
- 1数据结构-图的概念与存储结构(类C语言版)_图的逻辑结构
- 2人工智能到底是什么?人工智能如何改变社会?中国的人工智能应该做怎样的探索?_1、人工智能究竟是什么? 2、人工智能距离我们还有多远? 3、机遇或挑战,我们如何应
- 3找回pop掉的内容_git stash pop出来的还能查到吗?
- 4图文并茂结合Java代码理解冒泡排序的原理_java冒泡排序动态原理图
- 5Python日志库logging总结-可能是目前为止将logging库总结的最好的一篇文章_python longing
- 6(转)zookeeper报错:NoNodeException: KeeperErrorCode = NoNode for /XXX Node does not exist_zk error: -101 no node
- 7左连接、右连接、内连接、外连接_外接之间的关系
- 8Ubuntu 2404发布
- 9Linux学习之进程_让父进程睡眠 3s 后输出该父进程 id 号、其父进程 id 号和变量值,查看变量在父子
- 10linux防火墙(二)—— iptables语法之选项和控制类型
Explainable link prediction based on multi-granularity relation-embedded representation_基于文本内容建模用户的语义兴趣表示,进而预测和解释用户之间的社交关系,是具有挑
赞
踩
现有的链接预测方法侧重于在网络结构方面挖掘节点的关系,而忽略了节点的丰富属性。在微博社交网络中,文本内容描述了用户的多样性行为,描述了用户的多维和多粒度偏好。因此,基于用户的多粒度兴趣,我们可以预测和解释用户之间的社会关系。在这项工作中,我们开发了一种可解释的社会关系提取方法,该方法基于用户兴趣的分层语义特异性矩阵。首先,根据用户的微博内容,我们对用户兴趣主题进行建模并设计它们的语义特异性矩阵。然后,根据兴趣主题,我们通过翻译机制学习多维多粒度语义特异性矩阵,它反映了用户对从多个方面遵循关系原因。最后,通过利用多粒度语义特异性矩阵,我们预测和解释用户的社会遵循关系。为了证明我们的建议,我们在新浪微博和腾讯微博数据集上进行了广泛的实验。实验结果表明,所提出的模型在 Hits、MeanRank 和 MRR 指标方面优于最先进的方法。该提议可以从多粒度兴趣主题方面有效地预测用户的跟随关系,提高社交网络中链接预测的准确性。
语义特异性矩阵->多粒度语义特异性矩阵->预测;
引言
如今,Facebook、Twitter、微博等在线社交媒体网站已经成为人们分享活动、情绪和意见的重要渠道[1]。在这些交互式活动中,用户的文本数据反映了他们的情感态度和兴趣倾向,已广泛应用于个性化推荐、情感分析和链接预测[2]等任务。事实上,基于文本内容的丰富语义,捕捉精细多样的偏好来分析用户之间的社会行为的直觉[3]。特别是在微博场景中,文本内容对于理解用户的偏好非常有用,有助于预测用户行为[4]。因此,大多数朋友推荐系统都调查了用户的兴趣并预测他们的社会跟随关系。
传统的推荐系统侧重于对用户个人资料进行建模并计算用户的兴趣相似性以发现相似的朋友。最近,深度神经网络极大地提高了用户兴趣轮廓建模和朋友推荐的性能[5]。许多深度神经网络 [5],例如卷积神经网络 (CNN)、循环神经网络 (RNN) 和长短期记忆 (LSTM),已应用于语义表示和链接预测领域。然而,基于深度神经网络的链接预测主要连接各种特征嵌入来进行朋友推荐,这没有考虑用户从多层次兴趣结构方面的语义兴趣。此外,一些作品通过利用实体的知识图结构来提取社会关系。例如,已经提出了知识表示学习来对实体的关系进行建模[6-11]。此外,其他一些研究人员在网络嵌入方面预测朋友链接,通过保留网络结构的特征来学习顶点的潜在特征到低维向量[12-16]。尽管取得了显着成就[17-19],但现有的网络表示方法专注于网络结构学习,而无需充分考虑丰富的节点信息,对用户之间的行为关系有明显解释。因此,直观的是,将用户兴趣信息与实体表示相结合可以帮助识别用户之间的朋友关系。
在微博场景中,用户的兴趣是多维和多粒度的,可以通过一个人的微博内容来反映。特别是,存在一种普遍现象,即用户对产品的粗粒度-词、短语或句子感兴趣;而其他一些用户可能更喜欢产品的细粒度方面。也就是说,不同的用户可能会关注同一产品的不同方面。因此,我们可以通过系分析多粒度兴趣方面的潜在关来挖掘用户的社会关系。例如,给定一个用户跟随对 u → v,它指示用户 u 跟随用户 v。当用户 u 对“篮球”感兴趣并且用户 v 更喜欢“足球”时,我们可以通过“体育”的语义关联来建模和解释它们的后续关系。此外,当两个用户对“篮球”感兴趣时,用户对的语义特异性关联比用户更喜欢“体育”更密切。这是因为主语“篮球”比“体育”具有明显的语义特异性。“篮球”的精细语义特异性可以提供比“体育”更好的解释,以了解关系u→v‘。换句话说,细粒度主题中的语义相关性可以很容易地指示用户之间的行为关系。
在本文中,为了解决上述问题,我们提出了一种名为 MGTransR 的多粒度关系嵌入表示学习方法来模拟用户之间的社会关系。通过引入多粒度语义特异性矩阵,该方法是 TransR [9] 模型的扩展和改进,可以表示不同语义空间中的实体和关系。具体来说,在微博社交网络中,基于用户的微博,我们首先使用 tf - idf 机制创建用户兴趣配置文件来描述用户对的显式兴趣主题。根据明确的兴趣主题,我们构建了多维语义特异性嵌入来模拟用户兴趣配置文件之间的关系。因此,我们利用翻译机制来学习多粒度兴趣主题的语义特异性矩阵。具有多维和多粒度兴趣主体的语义特异性矩阵可以解释用户之间的后续关系。然后,基于不同兴趣主体的语义特异性矩阵,我们从多粒度兴趣方面预测具有 MGTransR 的用户之间的社会跟随关系。最后,实验结果表明,与传统的网络嵌入方法和翻译模型相比,该方法取得了有效的改进。所提出的可以从细粒度的角度解释用户的社会跟随意图。
本文的贡献如下:
(1)我们通过文本内容的语义关联开发了一种社交关系提取方法。语义关联反映了用户的关系意图。
(2) 我们设计了一种具有语义特异性矩阵的 MGTransR 机制来预测用户之间的后续关系。多粒度语义特异性矩阵从细粒度的角度对用户对关系进行建模。
(3) 我们从多粒度兴趣主题方面解释用户的社交跟随关系。不同的兴趣主题在引出用户的后续关系方面扮演着不同的角色。
相关工作
基于网络嵌入的链接预测
网络嵌入方法旨在将网络映射到低维空间,可以有效地学习网络结构并进行准确的链接预测。早期网络嵌入方法被提出来学习顶点的潜在表示,如DeepWalk[12]、Line[13]、Node2vec[14]、SDNE[15]、Max-margin DeepWalk[18]。最近,一些研究通过考虑标签信息关注新的网络嵌入。通过提取异构网络的元路径特征,Li等人[20]提出了一种基于集成元路径特征的三层BP神经网络模型来实现监督链路预测。通过考虑多模态内容(例如视觉内容和文本描述)和社会链接,Huang 等人。 [21] 设计了一个基于注意力的多视图变分自动编码器来进行网络嵌入,可以捕获不同模态之间的细粒度相关性单词。基于信息效用,Wan等人[22]将社交媒体中的帖子视为一个项目,提出了一种信息朋友推荐方法。网络中的信息扩散可以对协作节点表示进行建模。Zhao等人[23]提出了一种用于信息级联预测的深度协同嵌入方法,该方法有望捕获节点的级联特征和节点的非线性特征。通过将关系和单词构造为图中的节点,Zhao等人[24]利用迭代消息传递机制融合两种类型的语义节点来建模关系提取任务的节点表示。
虽然节点的辅助信息增强了它们的语义表示,但它们并没有进一步解释辅助信息在链接预测结果中的不同作用。一些研究人员从邻居的结构中学习节点的表示,并研究节点之间的链接预测结果。Wang等人[25]通过整合对象的结构信息和类型,改进了空间图卷积网络,对异构信息网络中节点的嵌入表示进行建模,利用局部社区发现的最小信息丢失来进行链接预测。通过使用用户的潜在兴趣,Zhao等人[26]研究了一种高效的网络嵌入过程来模拟用户的社交和行为信息,提高了朋友推荐任务的有效性和效率。基于社区感知随机游走,Keikha 等人。 [27] 利用社交网络的局部邻域和全局结构设计了一种用于节点分类和链接预测的“CARE”网络嵌入方法。在社交网络中,相似用户之间的不同类型的连接可以以某种方式解释目标用户的决策。通过利用相关网络的知识,Yang等人[28]充分利用了集体智慧,提出了一种用于链路预测问题的自适应用户距离度量框架。Zhu等人[29]充分利用了数据集之间的交互,提出了一种新的异构网络链路预测分类算法推荐方法。
基于深度学习的链接推荐
最近,深度学习方法在推荐系统中取得了显着的成果。许多研究人员利用深度神经网络来提高推荐系统[30]的性能。在朋友链接推荐系统中,通过将深度学习与有偏随机游走相结合,Pradhan 等人设计了一个基于多级融合的模型来提出建议,称为DRACoR,它可以为目标用户提供具有相似兴趣的潜在合作者。关于节点的一些辅助信息可以帮助对用户进行链接预测并给出原因的解释。各种特征被合并到深度神经网络中,做出可解释的推荐,例如文本关键字、评论、先验知识和社会属性[32]。通过探索单词、评论和特征的不同重要性,Yang等人[33]在面向人群智能的分层注意网络方面设计了一种基于深度学习的准确和可解释的推荐方法。Zhang等人[34]通过构建项目生活风格的知识图并对预测结果进行解释,研究了用户项目和生活方式之间的联系。通过注意力机制考虑评论中特定句子的重要性,Xie 等人。 [35] 为具有句子级解释的用户开发了一种新的注意力偏好个性化推荐。此外,一些研究人员利用深度学习方法开发了知识图的可解释推荐工作。例如,通过将外部知识图表示纳入新闻推荐中,Wang et al.[36]开发了一个深度知识感知网络来进行点击率预测,可以有效地从知识层面挖掘新闻之间的潜在关系。在多维知识图框架的基础上,Shi等人[37]利用不同的学习路径来学习知识图中对象之间的语义关系。此外,一些工作已经证明了注意力机制在可解释链接推荐中的有效性。考虑到实体和关系的相关信息,Geng等人[38]利用多头注意机制方法结合卷积神经网络学习联合实体和关系提取的语义表示。
现有方法主要关注链接推荐的性能改进,而忽略了链接关系的动机。如何根据用户的多样化兴趣从不同的角度描述用户之间的关系是非常有意义的。在这项研究中,我们首先区分用户在不同方面的兴趣差异,并研究细粒度兴趣主题中用户之间的语义相关性。基于细粒度兴趣主题中单词或句子的不同贡献,我们解释了用户的社交跟随行为。
基于知识嵌入的关系提取
近年来,社交链接关系提取的研究引起了特别关注。在知识嵌入方面,一些研究采用知识图谱来利用关系提取任务。Bordes等人[6]提出了一种实体和关系的知识嵌入学习方法,称为TransE。Wang等人[8]提出了TransH方法,利用连续嵌入空间中关系的一些映射属性,如自反、一对多、多对一和多对多关系。假设一个实体可能有几个方面,不同的关系涉及多个方面,Lin等人[9]研究了单独语义空间中的实体和关系嵌入,如TransR。此外,一些研究人员开发了知识图关系补全的矩阵方法。通过创新的神经网络架构,Bordes 等人。 [39] 将符号表示引入连续向量空间中以增强原始知识。Socher等人[40]利用表达神经网络对实体之间的关系进行建模。基于多个矩阵乘积和 Hadamard 乘积,Bordes 等人。
提出了一种新的神经网络架构,将多关系图嵌入到连续向量空间中。Liao等人[42]提出了一种融合关系表示学习框架,将语义结构和语言表达特征(如统计共现或依赖语法)融合到实体和关系的嵌入中。一些研究利用知识实体的语义关系来挖掘用户的链接语义。通过考虑兴趣和社会因素,Xu 等人。 [3] 对用户偏好进行建模,为具有相似兴趣和密切社交链接的目标用户推荐前 n 名追随者。基于节点间交互的平移操作,Liu et al.[16]设计了一种基于翻译的网络表示学习方法来建模社会关系的丰富语义信息。通过考虑外部知识图嵌入,Wang et al.[43]设计了一个端到端波纹网络框架,以刺激用户偏好对用户潜在兴趣知识实体的传播。基于知识库的结构化和非结构化数据,Zhang等人[44]在TransR方面提出了协作知识库嵌入方法,利用异构语义信息,可以提高推荐系统的性能。
现有方法通过考虑特定方面顶点的语义,在社会关系提取方面取得了一些好的结果。然而,在社交网络中,由于用户行为是多维的,基于外部知识对用户配置文件进行建模对解释用户行为有显着影响。在这项研究中,我们根据外部知识库构建了具有多维和多粒度偏好的社交网络中用户兴趣概况,这有助于从多个兴趣方面解释用户之间的复杂行为关系。此外,将用户兴趣配置文件融合到知识嵌入学习中可以有效地预测和解释用户的社交跟随关系。
提出的MGTransR的总体框架
在本节中,我们给出了所提出的 MGTransR 框架,可用于学习社会跟随关系嵌入和实体嵌入。图 1 显示了 MGTransR 的总体框架
在图1中,整个框架主要包括三个关键组件,即用户兴趣profile矩阵建模、多维关系嵌入表示学习和多粒度关系嵌入表示学习。首先,给定一个用户对 (u, v),如果用户 u 跟在 v 之后,我们可以将以下关系定义为 ur→ v。根据用户对发布的/转发微博内容,我们可以通过 tf -idf 机制对每个用户的兴趣配置文件进行建模。考虑到两个用户的所有兴趣subject项目,我们可以对用户兴趣profile初始化subject的语义特异性矩阵。然后,基于多维兴趣subject,能学习u v的实体表示和具有翻译机制的r的关系嵌入,称为 MDTransR。对于用户profile不同subject的语义特异性矩阵在跟随关系空间中建模不同的映射向量。例如,根据兴趣subject ci,语义特异性矩阵 Mi 描述了subject ci 对用户对 (u, v) 的跟随关系的解释作用。最后,考虑到用户兴趣的层次语义,当存在粗subject ci 及其子孩子subject cij 时,我们可以进一步学习subject cij 的细粒度语义特异性矩阵 Mij。翻译机制也用于对顶点和边缘表示进行建模,称为 MGTransR。基于不同粒度的语义特异性矩阵和跟随关系的边缘表示,我们可以预测目标用户的潜在朋友实体。

方法
用户兴趣profile矩阵初始化
在微博社交网络中,用户微博发布/转发可以反映用户之间的关系意图。一般来说,当用户跟随另一个用户时,可能会转发或评论目标用户的微博。因此,微博内容可用于对用户的兴趣profile进行建模。对于社交网络 G =(V , E),给定用户对 (u, v) ∈ E,根据用户的微博内容,我们可以在特定领域提取多个subject(主题)来描述用户兴趣(轮廓)profile。用户兴趣轮廓可以通过一些subject主题在相关领域建立语义关系,从而诱导用户对的跟随行为。在本文中,我们采用 tf - idf 机制对用户兴趣轮廓进行建模,并构建兴趣主题的语义特异性矩阵来推断用户的跟随关系。
对于用户 u,令 Du = {s1, s1,., sk} 是一个人的微博文档集。对于句子 s ∈ Du,我们可以定义 s = {w1, w2,., wn}。对于每个单词 w ∈ s,TF-IDF 权重计算为等式:
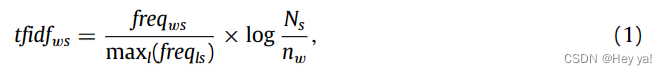
其中 freq_ws 是词 w 在微博 s 中的频率,max_l(freq_ls) 是词 l 在 s 中具有最大频率的频率。N_s 是微博句子的总数,n_w 是包含 w 的微博的数量。然后,考虑到用户的相关微博,定义用户u的词w 的内容兴趣度(content interest degree)为:
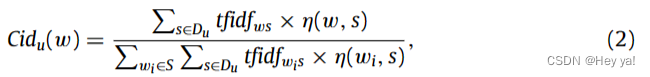
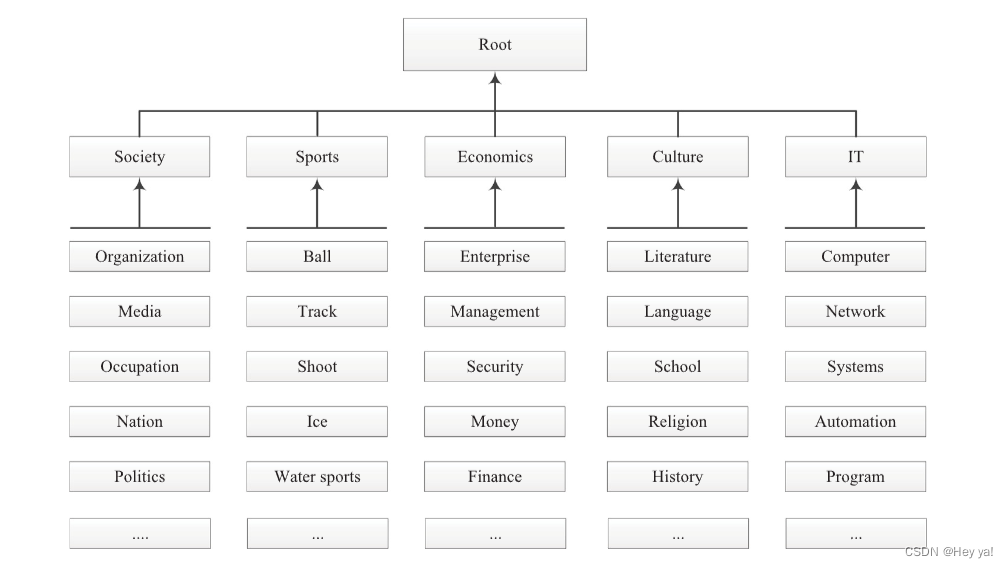
其中 S 是来源于基于类别C的本体知识中的主题集。如果 w ∈ s,η(w, s) = 1;否则,η(w, s) = 0。类别 C 涉及预定义的主题,例如社会、体育、经济学、文化、IT、自然、生活、历史、艺术、名人和地理,这些主题来自百度百科全书。图 2 显示了与五个主题相关的类别结构的一部分。
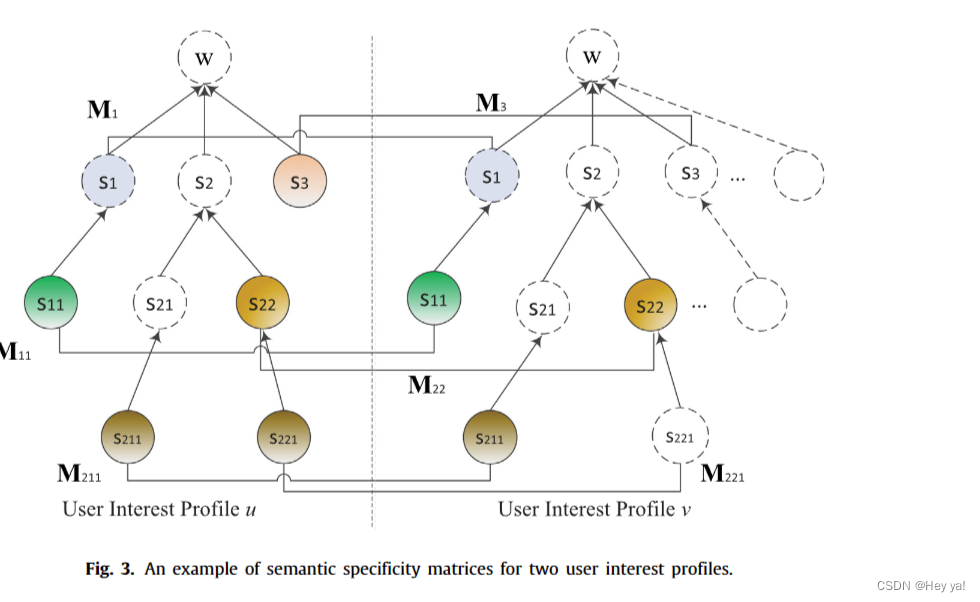
基于用户兴趣程度高的用户兴趣词,我们可以将它们与百度百科全书知识库中上述 11 个域的类别结构进行匹配。根据知识库及其类别结构中出现的感兴趣的主题,我们对用户的兴趣轮廓进行建模。用户兴趣轮廓是一个分层兴趣树,它描述了目标用户的不同领域的多粒度概念。不同层次的主题可以代表不同的语义特异性。对于用户对 (u, v),考虑到它们来自用户 u 和 v 的组合兴趣主题,我们通过相应矩阵初始化兴趣度最大的兴趣主题。每个主题 ID 都可以编码为矩阵。考虑到用户对 感兴趣的主题集,构建了多个语义特异性矩阵。语义特异性矩阵是学习参数。图 3 显示了用户兴趣轮廓对 及其语义特异性矩阵的示例。在图 3 中,由于用户兴趣轮廓哦 u 具有兴趣主题 s1、s3 和v具有 s1,我们可以分别为主题 s1、s3 分配初始化矩阵 M1、M3。然后,考虑到领域每个级别的主题,可以学习初始化的语义特异性矩阵来表示用户之间跟随关系的相关因素。
基于多维TransR的关系嵌入表示学习
给定一个跟随关系网络 G = (V , E),对于 u, v ∈ V 和 r ∈ E,我们可以将跟随关系三元组定义为 (u, r, v)。用户对 (u, v) 的语义表示可以通过翻译机制在实体空间和关系空间中学习。基于两个用户兴趣轮廓的语义特异性矩阵,我们可以从不同的兴趣方面解释用户的跟随关系。在本小节中,受 TransR [9] 的启发,我们通过实体的翻译机制利用来自不同兴趣方面的跟随关系。也就是说,对于以下关系三元组 (u, r, v),考虑粗粒度方面主题 c 的语义,我们利用它们的语义特异性矩阵 M_c 将用户实体 u, v 从实体空间映射到关系空间。基于特异性矩阵 M_c,我们将用户实体 u 和 v 的投影特异性向量定义为:

然后,u、v 和 r之间的翻译机制可以形式化为等式。 (5
![]()
考虑到对关系器上主语 c 的解释,用户对 (u, v) 的语义特异性距离可以相应地定义为等式。 (6)。
![]()
如图 3 所示,用户在第 l 层的兴趣主题可以从多维兴趣方面反映它们的后续关系。因此,可以通过为后续关系 r 建模不同的主题相关性来学习语义特异性矩阵。考虑到第 l 层的所有主题,我们可以最小化铰链损失来学习翻译部分,如下所示:
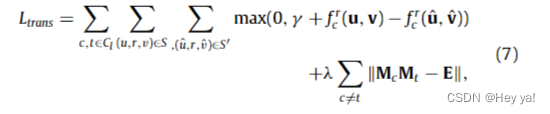
其中 Cl 是第 l 层的主题集,正交矩阵 Mc , Mt 用于从不同方面学习用户之间的后续行为。这里,γ > 0, λ > 0 是超参数。(ˆu, r,ˆv)是来自负采样集S '的负样本,如式(8)所示。
![]()
对于负样本过程,头部实体或尾部实体可以被其他用户随机替换,而无需遵循关系。基于上述思想,给定一个跟随关系三元组 (u, r, v),我们可以从多维兴趣方面分析和解释它们的后续关系 r,如 MDTransR。不同的语义特异性矩阵是正交的,这意味着用户之间遵循关系的不同原因。通过考虑两个用户配置文件对的最强语义特异性矩阵,我们可以在 4.4 节中预测具有 MDTransR 的用户之间的后续关系。
基于多粒度TransR的关系嵌入表示学习
具体来说,根据粗粒度给定主题,相应的语义矩阵对关系 r 进行了粗略的解释。由于用户兴趣配置文件具有分层兴趣主题结构,我们可以对不同粒度的语义关联进行建模,以表示细化的语义特异性。联合多粒度语义特异性矩阵从细化的语义兴趣方面解释用户遵循关系 r。
对于给定的主题 c 及其子主题集 Child(c),我们利用分层子类主题 ck ∈ Child(c) 详细解释以下关系 r。具体来说,根据主题 c 在粗粒度下的语义特异性矩阵 Mc,我们引入了另一个特异性矩阵 Mck 来表示细粒度主题 ck 的细化语义并学习遵循关系器,如 MGTransR。因此,我们通过突出细化语义的可解释贡献来重建用户实体的嵌入。然后,对于以下关系三元组 (u, r, v),细粒度通过语义特异性矩阵对用户实体 u 和 v 的投影向量可以定义为:

此外,根据翻译机制,用户对距离函数相应地表示为方程式。 (11)。
![]()
通过上述定义,考虑不同粒度的所有子主题 ci, cj,我们可以最小化铰链损失来学习方程式中的翻译部分。 (12)。
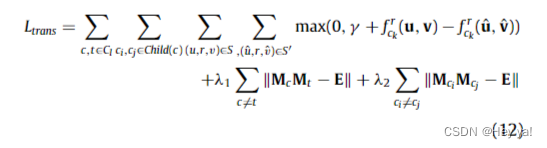
其中Mc、Mt是正交矩阵,Mci、Mcj也是正交的。它们可以确保学习到的不同语义来自不同的主题。同时,我们引入了两个超参数 λ1 和 λ2 来平衡特异性矩阵的语义差异。联合特异性矩阵 Mc 和 Mci 从粗粒度和细粒度兴趣主题方面解释了用户遵循关系。对兴趣主题的详细解释有助于理解用户对后续关系的链接预测结果。
社会关系解释
基于用户实体表示的翻译机制,语义特异性矩阵能够预测和解释用户用户之间的后续关系。
具体来说,给定一个用户对 (h, t),我们首先根据它们的微博内容获取用户的兴趣配置文件并标记他们的兴趣主题。根据感兴趣对象的多维语义特异性矩阵,我们可以根据 ^r = tMc - hMc 预测近似遵循关系分布。然后,输出层用于计算具有地面跟随关系 r 的分数,如 Score(MDTransR)。最后,考虑所有特异性矩阵,我们确定得分最高的主题来解释用户的后续行为。算法 1 给出了基于 MDTransR 方法的社会关系解释。在算法 1 中,步骤 3 初始化用户兴趣配置文件的语义特异性矩阵。第 6 步通过翻译机制学习语义特异性矩阵。步骤 8-12 确保获得最合适的主题来解释用户对之间的关系。
为了验证细化的主题特异性对用户之间的关系进行建模的有效性,我们进一步提出了细粒度的社会关系分数预测。根据多粒度语义特异性矩阵,我们将近似遵循关系分布预测为 ^r = tMc Mck -hMc Mck。然后,通过计算与地面跟随关系的相似分数作为 Score(MGTransR),选择得分最高的多粒度主题来解释用户对的后续行为。算法 2 给出了基于 MGTransR 的社会关系解释。
实验与分析
在本节中,我们将专注于回答几个研究问题来评估所提出的 MGTransR。研究问题包括:
• RQ 1:与最先进的方法相比,MGTransR 模型是否可以表现得更好链接预测结果?
• RQ 2:语义特异性矩阵是否可以准确反映用户对遵循关系?
• RQ 3:细粒度解释对于推荐结果是否合理?

