- 1selenium源码学习
- 2关系抽取任务常用数据集介绍_实体关系抽取数据集
- 3Superset,基于浏览器的开源BI工具
- 4Windows下MySQL服务启动常见的两种方式,完美适配Mysql5.7,MySql8.0_windows启动mysql
- 5解决eclipse中git插件中的cannot open git-upload-pack问题_eclipse.jgit.api 提示can not open git-upload-pack
- 6在docker上部署postgresSQL主从_docker postgrepsql
- 7QGLViewer+Qt5+VS2017开发环境搭建
- 8面向新闻评论课题笔记_如何进行新闻选题csnd
- 9深度学习与自然语言处理(4)_斯坦福cs224d 大作业测验1与解答_given dataset ! = {(%&,(&)}&+, - %: feature ve
- 10Docker 容器技术_docker容器技术
Pandas03
赞
踩
目录
数据修改

修改列名
将原 df 列名 Unnamed: 2、Unnamed: 3、Unnamed: 4 修改为 金牌数、银牌数、铜牌数
- import pandas as pd
- df = pd.read_csv('东京奥运会奖牌数据.csv')
- df.rename(columns={'Unnamed: 2':"金牌数",
- "Unnamed: 3":"银牌数",
- "Unnamed: 4":"铜牌数"},inplace=True)
修改行索引
将第一列(排名)设置为索引
df.set_index("排名",inplace=True)修改索引名(重置索引)rename_axis
修改索引名为 金牌排名
df.rename_axis("金牌排名",inplace=True)查询级别数
df.index.nlevels # 标题修改值
将 ROC(第一列第五行)修改为 俄奥委会
df.iloc[4,0] = '俄奥委会'修改类型
将【金牌数】列类型修改为int
- # 打开时定义数据类型
- df = pd.read_csv('东京奥运会奖牌数据.csv', dtype = {'column_name' : str})
-
- # 自定义的DataFrame
- df = pd.DataFrame(a, dtype='float') #示例1
- df = pd.DataFrame(data=d, dtype=np.int8) #示例2
-
- # 单列修改为数值
- df['金牌数'] = pd.to_numeric(df['金牌数'])
-
- # astype强制转换(两列)
- df[['金牌数','银牌数']] = df[['金牌数','银牌数']].astype(int)
替换值
- # 单值替换:将金牌数列的数字 0 替换为 无
- df['金牌数'].replace(0,'无',inplace=True)
-
- # 多值替换:将 无 替换为 缺失值 ;将 0 替换为 None
- import numpy as np
- df.replace(['无',0],[np.nan,'None'],inplace=True)
数据增加
新增列(固定值)
新增一列 【比赛地点】,值为 东京
df['比赛地点'] = '东京'新增列(计算值)
新增一列 【金银牌总数】列,值为该国家金银牌总数
- df = df.replace('None',0)
- df['金银牌总数']=df['金牌数'] + df['银牌数']
新增列(比较值)
新增一列 【最多奖牌数量】 列,值为该【金银牌】三列数量中最多的一个奖牌数量
例如中国金牌38,银牌32,铜牌18,最大值为38
- df['最多奖牌数量'] = df.bfill(1)[["金牌数", "银牌数",'铜牌数']].max(1)
-
- df['最多奖牌数量'] = df[["金牌数", "银牌数",'铜牌数']].max(1)
新增列(判断值)
新增一列 【金牌大于30】
如果一个国家的金牌数大于 30 则值为 是,反之为 否
- import numpy as np
- df['金牌大于30'] = np.where(df['金牌数']>30,'是','否')
增加多列
新增两列,分别是
-
金铜牌总数(金牌数+铜牌数)
-
银铜牌总数(银牌数+铜牌数)
df = df.assign(金铜牌总数=df.金牌数 + df.铜牌数,银铜牌总数=df.银牌数+df.铜牌数) 新增列(引用变量)
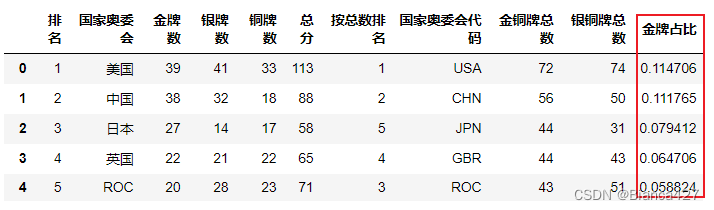
新增一列金牌占比,为各国金牌数除以总金牌数(变量:gold_sum)
eval()方法:可以借助列名称进行运算,不占用内存,可将字符串形式的字典列表等转换成字典列表
- gold_sum = df['金牌数'].sum()
- df.eval(f'金牌占比 = 金牌数 / {gold_sum}',inplace=True)
Pandas学习笔记十——高性能的eval和query方法_盐味橙汁的博客-CSDN博客
append 新增一行(末尾追加)
在 df 末尾追加一行,内容为 0,1,2,3… 一直到 df 的列长度
- df1 = pd.DataFrame([[i for i in range(len(df.columns))]], columns=df.columns)
- df_new = df.append(df1)
新增行(指定位置)
在第 2 行新增一行数据,即美国和中国之间。
- df1 = df.iloc[:1, :]
- df2 = df.iloc[1:, :] # 拼接上第二行后的数据
- df3 = pd.DataFrame([[i for i in range(len(df.columns))]], columns=df.columns)
- df_new = pd.concat([df1, df3, df2], ignore_index=True) # 时忽略原本的索引,从0开始重建索引。
drop数据删除
删除指定行
删除 df 第一行
df.drop(1)删除条件行
df.drop(df[df.金牌数<20].index)删除列
删除刚刚新增的 【比赛地点】 列
df.drop(columns=['比赛地点'],inplace=True)删除列(按列号)
删除 df 的 7、8、9、10 列
df.drop(df.columns[[7,8,9,10]], axis=1,inplace=True)数据筛选
iloc 筛选列
通过列号
提取第 1、2、3、4 列
df.iloc[:,[0,1,2,3]]通过列名
提取 金牌数、银牌数、铜牌数 三列
df[['金牌数','银牌数','铜牌数']]条件(列号)
筛选全部 奇数列
df.iloc[:,[i%2==1 for i in range(len(df.columns))]]条件(列名包含指定值)
提取全部列名中包含“数”的列
- df.loc[:,df.columns.str.contains("牌")]
-
- df.loc[:,df.columns.str.endswith("数")] # 结尾包含“数”
-
- df.loc[:,df.columns.str.startswith("国")] # 开头包含“数”
组合(行号+列名)
提取倒数后三列的10-20行
df.loc[10:20, '总分':] loc 筛选行
通过行号
提取第10行
df.loc[9:9]通过行号(多行)
提取第 10 行之后的全部行
df.loc[9:]固定间隔
提取 0-50 行,间隔为 3
df[:50:3]判断语句
- # 提取 【金牌数】 大于 30 的行
- df[df['金牌数'] > 30]
-
- # 提取 【金牌数】 等于 10 的行
- df[df['金牌数'] == 30]
-
- # 提取 【金牌数】 不等于 10 的行
- df[df['金牌数'] != 39]
- df.loc[~(df['金牌数'] == 39)]
条件(指定行号)
提取全部 奇数行
- df[[i%2==1 for i in range(len(df.index))]]
-
- df.loc[[i%2==1 for i in range(len(df.index))]]
isin 筛选(指定值)
提取 中国、美国、英国、日本、巴西五行数据
df[~df.'国家奥委会'.isin(['中国','美国'])]~逆向筛选
提取除了中国和美国的其他行数据
df[~df.'国家奥委会'.isin(['中国','美国'])]pandas.isin 用来清洗数据,过滤某些行,或者说选出你想要的某些行。
多条件
在上一题的条件下,新增一个条件:金牌数小于30
df.loc[(df['金牌数']<30)&df['国家奥委会'].isin(['中国','美国','英国','日本','巴西'])]条件求和(不适用groupby)
当【是否外市户籍】列为【是】时求和【金额】列
- # 三种方法
- print(df[df['是否外市户籍']=='是']['金额'].sum())
- print(sum(df[df['是否外市户籍']=='是']['金额']))
-
- import numpy as np
- print(np.where(df['是否外市户籍']=='是', df['金额'],0).sum())
条件计数
求【是否外市户籍】列为【是】的次数
print(df[df['是否外市户籍']=='是']['是否外市户籍'].count().tolist()组合筛选
筛选某行某列
提取第0行第2列
- df.iloc[0:1,1:2]
-
- df.iloc[0:1,[1]]
筛选多行多列
提取 第0-2行 第0-2列
- df.iloc[0:2,0:2] # : 连续范围
-
- df.iloc[0:2,[0,1]] # [] 可指定范围
组合(行号+列号)返回值
提取第4行,第4列的值
df.iloc[3,3] # 返回21at 组合(行号+列号)返回值
提取第4行,第4列的值
df.at[4,'金牌数'] # 返回20条件返回值
提取 【国家奥委会】 为 【中国】 的金牌数
- df.loc[df['国家奥委会']=='中国'].loc[1].at['金牌数']
-
- # df['国家奥委会']=='中国'] 返回布尔值
- # loc[1] 返回第一行True值
- # loc[1].at['金牌数'] 获得行列
query 计算式条件查询
df.query(expr, inplace=False, **kwargs)
参数:
-expr:查询条件,表达式
-inplace :是否替换原数据,默认为false
query方法可用方法是基于DataFrame列的计算代数式,对于按照某列的规则进行过滤的操作。
字符串仅在列名没有任何空格时才有效。所以在应用该方法之前,列名中的空格被替换为“_”
df.query('金牌数+银牌数>15')query(引用变量)
使用 query 提取 金牌数 大于 金牌均值的国家
- gold_mean = df['金牌数'].mean()
- df.query(f"金牌数>{gold_mean}")
select_dtypes筛选数据类型
select_dtypes 可以筛选数据类型的列

筛选数值类型的列
df4.select_dtypes(include=['int64']) 
多类型筛选(数据类型为和浮点数)
df4.select_dtypes(include=['int64','float64'])
逆向筛选
df4.select_dtypes(exclude=['int64','float64'])
groupby 数据分组
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=NoDefault.no_default, observed=False, dropna=True)
根据一定的规则拆分为多个组合,并应用不同的函数进行计算
- df[['地区','薪资']].groupby(by='地区').mean()
-
- # 取【地区】和【薪资】两列,按地区分组邱平均
as_index 分组取消索引
df.groupby("district",as_index=False)['salary'].mean()sort_values 排序
计算并提取平均薪资最高的地区
两列分组,先地区求平均值,排序
df[["district","salary"]].groupby(by='district').mean().sort_values('salary',ascending=False).head(1)
频率value_counts/size
计算不同行政区(district),不同规模公司(companySize)出现的次数
- pd.DataFrame(df.groupby('district')['companySize'].value_counts())
- pd.DataFrame(df.groupby(["district","companySize"]).size())
- # 效果一样
计数count
统计每个【区】出现的【公司】数量
等同于筛选district 计数 companySize
df.groupby("district")['companySize'].count()分组查看
查看各组信息groups
将数据按照 district、salary 进行分组,并查看各分组内容
相当于筛选district、salary
df.groupby(['district','salary']).groups
查看指定条件信息get_group
将数据按照 district、salary 进行分组,并查看西湖区薪资为 30000 的工作
等同于筛选【district=西湖区】【salary=30000】的值
df.groupby(["district",'salary']).get_group(("西湖区",30000)) # 接收元组分组规则
分组筛选统计
根据【createTime 】列,计算每天不同 【district】 新增的岗位数量
等同于筛选两列计数
- # createTime列提取每天,根据【createTime】、【district】日期和行政区分组计算个数
- # 1
- pd.DataFrame(df.groupby([df.createTime.apply(lambda x :x.day)])["district"].value_counts()).rename_axis(['发布日','行政区'])
-
- # 2
- pd.DataFrame(df.groupby([df['createTime'].apply(lambda x :x.day)])["district"].value_counts()).rename_axis(['发布日','行政区'])
-

分组筛选计算包含总数
计算各行政区district的企业领域industryField包含【电商】的总数
两列分组,industryField
- # 统计每行中(apply)包含(contains) “电商” 字符 的数量
- pd.DataFrame(df.groupby(['district'])["industryField"].apply(lambda x:x.str.contains("电商").sum()))
-
- # 分组查看包含"电商"的行
- df[["district","industryField"]].loc[df['industryField'].str.contains("电商")]
-
- # 单列包含"电商"的次数
- df[["district"]].loc[df['industryField'].str.contains("电商")].count()


![]()
通过字符长度分组
通过 positionName 的长度进行分组,并计算不同长度岗位名称的薪资均值
pd.DataFrame(df.set_index("positionName").groupby(len)['salary'].mean())通过字典进行分组
将 data1和 data3分为组1,data2和 data4分为组2,同组求和
df.groupby({'data1':1,'data2':2,'data3':1,'data4':2},axis=1).sum()将 score 和 matchScore 的和记为总分,与 salary 列同时进行分组,并查看结果
- # axis按列求和
- df.groupby({'salary':'薪资','score':'总分','matchScore':'总分'}, axis=1).sum()

通过多列
计算不同【工作年限】(workYear)和 【学历】(education)之间的【薪资】均值
pd.DataFrame(df['salary'].groupby([df['workYear'],df['education']]).mean())分组转换transform
在原数据框 df 新增一列,数值为该区的平均薪资水平
df['该区平均工资'] = df[['district','salary']].groupby('district').transform('mean')分组聚合统计agg
df.groupby("district")['salary'].agg("mean")分组过滤filter
提取平均【工资】小于30000的行政区的全部数据
df.groupby('district').filter(lambda x:x['salary'].mean()<30000)数据(列表)展开explode
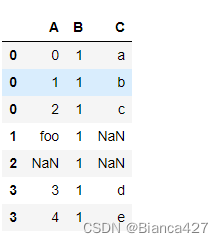
explode :如果数据中包含列表,使用explode进行展开,将list拆分多行

展开A列
df5.explode('A')
展开多列
- # pandas版本 >= 1.3 才可以完成
- df5.explode(list('AC'))
聚合统计
计算指标
分组计算不同行政区,薪水的最小值,最大值和平均值
- # 多个用列表 [ ]
- import numpy as np
- df.groupby('district')['salary'].agg([min,max,np.mean])
通过agg修改列名
修改列名和索引名
df.groupby('district').agg(最低工资=('salary','min'),最高工资=('salary','max'),平均工资=('salary','mean')).rename_axis(['行政区'])组合计算
对不同岗位(positionName)进行分组,并统计其薪水(salary)中位数和得分(score)均值
- # 用花括号 { }
- df.groupby('positionName').agg({'salary':np.median,'score':np.mean})
多层统计
对不同【行政区】进行分组,并统计【薪水】的均值、中位数、方差,以及【得分】的均值
- df.groupby('district').agg(
- {'salary':[np.mean, np.median, np.std],'score':np.mean})
自定义函数
聚合计算时新增一列计算最大值与平均值的差值
- def myfunc(x):
-
- return x.max()-x.mean()
-
- df.groupby('district').agg(最低工资=('salary', 'min'), 最高工资=(
- 'salary', 'max'), 平均工资=('salary', 'mean'), 最大值与均值差值=('salary', myfunc)).rename_axis(["行政区"])
数据统计
均值、中位数、众数
- df.总分.mean() #均值
- df.总分.median() # 中位数
- df.总分.mode() # 众数:是一组数据中出现次数最多的数值
agg统计部分信息
计算 总分、高端人才得分、办学层次得分的最大最小值、中位数、均值
- df.agg({
- "总分": ["min", "max", "median", "mean"],
- "高端人才得分": ["min", "max", "median", "mean"],
- "办学层次得分":["min", "max", "median", "mean"]})

describe 统计完整信息
查看数值型数据的统计信息(均值、分位数等),并保留两位小数
df.describe().round(2).Tcorr 相关系数统计信息
也就是相关系数矩阵,也就是每两列之间的相关性系数
df.corr() diff 计算行之间的差异
格式:DataFrame.diff(periods= 1,axis = 0)
| periods | 控制要移动的小数点,默认为1 |

向上计算行之间的差异,第一行是NAN,因为之前没有要计算的值。从第二行开始,405-400=5,400-200=200
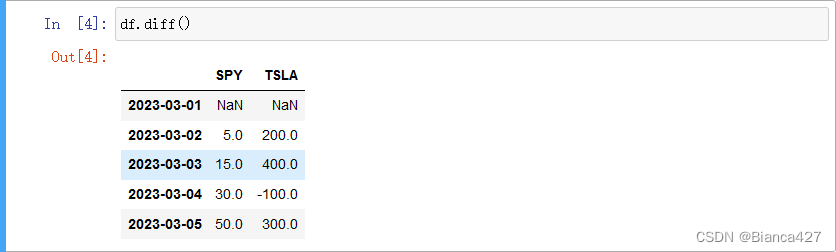
periods=1向下计算行之间的差异

pct_change 计算差值变化率
pct_change是计算差值变化率,相当于第二个减去第一个,再除以第一个,就是第二的数据
格式:DataFrame.pct_change(periods=1, fill_method=‘pad’, limit=None, freq=None, **kwargs)
- df=pd.DataFrame({"one":[1,3,5,7,9],"two":[2,4,6,8,10]})
-
- df.pct_change()
-

直接填充第一个为0, 保留两位小数
- df.pct_change().fillna(0).applymap(lambda x :format(x,'.2f'))
-
- # 百分比保留两位数
- df.pct_change().applymap(lambda x: format(x, '.2%'))

cunsum累加计算
cumsum 可以对数据按照指定方式进行累加,计算公式如下


按行/列累加
- df7[list('ABCD')].cumsum() #按列累加
- df7[list('ABCD')].cumsum(axis = 1) #按行累加

分组累加
将 df7 按照 item 按不同组对第 A 列进行累加
- df7 = df7.sort_values(['item']).reset_index(drop=True)
- df7['cumsum'] = df7.groupby('item')['A'].cumsum(axis=0)

nunique 统计指定轴上不唯一的元素数量

按列统计(B列1为重复值,剔除重复保留一个)
df6.nunique()
按行统计

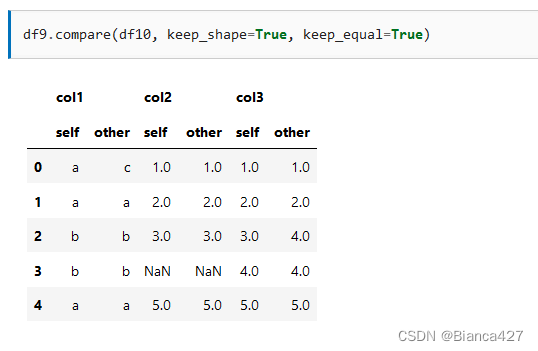
compare 比对两表数据(比较两个数据框之间的差异)
compare 用于比较两个数据框之间的差异

输出 df9 和 df10 的差异

保留数据框keep_shape

保留值 keep_equal