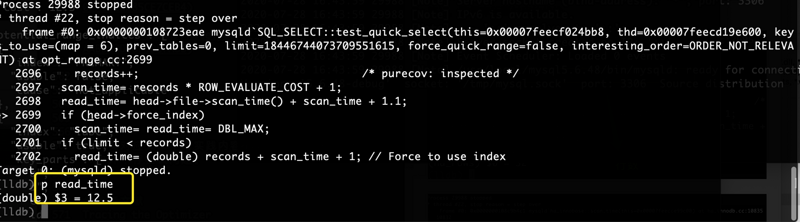
可以看到图中的“12.5”和2.2小节中OPTIMIZER_TRACE的table_scan一致。
我们可以看一下test_quick_select中的计算代码,在sql/opt_range.cc中:int SQL_SELECT::test_quick_select(THD *thd, key_map keys_to_use,
table_map prev_tables,
ha_rows limit, bool force_quick_range,
const ORDER::enum_order interesting_order)
{
double scan_time;
//...省略
records= head->file->stats.records; //行数
if (!records)
records++; /* purecov: inspected */
scan_time= records * ROW_EVALUATE_COST + 1;
read_time= head->file->scan_time() + scan_time + 1.1;
//...省略
//trace信息
Opt_trace_context * const trace= &thd->opt_trace;
Opt_trace_object trace_range(trace, "range_analysis");
Opt_trace_object(trace, "table_scan"). //trace 全表扫描
add("rows", head->file->stats.records). //trace 行数
add("cost", read_time); //trace 成本信息
//...省略
}
ROW_EVALUATE_COST宏,在sql/sql_const.h中://行代价
#define ROW_EVALUATE_COST 0.20
通过以上信息我们可以得知到mysql5.6.48中的计算成本:read_time= InnoDB页数 + scan_time + 1.1;
scan_time= 行数 * 行代价 + 1;
那么“行数”怎么获取,其实可以通过:-- 获取demo1表的表状态
show table status like 'demo1' \G;
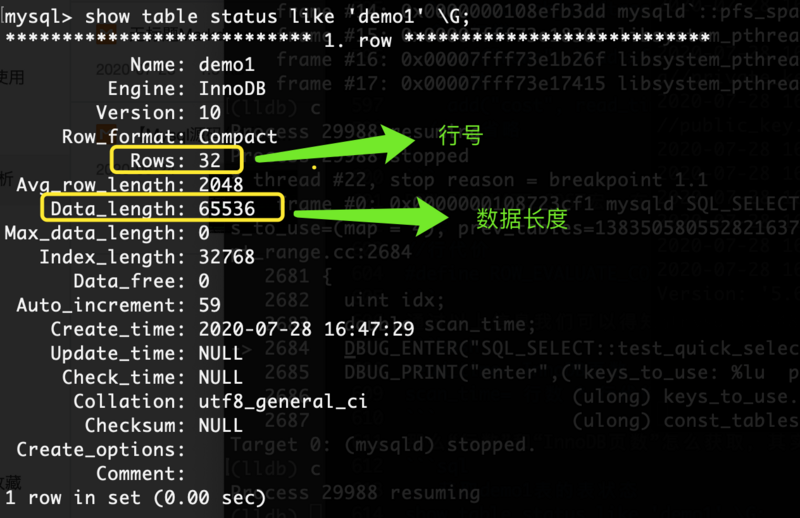
那么“InnoDB页数”又怎么获取:
InnoDB页数 = 数据长度 / InnoDB页大小
其实数据长度我们有了,是“65536”。
InnoDB页大小,可以通过show variables获取,通常是16k:show variables like 'innodb_page_size';
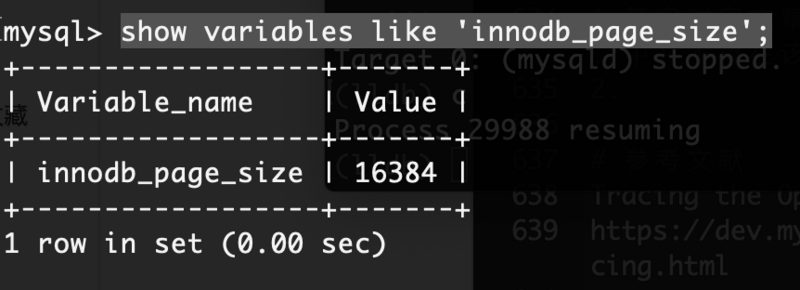
InnoDB页数 = 65536 / 16384 = 4
scan_time= 32 * 0.2 + 1 = 7.4
read_time= 4 + scan_time + 1.1 = 12.5
最终read_time等于12.5,也就是table_scan的cost成本。
注意: 其实在高版本中,比如mysql8.0中scan_time对应cpu_cost,read_time对应io_cost,不过计算公式有所改变。
3.2 覆盖索引成本int SQL_SELECT::test_quick_select(THD *thd, key_map keys_to_use,
table_map prev_tables,
ha_rows limit, bool force_quick_range,
const ORDER::enum_order interesting_order)
{
//...省略
int key_for_use= find_shortest_key(head, &head->covering_keys);
double key_read_time=
param.table->file->index_only_read_time(key_for_use,
rows2double(records)) +
records * ROW_EVALUATE_COST; //计算部分
//...省略
}
根据计算部分我们可以看到index_only_read_time函数,也是计算部分之一,函数原型如下(在sql/handler.cc中):double handler::index_only_read_time(uint keynr, double records)
{
double read_time;
uint keys_per_block= (stats.block_size/2/
(table_share->key_info[keynr].key_length + ref_length) +
1);
read_time=((double) (records + keys_per_block-1) /
(double) keys_per_block);
return read_time;
}
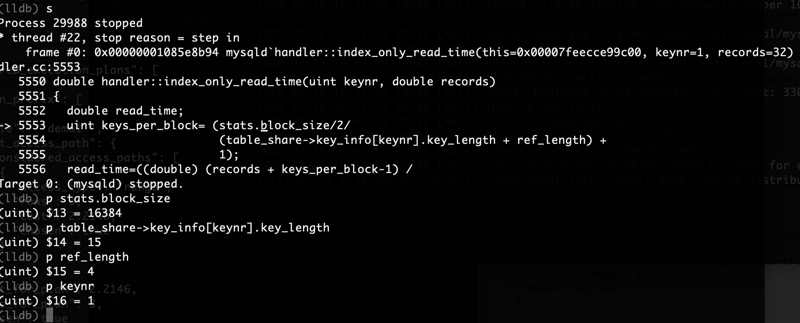
源码中records ROW_EVALUATE_COST = 32 0.2 = 6.4,这个是行成本。
行成本需要加上read_time,read_time计算就相对比较复杂。
keys_per_block = (索引块大小/2/(键长度+引用长度)+1)
根据图中可以得出:
keys_per_block = (16384/2/(15+4)+1) = 432
432其实是取整后的值。
然后read_time = ((double) (32 + 432 - 1) /(double) 432);
read_time = 463 / 432 = 1.0717
保留4位小数后等到结果1.0717,然后在加上行成本的6.4,最终得到我们覆盖索引成本的“7.4717”
3.3 执行计划的代价
要得到执行计划代价我们可以下一个断点:(lldb)b best_access_path
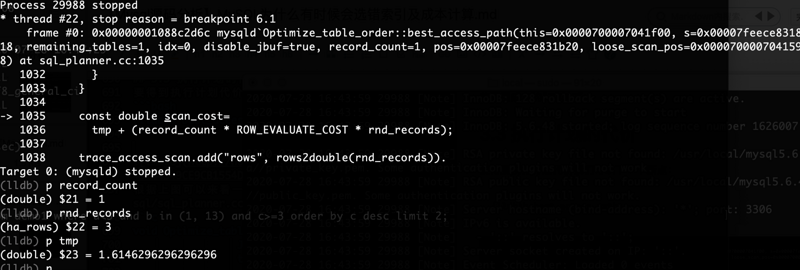
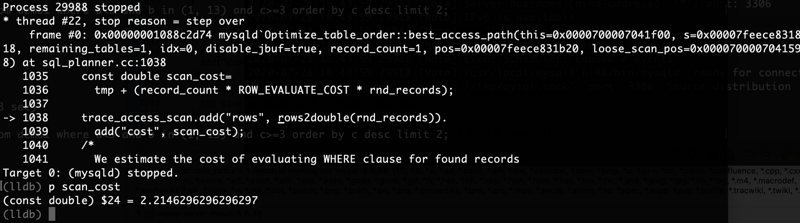
根据上图可以来看一下我们具体的代码实现部分,如下(在sql/sql_planner.cc中):void Optimize_table_order::best_access_path(
JOIN_TAB *s,
table_map remaining_tables,
uint idx,
bool disable_jbuf,
double record_count,
POSITION *pos,
POSITION *loose_scan_pos)
{
//...省略
const double scan_cost=
tmp + (record_count * ROW_EVALUATE_COST * rnd_records);
trace_access_scan.add("rows", rows2double(rnd_records)).
add("cost", scan_cost);
//...省略
}
scan_cost=tmp + (record_count * ROW_EVALUATE_COST * rnd_records);
record_count记录计数,当前为1,rnd_records为找到记录数当前为3。tmp计算部分比较复杂,可以留个小作业。看一下best_access_path函数中实现。
最终scan_cost=1.6146+(1 0.2 3)= 2.2146
2.2146为取小数后4位。
4. 解决选择索引错误方案
其实解决索引方案可以概括为几种:强制使用force index(key)进行语句查询。
使用ANALYZE TABLE tablename; (不建议使用)不建议使用原因是因为该方案,不建议在生产直接使用。可以使用于低峰段,比如说凌晨。删除不必要的索引;
总结其实对应文章中的实践内容bug,这个是5.6中的bug。在5.7中并不存在该问题。
不过的成本计算方式不同,不同的引擎计算基本的方式也不同,不同的mysql版本计算成本的方式也会不同。—— 三不同
InnoDB页大小计算= 数据长度 / InnoDB页大小。
ROW_EVALUATE_COST行代价等于0.2。
解决选择索引错误方案可以分为三种:强制使用force index(key)、使用ANALYZE TABLE tablename、删除不必要索引。
参考文献
MYSQL sql执行过程的一些跟踪分析(二.mysql优化器追踪分析)
http://blog.itpub.net/2986302...


