
- 1php curl 双向验证,php使用curl库进行ssl双向认证 | 酷客365
- 2UIChatBox模块示例demo_chatbox 搭档模板
- 3数据结构7:基本的二叉树遍历及题目_7-1 数据结构考题 二叉树的遍历-中序c语言编程题
- 4最详细的图文教程帮你解决GitHub下载慢或下载失败问题(2019.8.10亲测有效)_github下载失败需要用户验证
- 5Git进行pull request_git request-pull
- 6Hypervisor是什么_hypervisor的防御方法
- 7这个自然语言处理“工具”,玩得停不下来
- 8医学图像分析领域算法汇总_医学细胞图片算法
- 9ffmpeg控制crf转码压缩MP4等视频 (windows端/Linus端)&如何用ffmpeg批量压缩视频(windows端/Linus端)_linux ffmpeg 批量压缩
- 10【数据结构和算法初阶(C语言)】链表-单链表(手撕详讲单链表增删查改)_链表 删除 插入 c
Stable Diffusion Webui源码剖析_stable-diffusion-webui源码
赞
踩
1、关键python依赖
(1)xformers:优化加速方案。它可以对模型进行适当的优化来加速图片生成并降低显存占用。缺点是输出图像不稳定,有可能比不开Xformers略差。
(2)GFPGAN:它是腾讯开源的人脸修复算法,利用预先训练号的面部GAN(如styleGAN2)中封装的丰富多样的先验因素进行盲脸(blind face)修复,旨在开发用于现实世界人脸修复的实用算法。
(3)CLIP:Contrastive Language-Image Pre-Training,多模态方向的算法。可以训练出一个可以处理图像和文本的模型,从而使得模型可以同时理解图像和对图像的描述。
(4)OPEN-CLIP:一个开源的clip实现。
(5)Pyngrok:Ngrok工具的python实现,可以实现内网穿透
2、核心目录文件
(1)sd根目录下的repositories
存放算法源码
1)stable-diffusion-stability-ai:sd算法
2)taming-transformers:高分辨率图像合成算法
3)k-diffusion:扩散算法
4)CodeFormer:图片高清修复算法
5)BLIP:多模态算法
(2)sd根目录/models
存放模型文件
(3)sd根目录/extensions/sd-webui-additional-networks/models/lora
存放lora模型文件
3、参数初始化
进入webui.py的api_only()或者webui()函数时,已经完成了部分参数的初始化
Webui.py的依赖中有代码:from modules import shared
而shared.py中有如下代码:
opts = Options()
if os.path.exists(config_filename):
opts.load(config_filename)
config_filename对应cmd_opts.ui_settings_file,也就是根目录下的config.json文件
这些参数都将在程序正式运行前加载到shared.opts中
比如被选中的模型参数信息就有了。

4、webui之模型处理流程
(1)cleanup_models函数move模型文件
将models目录下的文件移到相关子目录下,比如ckpt文件和safetensors文件放到Stable-diffusion子目录下。
(2)启动SD模型setup_model流程
该模型位于:/data/work/xiehao/stable-diffusion-webui/models/Stable-diffusion
主要是通过list_models函数遍历所有的模型的信息并存到checkpoint_alisases中。
第1步,查看sd/models/Stable-diffusion下是否有cpkt和safetensors结尾的文件,有则放入model_list列表中,没有则从hugginface下载模型。
第2步,通过CheckpointInfo函数检查model_list中每个模型的checkpoint信息。如果是safetensors文件,通过read_metadata_from_safetensors读取文件信息。Safetensors模型的参数都存放在json中,把键值对读出来存放到metadata字段中。
第3步,最后把每个模型根据{id : 模型对象}的键值对存放到checkpoint_alisases全局变量中。
(3)启动codeformer模型的setup_model流程
该模型位于:/data/work/xiehao/stable-diffusion-webui/models/Codeformer
主要将Codeformer初始化之后的实例放到shared.face_restorers列表中。在此过程中并没有将模型参数装载到Codeformer网络中。
(4)启动GFPGAN模型的setup_model流程
(5)遍历并加载内置的upscaler算法
这些算法位于:/data/work/xiehao/stable-diffusion-webui/modules
遍历该目录下_model.py结尾的文件,通过importlib.import_module()进行加载,这一步未看到实际作用。
初始化以下放大算法[<class 'modules.upscaler.UpscalerNone'>, <class 'modules.upscaler.UpscalerLanczos'>, <class 'modules.upscaler.UpscalerNearest'>, <class 'modules.esrgan_model.UpscalerESRGAN'>, <class 'modules.realesrgan_model.UpscalerRealESRGAN'>],其中第1个没任何算法,第2-4是img.resize()方法实现的,第5、6个需要单独加载模型,数据都以UpscalerData格式存放,其中该对象的local_data_path存放了模型的本地地址信息。
比如:shared.sd_upscalers[5].local_data_path为:
'/data/work/xiehao/stable-diffusion-webui/models/RealESRGAN/RealESRGAN_x4plus_anime_6B.pth'
(6)加载py执行脚本load_scripts
遍历sd根目录/scripts下的py脚本 以及 extensions下各扩展组件的py脚本,放到scripts_list变量中,格式如下:ScriptFile(basedir='/data/work/xiehao/stable-diffusion-webui/extensions/sd-webui-controlnet', filename='processor.py', path='/data/work/xiehao/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/processor.py')
遍历并导入scripts_list中的类型为Script或ScriptPostprocessing的py文件:

Load_module(path)加载第三方组件时可能会输出日志信息:

(7)遍历VAE模型
目前没有装任何vae模型
(8)加载模型load_model
Select_checkpoint()函数,获取sd模型信息,majicmixRealistic_v4.safetensors/majicmixRealistic_v4.safetensors [d819c8be6b]
do_inpainting_hijack函数。设置PLMSSampler的p_sample_plms。关于该方法,重建图片的反向去噪过程的每一步的图片都应用了该方法。
get_checkpoint_state_dict函数。如果是safetensors则使用safetensors.torch.load_file加载模型参数,否则使用torch.load加载模型参数。加载到pl_sd的dict类型变量中。
pl_sd字典做进一步处理:如果最外层是state_dict的key,则取该key下的value。此时pl_sd下就是模型各个节点名及对应的weights值。然后替换下面的key值:

find_checkpoint_config函数。先从模型目录下找下yaml配置文件,如果没有则执行guess_model_config_from_state_dict函数,即从模型参数中获取模型配置,最后返回/data/work/xiehao/stable-diffusion-webui/configs/v1-inference.yaml作为配置文件,信息如下:

接着用OmegaConf.load加载yaml文件,然后通过/data/work/xiehao/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/util.py(82)instantiate_from_config()加载yaml信息获得model。具体步骤为:
步骤1,通过yaml的target信息,可以知道model为ldm.models.diffusion.ddpm的LatentDiffusion类。模型的源码位于:sd根目录/modules/models/diffusion/ddpm_edit.py。
步骤2,通过getattr(module的obj,class_name)获取model的类。
load_model_weights函数,将模型参数加载到模型中。通过model.load_state_dict(state_dict, strict=False)加载。因为程序参数no_half为false,所以模型量化需要从float32变为半精度tensor,half()的时候不对vae模块做处理。Vae模块为model.first_stage_model部分,所以先存到一个临时变量,half()量化完成后再赋值回去。Vae最后再单独变为float16。然后把模型放到cuda上。
Hijack函数,处理用户输入的embedding信息。假如给一个初始值,通过SD会生成未知的东西,我们通过添加额外的信息(比如prompts)让sd朝着我们想要的方向生成东西,这个就是劫持的功能,劫持是在embeddings层的。模型的embedding类为:transformers.models.clip.modeling_clip.CLIPTextEmbeddings,它的token_embeddings类为:torch.nn.modules.sparse.Embedding。
针对prompts的embedding处理类为:FrozenCLIPEmbedderWithCustomWords。约有4.9W个token。然后针对token的权重进行处理,普通单词为1.0, 中括号则除以1.1,小括号则乘以1.1.
指定优化方法apply_optimizations,通过xformers工具优化sd模型中的CrossAttention。(跨注意力机制是一种扩展自注意力机制的技术。自注意力机制是一种通过计算查询query、键key和值value之间的关联度来为输入序列中的每个元素分配权重的方法,而跨注意力机制则通过引入额外的输入序列来融合两个不同来源的信息以实现更准确的建模)。
load_textual_inversion_embeddings函数,加载根目录/embeddings下的embedding文件。加载[('/data/work/xiehao/stable-diffusion-webui/embeddings', <modules.textual_inversion.textual_inversion.DirWithTextualInversionEmbeddings object at 0x7ff2900b39d0>)]两个下的embeddings信息。比如:badhandv4、easynegative、EasyNegativeV2、ng_deepnegative_v1_75t等。
model_loaded_callback函数,遍历callback_map['callbacks_model_loaded']所有的回调函数,然后把sd_model模型传进去依次执行这些回调函数。比如/data/work/xiehao/stable-diffusion-webui/extensions/a1111-sd-webui-tagcomplete/scripts/tag_autocomplete_helper.py的get_embeddings方法,/data/work/xiehao/stable-diffusion-webui/extensions-builtin/Lora/scripts/lora_script.py的assign_lora_names_to_compvis_modules方法。
5、界面模式webui解读
(1)主框架
通过modules.ui.create_ui()方法构建ui界面
通过shared.demo.launch()方法启动ui界面。

(2)分页构建
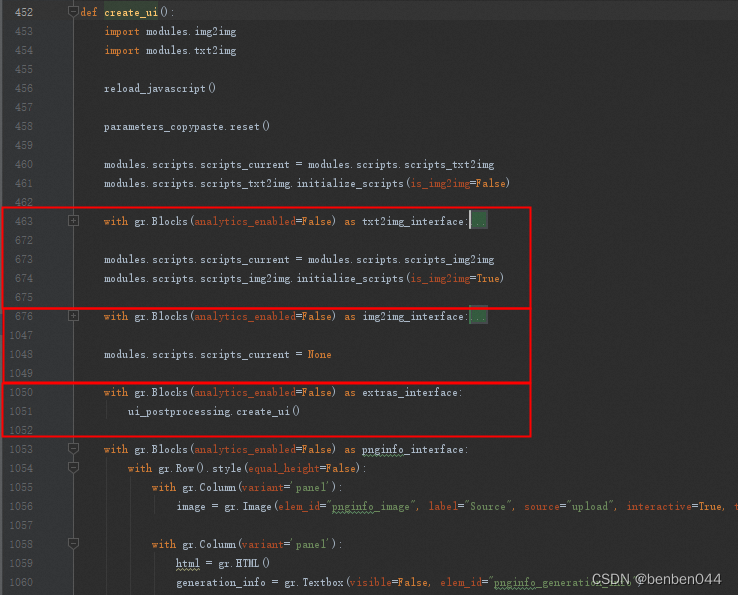
分页构建txt2img、img2img等的Tab。
6、txt2img的实现流程
在with gr.Blocks(analytics_enabled=False) as txt2img_interface:的第一行
通过create_toprow(is_img2img=False) 获得顶部输入框的按钮。
(1)Generate执行函数
“Generate”按钮对应“submit”变量。

程序把所有参数都传入inputs数组中,执行的方法是:wrap_gradio_gpu_call(modules.txt2img.txt2img, extra_outputs=[None, '', ''])。该方法的核心是modules.txt2img.txt2img,而wrap_gradio_gpu_call是给方法做了包裹。
(2)wrap_gradio_gpu_call执行函数
在wrap_gradio_gpu_call中,with queue_lock:可以看出,这一层包裹做的是排队。当有多个用户一起执行生成任务时,先来后到,先把任务入队,再根据获取锁的情况去放行,若排队等到就可以执行任务func(*args, **kwargs),返回的res就是执行的性能信息,比如cpu时间、内存、显存等。

(3)txt2img执行函数
func对应的就是输入的modules.txt2img.txt2img函数。
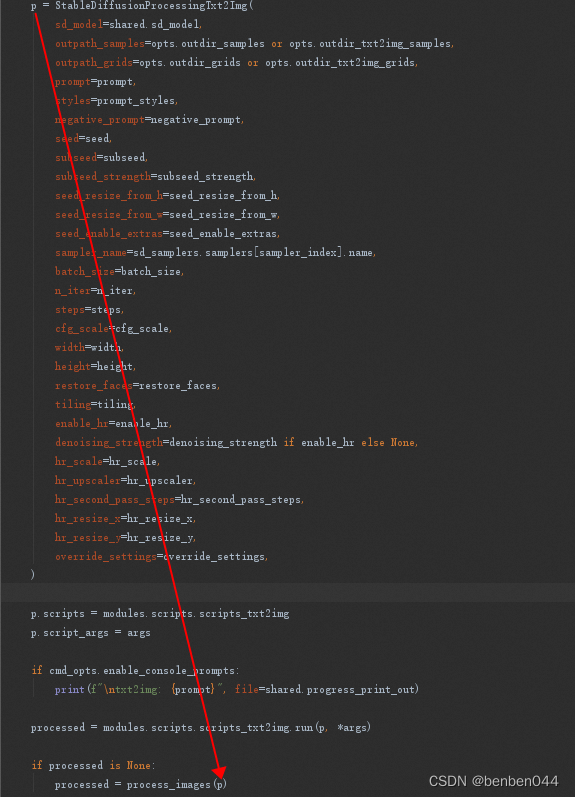
首先,通过StableDiffusionProcessingTxt2Img构建了一个对象p,然后通过process_images执行后返回processed,返回值processed.images就是生成的图片。
(4)StableDiffusionProcessingTxt2Img类的sample方法
首先初始化一个采样器,然后执行采样操作。

如果没有选择高清修复 self.enable_hr,那么直接返回这个采样结果。
(5)采样器创建create_sampler
根据名字读取配置构建采样器

(6)生成图片process_images
程序先加载sd模型和vae模型,然后调用process_images_inner生成多张图片。
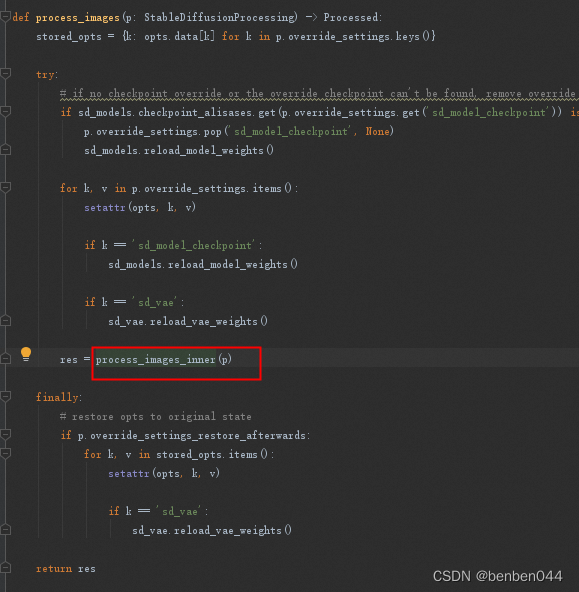
(7)process_images_inner函数
代码有250+行,从末尾往前看。
res 《-- output_images 《-- image 《-- x_sample 《-- x_samples_ddim 《-- samples_ddim
samples_ddim的定义如下:

p.sample用于迭代预测噪声并去除噪声,得到去噪后的图片的隐空间表示。
Decode_first_stage:上采样用于将隐空间转换到像素空间,samples_ddim的shape为[1, 4, 64, 64],x_samples_ddim的shape为[3, 512, 512]。

7、Lora功能的实现
在prompt中加入<lora: xxx>的字样,就可以加载lora模型。
(1)参数设置
Preload.py用于指定扩展的参数,只有一个参数—lora-dir,用于指定lora模型存放的地址。
![]()
(2)UI界面
在Lora/scripts/lora_scripts.py中实现了UI功能。
程序回调了on_model_loaded、on_script_unloaded、on_before_ui三个事件,on_before_ui便实现了UI相关功能,on_before_ui事件中回调了before_ui方法,before_ui方法给ui_extra_networks注册了页面ExtraNetworksPageLora。
ExtraNetworksPageLora主要是遍历lora模型,加载缩略图,而后返回信息。

(3)获取Lora列表
import lora时,会执行list_available_loras()函数。
该方法主要时遍历文件列表,然后将lora模型的信息保存到available_loras列表中。
(4)Lora模型实现
1)原理说明
Lora模型的原理中文表述为:学习理解一系列图片中的特征,能够将学习到的人物、动作、艺术风格、造型等特征良好地复刻并还原到作品中。
原理数学概述为:通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
在涉及到矩阵相乘的模块,在原始的PLM旁边增加一个新的通路,通过前后两个矩阵A,B相乘,第一个矩阵A负责降维,第二个矩阵B负责升维,中间层维度r。

可训练层维度和预训练模型层维度一致为d,先将维度d通过全连接层降维至r,再从r通过全连接层映射回d维度,其中r<<d,r是矩阵的秩,这样矩阵计算就从d*d变为d*r+r*d,参数量减少很多。
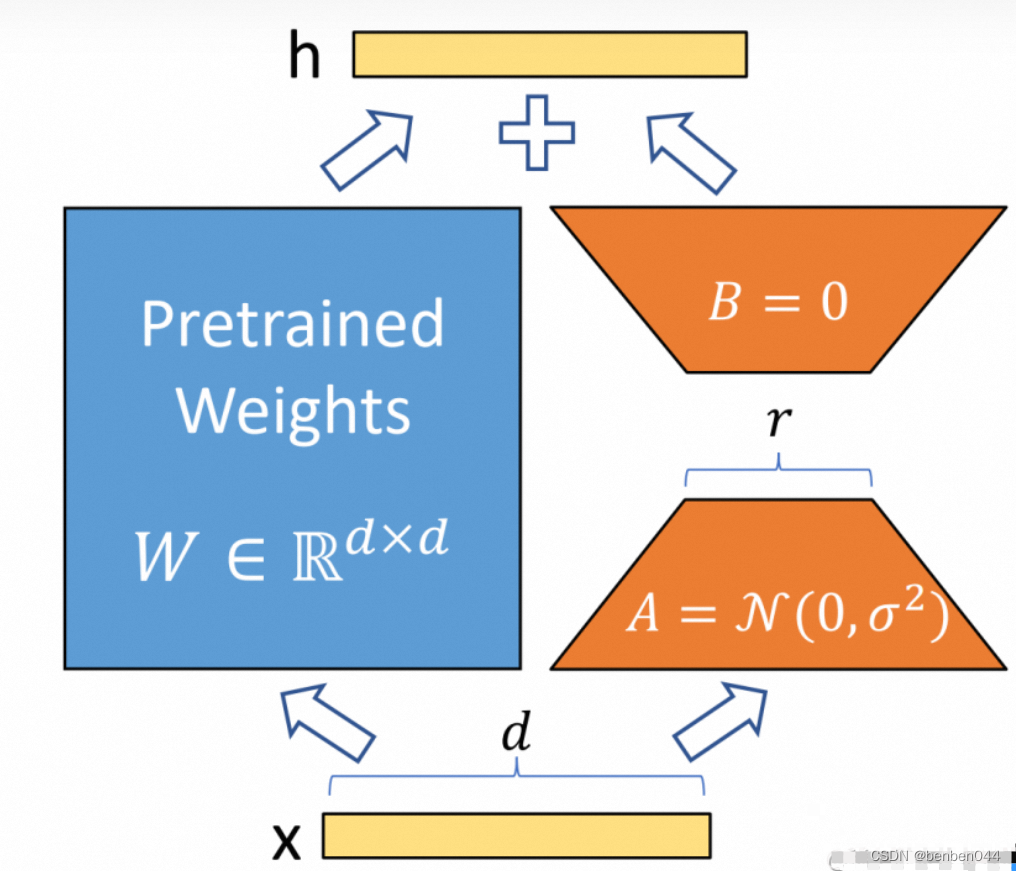
在任务训练时,固定模型的其他参数,只优化新增的两个矩阵的权重参数,将PLM跟新增的通路两部分的结果加起来作为最终的结果(两边通路的输入跟输出维度时一致的),即h=Wx+BAx。第一个矩阵的A的权重参数会通过高斯函数初始化,而第二个矩阵的B的权重参数则会初始化为零矩阵,这样能保证训练开始时新增的通路BA=0,从而对模型结果没有影响。
![]()
在推理时,将左右两部分的结果加到一起即可。h=Wx+BAx=(W+BA)x,所以只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原本PLM的W即可,对于推理来说,不会增加额外的计算资源。
2)sd实践
当scripts/lora_script.py脚本加载后,会执行:
torch.nn.Linear.forward = lora.lora_Linear_forward
torch.nn.Conv2d.forward = lora.lora_Conv2d_forward
相当于是把原有的torch.nn.Linear和torch.nn.Conv2d.forward给替换掉。
当然,程序也会将原先的forward实现保存起来,保存到torch.nn.Linear_forward_before_lora和nn.Conv2d_forward_before_lora,用于在卸载时恢复。
.
lora_Linear_forward和lora_Conv2d_forward都会调用lora_apply_weights方法

Lora_apply_weights函数说明:


最后的权重为Wx+(BA)x值之和。
Transformers中的MultiheadAttention中,初始化的3个成员变量为:
self.in_proj_weight = Parameter(torch.empty((3 * embed_dim, embed_dim)))
self.in_proj_bias = Parameter(torch.empty(3 * embed_dim))
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
在self.in_proj_weight中,使用packed_weights的形式一次性包装了Wq、Wk、Wv。

