
- 1《python程序设计教程》第2章 Python语言基础知识 习题2答案_python程序设计案例教程张宗霞第二章课后习题答案
- 2Kafka Producer send原理及重试机制浅析(retries/acks如何被使用的)_kafka producer.send
- 35. Manjaro 简介_manjaro是什么
- 4【Element Ui】 vue3中修改el-form的rules后不触发自动校验,再次修改rules时清除验证信息_el-form 修改:rules 触发校验
- 5虚拟机繁忙解决问题(已解决)_vm13:2 [wxapplib]] backgroundfetch privacy fail {"
- 6从头手搓一台ros2复合机器人(带机械臂)_lsn10p
- 7idea 回滚某次提交的代码_idea代码回滚到指定提交位置
- 8云计算-Amazon S3
- 9transformer上手(5) —— 必要的 Pytorch 知识_transformer库使用pytorch
- 10毕设项目分享 人脸识别系统
机器学习:线性回归,拉索(Lasso)回归,脊(Ridge)回归_lasso回归梯度下降
赞
踩
线性模型
线性回归
线性回归是一种线性模型,它通过在输入特征和输出之间找到最佳线性关系来建立模型。线性回归的目标是找到一条直线,使得所有样本到直线的距离之和最小。这条直线的方程为:
y
=
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
n
x
n
+
b
y = w_1x_1 + w_2x_2 + ... + w_nx_n + b
y=w1x1+w2x2+...+wnxn+b
其中,
w
1
,
w
2
,
.
.
.
,
w
n
w_1, w_2, ..., w_n
w1,w2,...,wn是权重,
b
b
b是偏置。线性回归的损失函数是均方误差:
M
S
E
=
1
m
∑
i
=
1
m
(
y
i
−
y
^
i
)
2
MSE = \frac{1}{m}\sum_{i=1}^{m}(y_i - \hat{y}_i)^2
MSE=m1i=1∑m(yi−y^i)2
其中,
m
m
m是样本数量,
y
i
y_i
yi是真实值,
y
^
i
\hat{y}_i
y^i是预测值。我们的目标是找到一组权重和偏置,使得均方误差最小。我们可以使用梯度下降法来求解。梯度下降法的更新公式为:
w
=
w
−
α
∂
M
S
E
∂
w
w = w - \alpha\frac{\partial{MSE}}{\partial{w}}
w=w−α∂w∂MSE
最大似然
线性回归的损失函数是均方误差,我们可以通过最大似然估计来推导出均方误差。假设我们的模型是:
y
=
y
^
+
ϵ
y =\hat{y}+ \epsilon
y=y^+ϵ
其中,
ϵ
\epsilon
ϵ是误差项,假设
ϵ
\epsilon
ϵ服从均值为0的正态分布,即
ϵ
∼
N
(
0
,
σ
2
)
\epsilon \sim N(0, \sigma^2)
ϵ∼N(0,σ2)。我们可以得到:
y
∼
N
(
y
^
,
σ
2
)
y \sim N(\hat{y}, \sigma^2)
y∼N(y^,σ2)
我们的目标是找到一组参数,使得样本的似然最大(样本出现的概率)。我们可以得到似然函数:
L
=
∏
i
=
1
m
f
(
x
i
∣
θ
)
=
∏
i
=
1
m
1
2
π
σ
e
x
p
(
−
(
y
i
−
y
^
i
)
2
2
σ
2
)
L=\prod_{i=1}^{m}f(x_i|\theta) = \prod_{i=1}^{m}\frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{(y_i - \hat{y}_i)^2}{2\sigma^2})
L=i=1∏mf(xi∣θ)=i=1∏m2π
σ1exp(−2σ2(yi−y^i)2)
对似然函数取对数,得到对数似然函数:
ℓ
=
−
m
2
l
o
g
(
2
π
)
−
m
l
o
g
(
σ
)
−
1
2
σ
2
∑
i
=
1
m
(
y
i
−
y
^
i
)
2
\ell = -\frac{m}{2}log(2\pi) - mlog(\sigma) - \frac{1}{2\sigma^2}\sum_{i=1}^{m}(y_i - \hat{y}_i)^2
ℓ=−2mlog(2π)−mlog(σ)−2σ21i=1∑m(yi−y^i)2
我们可以看到,对数似然函数的第三项就是均方误差。因此,最大似然估计和均方误差是等价的。
ℓ
=
M
S
E
\ell = MSE
ℓ=MSE
梯度下降
我们可以通过梯度下降法来求解线性回归的参数。我们的目标是最小化均方误差,即:
M
S
E
=
1
2
m
∑
i
=
1
m
(
y
i
−
y
^
i
)
2
我们可以对
w
w
w和
b
b
b分别求偏导:
∂
ℓ
∂
w
=
−
1
m
∑
i
=
1
m
x
i
(
y
i
−
y
^
i
)
\frac{\partial{\ell}}{\partial{w}} = -\frac{1}{m}\sum_{i=1}^{m}x_i(y_i - \hat{y}_i)\\
∂w∂ℓ=−m1i=1∑mxi(yi−y^i)
最后通过梯度更新参数:
w
=
w
−
η
∂
L
∂
w
w=w-\eta\frac{\partial{L}}{\partial{w}}
w=w−η∂w∂L
正则项
由于参数的数量可能很多,我们需要对参数进行约束,以防止过拟合。我们可以假设参数服从正态分布,即
w
∼
N
(
0
,
α
2
)
w \sim N(0, \alpha^2)
w∼N(0,α2)。则由贝叶斯公式:
p
(
y
,
w
)
=
p
(
y
∣
w
)
p
(
w
)
p(y,w)=p(y|w)p(w)
p(y,w)=p(y∣w)p(w)
带入似然函数:
ln
L
=
ln
∏
i
=
1
m
p
(
y
i
∣
w
)
p
(
w
)
=
ln
∏
i
=
1
m
1
2
π
σ
e
x
p
(
−
(
y
i
−
y
^
i
)
2
2
σ
2
)
1
2
π
α
e
x
p
(
−
w
2
2
α
2
)
=
∑
i
=
1
m
(
−
1
2
σ
2
(
y
i
−
y
^
i
)
2
)
−
1
2
α
2
w
2
−
m
ln
(
σ
)
−
m
2
ln
(
2
π
)
−
m
2
ln
(
α
)
=
−
1
2
σ
2
∑
i
=
1
m
(
y
i
−
y
^
i
)
2
−
1
2
α
2
w
2
+
C
=
−
M
S
E
−
1
2
α
2
w
2
+
C
则我们的目标是最大化
ln
L
\ln L
lnL,即最小化
M
S
E
+
1
2
α
2
w
2
MSE + \frac{1}{2\alpha^2}w^2
MSE+2α21w2。我们将
1
2
α
2
w
2
\frac{1}{2\alpha^2}w^2
2α21w2称为正则项,它可以防止过拟合。我们可以将正则项加入到损失函数中,得到正则化的损失函数:
ℓ
=
M
S
E
+
1
2
α
2
w
2
=
M
S
E
+
1
2
α
2
∥
w
∥
2
\ell = MSE + \frac{1}{2\alpha^2}w^2 =MSE+\frac{1}{2\alpha^2}\Vert w \Vert_2
ℓ=MSE+2α21w2=MSE+2α21∥w∥2
其中,
∥
w
∥
2
\Vert w \Vert_2
∥w∥2为L2范数,那么
∂
L
∂
w
=
∂
M
S
E
∂
w
+
1
α
2
w
=
λ
w
+
1
2
σ
∑
i
=
1
m
x
i
(
y
i
−
y
i
^
)
最后就可以使用该梯度公式和梯度下降算法更新参数。
该线性模型为Ridge Regression\
为什么假设正态分布:因为正态分布的一个特性是参数在均值(0)附近的概率很大,也就意味着至少部分特征 x i x_i xi的系数绝对值较大,模型在损失函数和数据的帮助下就可以从数据中选择出会影响结果的特征,这一点在特征的选择中尤为明显。
从概率论的角度来看待正则项:我们通过假设参数服从某一分布,就是对参数的分布做一个先验概率估计,从而排服从预估计分布的参数
如果假设的先验概率不是正态分布,而是拉普拉斯分布,
w
∼
L
a
p
l
a
c
e
(
μ
,
b
)
w\sim Laplace(\mu,b)
w∼Laplace(μ,b)
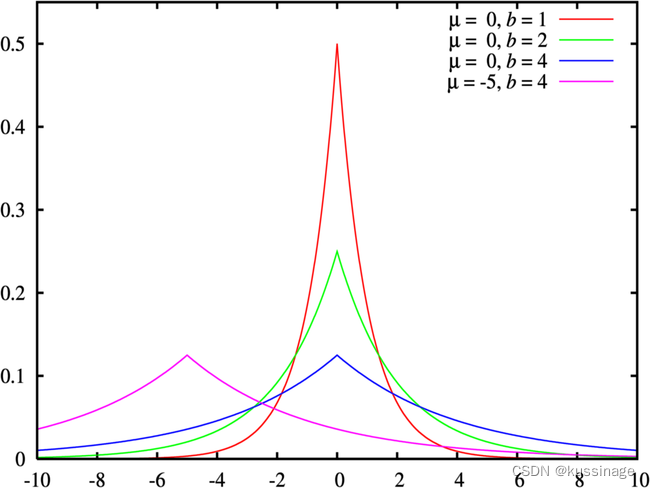
那么正则项就会变成L1范数
ℓ
=
M
S
E
+
∥
w
∥
1
\ell=MSE+\Vert w\Vert_1
ℓ=MSE+∥w∥1
此时该线性模型即是Lasso模型
- 美食网页代码 ...
赞
踩


