
KVM 虚拟化原理探究(5)— 网络IO虚拟化
标签(空格分隔): KVM
IO 虚拟化简介
前面的文章介绍了KVM的启动过程,CPU虚拟化,内存虚拟化原理。作为一个完整的风诺依曼计算机系统,必然有输入计算输出这个步骤。传统的IO包括了网络设备IO,块设备IO,字符设备IO等等,在KVM虚拟化原理探究里面,我们最主要介绍网络设备IO和块设备IO,其实他们的原理都很像,但是在虚拟化层又分化开了,这也是为什么网络设备IO虚拟化和块设备IO虚拟化要分开讲的原因。这一章介绍一下网络设备IO虚拟化,下一章介绍块设备IO虚拟化。
传统的网络IO流程
这里的传统并不是真的传统,而是介绍一下在非虚拟化环境下的网络设备IO流程。我们平常所使用的Linux版本,比如Debian或者CentOS等都是标准的Linux TCP/IP协议栈,协议栈底层提供了driver抽象层来适配不同的网卡,在虚拟化中最重要的是设备的虚拟化,但是了解整个网络IO流程后去看待虚拟化就会更加容易理解了。
标准的TCP/IP结构
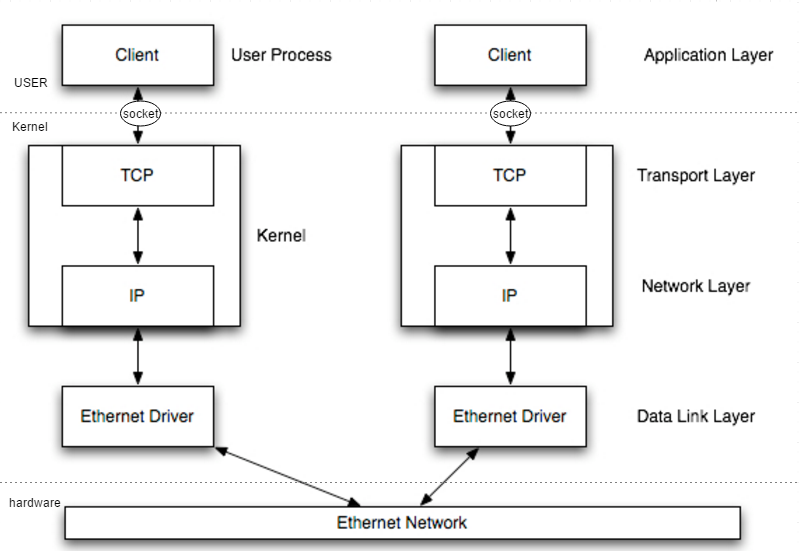
在用户层,我们通过socket与Kernel做交互,包括创建端口,数据的接收发送等操作。
在Kernel层,TCP/IP协议栈负责将我们的socket数据封装到TCP或者UDP包中,然后进入IP层,加入IP地址端口信息等,进入数据链路层,加入Mac地址等信息后,通过驱动写入到网卡,网卡再把数据发送出去。如下图所示,比较主观的图。
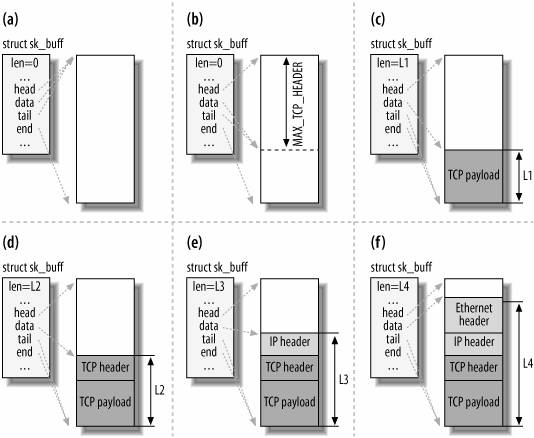
在Linux的TCP/IP协议栈中,每个数据包是有内核的skb_buff结构描述的,如下图所示,socket发送数据包的时候后,进入内核,内核从skb_buff的池中分配一个skb_buff用来承载数据流量。
当数据到了链路层,链路层做好相应的链路层头部封装后,调用驱动层适配层的发送接口 dev_queue_xmit,最终调用到 net_start_xmit 接口。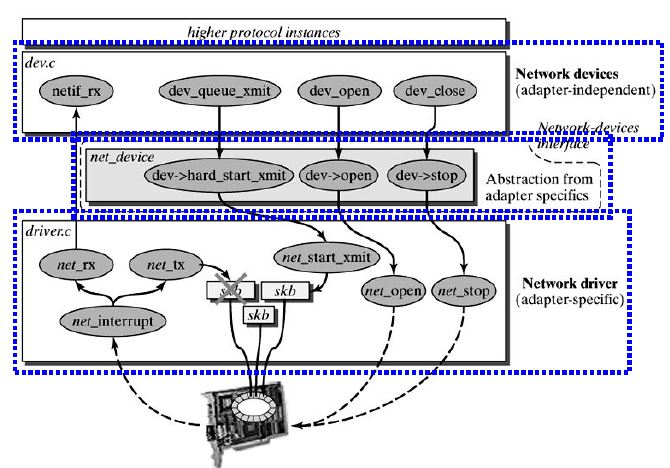
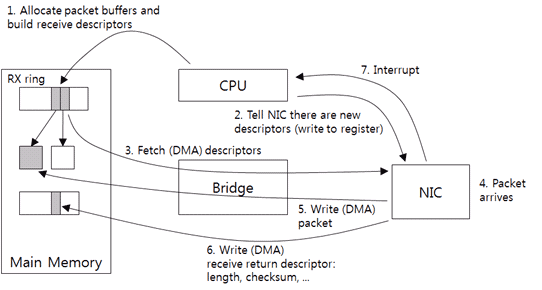
发送数据和接收数据驱动层都采用DMA模式,驱动加载时候会为网卡映射内存并设置描述状态(寄存器中),也就是内存的起始位,长度,剩余大小等等。发送时候将数据放到映射的内存中,然后设置网卡寄存器产生一个中断,告诉网卡有数据,网卡收到中断后处理对应的内存中的数据,处理完后向CPU产生一个中断告诉CPU数据发送完成,CPU中断处理过程中向上层driver通知数据发送完成,driver再依次向上层返回。在这个过程中对于driver来说,发送是同步的。接收数据的流程和发送数据几乎一致,这里就不细说了。DMA的模式对后面的IO虚拟化来说很重要。
KVM 网络IO虚拟化
准确来说,KVM只提供了一些基本的CPU和内存的虚拟化方案,真正的IO实现都由qemu-kvm来完成,只不过我们在介绍KVM的文章里都默认qemu-kvm和KVM为一个体系,就没有分的那么仔细了。实际上网络IO虚拟化都是由qemu-kvm来完成的。
KVM 全虚拟化IO
还记得我们第一章节的demo里面,我们的“镜像”调用了 out 指令产生了一个IO操作,然后因为此操作为敏感的设备访问类型的操作,不能在VMX non-root 模式下执行,于是VM exits,模拟器接管了这个IO操作。
- switch (kvm->vcpus->kvm_run->exit_reason) {
- case KVM_EXIT_UNKNOWN:
- printf("KVM_EXIT_UNKNOWN\n");
- break;
- // 虚拟机执行了IO操作,虚拟机模式下的CPU会暂停虚拟机并
- // 把执行权交给emulator
- case KVM_EXIT_IO:
- printf("KVM_EXIT_IO\n");
- printf("out port: %d, data: %d\n",
- kvm->vcpus->kvm_run->io.port,
- *(int *)((char *)(kvm->vcpus->kvm_run) + kvm->vcpus->kvm_run->io.data_offset)
- );
- break;
- ...
虚拟机退出并得知原因为 KVM_EXIT_IO,模拟器得知由于设备产生了IO操作并退出,于是获取这个IO操作并打印出数据。这里其实我们就最小化的模拟了一个虚拟IO的过程,由模拟器接管这个IO。
在qemu-kvm全虚拟化的IO过程中,其实原理也是一样,KVM捕获IO中断,由qemu-kvm接管这个IO,由于采用了DMA映射,qemu-kvm在启动时候会注册设备的mmio信息,以便能获取到DMA设备的映射内存和控制信息。
- static int pci_e1000_init(PCIDevice *pci_dev)
- {
- e1000_mmio_setup(d);
- // 为PCI设备设置 mmio 空间
- pci_register_bar(&d->dev, 0, PCI_BASE_ADDRESS_SPACE_MEMORY, &d->mmio);
- pci_register_bar(&d->dev, 1, PCI_BASE_ADDRESS_SPACE_IO, &d->io);
- d->nic = qemu_new_nic(&net_e1000_info, &d->conf, object_get_typename(OBJECT(d)), d->dev.qdev.id, d);
- add_boot_device_path(d->conf.bootindex, &pci_dev->qdev, "/ethernet-phy@0");
- }
对于PCI设备来说,当设备与CPU之间通过映射了一段连续的物理内存后,CPU对PCI设备的访问只需要像访问内存一样访问既可以。IO设备通常有两种模式,一种是port模式,一种是MMIO模式,前者就是我们demo里面的in/out指令,后者就是PCI设备的DMA访问方式,两种方式的操作都能被KVM捕获。
于是qemu-kvm将此操作代替Guest完成后并执行相应的“回调”,也就是向vCPU产生中断告诉IO完成并返回Guest继续执行。vCPU中断和CPU中断一样,设置相应的寄存器后中断便会触发。
在全虚拟化环境下,Guest中的IO都由qemu-kvm接管,在Guest中看到的一个网卡设备并不是真正的一块网卡,而是由物理机产生的一个tap设备。知识在驱动注册的时候将一些tap设备所支持的特性加入到了Guest的驱动注册信息里面,所以在Guest中看到有网络设备。
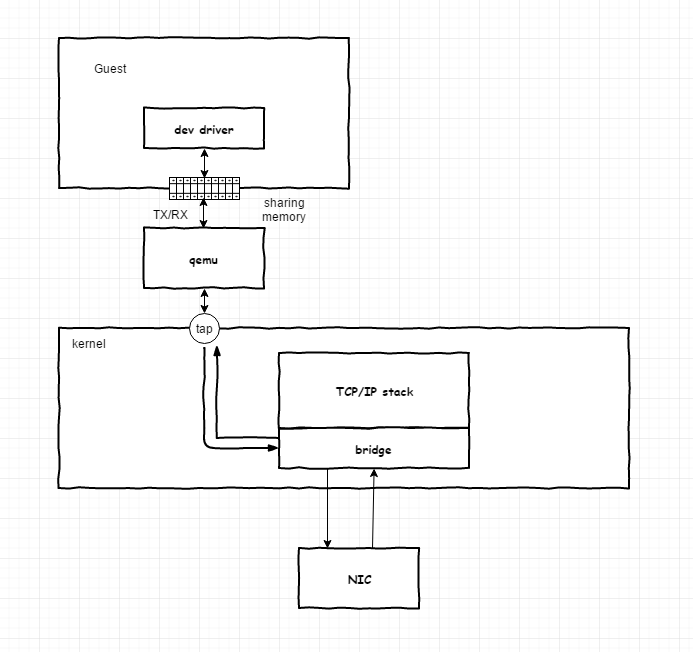
如上图所示,qemu接管了来自Guest的IO操作,真实的场景肯定是需要将数据再次发送出去的,而不是像demo一样打印出来,在Guest中的数据包二层封装的Mac地址后,qemu层不需要对数据进行拆开再解析,而只需要将数据写入到tap设备,tap设备和bridge之间交互完成后,由bridge直接发送到网卡,bridge(其实NIC绑定到了Bridge)开启了混杂模式,可以将所有请求都接收或者发送出去。
当一个 TAP 设备被创建时,在 Linux 设备文件目录下将会生成一个对应 char 设备,用户程序可以像打开普通文件一样打开这个文件进行读写。当执行 write()操作时,数据进入 TAP 设备,此时对于 Linux 网络层来说,相当于 TAP 设备收到了一包数据,请求内核接受它,如同普通的物理网卡从外界收到一包数据一样,不同的是其实数据来自 Linux 上的一个用户程序。Linux 收到此数据后将根据网络配置进行后续处理,从而完成了用户程序向 Linux 内核网络层注入数据的功能。当用户程序执行 read()请求时,相当于向内核查询 TAP 设备上是否有需要被发送出去的数据,有的话取出到用户程序里,完成 TAP 设备的发送数据功能。针对 TAP 设备的一个形象的比喻是:使用 TAP 设备的应用程序相当于另外一台计算机,TAP 设备是本机的一个网卡,他们之间相互连接。应用程序通过 read()/write()操作,和本机网络核心进行通讯。
类似这样的操作
- fd = open("/dev/tap", XXX)
- write(fd, buf, 1024);
- read(fd, buf, 1024);
bridge可能是一个Linux bridge,也可能是一个OVS(Open virtual switch),在涉及到网络虚拟化的时候,通常需要利用到bridge提供的VLAN tag功能。
以上就是KVM的网络全虚拟化IO流程了,我们也可以看到这个流程的不足,比如说当网络流量很大的时候,会产生过多的VM的切换,同时产生过多的数据copy操作,我们知道copy是很浪费CPU时钟周期的。于是qemu-kvm在发展的过程中,实现了virtio驱动。
KVM Virtio 驱动
基于 Virtio 的虚拟化也叫作半虚拟化,因为要求在Guest中加入virtio驱动,也就意味着Guest知道了自己运行于虚拟环境了。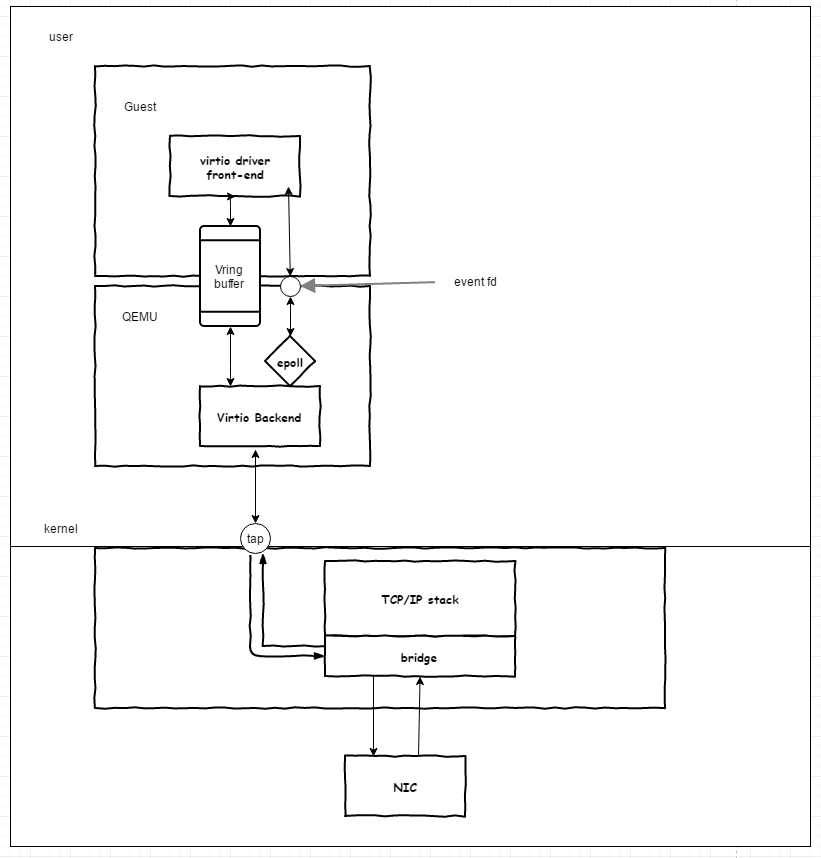
不同于全虚拟化的方式,Virtio通过在Guest的Driver层引入了两个队列和相应的队列就绪描述符与qemu-kvm层Virtio Backend进行通信,并用文件描述符来替代之前的中断。
Virtio front-end与Backend之间通过Vring buffer交互,在qemu中,使用事件循环机制来描述buffer的状态,这样当buffer中有数据的时候,qemu-kvm会监听到eventfd的事件就绪,于是就可以读取数据后发送到tap设备,当有数据从tap设备过来的时候,qemu将数据写入到buffer,并设置eventfd,这样front-end监听到事件就绪后从buffer中读取数据。
可以看到virtio在全虚拟化的基础上做了改动,降低了Guest exit和entry的开销,同时利用eventfd来建立控制替代硬件中断面膜是,一定程度上改善了网络IO的性能。
不过从整体流程上来看,virtio还是存在过多的内存拷贝,比如qemu-kvm从Vring buffer中拷贝数据后发送到tap设备,这个过程需要经过用户态到内核态的拷贝,加上一系列的系统调用,所以在流程上还可以继续完善,于是出现了内核态的virtio,被称作vhost-net。
KVM Vhost-net
我们用一张图来对比一下virtio与vhost-net,图片来自redhat官网。

vhost-net 绕过了 QEMU 直接在Guest的front-end和backend之间通信,减少了数据的拷贝,特别是减少了用户态到内核态的拷贝。性能得到大大加强,就吞吐量来说,vhost-net基本能够跑满一台物理机的带宽。
vhost-net需要内核支持,Redhat 6.1 后开始支持,默认状态下是开启的。
总结
KVM的网络设备IO虚拟化经过了全虚拟化->virtio->vhost-net的进化,性能越来越接近真实物理网卡,但是在小包处理方面任然存在差距,不过已经不是一个系统的瓶颈了,可以看到KVM在经过了这多年的发展后,性能也是越发的强劲,这也是他领先于其他虚拟化的重要原因之一。
在本章介绍了IO虚拟化后,下一章介绍块设备的虚拟化,块设备虚拟化同样利用了DMA的特性。

