
- 1使用easypoi完成word模板内容替换_easypoi替换word通配符
- 2wcf 基础连接已经关闭: 连接被意外关闭
- 3Android闹钟设置的解决方案_android 开启闹钟
- 4【建议收藏】数据库 SQL 入门——数据库与表操作(内附演示)_sql使用表
- 5FIFO原理_fifosize
- 6使用ESP8266连接阿里云并实现数据的收发(完整版)(不涉及单片机仅为连接单片机前的调试工作)_esp8266 怎么接收数据
- 7NoSQL非关系型数据库概述根据发展时间详细介绍_非关系型nosql数据库
- 8【Linux】深入解析动静态库:原理、制作、使用与动态链接机制
- 9课后答案︻︼─一大收集_清华数字电路与逻辑设计第二版答案
- 10git拉取和提交代码具体操作流程_使用git开发时在开发完一个功能后是先拉取代码吗
Transformer能解释一切吗?_生成式ai浪潮 transformer架构
赞
踩
提出Transformer的那篇论文《Attention is All You Need》问世已经是六年前的事了。当初的8位论文作者有6人出自谷歌,但到现在大多也已转身寻找新的故事。
Lukasz Kaiser去了OpenAI,他曾经谷歌大脑的同事Noam Shazeer成立了Character AI,估值已经超过10亿美元。另外两位同事Ashish Vaswani和Niki Parmar在创立了AI软件开发公司Adept AI Labs后,把这个同样估值超过10亿的初创公司交给了另一位联合创始人,又开始下一次创业了。
只有Llion Jones,这个从威尔士一个小村庄里走出来的程序员,还留在谷歌。他曾经谈起这个并不够学术的论文标题的由来,是对披头士的那首《All You Need is Love》的简单致敬。
而利用注意力机制来提高模型训练速度的Transformer架构,确实让AI从实验室深处的极寒之地里走出来了。它成为当下这场生成式AI浪潮无可争议的基础。某种程度上,上面提到的所有人,都没有真正离开这篇论文。
Mikolov在2010年提出RNN,这个框架在7年后被Transformer取代。而在Transformer问世后的一个相似时间周期后,其高内存消耗和高推理成本的局限性也开始显现出来。
替代者也跃跃欲试了。
一、“不可能三角”

图源:《Retentive Network: A Successor to Transformer for Large Language Models》
Transformer的自注意力机制增强了模型并行计算的能力,并且正契合了GPU对大规模数据进行并发处理的设计倾向。但Transformer在面对大型数据集和较长输入序列时,需要的计算量会陡增。
于是并行训练能力、性能和低成本推理,逐渐成为Transformer框架下的“不可能三角”。
近日,微软研究院和清华大学的研究团队提出了一个新的框架RetNet(Retentive Network)来代替Transformer,并表示RetNet可以打破这个“不可能三角”。
“这就像是M1芯片之于笔记本电脑。”一位产品经理在推特上这样形容RetNet。
二、O(N)困境
在这个“不可能三角”中,RetNet选择的突破口是推理成本。
由于使用了自注意力机制,Transformer模型展现出较高的训练并行性,同时在机器翻译、语言建模等任务上也取得了很好的表现。但取代了RNN的自注意力机制同样成为一种桎梏。
这集中体现在时间复杂度这个标尺上。在描述算法复杂度时,常用O(n)、O(n^2)、O(logn)等表示某个算法在计算耗时与输入数据量(n)之间的关系表示。
O(n)意味着数据量的增加与算法耗时成正比,O(n^2)意味着像冒泡排序那样,算法耗时是数据量的n^n倍。计算耗时越长,算法越复杂,也就意味着推理成本越高。
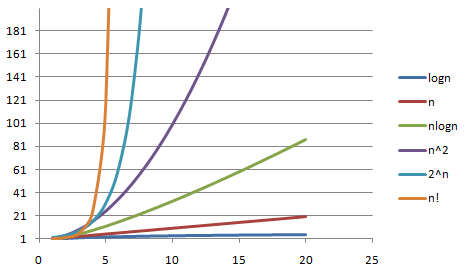
图源:博客园
拿文本翻译做个例子,在处理长文本序列时(假设文本长度为N),自注意力机制的时间复杂度为O(N^2),当N过大时,翻译速度很低。这也是为什么当前的大语言模型,在文本token长度上的进展颇为受人关注。
虽然Transformer可以有效训练并行性,但由于每步的O(N)复杂度以及内存绑定的键值缓存,它们的推理效率低下。这种低效率使得Transformer模型会消耗大量GPU内存并降低推理速度,因此不适合部署。
三、从O(N)到O(1)
O(1)无疑是最优的选择,这意味着无论数据输入量n如何变化,算法耗时都是一个常量。
RetNet框架的最大的惊艳之处就在这里,它将O(N)降维到了O(1)。
RetNet引入了一种多尺度保留机制(multi-scale retention mechanism)来取代多头注意力。作为三种计算范式之一的分块循环表示,可在内存和计算方面实现高效的O(1)推断,从而显著降低部署成本和延迟。
这意味着RetNet的推理成本是固定不变的。在一系列对比RETNet与Transformer及其变体的实验中,对比7B模型和 8k序列长度,RetNet的解码速度比带键值缓存的Transformers快8.4倍,节省70%的内存。RetNet的推理延迟变化对输入数据量的大小变化并不敏感,这也让它能够包容更大的吞吐量(Throughput)。
测试结果表示,在训练期间RetNet比标准Transformer节省了25-50%的内存和7倍的加速。
四、一些重要的实验结果

图源:《Retentive Network: A Successor to Transformer for Large Language Models》
O(1)为RetNet在GPU内存方面带来的优势是,它完全不随token数增加而变化。
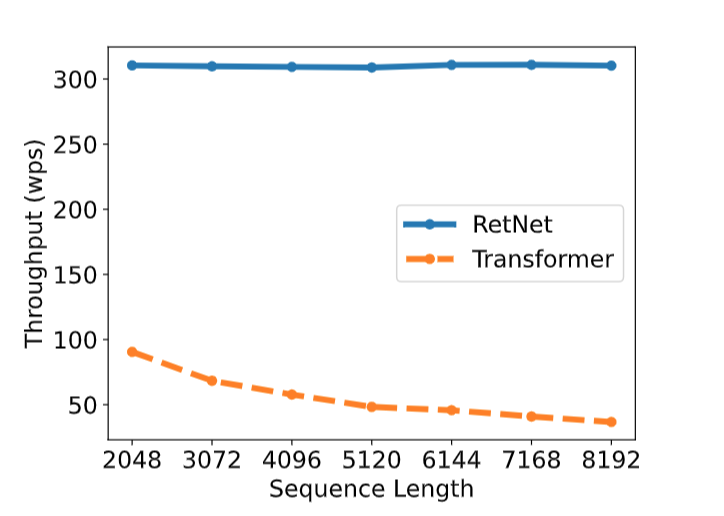
图源:《Retentive Network: A Successor to Transformer for Large Language Models》
Throughput(神经网络的吞吐量)是一个算法模型在单位时间内(例如,1s)可以处理的最大输入的训练样本数据。RetNet在输入端token数增加的情况下仍然能够维持高吞吐量,而Transformer在这方面的数据则随着token数的增加而逐渐衰减。
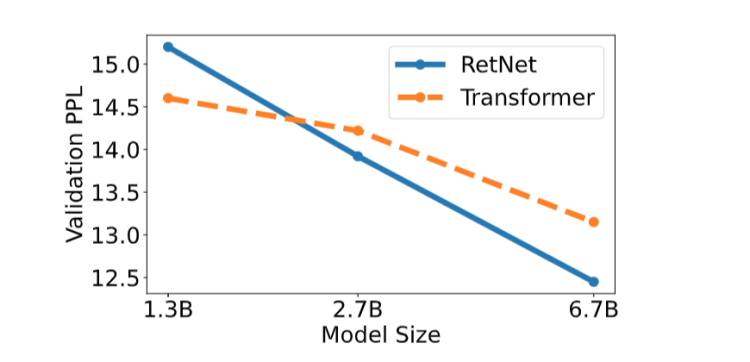
图源:《Retentive Network: A Successor to Transformer for Large Language Models》
Perplexity(困惑度)是语言模型最鲜明的评价标准。它衡量语言模型对单词序列中下一个单词的预测能力。当模型参数量变大时,困惑度往往会降低,即语言模型能够做出更优的预测——这也是为什么我们对万亿参数模型抱有极大期待。
论文中比较了RetNet与Transformer在1.3B、2.7B以及6.7B这三种不同尺寸上的困惑度变化,实验结果RetNet的困惑度下降更快,并且当模型大小超过2B时,RetNet的表现开始优于Transformer。
这一观察结果意义重大,它表明RetNet更适合需要大量计算资源和内存的大型语言模型。
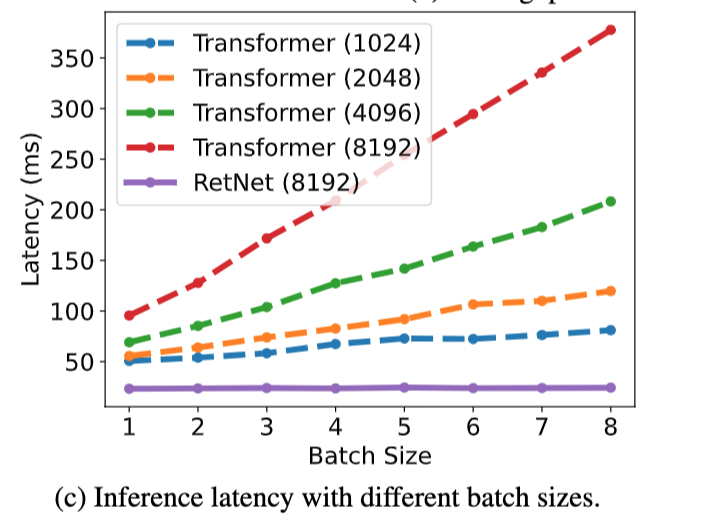
图源:《Retentive Network: A Successor to Transformer for Large Language Models》
2018年,大模型仍然前景未明的时候,黄仁勋在深度学习的综合性能评价方面提出了PLASTER框架。这是七个测量维度的缩写,其中延迟(Latency)的重要性仅仅被放在可编程性(Programmability)之后(其他五个维度分别是准确率(A)、模型大小(S)、吞吐量(T)、能效(E)以及学习率(R))。
RetNet与Transformer在不同Batch Size(一次训练所选取的样本数)下的延迟表现同样印证了,RetNet的响应速度将在训练规模进一步扩大后展现出优势。
五、Transformer能解释一切吗
这篇论文中的几位核心作者,在更早时候就已经开始关注GPT在上下文学习中的运行机制。2022年末ChatGPT问世后不久,他们发表了一篇表明Transformer注意力具有双重形式的梯度下降的论文。而这些研究者对于RetNet的野心并不会停留在文本输入上。
论文在最后表示,RetNet将会成为未来训练多模态大语言模型的核心角色。
在这篇论文发表的10天之前,世界人工智能大会上一家投资了智谱AI等多个大模型明星团队的创投公司表示,Transformer在短期内会是多模态的主流网络结构,但并不是人工智能技术的重点,“压缩整个数字世界的通用方法仍未出现”。
Transformer是目前几乎所有主流大模型的基石,这场基于Transformer而起的技术革命,已经快速到达了一个新的摇摆点。外部的压力来自暴涨的算力资源需求,以及人类所有的高质量语料可能在有限的期限内枯竭。

图源:推特
摇摆的地方在于,到底是Transformer还不够好,还是Transformer本身并不是一条正确道路?
至少从RetNet的角度,它仍然是相信Transformer的,RetNet是后者的颠覆版本,但并没有跳出以深度学习为基础,全神贯注在自然语言处理任务上做突破的逻辑框架。
另一种更剧烈的反对声音则直接站在了Transformer的对面,比如再度活跃起来的“卷积神经网络之父”杨立昆。
六、模型和数据,谁更重要
在几个月前的一次公开演讲中,杨立昆再次批评了GPT大模型。他认为根据概率生成自回归的大模型,根本无法破除幻觉难题。甚至直接断言GPT模型活不过5年。
LeCun的质疑是,基于文本训练的大型语言模型只能理解极片面的真实世界知识,而仅仅靠自回归预测下一个token的单一方式所形成的“智能”缺乏物理直觉。这样的模型能够在真实世界中对物理直觉问题做出对的回答——也可能做出错的回答。因为回答的依据来自将整个真实世界压缩成文本进行训练后所形成的逻辑关系,但这并不是直接面对物理世界本身。
并且由于这样的预测方式本质上缺乏时间尺度,这样的模型也就缺乏真正意义上的规划和决策能力。
矛头在根本上对准Transformer。
言下之意,Transformer统领了一种以预训练规模兑换智能涌现能力——所谓大力出奇迹——的发展道路(并且到目前为止取得了瞩目的成果),但如果真的有一条通往AGI的道路,到底是该以数据驱动模型,还是模型驱动数据?这仍是一个悬而未决的问题。
七、“刺激—反应”
杨立昆与这条区别于GPT的AGI未来猜想路径,更强调智能体主动发起的与物理世界之间的实时关系,这是强化学习擅长的事。在这一点上,Transformer的继承者RetNet也只是治标不治本。
OpenAI在ChatGPT中以人类反馈强化学习(RLHF)的微调方法补充了这种实时反馈的能力。但大语言模型的所有“常识”——也就是其智能所在——都来自一次次隆重的预训练,即在知道最优数据分布时,依靠巨大的模型、算力以及数据去拟合分布。这是Transformer与GPU在并行计算能力上的契合所带来的便利,而作为Transformer继任者的RetNet,只是在极力优化这整个后续的计算过程。
而强化学习与有监督学习、无监督学习都不一样。它本身并不知道最优分布,而是通过奖励信号的反馈机制不停的寻找相对的“最优”。这种在与环境交互中主动“试错”,并且获取正反馈(收益),进而从自身经验中进一步理解环境的方式,相比自监督学习来说更加接近人类对于物理世界的理解方式,这就像心理学中的“刺激—反应”理论。
很多人对强化学习的第一次感性认识都来自曾颠覆了人类围棋世界的AlphaGO,而到目前为止。全世界可能也没有另一家公司比AlphaGO背后的公司DeepMind更懂强化学习。
与RetNet在Transformer的基础上做调整不同,DeepMind在6月末提出了另一种大模型的迭代思路——AlphaGo+GPT4。
八、AlphaGo和AlphaZero
人类一败涂地的故事总是瞩目,但AlphaGO曾有一个后辈AlphaGo Zero。
2016年,AlphaGO用树搜索和上万张棋局的预先学习,4:1击败了李世乭。但另一个延续下去的故事是,AlphaGo Zero在一年后以100:0的战绩击溃了AlphaGO。
2017年《自然》上的一篇论文介绍了这项壮举,核心的内容是AlphaGo Zero如何在完全没有先验知识,即不依赖任何人类数据、指导或领域知识的前提下,通过自我学习来获得超越人类水平的专业领域能力。
换言之,AlphaGo Zero就好像带着一个空脑袋,坐在一间屋子里,在只掌握围棋游戏规则信息,眼前只有一副围棋棋盘和棋子的情况下,击败了AlphaGO。
AlphaGo Zero的不同之处在于它采用了一种完全基于强化学习的算法,仅仅将自己作为老师,以此诞生出更高质量的走法选择。与使用人类专家数据进行训练相比,纯粹的强化学习方法只需要多训练几个小时,但渐近性能(算法在接近其理论极限时的性能)要好得多。
AlphaGo Zero的胜利是强化学习的胜利。但它的局限性也很明显,就像杨立昆所推崇的能量模型(Energy-based Models)所具有的问题一样,“采样速度太慢了”,一位强化学习领域的研究者表示。
九、Gemini
现在这条更侧重强化学习的AGI路径,压在了DeepMind正在研究的一个新的名为Gemini的大模型身上。DeepMind CEO 哈萨比斯表示,对Gemini的研发投入将会超过数千万甚至数亿美金。做个对比,OpenAI用1个亿美金迭代出了GPT-4。
“Gemini”本身是双子座的意思。在哈萨比斯的表述中,这个全新的大模型将会是GPT4和AlphaGo的结合体,它仍然是一个大语言模型,但AlphaGo所具备的强化学习和树搜索能力会给Gemini带来更强的决策和规划能力——这个杨立昆认为GPT在AGI道路上早晚会遇到的阿喀琉斯之踵。
Gemini背后的谷歌显然希望能借着Gemini重新在与微软的争锋中占到一个好的位置。在ChatGPT问世之后,谷歌快速站到了OpenAI的对手Anthropic的背后。如果这被看作一种防守姿态的话,Gemini则更像谷歌主动发起的一场新的路线之争,就像曾经在GPT与BERT身上发生过的事情一样。
但无论如何,RetNet或是Gemini,改革或是淘汰Transformer的狂妄本身,已经包含了对这个伟大框架的所有敬意

