
热门标签
热门文章
- 1C#中Winform使用OpenFileDialog选择文件打开并获取文件路径_通过openfiledialog选择文件路径
- 2react项目内存溢出,加大内存的方式之一 Ineffective mark-compacts near heap limit Allocation failed - JavaScript heap_vscode的react项目内存溢出
- 3Redis实现分布式锁的原理:常见问题解析及解决方案、源码解析Redisson的使用_分布式事务redis解决方案
- 42024永久免费版CrossOver软件下载及使用方法详细的步骤_crossover安装包
- 5guitar pro 8许可证忘记了怎么办 guitar pro8谱数字可以改吗
- 6基于微信学生新生报到小程序系统设计与实现
- 7ROS Motion Planning运动规划库安装方法及进阶使用方法详细介绍
- 8pom可视化idea_GitHub - haizlin-idea/rsbi-pom: 睿思BI-数据仪表盘,开源商业智能,数据可视化系统...
- 9在CDH集群安装Flink
- 10单片机学习笔记---独立按键控制LED亮灭_单片机按键控制led灯亮灭
当前位置: article > 正文
GpuMall智算云教程:ChatGLM3-6B 对话预训练模型_chatglm3—6b怎么训练
作者:很楠不爱3 | 2024-05-23 17:37:15
赞
踩
chatglm3—6b怎么训练
#大模型##GpuMall智算云#
#算力##租赁#
1. 选择 ChatGLM3-6B 镜像创建实例
提示
训练 ChatGLM3-6B 模型,显卡显存建议选择等于大于 16GB 以上的显卡,因为 ChatGLM3-6B 模型载入后会占用大约 13GB 左右显卡显存。
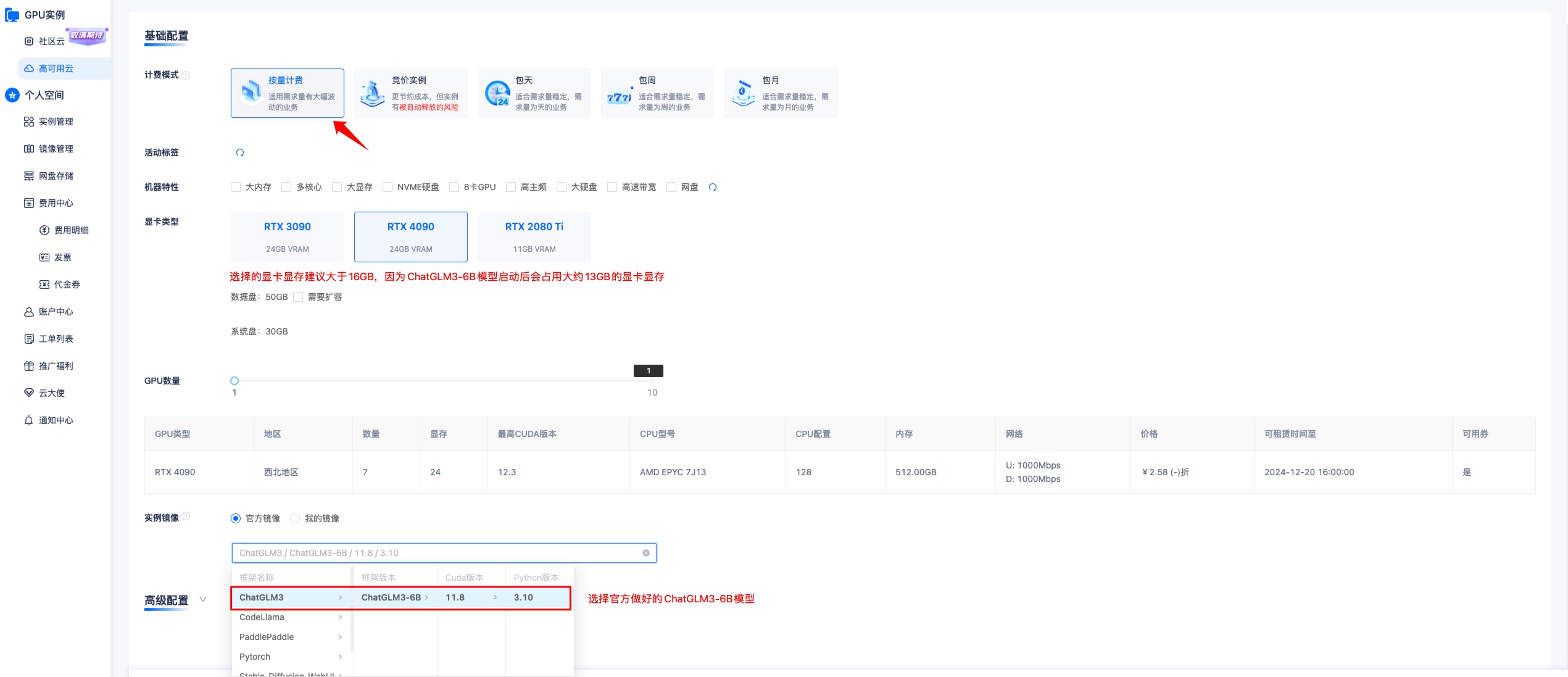
选择完成后创建实例,然后点击 JupyterLab,进入终端。

2. 通过内网拉取 ChatGLM3-6B 模型
执行如下命令拉取 ChatGLM3-6B 模型
- curl -fSLO https://gpumall-static-data-public-prod.oss-cn-shanghai.aliyuncs.com/platform/instance/downmodel
- chmod +x downmodel
- ./downmodel chatglm3-6b-model
通过上述操作拉取的模型会存储在
/gm-data/chatglm3-6b目录下,不建议移动,ChatGLM3-6B 代码中已指定模型路径为/gm-data/chatglm3-6b。
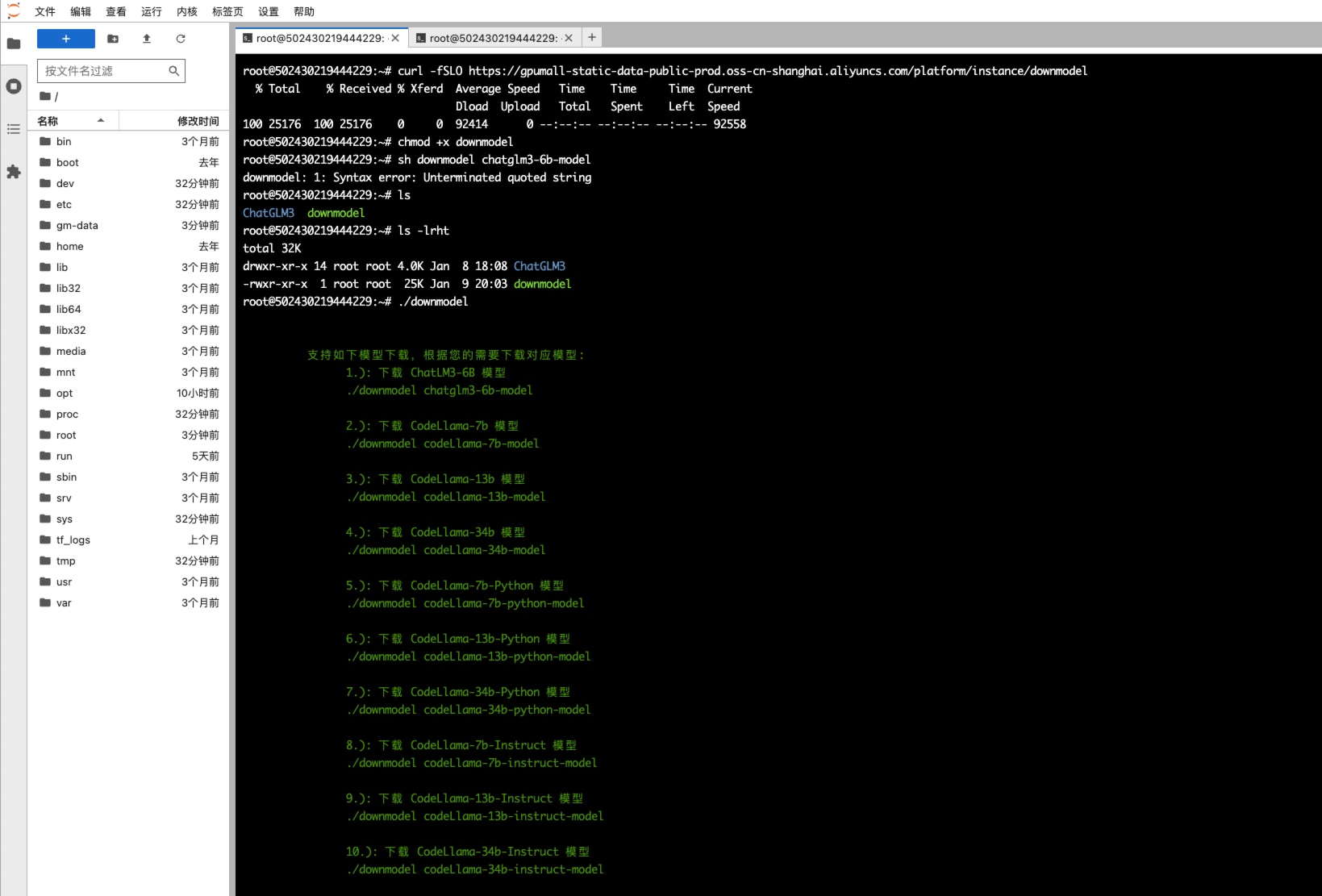
然后等待模型全部下载完成
3. 启动 ChatLM3-6B
ChatGLM3-6B 支持如下几种启动方式:
- #查看虚拟环境
- conda info -e
- # conda environments:
- #
- base /usr/local/miniconda3
- ChatGLM3 /usr/local/miniconda3/envs/ChatGLM3
-
- #切换到 ChatGLM3虚拟环境
- conda activate ChatGLM3
-
- #执行启动脚本会打印支持的几种启动方式
- /root/ChatGLM3/start.sh
-
- 支持如下几种启动方式,根据您需要选择一种启动方式即可:
- 方式一): Web 网页版对话,通过 Gradio 所生成的地址进行公网访问(国内网络访问可能稍慢),监听8501端口
- /root/ChatGLM3/start.sh web_gradio
-
- 方式二): Web 网页版对话,通过 GpuMall 平台自定义服务方式进行公网访问,监听8501端口
- /root/ChatGLM3/start.sh web_streamlit
-
- 方式三): 命令行对话,该选项可在命令行与 ChatGLM3-6B 进行交互对话
- /root/ChatGLM3/start.sh terminal
-
- 方式四): API 接口方式启动,对该接口进行调用,调用地址通过 GpuMall 平台自定义服务方式所提供的公网地址进行调用
- /root/ChatGLM3/start.sh openapi

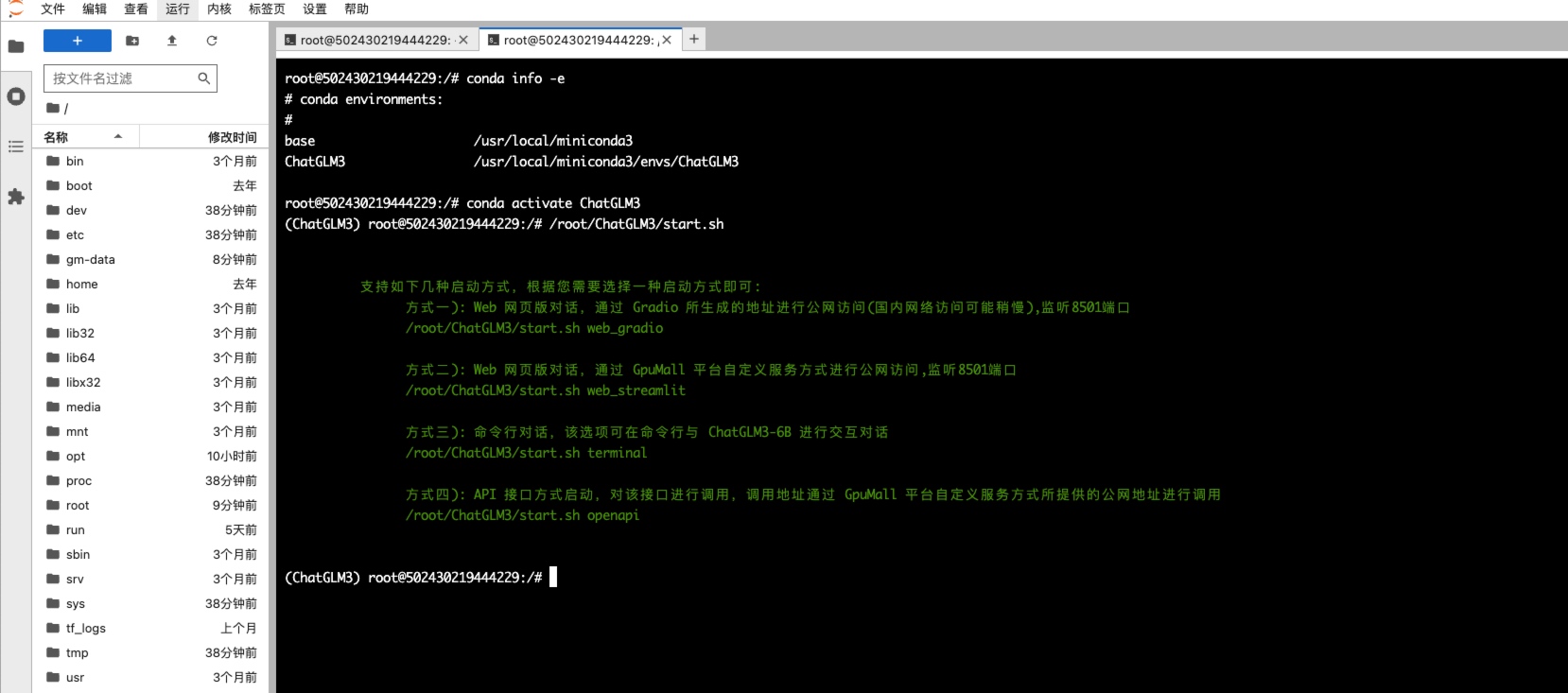
下面会依此演示以上四种启动和通过外网访问方式,根据自己需求选择任意一种即可(通过 API 调用访问方式用的较多)。
3.1 通过Gradio启动
通过 Gradio 方式启动,Gradio 会自动创建一个公网访问链接。
- /root/ChatGLM3/start.sh web_gradio
- Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:04<00:00, 1.66it/s]
- Running on local URL: http://127.0.0.1:8501
- Running on public URL: https://21e9e47a93316d5515.gradio.live #复制该链接,该链接为Gradio自动生成的公网访问地址,有效期是72个小时
-
- This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from Terminal to deploy to Spaces (https://huggingface.co/spaces)
复制上述链接到浏览器进行访问使用
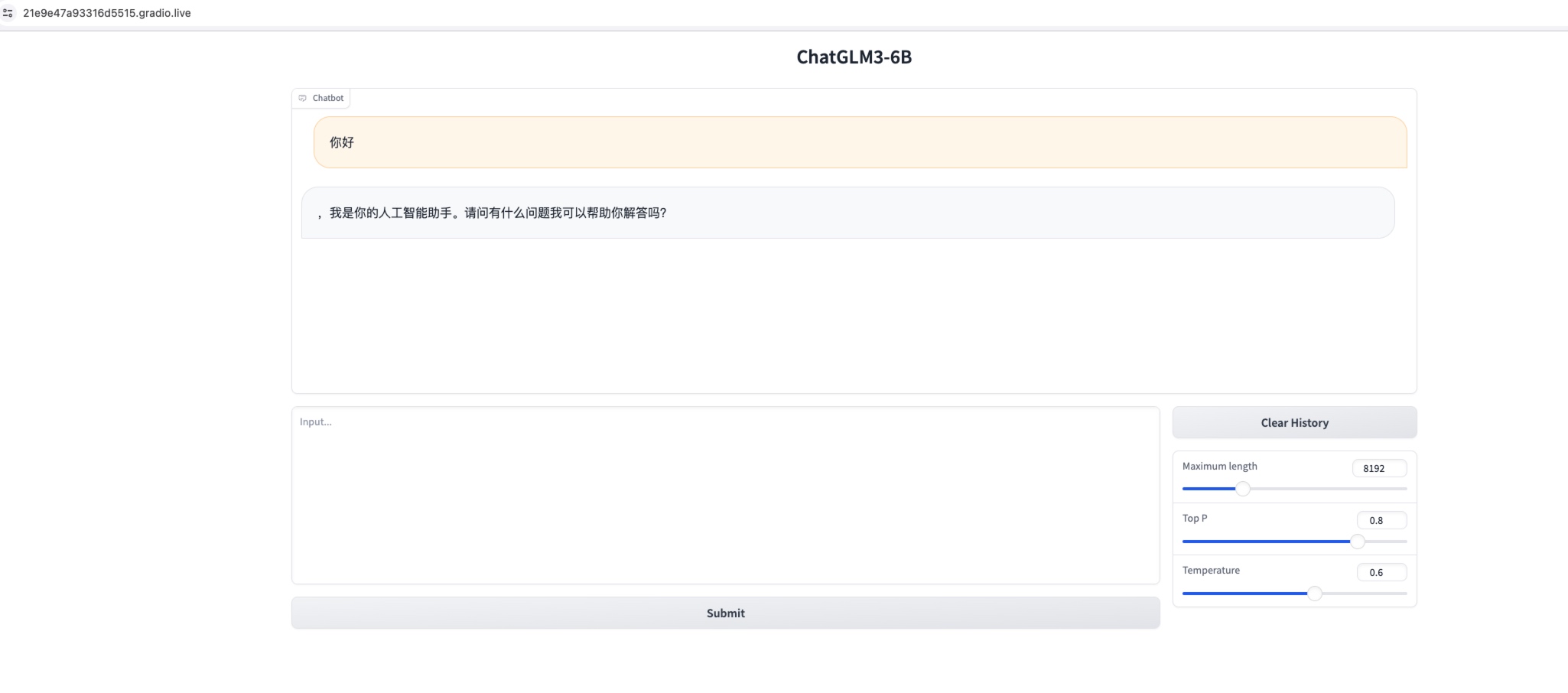
3.2 网页版启动
启动网页版,然后通过 GpuMall 平台的自定义服务进行访问
- /root/ChatGLM3/start.sh web_streamlit
-
- Collecting usage statistics. To deactivate, set browser.gatherUsageStats to False.
-
-
- You can now view your Streamlit app in your browser.
-
- Network URL: http://172.17.0.2:8501
- External URL: http://61.243.114.254:8501
启动后到 GpuMall 实例管理控制台,点击更多——》创建自定义端口。
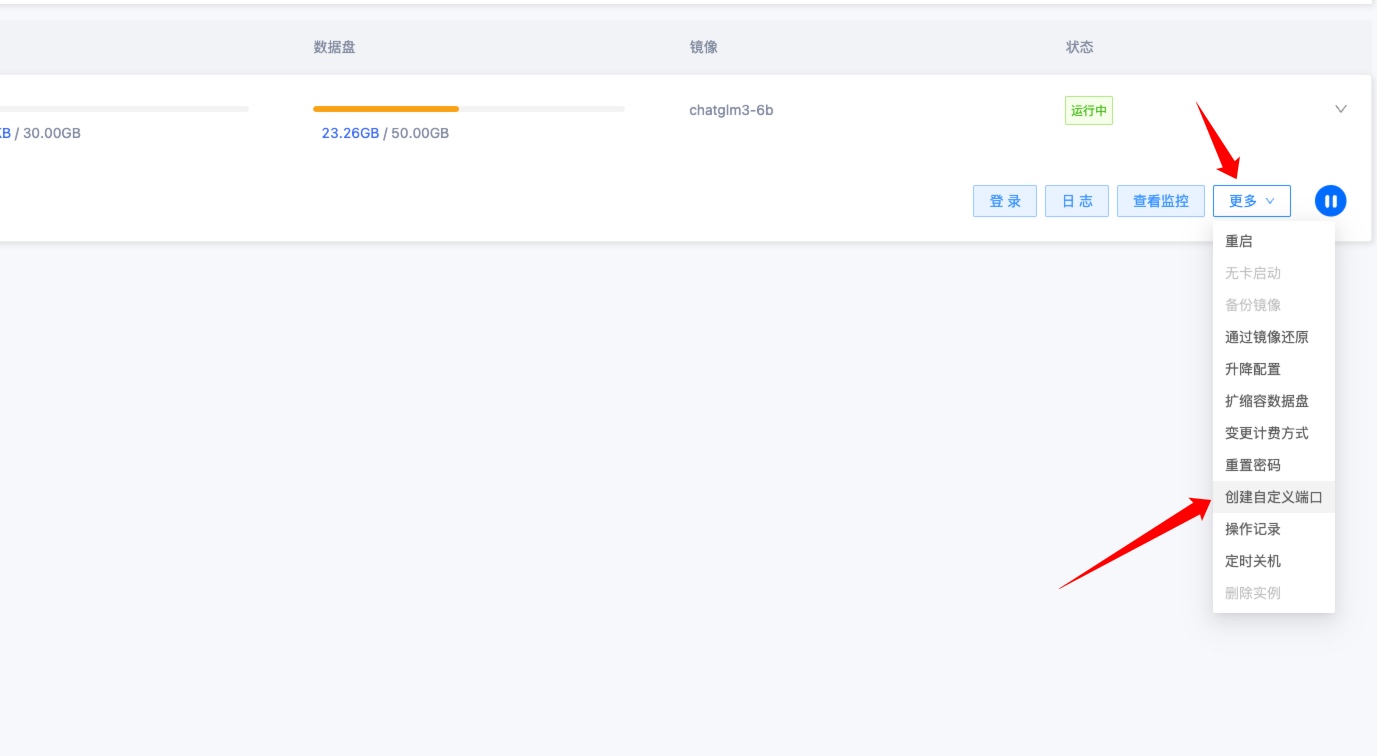
输入 8501,因为实例中的 ChatGLM3-6B 项目监听 8501 端口,然后点击确定。
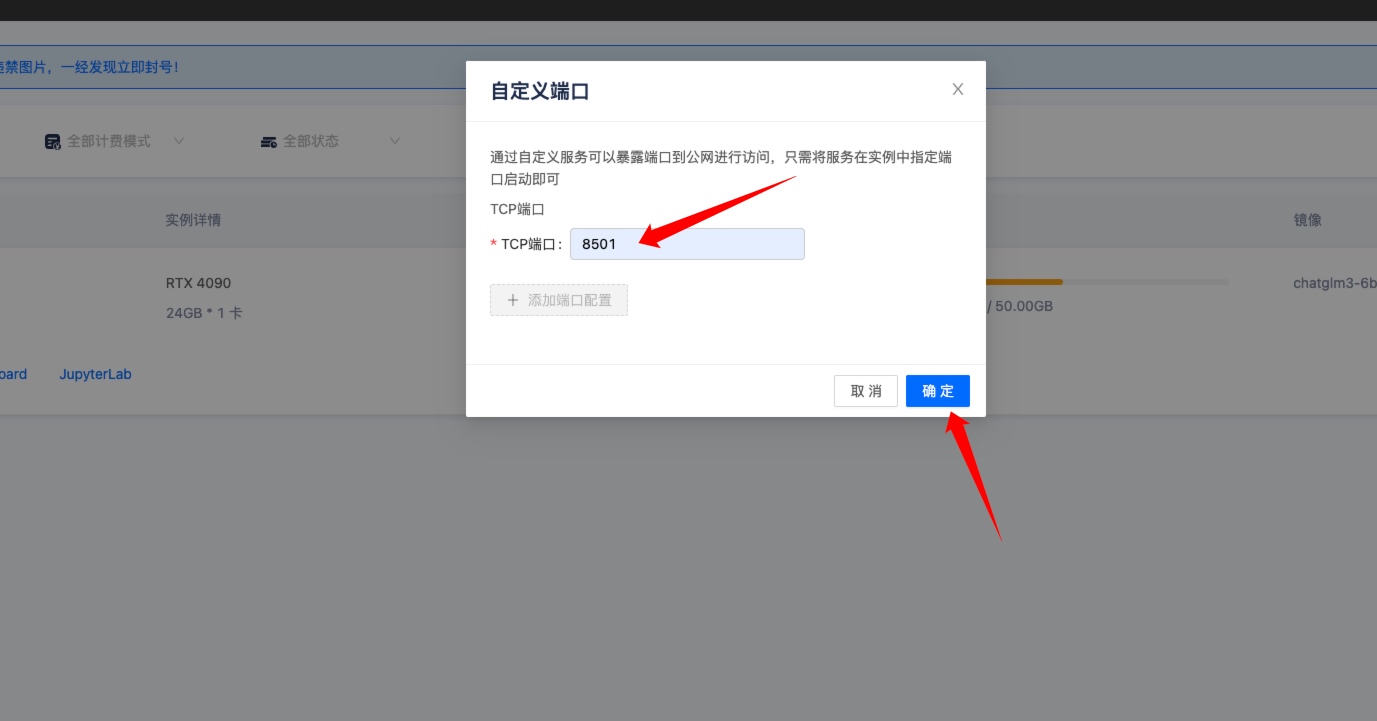
然后点击 自定义服务 跳转到公网访问网页页面地址。

跳转后开始使用
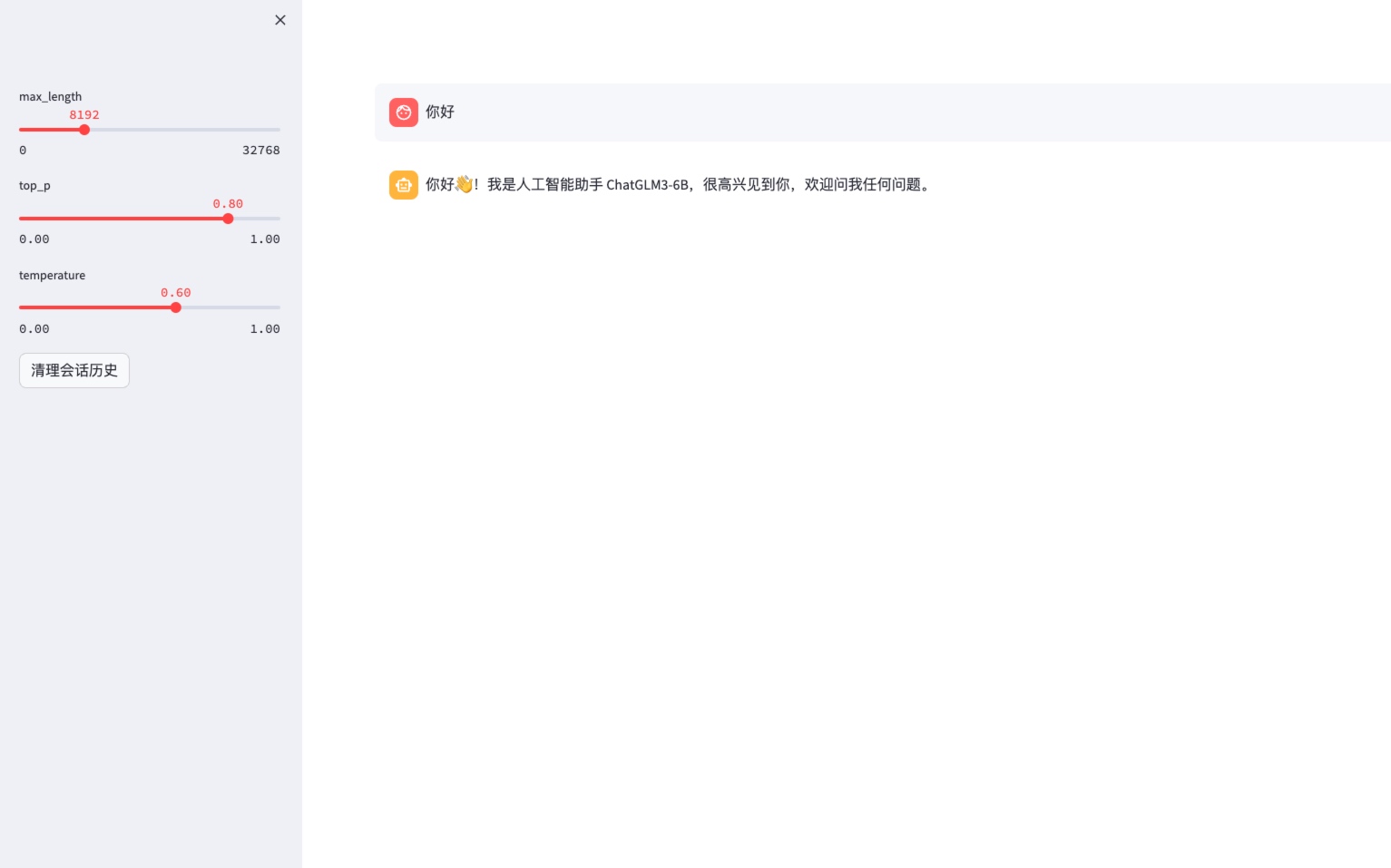
3.3 命令行对话
- root@502430219444229:~# /root/ChatGLM3/start.sh terminal
- Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:04<00:00, 1.65it/s]
- 欢迎使用 ChatGLM3-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序
-
- 用户:你好 #输入 文本内容
-
- ChatGLM:你好声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/很楠不爱3/article/detail/613807推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

