
- 1卷积神经网络算法解读
- 2qtcreator安装及配置
- 3vue3中报错ReferenceError: require is not defined_vue3 referenceerror: require is not defined
- 4MATLAB|【免费】高比例可再生能源电力系统的调峰成本量化与分摊模型
- 5油猴脚本编写_油猴脚本greay fork
- 6应届毕业生就业选择,考公还是进大厂?体制内就是最佳选择?_考公和去大厂
- 7matlab曲线拟合_matlab 拟合曲线方程
- 8油猴脚本开发,之如何添加html和css_油猴添加 css
- 9ATT&CK框架现有的14个战术进行了详细介绍_attck(三)之attck的十四个战术
- 10使用yolov5训练自己数据集并通过flask部署yolov5_yolov5 flask部署
java面试大厂必考题(2023)_java 基础笔试 大厂
赞
踩
Java面试总结汇总,整理了包括Java基础知识,集合容器,并发编程,JVM,常用开源框架Spring,MyBatis,数据库,中间件等,包含了Java工程师在面试中需要用到或者可能用到的绝大部分知识。
欢迎大家阅读,本人见识有限,写的博客难免有错误或者疏忽的地方,还望各位大佬指点,在此表示感激不尽。若有问题需要解答也可以留言,我会及时回复。
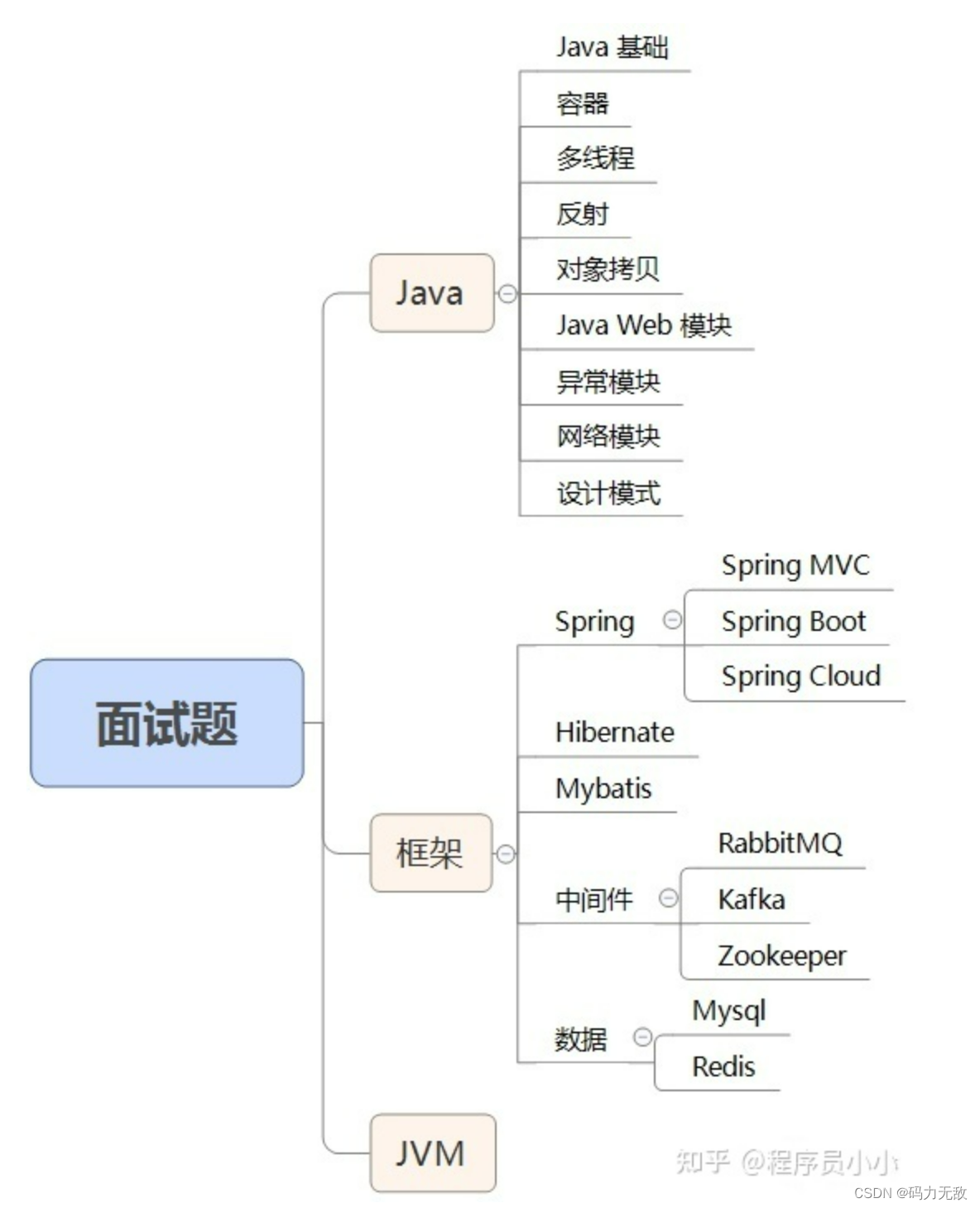
一、java基础
1.java有哪些数据结构?
- 基本数据类型:数值型:整数类型(byte,short,int,long)、浮点类型(float,double);字符型(char);布尔型(boolean);
- 引用数据类型:类(class)、接口(interface)、数组([])
Java基本数据类型图: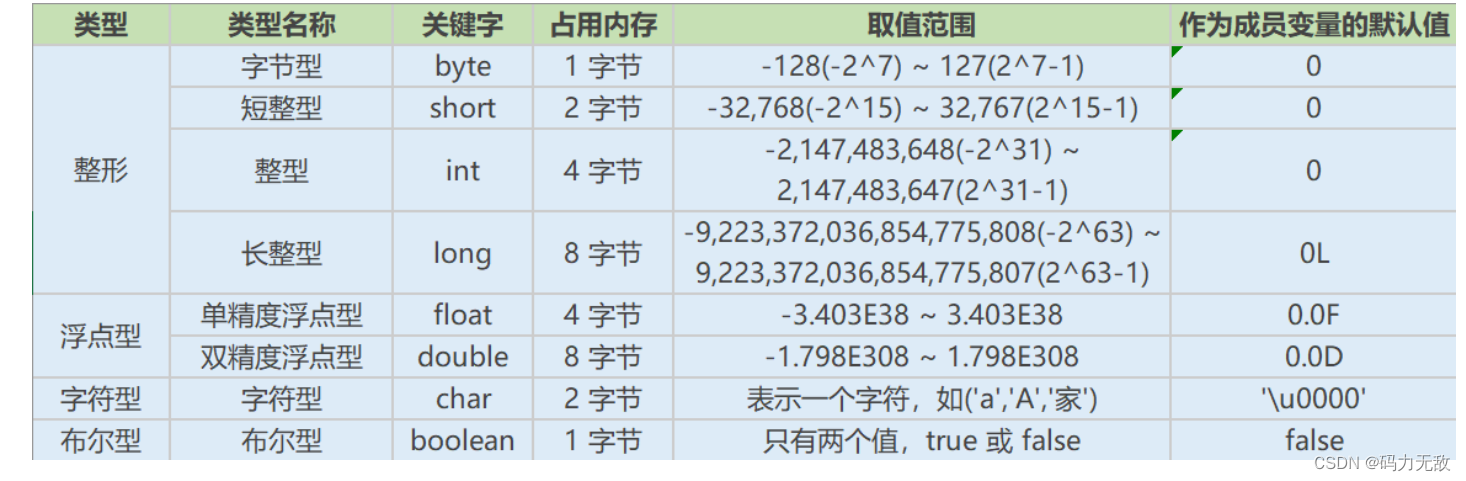
范围:
byte: - 128~127 (-2的7次方到2的7次方-1)
short: -32768~32767 (-2的15次方到2的15次方-1)
int: -2147483648~2147483647 (-2的31次方到2的31次方-1)
long: -9223372036854774808~922337203685477480 (-2的63次方到2的63次方-1)
2.final 有什么用?
用于修饰类、属性和方法;
被final修饰的类不可以被继承
被final修饰的方法不可以被重写
被final修饰的变量不可以被改变,被final修饰不可变的是变量的引用,而不是引用指向的内容,引用指向的内容是可以改变的
3.final finally finalize区别?
1).final可以修饰类、变量、方法,修饰类表示该类不能被继承、修饰方法表示该方法不能被重写、修饰变量表
示该变量是一个常量不能被重新赋值。
2).finally一般作用在try-catch代码块中,在处理异常的时候,通常我们将一定要执行的代码方法finally代码块
中,表示不管是否出现异常,该代码块都会执行,一般用来存放一些关闭资源的代码。
3).finalize是一个方法,属于Object类的一个方法,而Object类是所有类的父类,该方法一般由垃圾回收器来调
用,当我们调用System.gc() 方法的时候,由垃圾回收器调用finalize(),回收垃圾,一个对象是否可回收的最后判断。
4.this与super的区别?
super: 它引用当前对象的直接父类中的成员(用来访问直接父类中被隐藏的父类中成员数据或函数,基类与派生类中有相同成员定义时如:super.变量名 super.成员函数据名(实参)
this:它代表当前对象名(在程序中易产生二义性之处,应使用this来指明当前对象;如果函数的形参与类中的成员数据同名,这时需用this来指明成员变量名)
super()和this()类似,区别是,super()在子类中调用父类的构造方法,this()在本类内调用本类的其它构造方法。
super()和this()均需放在构造方法内第一行。
尽管可以用this调用一个构造器,但却不能调用两个。
this和super不能同时出现在一个构造函数里面,因为this必然会调用其它的构造函数,其它的构造函数必然也会有super语句的存在,所以在同一个构造函数里面有相同的语句,就失去了语句的意义,编译器也不会通过。
this()和super()都指的是对象,所以,均不可以在static环境中使用。包括:static变量,static方法,static语句块。
从本质上讲,this是一个指向本对象的指针, 然而super是一个Java关键字。
5.面向对象的特征主要有以下几个方面?
抽象:抽象是将一类对象的共同特征总结出来构造类的过程,包括数据抽象和行为抽象两方面。抽象只关注对象有哪些属性和行为,并不关注这些行为的细节是什么。
封装
封装把一个对象的属性私有化,同时提供一些可以被外界访问的属性的方法,如果属性不想被外界访问,我们大可不必提供方法给外界访问。但是如果一个类没有提供给外界访问的方法,那么这个类也没有什么意义了。
继承
继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承我们能够非常方便地复用以前的代码。
多态
所谓多态就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量到底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。
在Java中有两种形式可以实现多态:继承(多个子类对同一方法的重写)和接口(实现接口并覆盖接口中同一方法)。
其中Java 面向对象编程三大特性:封装 继承 多态
6.多态的实现?
Java实现多态有三个必要条件:继承、重写、向上转型。
继承:在多态中必须存在有继承关系的子类和父类。
重写:子类对父类中某些方法进行重新定义,在调用这些方法时就会调用子类的方法。
向上转型:在多态中需要将子类的引用赋给父类对象,只有这样该引用才能够具备技能调用父类的方法和子类的方法。
只有满足了上述三个条件,我们才能够在同一个继承结构中使用统一的逻辑实现代码处理不同的对象,从而达到执行不同的行为。
对于Java而言,它多态的实现机制遵循一个原则:当超类对象引用变量引用子类对象时,被引用对象的类型而不是引用变量的类型决定了调用谁的成员方法,但是这个被调用的方法必须是在超类中定义过的,也就是说被子类覆盖的方法。
7.面向对象五大基本原则是什么(可选)? *****
- 单一职责原则SRP(Single Responsibility Principle)
类的功能要单一,不能包罗万象,跟杂货铺似的。 - 开放封闭原则OCP(Open-Close Principle)
一个模块对于拓展是开放的,对于修改是封闭的,想要增加功能热烈欢迎,想要修改,哼,一万个不乐意。 - 里式替换原则LSP(the Liskov Substitution Principle LSP)
子类可以替换父类出现在父类能够出现的任何地方。比如你能代表你爸去你姥姥家干活。哈哈~~ - 依赖倒置原则DIP(the Dependency Inversion Principle DIP)
高层次的模块不应该依赖于低层次的模块,他们都应该依赖于抽象。抽象不应该依赖于具体实现,具体实现应该依赖于抽象。就是你出国要说你是中国人,而不能说你是哪个村子的。比如说中国人是抽象的,下面有具体的xx省,xx市,xx县。你要依赖的抽象是中国人,而不是你是xx村的。 - 接口分离原则ISP(the Interface Segregation Principle ISP)
设计时采用多个与特定客户类有关的接口比采用一个通用的接口要好。就比如一个手机拥有打电话,看视频,玩游戏等功能,把这几个功能拆分成不同的接口,比在一个接口里要好的多。
8.BIO,NIO,AIO 有什么区别? ******
- BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。
- NIO:Non IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复用。
- AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO ,异步 IO 的操作基于事件和回调机制。
详细回答: - BIO (Blocking I/O): 同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
- NIO (New I/O): NIO是一种同步非阻塞的I/O模型,在Java 1.4 中引入了NIO框架,对应 java.nio 包,提供了 Channel , Selector,Buffer等抽象。NIO中的N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。 NIO提供了与传统BIO模型中的 Socket 和 ServerSocket 相对应的 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发
- AIO (Asynchronous I/O): AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的IO模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。AIO 是异步IO的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO操作本身是同步的。查阅网上相关资料,我发现就目前来说 AIO 的应用还不是很广泛,Netty 之前也尝试使用过 AIO,不过又放弃了。
9.什么是反射机制。*****
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
静态编译和动态编译
**静态编译:**在编译时确定类型,绑定对象
**动态编译:**运行时确定类型,绑定对象
反射机制优缺点
优点: 运行期类型的判断,动态加载类,提高代码灵活度。
缺点: 性能瓶颈:反射相当于一系列解释操作,通知 JVM 要做的事情,性能比直接的java代码要慢很多。
10.反射机制的应用场景有哪些? *****
①我们在使用JDBC连接数据库时使用Class.forName()通过反射加载数据库的驱动程序;②Spring框架也用到很多反射机制,最经典的就是xml的配置模式。Spring 通过 XML 配置模式装载 Bean 的过程:1) 将程序内所有 XML 或 Properties 配置文件加载入内存中; 2)Java类里面解析xml或properties里面的内容,得到对应实体类的字节码字符串以及相关的属性信息; 3)使用反射机制,根据这个字符串获得某个类的Class实例; 4)动态配置实例的属性
11.Java获取反射的三种方法 *****
1.通过new对象实现反射机制 2.通过路径实现反射机制 3.通过类名实现反射机制
public class Get {
//获取反射机制三种方式
public static void main(String[] args) throws ClassNotFoundException {
//方式一(通过建立对象)
Student stu = new Student();
Class classobj1 = stu.getClass();
System.out.println(classobj1.getName());
//方式二(所在通过路径-相对路径)
Class classobj2 = Class.forName("fanshe.Student");
System.out.println(classobj2.getName());
//方式三(通过类名)
Class classobj3 = Student.class;
System.out.println(classobj3.getName());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
12.什么是字符串常量池?
字符串常量池位于堆内存中,专门用来存储字符串常量,可以提高内存的使用率,避免开辟多块空间存储相同的字符串,在创建字符串时 JVM 会首先检查字符串常量池,如果该字符串已经存在池中,则返回它的引用,如果不存在,则实例化一个字符串放到池中,并返回其引用。
13.String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的。
可变性
String类中使用字符数组保存字符串,private final char value[],所以string对象是不可变的。StringBuilder与StringBuffer都继承自AbstractStringBuilder类,在AbstractStringBuilder中也是使用字符数组保存字符串,char[] value,这两种对象都是可变的。
线程安全性
String中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder是StringBuilder与StringBuffer的公共父类,定义了一些字符串的基本操作,如expandCapacity、append、insert、indexOf等公共方法。StringBuffer对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder并没有对方法进行加同步锁,所以是非线程安全的。
性能
每次对String 类型进行改变的时候,都会生成一个新的String对象,然后将指针指向新的String 对象。StringBuffer每次都会对StringBuffer对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用StirngBuilder 相比使用StringBuffer 仅能获得10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
对于三者使用的总结
如果要操作少量的数据用 = String
单线程操作字符串缓冲区 下操作大量数据 = StringBuilder
多线程操作字符串缓冲区 下操作大量数据 = StringBuffer
14.Integer a= 127 与 Integer b = 127相等吗
对于对象引用类型:==比较的是对象的内存地址。
对于基本数据类型:==比较的是值。
如果整型字面量的值在-128到127之间,那么自动装箱时不会new新的Integer对象,而是直接引用常量池中的Integer对象,超过范围 a1==b1的结果是false。
自动装箱与拆箱
装箱:将基本类型用它们对应的引用类型包装起来;
拆箱:将包装类型转换为基本数据类型;
int 和 Integer 有什么区别
Java 是一个近乎纯洁的面向对象编程语言,但是为了编程的方便还是引入了基本数据类型,但是为了能够将这些基本数据类型当成对象操作,Java 为每一个基本数据类型都引入了对应的包装类型(wrapper class),int 的包装类就是 Integer,从 Java 5 开始引入了自动装箱/拆箱机制,使得二者可以相互转换。
Java 为每个原始类型提供了包装类型:
原始类型: boolean,char,byte,short,int,long,float,double
包装类型:Boolean,Character,Byte,Short,Integer,Long,Float,Double
14.java动态代理?*****
描述动态代理的几种实现方式?分别说出相应的优缺点
代理可以分为 “静态代理” 和 “动态代理”,动态代理又分为 “JDK动态代理” 和 “CGLIB动态代理” 实现。
-
静态代理:代理对象和实际对象都继承了同一个接口,在代理对象中指向的是实际对象的实例,这样对外暴露的是代理对象而真正调用的是 Real Object
优点:可以很好的保护实际对象的业务逻辑对外暴露,从而提高安全性。
缺点:不同的接口要有不同的代理类实现,会很冗余 -
JDK 动态代理:为了解决静态代理中,生成大量的代理类造成的冗余;JDK 动态代理只需要实现 InvocationHandler 接口,重写 invoke 方法便可以完成代理的实现,jdk的代理是利用反射生成代理类 Proxyxx.class 代理类字节码,并生成对象 jdk动态代理之所以只能代理接口是因为代理类本身已经extends了Proxy,而java是不允许多重继承的,但是允许实现多个接口。
优点:解决了静态代理中冗余的代理实现类问题。
缺点:JDK 动态代理是基于接口设计实现的,如果没有接口,会抛异常。
- CGLIB 代理:
由于 JDK 动态代理限制了只能基于接口设计,而对于没有接口的情况,JDK方式解决不了;CGLib 采用了非常底层的字节码技术,其原理是通过字节码技术为一个类创建子类,并在子类中采用方法拦截的技术拦截所有父类方法的调用,顺势织入横切逻辑,来完成动态代理的实现。实现方式实现 MethodInterceptor 接口,重写 intercept 方法,通过 Enhancer 类的回调方法来实现。但是CGLib在创建代理对象时所花费的时间却比JDK多得多,所以对于单例的对象,因为无需频繁创建对象,用CGLib合适,反之,使用JDK方式要更为合适一些。 同时,由于CGLib由于是采用动态创建子类的方法,对于final方法,无法进行代理。
优点:没有接口也能实现动态代理,而且采用字节码增强技术,性能也不错。
缺点:技术实现相对难理解些。
15.类加载机制?*****
一个类从加载到使用到卸载一共经过了5个步骤:加载 -> 连接 -> 初始化
其中连接分为验证,准备,解析三个阶段
1,加载
那么什么时候会将.class文件加载到jvm中?
就是在你使用这个类的时候。
验证,准备,解析
2,验证
验证是对class文件进行校验,判断它是否符合指定的规范,不然你把.class文件丢给JVM,结果JVM根本不认识就很离谱。
3,准备
类变量(成员变量),静态变量分配内存空间,并且设置默认值,数值类型就是0,布尔类型就是false,其他引用类型就是null。
4,解析
把符号引用替换为直接引用。
这个我是这么理解的,符号引用就是 int num=0,这个num(变量名)就是符号引用,那么jvm会将这个num解析成指向内存中这个变量的指针,这个指针就是直接引用;
这里只是拿类变量打个比方,他还会将方法
5,初始化
初始化就是将之前分配了默认值的变量,设置变量值。
17.双亲委派模型?*****
类加载是通过加载器来实现的,那么有哪几种加载器呢?
(1)启动类加载器:Bootstrap ClassLoader,加载jdk中lib目录下的核心类;
(2)类扩展加载器:Extension ClassLoader,加载jdk中lib/ext目录的类;
(3)应用程序加载器:Application ClassLoader,加载自己写的class类;
(4)自定义加载器:自己实现,根据自己的需求自定义加载类;
(5)双亲委派机制
jvm的类加载器是有亲子结构的,会先从上到下查找需要加载的类,如果在上面找到了,那么会用父加载器来完成加载,如果父类没找到会去子类加载器接着找,直到最后,如果都没有就会报错:ClassNotFoundException
这就是所谓的双亲委派模型:先找父亲去加载,不行的话再由儿子来加载。
这样的话,可以避免多层级的加载器结构重复加载某些类。
18.设计模式
- 单例模式:保证被创建一次,节省系统开销。
- 工厂模式(简单工厂、抽象工厂):解耦代码。
- 观察者模式:定义了对象之间的一对多的依赖,这样一来,当一个对象改变时,它的所有的依赖者都会收到通知并自动更新。
- 外观模式:提供一个统一的接口,用来访问子系统中的一群接口,外观定义了一个高层的接口,让子系统更容易使用。
- 模版方法模式:定义了一个算法的骨架,而将一些步骤延迟到子类中,模版方法使得子类可以在不改变算法结构的情况下,重新定义算法的步骤。
- 状态模式:允许对象在内部状态改变时改变它的行为,对象看起来好像修改了它的类。
- 装饰器设计模式:(Decorator design pattern)被用于多个 Java IO 类中。
19.为什么密码用char[]来存储比用String安全?
如果密码是存储在 Java String 对象中的,则直到对它进行垃圾收集或进程终止之前,密码会一直驻留在内存中。即使进行了垃圾收集,它仍会存在于空闲内存堆中,直到重用该内存空间为止。密码 String 在内存中驻留得越久,遭到窃听的危险性就越大。
更糟的是,如果实际内存减少,则操作系统会将这个密码 String 换页调度到磁盘的交换空间,因此容易遭受磁盘块窃听攻击。
为了将这种泄密的可能性降至最低(但不是消除),您应该将密码存储在 char 数组中,并在使用后对其置零。(String 是不可变的,所以无法对其置零。
20.tomcat容器是如何创建servlet类实例
当容器启动时,会读取在webapps目录下所有的web应用中的web.xml文件,然后对xml文件进行解析,并读取servlet注册信息。
然后,将每个应用中注册的servlet类都进行加载,并通过反射的方式实例化。(有时候也是在第一次请求时实例化)
在servlet注册时加上1如果为正数,则在一开始就实例化,如果不写或为负数,则第一次请求实例化。
21.什么是tomcat?
Tomacat是由Apache推出的Servlet容器,可实现JavaWeb程序的装载,是配置JSP和JAVA系统必备的一款环境。
Tomcat不仅仅是一个Servlet容器,它也具有传统的Web服务器的功能:处理Html页面。但是与Apache相比,在处理静态Html上的能力略逊一筹。
22.如何自定义注解?
第一步,定义注解——相当于定义标记;
第二步,配置注解——把标记打在需要用到的程序代码中;
第三步,解析注解——在编译期或运行时检测到标记,并进行特殊操作。
注解类型的声明部分:
注解在Java中,与类、接口、枚举类似,因此其声明语法基本一致,只是所使用的关键字有所不同@interface。在底层实现上,所有定义的注解都会自动继承java.lang.annotation.Annotation接口。
public @interface CherryAnnotation {
public String name();
int age() default 18;
int[] array();
}
- 1
- 2
- 3
- 4
- 5
常用的元注解:
- @Target注解,是专门用来限定某个自定义注解能够被应用在哪些Java元素上面的。它使用一个枚举类型定义如下:
public enum ElementType { /** 类,接口(包括注解类型)或枚举的声明 */ TYPE, /** 属性的声明 */ FIELD, /** 方法的声明 */ METHOD, /** 方法形式参数声明 */ PARAMETER, /** 构造方法的声明 */ CONSTRUCTOR, /** 局部变量声明 */ LOCAL_VARIABLE, /** 注解类型声明 */ ANNOTATION_TYPE, /** 包的声明 */ PACKAGE }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- @Retention:表示注解的生命周期,即注解被保留的阶段。
(1) RetentionPolicy.SOURCE :在源文件中有效(即源文件保留),编译时编译器会直接丢弃这种策略的注解;
(2) RetentionPolicy.CLASS : 在class文件中有效(即class保留),当运行Java程序时, JVM不会保留注解。这是默认值
(3) RetentionPolicy.RUNTIME : 在运行时有效(即运行时保留),当运行 Java 程序时, JVM会保留注解。程序可以通过反射获取该注释。 - @Documented:表示该注解修饰的注解,可以被抽取到API文档中。 定义为Documented的注解必须设置Retention值为RetentionPolicy.RUNTIME 。
- @Inherited:表示该注解可以被子类继承。
- 如果一个注解被定义为RetentionPolicy.SOURCE,则它将被限定在Java源文件中,那么这个注解即不会参与编译也不会在运行期起任何作用,这个注解就和一个注释是一样的效果,只能被阅读Java文件的人看到;
- 如果一个注解被定义为RetentionPolicy.CLASS,则它将被编译到Class文件中,那么编译器可以在编译时根据注解做一些处理动作,但是运行时JVM(Java虚拟机)会忽略它,我们在运行期也不能读取到;
- 如果一个注解被定义为RetentionPolicy.RUNTIME,那么这个注解可以在运行期的加载阶段被加载到Class对象中。那么在程序运行阶段,我们可以通过反射得到这个注解,并通过判断是否有这个注解或这个注解中属性的值,从而执行不同的程序代码段。我们实际开发中的自定义注解几乎都是使用的RetentionPolicy.RUNTIME;
23.分布式事务的解决方案?
1.两阶段提交/XA
XA是由X/Open组织提出的分布式事务的规范,XA规范主要定义了(全局)事务管理器™和(局部)资源管理器(RM)之间的接口。本地的数据库如mysql在XA中扮演的是RM角色。
XA一共分为两阶段:
第一阶段(prepare):即所有的参与者RM准备执行事务并锁住需要的资源。参与者ready时,向TM报告已准备就绪。
第二阶段 (commit/rollback):当事务管理者™确认所有参与者(RM)都ready后,向所有参与者发送commit命令。
目前主流的数据库基本都支持XA事务,包括mysql、oracle、sqlserver、postgre
XA 事务由一个或多个资源管理器(RM)、一个事务管理器(TM)和一个应用程序(ApplicationProgram)组成。
XA事务的特点是:简单易理解,开发较容易。对资源进行了长时间的锁定,并发度低。
2.SAGA
Saga其核心思想是将长事务拆分为多个本地短事务,由Saga事务协调器协调,如果正常结束那就正常完成,如果某个步骤失败,则根据相反顺序一次调用补偿操作。
SAGA事务的特点:
- 并发度高,不用像XA事务那样长期锁定资源
- 需要定义正常操作以及补偿操作,开发量比XA大
- 一致性较弱,对于转账,可能发生A用户已扣款,最后转账又失败的情况

- TCC,TCC分为3个阶段
- Try 阶段:尝试执行,完成所有业务检查(一致性), 预留必须业务资源(准隔离性)
- Confirm 阶段:确认执行真正执行业务,不作任何业务检查,只使用 Try 阶段预留的业务资源,Confirm 操作要求具备幂等设计,Confirm 失败后需要进行重试。
- Cancel 阶段:取消执行,释放 Try 阶段预留的业务资源。Cancel 阶段的异常和 Confirm 阶段异常处理方案基本上一致,要求满足幂等设计。
转账作为例子,通常会在Try里面冻结金额,但不扣款,Confirm里面扣款,Cancel里面解冻金额.
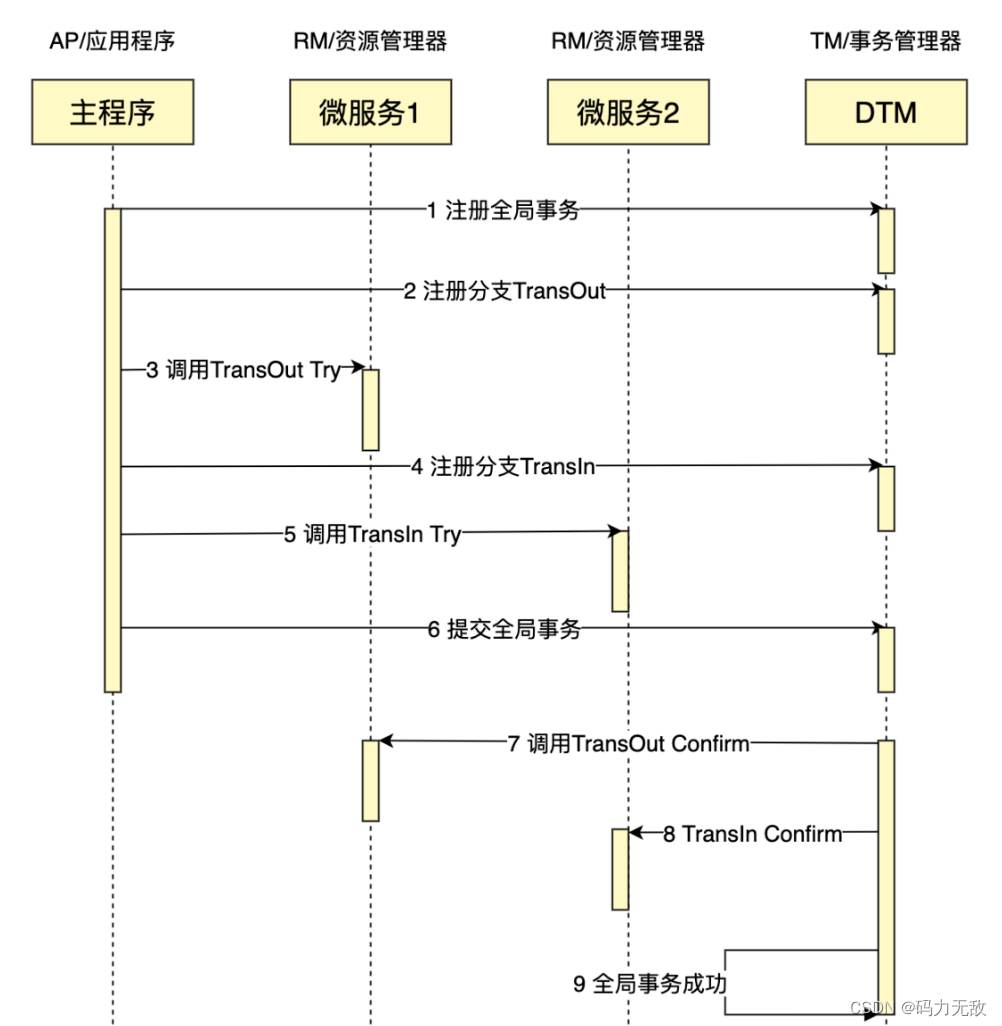
TCC特点如下:
- 并发度较高,无长期资源锁定。
- 开发量较大,需要提供Try/Confirm/Cancel接口。
- 一致性较好,不会发生SAGA已扣款最后又转账失败的情况
- TCC适用于订单类业务,对中间状态有约束的业务
java语言可参考seata-tcc.
- 本地消息表
写本地消息和业务操作放在一个事务里,保证了业务和发消息的原子性,要么他们全都成功,要么全都失败。
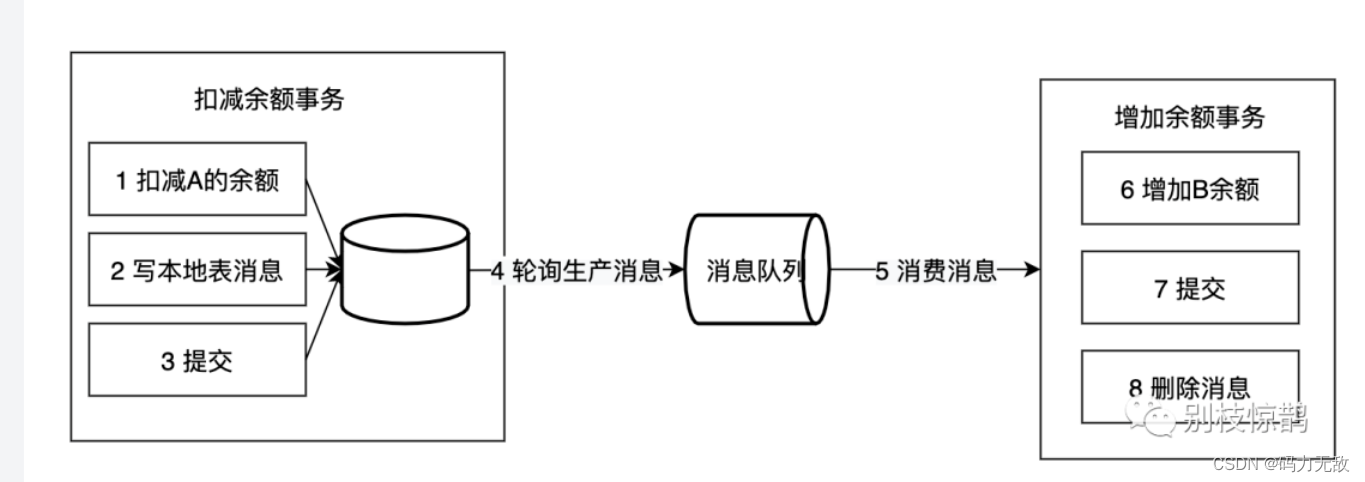
本地消息表的特点:
- 长事务仅需要分拆成多个任务,使用简单
- 生产者需要额外的创建消息表
- 每个本地消息表都需要进行轮询
- 消费者的逻辑如果无法通过重试成功,那么还需要更多的机制,来回滚操作
5.事务消息
该事务消息本质上是把本地消息表放到RocketMQ上,解决生产端的消息发送与本地事务执行的原子性问题。
事务消息发送及提交:
- 发送消息(half消息)
- 服务端存储消息,并响应消息的写入结果
- 根据发送结果执行本地事务(如果写入失败,此时half消息对业务不可见,本地逻辑不执行)
- 根据本地事务状态执行Commit或者Rollback(Commit操作发布消息,消息对消费者可见)
事务消息特点如下:
- 长事务仅需要分拆成多个任务,并提供一个反查接口,使用简单
- 消费者的逻辑如果无法通过重试成功,那么还需要更多的机制,来回滚操作
6.最大努力通知
可靠消息一致性,发起通知方需要保证将消息发出去,并且将消息发到接收通知方,消息的可靠性关键由发起通知方来保证。
最大努力通知,发起通知方尽最大的努力将业务处理结果通知为接收通知方,但是可能消息接收不到,此时需要接收通知方主动调用发起通知方的接口查询业务处理结果,通知的可靠性关键在接收通知方。
二、Java集合
1.有几种集合?集合的区别?
Map接口和Collection接口是所有集合框架的父接口:
- Collection接口的子接口包括:Set接口和List接口、Queue
- Map接口的实现类主要有:HashMap、TreeMap、Hashtable、SortedMap等。
- Set接口的实现类主要有:HashSet、TreeSet、LinkedHashSet等
- List接口的实现类主要有:ArrayList、LinkedList、Stack以及Vector等
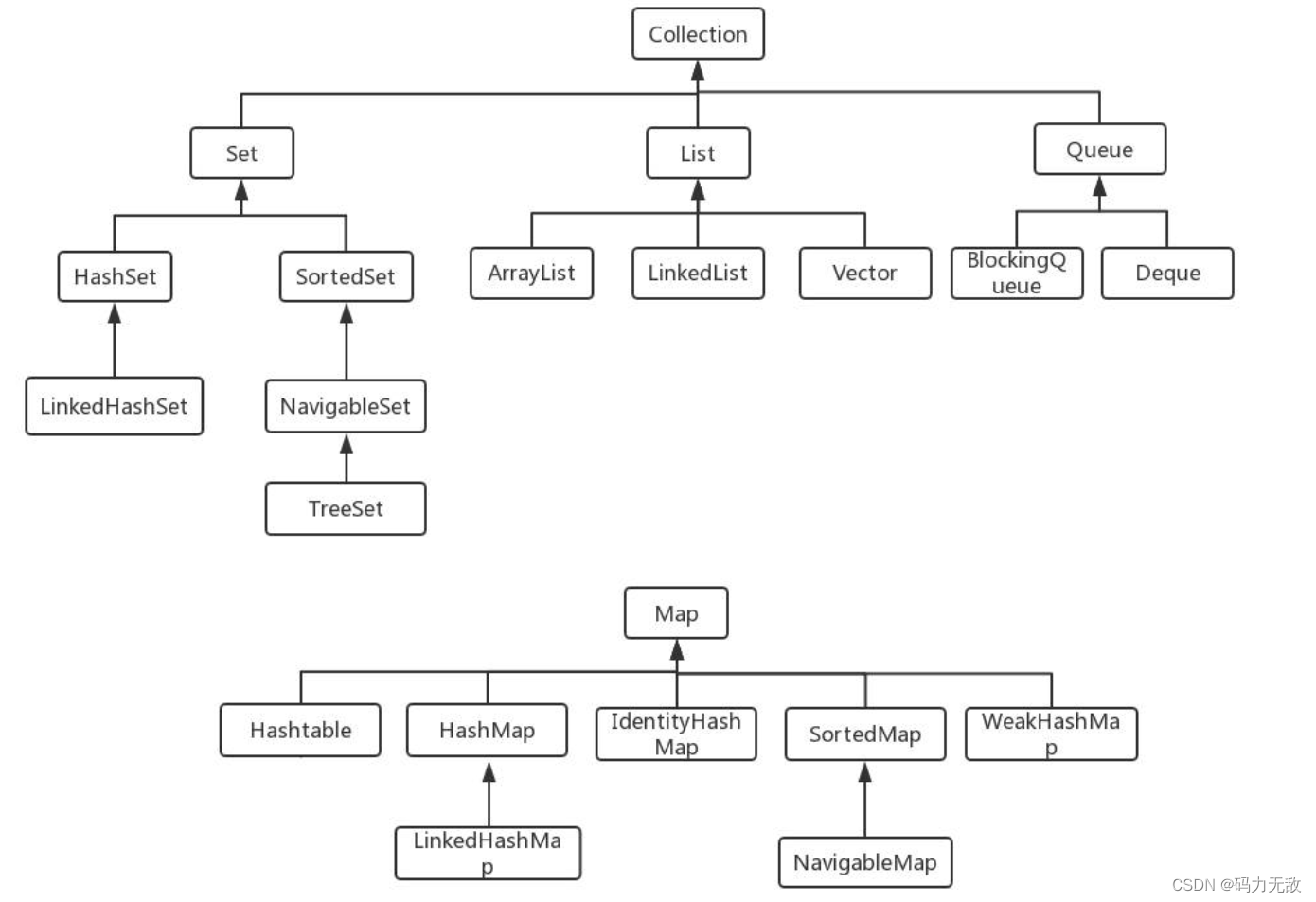
Collection集合主要有List和Set两大接口
- List:一个有序(元素存入集合的顺序和取出的顺序一致)容器,元素可以重复,可以插入多个null元素,元素都有索引。常用的实现类有 ArrayList、LinkedList 和 Vector。
- Set:一个无序(存入和取出顺序有可能不一致)容器,不可以存储重复元素,只允许存入一个null元素,必须保证元素唯一性。Set 接口常用实现类是 HashSet、LinkedHashSet 以及 TreeSet。
Map是一个键值对集合,存储键、值和之间的映射。 Key无序,唯一;value 不要求有序,允许重复。Map没有继承于Collection接口,从Map集合中检索元素时,只要给出键对象,就会返回对应的值对象。
Map 的常用实现类:HashMap、TreeMap、HashTable、LinkedHashMap、ConcurrentHashMap
2.集合框架底层数据结构?
Collection
- List
Arraylist: Object数组
Vector: Object数组
LinkedList: 双向循环链表 - Set
- HashSet(无序,唯一):基于 HashMap 实现的,底层采用 HashMap 来保存元素
- LinkedHashSet: LinkedHashSet 继承与 HashSet,并且其内部是通过 LinkedHashMap 来实现的。有点类似于我们之前说的LinkedHashMap 其内部是基于 Hashmap 实现一样,不过还是有一点点区别的。
- TreeSet(有序,唯一): 红黑树(自平衡的排序二叉树。)
Map
- HashMap: JDK1.8之前HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突).JDK1.8以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
- LinkedHashMap:LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。
- HashTable: 数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的,线程安全。
- TreeMap: 红黑树(自平衡的排序二叉树)
3.怎么确保一个集合不能被修改?
可以使用 Collections. unmodifiableCollection(Collection c) 方法来创建一个只读集合,这样改变集合的任何操作都会抛出 Java. lang. UnsupportedOperationException 异常。
4.ArrayList的扩容机制。
ArrayList的add,modCount是记录ArrayList被修改次数的,此add方法的参数就是一个被加元素E e。
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
- 1
- 2
- 3
- 4
- 5
然后是另一个add方法,所传的值是被加元素、当前数组和当前数组的元素个数。它判断当前数组是不是满的,判断元素个数是否等于当前容量。如果当前空间是满的,就需要扩容了,grow函数就是扩容函数了,扩容后再将被加元素加到数组中。
private void add(E e, Object[] elementData, int s) {
// 判断元素个数是否等于当前容量
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
ArrayList的特点:
1.ArrayList的底层数据结构是数组,所以查找遍历快,增删慢。
2.ArrayList可随着元素的增长而自动扩容,正常扩容的话,每次扩容到原来的1.5倍。
3.ArrayList的线程是不安全的。
ArrayList的扩容:
扩容可分为两种情况:
第一种情况,当ArrayList的容量为0时,此时添加元素的话,需要扩容,三种构造方法创建的ArrayList在扩容时略有不同:
1.无参构造,创建ArrayList后容量为0,添加第一个元素后,容量变为10,此后若需要扩容,则正常扩容。
2.传容量构造,当参数为0时,创建ArrayList后容量为0,添加第一个元素后,容量为1,此时ArrayList是满的,下次添加元素时需正常扩容。
3.传列表构造,当列表为空时,创建ArrayList后容量为0,添加第一个元素后,容量为1,此时ArrayList是满的,下次添加元素时需正常扩容。
第二种情况,当ArrayList的容量大于0,并且ArrayList是满的时,此时添加元素的话,进行正常扩容,每次扩容到原来的1.5倍。
4.ArrayList 和 LinkedList 的区别是什么?
- 数据结构实现:ArrayList 是动态数组的数据结构实现,而 LinkedList 是双向链表的数据结构实现。
- 随机访问效率:ArrayList 比 LinkedList 在随机访问的时候效率要高,因为 LinkedList 是线性的数据存储方式,所以需要移动指针从前往后依次查找。
- 增加和删除效率:在非首尾的增加和删除操作,LinkedList 要比 ArrayList 效率要高,因为 ArrayList 增删操作要影响数组内的其他数据的下标。
- 内存空间占用:LinkedList 比 ArrayList 更占内存,因为 LinkedList 的节点除了存储数据,还存储了两个引用,一个指向前一个元素,一个指向后一个元素。
- 线程安全:ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
综合来说,在需要频繁读取集合中的元素时,更推荐使用 ArrayList,而在插入和删除操作较多时,更推荐使用 LinkedList。
5.ArrayList 和 Vector 的区别是什么?
这两个类都实现了 List 接口(List 接口继承了 Collection 接口),他们都是有序集合
- 线程安全:Vector 使用了 Synchronized 来实现线程同步,是线程安全的,而 ArrayList 是非线程安全的。
- 性能:ArrayList 在性能方面要优于 Vector。
- 扩容:ArrayList 和 Vector 都会根据实际的需要动态的调整容量,只不过在 Vector 扩容每次会增加 1 倍,而 ArrayList 只会增加 50%。
Vector类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象、但是一个线程访问Vector的话代码要在同步操作上耗费大量的时间。
Arraylist不是同步的,所以在不需要保证线程安全时时建议使用Arraylist。
6.多线程场景下如何使用 ArrayList?
ArrayList 不是线程安全的,如果遇到多线程场景,可以通过 Collections 的 synchronizedList 方法将其转换成线程安全的容器后再使用。例如像下面这样:
List<String> synchronizedList = Collections.synchronizedList(list);
synchronizedList.add("aaa");
synchronizedList.add("bbb");
- 1
- 2
- 3
7.List 和 Set 的区别
List , Set 都是继承自Collection 接口
List 特点:一个有序(元素存入集合的顺序和取出的顺序一致)容器,元素可以重复,可以插入多个null元素,元素都有索引。常用的实现类有 ArrayList、LinkedList 和 Vector。
Set 特点:一个无序(存入和取出顺序有可能不一致)容器,不可以存储重复元素,只允许存入一个null元素,必须保证元素唯一性。Set 接口常用实现类是 HashSet、LinkedHashSet 以及 TreeSet。
另外 List 支持for循环,也就是通过下标来遍历,也可以用迭代器,但是set只能用迭代,因为他无序,无法用下标来取得想要的值。
Set和List对比
Set:检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
List:和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变
8.说一下 HashMap 的实现原理?
HashMap 基于 Hash 算法实现的
- 当我们往Hashmap中put元素时,利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
- 存储时,如果出现hash值相同的key,此时有两种情况。(1)如果key相同,则覆盖原始值;(2)如果key不同(出现冲突),则将当前的key-value放入链表中
- 获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
- 理解了以上过程就不难明白HashMap是如何解决hash冲突的问题,核心就是使用了数组的存储方式,然后将冲突的key的对象放入链表中,一旦发现冲突就在链表中做进一步的对比。
需要注意Jdk 1.8中对HashMap的实现做了优化,当链表中的节点数据超过八个之后,该链表会转为红黑树来提高查询效率,从原来的O(n)到O(logn)
9.HashMap在JDK1.7和JDK1.8中有哪些不同?HashMap的底层实现?
JDK1.8之前采用的是拉链法。拉链法:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
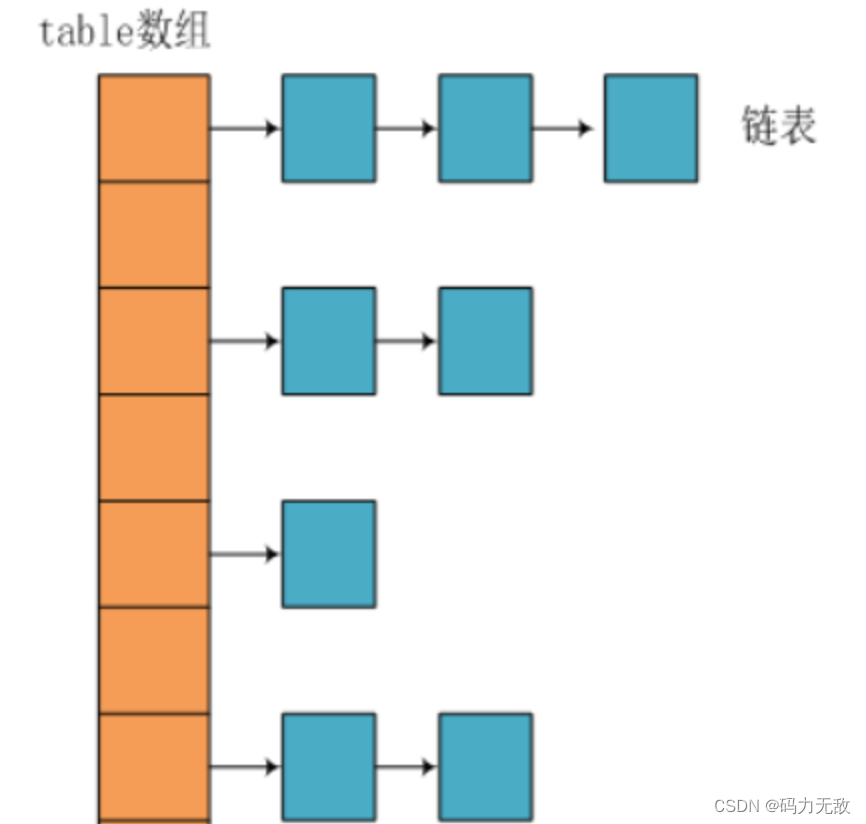
JDK1.8之后
相比于之前的版本,jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
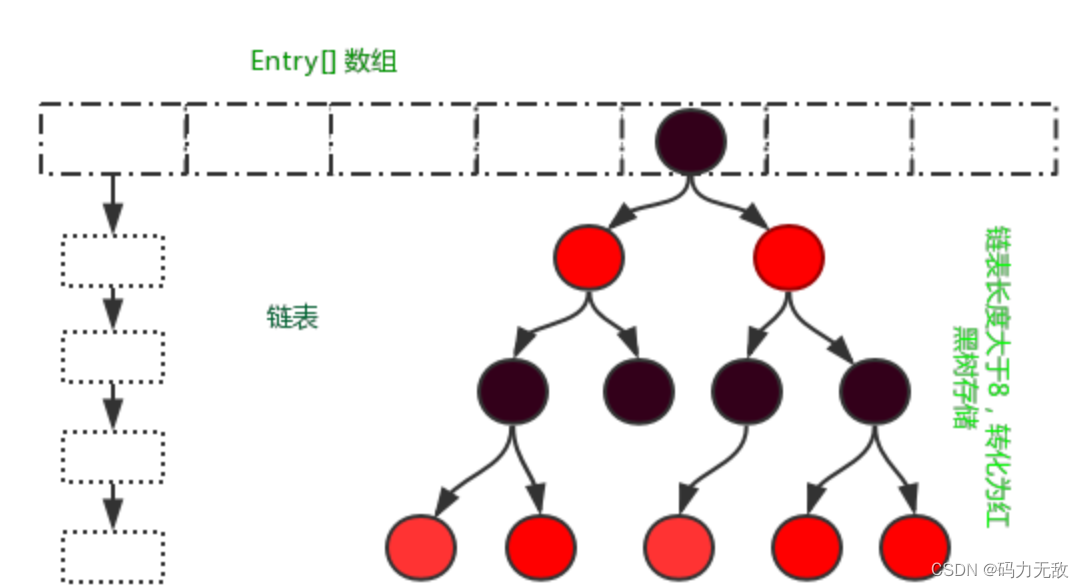
比较:扩容时候又扩容因子:0.75,数组长度为12,默认16.
10 .HashMap的扩容操作是怎么实现的?
①.在jdk1.8中,resize方法是在hashmap中的键值对大于阀值时或者初始化时,就调用resize方法进行扩容;
②.每次扩展的时候,都是扩展2倍;扩容因子0.75.
③.扩展后Node对象的位置要么在原位置,要么移动到原偏移量两倍的位置。
在putVal()中,我们看到在这个函数里面使用到了2次resize()方法,resize()方法表示的在进行第一次初始化时会对其进行扩容,或者当该数组的实际大小大于其临界值值(第一次为12),这个时候在扩容的同时也会伴随的桶上面的元素进行重新分发,这也是JDK1.8版本的一个优化的地方,
在1.7中,扩容之后需要重新去计算其Hash值,根据Hash值对其进行分发,但在1.8版本中,则是根据在同一个桶的位置中进行判断(e.hash & oldCap)是否
为0,重新进行hash分配后,该元素的位置要么停留在原始位置,要么移动到原始位置+增加的数组大小这个位置上。(移动到原偏移量两倍的位置)
11.简单总结一下HashMap是使用了哪些方法来有效解决哈希冲突的:
- 使用链地址法(使用散列表)来链接拥有相同hash值的数据;
- 使用2次扰动函数(hash函数)来降低哈希冲突的概率,使得数据分布更平均;
- 引入红黑树进一步降低遍历的时间复杂度,使得遍历更快;
12. HashMap 与 HashTable 有什么区别?
- 线程安全: HashMap 是非线程安全的,HashTable 是线程安全的;HashTable 内部的方法基本都经过 synchronized 修饰。(如果你要保证线程安全的话就使用 ConcurrentHashMap 吧!);
- 效率: 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
- 对Null key 和Null value的支持: HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。但是在 HashTable 中 put 进的键值只要有一个 null,直接抛NullPointerException。
- **初始容量大小和每次扩充容量大小的不同 **: ①创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小。也就是说 HashMap 总是使用2的幂作为哈希表的大小,后面会介绍到为什么是2的幂次方。
- 底层数据结构: JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
- 推荐使用:在 Hashtable 的类注释可以看到,Hashtable 是保留类不建议使用,推荐在单线程环境下使用 HashMap 替代,如果需要多线程使用则用 ConcurrentHashMap 替代。
14.如何决定使用 HashMap 还是 TreeMap?
对于在Map中插入、删除和定位元素这类操作,HashMap是最好的选择。然而,假如你需要对一个有序的key集合进行遍历,TreeMap是更好的选择。基于你的collection的大小,也许向HashMap中添加元素会更快,将map换为TreeMap进行有序key的遍历。
15.HashMap 和 ConcurrentHashMap 的区别?
- ConcurrentHashMap对整个桶数组进行了分割分段(Segment),然后在每一个分段上都用lock锁进行保护,相对于HashTable的synchronized锁的粒度更精细了一些,并发性能更好,而HashMap没有锁机制,不是线程安全的。(JDK1.8之后ConcurrentHashMap启用了一种全新的方式实现,利用CAS算法。)
- HashMap的键值对允许有null,但是ConCurrentHashMap都不允许。
16.ConcurrentHashMap 和 Hashtable 的区别?
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
- 底层数据结构: JDK1.7的 ConcurrentHashMap 底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
- 实现线程安全的方式(重要): ① 在JDK1.7的时候,ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。(默认分配16个Segment,比Hashtable效率提高16倍。)
到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对 synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;
② Hashtable(同一把锁) :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
17.ConcurrentHashMap 底层具体实现知道吗?实现原理是什么?
JDK1.7
首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
在JDK1.7中,ConcurrentHashMap采用Segment + HashEntry的方式进行实现,结构如下:
一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和HashMap类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个HashEntry数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment的锁。
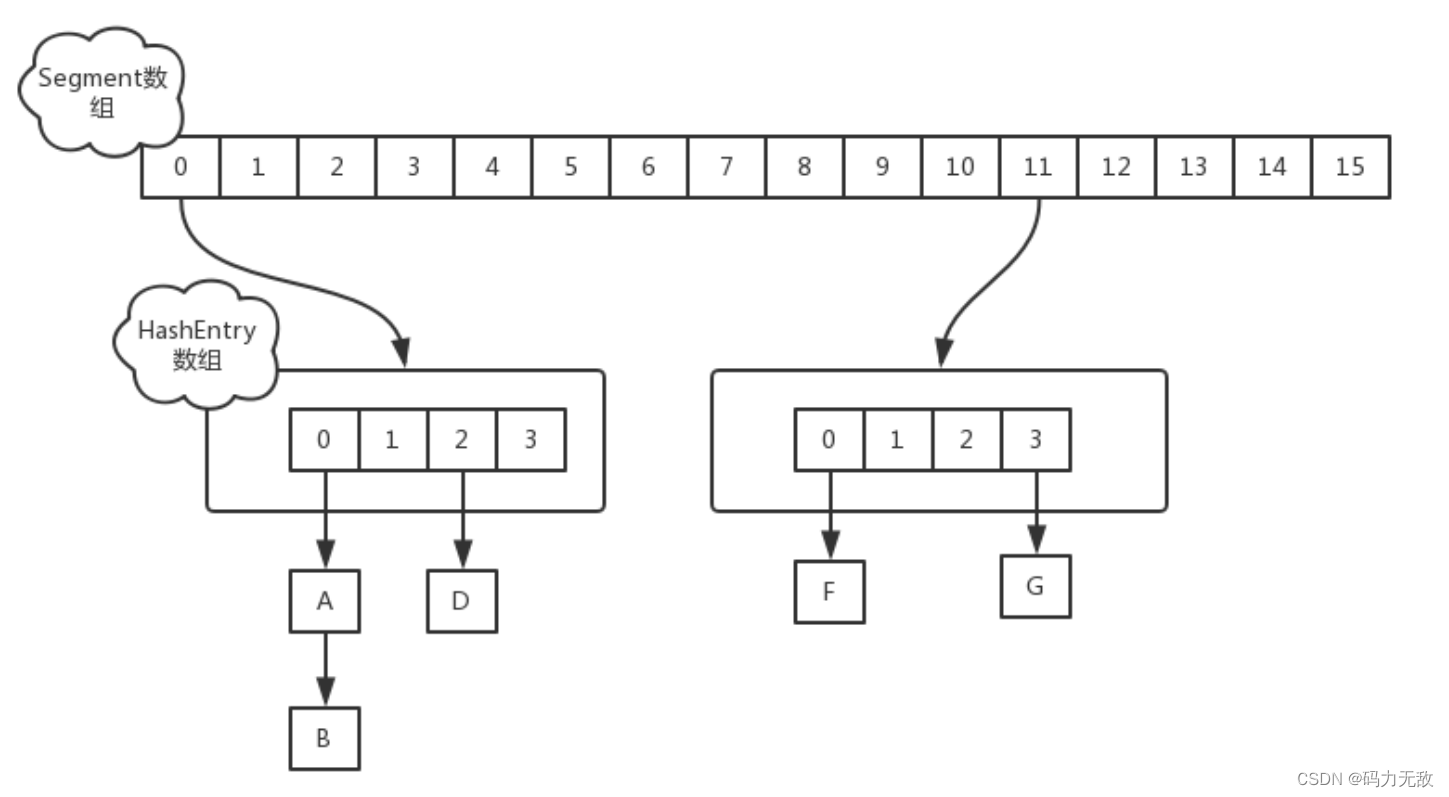
- 该类包含两个静态内部类 HashEntry 和 Segment ;前者用来封装映射表的键值对,后者用来充当锁的角色;
- Segment 是一种可重入的锁 ReentrantLock,每个 Segment 守护一个HashEntry 数组里得元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 锁。
JDK1.8
在JDK1.8中,放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保证并发安全进行实现,synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
 附加源码,有需要的可以看看
附加源码,有需要的可以看看
插入元素过程(建议去看看源码):
如果相应位置的Node还没有初始化,则调用CAS插入相应的数据;
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
- 1
- 2
- 3
- 4
如果相应位置的Node不为空,且当前该节点不处于移动状态,则对该节点加synchronized锁,如果该节点的hash不小于0,则遍历链表更新节点或插入新节点;
if (fh >= 0) { binCount = 1; for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 如果该节点是TreeBin类型的节点,说明是红黑树结构,则通过putTreeVal方法往红黑树中插入节点;如果binCount不为0,说明put操作对数据产生了影响,如果当前链表的个数达到8个,则通过treeifyBin方法转化为红黑树,如果oldVal不为空,说明是一次更新操作,没有对元素个数产生影响,则直接返回旧值;
- 如果插入的是一个新节点,则执行addCount()方法尝试更新元素个数baseCount;
三、java异常
1.Java异常简介
Java异常是Java提供的一种识别及响应错误的一致性机制。
Java异常机制可以使程序中异常处理代码和正常业务代码分离,保证程序代码更加优雅,并提高程序健壮性。在有效使用异常的情况下,异常能清晰的回答what, where, why这3个问题:异常类型回答了“什么”被抛出,异常堆栈跟踪回答了“在哪”抛出,异常信息回答了“为什么”会抛出。
Java异常架构
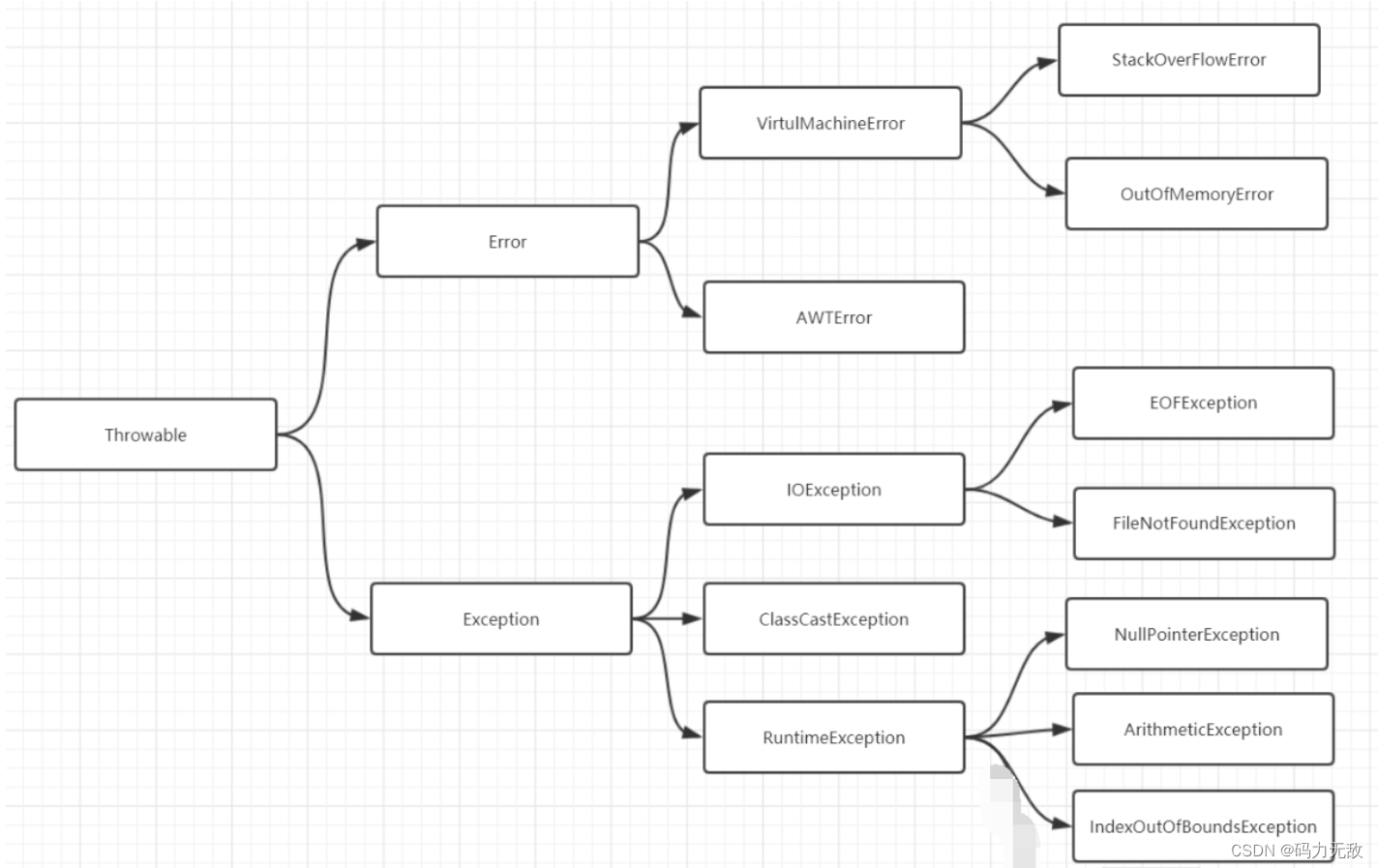
- Throwable
Throwable 是 Java 语言中所有错误与异常的超类。
Throwable 包含两个子类:Error(错误)和 Exception(异常),它们通常用于指示发生了异常情况。
Throwable 包含了其线程创建时线程执行堆栈的快照,它提供了 printStackTrace() 等接口用于获取堆栈跟踪数据等信息。
- Error(错误)
定义:Error 类及其子类。程序中无法处理的错误,表示运行应用程序中出现了严重的错误。
特点:此类错误一般表示代码运行时 JVM 出现问题。通常有 Virtual MachineError(虚拟机运行错误)、NoClassDefFoundError(类定义错误)等。比如 OutOfMemoryError:内存不足错误;StackOverflowError:栈溢出错误。此类错误发生时,JVM 将终止线程。
这些错误是不受检异常,非代码性错误。因此,当此类错误发生时,应用程序不应该去处理此类错误。按照Java惯例,我们是不应该实现任何新的Error子类的!
Exception(异常)
程序本身可以捕获并且可以处理的异常。Exception 这种异常又分为两类:运行时异常和编译时异常。
运行时异常
定义:RuntimeException 类及其子类,表示 JVM 在运行期间可能出现的异常。
特点:Java 编译器不会检查它。也就是说,当程序中可能出现这类异常时,倘若既"没有通过throws声明抛出它",也"没有用try-catch语句捕获它",还是会编译通过。比如NullPointerException空指针异常、ArrayIndexOutBoundException数组下标越界异常、ClassCastException类型转换异常、ArithmeticExecption算术异常。此类异常属于不受检异常,一般是由程序逻辑错误引起的,在程序中可以选择捕获处理,也可以不处理。虽然 Java 编译器不会检查运行时异常,但是我们也可以通过 throws 进行声明抛出,也可以通过 try-catch 对它进行捕获处理。如果产生运行时异常,则需要通过修改代码来进行避免。例如,若会发生除数为零的情况,则需要通过代码避免该情况的发生!
RuntimeException 异常会由 Java 虚拟机自动抛出并自动捕获(就算我们没写异常捕获语句运行时也会抛出错误!!),此类异常的出现绝大数情况是代码本身有问题应该从逻辑上去解决并改进代码。
编译时异常
定义: Exception 中除 RuntimeException 及其子类之外的异常。
特点: Java 编译器会检查它。如果程序中出现此类异常,比如 ClassNotFoundException(没有找到指定的类异常),IOException(IO流异常),要么通过throws进行声明抛出,要么通过try-catch进行捕获处理,否则不能通过编译。在程序中,通常不会自定义该类异常,而是直接使用系统提供的异常类。该异常我们必须手动在代码里添加捕获语句来处理该异常。
- 受检异常与非受检异常
Java 的所有异常可以分为受检异常(checked exception)和非受检异常(unchecked exception)。
受检异常
编译器要求必须处理的异常。正确的程序在运行过程中,经常容易出现的、符合预期的异常情况。一旦发生此类异常,就必须采用某种方式进行处理。除 RuntimeException 及其子类外,其他的 Exception 异常都属于受检异常。编译器会检查此类异常,也就是说当编译器检查到应用中的某处可能会此类异常时,将会提示你处理本异常——要么使用try-catch捕获,要么使用方法签名中用 throws 关键字抛出,否则编译不通过。
非受检异常
编译器不会进行检查并且不要求必须处理的异常,也就说当程序中出现此类异常时,即使我们没有try-catch捕获它,也没有使用throws抛出该异常,编译也会正常通过。该类异常包括运行时异常(RuntimeException极其子类)和错误(Error)。
2.Error 和 Exception 区别是什么?
Error 类型的错误通常为虚拟机相关错误,如系统崩溃,内存不足,堆栈溢出等,编译器不会对这类错误进行检测,JAVA 应用程序也不应对这类错误进行捕获,一旦这类错误发生,通常应用程序会被终止,仅靠应用程序本身无法恢复;
Exception 类的错误是可以在应用程序中进行捕获并处理的,通常遇到这种错误,应对其进行处理,使应用程序可以继续正常运行。
3.运行时异常和一般异常(受检异常)区别是什么?
运行时异常包括 RuntimeException 类及其子类,表示 JVM 在运行期间可能出现的异常。 Java 编译器不会检查运行时异常。
受检异常是Exception 中除 RuntimeException 及其子类之外的异常。 Java 编译器会检查受检异常。
RuntimeException异常和受检异常之间的区别:是否强制要求调用者必须处理此异常,如果强制要求调用者必须进行处理,那么就使用受检异常,否则就选择非受检异常(RuntimeException)。一般来讲,如果没有特殊的要求,我们建议使用RuntimeException异常。
4.JVM 是如何处理异常的?
在一个方法中如果发生异常,这个方法会创建一个异常对象,并转交给 JVM,该异常对象包含异常名称,异常描述以及异常发生时应用程序的状态。创建异常对象并转交给 JVM 的过程称为抛出异常。可能有一系列的方法调用,最终才进入抛出异常的方法,这一系列方法调用的有序列表叫做调用栈。
JVM 会顺着调用栈去查找看是否有可以处理异常的代码,如果有,则调用异常处理代码。当 JVM 发现可以处理异常的代码时,会把发生的异常传递给它。如果 JVM 没有找到可以处理该异常的代码块,JVM 就会将该异常转交给默认的异常处理器(默认处理器为 JVM 的一部分),默认异常处理器打印出异常信息并终止应用程序。
5.throw 和 throws 的区别是什么?
java 中的异常处理除了包括捕获异常和处理异常之外,还包括声明异常和拋出异常,可以通过 throws 关键字在方法上声明该方法要拋出的异常,或者在方法内部通过 throw 拋出异常对象。
throws 关键字和 throw 关键字在使用上的几点区别如下:
- throw 关键字用在方法内部,只能用于抛出一种异常,用来抛出方法或代码块中的异常,受查异常和非受查异常都可以被抛出。
- throws 关键字用在方法声明上,可以抛出多个异常,用来标识该方法可能抛出的异常列表。一个方法用 throws 标识了可能抛出的异常列表,调用该方法的方法中必须包含可处理异常的代码,否则也要在方法签名中用 throws 关键字声明相应的异常。
6. final、finally、finalize 有什么区别?
- final可以修饰类、变量、方法,修饰类表示该类不能被继承、修饰方法表示该方法不能被重写、修饰变量表示该变量是一个常量不能被重新赋值。
- finally一般作用在try-catch代码块中,在处理异常的时候,通常我们将一定要执行的代码方法finally代码块中,表示不管是否出现异常,该代码块都会执行,一般用来存放一些关闭资源的代码。
- finalize是一个方法,属于Object类的一个方法,而Object类是所有类的父类,Java 中允许使用 finalize()方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。
7. NoClassDefFoundError 和ClassNotFoundException 区别?
-
NoClassDefFoundError 是一个 Error 类型的异常,是由 JVM 引起的,不应该尝试捕获这个异常。
引起该异常的原因是 JVM 或 ClassLoader 尝试加载某类时在内存中找不到该类的定义,该动作发生在运行期间,即编译时该类存在,但是在运行时却找不到了,可能是变异后被删除了等原因导致; -
ClassNotFoundException 是一个受查异常,需要显式地使用 try-catch 对其进行捕获和处理,或在方法签名中用 throws 关键字进行声明。当使用 Class.forName, ClassLoader.loadClass 或 ClassLoader.findSystemClass 动态加载类到内存的时候,通过传入的类路径参数没有找到该类,就会抛出该异常;另一种抛出该异常的可能原因是某个类已经由一个类加载器加载至内存中,另一个加载器又尝试去加载它。
8 .try-catch-finally 中哪个部分可以省略?
答:catch 可以省略
原因
更为严格的说法其实是:try只适合处理运行时异常,try+catch适合处理运行时异常+普通异常。也就是说,如果你只用try去处理普通异常却不加以catch处理,编译是通不过的,因为编译器硬性规定,普通异常如果选择捕获,则必须用catch显示声明以便进一步处理。而运行时异常在编译时没有如此规定,所以catch可以省略,你加上catch编译器也觉得无可厚非。
理论上,编译器看任何代码都不顺眼,都觉得可能有潜在的问题,所以你即使对所有代码加上try,代码在运行期时也只不过是在正常运行的基础上加一层皮。但是你一旦对一段代码加上try,就等于显示地承诺编译器,对这段代码可能抛出的异常进行捕获而非向上抛出处理。如果是普通异常,编译器要求必须用catch捕获以便进一步处理;如果运行时异常,捕获然后丢弃并且+finally扫尾处理,或者加上catch捕获以便进一步处理。
至于加上finally,则是在不管有没捕获异常,都要进行的“扫尾”处理。
9.常见的 RuntimeException 有哪些?
ClassCastException(类转换异常)
IndexOutOfBoundsException(数组越界)
NullPointerException(空指针)
ArrayStoreException(数据存储异常,操作数组时类型不一致)
还有IO操作的BufferOverflowException异常
10.Java常见异常有哪些?
java.lang.IllegalAccessError:违法访问错误。当一个应用试图访问、修改某个类的域(Field)或者调用其方法,但是又违反域或方法的可见性声明,则抛出该异常。
java.lang.InstantiationError:实例化错误。当一个应用试图通过Java的new操作符构造一个抽象类或者接口时抛出该异常.
java.lang.OutOfMemoryError:内存不足错误。当可用内存不足以让Java虚拟机分配给一个对象时抛出该错误。
java.lang.StackOverflowError:堆栈溢出错误。当一个应用递归调用的层次太深而导致堆栈溢出或者陷入死循环时抛出该错误。
java.lang.ClassCastException:类造型异常。假设有类A和B(A不是B的父类或子类),O是A的实例,那么当强制将O构造为类B的实例时抛出该异常。该异常经常被称为强制类型转换异常。
java.lang.ClassNotFoundException:找不到类异常。当应用试图根据字符串形式的类名构造类,而在遍历CLASSPAH之后找不到对应名称的class文件时,抛出该异常。
java.lang.ArithmeticException:算术条件异常。譬如:整数除零等。
java.lang.ArrayIndexOutOfBoundsException:数组索引越界异常。当对数组的索引值为负数或大于等于数组大小时抛出。
java.lang.IndexOutOfBoundsException:索引越界异常。当访问某个序列的索引值小于0或大于等于序列大小时,抛出该异常。
java.lang.InstantiationException:实例化异常。当试图通过newInstance()方法创建某个类的实例,而该类是一个抽象类或接口时,抛出该异常。
java.lang.NoSuchFieldException:属性不存在异常。当访问某个类的不存在的属性时抛出该异常。
java.lang.NoSuchMethodException:方法不存在异常。当访问某个类的不存在的方法时抛出该异常。
java.lang.NullPointerException:空指针异常。当应用试图在要求使用对象的地方使用了null时,抛出该异常。譬如:调用null对象的实例方法、访问null对象的属性、计算null对象的长度、使用throw语句抛出null等等。
java.lang.NumberFormatException:数字格式异常。当试图将一个String转换为指定的数字类型,而该字符串确不满足数字类型要求的格式时,抛出该异常。
java.lang.StringIndexOutOfBoundsException:字符串索引越界异常。当使用索引值访问某个字符串中的字符,而该索引值小于0或大于等于序列大小时,抛出该异常。
11.Java异常处理最佳实践?
- 在 finally 块中清理资源或者使用 try-with-resource 语句
- 优先明确的异常,出的异常越明确越好。保证提供给他们尽可能多的信息。
- 对异常进行文档说明。在 Javadoc 添加 @throws 声明,并且描述抛出异常的场景。
- 使用描述性消息抛出异常。在抛出异常时,需要尽可能精确地描述问题和相关信息。
- 优先捕获最具体的异常。并将不太具体的 catch 块添加到列表的末尾。
- 不要捕获 Throwable 类,Throwable 是所有异常和错误的超类。你可以在 catch 子句中使用它,但是你永远不应该这样做!
如果在 catch 子句中使用 Throwable ,它不仅会捕获所有异常,也将捕获所有的错误。JVM 抛出错误,指出不应该由应用程序处理的严重问题。 典型的例子是 OutOfMemoryError 或者 StackOverflowError 。两者都是由应用程序控制之外的情况引起的,无法处理。
所以,最好不要捕获 Throwable ,除非你确定自己处于一种特殊的情况下能够处理错误。
7. 不要忽略异常。
8. 不要记录并抛出异常,会多输出日志。
try {
new Long("xyz");
} catch (NumberFormatException e) {
log.error(e);
throw e;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 包装异常时不要抛弃原始的异常
捕获标准异常并包装为自定义异常是一个很常见的做法。这样可以添加更为具体的异常信息并能够做针对的异常处理。
在你这样做时,请确保将原始异常设置为原因(注:参考下方代码 NumberFormatException e 中的原始异常 e )。Exception 类提供了特殊的构造函数方法,它接受一个 Throwable 作为参数。否则,你将会丢失堆栈跟踪和原始异常的消息,这将会使分析导致异常的异常事件变得困难。
public void wrapException(String input) throws MyBusinessException {
try {
// do something
} catch (NumberFormatException e) {
throw new MyBusinessException("A message that describes the error.", e);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 不要使用异常控制程序的流程。
- 使用标准异常
- 异常会影响性能,创建一个异常非常慢,抛出一个异常又会消耗1~5ms,当一个异常在应用的多个层级之间传递时,会拖累整个应用的性能。
四、Java并发-多线程
1.并发编程三要素是什么?在 Java 程序中怎么保证多线程的运行安全?***
并发编程三要素(线程的安全性问题体现在):
原子性:原子,即一个不可再被分割的颗粒。原子性指的是一个或多个操作要么全部执行成功要么全部执行失败。
可见性:一个线程对共享变量的修改,另一个线程能够立刻看到。(synchronized,volatile)
有序性:程序执行的顺序按照代码的先后顺序执行。(处理器可能会对指令进行重排序)
出现线程安全问题的原因:
- 线程切换带来的原子性问题
- 缓存导致的可见性问题
- 编译优化带来的有序性问题
解决办法:
- JDK Atomic开头的原子类、synchronized、LOCK,可以解决原子性问题
- synchronized、volatile、LOCK,可以解决可见性问题
- Happens-Before 规则可以解决有序性问题
2. 如何在 Windows 和 Linux 上查找哪个线程cpu利用率最高?
windows上面用任务管理器看,linux下可以用 top 这个工具看。
找出cpu耗用厉害的进程pid, 终端执行top命令,然后按下shift+p 查找出cpu利用最厉害的pid号
根据上面第一步拿到的pid号,top -H -p pid 。然后按下shift+p,查找出cpu利用率最厉害的线程号,比如top -H -p 1328
将获取到的线程号转换成16进制,去百度转换一下就行
使用jstack工具将进程信息打印输出,jstack pid号 > /tmp/t.dat,比如jstack 31365 > /tmp/t.dat
编辑/tmp/t.dat文件,查找线程号对应的信息
3.什么是线程死锁
死锁是指两个或两个以上的进程(线程)在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程(线程)称为死锁进程(线程)。
多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
4. 形成死锁的四个必要条件是什么?
- 互斥条件:线程(进程)对于所分配到的资源具有排它性,即一个资源只能被一个线程(进程)占用,直到被该线程(进程)释放
- 请求与保持条件:一个线程(进程)因请求被占用资源而发生阻塞时,对已获得的资源保持不放。
- 不剥夺条件:线程(进程)已获得的资源在末使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
- 循环等待条件:当发生死锁时,所等待的线程(进程)必定会形成一个环路(类似于死循环),造成永久阻塞.
如何避免线程死锁
- 破坏请求与保持条件:一次性申请所有的资源。
- 破坏不剥夺条件:占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
- 破坏循环等待条件:靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
5.创建线程有哪几种方式?
- 继承 Thread 类;
- 实现 Runnable 接口;
- 实现 Callable 接口;
- 使用 Executors 工具类创建线程池
继承 Thread 类
- 定义一个Thread类的子类,重写run方法,将相关逻辑实现,run()方法就是线程要执行的业务逻辑方法
- 创建自定义的线程子类对象
- 调用子类实例的star()方法来启动线程
实现 Runnable 接口
- 定义Runnable接口实现类MyRunnable,并重写run()方法
- 创建MyRunnable实例myRunnable,以myRunnable作为target创建Thead对象,该Thread对象才是真正的线程对象
- 调用线程对象的start()方法
public class RunnableTest {
public static void main(String[] args) {
MyRunnable myRunnable = new MyRunnable();
Thread thread = new Thread(myRunnable);
thread.start();
System.out.println(Thread.currentThread().getName() + " main()方法执行完成");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
实现 Callable 接口
8. 创建实现Callable接口的类myCallable
9. 以myCallable为参数创建FutureTask对象
10. 将FutureTask作为参数创建Thread对象
11. 调用线程对象的start()方法
public class CallableTest {
public static void main(String[] args) {
FutureTask<Integer> futureTask = new FutureTask<Integer>(new MyCallable());
Thread thread = new Thread(futureTask);
thread.start();
try {
Thread.sleep(1000);
System.out.println("返回结果 " + futureTask.get());
} catch (ExecutionException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " main()方法执行完成");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
使用 Executors 工具类创建线程池
Executors提供了一系列工厂方法用于创先线程池,返回的线程池都实现了ExecutorService接口。
主要有newFixedThreadPool,newCachedThreadPool,newSingleThreadExecutor,newScheduledThreadPool.
public class SingleThreadExecutorTest {
public static void main(String[] args) {
ExecutorService executorService = Executors.newSingleThreadExecutor();
MyRunnable runnableTest = new MyRunnable();
for (int i = 0; i < 5; i++) {
executorService.execute(runnableTest);
}
System.out.println("线程任务开始执行");
executorService.shutdown();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
6.说一下 runnable 和 callable 有什么区别?
相同点
都是接口
都可以编写多线程程序
都采用Thread.start()启动线程
主要区别
- Runnable 接口 run 方法无返回值;Callable 接口 call 方法有返回值,是个泛型,和Future、FutureTask配合可以用来获取异步执行的结果
- Runnable 接口 run 方法只能抛出运行时异常,且无法捕获处理;Callable 接口 call 方法允许抛出异常,可以获取异常信息。
注:Callalbe接口支持返回执行结果,需要调用FutureTask.get()得到,此方法会阻塞主进程的继续往下执行,如果不调用不会阻塞。
7.线程的生命周期?*****
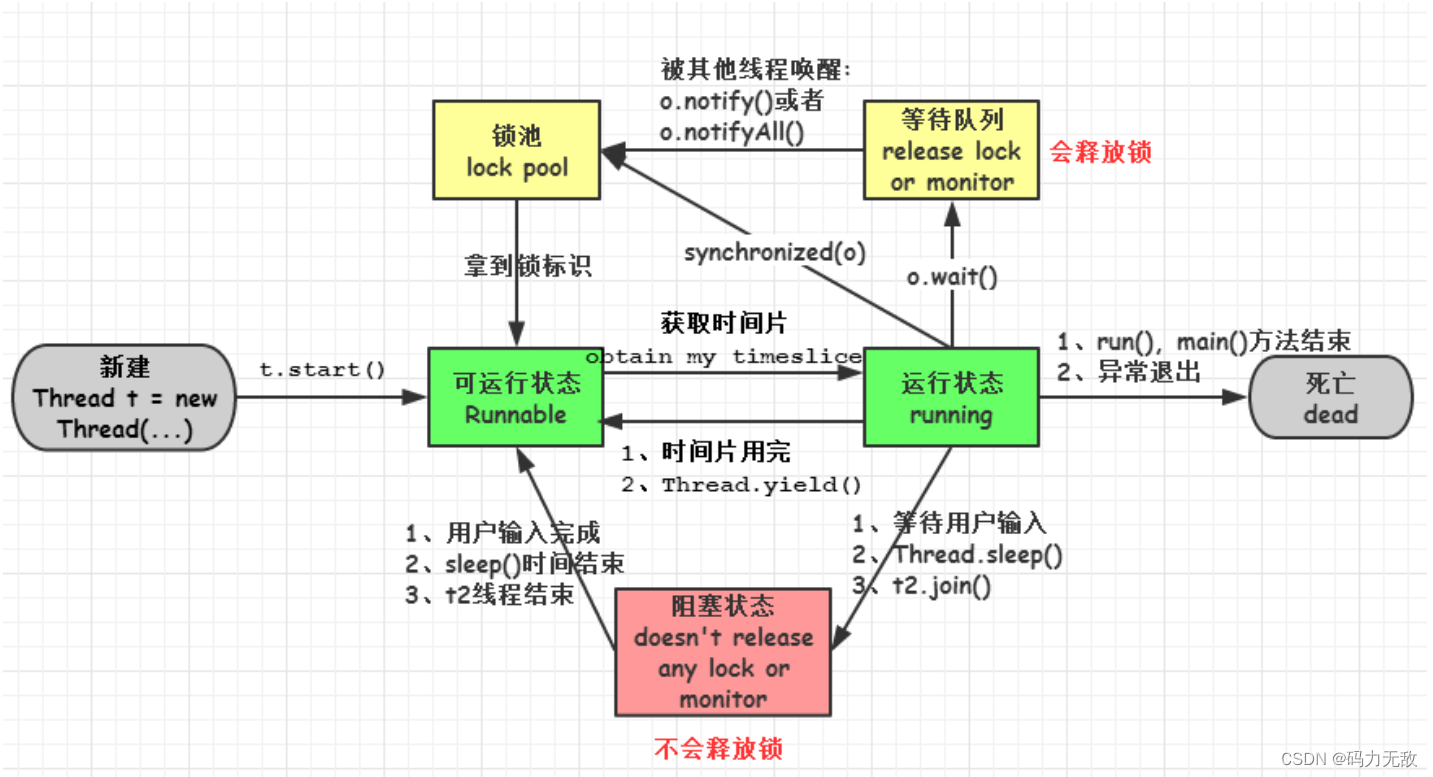
- 新建(new):新创建了一个线程对象。
- 可运行(runnable):线程对象创建后,当调用线程对象的 start()方法,该线程处于就绪状态,等待被线程调度选中,获取cpu的使用权。
- 运行(running):可运行状态(runnable)的线程获得了cpu时间片(timeslice),执行程序代码。注:就绪状态是进入到运行状态的唯一入口,也就是说,线程要想进入运行状态执行,首先必须处于就绪状态中;
- 阻塞(block):处于运行状态中的线程由于某种原因,暂时放弃对 CPU的使用权,停止执行,此时进入阻塞状态,直到其进入到就绪状态,才 有机会再次被 CPU 调用以进入到运行状态。
阻塞的情况分三种:
(一). 等待阻塞:运行状态中的线程执行 wait()方法,JVM会把该线程放入等待队列(waitting queue)中,使本线程进入到等待阻塞状态;
(二). 同步阻塞:线程在获取 synchronized 同步锁失败(因为锁被其它线程所占用),,则JVM会把该线程放入锁池(lock pool)中,线程会进入同步阻塞状态;
(三). 其他阻塞: 通过调用线程的 sleep()或 join()或发出了 I/O 请求时,线程会进入到阻塞状态。当 sleep()状态超时、join()等待线程终止或者超时、或者 I/O 处理完毕时,线程重新转入就绪状态。
- 死亡(dead):线程run()、main()方法执行结束,或者因异常退出了run()方法,则该线程结束生命周期。死亡的线程不可再次复生。
8.Java 中用到的线程调度算法是什么?
计算机通常只有一个 CPU,在任意时刻只能执行一条机器指令,每个线程只有获得CPU 的使用权才能执行指令。所谓多线程的并发运行,其实是指从宏观上看,各个线程轮流获得 CPU 的使用权,分别执行各自的任务。在运行池中,会有多个处于就绪状态的线程在等待 CPU,JAVA 虚拟机的一项任务就是负责线程的调度,线程调度是指按照特定机制为多个线程分配 CPU 的使用权。
有两种调度模型:分时调度模型和抢占式调度模型。
分时调度模型是指让所有的线程轮流获得 cpu 的使用权,并且平均分配每个线程占用的 CPU 的时间片这个也比较好理解。
Java虚拟机采用抢占式调度模型,是指优先让可运行池中优先级高的线程占用CPU,如果可运行池中的线程优先级相同,那么就随机选择一个线程,使其占用CPU。处于运行状态的线程会一直运行,直至它不得不放弃 CPU。
9 .线程的调度策略
线程调度器选择优先级最高的线程运行,但是,如果发生以下情况,就会终止线程的运行:
(1)线程体中调用了 yield 方法让出了对 cpu 的占用权利
(2)线程体中调用了 sleep 方法使线程进入睡眠状态
(3)线程由于 IO 操作受到阻塞
(4)另外一个更高优先级线程出现
(5)在支持时间片的系统中,该线程的时间片用完
10.什么是线程调度器(Thread Scheduler)和时间分片(Time Slicing )?
线程调度器是一个操作系统服务,它负责为 Runnable 状态的线程分配 CPU 时间。一旦我们创建一个线程并启动它,它的执行便依赖于线程调度器的实现。
时间分片是指将可用的 CPU 时间分配给可用的 Runnable 线程的过程。分配 CPU 时间可以基于线程优先级或者线程等待的时间。
线程调度并不受到 Java 虚拟机控制,所以由应用程序来控制它是更好的选择(也就是说不要让你的程序依赖于线程的优先级)。
11.请说出与线程同步以及线程调度相关的方法。
(1) wait():使一个线程处于等待(阻塞)状态,并且释放所持有的对象的锁;
(2)sleep():使一个正在运行的线程处于睡眠状态,是一个静态方法,调用此方法要处理 InterruptedException 异常,不释放锁。
(3)notify():唤醒一个处于等待状态的线程,当然在调用此方法的时候,并不能确切的唤醒某一个等待状态的线程,而是由 JVM 确定唤醒哪个线程,而且与优先级无关;
(4)notityAll():唤醒所有处于等待状态的线程,该方法并不是将对象的锁给所有线程,而是让它们竞争,只有获得锁的线程才能进入就绪状态;
12.sleep() 和 wait() 有什么区别?
两者都可以暂停线程的执行
- 类的不同:sleep() 是 Thread线程类的静态方法,wait() 是 Object类的方法。
- 是否释放锁:sleep() 不释放锁;wait() 释放锁。
- 用途不同:Wait 通常被用于线程间交互/通信,sleep 通常被用于暂停执行。
- 用法不同:wait() 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 notify() 或者 notifyAll() 方法。sleep() 方法执行完成后,线程会自动苏醒。或者可以使用wait(long timeout)超时后线程会自动苏醒。
13.为什么线程通信的方法 wait(), notify()和 notifyAll()被定义在 Object 类里?***
Java中,任何对象都可以作为锁,并且 wait(),notify()等方法用于等待对象的锁或者唤醒线程,在 Java 的线程中并没有可供任何对象使用的锁,所以任意对象调用方法一定定义在Object类中。
wait(), notify()和 notifyAll()这些方法在同步代码块中调用
有的人会说,既然是线程放弃对象锁,那也可以把wait()定义在Thread类里面啊,新定义的线程继承于Thread类,也不需要重新定义wait()方法的实现。然而,这样做有一个非常大的问题,一个线程完全可以持有很多锁,你一个线程放弃锁的时候,到底要放弃哪个锁?当然了,这种设计并不是不能实现,只是管理起来更加复杂。
综上所述,wait()、notify()和notifyAll()方法要定义在Object类中。
14.为什么 wait(), notify()和 notifyAll()必须在同步方法或者同步块中被调用?
当一个线程需要调用对象的 wait()方法的时候,这个线程必须拥有该对象的锁,接着它就会释放这个对象锁并进入等待状态直到其他线程调用这个对象上的 notify()方法。
同样的,当一个线程需要调用对象的 notify()方法时,它会释放这个对象的锁,以便其他在等待的线程就可以得到这个对象锁。由于所有的这些方法都需要线程持有对象的锁,这样就只能通过同步来实现,所以他们只能在同步方法或者同步块中被调用。
15.Thread 类中的 yield 方法有什么作用?
使当前线程从执行状态(运行状态)变为可执行态(就绪状态)。
当前线程到了就绪状态,那么接下来哪个线程会从就绪状态变成执行状态呢?可能是当前线程,也可能是其他线程,看系统的分配了。
16.线程的 sleep()方法和 yield()方法有什么区别?
(1) sleep()方法给其他线程运行机会时不考虑线程的优先级,因此会给低优先级的线程以运行的机会;yield()方法只会给相同优先级或更高优先级的线程以运行的机会;
(2) 线程执行 sleep()方法后转入阻塞(blocked)状态,而执行 yield()方法后转入就绪(ready)状态;
(3)sleep()方法声明抛出 InterruptedException,而 yield()方法没有声明任何异常;
(4)sleep()方法比 yield()方法(跟操作系统 CPU 调度相关)具有更好的可移植性,通常不建议使用yield()方法来控制并发线程的执行。
17.如何停止一个正在运行的线程?*****
在java中有以下3种方法可以终止正在运行的线程:
- 使用退出标志,使线程正常退出,也就是当run方法完成后线程终止。
- 使用stop方法强行终止,已经过期,不推荐。stop方法会导致代码逻辑不完整是一种“恶意”的中断,一旦执行stop方法,即终止当前正在运行的线程,不管线程逻辑是否完整,这是非常危险的。
- 使用interrupt方法中断线程。
18.Java 中 interrupted 和 isInterrupted 方法的区别?
interrupt:用于中断线程。调用该方法的线程的状态为将被置为”中断”状态。
注意:线程中断仅仅是置线程的中断状态位,不会停止线程。需要用户自己去监视线程的状态为并做处理。支持线程中断的方法(也就是线程中断后会抛出interruptedException 的方法)就是在监视线程的中断状态,一旦线程的中断状态被置为“中断状态”,就会抛出中断异常。
interrupted:是静态方法,查看当前中断信号是true还是false并且清除中断信号。如果一个线程被中断了,第一次调用 interrupted 则返回 true,第二次和后面的就返回 false 了。
isInterrupted:查看当前中断信号是true还是false
19.Java 中你怎样唤醒一个阻塞的线程?
首先 ,wait()、notify() 方法是针对对象的,调用任意对象的 wait()方法都将导致线程阻塞,阻塞的同时也将释放该对象的锁,相应地,调用任意对象的 notify()方法则将随机解除该对象阻塞的线程,但它需要重新获取该对象的锁,直到获取成功才能往下执行;
其次,wait、notify 方法必须在 synchronized 块或方法中被调用,并且要保证同步块或方法的锁对象与调用 wait、notify 方法的对象是同一个,如此一来在调用 wait 之前当前线程就已经成功获取某对象的锁,执行 wait 阻塞后当前线程就将之前获取的对象锁释放。
20.notify() 和 notifyAll() 有什么区别?
如果线程调用了对象的 wait()方法,那么线程便会处于该对象的等待池中,等待池中的线程不会去竞争该对象的锁。
notifyAll() 会唤醒所有的线程,notify() 只会唤醒一个线程。
notifyAll() 调用后,会将全部线程由等待池移到锁池,然后参与锁的竞争,竞争成功则继续执行,如果不成功则留在锁池等待锁被释放后再次参与竞争。而 notify()只会唤醒一个线程,具体唤醒哪一个线程由虚拟机控制。
21.如何在两个线程间共享数据?****
在两个线程间共享变量即可实现共享。
Java 里面进行多线程通信的主要方式就是共享内存的方式,共享内存主要的关注点有两个:可见性和有序性原子性。Java 内存模型(JMM)解决了可见性和有序性的问题,而锁解决了原子性的问题。
方法一:
- 将数据抽象成一个类,并对类里的数据操作方法加上锁:在方法上加“synchronized“,可以做到同步,
- 将 Runnable 对象作为一个类的内部类,共享数据作为这个类的成员变量,每个线程对共享数据的操作方法也封装在外部类,以便实现对数据的各个操作的同步和互斥,作为内部类的各个 Runnable 对象调用外部类的这些方法。
public class MyData { private int j=0; public synchronized void add(){ j++; System.out.println("线程"+Thread.currentThread().getName()+"j 为:"+j); } public synchronized void dec(){ j--; System.out.println("线程"+Thread.currentThread().getName()+"j 为:"+j); } public int getData(){ return j; } } public class TestThread { public static void main(String[] args) { final MyData data = new MyData(); for(int i=0;i<2;i++){ new Thread(new Runnable(){ public void run() { data.add(); } }).start(); new Thread(new Runnable(){ public void run() { data.dec(); } }).start(); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
22.Java 如何实现多线程之间的通讯和协作?
可以通过中断 和 共享变量的方式实现线程间的通讯和协作。
Java中线程通信协作的最常见的两种方式:
一.syncrhoized加锁的线程的Object类的wait()/notify()/notifyAll()
二.ReentrantLock类加锁的线程的Condition类的await()/signal()/signalAll()
线程间直接的数据交换:
三.通过管道进行线程间通信:1)字节流;2)字符流
23.什么是线程同步和线程互斥,有哪几种实现方式?
当一个线程对共享的数据进行操作时,应使之成为一个”原子操作“,即在没有完成相关操作之前,不允许其他线程打断它,否则,就会破坏数据的完整性,必然会得到错误的处理结果,这就是线程的同步。
线程互斥是指对于共享的进程系统资源,在各单个线程访问时的排它性。当有若干个线程都要使用某一共享资源时,任何时刻最多只允许一个线程去使用,其它要使用该资源的线程必须等待,直到占用资源者释放该资源。线程互斥可以看成是一种特殊的线程同步。
实现线程同步的方法
- 同步代码方法:sychronized 关键字修饰的方法
- 同步代码块:sychronized 关键字修饰的代码块
- 使用特殊变量域volatile实现线程同步:volatile关键字为域变量的访问提供了一种免锁机制
- 使用重入锁实现线程同步:reentrantlock类是可冲入、互斥、实现了lock接口的锁他与sychronized方法具有相同的基本行为和语义
25.如果你提交任务时,线程池队列已满,会发生什么?
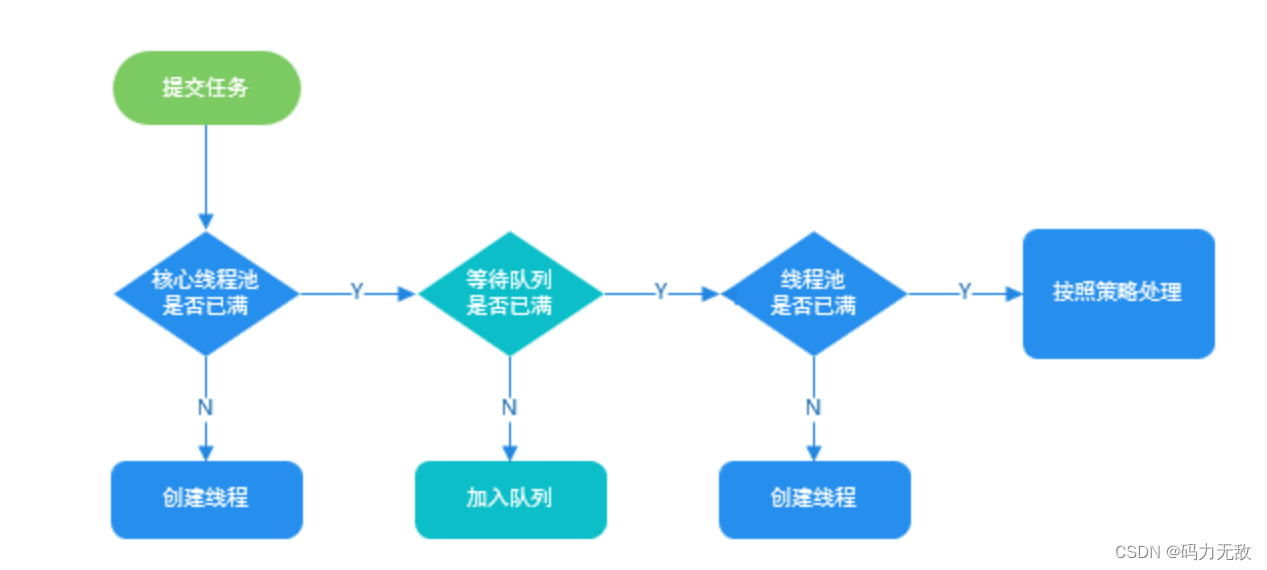
(1)如果使用的是无界队列 LinkedBlockingQueue,也就是无界队列的话,没关系,继续添加任务到阻塞队列中等待执行,因为 LinkedBlockingQueue 可以近乎认为是一个无穷大的队列,可以无限存放任务
(2)如果使用的是有界队列比如 ArrayBlockingQueue,任务首先会被添加到ArrayBlockingQueue 中,ArrayBlockingQueue 满了,会根据maximumPoolSize 的值增加线程数量,如果增加了线程数量还是处理不过来,ArrayBlockingQueue 继续满,那么则会使用拒绝策略RejectedExecutionHandler 处理满了的任务,默认是 AbortPolicy
26.在 Java 程序中怎么保证多线程的运行安全?
方法一:使用原子类、java原子类的实现都在java.util.concurrent.atomic包下,基本是通过自旋+原子CAS操作实现的,不会出现安全问题。AtomicInteger、AtomicReference、AtomicInteger、AtomicIntegerArray、AtomicIntegerFieldUpdaterImpl、针对累加这种特殊的业务场景,JUC提供了专门的LongAdder累加器,它比AtomicLong原子类性能更高,在高并发的情况下,多线程同时执行add()函数,AtomicLong会因为大量线程而不断自旋导致性能下降,但是LongAdder却能保持高性能。详细见:https://juejin.cn/post/7201009854524375095 其底层原理比较复杂,涉及到数据分片,哈希优化,去伪共享,非精确求和等各种优化手段。方法二:加锁:自动锁 synchronized,手动锁 Lock。
其底层原理比较复杂,涉及到数据分片,哈希优化,去伪共享,非精确求和等各种优化手段。方法二:加锁:自动锁 synchronized,手动锁 Lock。
AtomicInteger:自旋 + CAS操作来实现一个线程安全的累加器。原理:
private static final Unsafe unsafe = Unsafe.getUnsafe(); private static final long valueOffset; private volatile int value; static { try { valueOffset = unsafe.objectFieldOffset(Accumulator.class.getDeclaredField("value")); } catch (Exception ex) { throw new Error(ex); } } public void increment_cas(){ boolean success = false; while(!success){ int oldValue = value; int newValue = oldValue + 1; success = unsafe.compareAndSwapInt(this, valueOffset, oldValue, newValue); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20

27.线程类的构造方法、静态块是被哪个线程调用的?
线程类的构造方法、静态块是被 new这个线程类所在的线程所调用的,而 run 方法里面的代码才是被线程自身所调用的。
如果说上面的说法让你感到困惑,那么我举个例子,假设 Thread2 中 new 了Thread1,main 函数中 new 了 Thread2,那么:
(1)Thread2 的构造方法、静态块是 main 线程调用的,Thread2 的 run()方法是Thread2 自己调用的
(2)Thread1 的构造方法、静态块是 Thread2 调用的,Thread1 的 run()方法是Thread1 自己调用的
28.synchronized 的作用?
在 Java 中,synchronized 关键字是用来控制线程同步的,就是在多线程的环境下,控制 synchronized 代码段不被多个线程同时执行。synchronized 可以修饰类、方法、变量。
另外,在 Java 早期版本中,synchronized属于重量级锁,效率低下,因为监视器锁(monitor)是依赖于底层的操作系统的 Mutex Lock 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,这也是为什么早期的 synchronized 效率低的原因。庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对synchronized 较大优化,所以现在的 synchronized 锁效率也优化得很不错了。JDK1.6对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
29.synchronized关键字最主要的三种使用方式?
- 修饰实例方法: 作用于当前对象实例加锁,进入同步代码前要获得当前对象实例的锁
- 修饰静态方法: 也就是给当前类加锁,会作用于类的所有对象实例,因为静态成员不属于任何一个实例对象,是类成员( static 表明这是该类的一个静态资源,不管new了多少个对象,只有一份)。所以如果一个线程A调用一个实例对象的非静态 synchronized 方法,而线程B需要调用这个实例对象所属类的静态 synchronized 方法,是允许的,不会发生互斥现象,因为访问静态 synchronized 方法占用的锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁。
- 修饰代码块: 指定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。
30.说一下 synchronized 底层实现原理?
synchronized是Java中的一个关键字,要通过javap命令,查看相应的字节码文件。synchronized关键字毕竟是jvm底层实现的,会设计用户态和内核态的切换,cpu会消耗更多的时间在线程调度上。
可以看出在执行同步代码块之前之后都有一个monitor字样,其中前面的是monitorenter,后面的是离开monitorexit,不难想象一个线程也执行同步代码块,首先要获取锁,而获取锁的过程就是monitorenter ,在执行完代码块之后,要释放锁,释放锁就是执行monitorexit指令。
为什么会有两个monitorexit呢?
这个主要是防止在同步代码块中线程因异常退出,而锁没有得到释放,这必然会造成死锁(等待的线程永远获取不到锁)。因此最后一个monitorexit是保证在异常情况下,锁也可以得到释放,避免死锁。
仅有ACC_SYNCHRONIZED这么一个标志,该标记表明线程进入该方法时,需要monitorenter,退出该方法时需要monitorexit。
synchronized可重入的原理
重入锁是指一个线程获取到该锁之后,该线程可以继续获得该锁。底层原理维护一个计数器,当线程获取该锁时,计数器加一,再次获得该锁时继续加一,释放锁时,计数器减一,当计数器值为0时,表明该锁未被任何线程所持有,其它线程可以竞争获取锁。
什么是自旋?
JDK版本高于1.6的时候,synchronized已经被做了CAS的优化,
很多 synchronized 里面的代码只是一些很简单的代码,执行时间非常快,此时等待的线程都加锁可能是一种不太值得的操作,因为线程阻塞涉及到用户态和内核态切换的问题。既然 synchronized 里面的代码执行得非常快,不妨让等待锁的线程不要被阻塞,而是在 synchronized 的边界做忙循环,这就是自旋。如果做了多次循环发现还没有获得锁,再阻塞,这样可能是一种更好的策略。
lock实现原理则是依赖于硬件,现代处理器都支持CAS指令,所谓CAS指令简单的来说Compare And Set,CPU循环执行指令直到得到所期望的结果,换句话来说就是当变量真实值不等于当前线程调用时的值的时候(说明其他线程已经将这个值改变),就不会赋予变量新的值。这样就保证了变量在多线程环境下的安全性。
30.多线程中 synchronized 锁升级的原理是什么?
在锁对象的对象头里面有一个 threadid 字段,在第一次访问的时候 threadid 为空,jvm 让其持有偏向锁,并将 threadid 设置为其线程 id,再次进入的时候会先判断 threadid 是否与其线程 id 一致,如果一致则可以直接使用此对象,如果不一致,则升级偏向锁为轻量级锁,通过自旋循环一定次数来获取锁,执行一定次数之后,如果还没有正常获取到要使用的对象,此时就会把锁从轻量级升级为重量级锁,此过程就构成了 synchronized 锁的升级。
锁的升级的目的:锁升级是为了减低了锁带来的性能消耗。在 Java 6 之后优化 synchronized 的实现方式,使用了偏向锁升级为轻量级锁再升级到重量级锁的方式,从而减低了锁带来的性能消耗。
31.synchronized、volatile、CAS 比较?
(1)synchronized 是悲观锁,属于抢占式,会引起其他线程阻塞。
(2)volatile 提供多线程共享变量可见性和禁止指令重排序优化。
(3)CAS 是基于冲突检测的乐观锁(非阻塞)
32.synchronized 和 Lock 有什么区别?
- 首先synchronized是Java内置关键字,在JVM层面,Lock是个Java类;
- synchronized 可以给类、方法、代码块加锁;而 lock 只能给代码块加锁。
- synchronized 不需要手动获取锁和释放锁,使用简单,发生异常会自动释放锁,不会造成死锁;而 lock 需要自己加锁和释放锁,如果使用不当没有 unLock()去释放锁就会造成死锁。
- 通过 Lock 可以知道有没有成功获取锁,而 synchronized 却无法办到。
33.synchronized 和 ReentrantLock 区别是什么?
synchronized 是java关键字,ReentrantLock 是类,这是二者的本质区别。既然 ReentrantLock 是类,那么它就提供了比synchronized 更多更灵活的特性,可以被继承、可以有方法、可以有各种各样的类变量
synchronized 早期的实现比较低效,对比 ReentrantLock,大多数场景性能都相差较大,但是在 Java 6 中对 synchronized 进行了非常多的改进。
相同点:两者都是可重入锁
两者都是可重入锁。“可重入锁”概念是:同一个线程每次获取锁,是可重复获取的,再次获取锁的计数器都自增1,所以要等到锁的计数器下降为0时才能释放锁。
主要区别如下:
- ReentrantLock 使用起来比较灵活,但是必须有释放锁的配合动作;
- ReentrantLock 必须手动获取与释放锁,而 synchronized 不需要手动释放和开启锁;
- ReentrantLock 只适用于代码块锁,而 synchronized 可以修饰类、方法、代码块等。
- 二者的锁机制其实也是不一样的。ReentrantLock 底层调用的是 Unsafe 的park 方法加锁,synchronized 操作的应该是对象头中 mark word。
Java中每一个对象都可以作为锁,这是synchronized实现同步的基础:
- 普通同步方法,锁是当前实例对象
- 静态同步方法,锁是当前类的class对象
- 同步方法块,锁是括号里面的对象
34. volatile 关键字的作用
对于可见性,Java 提供了 volatile 关键字来保证可见性和禁止指令重排。 volatile 提供 happens-before 的保证,禁止指令重排,确保一个线程的修改能对其他线程是可见的。当一个共享变量被 volatile 修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
从实践角度而言,volatile 的一个重要作用就是和 CAS 结合,保证了原子性,详细的可以参见 java.util.concurrent.atomic 包下的类,比如 AtomicInteger。
volatile 常用于多线程环境下的单次操作(单次读或者单次写)。
只需要给instance的声明加上volatile关键字即可volatile关键字的一个作用是禁止指令重排,把instance声明为volatile之后,对它的写操作就会有一个内存屏障(什么是内存屏障?),这样,在它的赋值完成之前,就不用会调用读操作。注意:volatile阻止的不是singleton = newSingleton()这句话内部[1-2-3]的指令重排,而是保证了在一个写操作([1-2-3])完成之前,不会调用读操作(if (instance == null))。
34.volatile 能使得一个非原子操作变成原子操作吗?***
关键字volatile的主要作用是使变量在多个线程间可见,但无法保证原子性,对于多个线程访问同一个实例变量需要加锁进行同步。
虽然volatile只能保证可见性不能保证原子性,但用volatile修饰long和double可以保证其操作原子性。
所以从Oracle Java Spec里面可以看到:
对于64位的long和double,如果没有被volatile修饰,那么对其操作可以不是原子的。在操作的时候,可以分成两步,每次对32位操作。
如果使用volatile修饰long和double,那么其读写都是原子操作
对于64位的引用地址的读写,都是原子操作
在实现JVM时,可以自由选择是否把读写long和double作为原子操作
推荐JVM实现为原子操作
35.Java Concurrency API 中的 Lock 接口(Lock interface)是什么?对比同步它有什么优势?
Lock 接口比同步方法和同步块提供了更具扩展性的锁操作。他们允许更灵活的结构,可以具有完全不同的性质,并且可以支持多个相关类的条件对象。
它的优势有:
(1)可以使锁更公平,支持非公平锁(默认)和公平锁。synchronized 只支持非公平锁。
(2)可以使线程在等待锁的时候响应中断,lockInterruptibly
(3)可以让线程尝试获取锁,并在无法获取锁的时候立即返回或者等待一段时间,tryLock
(4)可以在不同的范围,以不同的顺序获取和释放锁。
整体上来说 Lock 是 synchronized 的扩展版,Lock 提供了无条件的、可轮询的(tryLock 方法)、定时的(tryLock 带参方法)、可中断的(lockInterruptibly)、可多条件队列的(newCondition 方法)锁操作。非公平锁的每个请求都会尝试获取锁,获取不到才放入队列。
37.乐观锁和悲观锁的理解及如何实现,有哪些实现方式?
悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。再比如 Java 里面的同步原语 synchronized 关键字的实现也是悲观锁。
乐观锁:顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于 write_condition 机制,其实都是提供的乐观锁。在 Java中 java.util.concurrent.atomic 包下面的原子变量类就是使用了乐观锁的一种实现方式 CAS 实现的。
乐观锁的实现方式:
1、使用版本标识来确定读到的数据与提交时的数据是否一致。提交后修改版本标识,不一致时可以采取丢弃和再次尝试的策略。
2、java 中的 Compare and Swap 即 CAS ,当多个线程尝试使用 CAS 同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。 CAS 操作中包含三个操作数 —— 需要读写的内存位置(V)、进行比较的预期原值(A)和拟写入的新值(B)。如果内存位置 V 的值与预期原值 A 相匹配,那么处理器会自动将该位置值更新为新值 B。否则处理器不做任何操作。
38.什么是 CAS?
CAS 是 compare and swap 的缩写,即我们所说的比较交换。
cas 是一种基于锁的操作,而且是乐观锁。在 java 中锁分为乐观锁和悲观锁。悲观锁是将资源锁住,等一个之前获得锁的线程释放锁之后,下一个线程才可以访问。而乐观锁采取了一种宽泛的态度,通过某种方式不加锁来处理资源,比如通过给记录加 version 来获取数据,性能较悲观锁有很大的提高。
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。如果内存地址里面的值和 A 的值是一样的,那么就将内存里面的值更新成 B。CAS是通过无限循环来获取数据的,若果在第一轮循环中,a 线程获取地址里面的值被b 线程修改了,那么 a 线程需要自旋,到下次循环才有可能机会执行。
java.util.concurrent.atomic 包下的类大多是使用 CAS 操作来实现的(AtomicInteger,AtomicBoolean,AtomicLong)。
39.CAS 的会产生什么问题?
1、ABA 问题:
比如说一个线程 one 从内存位置 V 中取出 A,这时候另一个线程 two 也从内存中取出 A,并且 two 进行了一些操作变成了 B,然后 two 又将 V 位置的数据变成 A,这时候线程 one 进行 CAS 操作发现内存中仍然是 A,然后 one 操作成功。尽管线程 one 的 CAS 操作成功,但可能存在潜藏的问题。从 Java1.5 开始 JDK 的 atomic包里提供了一个类 AtomicStampedReference 来解决 ABA 问题。
2、循环时间长开销大:
对于资源竞争严重(线程冲突严重)的情况,CAS 自旋的概率会比较大,从而浪费更多的 CPU 资源,效率低于 synchronized。
3、只能保证一个共享变量的原子操作:
当对一个共享变量执行操作时,我们可以使用循环 CAS 的方式来保证原子操作,但是对多个共享变量操作时,循环 CAS 就无法保证操作的原子性,这个时候就可以用锁。
40.什么是死锁?条件 ?避免?
当线程 A 持有独占锁a,并尝试去获取独占锁 b 的同时,线程 B 持有独占锁 b,并尝试获取独占锁 a 的情况下,就会发生 AB 两个线程由于互相持有对方需要的锁,而发生的阻塞现象,我们称为死锁。
产生死锁的必要条件:
1、互斥条件:所谓互斥就是进程在某一时间内独占资源。
2、请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
3、不剥夺条件:进程已获得资源,在末使用完之前,不能强行剥夺。
4、循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
防止死锁可以采用以下的方法:
- 尽量使用 tryLock(long timeout, TimeUnit unit)的方法(ReentrantLock、ReentrantReadWriteLock),设置超时时间,超时可以退出防止死锁。
- 尽量使用 Java. util. concurrent 并发类代替自己手写锁。
- 尽量降低锁的使用粒度,尽量不要几个功能用同一把锁。
- 尽量减少同步的代码块。
41.死锁与活锁的区别,死锁与饥饿的区别?
死锁:是指两个或两个以上的进程(或线程)在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。
活锁:任务或者执行者没有被阻塞,由于某些条件没有满足,导致一直重复尝试,失败,尝试,失败。
活锁和死锁的区别在于,处于活锁的实体是在不断的改变状态,这就是所谓的“活”, 而处于死锁的实体表现为等待;活锁有可能自行解开,死锁则不能。
饥饿:一个或者多个线程因为种种原因无法获得所需要的资源,导致一直无法执行的状态。
Java 中导致饥饿的原因:
1、高优先级线程吞噬所有的低优先级线程的 CPU 时间。
2、线程被永久堵塞在一个等待进入同步块的状态,因为其他线程总是能在它之前持续地对该同步块进行访问。
3、线程在等待一个本身也处于永久等待完成的对象(比如调用这个对象的 wait 方法),因为其他线程总是被持续地获得唤醒。
42.AQS是什么?原理分析?
AQS的全称为(AbstractQueuedSynchronizer),这个类在java.util.concurrent.locks包下面。
AQS是一个用来构建锁和同步器的框架,使用AQS能简单且高效地构造出应用广泛的大量的同步器,比如ReentrantLock,Semaphore,ReentrantReadWriteLock,SynchronousQueue,FutureTask等等皆是基于AQS的。当然,我们自己也能利用AQS非常轻松容易地构造出符合我们自己需求的同步器。
原理分析:
AQS核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。
CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS是将每条请求共享资源的线程封装成一个CLH锁队列的一个结点(Node)来实现锁的分配。
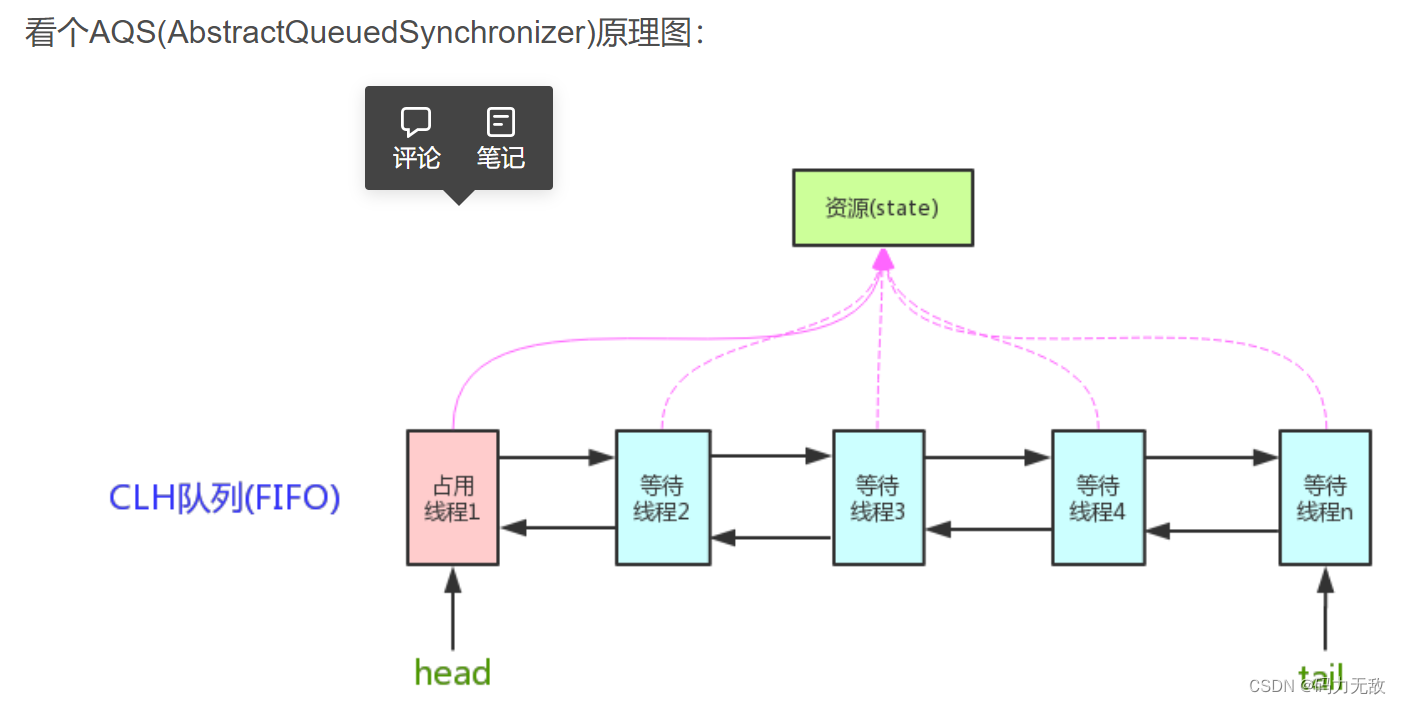 AQS使用一个int成员变量来表示同步状态,通过内置的FIFO队列来完成获取资源线程的排队工作。AQS使用CAS对该同步状态进行原子操作实现对其值的修改。
AQS使用一个int成员变量来表示同步状态,通过内置的FIFO队列来完成获取资源线程的排队工作。AQS使用CAS对该同步状态进行原子操作实现对其值的修改。
private volatile int state;//共享变量,使用volatile修饰保证线程可见性
//返回同步状态的当前值
protected final int getState() {
return state;
}
// 设置同步状态的值
protected final void setState(int newState) {
state = newState;
}
//原子地(CAS操作)将同步状态值设置为给定值update如果当前同步状态的值等于expect(期望值)
protected final boolean compareAndSetState(int expect, int update) {
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
AQS 对资源的共享方式
AQS定义两种资源共享方式
- Exclusive(独占):只有一个线程能执行,如ReentrantLock。又可分为公平锁和非公平锁:
公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
非公平锁:当线程要获取锁时,先进行cas尝试去获取锁,获取不到才放入对队列,无视队列顺序直接去抢锁,避免了用户态到内核态的切换,提升锁效率。 - Share(共享):多个线程可同时执行,如Semaphore/CountDownLatch。Semaphore、CountDownLatch、 CyclicBarrier、ReadWriteLock 我们都会在后面讲到。
不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS已经在顶层实现好了。
43.AQS底层使用了模板方法模式
同步器的设计是基于模板方法模式的,如果需要自定义同步器一般的方式是这样(模板方法模式很经典的一个应用):
- 使用者继承AbstractQueuedSynchronizer并重写指定的方法。(这些重写方法很简单,无非是对于共享资源state的获取和释放)
- 将AQS组合在自定义同步组件的实现中,并调用其模板方法,而这些模板方法会调用使用者重写的方法。
这和我们以往通过实现接口的方式有很大区别,这是模板方法模式很经典的一个运用。
AQS使用了模板方法模式,自定义同步器时需要重写下面几个AQS提供的模板方法。
isHeldExclusively()//该线程是否正在独占资源。只有用到condition才需要去实现它。
tryAcquire(int)//独占方式。尝试获取资源,成功则返回true,失败则返回false。
tryRelease(int)//独占方式。尝试释放资源,成功则返回true,失败则返回false。
tryAcquireShared(int)//共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true,失败则返回false。
- 1
- 2
- 3
- 4
- 5
以ReentrantLock为例,state初始化为0,表示未锁定状态。A线程lock()时,会调用tryAcquire()独占该锁并将state+1。此后,其他线程再tryAcquire()时就会失败,直到A线程unlock()到state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A线程自己是可以重复获取此锁的(state会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证state是能回到零态的。
再以CountDownLatch以例,任务分为N个子线程去执行,state也初始化为N(注意N要与线程个数一致)。这N个子线程是并行执行的,每个子线程执行完后countDown()一次,state会CAS(Compare and Swap)减1。等到所有子线程都执行完后(即state=0),会unpark()主调用线程,然后主调用线程就会从await()函数返回,继续后余动作。
一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现tryAcquire-tryRelease、tryAcquireShared-tryReleaseShared中的一种即可。但AQS也支持自定义同步器同时实现独占和共享两种方式,如ReentrantReadWriteLock。
44.ReadWriteLock 是什么
ReadWriteLock 是一个读写锁接口,读写锁是用来提升并发程序性能的锁分离技术,ReentrantReadWriteLock 是 ReadWriteLock 接口的一个具体实现,实现了读写的分离,读锁是共享的,写锁是独占的,读和读之间不会互斥,读和写、写和读、写和写之间才会互斥,提升了读写的性能。
而读写锁有以下三个重要的特性:
(1)公平选择性:支持非公平(默认)和公平的锁获取方式,吞吐量还是非公平优于公平。
(2)重进入:读锁和写锁都支持线程重进入。
(3)锁降级:遵循获取写锁、获取读锁再释放写锁的次序,写锁能够降级成为读锁。
45并发容器之ConcurrentHashMap?
ConcurrentHashMap是Java中的一个线程安全且高效的HashMap实现。
JDK 1.6版本关键要素:
- segment继承了ReentrantLock充当锁的角色,为每一个segment提供了线程安全的保障;
- segment维护了哈希散列表的若干个桶,每个桶由HashEntry构成的链表
JDK1.8后,ConcurrentHashMap****抛弃了原有的Segment 分段锁,而采用了 CAS + synchronized来保证并发安全性。
ConcurrentHashMap 把实际 map 划分成若干部分来实现它的可扩展性和线程安全。这种划分是使用并发度获得的,它是 ConcurrentHashMap 类构造函数的一个可选参数,默认值为 16,这样在多线程情况下就能避免争用。
在 JDK8 后,它摒弃了 Segment(锁段)的概念,而是启用了一种全新的方式实现,利用 CAS 算法。降低锁的粒度,变为node,锁只锁node数据节点,在hash不冲突的情况下,大大提升效率。
46.SynchronizedMap 和 ConcurrentHashMap 有什么区别?
SynchronizedMap 一次锁住整张表来保证线程安全,所以每次只能有一个线程来访为 map。
ConcurrentHashMap 使用分段锁来保证在多线程下的性能。
ConcurrentHashMap 中则是一次锁住一个桶。ConcurrentHashMap 默认将hash 表分为 16 个桶,诸如 get,put,remove 等常用操作只锁当前需要用到的桶。
这样,原来只能一个线程进入,现在却能同时有 16 个写线程执行,并发性能的提升是显而易见的。
另外 ConcurrentHashMap 使用了一种不同的迭代方式。在这种迭代方式中,当iterator 被创建后集合再发生改变就不再是抛出ConcurrentModificationException,取而代之的是在改变时 new 新的数据从而不影响原有的数据,iterator 完成后再将头指针替换为新的数据 ,这样 iterator线程可以使用原来老的数据,而写线程也可以并发的完成改变。
47.并发容器之CopyOnWriteArrayList 是什么,可以用于什么应用场景?有哪些优缺点?
CopyOnWriteArrayList 是一个并发容器。有很多人称它是线程安全的,我认为这句话不严谨,缺少一个前提条件,那就是非复合场景下操作它是线程安全的。
CopyOnWriteArrayList(免锁容器)的好处之一是当多个迭代器同时遍历和修改这个列表时,不会抛出 ConcurrentModificationException。在CopyOnWriteArrayList 中,写入将导致创建整个底层数组的副本,而源数组将保留在原地,使得复制的数组在被修改时,读取操作可以安全地执行。
通过源码分析,我们看出它的优缺点比较明显,所以使用场景也就比较明显。就是合适读多写少的场景。
CopyOnWriteArrayList 的缺点
1.由于写操作的时候,需要拷贝数组,会消耗内存,如果原数组的内容比较多的情况下,可能导致 young gc 或者 full gc。
2.不能用于实时读的场景,像拷贝数组、新增元素都需要时间,所以调用一个 set 操作后,读取到数据可能还是旧的,虽然CopyOnWriteArrayList 能做到最终一致性,但是还是没法满足实时性要求。
3.由于实际使用中可能没法保证 CopyOnWriteArrayList 到底要放置多少数据,万一数据稍微有点多,每次 add/set 都要重新复制数组,这个代价实在太高昂了。在高性能的互联网应用中,这种操作分分钟引起故障。
CopyOnWriteArrayList 的设计思想
- 读写分离,读和写分开
- 最终一致性
- 使用另外开辟空间的思路,来解决并发冲突
48.ThreadLocal 是什么?有哪些使用场景?
ThreadLocal 是一个本地线程副本变量工具类,在每个线程中都创建了一个 ThreadLocalMap 对象,简单说 ThreadLocal 就是一种以空间换时间的做法,每个线程可以访问自己内部 ThreadLocalMap 对象内的 value。通过这种方式,避免资源在多线程间共享。
原理:线程局部变量是局限于线程内部的变量,属于线程自身所有,不在多个线程间共享。Java提供ThreadLocal类来支持线程局部变量,是一种实现线程安全的方式。但是在管理环境下(如 web 服务器)使用线程局部变量的时候要特别小心,在这种情况下,工作线程的生命周期比任何应用变量的生命周期都要长。任何线程局部变量一旦在工作完成后没有释放,Java 应用就存在内存泄露的风险。
经典的使用场景是为每个线程分配一个 JDBC 连接 Connection。这样就可以保证每个线程的都在各自的 Connection 上进行数据库的操作,不会出现 A 线程关了 B线程正在使用的 Connection; 还有 Session 管理 等问题。
49.ThreadLocal造成内存泄漏的原因?
ThreadLocalMap 中使用的 key 为 ThreadLocal 的弱引用,而 value 是强引用。所以,如果 ThreadLocal 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。这样一来,ThreadLocalMap 中就会出现key为null的Entry。假如我们不做任何措施的话,value 永远无法被GC 回收,这个时候就可能会产生内存泄露。ThreadLocalMap实现中已经考虑了这种情况,在调用 set()、get()、remove() 方法的时候,会清理掉 key 为 null 的记录。使用完 ThreadLocal方法后 最好手动调用remove()方法。
ThreadLocal内存泄漏解决方案?
- 每次使用完ThreadLocal,都调用它的remove()方法,清除数据。
- 在使用线程池的情况下,没有及时清理ThreadLocal,不仅是内存泄漏的问题,更严重的是可能导致业务逻辑出现问题。所以,使用ThreadLocal就跟加锁完要解锁一样,用完就清理。
50.父子线程如何传递数据?
除了通过方法形参传入之外,还可以通过InheritableThreadLocal在子线程创建的时候从父线程中同步数据。
既然InheritableThreadLocal与ThreadLocal并没有多大区别,那它是怎么实现的父线程向子线程传递数据呢?其实就是把对Thread对象中的threadLocals变量的操作替换成了对inheritableThreadLocals变量的操作,就这么一点区别。
if (parent.inheritableThreadLocals != null) {
this.inheritableThreadLocals =
ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
}
- 1
- 2
- 3
- 4
就将父线程的Map中的数据传递到了子线程的Map中,并且由于子线程中的inheritableThreadLocals是一个新的对象,与父线程之间互不影响。
51.什么是阻塞队列BlockingQueue?阻塞队列的实现原理是什么?如何使用阻塞队列来实现生产者-消费者模型?
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。
这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。
阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
DK7 提供了 7 个阻塞队列。分别是:
ArrayBlockingQueue :一个由数组结构组成的有界阻塞队列。
LinkedBlockingQueue :一个由链表结构组成的有界阻塞队列。
LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列。
DelayQueue:一个使用优先级队列实现的无界阻塞队列。
SynchronousQueue:一个不存储元素的阻塞队列。
Java 5 之前实现同步存取时,可以使用普通的一个集合,然后在使用线程的协作和线程同步可以实现生产者,消费者模式,主要的技术就是用好,wait,notify,notifyAll,sychronized 这些关键字。而在 java 5 之后,可以使用阻塞队列来实现,此方式大大简少了代码量,使得多线程编程更加容易,安全方面也有保障。
BlockingQueue 接口是 Queue 的子接口,它的主要用途并不是作为容器,而是作为线程同步的的工具,因此他具有一个很明显的特性,当生产者线程试图向 BlockingQueue 放入元素时,如果队列已满,则线程被阻塞,当消费者线程试图从中取出一个元素时,如果队列为空,则该线程会被阻塞,正是因为它所具有这个特性,所以在程序中多个线程交替向 BlockingQueue 中放入元素,取出元素,它可以很好的控制线程之间的通信。
阻塞队列使用最经典的场景就是 socket 客户端数据的读取和解析,读取数据的线程不断将数据放入队列,然后解析线程不断从队列取数据解析。
52.并发容器之ArrayBlockingQueue与LinkedBlockingQueue详解
阻塞队列最核心的功能是,能够可阻塞式的插入和删除队列元素。
当前队列为空时,会阻塞消费数据的线程,直至队列非空时,通知被阻塞的线程;当队列满时,会阻塞插入数据的线程,直至队列未满时,通知插入数据的线程(生产者线程)。那么,多线程中消息通知机制最常用的是lock的condition机制。
/** The queued items */ final Object[] items; /** items index for next take, poll, peek or remove */ int takeIndex; /** items index for next put, offer, or add */ int putIndex; /** Number of elements in the queue */ int count; /* * Concurrency control uses the classic two-condition algorithm * found in any textbook. */ /** Main lock guarding all access */ final ReentrantLock lock; /** Condition for waiting takes */ private final Condition notEmpty; /** Condition for waiting puts */ private final Condition notFull;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
从源码中可以看出ArrayBlockingQueue内部是采用数组进行数据存储的(属性items),为了保证线程安全,采用的是ReentrantLock lock,为了保证可阻塞式的插入删除数据利用的是Condition,当获取数据的消费者线程被阻塞时会将该线程放置到notEmpty等待队列中,当插入数据的生产者线程被阻塞时,会将该线程放置到notFull等待队列中。而notEmpty和notFull等中要属性在构造方法中进行创建:
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0) throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
put(E e)方法源码如下:
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
//如果当前队列已满,将线程移入到notFull等待队列中
while (count == items.length)
notFull.await();
//满足插入数据的要求,直接进行入队操作
enqueue(e);
} finally {
lock.unlock();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
该方法的逻辑很简单,当队列已满时(count == items.length)将线程移入到notFull等待队列中,如果当前满足插入数据的条件,就可以直接调用enqueue(e)插入数据元素。enqueue方法源码为:
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
//插入数据
items[putIndex] = x;
if (++putIndex == items.length)
putIndex = 0;
count++;
//通知消费者线程,当前队列中有数据可供消费
notEmpty.signal();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
先完成插入数据,即往数组中添加数据(items[putIndex] = x),然后通知被阻塞的消费者线程,当前队列中有数据可供消费(notEmpty.signal())。
take方法也主要做了两步:1. 如果当前队列为空的话,则将获取数据的消费者线程移入到等待队列中;2. 若队列不为空则获取数据,即完成出队操作dequeue。dequeue方法源码为:
private E dequeue() { // assert lock.getHoldCount() == 1; // assert items[takeIndex] != null; final Object[] items = this.items; @SuppressWarnings("unchecked") //获取数据 E x = (E) items[takeIndex]; items[takeIndex] = null; if (++takeIndex == items.length) takeIndex = 0; count--; if (itrs != null) itrs.elementDequeued(); //通知被阻塞的生产者线程 notFull.signal(); return x; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
LinkedBlockingQueue实现原理
LinkedBlockingQueue是用链表实现的有界阻塞队列,当构造对象时为指定队列大小时,队列默认大小为Integer.MAX_VALUE。从它的构造方法可以看出:
/** Current number of elements */ private final AtomicInteger count = new AtomicInteger(); // Head of linked list. Invariant: head.item == null transient Node<E> head; //Tail of linked list. Invariant: last.next == null private transient Node<E> last; /** Lock held by take, poll, etc */ private final ReentrantLock takeLock = new ReentrantLock(); /** Lock held by put, offer, etc */ private final ReentrantLock putLock = new ReentrantLock(); /** Wait queue for waiting takes */ private final Condition notEmpty = takeLock.newCondition(); /** Wait queue for waiting puts */ private final Condition notFull = putLock.newCondition();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
LinkedBlockingQueue在插入数据和删除数据时分别是由两个不同的lock(takeLock和putLock)来控制线程安全的,因此,也由这两个lock生成了两个对应的condition(notEmpty和notFull)来实现可阻塞的插入和删除数据。并且,采用了链表的数据结构来实现队列。
ArrayBlockingQueue与LinkedBlockingQueue的比较
- 相同点:ArrayBlockingQueue和LinkedBlockingQueue都是通过condition通知机制来实现可阻塞式插入和删除元素,并满足线程安全的特性;
- 不同点:
- ArrayBlockingQueue底层是采用的数组进行实现,而LinkedBlockingQueue则是采用链表数据结构;
- ArrayBlockingQueue插入和删除数据,只采用了一个lock,而LinkedBlockingQueue则是在插入和删除分别采用了putLock和takeLock,这样可以降低线程由于线程无法获取到lock而进入WAITING状态的可能性,从而提高了线程并发执行的效率。
53.什么是线程池?有哪几种创建方式?
线程池顾名思义就是事先创建若干个可执行的线程放入一个池(容器)中,需要的时候从池中获取线程不用自行创建,使用完毕不需要销毁线程而是放回池中,从而减少创建和销毁线程对象的开销。
Java 5+中的 Executor 接口定义一个执行线程的工具。它的子类型即线程池接口是 ExecutorService。要配置一个线程池是比较复杂的,尤其是对于线程池的原理不是很清楚的情况下,因此在工具类 Executors 面提供了一些静态工厂方法,生成一些常用的线程池。如下:
(1)newSingleThreadExecutor:创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
(2)newFixedThreadPool:创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。如果希望在服务器上使用线程池,建议使用 newFixedThreadPool方法来创建线程池,这样能获得更好的性能。
(3) newCachedThreadPool:创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,那么就会回收部分空闲(60 秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说 JVM)能够创建的最大线程大小。
(4)newScheduledThreadPool:创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
55.线程池都有哪些状态?
- RUNNING:这是最正常的状态,接受新的任务,处理等待队列中的任务。
- SHUTDOWN:不接受新的任务提交,但是会继续处理等待队列中的任务。
- STOP:不接受新的任务提交,不再处理等待队列中的任务,中断正在执行任务的线程。
- TIDYING:所有的任务都销毁了,workCount 为 0,线程池的状态在转换为 TIDYING 状态时,会执行钩子方法 terminated()。
- TERMINATED:terminated()方法结束后,线程池的状态就会变成这个。
56.在 Java 中 Executor 和 Executors 的区别?
- Executors 工具类的不同方法按照我们的需求创建了不同的线程池,来满足业务的需求。
- Executor 接口对象能执行我们的线程任务。
- ExecutorService 接口继承了 Executor 接口并进行了扩展,提供了更多的方法我们能获得任务执行的状态并且可以获取任务的返回值。
- 使用 ThreadPoolExecutor 可以创建自定义线程池。
- Future 表示异步计算的结果,他提供了检查计算是否完成的方法,以等待计算的完成,并可以使用 get()方法获取计算的结果。
57.线程池中 submit() 和 execute() 方法有什么区别?
接收参数:execute()只能执行 Runnable 类型的任务。submit()可以执行 Runnable 和 Callable 类型的任务。
返回值:submit()方法可以返回持有计算结果的 Future 对象,而execute()没有
异常处理:submit()方便Exception处理
58.线程池之ThreadPoolExecutor详解
《阿里巴巴Java开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
Executors 各个方法的弊端:
newFixedThreadPool 和 newSingleThreadExecutor:
主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至 OOM。
newCachedThreadPool 和 newScheduledThreadPool:
主要问题是线程数最大数是 Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至 OOM。
ThreadPoolExecutor() 是最原始的线程池创建,也是阿里巴巴 Java 开发手册中明确规范的创建线程池的方式。
59.ThreadPoolExecutor构造函数重要参数分析
hreadPoolExecutor 3 个最重要的参数:
- corePoolSize :核心线程数,线程数定义了最小可以同时运行的线程数量。
- maximumPoolSize :线程池中允许存在的工作线程的最大数量
- workQueue:当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,任务就会被存放在队列中。
ThreadPoolExecutor其他常见参数:
- keepAliveTime:线程池中的线程数量大于 corePoolSize 的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了 keepAliveTime才会被回收销毁;
- unit :keepAliveTime 参数的时间单位。
- threadFactory:为线程池提供创建新线程的线程工厂
- handler :线程池任务队列超过 maxinumPoolSize 之后的拒绝策略
60.ThreadPoolExecutor 饱和策略定义:
- ThreadPoolExecutor.AbortPolicy:抛出 RejectedExecutionException来拒绝新任务的处理。(默认)
- ThreadPoolExecutor.CallerRunsPolicy:调用执行自己的线程运行任务。您不会任务请求。但是这种策略会降低对于新任务提交速度,影响程序的整体性能。当最大池被填满时,此策略为我们提供可伸缩队列。如果您的应用程序可以承受此延迟并且你不能任务丢弃任何一个任务请求的话,你可以选择这个策略。
- ThreadPoolExecutor.DiscardPolicy:不处理新任务,直接丢弃掉。
- ThreadPoolExecutor.DiscardOldestPolicy: 此策略将丢弃最早的未处理的任务请求。
61.线程池实现原理?
62.FutureTask详解?
63.什么是原子操作?在 Java Concurrency API 中有哪些原子类(atomic classes)?
在 Java 中可以通过锁和循环 CAS 的方式来实现原子操作。 CAS 操作——Compare & Set,或是 Compare & Swap,现在几乎所有的 CPU 指令都支持 CAS 的原子操作。
java.util.concurrent 这个包里面提供了一组原子类。其基本的特性就是在多线程环境下,当有多个线程同时执行这些类的实例包含的方法时,具有排他性,即当某个线程进入方法,执行其中的指令时,不会被其他线程打断,而别的线程就像自旋锁一样,一直等到该方法执行完成,才由 JVM 从等待队列中选择另一个线程进入,这只是一种逻辑上的理解。
原子类:AtomicBoolean,AtomicInteger,AtomicLong,AtomicReference
原子数组:AtomicIntegerArray,AtomicLongArray,AtomicReferenceArray
原子属性更新器:AtomicLongFieldUpdater,AtomicIntegerFieldUpdater,AtomicReferenceFieldUpdater
解决 ABA 问题的原子类:AtomicMarkableReference(通过引入一个 boolean来反映中间有没有变过),AtomicStampedReference(通过引入一个 int 来累加来反映中间有没有变过)
64.说一下 atomic 的原理?
Atomic包中的类基本的特性就是在多线程环境下,当有多个线程同时对单个(包括基本类型及引用类型)变量进行操作时,具有排他性,即当多个线程同时对该变量的值进行更新时,仅有一个线程能成功,而未成功的线程可以向自旋锁一样,继续尝试,一直等到执行成功。
// setup to use Unsafe.compareAndSwapInt for updates(更新操作时提供“比较并替换”的作用)
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native方法Unsafe来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
CAS的原理是拿期望的值和原本的一个值作比较,如果相同则更新成新的值。UnSafe 类的 objectFieldOffset() 方法是一个本地方法,这个方法是用来拿到“原来的值”的内存地址,返回值是 valueOffset。另外 value 是一个volatile变量,在内存中可见,因此 JVM 可以保证任何时刻任何线程总能拿到该变量的最新值。
并发工具
65.在 Java 中 CycliBarriar 和 CountdownLatch 有什么区别?
CountDownLatch与CyclicBarrier都是用于控制并发的工具类,都可以理解成维护的就是一个计数器,但是这两者还是各有不同侧重点的:
- CountDownLatch一般用于某个线程A等待若干个其他线程执行完任务之后,它才执行;而CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行;CountDownLatch强调一个线程等多个线程完成某件事情。CyclicBarrier是多个线程互等,等大家都完成,再携手共进。
- 调用CountDownLatch的countDown方法后,当前线程并不会阻塞,会继续往下执行;而调用CyclicBarrier的await方法,会阻塞当前线程,直到CyclicBarrier指定的线程全部都到达了指定点的时候,才能继续往下执行;
- CountDownLatch方法比较少,操作比较简单,而CyclicBarrier提供的方法更多,比如能够通过getNumberWaiting(),isBroken()这些方法获取当前多个线程的状态,并且CyclicBarrier的构造方法可以传入barrierAction,指定当所有线程都到达时执行的业务功能;
- CountDownLatch是不能复用的,而CyclicLatch是可以复用的。
66.并发工具之Semaphore与Exchanger
Semaphore 有什么作用
Semaphore 就是一个信号量,它的作用是限制某段代码块的并发数。Semaphore有一个构造函数,可以传入一个 int 型整数 n,表示某段代码最多只有 n 个线程可以访问,如果超出了 n,那么请等待,等到某个线程执行完毕这段代码块,下一个线程再进入。由此可以看出如果 Semaphore 构造函数中传入的 int 型整数 n=1,相当于变成了一个 synchronized 了。
Semaphore(信号量)-允许多个线程同时访问: synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,Semaphore(信号量)可以指定多个线程同时访问某个资源。
什么是线程间交换数据的工具Exchanger
Exchanger是一个用于线程间协作的工具类,用于两个线程间交换数据。它提供了一个交换的同步点,在这个同步点两个线程能够交换数据。交换数据是通过exchange方法来实现的,如果一个线程先执行exchange方法,那么它会同步等待另一个线程也执行exchange方法,这个时候两个线程就都达到了同步点,两个线程就可以交换数据。
常用的并发工具类有哪些?
- Semaphore(信号量)-允许多个线程同时访问: synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,Semaphore(信号量)可以指定多个线程同时访问某个资源。
- CountDownLatch(倒计时器): CountDownLatch是一个同步工具类,用来协调多个线程之间的同步。这个工具通常用来控制线程等待,它可以让某一个线程等待直到倒计时结束,再开始执行。
- CyclicBarrier(循环栅栏): CyclicBarrier 和 CountDownLatch 非常类似,它也可以实现线程间的技术等待,但是它的功能比 CountDownLatch 更加复杂和强大。主要应用场景和 CountDownLatch 类似。CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。CyclicBarrier默认的构造方法是 CyclicBarrier(int parties),其参数表示屏障拦截的线程数量,每个线程调用await()方法告诉 CyclicBarrier 我已经到达了屏障,然后当前线程被阻塞。
67.如何计算线程的数量?
一般多线程执行的任务类型可以分为 CPU 密集型和 I/O 密集型,根据不同的任务类型,我们计算线程数的方法也不一样。
CPU 密集型
这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。
一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
4 核 intel i5 CPU 机器上,4~6 个线程数是最合适的。
I/O 密集型任务
这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
五、JVM
1.jvm是什么?

JVM包含两个子系统和两个组件,两个子系统为Class loader(类装载)、Execution engine(执行引擎);两个组件为Runtime data area(运行时数据区)、Native Interface(本地接口)。
作用 :
- 首先通过编译器把 Java 代码转换成字节码,类加载器(ClassLoader)再把字节码加载到内存中,将其放在运行时数据区(Runtime data area)的方法区内。
- 其次命令解析器执行引擎(Execution Engine),将字节码翻译成底层系统指令。
- 最后交由 CPU 去执行,而这个过程中需要调用其他语言的本地库接口(Native Interface)来实现整个程序的功能。
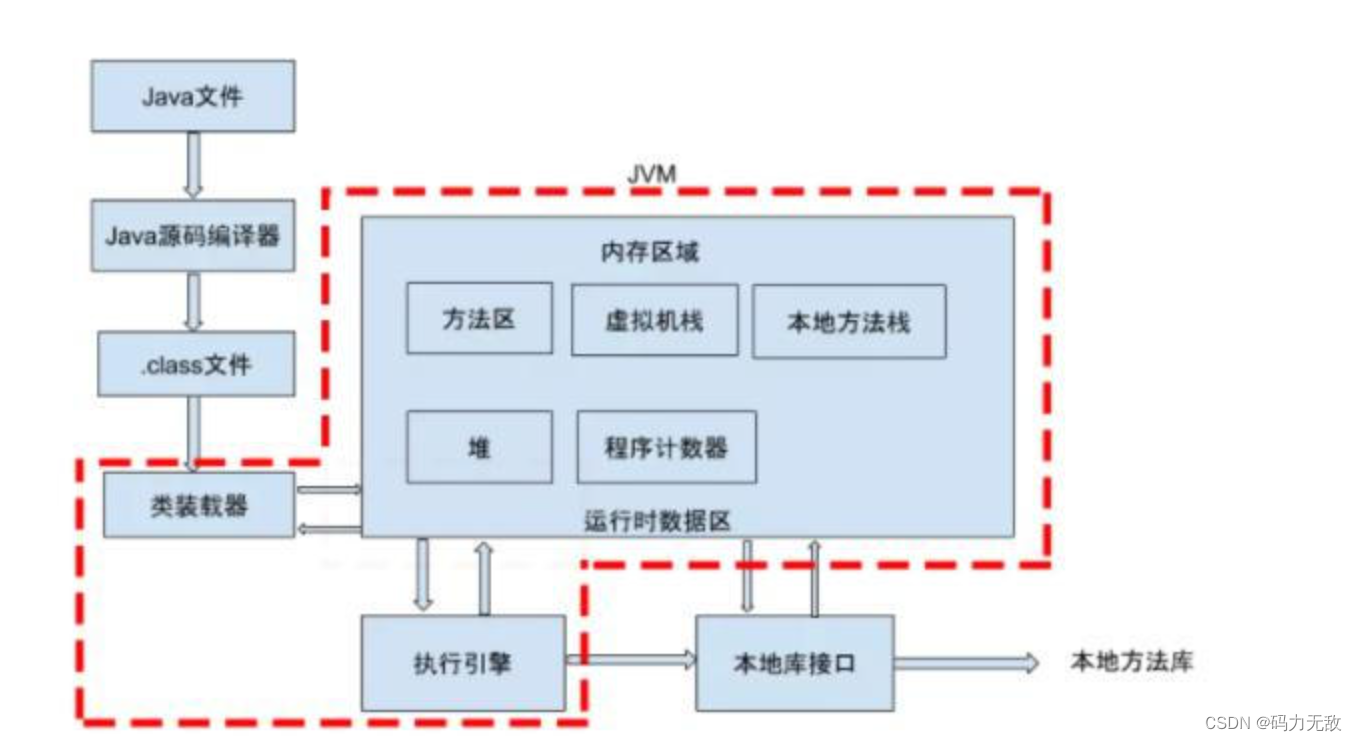
类的加载指的是将类的.class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法区内,然后在堆区创建一个 java.lang.Class对象,用来封装类在方法区内的数据结构。
2.说一下 JVM 运行时数据区

- 程序计数器(Program Counter Register):当前线程所执行的字节码的行号指示器,字节码解析器的工作是通过改变这个计数器的值,来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能,都需要依赖这个计数器来完成;
- Java 虚拟机栈(Java Virtual Machine Stacks):是线程私有的,栈帧存储了方法的局部变量表、操作数栈、动态连接和方法返回地址等信息。每一个方法从调用至执行完成的过程,都对应着一个栈帧在虚拟机栈里从入栈到出栈的过程。
- 本地方法栈(Native Method Stack):与虚拟机栈的作用是一样的,只不过虚拟机栈是服务 Java 方法的,而本地方法栈是为虚拟机调用 Native 方法服务的;
- Java 堆(Java Heap):Java 虚拟机中内存最大的一块,是被所有线程共享的,几乎所有的对象实例都在这里分配内存;
- 方法区(Methed Area):用于存储已被虚拟机加载的类信息、常量/运行时常量池、静态变量、即时编译后的代码等数据。
备注:常量池:字符串常量池、class常量池、运行时常量池(会把符号引用替换为直接引用)。
3.说一下堆栈的区别?
- 物理地址,堆的物理地址分配对对象是不连续的。因此性能慢些。在GC的时候也要考虑到不连续的分配,所以有各种算法。比如,标记-消除,复制,标记-压缩,分代(即新生代使用复制算法,老年代使用标记——压缩)。
栈使用的是数据结构中的栈,先进后出的原则,物理地址分配是连续的。所以性能快。 - 内存分别:堆因为是不连续的,所以分配的内存是在运行期确认的,因此大小不固定。一般堆大小远远大于栈。
栈是连续的,所以分配的内存大小要在编译期就确认,大小是固定的。 - 存放的内容:
堆存放的是对象的实例和数组。因此该区更关注的是数据的存储。
栈存放:局部变量,操作数栈,返回结果。该区更关注的是程序方法的执行。
4.垃圾回收器的基本原理是什么?垃圾回收器可以马上回收内存吗?有什么办法主动通知虚拟机进行垃圾回收?
对于GC来说,当程序员创建对象时,GC就开始监控这个对象的地址、大小以及使用情况。
通常,GC采用有向图的方式记录和管理堆(heap)中的所有对象。通过这种方式确定哪些对象是"可达的",哪些对象是"不可达的"。当GC确定一些对象为"不可达"时,GC就有责任回收这些内存空间。
可以。程序员可以手动执行System.gc(),通知GC运行,但是Java语言规范并不保证GC一定会执行。
5,怎么判断对象是否可以被回收?
垃圾收集器在做垃圾回收的时候,首先需要判定的就是哪些内存是需要被回收的,哪些对象是「存活」的,是不可以被回收的;哪些对象已经「死掉」了,需要被回收。
一般有两种方法来判断:
- 引用计数器法:为每个对象创建一个引用计数,有对象引用时计数器 +1,引用被释放时计数 -1,当计数器为 0 时就可以被回收。它有一个缺点不能解决循环引用的问题;
- 可达性分析算法:从 GC Roots 开始向下搜索,搜索所走过的路径称为引用链。当一个对象到 GC Roots 没有任何引用链相连时,则证明此对象是可以被回收的。
6.JVM中的永久代中会发生垃圾回收吗?
垃圾回收不会发生在永久代,如果永久代满了或者是超过了临界值,会触发完全垃圾回收(Full GC)。如果你仔细查看垃圾收集器的输出信息,就会发现永久代也是被回收的。这就是为什么正确的永久代大小对避免Full GC是非常重要的原因。请参考下Java8:已经移除了永久代,从永久代到元数据区
7.说一下 JVM 有哪些垃圾回收算法?
- 标记-清除算法:标记无用对象,然后进行清除回收。缺点:效率不高,无法清除垃圾碎片。
- 标记-整理算法:标记无用对象,让所有存活的对象都向一端移动,然后直接清除掉端边界以外的内存。
- 复制算法:按照容量划分二个大小相等的内存区域,当一块用完的时候将活着的对象复制到另一块上,然后再把已使用的内存空间一次清理掉。缺点:内存使用率不高,只有原来的一半。
- 分代算法:根据对象存活周期的不同将内存划分为几块,一般是新生代和老年代,新生代基本采用复制算法,老年代采用标记整理算法。
8.说一下 JVM 有哪些垃圾回收器?
- Serial收集器(复制算法): 新生代单线程收集器,标记和清理都是单线程,优点是简单高效;
- ParNew收集器 (复制算法): 新生代收并行集器,实际上是Serial收集器的多线程版本,在多核CPU环境下有着比Serial更好的表现;
Parallel Scavenge收集器 (复制算法): 新生代并行收集器,追求高吞吐量,高效利用 CPU。吞吐量 = 用户线程时间/(用户线程时间+GC线程时间),高吞吐量可以高效率的利用CPU时间,尽快完成程序的运算任务,适合后台应用等对交互相应要求不高的场景; - Serial Old收集器 (标记-整理算法): 老年代单线程收集器,Serial收集器的老年代版本;
- Parallel Old收集器 (标记-整理算法): 老年代并行收集器,吞吐量优先,Parallel Scavenge收集器的老年代版本;
- CMS(Concurrent Mark Sweep)收集器(标记-清除算法): 老年代并行收集器,以获取最短回收停顿时间为目标的收集器,具有高并发、低停顿的特点,追求最短GC回收停顿时间。
- G1(Garbage First)收集器 (标记-整理算法): Java堆并行收集器,G1收集器是JDK1.7提供的一个新收集器,G1收集器基于“标记-整理”算法实现,也就是说不会产生内存碎片。此外,G1收集器不同于之前的收集器的一个重要特点是:G1回收的范围是整个Java堆(包括新生代,老年代),而前六种收集器回收的范围仅限于新生代或老年代。
9.简述分代垃圾回收器是怎么工作的?
分代回收器有两个分区:老生代和新生代,新生代默认的空间占比总空间的 1/3,老生代的默认占比是 2/3。
新生代使用的是复制算法,新生代里有 3 个分区:Eden、To Survivor、From Survivor,它们的默认占比是 8:1:1,它的执行流程如下:
- 把 Eden + From Survivor 存活的对象放入 To Survivor 区;
- 清空 Eden 和 From Survivor 分区;
- From Survivor 和 To Survivor 分区交换,From Survivor 变 To Survivor,To Survivor 变 From Survivor。
每次在 From Survivor 到 To Survivor 移动时都存活的对象,年龄就 +1,当年龄到达 15(默认配置是 15)时,升级为老生代。大对象也会直接进入老生代。
老生代当空间占用到达某个值之后就会触发全局垃圾收回,一般使用标记整理的执行算法。以上这些循环往复就构成了整个分代垃圾回收的整体执行流程。
10.简述java内存分配与回收策率以及Minor GC和Major GC
- 对象优先在 Eden 区分配
多数情况,对象都在新生代 Eden 区分配。当 Eden 区分配没有足够的空间进行分配时,虚拟机将会发起一次 Minor GC。如果本次 GC 后还是没有足够的空间,则将启用分配担保机制在老年代中分配内存。
这里我们提到 Minor GC,如果你仔细观察过 GC 日常,通常我们还能从日志中发现 Major GC/Full GC。
Minor GC 是指发生在新生代的 GC,因为 Java 对象大多都是朝生夕死,所有 Minor GC 非常频繁,一般回收速度也非常快;
Major GC/Full GC 是指发生在老年代的 GC,出现了 Major GC 通常会伴随至少一次 Minor GC。Major GC 的速度通常会比 Minor GC 慢 10 倍以上。
- 大对象直接进入老年代
避免对象直接在新生代分配,发生大量的内存复制。 - 长期存活对象将进入老年代
避免存活对象的年龄+1,发生对象的移动。
11.说一下类装载的执行过程?
- 加载:根据查找路径找到相应的 class 文件然后导入;
- 验证:检查加载的 class 文件的正确性;
- 准备:给类中的静态变量分配内存空间;
- 解析:虚拟机将常量池中的符号引用替换成直接引用的过程。符号引用就理解为一个标示,而在直接引用直接指向内存中的地址;
- 初始化:对静态变量和静态代码块执行初始化工作。
12.什么是双亲委派模型?
双亲委派模型:如果一个类加载器收到了类加载的请求,它首先不会自己去加载这个类,而是把这个请求委派给父类加载器去完成,每一层的类加载器都是如此,这样所有的加载请求都会被传送到顶层的启动类加载器中,只有当父加载无法完成加载请求(它的搜索范围中没找到所需的类)时,子加载器才会尝试去加载类。避免类的重复加载。
当一个类收到了类加载请求时,不会自己先去加载这个类,而是将其委派给父类,由父类去加载,如果此时父类不能加载,反馈给子类,由子类去完成类的加载。
13.JVM调优?
JDK 自带了很多监控工具,都位于 JDK 的 bin 目录下,其中最常用的是 jconsole 和 jvisualvm 这两款视图监控工具。
jconsole:用于对 JVM 中的内存、线程和类等进行监控;
jvisualvm:JDK 自带的全能分析工具,可以分析:内存快照、线程快照、程序死锁、监控内存的变化、gc 变化等。
常用的 JVM 调优的参数都有哪些?
-Xms2g:初始化推大小为 2g;
-Xmx2g:堆最大内存为 2g;
-XX:NewRatio=4:设置年轻的和老年代的内存比例为 1:4;
-XX:SurvivorRatio=8:设置新生代 Eden 和 Survivor 比例为 8:2;
–XX:+UseParNewGC:指定使用 ParNew + Serial Old 垃圾回收器组合;
-XX:+UseParallelOldGC:指定使用 ParNew + ParNew Old 垃圾回收器组合;
-XX:+UseConcMarkSweepGC:指定使用 CMS + Serial Old 垃圾回收器组合;
-XX:+PrintGC:开启打印 gc 信息;
-XX:+PrintGCDetails:打印 gc 详细信息。
14.如何调优?调优的步骤?
- 监控GC的状态。
- 每次垃圾回收的时间越来越长,由之前的10ms延长到50ms左右,FullGC的时间也有之前的0.5s延长到4、5s
- FullGC的次数越来越多,最频繁时隔不到1分钟就进行一次FullGC
- 年老代的内存越来越大并且每次FullGC后年老代没有内存被释放
- 分析结果,判断是否需要优化
如果各项参数设置合理,系统没有超时日志出现,GC频率不高,GC耗时不高,那么没有必要进行GC优化,如果GC时间超过1-3秒,或者频繁GC,则必须优化。
注:如果满足下面的指标,则一般不需要进行GC:
- Minor GC执行时间不到50ms;
- Minor GC执行不频繁,约10s一次;
- Full GC执行时间不到1s;
- Full GC执行频率不算频繁,不低于10min1次;
- 调整GC类型和内存分配:如果内存分配过大或过小,或者采用的GC收集器比较慢.
JVM调优参数参考
1.针对JVM堆的设置,一般可以通过-Xms -Xmx限定其最小、最大值,为了防止垃圾收集器在最小、最大之间收缩堆而产生额外的时间,通常把最大、最小设置为相同的值;
2.年轻代和年老代将根据默认的比例(1:2)分配堆内存, 可以通过调整二者之间的比率NewRadio来调整二者之间的大小,也可以针对回收代。
比如年轻代,通过 -XX:newSize -XX:MaxNewSize来设置其绝对大小。同样,为了防止年轻代的堆收缩,我们通常会把-XX:newSize -XX:MaxNewSize设置为同样大小。
合理设置年轻代和年老代大小
1)更大的年轻代必然导致更小的年老代,大的年轻代会延长普通GC的周期,但会增加每次GC的时间;小的年老代会导致更频繁的Full GC
2)更小的年轻代必然导致更大年老代,小的年轻代会导致普通GC很频繁,但每次的GC时间会更短;大的年老代会减少Full GC的频率
如何选择应该依赖应用程序对象生命周期的分布情况: 如果应用存在大量的临时对象,应该选择更大的年轻代;如果存在相对较多的持久对象,年老代应该适当增大。但很多应用都没有这样明显的特性。
在抉择时应该根 据以下两点:
(1)本着Full GC尽量少的原则,让年老代尽量缓存常用对象,JVM的默认比例1:2也是这个道理 。
(2)通过观察应用一段时间,看其他在峰值时年老代会占多少内存,在不影响Full GC的前提下,根据实际情况加大年轻代,比如可以把比例控制在1:1。但应该给年老代至少预留1/3的增长空间。
3.在配置较好的机器上(比如多核、大内存),可以为年老代选择并行收集算法:-XX:+UseParallelOldGC。
5.线程堆栈的设置:每个线程默认会开启1M的堆栈,用于存放栈帧、调用参数、局部变量等,对大多数应用而言这个默认值太了,一般256K就足用。
15.Young GC过于频繁,主要有以下影响?
- GC线程消耗的CPU时间过多,容易触发Linux CFS 限制进程的CPU
- 虽然单次GC停顿较短,但频次高了之后,整个服务的吞吐量会下降
- GC过于频繁,慢请求产生的临时对象经过几轮YoungGC后容易晋升到老年代
目前YoungGC一分钟超过60次,则会触发报警,建议控制在20次/分钟以内。
Young GC过于频繁,说明JVM内存分配压力大,可能是Young区比较小或者代码加载到内存的数据过多。
可能的原因:
- Eden区过小:g1 newSizePercent
- 大批量加载数据。
- 内存分配速率过高
代码原因导致的数据加载过多,常见于:
- 文件上传下载、报表导入导出
- 数据量随业务发展突增,代码没有分页或没有限制分页大小,或部分请求参数组合导致返回了大量数据
- 业务逻辑涉及的内存全量加载到内存里计算,不复用中间结果,相同的数据重复请求
- Redis缓存了大List,导致序列化/反序列化临时对象过多
16.cpu偏高如何排查和治理?
- 首先top命令查看服务器cpu等情况:
- top -H -p pid命令查看具体的线程情况.
- 将线程的pid转为16进制.
- 使用jvm工具jstack打印该进程的堆栈信息.jstack 29737 |grep -A 50 753d .
常见的cpu飙升原因:
- 程序中存在死循环或者长时间占用 CPU 的操作。比如,不合理的递归操作、循环操作等等。
- 程序中存在大量的计算操作,例如复杂的算法、大量的数值计算等等。
- 程序中存在大量的 IO 操作,例如读写文件、网络通信等等。
- 程序中存在大量的线程创建和销毁操作,以及线程间的竞争和同步操作。
- 程序中存在内存泄漏或者内存溢出,导致 JVM 不断进行垃圾回收。
- 程序中存在大量的数据库操作,导致数据库连接池的耗尽和数据库负载过高。
针对这些问题,需要具体情况具体分析,采取相应的优化措施,例如修改代码逻辑、优化算法、降低 IO 操作频率、减少线程创建和销毁、增加 JVM 内存等等。
六、redis
1.什么是redis?
Redis是高性能非关系型(NoSQL)的键值对数据库。
Redis 可以存储键和五种不同类型的值之间的映射。键的类型只能为字符串,值支持五种数据类型:字符串、列表、集合、散列表、有序集合。
Redis 的数据是存在内存中的,所以读写速度非常快,因此 redis 被广泛应用于缓存方向,每秒可以处理超过 10万次读写操作,是已知性能最快的Key-Value DB。另外,Redis 也经常用来做分布式锁。除此之外,Redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
2.Redis有哪些优缺点?
Redis有哪些优缺点
优点
- 读写性能优异, Redis能读的速度是11W次/s,写的速度是8W次/s。
- 支持数据持久化,支持AOF和RDB两种持久化方式。
- 支持事务,Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行。
- 数据结构丰富,除了支持string类型的value外还支持hash、set、zset、list等数据结构。
- 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
缺点
- 数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
- Redis 不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复。
- 主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性。
- Redis 较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。为避免这一问题,运维人员在系统上线时必须确保有足够的空间,这对资源造成了很大的浪费。
3.Redis为什么这么快?
- 完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是O(1);
- 数据结构简单,对数据操作也简单,Redis 中的数据结构是专门进行设计的;
- 采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
- 使用多路 I/O 复用模型,非阻塞 IO;
- 使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis 直接自己构建了 VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
4.Redis的应用场景
总结一
- 计数器:可以对 String 进行自增自减运算,从而实现计数器功能。INCR。
- 缓存:将热点数据放到内存中,设置内存的最大使用量以及淘汰策略来保证缓存的命中率。
- 会话缓存:可以使用 Redis 来统一存储多台应用服务器的会话信息。
- 查找表:例如 DNS 记录就很适合使用 Redis 进行存储。
- 消息队列:List 是一个双向链表,可以通过 lpush 和 rpop 写入和读取消息。
- 分布式锁实现: Redis 自带的 SETNX 命令实现分布式锁,除此之外,还可以使用官方提供的 RedLock 分布式锁实现。
总结二:
通过上面的数据类型的特性,基本就能想到合适的应用场景了。
string——适合最简单的k-v存储,类似于memcached的存储结构,短信验证码,配置信息等,就用这种类型来存储。
hash——一般key为ID或者唯一标示,value对应的就是详情了。如商品详情,个人信息详情,新闻详情等。
list——因为list是有序的,比较适合存储一些有序且数据相对固定的数据。如省市区表、字典表等。因为list是有序的,适合根据写入的时间来排序,如:最新的***,消息队列等。
set——可以简单的理解为ID-List的模式,如微博中一个人有哪些好友,set最牛的地方在于,可以对两个set提供交集、并集、差集操作。例如:查找两个人共同的好友等。
Sorted Set——是set的增强版本,增加了一个score参数,自动会根据score的值进行排序。比较适合类似于top 10等不根据插入的时间来排序的数据。
如上所述,虽然Redis不像关系数据库那么复杂的数据结构,但是,也能适合很多场景,比一般的缓存数据结构要多。了解每种数据结构适合的业务场景,不仅有利于提升开发效率,也能有效利用Redis的性能。
5. 什么是Redis持久化?
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失。
Redis 的持久化机制是什么?各自的优缺点?
Redis 提供两种持久化机制 RDB(默认) 和 AOF 机制:
RDB:持久化
RDB是Redis默认的持久化方式。按照一定的时间将内存的数据以快照的形式保存到硬盘中,对应产生的数据文件为dump.rdb。通过配置文件中的save参数来定义快照的周期。
RDB优点:
1、只有一个文件 dump.rdb,方便持久化。
2、容灾性好,一个文件可以保存到安全的磁盘。
3、性能最大化,fork 子进程来完成写操作,让主进程继续处理命令,所以是 IO 最大化。使用单独子进程来进行持久化,主进程不会进行任何 IO 操作,保证了 redis 的高性能
4.相对于数据集大时,比 AOF 的启动效率更高。
RDB缺点:
1、数据安全性低。RDB 是间隔一段时间进行持久化,如果持久化之间 redis 发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候)
2、AOF(Append-only file)持久化方式: 是指所有的命令行记录以 redis 命令请 求协议的格式完全持久化存储)保存为 aof 文件。
AOF:持久化
AOF持久化(即Append Only File持久化),则是将Redis执行的每次写命令记录到单独的日志文件中,当重启Redis会重新将持久化的日志中文件恢复数据。
当两种方式同时开启时,数据恢复Redis会优先选择AOF恢复。
AOF优点:
1、数据安全,aof 持久化可以配置 appendfsync 属性,有 always,每进行一次 命令操作就记录到 aof 文件中一次。
2、通过 append 模式写文件,即使中途服务器宕机,可以通过 redis-check-aof 工具解决数据一致性问题。
3、AOF 机制的 重写rewrite 模式。就是对命令的合并,类似的最终db的终态命令。重写的条件:
- 没有 BGSAVE 命令在执行
- 没有 BGREWRITEAOF 在执行
- 当前AOF文件大小 > server.aof_rewrite_min_size(默认为1MB)
- 当前AOF文件大小和最后一次AOF重写后的大小之间的比率大于等于指定的增长百分比(默认为1倍,100%)
AOF缺点:
1、AOF 文件比 RDB 文件大,且恢复速度慢。
2、数据集大的时候,比 rdb 启动效率低。
6.如何选择合适的持久化方式?
- 对数据安全性要求较高,你应该同时使用两种持久化功能。在这种情况下,当 Redis 重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
- 如果可以接受数分钟以内的数据丢失,那么你可以只使用RDB持久化。
- 有很多用户都只使用AOF持久化,但并不推荐这种方式,因为定时生成RDB快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比AOF恢复的速度要快。
- 如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化方式。
7.Redis持久化数据和缓存怎么做扩容?
-
如果Redis被当做缓存使用,使用一致性哈希实现动态扩容缩容。
-
如果Redis被当做一个持久化存储使用,必须使用固定的keys-to-nodes映射关系,节点的数量一旦确定不能变化.必须使用可以在运行时进行数据再平衡的一套系统,而当前只有Redis集群可以做到这样。
8.Redis的过期键的删除策略
我们都知道,Redis是key-value数据库,我们可以设置Redis中缓存的key的过期时间。Redis的过期策略就是指当Redis中缓存的key过期了,Redis如何处理。
过期策略通常有以下三种:
- 定时过期:每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
- 惰性过期:只有当访问一个key时,才会判断该key是否已过期,过期则清除。该策略可以最大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
- 定期过期:每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。
Redis中同时使用了惰性过期和定期过期两种过期策略。
9.MySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据?
redis内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。
10.Redis的内存淘汰策略有哪些?
Redis的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。
全局的键空间选择性移除
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。(这个是最常用的)
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。
设置过期时间的键空间选择性移除 - volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
11.redis线程模型
Redis基于Reactor模式的文件事件处理器(file event handler)。
它的组成结构为4部分:多个套接字、IO多路复用程序、文件事件分派器、事件处理器。
因为文件事件分派器队列的消费是单线程的,所以Redis才叫单线程模型。
- 文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字, 并根据套接字目前执行的任务来为套接字关联不同的事件处理器。
- 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时, 与操作相对应的文件事件就会产生, 这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
虽然文件事件处理器以单线程方式运行, 但通过使用 I/O 多路复用程序来监听多个套接字, 文件事件处理器既实现了高性能的网络通信模型, 又可以很好地与 redis 服务器中其他同样以单线程方式运行的模块进行对接, 这保持了 Redis 内部单线程设计的简单性。
12.redis事务?
Redis 事务的本质是通过MULTI、EXEC、WATCH等一组命令的集合。事务支持一次执行多个命令,一个事务中所有命令都会被序列化。在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。
总结说:redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令。
13.Redis事务相关命令
Redis事务功能是通过MULTI、EXEC、DISCARD和WATCH 四个原语实现的
Redis会将一个事务中的所有命令序列化,然后按顺序执行。
- redis 不支持回滚,“Redis 在事务失败时不进行回滚,而是继续执行余下的命令”, 所以 Redis 的内部可以保持简单且快速。
- 如果在一个事务中的命令出现错误,那么所有的命令都不会执行;
- 如果在一个事务中出现运行错误,那么正确的命令会被执行。
- MULTI命令用于开启一个事务,它总是返回OK。 MULTI执行之后,客户端可以继续向服务器发送任意多条命令,这些命令不会立即被执行,而是被放到一个队列中,当EXEC命令被调用时,所有队列中的命令才会被执行。
- EXEC:执行所有事务块内的命令。返回事务块内所有命令的返回值,按命令执行的先后顺序排列。 当操作被打断时,返回空值 nil 。
- DISCARD,客户端可以清空事务队列,并放弃执行事务, 并且客户端会从事务状态中退出。
- WATCH 命令是一个乐观锁,可以为 Redis 事务提供 check-and-set (CAS)行为。 可以监控一个或多个键,一旦其中有一个键被修改(或删除),之后的事务就不会执行,监控一直持续到EXEC命令。
- UNWATCH命令可以取消watch对所有key的监控。
15.Redis事务保证原子性吗,支持回滚吗
Redis中,单条命令是原子性执行的,但事务不保证原子性,且没有回滚。事务中任意命令执行失败,其余的命令仍会被执行。
redis集群方案
redis Sharding(hash算法)、redis-proxy(代理)、Redis 主从架构
16.哨兵模式
sentinel,中文名是哨兵。哨兵是 redis 集群机构中非常重要的一个组件,主要有以下功能:
- 集群监控:负责监控 redis master 和 slave 进程是否正常工作。
- 消息通知:如果某个 redis 实例有故障,那么哨兵负责发送消息作为报警通知给管理员。
- 故障转移:如果 master node 挂掉了,会自动转移到 slave node 上。
-配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址。
哨兵用于实现 redis 集群的高可用,本身也是分布式的,作为一个哨兵集群去运行,互相协同工作。
- 故障转移时,判断一个 master node 是否宕机了,需要大部分的哨兵都同意才行,涉及到了分布式选举的问题。
- 即使部分哨兵节点挂掉了,哨兵集群还是能正常工作的。
17.官方Redis Cluster 方案
Redis Cluster是一种服务端分片技术,3.0版本开始正式提供。Redis Cluster并没有使用一致性hash,而是采用hash slot(槽)的概念,一共分成16384个槽。将请求发送到任意节点,接收到请求的节点会将查询请求发送到正确的节点上执行。
方案说明
- 通过哈希的方式,将数据分片,每个节点均分存储一定哈希槽(哈希值)区间的数据,默认分配了16384 个槽位
- 每份数据分片会存储在多个互为主从的多节点上
3.数据写入先写主节点,再同步到从节点(支持配置为阻塞同步)
4.同一分片多个节点间的数据不保持一致性
5.读取数据时,当客户端操作的key没有分配在该节点上时,redis会返回转向指令,指向正确的节点
6.扩容时时需要需要把旧节点的数据迁移一部分到新节点
在 redis cluster 架构下,每个 redis 要放开两个端口号,比如一个是 6379,另外一个就是 加1w 的端口号,比如 16379。
16379 端口号是用来进行节点间通信的,也就是 cluster bus 的东西,cluster bus 的通信,用来进行故障检测、配置更新、故障转移授权。cluster bus 用了另外一种二进制的协议,gossip 协议,用于节点间进行高效的数据交换,占用更少的网络带宽和处理时间
18.分布式寻址算法
- hash 算法(大量缓存重建)
- 一致性 hash 算法(自动缓存迁移)+ 虚拟节点(自动负载均衡)
- redis cluster 的 hash slot 算法。
19.redis主从架构
单机的 redis,能够承载的 QPS 大概就在上万到几万不等。对于缓存来说,一般都是用来支撑读高并发的。因此架构做成主从(master-slave)架构,一主多从,主负责写,并且将数据复制到其它的 slave 节点,从节点负责读。所有的读请求全部走从节点。这样也可以很轻松实现水平扩容,支撑读高并发。
redis replication -> 主从架构 -> 读写分离 -> 水平扩容支撑读高并发。
redis replication 的核心机制
- redis 采用异步方式复制数据到 slave 节点,不过 redis2.8 开始,slave node 会周期性地确认自己每次复制的数据量;
- 一个 master node 是可以配置多个 slave node 的;
- slave node 也可以连接其他的 slave node;
- slave node 做复制的时候,不会 block master node 的正常工作;
- slave node 在做复制的时候,也不会 block 对自己的查询操作,它会用旧的数据集来提供服务;但是复制完成的时候,需要删除旧数据集,加载新数据集,这个时候就会暂停对外服务了;
- slave node 主要用来进行横向扩容,做读写分离,扩容的 slave node 可以提高读的吞吐量。
注意,如果采用了主从架构,那么建议必须开启 master node 的持久化。
20.redis 主从复制的核心原理
- 当启动一个 slave node 的时候,它会发送一个 PSYNC 命令给 master node。
- 如果这是 slave node 初次连接到 master node,那么会触发一次 full resynchronization 全量复制。此时 master 会启动一个后台线程,开始生成一份 RDB 快照文件,同时还会将从客户端 client 新收到的所有写命令缓存在内存中。
- RDB 文件生成完毕后, master 会将这个 RDB 发送给 slave,slave 会先写入本地磁盘,然后再从本地磁盘加载到内存中,
- 接着 master 会将内存中缓存的写命令发送到 slave,slave 也会同步这些数据。
- slave node 如果跟 master node 有网络故障,断开了连接,会自动重连,连接之后 master node 仅会复制给 slave 部分缺少的数据。
21.Redis集群的主从复制模型是怎样的?
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型。Redis集群没有使用一致性hash,而是引入了哈希槽的概念,Redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽。每个节点都会有N-1个复制品。
22.Redis实现分布式锁
redis为单进程单线程模式,采用队列模式将并发访问变成串行访问,可以使用SETNX命令实现分布式锁。
使用SETNX命令获取锁,若返回0(key已存在,锁已存在)则获取失败,反之获取成功。
为了防止获取锁后程序出现异常,导致其他线程/进程调用SETNX命令总是返回0而进入死锁状态,需要为该key设置一个“合理”的过期时间。
释放锁,使用DEL命令将锁数据删除。
方案一:SETNX + EXPIRE
方案二:SETNX + value值是(系统时间+过期时间)
方案七:多机实现的分布式锁Redlock+Redisson
红锁?
采用用主节点过半机制,即获取锁或者释放锁成功的标志为:在过半的节点上操作成功。主要是解决单机故障。
RedLock的实现步骤:如下
- 按顺序向5个master节点请求加锁
- 根据设置的超时时间来判断,是不是要跳过该master节点。
- 如果大于等于N/2+1个节点加锁成功,并且使用的时间小于锁的有效期,即可认定加锁成功啦。
- 如果获取锁失败,对所有节点解锁!
23.说说Redis哈希槽的概念?
Redis集群没有使用一致性hash,而是引入了哈希槽的概念,Redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽。
24.Redis是单线程的,如何提高多核CPU的利用率?
可以在同一个服务器部署多个Redis的实例,并把他们当作不同的服务器来使用,在某些时候,无论如何一个服务器是不够的, 所以,如果你想使用多个CPU,你可以考虑一下分片(shard)。
分区可以让Redis管理更大的内存,Redis将可以使用所有机器的内存。如果没有分区,你最多只能使用一台机器的内存。分区使Redis的计算能力通过简单地增加计算机得到成倍提升,Redis的网络带宽也会随着计算机和网卡的增加而成倍增长。
24.你知道有哪些Redis分区实现方案?
- 客户端分区就是在客户端就已经决定数据会被存储到哪个redis节点或者从哪个redis节点读取。大多数客户端已经实现了客户端分区。
- 代理分区 意味着客户端将请求发送给代理,然后代理决定去哪个节点写数据或者读数据。代理根据分区规则决定请求哪些Redis实例,然后根据Redis的响应结果返回给客户端。redis和memcached的一种代理实现就是Twemproxy
- 查询路由(Query routing) 的意思是客户端随机地请求任意一个redis实例,然后由Redis将请求转发给正确的Redis节点。Redis Cluster实现了一种混合形式的查询路由,但并不是直接将请求从一个redis节点转发到另一个redis节点,而是在客户端的帮助下直接redirected到正确的redis节点。
25.如何解决 Redis 的并发竞争 Key 问题?
所谓 Redis 的并发竞争 Key 的问题也就是多个系统同时对一个 key 进行操作,但是最后执行的顺序和我们期望的顺序不同,这样也就导致了结果的不同!
推荐一种方案:分布式锁(zookeeper 和 redis 都可以实现分布式锁)。(如果不存在 Redis 的并发竞争 Key 问题,不要使用分布式锁,这样会影响性能)
基于zookeeper临时有序节点可以实现的分布式锁。大致思想为:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。完成业务流程后,删除对应的子节点释放锁。
在实践中,当然是从以可靠性为主。所以首推Zookeeper。
26.缓存异常
缓存雪崩是指缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案:
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 一般并发量不是特别多的时候,使用最多的解决方案是加锁排队。
- 自动刷新缓存,给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存。
缓存穿透是指缓存和数据库中都没有的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案:
4. 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
5. 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
6. 采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
解决方案:
7. 设置热点数据永远不过期。
8. 加互斥锁,互斥锁
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。
解决方案:
9. 直接写个缓存刷新页面,上线时手工操作一下;
10. 数据量不大,可以在项目启动的时候自动进行加载;
11. 定时刷新缓存;
27.缓存热点key过期如何解决?
缓存中的一个Key(比如一个促销商品),在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
解决方案:
对缓存查询加锁,如果KEY不存在,就加锁,然后查DB入缓存,然后解锁;其他进程如果发现有锁就等待,然后等解锁后返回数据或者进入DB查询。
28.Redis支持的Java客户端都有哪些?官方推荐用哪个?
Redisson、Jedis、lettuce等等,官方推荐使用Redisson。
Redis和Redisson有什么关系?
Redisson是一个高级的分布式协调Redis客服端,能帮助用户在分布式环境中轻松实现一些Java的对象 (Bloom filter, BitSet, Set, SetMultimap, ScoredSortedSet, SortedSet, Map, ConcurrentMap, List, ListMultimap, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, ReadWriteLock, AtomicLong, CountDownLatch, Publish / Subscribe, HyperLogLog)。
Jedis与Redisson对比有什么优缺点?
Jedis是Redis的Java实现的客户端,其API提供了比较全面的Redis命令的支持;Redisson实现了分布式和可扩展的Java数据结构,和Jedis相比,功能较为简单,不支持字符串操作,不支持排序、事务、管道、分区等Redis特性。Redisson的宗旨是促进使用者对Redis的关注分离,从而让使用者能够将精力更集中地放在处理业务逻辑上。
29.Redis常见性能问题和解决方案?
- Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化。
- 如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
- 为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内。
- 尽量避免在压力较大的主库上增加从库
- Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。
- 为了Master的稳定性,主从复制不要用图状结构,用单向链表结构更稳定,即主从关系为:Master<–Slave1<–Slave2<–Slave3…,这样的结构也方便解决单点故障问题,实现Slave对Master的替换,也即,如果Master挂了,可以立马启用Slave1做Master,其他不变。
30.假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如果将它们全部找出来?
使用keys指令可以扫出指定模式的key列表。
对方接着追问:如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
这个时候你要回答redis关键的一个特性:redis的单线程的。keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用scan指令,scan指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长。
31.Redis如何实现延时队列?
使用sortedset,使用时间戳做score, 消息内容作为key,调用zadd来生产消息,消费者使用zrangbyscore获取n秒之前的数据做轮询处理。
32.redis是单线程的吗?redis4.0和redis6.0分别做了什么?
redis4.0之前的版本使用的是单线程,也就是说只有一个 worker队列,所有的读写操作都要在这一个队列进行操作,好处是不会有线程安全问题。但如果删除一个大key耗时很长。
因此,在4.0版本引入了Lazy Free机制,将慢操作异步化了。采用非阻塞删除(对应命令UNLINK),大键的空间回收交由单独线程实现,主线程只做关系解除,可以快速返回,继续处理其他事件,避免服务器长时间阻塞。
Redis的性能瓶颈并不在CPU上,而是在内存和网络上。所以6.0发布的多线程并未将事件处理改成多线程,而是在I/O上。但是,6.0版本的多线程并非彻底的多线程,I/O线程只能同时执行读或者同时执行写操作,期间事件处理线程一直处于等待状态,并非流水线模型,有很多轮训等待开销。
总结:Redis的单线程,主要是指事件处理上,但是Redis的其他功能,如持久化、异步删除这些都是由额外的线程执行的。在Redis6.0版本的多线程并非彻底的多线程,I/O线程只能同时执行读或者同时执行写操作。默认关闭在开启多线程后,并不会存在线程并发的安全问题,因为Redis的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程顺序执行。
33.redis 集群模式的工作原理能说一下么?
Redis3.0加入了Redis的集群模式,实现了数据的分布式存储,对数据进行分片,将不同的数据存储在不同的master节点上面,从而解决了海量数据的存储问题。
Redis集群采用去中心化的思想,没有中心节点的说法,对于客户端来说,整个集群可以看成一个整体,可以连接任意一个节点进行操作,就像操作单一Redis实例一样,不需要任何代理中间件,当客户端操作的key没有分配到该node上时,Redis会返回转向指令,指向正确的node。
Redis也内置了高可用机制,支持N个master节点,每个master节点都可以挂载多个slave节点,当master节点挂掉时,集群会提升它的某个slave节点作为新的master节点。
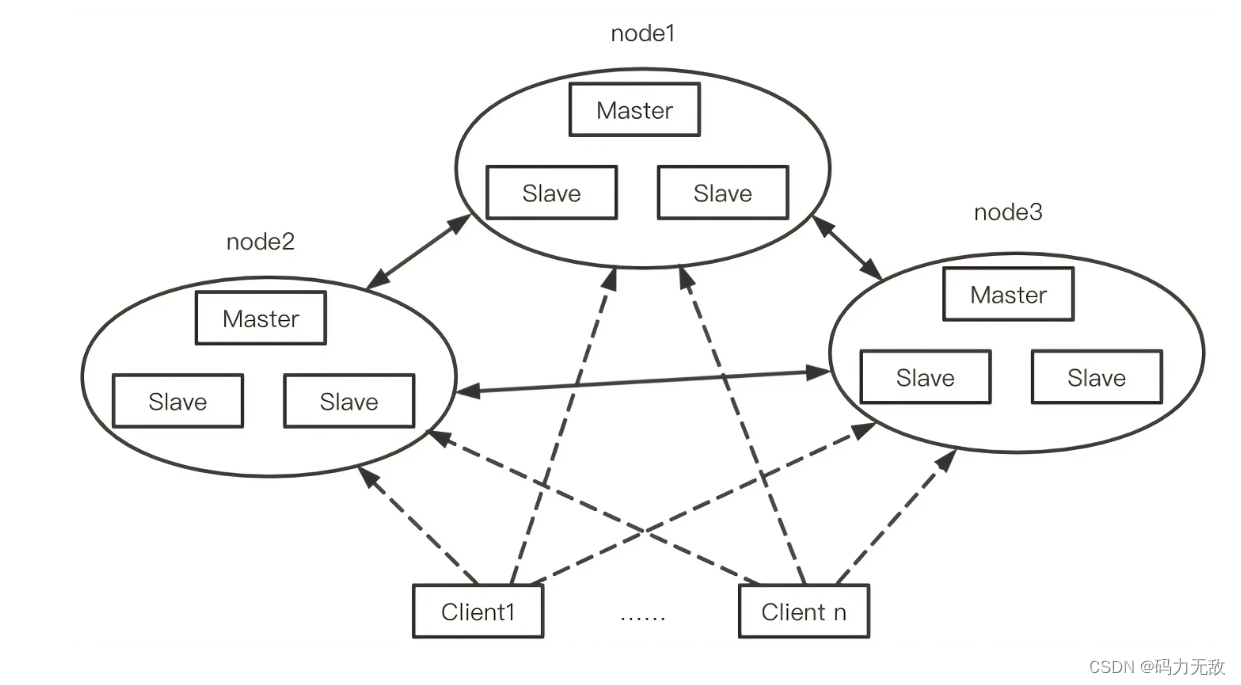
如何请求重定向?
- 但是由于“缓存节点1”中保存了所有集群中缓存节点的信息,因此它知道这个 Slot 的数据在“缓存节点2”中保存,
- 因此向 Redis 客户端发送了一个 MOVED/ASK的重定向请求。这个请求告诉其应该访问的“缓存节点2”的地址。ASK是槽正在迁移需要确认。
- Redis 客户端拿到这个地址,继续访问“缓存节点2”并且拿到数据。
- 这个重定向过程显然会增加集群的网络负担和单次请求耗时。所以大部分客户端本地维护一份hashslot => node的映射表缓存,大部分情况下,直接走本地缓存就可以找到hashslot => node,不需要通过节点进行moved重定向。
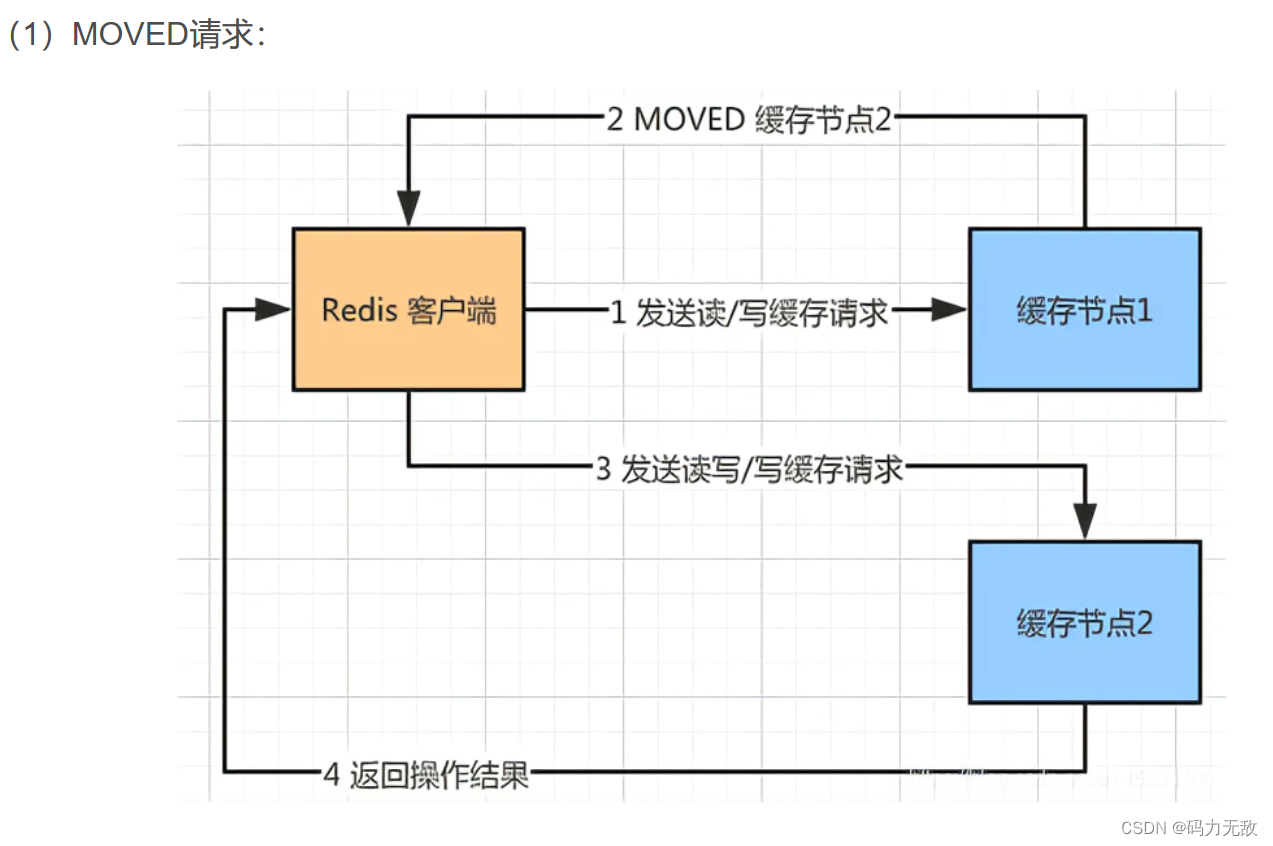
34.什么是hash槽算法?
- 普通hash算法:将key使用hash算法计算之后,按照节点数量来取余,即hash(key)%N。优点就是比较简单,但是扩容或者摘除节点时需要重新根据映射关系计算,会导致数据重新迁移。
- 一致性hash算法:为每一个节点分配一个token,构成一个哈希环;查找时先根据key计算hash值,然后顺时针找到第一个大于等于该哈希值的token节点。优点是在加入和删除节点时只影响相邻的两个节点,缺点是加减节点会造成部分数据无法命中,所以一般用于缓存,而且用于节点量大的情况下,扩容一般增加一倍节点保障数据负载均衡。
- 哈希槽分区算法:Redis集群中有16384个哈希槽(槽的范围是 0 -16383,哈希槽),将不同的哈希槽分布在不同的Redis节点上面进行管理,也就是说每个Redis节点只负责一部分的哈希槽。在对数据进行操作的时候,集群会对使用CRC16算法对key进行计算并对16384取模(slot = CRC16(key)%16383),得到的结果就是 Key-Value 所放入的槽,通过这个值,去找到对应的槽所对应的Redis节点。
当需要增加节点时,只需要把其他节点的某些哈希槽挪到新节点就可以了;当需要移除节点时,只需要把移除节点上的哈希槽挪到其他节点就行了;
默认情况下,redis集群的读和写都是到master上去执行的,不支持slave节点读和写,跟Redis主从复制下读写分离不一样,因为redis集群的核心的理念,主要是使用slave做数据的热备,以及master故障时的主备切换,实现高可用的。Redis的读写分离,是为了横向任意扩展slave节点去支撑更大的读吞吐量。而redis集群架构下,本身master就是可以任意扩展的,如果想要支撑更大的读或写的吞吐量,都可以直接对master进行横向扩展。
这个重定向过程显然会增加集群的网络负担和单次请求耗时。所以大部分的客户端都是smart的。所谓 smart客户端,就是指客户端本地维护一份hashslot => node的映射表缓存,大部分情况下,直接走本地缓存就可以找到hashslot => node,不需要通过节点进行moved重定向。
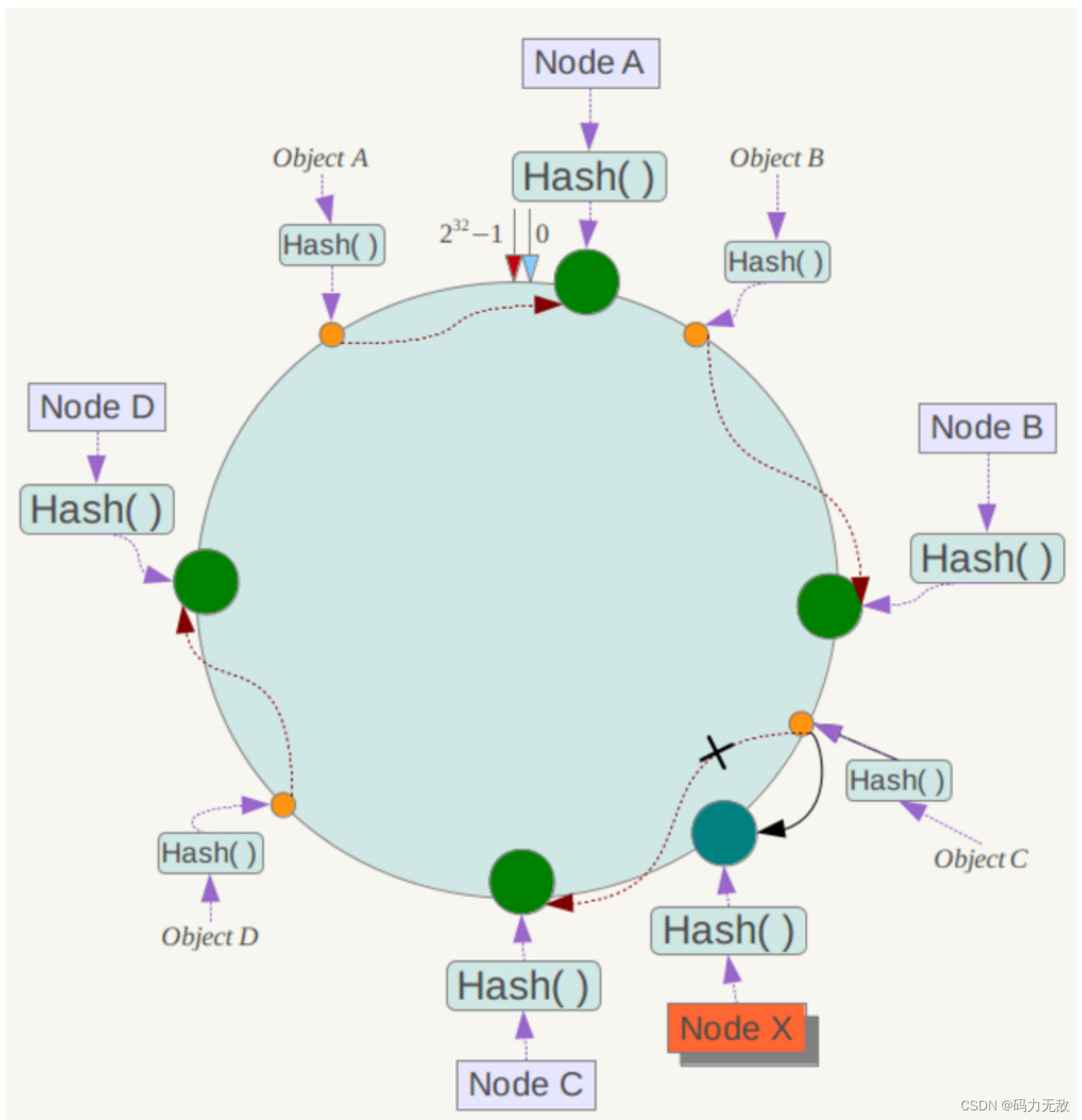
Hash只要集群的数量N发生变化,之前的所有Hash映射就会全部失效。**一致性Hash通过构建环状的Hash空间代替线性Hash空间的方法解决了这个问题。**则受影响的数据仅仅是新服务器到其环空间中前一台服务器。
35.redis如何实现扩容?扩容需要做什么?
1)客户端让目标节点发起准备导入槽数据。使用命令:cluster setslot {slot} importing {sourceNodeId}
(2)之后让源节点准备迁出对应的槽数据。使用命令:cluster setslot {slot} migrating {targetNodeId}
(3)此时源节点准备迁移数据了,在迁移之前把要迁移的数据获取出来。通过命令 cluster getkeysinslot {slot} {count}。Count 表示迁移的 Slot 的个数。
(4)然后在源节点上执行,migrate {targetIP} {targetPort} “” 0 {timeout} keys {keys} 命令,把获取的键通过流水线批量迁移到目标节点。
(5)重复 3 和 4 两步不断将数据迁移到目标节点。
(6)完成数据迁移到目标节点以后,通过 cluster setslot {slot} node {targetNodeId} 命令通知对应的槽被分配到目标节点,并且广播这个信息给全网的其他主节点,更新自身的槽节点对应表。
36.redis如何实现秒杀系统?
方案1:Redis + MQ
- 秒杀之前,将产品的库存从数据库同步到Redis
- 秒杀时,通过lua脚本保证原子性。扣减库存。返回1(表示成功),则将订单数据通过MQ投递出去
- MQ消费者收到数据后,持久化到数据库中。
方案二:原子增减
主要是这几个命令:incr、incrby、decr、decrby
37.实现分布式锁的方式有几种?
- 基于缓存(Redis等)实现分布式锁; setnx、redLock、lua脚本
- 基于数据库实现分布式锁; 行锁设置自动提交为false,释放commit、乐观锁。
- 基于Zookeeper实现分布式锁;
三种方案的比较
- 从理解的难易程度角度(从低到高):数据库 > 缓存 > Zookeeper
- 从实现的复杂性角度(从低到高):Zookeeper > 缓存 > 数据库
- 从性能角度(从高到低):缓存 > Zookeeper >= 数据库
- 从可靠性角度(从高到低):Zookeeper > 缓存 > 数据库
通过数据库的排他锁来实现分布式锁的原理:
基于 MySQL 的 InnoDB 引擎,可以使用以下方法来实现加锁操作:
public boolean lock(){
connection.setAutoCommit(false)
while(true){
try{
result = select * from methodLock where method_name=xxx for update;
if(result==null){
return true;
}
}catch(Exception e){
}
sleep(1000);
}
return false;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3.我们可以认为获得排它锁的线程即可获得分布式锁,当获取到锁之后,可以执行方法的业务逻辑,执行完方法之后,再通过以下方法解锁:
public void unlock(){
connection.commit();
}
- 1
- 2
- 3
38.zookeeper实现分布式锁的原理?
基于zookeeper临时有序节点可以实现的分布式锁。
大致思想即为:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。
来看下Zookeeper能不能解决前面提到的问题。
- 锁无法释放?使用Zookeeper可以有效的解决锁无法释放的问题,因为在创建锁的时候,客户端会在ZK中创建一个临时节点,一旦客户端获取到锁之后突然挂掉(Session连接断开),那么这个临时节点就会自动删除掉。其他客户端就可以再次获得锁。
- 非阻塞锁?使用Zookeeper可以实现阻塞的锁,客户端可以通过在ZK中创建顺序节点,并且在节点上绑定监听器,一旦节点有变化,Zookeeper会通知客户端,客户端可以检查自己创建的节点是不是当前所有节点中序号最小的,如果是,那么自己就获取到锁,便可以执行业务逻辑了。
- 不可重入?使用Zookeeper也可以有效的解决不可重入的问题,客户端在创建节点的时候,把当前客户端的主机信息和线程信息直接写入到节点中,下次想要获取锁的时候和当前最小的节点中的数据比对一下就可以了。如果和自己的信息一样,那么自己直接获取到锁,如果不一样就再创建一个临时的顺序节点,参与排队。
- 单点问题?使用Zookeeper可以有效的解决单点问题,ZK是集群部署的,只要集群中有半数以上的机器存活,就可以对外提供服务。
- 公平问题?使用Zookeeper可以解决公平锁问题,客户端在ZK中创建的临时节点是有序的,每次锁被释放时,ZK可以通知最小节点来获取锁,保证了公平。
38.什么是Lua?如何实现?
Redis中的Lua脚本是一种用于扩展和定制Redis命令的机制,可以将多个命令合并到一个脚本中,并在Redis服务器端原子性地执行该脚本。通过使用Lua脚本,可以减少网络通信、降低响应时间、提高性能等。
39.JedisCluster如何寻址集群的?
JedisCluster配置只用指定集群中某一个节点的IP,端口信息就可以了。JedisCluster初始化时,会找配置的节点获取整个集群的信息(cluster nodes命令)。
解析集群信息,得到集群中所有master信息,然后遍历每台master,通过ip,端口构建jedis实例,然后put到一个全局nodes变量里面(Map类型) , key为ip,端口,值为Jedis实例,nodes值如下:
nodes={172.19.93.120:6380=redis.clients.jedis.JedisPool@74ad1f1f,.....}
- 1
在上面遍历master过程中,还遍历此台master负责的槽索引,然后又put到一个全局map slots里面。值为上面的Jedis实例, slots值如下:
slots={0=redis.clients.jedis.JedisPool@74ad1f1f,
1=redis.clients.jedis.JedisPool@74ad1f1f,
- 1
- 2
有了上面的slots变量,当有值set 时, 会先算出slot = getCRC16(key)&(16383-1),假如是12182 , 然后调用slots.get(12182) 得到jedis实例,然后去操作redis。
如果发现MovedDataException,说明初始化得到的槽位与节点的对应关系有问题,(节点新增或者宕机)就会重置slots。
40.如何发现和解决热key?
- 1.1 集群中每个slot的qps监控。
- 1.2 proxy的代理机制作为整个流量入口统计。
- 1.3 redis基于LFU的热点key发现机制。
redis 4.0以上的版本支持了每个节点上的基于LFU的热点key发现机制,使用redis-cli –hotkeys即可,执行redis-cli时加上–hotkeys选项。可以定时在节点中使用该命令来发现对应热点key。 - 1.4 基于Redis客户端做探测
热key的解决?
- 对特定key或slot做限流,因为业务有损,所以建议只用在出现线上问题,需要止损的时候进行特定的限流。
- 使用本地缓存,使用本地缓存存储一份,以java为例,guavaCache就是现成的工具。带来了问题数据不一致,设置过期多大过期时间要业务接受。
- 拆key,既能保证不出现热key问题,又能尽量的保证数据一致性。
我们在放入缓存时就将对应业务的缓存key拆分成多个不同的key。
一个key名字叫做"good_100",那我们就可以把它拆成四份,“good_100_copy1”、“good_100_copy2”、“good_100_copy3”、“good_100_copy4”,每次更新和新增时都需要去改动这N个key。
2.4 本地缓存的另外一种思路 配置中心
长轮询+本地化的配置。首先服务启动时会初始化全部的配置,然后定时启动长轮询去查询当前服务监听的配置有没有变更,如果有变更,长轮询的请求便会立刻返回,更新本地配置;如果没有变更,对于所有的业务代码都是使用本地的内存缓存配置。
也可以做服务的业务隔离、redis缓存集群的隔离,避免影响到正常业务的同时,也会可以临时采取更好的容灾、限流措施。
一些整合的方案
目前市面上已经有了不少关于hotKey相对完整的应用级解决方案,其中京东在这方面有开源的hotkey工具,原理就是在client端做洞察,然后上报对应hotkey,server端检测到后,将对应hotkey下发到对应服务端做本地缓存,并且这个本地缓存在远程对应的key更新后,会同步更新,已经是目前较为成熟的自动探测热key、分布式一致性缓存解决方案,京东零售热key。
41. redis的数据结构?
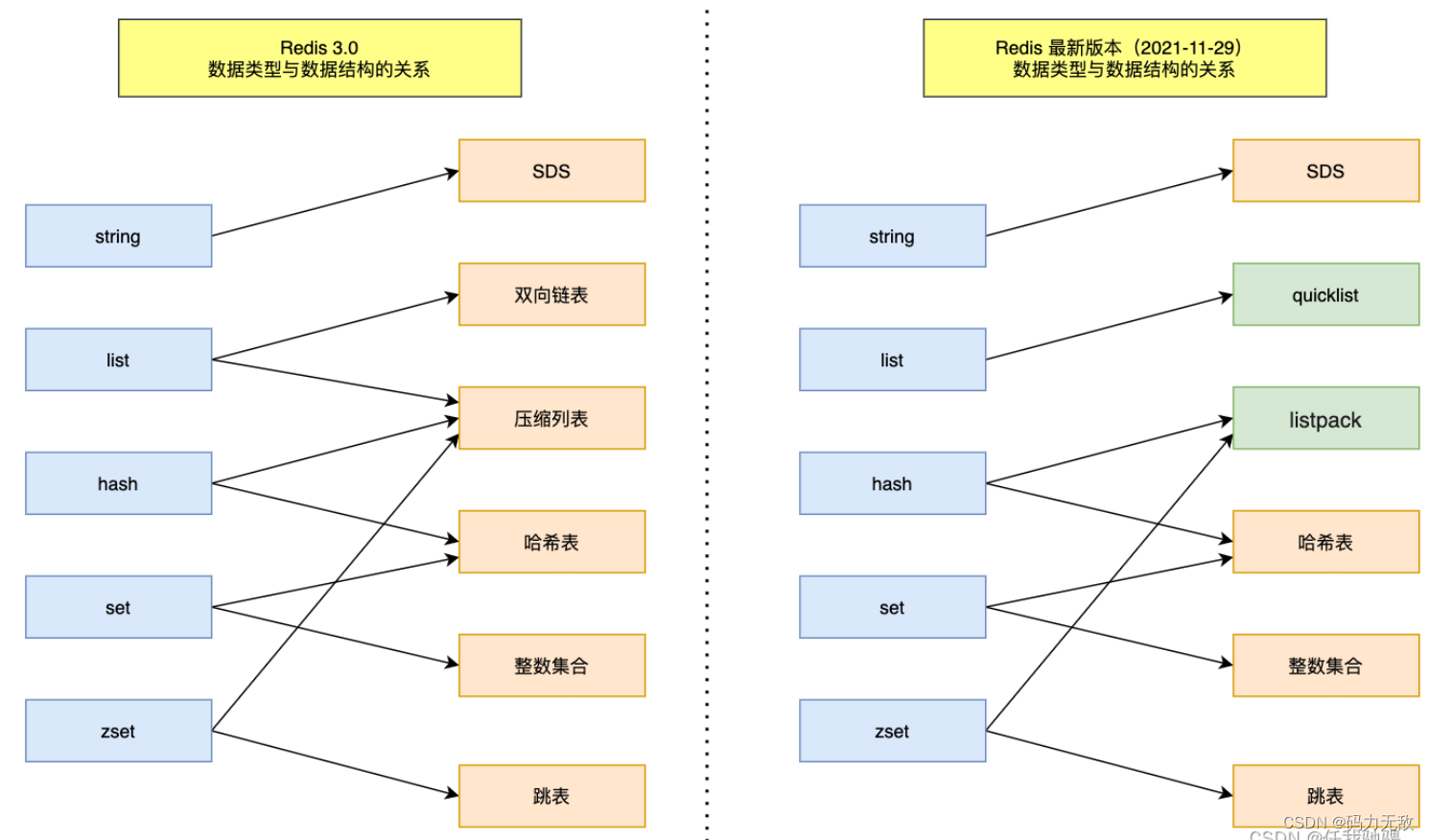
Redis 是使用了一个「哈希表」保存所有键值对,哈希表的最大好处就是让我们可以用 O(1) 的时间复杂度来快速查找到键值对。哈希表其实就是一个数组,数组中的元素叫做哈希桶。
Zset 对象是唯一一个同时使用了两个数据结构来实现的 Redis 对象,这两个数据结构一个是跳表,一个是哈希表。这样的好处是既能进行高效的范围查询,也能进行高效单点查询。
41.redis锁如何续期?
- 自动续期 守护线程
我们可以先给锁设置一个LockTime,然后启动一个守护线程,让守护线程在一段时间后,重新去设置这个锁的LockTime。
- 和释放锁的情况一样,我们需要先判断持有锁客户端是否有变化。否则会造成无论谁持有锁,守护线程都会去重新设置锁的LockTime。
- 守护线程要在合理的时间再去重新设置锁的LockTime,否则会造成资源的浪费。不能动不动就去续。
- 如果持有锁的线程已经处理完业务了,那么守护线程也应该被销毁。不能业务运行结束了,守护者还在那里继续运行,浪费资源。
- Redisson的看门狗机制就是这种机制实现自动续期的:
Redisson看门狗机制, 只要客户端加锁成功,就会启动一个 Watch Dog。
- leaseTime 必须是 -1 才会开启 Watch Dog 机制,如果需要开启 Watch Dog 机制就必须使用默认的加锁时间为 30s。
- 如果你自己自定义时间,超过这个时间,锁就会自定释放,并不会自动续期。
Watch Dog 机制其实就是一个后台定时任务线程,获取锁成功之后,会将持有锁的线程放入到一个 RedissonLock.EXPIRATION_RENEWAL_MAP里面,然后每隔 10 秒 (internalLockLeaseTime / 3) 检查一下,如果客户端 还持有锁 key(判断客户端是否还持有 key,其实就是遍历 EXPIRATION_RENEWAL_MAP 里面线程 id 然后根据线程 id 去 Redis 中查,如果存在就会延长 key 的时间),那么就会不断的延长锁 key 的生存时间。
42. redis的String优化?
Redis 中会有一个全局的哈希表来保存所有的键值对,哈希表中每一项存储的是 dictEntry 结构体。
dictEntry 结构体中有三个指针,在64位机器下占24个字节,jemalloc 会为它分配32字节大小的内存单元。
所以选用 String 类型来存储字符串,上面的 RedisObject 结构、SDS 结构、dictEntry 结构的都会存在一定的内存开销
Redis 中的底层数据结构,提供了压缩列表,这种是很节省内存空间的。
我们可以使用 Hash 这种数据结构,因为在一定情况下这种结构底层的用的是压缩列表,这是一种很节省内存的数据结构。
43.redis的最佳实践?
1. 如何使用 Redis 更节省内存?
在开发过程中,业务层面的优化建议如下:
- key的长度尽量要短,在数据量非常大时,过长的key名会占用更多的内存
- 一定避免存储过大的数据(大value),过大的数据在分配内存和释放内存时耗时严重,会阻塞主线程。String:大小控制在 10KB 以下, List/Hash/Set/ZSet:元素数量控制在 1 万以下。
- Redis 4.0以上建议开启lazy-free机制,释放大value时异步操作,不阻塞主线程。
- 建议设置过期时间,把Redis当做缓存使用,尤其在数量很大的时,不设置过期时间会导致内存的无限增长
- 不使用复杂度过高的命令,例如SORT、SINTER、SINTERSTORE、ZUNIONSTORE、ZINTERSTORE,使用这些命令耗时较久,会阻塞主线程
- 查询数据时,一次尽量获取较少的数据,在不确定容器元素个数的情况下,避免使用LRANGE key 0 -1,ZRANGE key 0 -1这类操作,应该设置具体查询的元素个数,推荐一次查询100个以下元素
- 写入数据时,一次尽量写入较少的数据,例如HSET key value1 value2 value3…,-控制一次写入元素的数量,推荐在100以下,大数据量分多个批次写入
- 批量操作数据时,批量命令代替单个命令。用MGET/MSET替换GET/SET、HMGET/MHSET替换HGET/HSET,减少请求来回的网络IO次数,降低延迟,对于没有批量操作的命令,推荐使用pipeline,一次性发送多个命令到服务端
- 禁止使用KEYS命令,需要扫描实例时,建议使用SCAN,线上操作一定要控制扫描的频率,避免对Redis产生性能抖动
- 避免某个时间点集中过期大量的key,集中过期时推荐增加一个随机时间,把过期时间打散,降低集中过期key时Redis的压力,避免阻塞主线程
- 根据业务场景,选择合适的淘汰策略,通常随机过期要比LRU过期淘汰数据更快
- 使用连接池访问Redis,并配置合理的连接池参数,避免短连接,TCP三次握手和四次挥手的耗时也很高
- 只使用db0,不推荐使用多个db,使用多个db会增加Redis的负担,每次访问不同的db都需要执行SELECT命令,如果业务线不同,建议拆分多个实例,还能提高单个实例的性能
- 读的请求量很大时,推荐使用读写分离,前提是可以容忍从节数据更新不及时的问题
- 写请求量很大时,推荐使用集群,部署多个实例分摊写压力。
- 不开启 AOF 或 AOF 配置为每秒刷盘
- 如何保证 Redis 的可靠性?
- 按业务线部署实例,资源隔离。
- 部署主从集群。
- 合理配置主从复制参数
- 部署哨兵集群,实现故障自动切换
七、mq
1. 为什么使用MQ?MQ的优点?
- 异步处理 - 相比于传统的串行、并行方式,提高了系统吞吐量。
- 应用解耦 - 系统间通过消息通信,不用关心其他系统的处理。
- 流量削锋 - 可以通过消息队列长度控制请求量;可以缓解短时间内的高并发请求。
2.几种消息中间件的区别?
- ActiveMQ是老牌的消息中间件,吞吐量较低,不支持顺序消费,并发量不高很少使用。
- RabbitMQ,吞吐量较低,不支持顺序消费,自身是基于erlang语言开发的,改造困难。
- RocketMQ,是阿里开源,超高并发、高吞吐,性能卓越,同时还支持分布式事务等特殊场景,开源版本不够成熟,社区活跃度没kafka高,集群部署。RocketMQ 大约在10万条/秒。
- kfaka,专为超高吞吐量的实时日志采集、实时数据同步、实时数据计算等场景来设计,功能比较少,社区成熟,部署简单采用分区,天然无状态。Kafka单机写入 TPS 号称在百万条/秒;
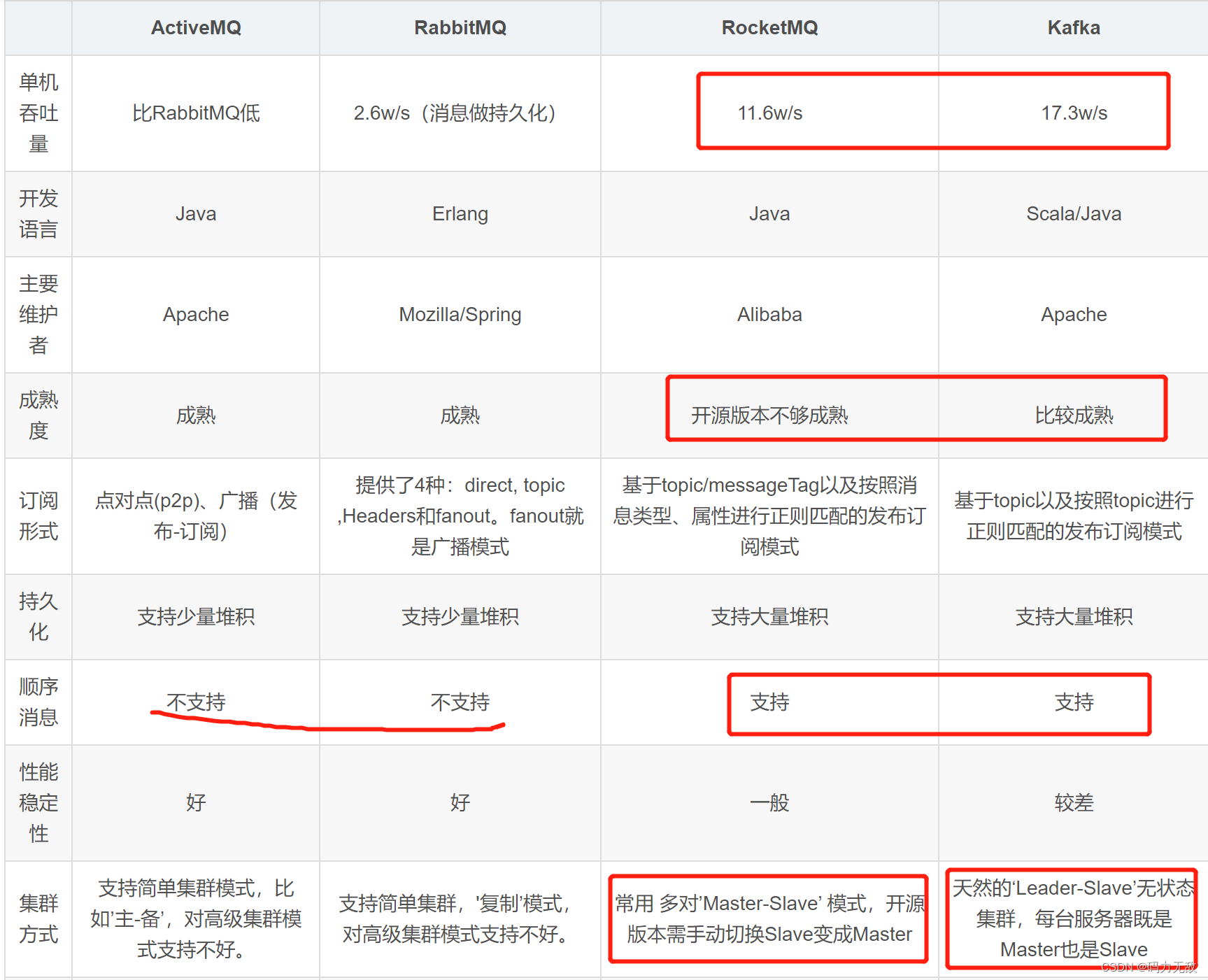
3.Kafka部分名词解释如下:
- Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
- Topic:一类消息,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发。
- Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。
- Segment:partition物理上由多个segment组成,下面2.2和2.3有详细说明。
offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息.
4 partiton中segment文件存储结构?
- 每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。
- 每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。
- segment file组成:由2大部分组成,分别为index file和data file,此2个文件一一对应,成对出现,后缀”.index”和“.log”分别表示为segment索引文件、数据文件.
- segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
Kafka高效文件存储设计特点
- Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
- 通过索引信息可以快速定位message和确定response的最大大小。
- 通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作。
- 通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。
5. kafka在什么情况下会进行在平衡?
所谓的再平衡,指的是在kafka consumer所订阅的topic发生变化时发生的一种分区重分配机制。一般有三种情况会触发再平衡:
-consumer所订阅的topic发生了新增分区的行为,那么新增的分区就会分配给当前的consumer,此时就会触发再平衡。
- consumer group中的新增或删除某个consumer,导致其所消费的分区需要分配到组内其他的consumer上;
- consumer订阅的topic发生变化,比如订阅的topic采用的是正则表达式的形式,如test-*此时如果有一个新建了一个topic test-user,那么这个topic的所有分区也是会自动分配给当前的consumer的,此时就会发生再平衡;
Kafka提供的再平衡策略主要有三种:Round Robin,Range和Sticky,默认使用的是Range。这三种分配策略的主要区别在于:
- Round Robin:会采用轮询的方式将当前所有的分区依次分配给所有的consumer;
- Range:首先会计算每个consumer可以消费的分区个数,然后按照顺序将指定个数范围的分区分配给各个consumer;
- Sticky:这种分区策略是最新版本中新增的一种策略,其主要实现了两个目的:将现有的分区尽可能均衡的分配给各个consumer,存在此目的的原因在于Round Robin和Range分配策略实际上都会导致某几个consumer承载过多的分区,从而导致消费压力不均衡;
6.RocketMQ
消息存储是由ConsumeQueue和CommitLog配合完成的。一个Topic里面有多个MessageQueue,每个MessageQueue对应一个ConsumeQueue。
每个ConsumeQueue存储的是每个消息在commitlog这个文件的地址,但是消息存在于commitlog中;
CommitLog就存储文件具体的字节信息。文件大小默认1g,文件名称20位数,左边补0右边为偏移量。消息顺序写入文件,文件满了则写入下一个文件。
所以总结如下:
1、consumerQueue消息格式大小固定(20字节),写入pagecache之后被触发刷盘频率相对较低。就是因为每次写入的消息小,造成他占用的pagecache少,主要占用方一旦被清理,那么他就可以不用清理了;
2、kafka中多partition会存在随机写的可能性,partition之间刷盘的冲撞率会高,但是rocketmq中commitLog都是顺序写。
7.Rocket的消费模型?
- push:producer发送消息后,broker马上把消息投递给consumer。这种方式好在实时性比较高,但是会增加broker的负载;而且消费端能力不同,如果push推送过快,消费端会出现很多问题。
- pull:producer发送消息后,broker什么也不做,等着consumer自己来读取。它的优点在于主动权在消费者端,可控性好;但是间隔时间不好设置,间隔太短浪费资源,间隔太长又会消费不及时。
- 长轮询:当consumer过来请求时,broker会保持当前连接一段时间 默认15s,如果这段时间内有消息到达,则立刻返回给consumer;15s没消息的话则返回空然后重新请求。这种方式的缺点就是服务端要保存consumer状态,客户端过多会一直占用资源。
RocketMQ默认是采用pushConsumer方式消费的,从概念上来说是推送给消费者,它的本质是pull+长轮询。这样既通过长轮询达到了push的实时性,又有了pull的可控性。系统收到消息后会自动处理消息和offset(消息偏移量),如果期间有新的consumer加入会自动做负载均衡(集群模式下offset存在broker中; 广播模式下offset存在consumer里)。当然我们也可以设置为pullConsumer模式,这样灵活性会提高,但是代码却会很复杂,需要手动维护offset,消息存储和状态。
8.为什么kafka比RocketMQ吞吐量更高?
kafka性吞吐量更高主要是由于Producer端将多个小消息合并,批量发向Broker。kafka采用异步发送的机制,当发送一条消息时,消息并没有发送到broker而是缓存起来,然后直接向业务返回成功,当缓存的消息达到一定数量时再批量发送。
此时减少了网络io,从而提高了消息发送的性能,但是如果消息发送者宕机,会导致消息丢失,业务出错,所以理论上kafka利用此机制提高了io性能却降低了可靠性。
RocketMQ为何无法使用同样的方式
- RocketMQ通常使用的Java语言,缓存过多消息会导致频繁GC。
- Producer调用发送消息接口,消息未发送到Broker,向业务返回成功,此时Producer宕机,会导致消息丢失,业务出错。
- Producer通常为分布式系统,且每台机器都是多线程发送,我们认为线上的系统单个Producer每秒产生的数据量有限,不可能上万。
- 缓存的功能完全可以由上层业务完成。
9 .为什么选择RocketMQ?
当broker里面的topic的partition数量过多时,kafka的性能却不如rocketMq。
kafka和rocketMq都使用文件存储,但是kafka是一个分区一个文件,当topic过多,分区的总量也会增加,kafka中存在过多的文件,当对消息刷盘时,就会出现文件竞争磁盘,出现性能的下降。一个partition(分区)一个文件,顺序读写。一个分区只能被一个消费组中的一个 消费线程进行消费,因此可以同时消费的消费端也比较少。
rocketMq所有的队列都存储在一个文件中,每个队列的存储的消息量也比较小,因此topic的增加对rocketMq的性能的影响较小。rocketMq可以存的topic比较多,可以适应比较复杂的业务。
10.如何保证消息一致性?事务消息
事务消息,它实现了消息生成者本地事务与消息发送的原子性,保证了消息生成者本地事务处理成功与消息发送成功的最终一致性问题。
1、事务消息与普通消息的区别就在于消息生产环节,生产者首先预发送一条消息到MQ(这也被称为发送half消息)
2、MQ接受到消息后,先进行持久化,则存储中会新增一条状态为待发送的消息
3、然后返回ACK给消息生产者,此时MQ不会触发消息推送事件
4、生产者预发送消息成功后,执行本地事务
5、执行本地事务,执行完成后,发送执行结果给MQ
6、MQ会根据结果删除或者更新消息状态为可发送
7、如果消息状态更新为可发送,则MQ会push消息给消费者,后面消息的消费和普通消息是一样的。
现在目前较为主流的MQ,只有RocketMQ支持事务消息。据笔者了解,早年阿里对MQ增加事务消息也是因为支付宝那边因为业务上的需求而产生的。因此,如果我们希望强依赖一个MQ的事务消息来做到消息最终一致性的话,在目前的情况下,技术选型上只能去选择RocketMQ来解决。
上面我们也分析了事务消息所存在的异常情况,即MQ存储了待发送的消息,但是MQ无法感知到上游处理的最终结果。对于RocketMQ而言,它的解决方案非常的简单,就是其内部实现会有一个定时任务,去轮训状态为待发送的消息,然后给producer发送check请求,而producer必须实现一个check监听器,监听器的内容通常就是去检查与之对应的本地事务是否成功(一般就是查询DB),如果成功了,则MQ会将消息设置为可发送,否则就删除消息。
事务消息是针对生产端而言的,而消费端,消费端的一致性是通过MQ的重试机制来完成的。
11.kafka的设计架构
- Producer:生产者可以将数据发布到所选择的topic(主题)中。生成者负责将记录分配到topic的哪一个分区(partition)中,这里可以使用对多个partition循环发送来实现多个server负载均衡
- Broker:日志的分区(partition)分布在Kafka集群的服务器上。每个服务器处理数据和请求时,共享这些分区。每一个分区都会在以配置的服务器上进行备份,确保容错性。
其中,每个分区都有一台server作为leader,零台或堕胎server作为follows。leader server处理一切对分区的读写请求,而follwers只需被动的同步leader上的数据。当leader宕机了,followers中的一台server会自动成为新的eader,每台server都会成为某些分区的leader和某些分区的follower,因此集群的负载是均衡的 - Consumer:消费者使用一个group(消费组)名称来表示,发布到topic中的每条记录将被分配到订阅消费组中的其中一个消费者示例。消费者实例可以分布在多个进程中或多个机器上
12.Kafka 生产者架构
基本流程:
- 主线程Producer中会经过拦截器、序列化器、分区器,然后将处理好的消息发送到消息累加器中
- 消息累加器每个分区会对应一个队列,在收到消息后,将消息放到队列中
- 使用ProducerBatch批量的进行消息发送到Sender线程处理(这里为了提高发送效率,减少带宽),ProducerBatch中就是我们需要发送的消息,其中消息累加器中可以使用Buffer.memory配置,默认为32MB
- Sender线程会从队列的队头部开始读取消息,然后创建request后会经过会被缓存,然后提交到Selector,Selector发送消息到Kafka集群。
- 对于一些还没收到Kafka集群ack响应的消息,会将未响应接收消息的请求进行缓存,当收到Kafka集群ack响应后,会将request请求在缓存中清除并同时移除消息累加器中的消息
13.Kafka 消费者架构
 基本流程:
基本流程:
- Consumer Group中的Consumer向各自注册的分区上进行消费消息
- Consumer消费消息后会将当前标注的消费位移信息以消息的方式提交到位移主题中记录,一个Consumer Group中多个Consumer会做负载均衡,如果一个Consumer宕机,会自动切换到组内别的Consumer进行消费。
- 位移主题:位移主题的主要作用是保存Kafka消费者的位移信息
14.zookeep的作用?
- 无论是broker集群,还是 producer 和 consumer ,都依赖于 Zookeeper 来保证系统可用性集群保存一些 meta 信息。
- Kafka 使用 Zookeeper 作为其分布式协调框架,可以很好地将消息生产、消息存储、消息消费的过程结合在一起。
- Kafka 借助 Zookeeper,让生产者、消费者和 broker 在内的所有组件,在无状态的情况下,建立起生产者和消费者的订阅关系,并实现生产者与消费者的负载均衡。
ZooKeeper 是 Kafka 用来负责集群元数据的管理、控制器的选举等操作的。
21年4月,Kafka 2.8.0 用自管理的Quorum代替ZooKeeper管理元数据。
15.Kafka 如何保证数据有序性?
解决方案:将需要顺序消费的消息发送的时候设置将某个topic发送到指定的partition(也可以根据key的hash与分区进行运算),则在partition中的消息也是有序的,消费的时候将一组同hash的key放到同一个queue中,保证同一个消费者下的同一个线程对此queue进行消费。
16.Kafka 如何保证数据可靠性?
生产者:
Kafka 在 Producer 里面提供了消息确认机制。也就是说我们可以通过配置来决定有几个副本收到这条消息才算消息发送成功。可以在定义 Producer 时通过 acks 参数指定。
- acks=0:生产者不会等待任何来自服务器的响应。
- acks=1(默认值):只要集群的Leader节点收到消息,生产者就会收到一个来自服务器的成功响应。
- acks=-1:只有当所有参与复制的节点全部都收到消息时,生产者才会收到一个来自服务器的成功响应。
Producer 发送消息还可以选择同步(默认,通过 producer.type=sync 配置) 或者异步(producer.type=async)模式。如果设置成异步,虽然会极大的提高消息发送的性能,但是这样会增加丢失数据的风险。如果需要确保消息的可靠性,必须将 producer.type 设置为 sync。
分区:
Kafka 可以保证单个分区里的事件是有序的,分区可以在线(可用),也可以离线(不可用)。在众多的分区副本里面有一个副本是 Leader,其余的副本是 follower,所有的读写操作都是经过 Leader 进行的,同时 follower 会定期地去 leader 上复制数据。当 Leader 挂掉之后,其中一个 follower 会重新成为新的 Leader。通过分区副本,引入了数据冗余,同时也提供了 Kafka 的数据可靠性。
Kafka 的分区多副本架构是 Kafka 可靠性保证的核心,把消息写入多个副本可以使 Kafka 在发生崩溃时仍能保证消息的持久性。
leader选举:
在介绍 Leader 选举之前,让我们先来了解一下 ISR(in-sync replicas)列表。每个分区的 leader 会维护一个 ISR 列表,ISR 列表里面就是 follower 副本的 Borker 编号,只有“跟得上” Leader 的 follower 副本才能加入到 ISR 里面,这个是通过 replica.lag.time.max.ms 参数配置的。只有 ISR 里的成员才有被选为 leader 的可能。
所以当 Leader 挂掉了,而且 unclean.leader.election.enable=false 的情况下,Kafka 会从 ISR 列表中选择第一个 follower 作为新的 Leader,因为这个分区拥有最新的已经 committed 的消息。通过这个可以保证已经 committed 的消息的数据可靠性。
综上所述,为了保证数据的可靠性,我们最少需要配置一下几个参数:
producer 级别:acks=all(或者 request.required.acks=-1),同时发生模式为同步 producer.type=sync
topic 级别:设置 replication.factor>=3,并且 min.insync.replicas>=2;
broker 级别:关闭不完全的 Leader 选举,即 unclean.leader.election.enable=false;
17.如何保证kafka数据一致性?
只有 High Water Mark 以上的消息才支持 Consumer 读取,而 High Water Mark 取决于 ISR 列表里面偏移量最小的分区,对应于上图的副本2,这个很类似于木桶原理。
这样做的原因是还没有被足够多副本复制的消息被认为是“不安全”的。
当然,引入了 High Water Mark 机制,会导致 Broker 间的消息复制因为某些原因变慢,那么消息到达消费者的时间也会随之变长(因为我们会先等待消息复制完毕)。
延迟时间可以通过参数 replica.lag.time.max.ms 参数配置,它指定了副本在复制消息时可被允许的最大延迟时间。
17.Kafka 高性能原因分析?
- 顺序写入:顺序写入与随机写入速度相差高达6000倍
- 批量处理:使用消息累加器仅多个消息批量发送,既节省带宽有提高了发送速度
- 消息压缩:kafka支持队消息压缩,支持格式有:gzip、snapply、lz4,可以使用compression.type配置
- 页缓存:在消息发送后,并没有等到消息写入磁盘后才返回,而是到页缓存page Cache中就返回。page Cache与文件系统的写入由操作系统自动完成
- 零拷贝(zero-copy):Kafka两个重要过程都使用了零拷贝技术,且都是操作系统层面的狭义零拷贝,一是Producer生产的数据存到broker,二是 Consumer从broker读取数据。
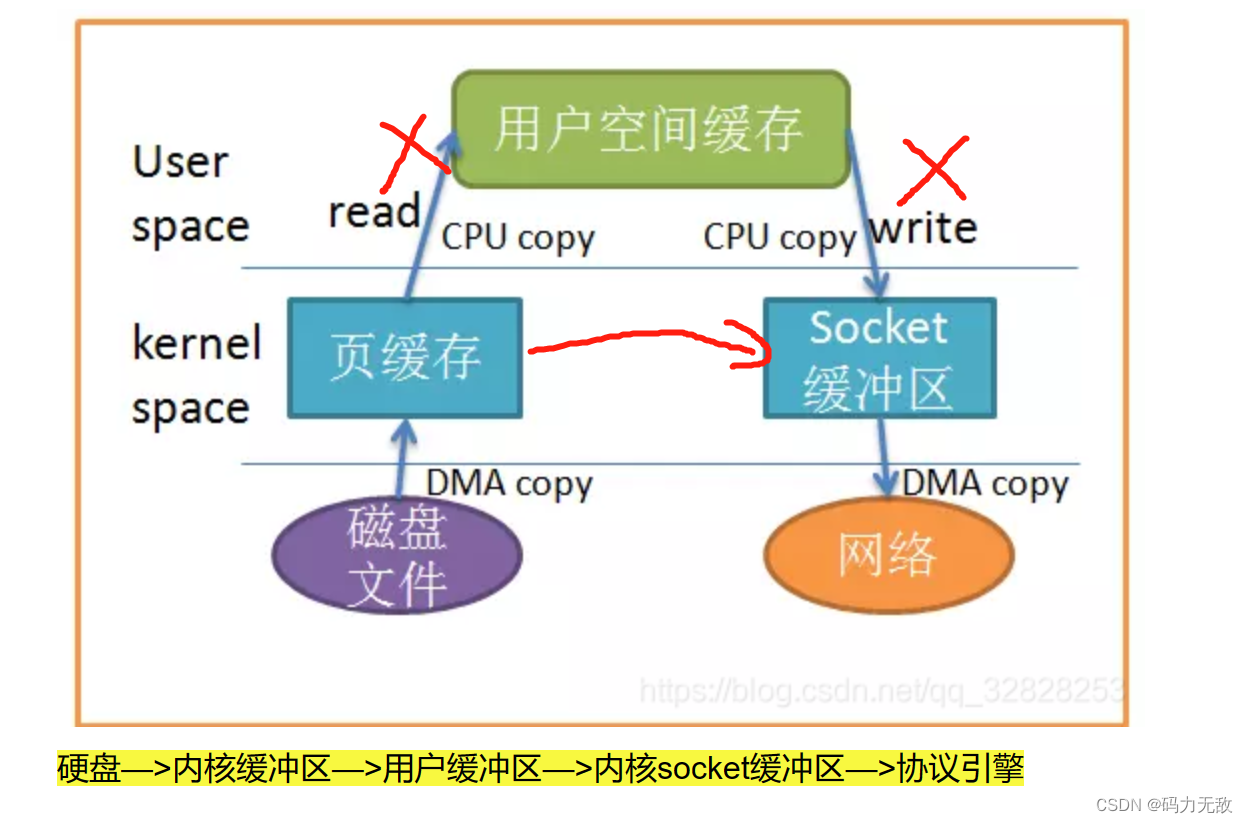
八、netty
1.netty是什么?
Netty是 一个异步事件驱动的网络应用程序框架,用于快速开发可维护的高性能协议服务器和客户端。Netty是基于nio的,它封装了jdk的nio,让我们使用起来更加方法灵活。
特点/优势:
- 高并发:Netty 是一款基于 NIO(Nonblocking IO,非阻塞IO)开发的网络通信框架,对比于 BIO(Blocking I/O,阻塞IO),他的并发性能得到了很大提高。Netty 的综合性能最优。
- 传输快:Netty 的传输依赖于零拷贝特性,尽量减少不必要的内存拷贝,实现了更高效率的传输。
- 封装好:Netty 封装了 NIO 操作的很多细节,提供了易于使用调用接口。
- 功能强大:预置了多种编解码功能,支持多种主流协议。
- 定制能力强:可以通过 ChannelHandler 对通信框架进行灵活地扩展。
- 稳定:Netty 修复了已经发现的所有 NIO 的 bug,让开发人员可以专注于业务本身。
- 社区活跃:Netty 是活跃的开源项目,版本迭代周期短,bug 修复速度快。
2. netty为什么高性能?
- IO 线程模型:多路复用,同步非阻塞,用最少的资源做更多的事。
- 内存零拷贝:尽量减少不必要的内存拷贝,实现了更高效率的传输。
- 内存池设计:申请的内存可以重用,主要指直接内存。内部实现是用一颗二叉查找树管理内存分配情况。
- 串形化处理读写:避免使用锁带来的性能开销。
- 高性能序列化协议:支持 protobuf 等高性能序列化协议。
3. BIO、NIO和AIO的区别?
- BIO:同步阻塞IO,一个连接一个线程,客户端有连接请求时服务器端就需要启动一个线程进行处理。线程开销大。伪异步IO:将请求连接放入线程池,一对多,但线程还是很宝贵的资源。保持连接,不能做别的事情。
对于BIO,1000个连接就需要5GB,在4s内,服务器内存消耗都是5GB。 - NIO:同步非阻塞IO,一个请求一个线程,但客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。不用保持一个连接,不能做其他事情。用轮询代替保持连接。
- AIO:异步非阻塞IO,不用保持连接,可以做别的事情,采用通知机制,通知机制消耗资源,还存在突然前面的事情又插过来要做了,必然引入了一个多线程的协调工作。
BIO是面向流的,NIO是面向缓冲区的;BIO的各种流是阻塞的。而NIO是非阻塞的;BIO的Stream是单向的,而NIO的channel是双向的。
NIO的特点:事件驱动模型、单线程处理多任务、非阻塞I/O,I/O读写不再阻塞,而是返回0、基于block的传输比基于流的传输更高效、更高级的IO函数zero-copy、IO多路复用大大提高了Java网络应用的可伸缩性和实用性。基于Reactor线程模型。
4.NIO的组成?
- Buffer:与Channel进行交互,数据是从Channel读入缓冲区,从缓冲区写入Channel中的,DirectByteBuffer可减少一次系统空间到用户空间的拷贝。
- Channel:表示 IO 源与目标打开的连接,是双向的,但不能直接访问数据,只能与Buffer 进行交互。
- Selector:可使一个单独的线程管理多个Channel,open方法可创建Selector,register方法向多路复用器器注册通道,可以监听的事件类型:读、写、连接、accept。注册事件后会产生一个SelectionKey:它表示SelectableChannel 和Selector 之间的注册关系
NIO的服务端建立过程:
- Selector.open():打开一个Selector;
- ServerSocketChannel.open():创建服务端的Channel;
- bind():绑定到某个端口上。并配置非阻塞模式;
- register():注册Channel和关注的事件到Selector上;
- select()轮询拿到已经就绪的事件。
5.IO多路复用的三种技术?select,poll,epoll
目前支持I/O多路复用的系统调用有select,pselect,poll,epoll。与多进程和多线程技术相比,I/O多路复用技术的最大优势是系统开销小,系统不必创建进程/线程,也不必维护这些进程/线程,从而大大减小了系统的开销。
I/O多路复用就是一种通知机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间
- select:会将需要监控的readfds集合拷贝到内核空间,不断轮询所有文件数据fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。select和poll在“醒着”的时候要遍历整个fd集合。
- poll:poll改变了fds集合的描述方式,使用了pollfd结构而不是select的fd_set结构,使得poll支持的fds集合限制远大于select的1024。poll虽然解决了fds集合大小1024的限制问题,从实现来看。很明显它并没优化大量描述符数组被整体复制于用户态和内核态的地址空间之间,以及个别描述符就绪触发整体描述符集合的遍历的低效问题。poll随着监控的socket集合的增加性能线性下降,使得poll也并不适合用于大并发场景。
- epoll:其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,不需要遍历整个fd集合。这节省了大量的CPU时间。这就是回调机制带来的性能提升。
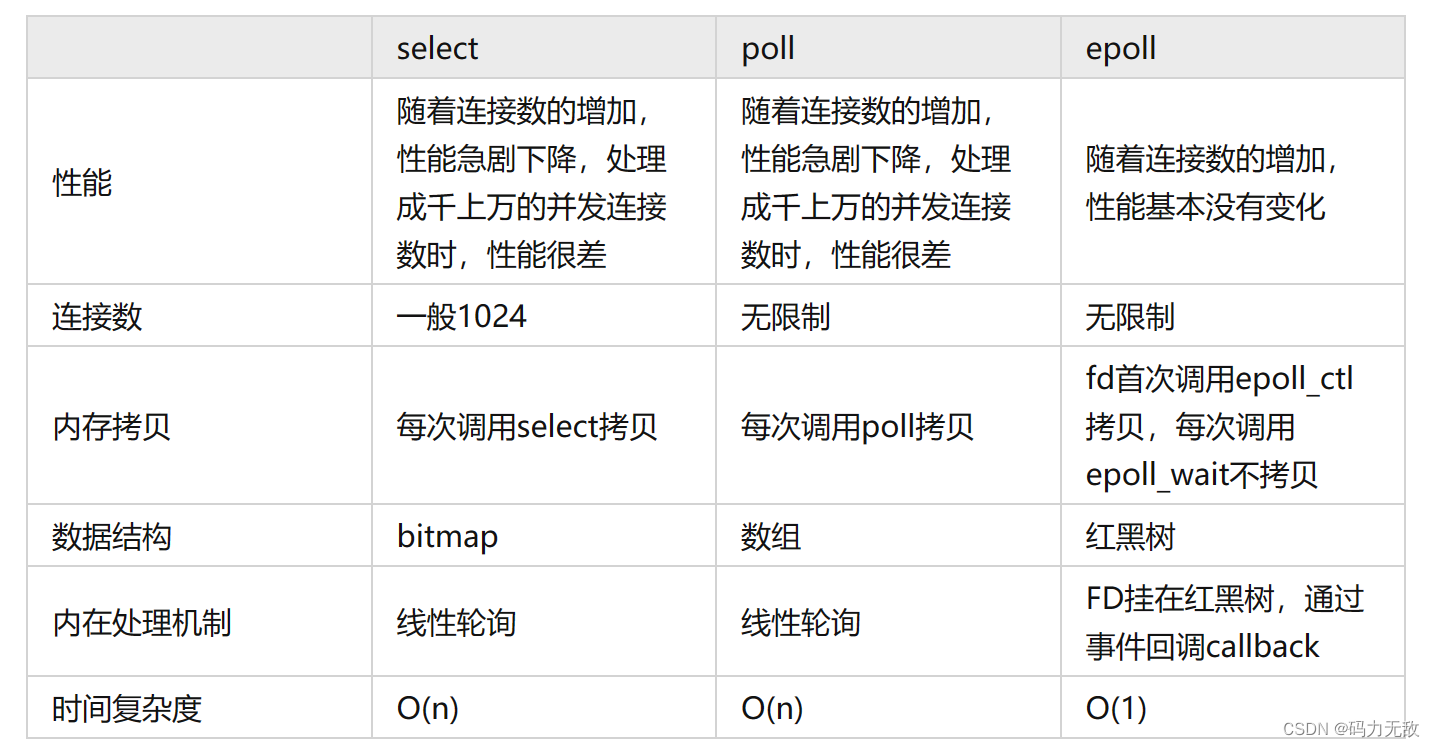
6.Netty的线程模型?
Netty通过Reactor模型基于多路复用器接收并处理用户请求,内部实现了两个线程池,boss线程池和work线程池,
- boss线程池:线程负责处理请求的accept事件,当接收到accept事件的请求时,把对应的socket封装到一个NioSocketChannel中,并交给work线程池,
- work线程池:负责请求的read和write事件,由对应的Handler处理。
Reactor模型有3个变种:单Reactor单线程,单Reactor多线程,主从Reactor多线程。
单线程模型:所有I/O操作都由一个线程完成,即多路复用、事件分发和处理都是在一个Reactor线程上完成的。既要接收客户端的连接请求,向服务端发起连接,又要发送/读取请求或应答/响应消息。一个NIO 线程同时处理成百上千的链路,性能上无法支撑,速度慢,若线程进入死循环,整个程序不可用,对于高负载、大并发的应用场景不合适。
多线程模型:有一个NIO 线程(Acceptor) 只负责监听服务端,接收客户端的TCP 连接请求;NIO 线程池负责网络IO 的操作,即消息的读取、解码、编码和发送;1 个NIO 线程可以同时处理N 条链路,但是1 个链路只对应1 个NIO 线程,这是为了防止发生并发操作问题。但在并发百万客户端连接或需要安全认证时,一个Acceptor 线程可能会存在性能不足问题。
主从多线程模型:Acceptor 线程用于绑定监听端口,接收客户端连接,将SocketChannel 从主线程池的Reactor 线程的多路复用器上移除,重新注册到Sub 线程池的线程上,用于处理I/O 的读写等操作,从而保证mainReactor只负责接入认证、握手等操作;**
7. 什么是netty的0拷贝?
- Netty 的接收和发送 ByteBuffer 采用 DIRECT BUFFERS,使用堆外直接内存进行 Socket 读写,不需要进行字节缓冲区的二次拷贝。如果使用传统的堆内存(HEAP BUFFERS)进行 Socket 读写,JVM 会将堆内存 Buffer 拷贝一份到直接内存中,然后才写入 Socket 中。相比于堆外直接内存,消息在发送过程中多了一次缓冲区的内存拷贝。
- Netty 提供了组合buffer对象 CompositeByteBuf 类,它可以将多个 ByteBuf 合并为一个逻辑上的 ByteBuf,避免了各个 ByteBuf 之间的拷贝。
- Netty 的文件传输采用了 transferTo 方法,它可以直接将文件缓冲区的数据发送到目标 Channel,避免了传统通过循环 write 方式导致的内存拷贝问题。
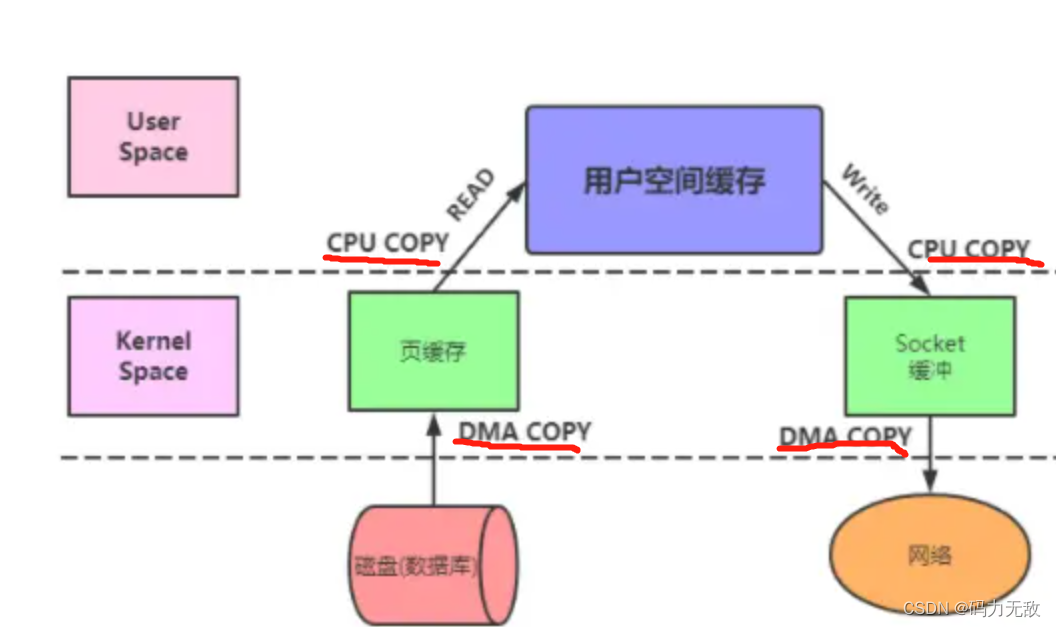
8.Netty 中有哪种重要组件?
- Channel:Netty 网络操作抽象类,它除了包括基本的 I/O 操作,如 bind、connect、read、write 等。
- EventLoop:主要是配合 Channel 处理 I/O 操作,用来处理连接的生命周期中所发生的事情。
- ChannelFuture:Netty 框架中所有的 I/O 操作都为异步的,因此我们需要 ChannelFuture 的 addListener()注册一个 ChannelFutureListener 监听事件,当操作执行成功或者失败时,监听就会自动触发返回结果。
- ChannelHandler:充当了所有处理入站和出站数据的逻辑容器。ChannelHandler 主要用来处理各种事件,这里的事件很广泛,比如可以是连接、数据接收、异常、数据转换等。
- ChannelPipeline:为 ChannelHandler 链提供了容器,当 channel 创建时,就会被自动分配到它专属的 ChannelPipeline,这个关联是永久性的。
9.Netty线程模型?
Netty主要基于主从Reactors多线程模型(如下图)做了一定的修改,其中主从Reactor多线程模型有多个Reactor:MainReactor和SubReactor:
- MainReactor负责客户端的连接请求,并将请求转交给SubReactor
- SubReactor负责相应通道的IO读写请求
- 非IO请求(具体逻辑处理)的任务则会直接写入队列,等待worker threads进行处。
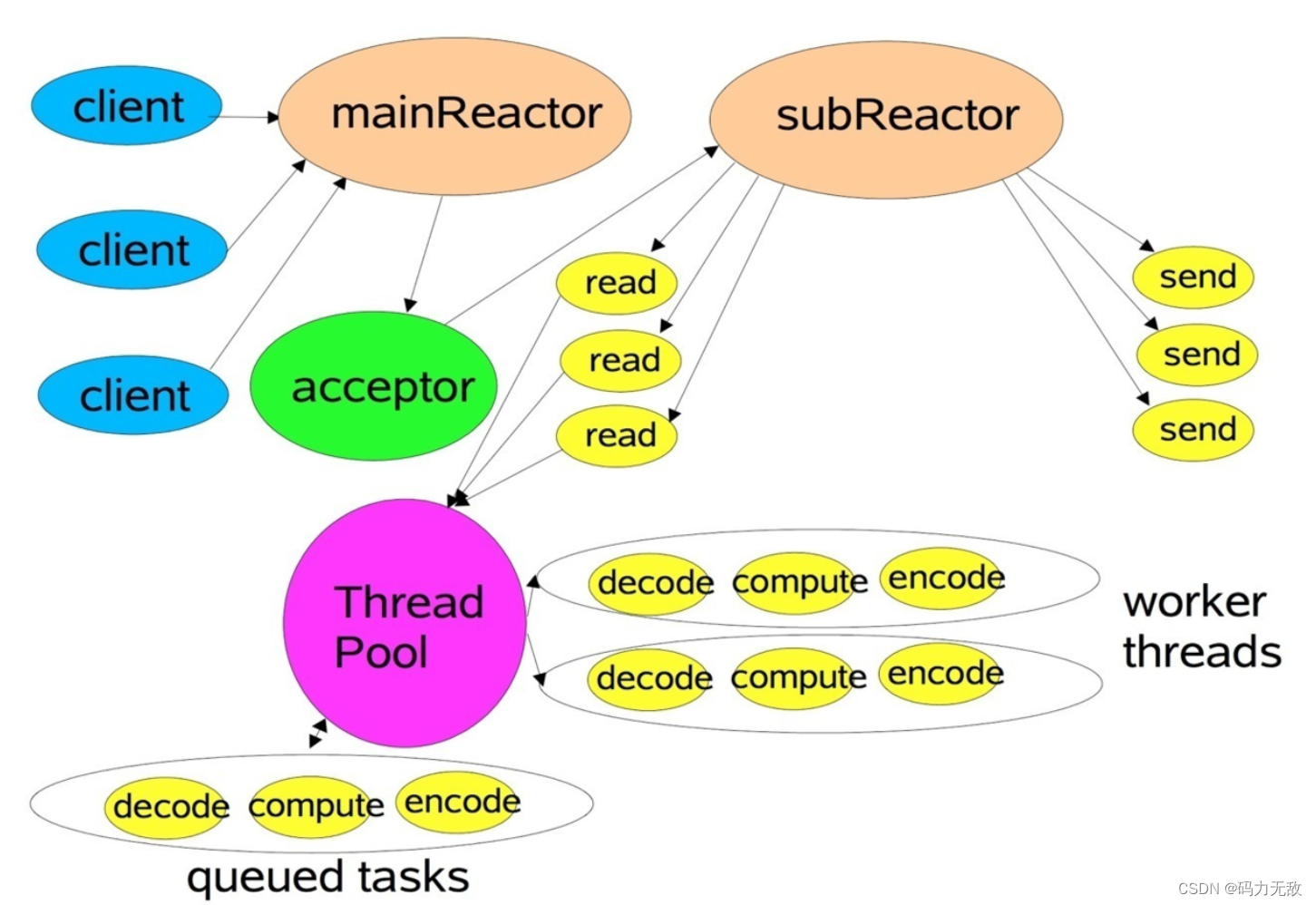
Netty中的I/O操作是异步的,包括bind、write、connect等操作会简单的返回一个ChannelFuture,调用者并不能立刻获得结果,通过Future-Listener机制,用户可以方便的主动获取或者通过通知机制获得IO操作结果。
当future对象刚刚创建时,处于非完成状态,调用者可以通过返回的ChannelFuture来获取操作执行的状态,注册监听函数来执行完成后的操,常见有如下操作:
通过isDone方法来判断当前操作是否完成
通过isSuccess方法来判断已完成的当前操作是否成功
通过getCause方法来获取已完成的当前操作失败的原因
通过isCancelled方法来判断已完成的当前操作是否被取消
通过addListener方法来注册监听器,当操作已完成(isDone方法返回完成),将会通知指定的监听器;如果future对象已完成,则理解通知指定的监听器。
相比传统阻塞I/O,执行I/O操作后线程会被阻塞住, 直到操作完成;异步处理的好处是不会造成线程阻塞,线程在I/O操作期间可以执行别的程序,在高并发情形下会更稳定和更高的吞吐量。
10.netty的架构设计?
模块组件:
- Bootstrap、ServerBootstrap:一个Netty应用通常由一个Bootstrap开始,主要作用是配置整个Netty程序,串联各个组件,Netty中Bootstrap类是客户端程序的启动引导类,ServerBootstrap是服务端启动引导类。
- Future、ChannelFuture:
Netty中所有的IO操作都是异步的,通过Future和ChannelFutures,他们可以注册一个监听事件,当操作执行成功或失败时监听会自动触发监听事件。 - Channel:Netty网络通信的组件,能够用于执行网络I/O操作。 Channel为用户提供:当前网络连接的通道的状态、网络连接的配置参数 、提供异步的网络I/O操作(如建立连接,读写,绑定端口)、支持关联I/O操作与对应的处理程序。
- Selector:Netty基于Selector对象实现I/O多路复用,通过 Selector, 一个线程可以监听多个连接的Channel事件, 当向一个Selector中注册Channel 后,Selector 内部的机制就可以自动轮询这些注册的Channel,是否有已就绪的I/O事件(例如可读, 可写, 网络连接完成等),这样程序就可以很简单地使用一个线程高效地管理多个 Channel 。
- NioEventLoop:NioEventLoop中维护了一个线程和任务队列,支持异步提交执行任务,线程启动时会调用NioEventLoop的run方法,执行I/O任务和非I/O任务:每个线程(NioEventLoop)负责处理多个Channel上的事件
-
- I/O任务:即selectionKey中ready的事件,如accept、connect、read、write等,由processSelectedKeys方法触发。
-
- 非IO任务:添加到taskQueue中的任务,如register0、bind0等任务,由runAllTasks方法触发。
- NioEventLoopGroup:NioEventLoopGroup,主要管理eventLoop的生命周期,可以理解为一个线程池,
- ChannelHandler:ChannelHandler是一个接口,处理I / O事件或拦截I / O操作,并将其转发到其ChannelPipeline(业务处理链)中的下一个处理程序。
- ChannelHandlerContext:保存Channel相关的所有Context上下文信息,同时关联一个ChannelHandler对象
- ChannelPipline:保存ChannelHandler的List,用于处理或拦截Channel的入站事件和出站操作
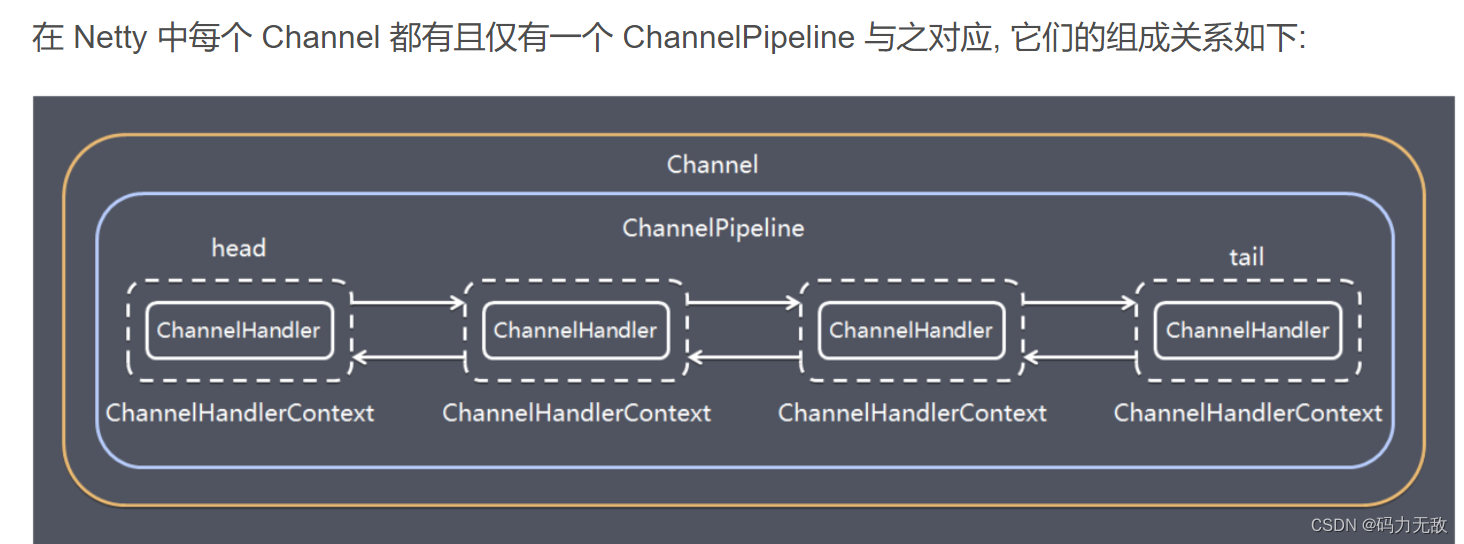
一个 Channel 包含了一个 ChannelPipeline, 而 ChannelPipeline 中又维护了一个由 ChannelHandlerContext 组成的双向链表,先进先出。并且每个 ChannelHandlerContext 中又关联着一个 ChannelHandler。
11.netty工作原理。
- 初始化创建2个NioEventLoopGroup,其中boosGroup用于Accetpt连接建立事件并分发请求, workerGroup用于处理I/O读写事件和业务逻辑
- 基于ServerBootstrap(服务端启动引导类),配置EventLoopGroup、Channel类型,连接参数、配置入站、出站事件handler
- 绑定端口,开始工作。
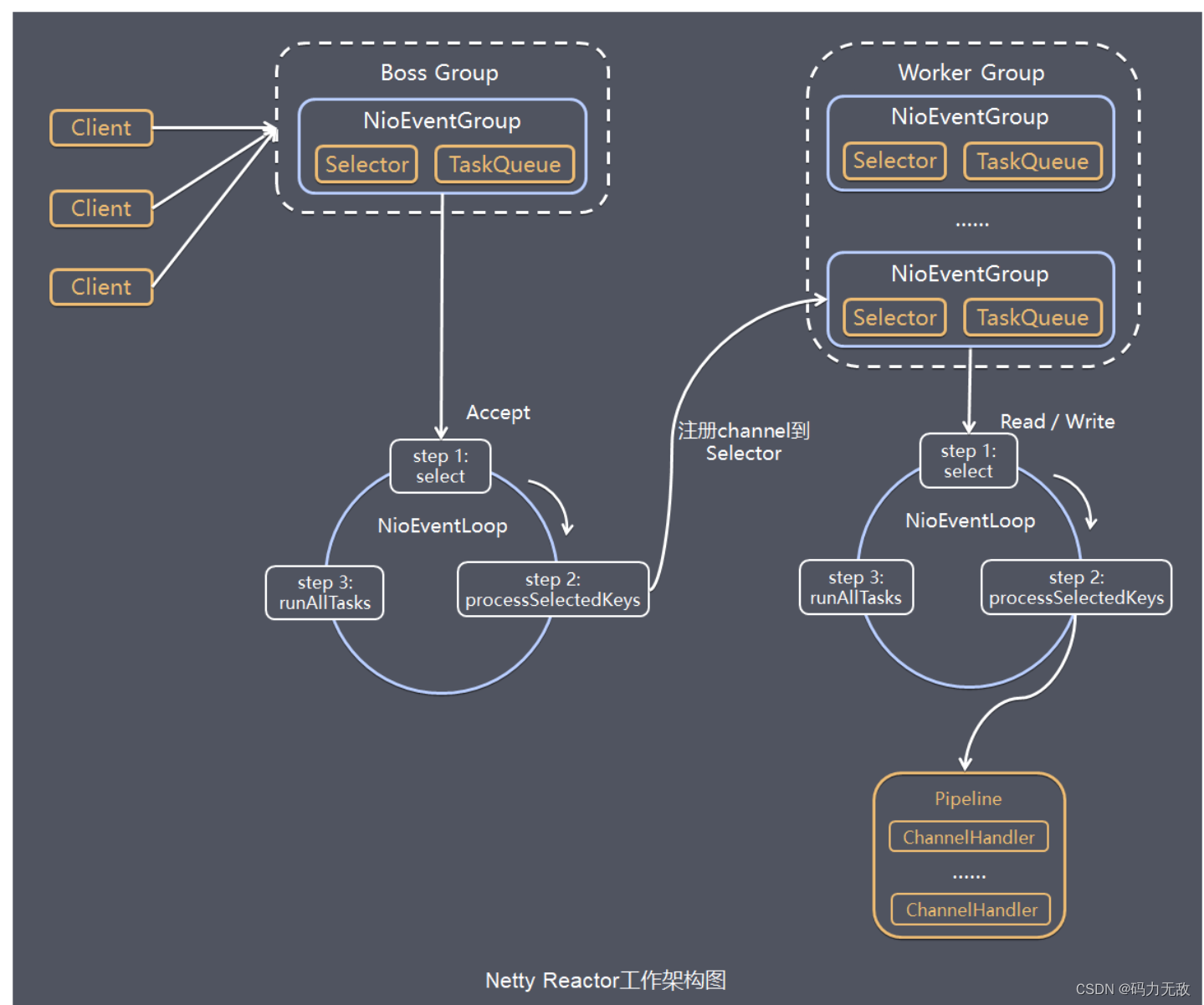
每个Boss NioEventLoop循环执行的任务包含3步:
- 1 轮询accept事件
- 2 处理accept I/O事件,与Client建立连接,生成NioSocketChannel,并将NioSocketChannel注册到某个Worker NioEventLoop的Selector上
- 3 处理任务队列中的任务,runAllTasks。任务队列中的任务包括用户调用eventloop.execute或schedule执行的任务,或者其它线程提交到该eventloop的任务。
每个Worker NioEventLoop循环执行的任务包含3步:
- 1 轮询read、write事件;
- 2 处I/O事件,即read、write事件,在NioSocketChannel可读、可写事件发生时进行处理
- 3 处理任务队列中的任务,runAllTasks。
常见的连接参数
TCP_NODELAY:尽可能发送大块数据
SO_SNDBUF:是操作系统内核的写缓冲区
SO_RECBUF:是操作系统内核的读缓冲区
SO_BACKLOG:用于构造服务端套接字ServerSocket对象,标识当服务器请求处理线程全满时,用于临时存放已完成三次握手的请求的队列(accept 全连接队列)的最大长度。若队列满则连接拒绝。
SO_TIMEOUT、SO_KEEPALIVE
12.Netty解决半包(TCP粘包/拆包导致)读写问题?
一般TCP粘包/拆包解决办法
- 定长消息,例如每个报文长度固定,不够补空格
- 使用回车换行符分割,在包尾加上分割符,例如Http协议
- 消息分割,头为长度(消息总长度或消息体长度),通常头用一个int32表示
- 复杂的应用层协议
HTTP协议主要包含三部分:请求行(line),请求头(header),请求正文(body)
-
请求行(Line):主要包含三部分:Method ,URI ,协议/版本。 各部分之间使用空格(SP)分割。整个请求头使用CRLF分割。(比如:POST /1.0.0/_health_check HTTP/1.1 CRLF),如果读取到CRLF,则意味着请求行的信息已经读取完成。
-
请求头(Header): 格式为(name :value),用于客户端请求的描述信息。header之间以CRLF进行分割。最后一个header会多加一个CRLF。( 比如:Connection: keep-alive CRLF CRLF),如果连续读取两个CRLF,则意味着header的信息读取完成。
-
请求正文(body) :里面主要是Post提交的数据(可支持多种格式,格式在Content-Type定义,长度是在Content-Length里面定义)。
HTTP协议通常使用Content-Length来标识body的长度,在服务器端,需要先申请对应长度的buffer,然后再赋值。如果需要一边生产数据一边发送数据,就需要使用"Transfer-Encoding: chunked" 来代替Content-Length,也就是对数据进行分块传输。
九、mysql
1.数据库三大范式是什么?
第一范式:每个列都不可以再拆分。
第二范式:在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。
第三范式:在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。
在设计数据库结构的时候,要尽量遵守三范式,如果不遵守,必须有足够的理由。比如性能。事实上我们经常会为了性能而妥协数据库的设计。
2.MySQL的binlog有几种类型和模式 ?分别有什么区别?
有三种模式 ,statement,row和mixed。
- statement模式下,每一条会修改数据的sql都会记录在binlog中。不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能。由于sql的执行是有上下文的,因此在保存的时候需要保存相关的信息,同时还有一些使用了函数之类的语句无法被记录复制。
- row级别下,不记录sql语句上下文相关信息,仅保存哪条记录被修改。记录单元为每一行的改动,基本是可以全部记下来但是由于很多操作,会导致大量行的改动(比如alter table),因此这种模式的文件保存的信息太多,日志量太大。新版的MySQL中对row级别也做了一些优化,当表结构发生变化的时候,会记录语句而不是逐行记录。
- mixed,一种折中的方案,普通操作使用statement记录,当无法使用statement的时候使用row。
mysql的主从复制原理是使用binlog进行复制。
3.引擎
3.1 常用的存储引擎有以下:
- Innodb引擎:Innodb引擎提供了对数据库ACID事务的支持。并且还提供了行级锁和外键的约束。它的设计的目标就是处理大数据容量的数据库系统。
- MyIASM引擎(原本Mysql的默认引擎):不提供事务的支持,也不支持行级锁和外键。
- MEMORY引擎:所有的数据都在内存中,数据的处理速度快,但是安全性不高。
3.2 MyISAM索引与InnoDB索引的区别?
- InnoDB索引是聚簇索引,MyISAM索引是非聚簇索引。
- InnoDB的主键索引的叶子节点存储着行数据,因此主键索引非常高效。
- MyISAM索引的叶子节点存储的是行数据地址,需要再寻址一次才能得到数据。
- InnoDB非主键索引的叶子节点存储的是主键和其他带索引的列数据,因此查询时做到覆盖索引会非常高效。
4.索引使用场景
- where,查询条件触发索引;
- order by: 当我们使用order by将查询结果按照某个字段排序时,如果该字段没有建立索引,那么执行计划会将查询出的所有数据使用外部排序(将数据从硬盘分批读取到内存使用内部排序,最后合并排序结果),这个操作是很影响性能的,因为需要将查询涉及到的所有数据从磁盘中读到内存(如果单条数据过大或者数据量过多都会降低效率),更无论读到内存之后的排序了。
- join.对join语句匹配关系(on)涉及的字段建立索引能够提高效率.
- 索引覆盖.
如果要查询的字段都建立过索引,那么引擎会直接在索引表中查询而不会访问原始数据(否则只要有一个字段没有建立索引就会做全表扫描),这叫索引覆盖。因此我们需要尽可能的在select后只写必要的查询字段,以增加索引覆盖的几率。
5.索引有哪几种类型?
- 主键索引: 数据列不允许重复,不允许为NULL,一个表只能有一个主键。
- 唯一索引: 数据列不允许重复,允许为NULL值,一个表允许多个列创建唯一索引。
1.可以通过 ALTER TABLE table_name ADD UNIQUE (column); 创建唯一索引
2.可以通过 ALTER TABLE table_name ADD UNIQUE (column1,column2); 创建唯一组合索引 - 普通索引: 基本的索引类型,没有唯一性的限制,允许为NULL值。
1.可以通过ALTER TABLE table_name ADD INDEX index_name (column);创建普通索引
2.可以通过ALTER TABLE table_name ADD INDEX index_name(column1, column2, column3);创建组合索引 - 全文索引: 是目前搜索引擎使用的一种关键技术。
可以通过ALTER TABLE table_name ADD FULLTEXT (column);创建全文索引
6.索引的数据结构(b树,hash)
索引的数据结构和具体存储引擎的实现有关,在MySQL中使用较多的索引有Hash索引,B+树索引等,而我们经常使用的InnoDB存储引擎的默认索引实现为:B+树索引。
对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;
其余大部分场景,建议选择BTree索引。
InnoDB的索引类型目前只有两种:BTREE(B树)索引和HASH索引。
B树索引是Mysql数据库中使用最频繁的索引类型,基本所有存储引擎都支持BTree索引。通常我们说的索引不出意外指的就是(B树)索引(实际是用B+树实现的,因为在查看表索引时,mysql一律打印BTREE,所以简称为B树索引)
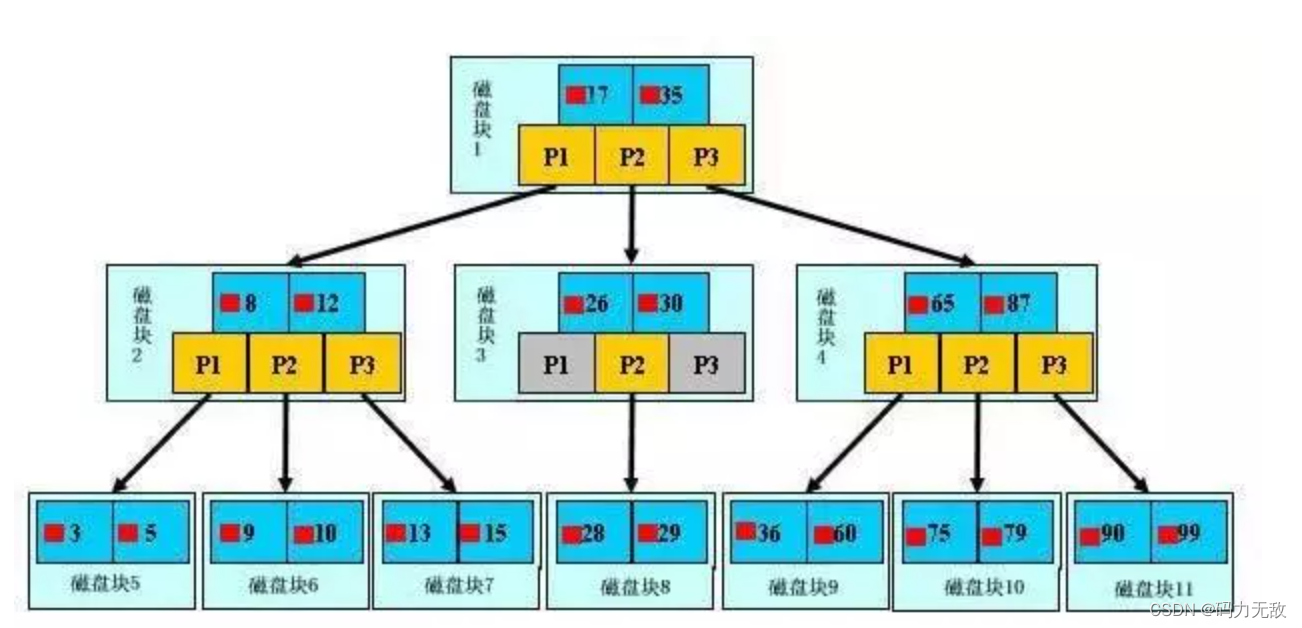
查询方式:
主键索引区:PI(关联保存的时数据的地址)按主键查询,
普通索引区:si(关联的id的地址,然后再到达上面的地址)。所以按主键查询,速度最快
B+tree性质:
1.)n棵子tree的节点包含n个关键字,不用来保存数据而是保存数据的索引。
2.)所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.)所有的非终端结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字。
4.)B+ 树中,数据对象的插入和删除仅在叶节点上进行。
5.)B+树2个头指针,一个是树的根节点,一个是最小关键码的叶节点。
2)哈希索引
简要说下,类似于数据结构中简单实现的HASH表(散列表)一样,当我们在mysql中用哈希索引时,主要就是通过Hash算法(常见的Hash算法有直接定址法、平方取中法、折叠法、除数取余法、随机数法),将数据库字段数据转换成定长的Hash值,与这条数据的行指针一并存入Hash表的对应位置;如果发生Hash碰撞(两个不同关键字的Hash值相同),则在对应Hash键下以链表形式存储。当然这只是简略模拟图。
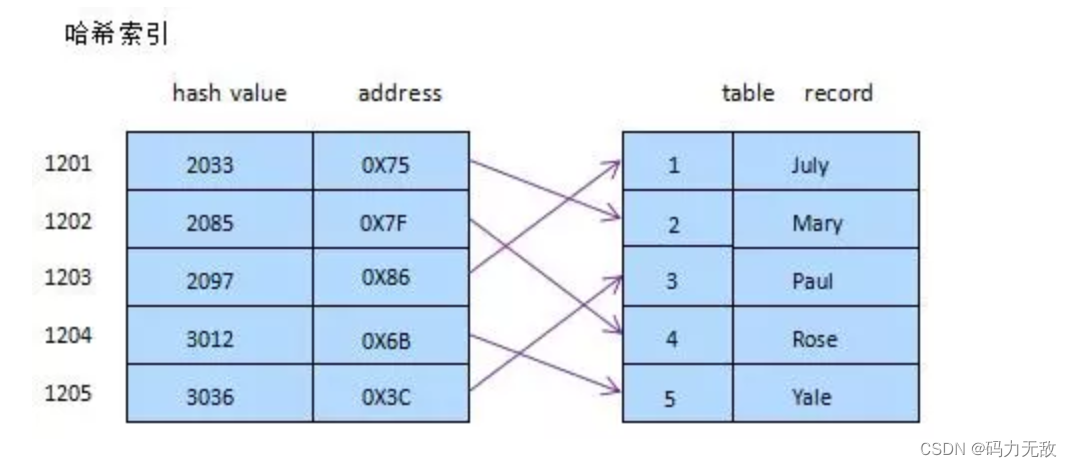
7.索引设计的原则?
- 适合索引的列是出现在where子句中的列,或者连接子句中指定的列
- 基数较小的类,索引效果较差,没有必要在此列建立索引
- 使用短索引,如果对长字符串列进行索引,应该指定一个前缀长度,这样能够节省大量索引空间
- 不要过度索引。索引需要额外的磁盘空间,并降低写操作的性能。在修改表内容的时候,索引会进行更新甚至重构,索引列越多,这个时间就会越长。所以只保持需要的索引有利于查询即可。
8.创建索引的原则(重中之重)
1) 最左前缀匹配原则,组合索引非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2)查询频繁的字段才去创建索引,更新频繁字段不适合创建索引.
3)散列度很低的列,不适合做索引列(如性别,男女未知,最多也就三种,区分度实在太低)
4)尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
5)定义有外键的数据列一定要建立索引。
6)对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。
7)对于定义为text、image和bit的数据类型的列不要建立索引。
9.百万级别或以上的数据如何删除
- 所以我们想要删除百万数据的时候可以先删除索引(此时大概耗时三分多钟)
- 然后删除其中无用数据(此过程需要不到两分钟)
- 删除完成后重新创建索引(此时数据较少了)创建索引也非常快,约十分钟左右。
- 与之前的直接删除绝对是要快速很多,更别说万一删除中断,一切删除会回滚。那更是坑了。
10.什么是最左前缀原则?什么是最左匹配原则?
顾名思义,就是最左优先,在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。
- 最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
- =和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
11.B树和B+树的区别
- 在B树中,你可以将键和值存放在内部节点和叶子节点;但在B+树中,内部节点都是键,没有值,叶子节点同时存放键和值。
- B+树的叶子节点有一条链相连,而B树的叶子节点各自独立。
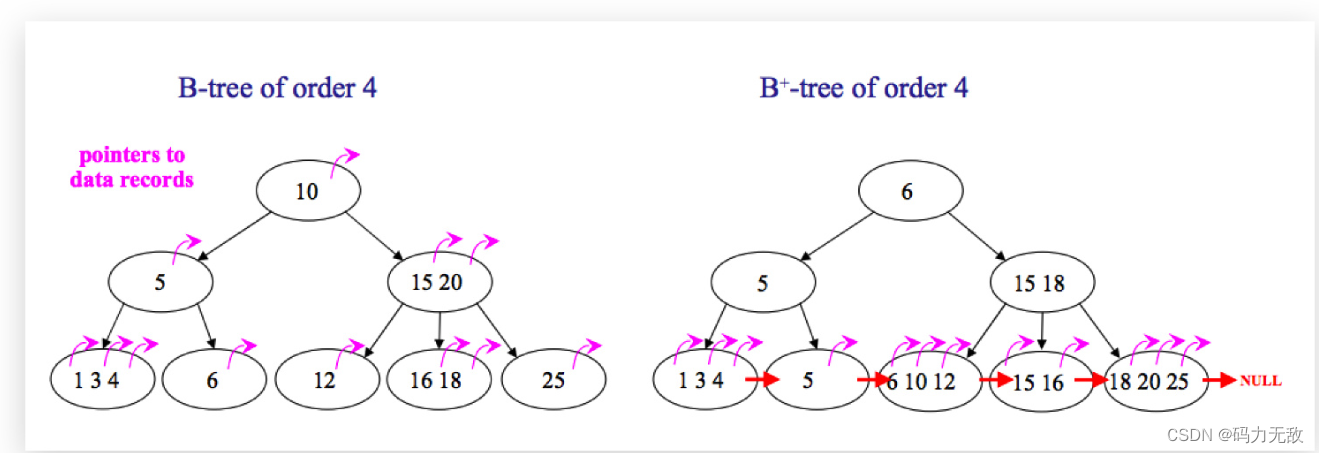
B树的好处?
B树可以在内部节点同时存储键和值,因此,把频繁访问的数据放在靠近根节点的地方将会大大提高热点数据的查询效率。这种特性使得B树在特定数据重复多次查询的场景中更加高效。
使用B+树的好处
由于B+树的内部节点只存放键,不存放值,因此,一次读取,可以在内存页中获取更多的键,有利于更快地缩小查找范围。 B+树的叶节点由一条链相连,因此,当需要进行一次全数据遍历的时候,B+树只需要使用O(logN)时间找到最小的一个节点,然后通过链进行O(N)的顺序遍历即可。而B树则需要对树的每一层进行遍历,这会需要更多的内存置换次数,因此也就需要花费更多的时间。
10.数据库为什么使用B+树而不是B树?
- B树只适合随机检索,而B+树同时支持随机检索和顺序检索;
- B+树空间利用率更高,可减少I/O次数,磁盘读写代价更低。一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗。B+树的内部结点并没有指向关键字具体信息的指针,只是作为索引使用,其内部结点比B树小,盘块能容纳的结点中关键字数量更多,一次性读入内存中可以查找的关键字也就越多,相对的,IO读写次数也就降低了。而IO读写次数是影响索引检索效率的最大因素;
- B+树的查询效率更加稳定。B树搜索有可能会在非叶子结点结束,越靠近根节点的记录查找时间越短,只要找到关键字即可确定记录的存在,其性能等价于在关键字全集内做一次二分查找。而在B+树中,顺序检索比较明显,随机检索时,任何关键字的查找都必须走一条从根节点到叶节点的路,所有关键字的查找路径长度相同,导致每一个关键字的查询效率相当。
- B-树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。B+树的叶子节点使用指针顺序连接在一起,只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作。
- 增删文件(节点)时,效率更高。因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率。
11.B+树在满足聚簇索引和覆盖索引的时候不需要回表查询数据?
在B+树的索引中,叶子节点可能存储了当前的key值,也可能存储了当前的key值以及整行的数据,这就是聚簇索引和非聚簇索引。 在InnoDB中,只有主键索引是聚簇索引,如果没有主键,则挑选一个唯一键建立聚簇索引。如果没有唯一键,则隐式的生成一个键来建立聚簇索引。
当查询使用聚簇索引时,在对应的叶子节点,可以获取到整行数据,因此不用再次进行回表查询。
12.什么是聚簇索引?何时使用聚簇索引与非聚簇索引?
- 聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
- 非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,myisam通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因。
澄清一个概念:innodb中,在聚簇索引之上创建的索引称之为辅助索引,辅助索引访问数据总是需要二次查找,非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引,辅助索引叶子节点存储的不再是行的物理位置,而是主键值。
13.联合索引是什么?为什么需要注意联合索引中的顺序?
MySQL可以使用多个字段同时建立一个索引,叫做联合索引。在联合索引中,如果想要命中索引,需要按照建立索引时的字段顺序挨个使用,否则无法命中索引。
具体原因为:
MySQL使用索引时需要索引有序,假设现在建立了"name,age,school"的联合索引,那么索引的排序为: 先按照name排序,如果name相同,则按照age排序,如果age的值也相等,则按照school进行排序。
当进行查询时,此时索引仅仅按照name严格有序,因此必须首先使用name字段进行等值查询,之后对于匹配到的列而言,其按照age字段严格有序,此时可以使用age字段用做索引查找,以此类推。
因此在建立联合索引的时候应该注意索引列的顺序,一般情况下,将查询需求频繁或者字段选择性高的列放在前面。此外可以根据特例的查询或者表结构进行单独的调整。
14.什么是数据库事务?
事务是逻辑上的一组操作,要么都执行,要么都不执行。
事物的四大特性(ACID)介绍一下?
- 原子性: 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
- 一致性: 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
- 隔离性: 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
- 持久性: 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
15.什么是脏读?幻读?不可重复读?
- 脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
- 不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
- 幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。数据变多。
16.什么是事务的隔离级别?MySQL的默认隔离级别是什么?
为了达到事务的四大特性,数据库定义了4种不同的事务隔离级别,由低到高依次为Read uncommitted、Read committed、Repeatable read、Serializable,这四个级别可以逐个解决脏读、不可重复读、幻读这几类问题。
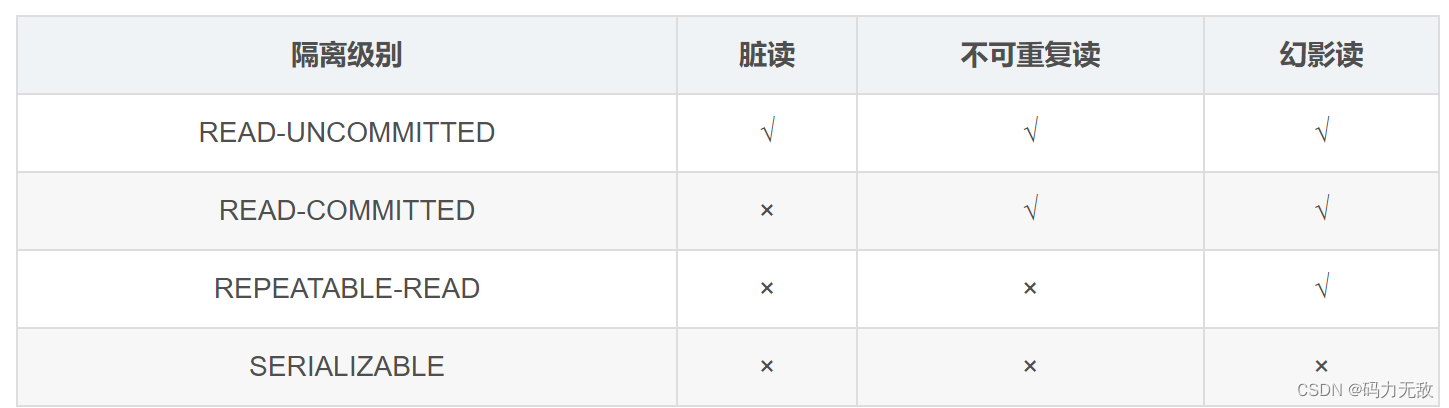
SQL 标准定义了四个隔离级别:
- READ-UNCOMMITTED(读取未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、不可重复读、幻读。
- READ-COMMITTED(读取已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是不可重复读和幻读仍有可能发生。
- REPEATABLE-READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- SERIALIZABLE(可串行化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
Mysql 默认采用的 REPEATABLE_READ
17.锁
1.隔离级别与锁的关系
- 在Read Uncommitted级别下,读取数据不需要加共享锁,这样就不会跟被修改的数据上的排他锁冲突
- 在Read Committed级别下,读操作需要加共享锁,但是在语句执行完以后释放共享锁;
- 在Repeatable Read级别下,读操作需要加共享锁,但是在事务提交之前并不释放共享锁,也就是必须等待事务执行完毕以后才释放共享锁。
- SERIALIZABLE 是限制性最强的隔离级别,因为该级别锁定整个范围的键,并一直持有锁,直到事务完成。
2.按照锁的粒度分数据库锁有哪些?锁机制与InnoDB锁算法
在关系型数据库中,可以按照锁的粒度把数据库锁分为行级锁(INNODB引擎)、表级锁(MYISAM引擎)和页级锁(BDB引擎 )。
MyISAM和InnoDB存储引擎使用的锁:
-MyISAM采用表级锁(table-level locking)。
InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁
行级锁,表级锁和页级锁对比
-
行级锁 行级锁是Mysql中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突。其加锁粒度最小,但加锁的开销也最大。行级锁分为共享锁 和 排他锁。
特点:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。 -
表级锁 表级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分MySQL引擎支持。最常使用的MYISAM与INNODB都支持表级锁定。表级锁定分为表共享读锁(共享锁)与表独占写锁(排他锁)。
特点:开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。 -
页级锁 页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。
特点:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
3.从锁的类别上分MySQL都有哪些锁呢?像上面那样子进行锁定岂不是有点阻碍并发效率了
从锁的类别上来讲,有共享锁和排他锁。
- 共享锁: 又叫做读锁。 当用户要进行数据的读取时,对数据加上共享锁。共享锁可以同时加上多个。
- 排他锁: 又叫做写锁。 当用户要进行数据的写入时,对数据加上排他锁。排他锁只可以加一个,他和其他的排他锁,共享锁都相斥。
锁的粒度取决于具体的存储引擎,InnoDB实现了行级锁,页级锁,表级锁。他们的加锁开销从大到小,并发能力也是从大到小。
4.MySQL中InnoDB引擎的行锁是怎么实现的?
InnoDB是基于索引来完成行锁,
select * from tab_with_index where id = 1 for update;
for update 可以根据条件来完成行锁锁定,并且 id 是有索引键的列,如果 id 不是索引键那么InnoDB将完成表锁,并发将无从谈起
5. InnoDB存储引擎的锁的算法有三种
- Record lock:单个行记录上的锁
- Gap lock:间隙锁,锁定一个范围,不包括记录本身,Gap锁设计的目的是为了阻止多个事务将记录插入到同一范围内,而这会导致幻读问题的产生。
- Next-key lock:record+gap 锁定一个范围,包含记录本身。对于行的查询使用next-key lock,了解决幻读问题。当查询的索引含有唯一属性时,将next-key lock降级为record key。
6.什么是死锁?如何解决?
死锁是指两个或多个事务在同一资源上相互占用,并请求锁定对方的资源,从而导致恶性循环的现象。
常见的解决死锁的方法
1、如果不同程序会并发存取多个表,尽量约定以相同的顺序访问表,可以大大降低死锁机会。
2、在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率;
3、对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁定来减少死锁产生的概率;
如果业务处理不好可以用分布式事务锁或者使用乐观锁
7.数据库的乐观锁和悲观锁是什么?怎么实现的?
- 悲观锁:假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。在查询完数据的时候就把事务锁起来,直到提交事务。实现方式:使用数据库中的锁机制。
- 乐观锁:假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性。在修改数据的时候把事务锁起来,通过version的方式来进行锁定。实现方式:乐一般会使用版本号机制或CAS算法实现。
18.varchar与char的区别
char的特点
- char表示定长字符串,长度是固定的;
- 如果插入数据的长度小于char的固定长度时,则用空格填充;
- 因为长度固定,所以存取速度要比varchar快很多,甚至能快50%,但正因为其长度固定,所以会占据多余的空间,是空间换时间的做法;
- 对于char来说,最多能存放的字符个数为255,和编码无关
varchar的特点
- varchar表示可变长字符串,长度是可变的;
插入的数据是多长,就按照多长来存储; - varchar在存取方面与char相反,它存取慢,因为长度不固定,但正因如此,不占据多余的空间,是时间换空间的做法;
- 对于varchar来说,最多能存放的字符个数为65532。
总之,结合性能角度(char更快)和节省磁盘空间角度(varchar更小),具体情况还需具体来设计数据库才是妥当的做法。
19.drop、delete与truncate的区别
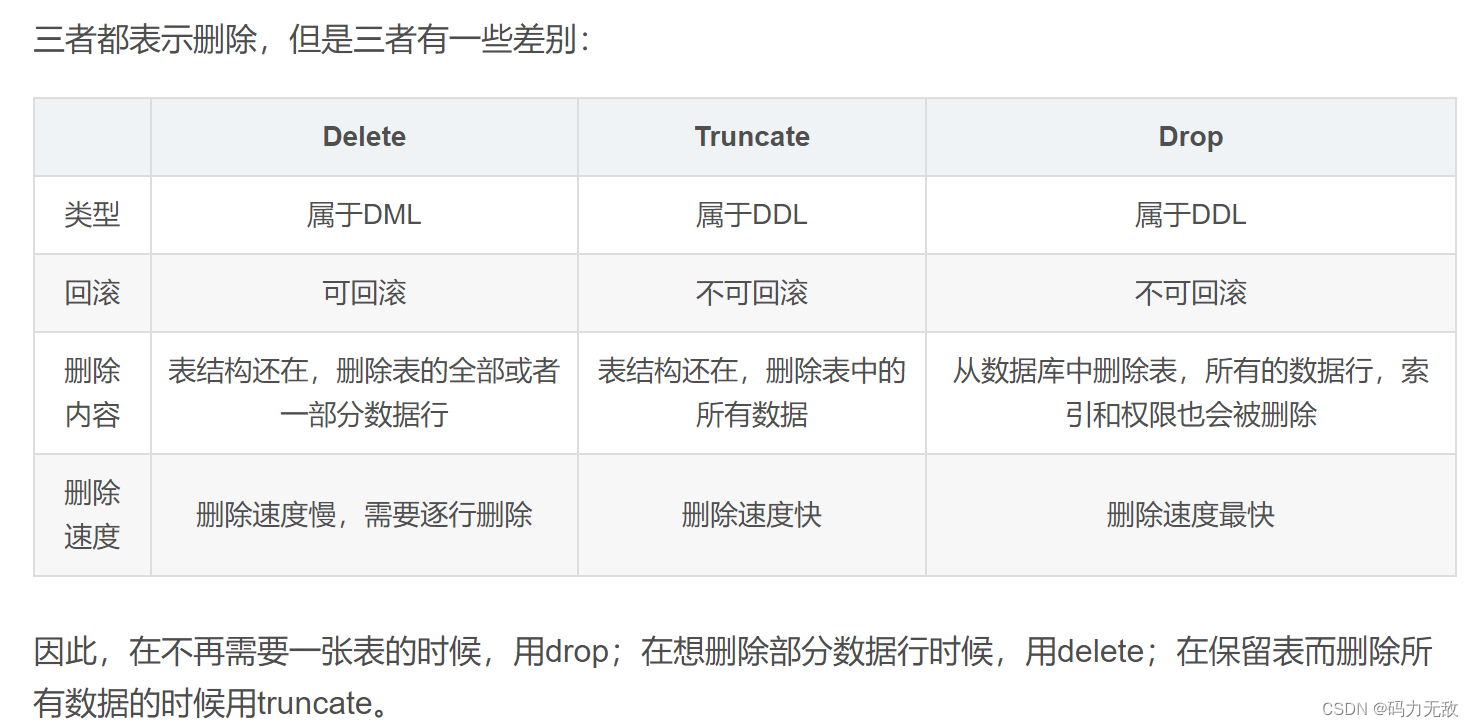
20.sql优化?
- 优化索引 、sql语句+索引;执行索引,避免 不走索引。
- 第二加缓存,memcached, redis;
- 主从复制,读写分离;
- 垂直拆分,根据你模块的耦合度,将一个大的系统分为多个小的系统,也就是分布式系统;
- 水平切分,针对数据量大的表,这一步最麻烦,最能考验技术水平,要选择一个合理的sharding key, 为了有好的查询效率,表结构也要改动,做一定的冗余,应用也要改,sql中尽量带sharding key,将数据定位到限定的表上去查,而不是扫描全部的表;
优化思路 :
- 首先分析语句,看看是否load了额外的数据,可能是查询了多余的行并且抛弃掉了,可能是加载了许多结果中并不需要的列,对语句进行分析以及重写。
- 分析语句的执行计划,然后获得其使用索引的情况,之后修改语句或者修改索引,使得语句可以尽可能的命中索引。
- 如果对语句的优化已经无法进行,可以考虑表中的数据量是否太大,如果是的话可以进行横向或者纵向的分表。
21.超大分页怎么处理?
- 数据库层面,这也是我们主要集中关注的(虽然收效没那么大),类似于select * from table where age > 20 limit 1000000,10这种查询其实也是有可以优化的余地的. 这条语句需要load1000000数据然后基本上全部丢弃,只取10条当然比较慢. 当时我们可以修改为select * from table where id in (select id from table where age > 20 limit 1000000,10).这样虽然也load了一百万的数据,但是由于索引覆盖,要查询的所有字段都在索引中,所以速度会很快. 同时如果ID连续的好,我们还可以select * from table where id > 1000000 limit 10,效率也是不错的,优化的可能性有许多种,但是核心思想都一样,就是减少load的数据.
- 从需求的角度减少这种请求…主要是不做类似的需求(直接跳转到几百万页之后的具体某一页.只允许逐页查看或者按照给定的路线走,这样可预测,可缓存)以及防止ID泄漏且连续被人恶意攻击.
解决超大分页,其实主要是靠缓存,可预测性的提前查到内容,缓存至redis等k-V数据库中,直接返回即可.
在阿里巴巴《Java开发手册》中,对超大分页的解决办法是类似于上面提到的第一种.
【推荐】利用延迟关联或者子查询优化超多分页场景。
说明:MySQL并不是跳过offset行,而是取offset+N行,然后返回放弃前offset行,返回N行,那当offset特别大的时候,效率就非常的低下,要么控制返回的总页数,要么对超过特定阈值的页数进行SQL改写。
正例:先快速定位需要获取的id段,然后再关联:
SELECT a.* FROM 表1 a, (select id from 表1 where 条件 LIMIT 100000,20 ) b where a.id=b.id
- 1
- 2
- 3
- 4
- 5
- 6
22.主键使用自增ID还是UUID?
推荐使用自增ID,不要使用UUID。
- 因为在InnoDB存储引擎中,主键索引是作为聚簇索引存在的,也就是说,主键索引的B+树叶子节点上存储了主键索引以及全部的数据(按照顺序),如果主键索引是自增ID,那么只需要不断向后排列即可。
- 如果是UUID,由于到来的ID与原来的大小不确定,会造成非常多的数据插入,数据移动,然后导致产生很多的内存碎片,进而造成插入性能的下降。
总之,在数据量大一些的情况下,用自增主键性能会好一些。
关于主键是聚簇索引,如果没有主键,InnoDB会选择一个唯一键来作为聚簇索引,如果没有唯一键,会生成一个隐式的主键。
字段为什么要求定义为not null?
null值会占用更多的字节,且会在程序中造成很多与预期不符的情况。
23.sql优化的思路和范围?
优化查询过程中的数据访问
- 访问数据太多导致查询性能下降
- 确定应用程序是否在检索大量超过需要的数据,可能是太多行或列
确认MySQL服务器是否在分析大量不必要的数据行
避免犯如下SQL语句错误 - 查询不需要的数据。解决办法:使用limit解决
- 多表关联返回全部列。解决办法:指定列名
- 总是返回全部列。解决办法:避免使用SELECT *
- 重复查询相同的数据。解决办法:可以缓存数据,下次直接读取缓存
是否在扫描额外的记录。解决办法: - 使用explain进行分析,如果发现查询需要扫描大量的数据,但只返回少数的行,可以通过如下技巧去优化:
- 使用索引覆盖扫描,把所有的列都放到索引中,这样存储引擎不需要回表获取对应行就可以返回结果。
- 改变数据库和表的结构,修改数据表范式
- 重写SQL语句,让优化器可以以更优的方式执行查询。
优化长难的查询语句
1.将一个大的查询分解为多个小的查询,
2.切分查询:将一个大的查询分为多个小的相同的查询。
3.分解关联查询,让缓存的效率更高。
4.执行单个查询可以减少锁的竞争。在应用层做关联更容易对数据库进行拆分。查询效率会有大幅提升。
5. 较少冗余记录的查询。
优化特定类型的查询语句
- count(*)会忽略所有的列,直接统计所有列数,不要使用count(列名)
- 可以使用explain查询近似值,用近似值替代count(*)
- 增加汇总表
- 使用缓存
优化关联查询
- 确定ON或者USING子句中是否有索引。
- 确保GROUP BY和ORDER BY只有一个表中的列,这样MySQL才有可能使用索引。
优化子查询
- 用关联查询替代
- 优化GROUP BY和DISTINCT
优化LIMIT分页
LIMIT偏移量大的时候,查询效率较低
可以记录上次查询的最大ID,下次查询时直接根据该ID来查询
优化UNION查询
UNION ALL的效率高于UNION
优化WHERE子句
- 对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
- 应尽量避免在 where 子句中对字段进行 null 值判断
- 应尽量避免在 where 子句中使用!=或<>操作符。
- .应尽量避免在 where 子句中使用or 来连接条件。
- in 和 not in 也要慎用,否则会导致全表扫描。
- like模糊查询也会导致全表扫描。
- 应尽量避免在 where 子句中对字段进行函数、算术运算或其他表达式运算。
24.数据库优化?
- 数据库结构优化,需要考虑数据冗余、查询和更新的速度、字段的数据类型是否合理等多方面的内容。
- 将字段很多的表分解成多个表,如果有些字段的使用频率很低,可以将这些字段分离出来形成新表
- 增加中间表,对于需要经常联合查询的表,可以建立中间表以提高查询效率。
- 增加冗余字段,设计数据表时应尽量遵循范式理论的规约,尽可能的减少冗余字段,让数据库设计看起来精致、优雅。但是,合理的加入冗余字段可以提高查询速度。但注意冗余字段的更新同步问题。
25.MySQL数据库cpu飙升到500%的话他怎么处理?
当 cpu 飙升到 500%时,先用操作系统命令 top 命令观察是不是 mysqld 占用导致的,如果不是,找出占用高的进程,并进行相关处理。
如果是 mysqld 造成的, show processlist,看看里面跑的 session 情况,是不是有消耗资源的 sql 在运行。找出消耗高的 sql,看看执行计划是否准确, index 是否缺失,或者实在是数据量太大造成。
一般来说,肯定要 kill 掉这些线程(同时观察 cpu 使用率是否下降),等进行相应的调整(比如说加索引、改 sql、改内存参数)之后,再重新跑这些 SQL。
也有可能是每个 sql 消耗资源并不多,但是突然之间,有大量的 session 连进来导致 cpu 飙升,这种情况就需要跟应用一起来分析为何连接数会激增,再做出相应的调整,比如说限制连接数等
26.大表怎么优化?某个表有近千万数?
- 限定数据的范围: 务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内。;
- 读/写分离: 经典的数据库拆分方案,主库负责写,从库负责读;
- 缓存: 使用MySQL的缓存,另外对重量级、更新少的数据可以考虑使用应用级别的缓存;
- 垂直分区:把一张列比较多的表拆分为多张表。
- 垂直分表:把主键和一些列放在一个表,然后把主键和另外的列放在另一个表中。
- 水平分区:保持数据表结构不变,通过某种策略存储数据分片。这样每一片数据分散到不同的表或者库中,达到了分布式的目的。 水平拆分可以支撑非常大的数据量。水平拆分最好分库。
27.MySQL主从复制工作原理
- 在主库上把数据更高记录到二进制日志
- 从库将主库的日志复制到自己的中继日志
- 从库读取中继日志的事件,将其重放到从库数据中
基本原理流程,3个线程以及之间的关联
- 主:binlog线程——记录下所有改变了数据库数据的语句,放进master上的binlog中;
- 从:io线程——在使用start slave 之后,负责从master上拉取 binlog 内容,放进自己的relay log中;
- 从:sql执行线程——执行relay log中的语句;
28.msql的事务传播机制?
- PROPAGATION_REQUIRED:支持当前事务,如果当前没有事务,就新建一个事务。也就是说业务方法需要在一个事务中运行,如果
业务方法被调用时,调用业务方法的行为(方法)已经处在一个事务中,那么就加入到该事务,否则为自己创建一个新的事务。
(默认传播属性) - PROPAGATION_SUPPORTS:支持当前事务,如果当前没有事务,就以非事务方式执行。也就是说如果业务方法在某个事务范围内被调用,
则该方法成为该事务的一部分。如果业务方法在事务范围外被调用,则该方法在没有事务的环境下执行。 - PROPAGATION_MANDATORY:支持当前事务,如果当前没有事务,就抛出异常。也就是说业务方法只能在一个已经存在的事务中执行,
业务方法不能发起自己的事务。如果业务方法在没有事务的环境下被调用,容器就会抛出例外。 - PROPAGATION_REQUIRESNEW:如果当前存在事务,把当前事务挂起,新建事务。也就是说业务方法被调用时,不管是否已经存在事务,
业务方法总会为自己发起一个新的事务。如果调用业务方法的行为(方法)已经运行在一个事务中,则原有事务会被挂起,新的事务
会被创建,直到业务方法执行结束,新事务才算结束,原先的事务才会恢复执行。 - PROPAGATION_NOT_SUPPORTED:以非事务方式执行,如果当前存在事务,就把当前事务挂起。也就是说业务方法不需要事务。如果
方法没有被关联到一个事务中,容器不会为它开启事务。如果方法在一个事务中被调用,该事务会被挂起,在方法调用结束后,
原先的事务便会恢复执行。 - PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。也就是说业务方法绝对不能在事务范围内执行。如果业务
方法在某个事务中执行,容器会抛出例外,只有业务方法没有关联到任何事务,才能正常执行。 - PROPAGATION_NESTED:如果一个活动的事务存在,则运行在一个嵌套的事务中。 如果没有活动事务, 则按REQUIRED属性执行。
它使用了一个单独的事务, 这个事务拥有多个可以回滚的保存点。内部事务的回滚不会对外部事务造成影响。它只对
DataSourceTransactionManager事务管理器起效。
29. mysql隐式类型转换?
两个值进行运算或者比较,首先要求数据类型必须一致。如果发现两个数据类型不一致时就会发生隐式类型转换。例如,把字符串转成数字,或者相反:
转换规则:
- 两个参数至少有一个是 NULL 时,比较的结果也是 NULL,例外是使用 <=> 对两个 NULL 做比较时会返回 1,这两种情况都不需要做类型转换;
- 两个参数都是字符串,会按照字符串来比较,不做类型转换;
- 两个参数都是整数,按照整数来比较,不做类型转换;
- 十六进制的值和非数字做比较时,会被当做二进制字符串;
- 有一个参数是 TIMESTAMP 或 DATETIME,并且另外一个参数是常量,常量会被转换为 时间戳;
- 有一个参数是 decimal 类型,如果另外一个参数是 decimal 或者整数,会将整数转换为 decimal 后进行比较,如果另外一个参数是浮点数(一般默认是 double),则会把 decimal 转换为浮点数进行比较;
- 所有其他情况下,两个参数都会被转换为浮点数再进行比较;
我们在平时的开发过程中,尽量要避免隐式转换,因为一旦发生隐式转换除了会降低性能外, 还有很大可能会出现不期望的结果,就像我最开始遇到的那个问题一样。
之所以性能会降低,还有一个原因就是让本来有的索引失效。
30.如何解决主从延迟?
- 配合 semi-sync 半同步复制;
- 一主多从,分摊从库压力;
- 强制走主库方案(强一致性);
- sleep 方案:主库更新后,读从库之前先 sleep 一下;
- 判断主备无延迟方案(例如判断 seconds_behind_master 参数是否已经等于 0、对比位点);
- 并行复制 — 解决从库复制延迟的问题;
这里主要介绍我在项目中使用的几种方案,分别是半同步复制、实时性操作强制走主库、并行复制。
31.explain如何查看是否回表
执行计划重点关注跟索引相关的关键项,有 Id、select_type 、table、type、possible_keys、key、key_len、rows、ref、Extra 等。
select_type:查询的类型,主要用于区别普通查询,联合查询,子查询等复杂查询。
SIMPLE:简单的 SELECT 查询,查询中不包含子查询或 UNION 查询。
PRIMARY:查主查询,即最外面的查询。
SUBQUERY:子查询中的第一个 SELECT。
DERIVED:导出表的 SELECT(FROM 子句的子查询)。
UNION:UNION 中的第二个或后面的查询语句。
UNION RESULT: UNION 的结果。
type
对表访问方式,表示 MySQL 在表中找到所需行的方式,又称“访问类型”。
常用的类型有: ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能逐渐变好)。
ALL:Full Table Scan, MySQL 将遍历全表以找到匹配的行。
index:Full Index Scan,index 与 ALL 区别为 index 类型只遍历索引树。
range:只检索给定范围的行,使用一个索引来选择行。常见于:<、<=、>、>=、between 等。
ref:表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值。
eq_ref:类似 ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配。简单来说,就是多表连接中使用 primary key 或者 unique key 作为关联条件。
const:查询条件是主键或者非 NULL 的 UNIQUE 索引,因此结果只有一条,同时优化过程中查询列值会转成常量。
system:system 是 const 类型的特例,当查询的表只有一行的情况下使用 system。
NULL:不用访问表就可以直接得到结果。(例如:SELECT 1)
Extra
Distinct:一旦找到了与行相联合匹配的行就不再搜索了。
Using filesort:通常出现在 order by,当试图对一个不是索引的字段进行排序时,MySQL 就会自动对该字段进行排序,这个过程就称为“文件排序”。文件排序,性能非常慢,需要优化。
Using index:表示查询的列全在索引中,且 where 筛选条件符合索引的前导列原则,即使用了覆盖索引(Covering Index),避免了访问表的数据行,效率高。使用索引来直接获取列的数据,而不需回表。
Using temporary:表示在查询过程中产生了临时表用于保存中间结果。MySQL 在对查询结果进行排序时会使用临时表,常见于group by。group by 的实质是先排序后分组,同 order by 一样,group by 和索引息息相关。出现 Using temporary 意味着产生了临时表存储中间结果并且最后删掉了该临时表,这个过程很消耗性能。
Using Where:查询的列被索引覆盖,并且 where 筛选条件是索引列之一但不是索引的前导列,Extra 中为 Using where; Using index,意味着无法直接通过索引查找来查询到符合条件的数据。
ALL:这个连接类型对于前面的每一个记录联合进行完全扫描,这一般比较糟糕,需要优化。
33. 什么是MVCC?
MVCC就是为了实现读-写冲突不加锁,而这个读指的就是快照读,而非当前读,当前读实际上就是一种加锁的操作,是悲观锁的实现。
MVCC优点:
- MVCC在MySQL InnoDB中的实现主要是为了提高数据库的并发性能,用更好的方式去处理读-写或写-读之间的冲突,也能做到不加锁,非阻塞并发读,提高了数据库并发读写的性能。
- MVCC还可以解决脏读,不可重复读,幻读等事务隔离问题。但它还不能解决更新丢失的问题,不能解决写-写之间的的并发控制。
所谓的MVCC(Multi-Version Concurrency Control ,多版本并发控制)指的就是在使用READ COMMITTD、REPEATABLE READ这两种隔离级别的事务在执行普通SELECT操作时访问记录的版本链的过程,这样子可以使不同事务的读-写、写-读操作并发执行,从而提升系统性能。
READ COMMITTD、REPEATABLE READ这两个隔离级别的一个很大不同就是:生成ReadView的时机不同,READ COMMITTD在每一次进行普通SELECT操作前都会生成一个ReadView,而REPEATABLE READ只在第一次进行普通SELECT操作前生成一个ReadView,之后的查询操作都重复使用这个ReadView就好了,从而基本上可以避免幻读现象。
详细见:https://www.cnblogs.com/nevererror/p/16251856.html

十、es
十一、定时任务
1.Spring Boot 中如何实现定时任务 ?
定时任务也是一个常见的需求,Spring Boot 中对于定时任务的支持主要还是来自 Spring 框架。
在 Spring Boot 中使用定时任务主要有两种不同的方式,一个就是使用 Spring 中的 @Scheduled 注解,另一个则是使用第三方框架 Quartz。
-
使用 Spring 中的 @Scheduled 的方式主要通过 @Scheduled 注解来实现。
-
使用 Quartz ,则按照 Quartz 的方式,定义 Job 和 Trigger 即可。
十二、sping
1.什么是sping?他的作用?
Spring是一个轻量级Java开发框架,Spring最根本的使命是解决企业级应用开发的复杂性,即简化Java开发。Sping的两个核心特性,也就是依赖注入和面向切面编程AOP。
为了降低Java开发的复杂性,Spring采取了以下4种关键策略。
- 基于POJO的轻量级和最小侵入性编程;
- 通过依赖注入和面向接口实现松耦合;
- 基于切面和惯例进行声明式编程;
- 通过切面和模板减少样板式代码。
2.Spring框架的设计目标,设计理念,和核心是什么
-
Spring设计目标:Spring为开发者提供一个一站式轻量级应用开发平台;
-
Spring设计理念:在JavaEE开发中,支持POJO和JavaBean开发方式,使应用面向接口开发,充分支持OO(面向对象)设计方法;Spring通过IoC容器实现对象耦合关系的管理,并实现依赖反转,将对象之间的依赖关系交给IoC容器,实现解耦;
-
Spring框架的核心:IoC容器和AOP模块。通过IoC容器管理POJO对象以及他们之间的耦合关系;通过AOP以动态非侵入的方式增强服务。
IoC让相互协作的组件保持松散的耦合,而AOP编程允许你把遍布于应用各层的功能分离出来形成可重用的功能组件。
3.Spring由哪些模块组成?
- spring core:提供了框架的基本组成部分,包括控制反转(Inversion of Control,IOC)和依赖注入(Dependency Injection,DI)功能。
- spring beans:提供了BeanFactory,是工厂模式的一个经典实现,Spring将管理对象称为Bean。
- spring context:构建于 core 封装包基础上的 context 封装包,提供了一种框架式的对象访问方法。
- spring jdbc:提供了一个JDBC的抽象层,消除了烦琐的JDBC编码和数据库厂商特有的错误代码解析, 用于简化JDBC。
- spring aop:提供了面向切面的编程实现,让你可以自定义拦截器、切点等。
- spring Web:提供了针对 Web 开发的集成特性,例如文件上传,利用 servlet listeners 进行 ioc 容器初始化和针对 Web 的 ApplicationContext。
- spring test:主要为测试提供支持的,支持使用JUnit或TestNG对Spring组件进行单元测试和集成测试。
4.Spring 框架中都用到了哪些设计模式?
- 工厂模式:BeanFactory就是简单工厂模式的体现,用来创建对象的实例;
- 单例模式:Bean默认为单例模式。
- 代理模式:Spring的AOP功能用到了JDK的动态代理和CGLIB字节码生成技术;
- 模板方法:用来解决代码重复的问题。比如. RestTemplate, JmsTemplate, JpaTemplate。
- 观察者模式:定义对象键一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知被制动更新,如Spring中listener的实现–ApplicationListener。
5. 什么是Spring IOC 容器?
控制反转即IoC (Inversion of Control),它把传统上由程序代码直接操控的对象的调用权交给容器,通过容器来实现对象组件的装配和管理。所谓的“控制反转”概念就是对组件对象控制权的转移,从程序代码本身转移到了外部容器。
Spring IOC 负责创建对象,管理对象(通过依赖注入(DI),装配对象,配置对象,并且管理这些对象的整个生命周期。
控制反转(IoC)有什么作用:
- 管理对象的创建和依赖关系的维护。
- 解耦,由容器去维护具体的对象
- 托管了类的产生过程,比如代理,把处理交给容器,应用程序则无需去关心类是如何完成代理。
6.Spring IoC 的实现机制
Spring 中的 IoC 的实现原理就是工厂模式加反射机制。
比如定义一个水果加工的工厂,有苹果、橘子。实现工厂。
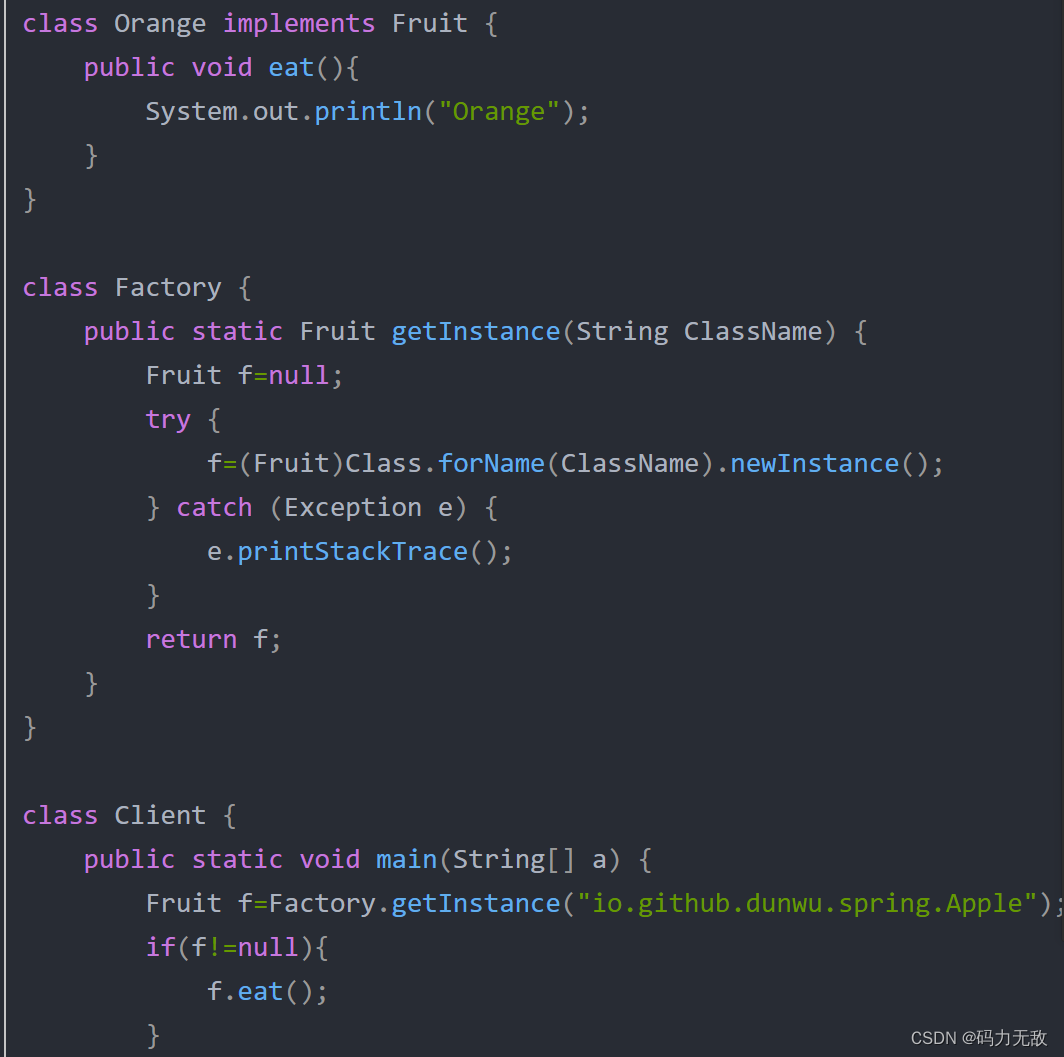
7.什么是Spring的依赖注入-Sping IOC?
控制反转IoC是一个很大的概念,可以用不同的方式来实现。其主要实现方式有两种:依赖注入和依赖查找
依赖注入:所谓依赖注入(Dependency Injection),即组件之间的依赖关系由容器在应用系统运行期来决定,也就是由容器动态地将某种依赖关系的目标对象实例注入到应用系统中的各个关联的组件之中。组件不做定位查询,只提供普通的Java方法让容器去决定依赖关系。
让容器全权负责依赖查询,受管组件只需要暴露JavaBean的setter方法或者带参数的构造器或者接口,使容器可以在初始化时组装对象的依赖关系。
有哪些不同类型的依赖注入实现方式?
依赖注入是时下最流行的IoC实现方式,依赖注入分为接口注入(Interface Injection),Setter方法注入(Setter Injection)和构造器注入(Constructor Injection)三种方式。其中接口注入由于在灵活性和易用性比较差,现在从Spring4开始已被废弃。
-
构造器依赖注入:构造器依赖注入通过容器触发一个类的构造器来实现的,该类有一系列参数,每个参数代表一个对其他类的依赖。
-
Setter方法注入:Setter方法注入是容器通过调用无参构造器或无参static工厂 方法实例化bean之后,调用该bean的setter方法,即实现了基于setter的依赖注入。
8.BeanFactory 和 ApplicationContext有什么区别?
BeanFactory和ApplicationContext是Spring的两大核心接口,都可以当做Spring的容器。其中ApplicationContext是BeanFactory的子接口。
BeanFactory:是Spring里面最底层的接口,包含了各种Bean的定义,读取bean配置文档,管理bean的加载、实例化,控制bean的生命周期,维护bean之间的依赖关系。以理解为就是个 HashMap,Key 是 BeanName,Value 是 Bean 实例。通常只提供注册(put),获取(get)这两个功能。我们可以称之为 “低级容器”。
BeanFactroy采用的是延迟加载形式来注入Bean的,即只有在使用到某个Bean时(调用getBean()),才对该Bean进行加载实例化。
ApplicationContext 可以称之为 “高级容器”。它是在容器启动时,一次性创建了所有的Bean。因为他比 BeanFactory 多了更多的功能。他继承了多个接口。因此具备了更多的功能。例如资源的获取,支持多种消息(例如 JSP tag 的支持),对 BeanFactory 多了工具级别的支持等待。
9.Spring有几种配置方式?
- XML配置文件。
- 基于注解的配置。
- 基于java的配置。
10.说一下Spring的事务传播行为?
① PROPAGATION_REQUIRED:如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,该设置是最常用的设置。
② PROPAGATION_SUPPORTS:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。
③ PROPAGATION_MANDATORY:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。
④ PROPAGATION_REQUIRES_NEW:创建新事务,无论当前存不存在事务,都创建新事务。
⑤ PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
⑥ PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。
⑦ PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则按REQUIRED属性执行。
11.sping循环依赖怎么解决?
A依赖B,B依赖A;或者C依赖C;或者A>B>C>A。
在sping中,一个完整的对象包含两部分:当前对象实例化和对象属性的实例化。
在Spring中,对象的实例化是通过反射实现的,而对象的属性则是在对象实例化之后通过一定的方式设置的。
首先,Spring内部维护了三个Map,也就是我们通常说的三级缓存。
- 一级缓存为:singletonObjects,俗称“单例池”“容器”,缓存创建完成单例Bean的地方。
- 二级缓存为:earlySingletonObjects;映射Bean的早期引用,也就是说在这个Map里的Bean不是完整的,甚至还不能称之为“Bean”,只是一个Instance。
- 三级缓存为:singletonFactories; 映射创建Bean的原始工厂。
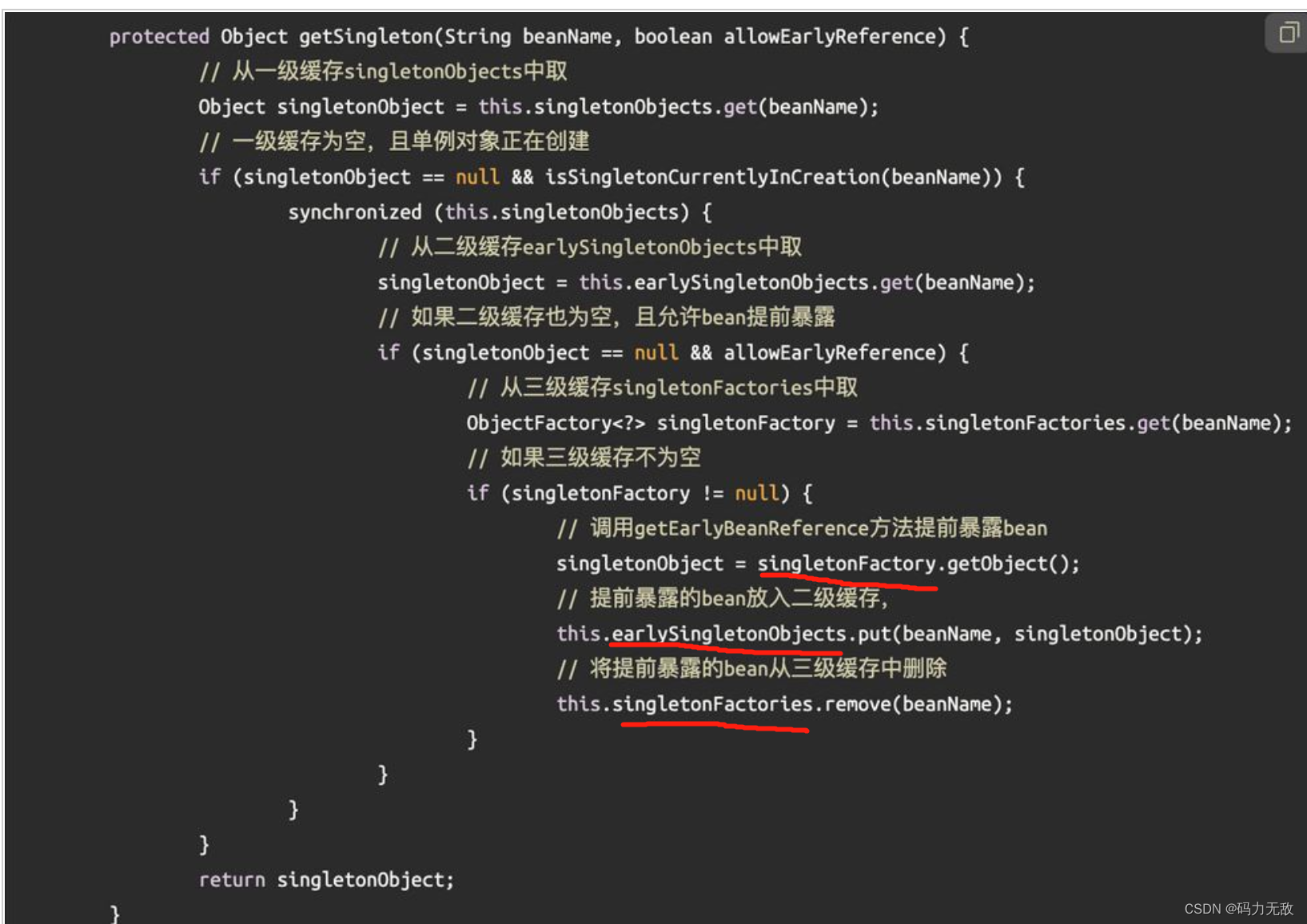
其他情况如何解决?
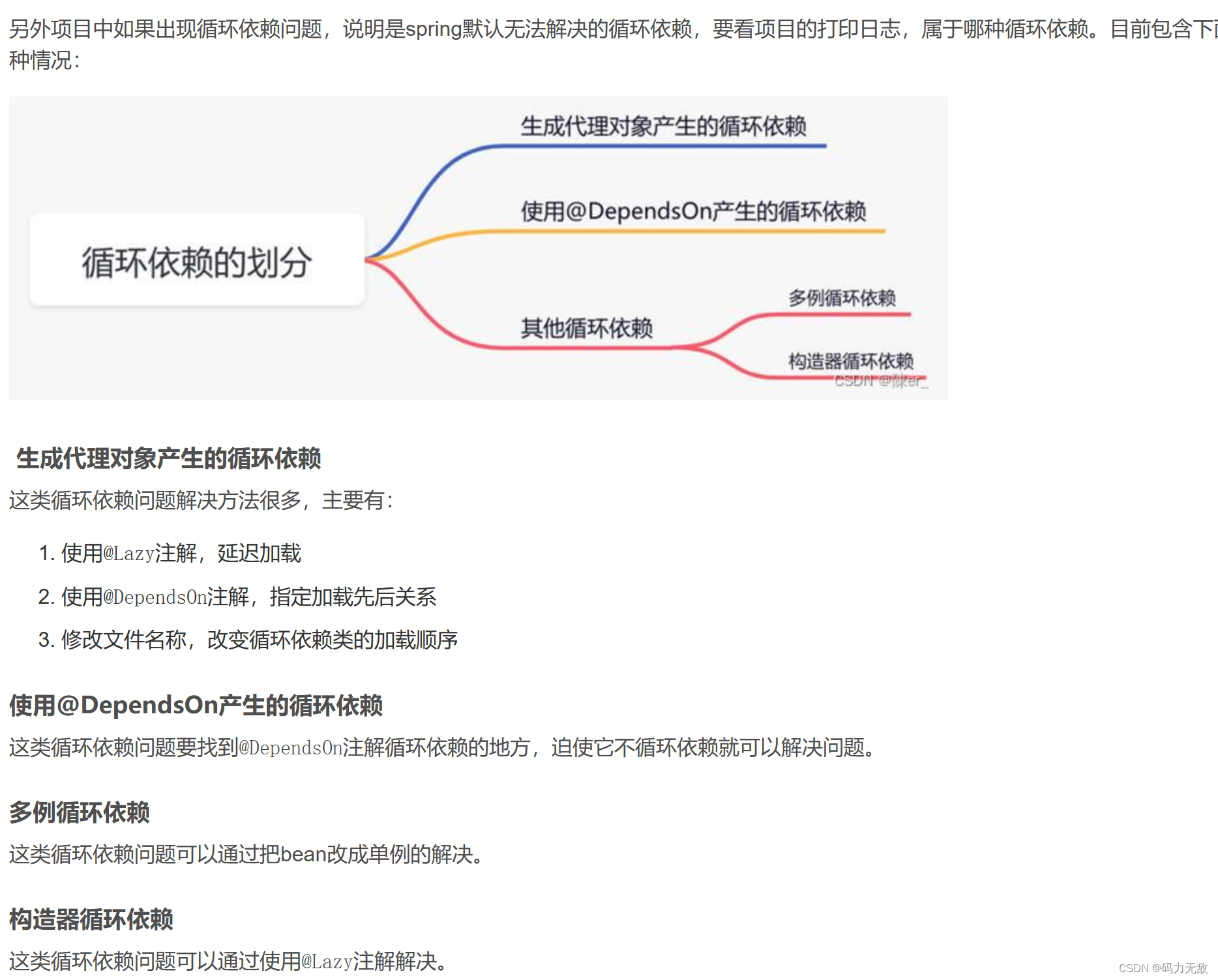
12.Spring AOP and AspectJ AOP 有什么区别?AOP 有哪些实现方式?
AOP实现的关键在于 代理模式,AOP代理主要分为静态代理和动态代理。静态代理的代表为AspectJ;动态代理则以Spring AOP为代表。
(1)AspectJ是静态代理的增强,所谓静态代理,就是AOP框架会在编译阶段生成AOP代理类,因此也称为编译时增强,他会在编译阶段将AspectJ(切面)织入到Java字节码中,运行的时候就是增强之后的AOP对象。
(2)Spring AOP使用的动态代理,所谓的动态代理就是说AOP框架不会去修改字节码,而是每次运行时在内存中临时为方法生成一个AOP对象,这个AOP对象包含了目标对象的全部方法,并且在特定的切点做了增强处理,并回调原对象的方法。
————————————————
版权声明:本文为CSDN博主「ThinkWon」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/ThinkWon/article/details/104397516
13.spingBean的生命周期?
当一个 Bean 被加载到 Spring 容器时,它就具有了生命,而 Spring 容器在保证一个 Bean 能够使用之前,会进行很多工作。Spring 容器中 Bean 的生命周期流程如图 1 所示。

Bean 生命周期的整个执行过程描述如下。
- 1)根据配置情况调用 Bean 构造方法或工厂方法实例化 Bean。
- 2)利用依赖注入完成 Bean 中所有属性值的配置注入。
- 3)如果 Bean 实现了 BeanNameAware 接口,则 Spring 调用 Bean 的 setBeanName() 方法传入当前 Bean 的 id 值。
- 4)如果 Bean 实现了 BeanFactoryAware 接口,则 Spring 调用 setBeanFactory() 方法传入当前工厂实例的引用。
- 5)如果 Bean 实现了 ApplicationContextAware 接口,则 Spring 调用 setApplicationContext() 方法传入当前 ApplicationContext 实例的引用。
- 6)如果 BeanPostProcessor 和 Bean 关联,则 Spring 将调用该接口的预初始化方法 postProcessBeforeInitialzation() 对 Bean 进行加工操作,此处非常重要,Spring 的 AOP 就是利用它实现的。
- 7)如果 Bean 实现了 InitializingBean 接口,则 Spring 将调用 afterPropertiesSet() 方法。
- 8)如果在配置文件中通过 init-method 属性指定了初始化方法,则调用该初始化方法。
- 9)如果 BeanPostProcessor 和 Bean 关联,则 Spring 将调用该接口的初始化方法 postProcessAfterInitialization()。此时,Bean 已经可以被应用系统使用了。
- 10)如果在 中指定了该 Bean 的作用范围为 scope=“singleton”,则将该 Bean 放入 Spring IoC 的缓存池中,将触发 Spring 对该 Bean 的生命周期管理;如果在 中指定了该 Bean 的作用范围为 scope=“prototype”,则将该 Bean 交给调用者,调用者管理该 Bean 的生命周期,Spring 不再管理该 Bean。
- 11)如果 Bean 实现了 DisposableBean 接口,则 Spring 会调用 destory() 方法将 Spring 中的 Bean 销毁;如果在配置文件中通过 destory-method 属性指定了 Bean 的销毁方法,则 Spring 将调用该方法对 Bean 进行销毁。
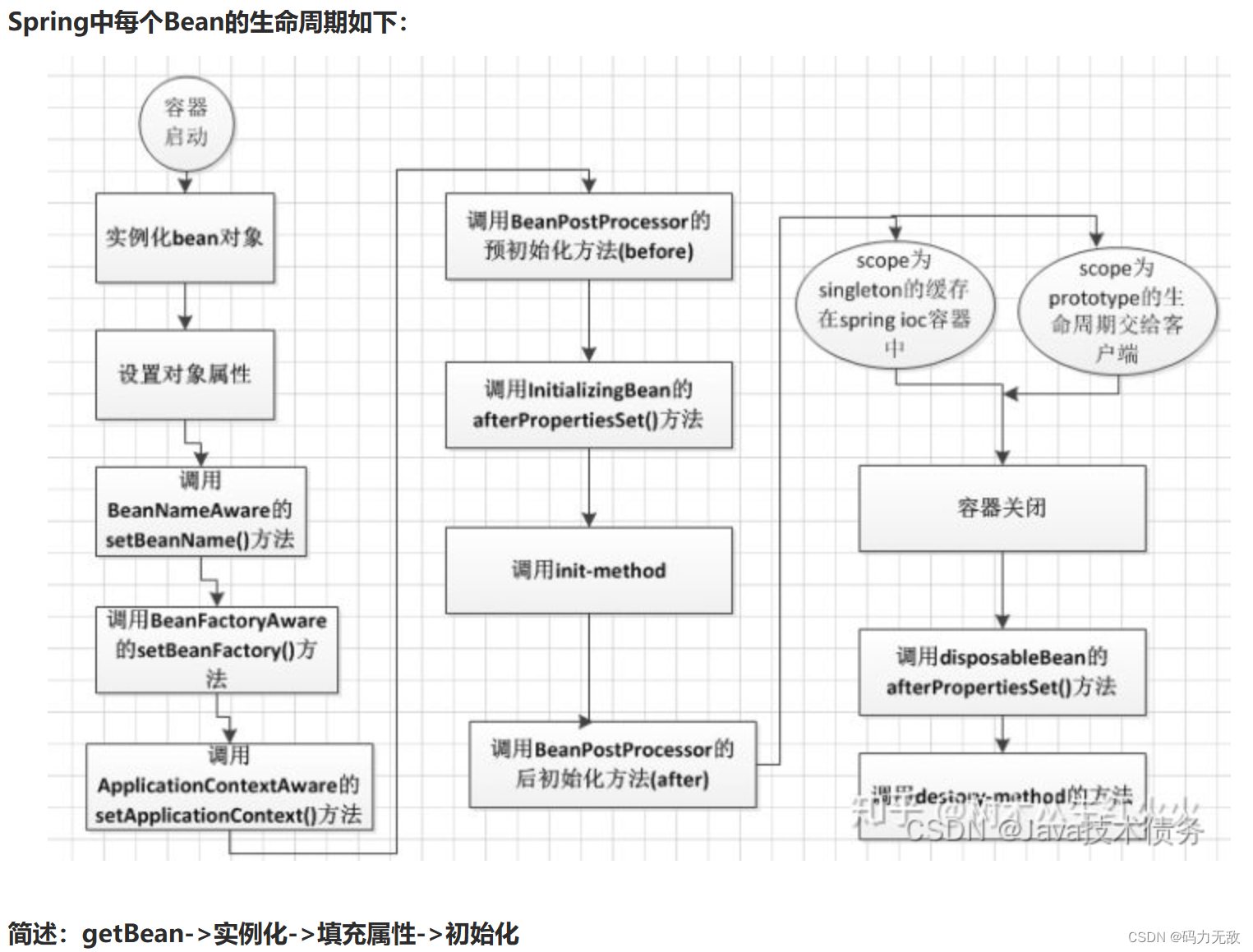
14.sping和spingBoot的区别?
-
spring 为开发 Java 程序提供了全面的基础架构支持,包括依赖注入以及一些开箱即用的模块,大大缩短了程序的开发时间。
Spring JDBC 、 Spring MVC 、 Spring AOP 、 Spring TEST 、 Spring Security 、 Spring ORM。 -
SpringBoot 是一个轻量级的微服务器,是 Spring 框架的扩展。它消除了 复杂的xml 的配置,可以直接main 函数启动,嵌入式 web 服务器,避免了应用程序部署的复杂性。
SpringBoot对组件包进行了封装,只需要一个依赖项来启动和运行 Web 应用程序,尽可能的自动化配置Spring 功能。
15.Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
启动类上面的注解是@SpringBootApplication,它也是 Spring Boot 的核心注解,主要组合包含了以下 3 个注解:
- @SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
- @EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源自动配置功能:@SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。
- @ComponentScan:Spring组件扫描。
17.Spring Boot 自动配置原理是什么?
注解 @EnableAutoConfiguration, @Configuration, @ConditionalOnClass 就是自动配置的核心,
@EnableAutoConfiguration 给容器导入META-INF/spring.factories 里定义的自动配置类。
筛选有效的自动配置类。
每一个自动配置类结合对应的 xxxProperties.java 读取配置文件进行自动配置功能
18.Spring Boot 中如何解决跨域问题 ?
跨域可以在前端通过 JSONP 来解决,但是 JSONP 只可以发送 GET 请求,无法发送其他类型的请求,不推荐。
推荐在后端通过 (CORS,Cross-origin resource sharing) 来解决跨域问题。现在可以通过实现WebMvcConfigurer接口然后重写addCorsMappings方法解决跨域问题。
@Configuration
public class CorsConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**")
.allowedOrigins("*")
.allowCredentials(true)
.allowedMethods("GET", "POST", "PUT", "DELETE", "OPTIONS")
.maxAge(3600);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
十三、mybatis
1.什么是mybatis
MyBatis 是一款优秀的持久层框架,一个半 ORM(对象关系映射)框架,它支持定制化 SQL、存储过程以及高级映射。
MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生类型、接口和 Java 的 POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
在查询关联对象或关联集合对象时,需要手动编写sql来完成,所以,称之为半自动ORM映射工具。
2.JDBC编程有哪些不足之处,MyBatis是如何解决这些问题的?
1、数据库链接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库连接池可解决此问题。
解决:在mybatis-config.xml中配置数据链接池,使用连接池管理数据库连接。
2、Sql语句写在代码中造成代码不易维护,实际应用sql变化的可能较大,sql变动需要改变java代码。
解决:将Sql语句配置在XXXXmapper.xml文件中与java代码分离。
3、向sql语句传参数麻烦,因为sql语句的where条件不一定,可能多也可能少,占位符需要和参数一一对应。
解决: Mybatis自动将java对象映射至sql语句。
4、对结果集解析麻烦,sql变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成pojo对象解析比较方便。
解决:Mybatis自动将sql执行结果映射至java对象。
2. Mybatis优缺点
优点
与传统的数据库访问技术相比,ORM有以下优点:
- 基于SQL语句编程,相当灵活,不会对应用程序或者数据库的现有设计造成任何影响,SQL写在XML里,解除sql与程序代码的耦合,便于统一管理;提供XML标签,支持编写动态SQL语句,并可重用
- 与JDBC相比,减少了50%以上的代码量,消除了JDBC大量冗余的代码,不需要手动开关连接
- 很好的与各种数据库兼容(因为MyBatis使用JDBC来连接数据库,所以只要JDBC支持的数据库MyBatis都支持)
- 提供映射标签,支持对象与数据库的ORM字段关系映射;提供对象关系映射标签,支持对象关系组件维护
- 能够与Spring很好的集成
缺点
- SQL语句的编写工作量较大,尤其当字段多、关联表多时,对开发人员编写SQL语句的功底有一定要求。
- SQL语句依赖于数据库,导致数据库移植性差,不能随意更换数据库
4.MyBatis的解析和运行原理
4.1 MyBatis编程步骤是什么样的?
1、 创建SqlSessionFactory
2、 通过SqlSessionFactory创建SqlSession
3、 通过sqlsession执行数据库操作
4、 调用session.commit()提交事务
5、 调用session.close()关闭会话
4.2 请说说MyBatis的工作原理?
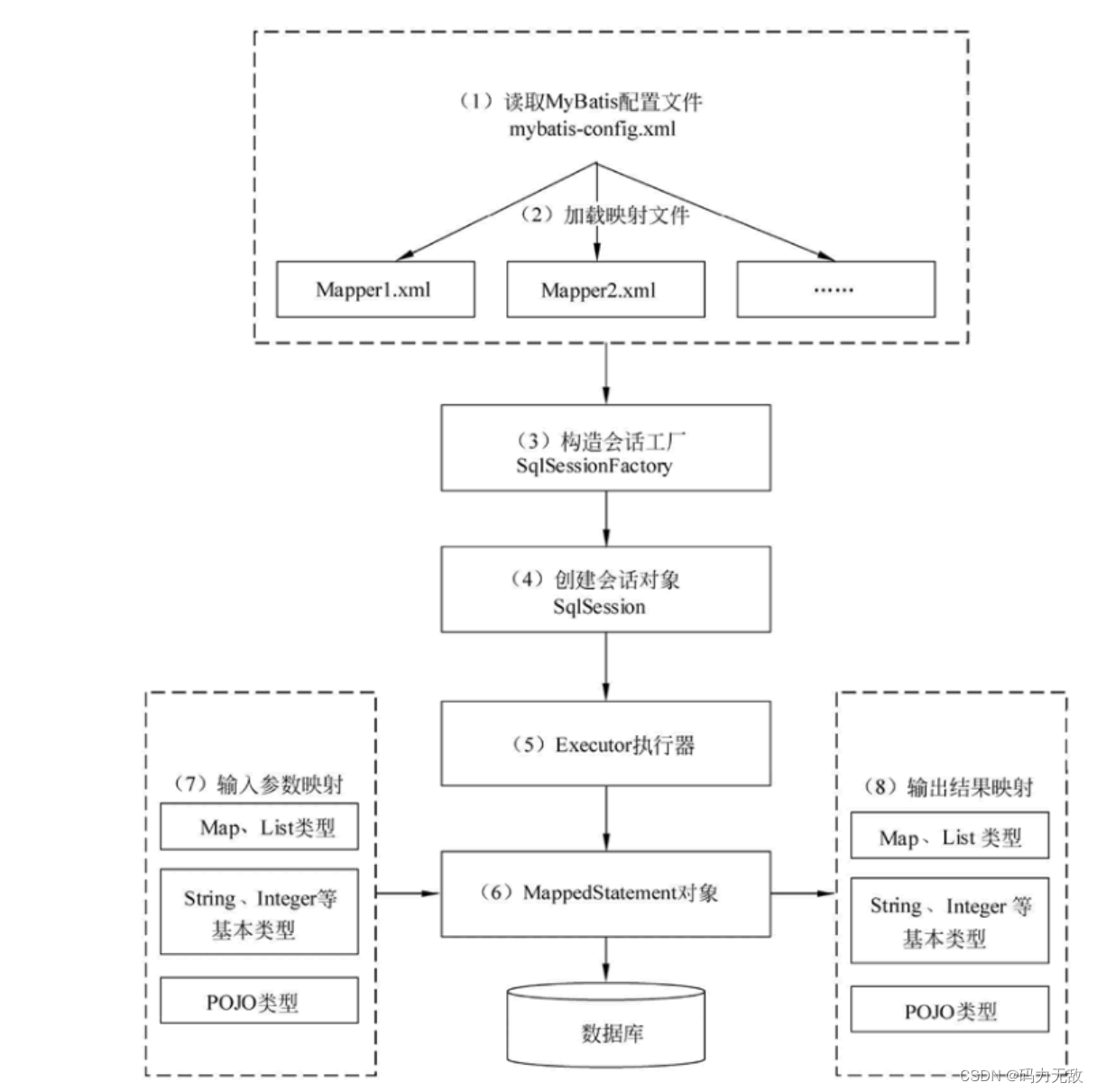
1)读取 MyBatis 配置文件:mybatis-config.xml 为 MyBatis 的全局配置文件,配置了 MyBatis 的运行环境等信息,例如数据库连接信息。
2)加载映射文件。映射文件即 SQL 映射文件,该文件中配置了操作数据库的 SQL 语句,需要在 MyBatis 配置文件 mybatis-config.xml 中加载。mybatis-config.xml 文件可以加载多个映射文件,每个文件对应数据库中的一张表。
3)构造会话工厂:通过 MyBatis 的环境等配置信息构建会话工厂 SqlSessionFactory。
4)创建会话对象:由会话工厂创建 SqlSession 对象,该对象中包含了执行 SQL 语句的所有方法。
5)Executor 执行器:MyBatis 底层定义了一个 Executor 接口来操作数据库,它将根据 SqlSession 传递的参数动态地生成需要执行的 SQL 语句,同时负责查询缓存的维护。
6)MappedStatement 对象:在 Executor 接口的执行方法中有一个 MappedStatement 类型的参数,该参数是对映射信息的封装,用于存储要映射的 SQL 语句的 id、参数等信息。
7)输入参数映射:输入参数类型可以是 Map、List 等集合类型,也可以是基本数据类型和 POJO 类型。输入参数映射过程类似于 JDBC 对 preparedStatement 对象设置参数的过程。
8)输出结果映射:输出结果类型可以是 Map、 List 等集合类型,也可以是基本数据类型和 POJO 类型。输出结果映射过程类似于 JDBC 对结果集的解析过程。
4.3 Mybatis都有哪些Executor执行器?它们之间的区别是什么?
Mybatis有三种基本的Executor执行器,SimpleExecutor、ReuseExecutor、BatchExecutor。
- SimpleExecutor:每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。
- ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map<String, Statement>内,供下一次使用。简言之,就是重复使用Statement对象。
- BatchExecutor:执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理。与JDBC批处理相同。
4.4 Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的就是一对一,collection指的就是一对多查询。在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false。
它的原理是,使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。这就是延迟加载的基本原理。
5.映射器
5.1 #{}和${}的区别?
- #{}是占位符,预编译处理;${}是拼接符,字符串替换,没有预编译处理。
- Mybatis在处理#{}时,#{}传入参数是以字符串传入,会将SQL中的#{}替换为?号,调用PreparedStatement的set方法来赋值。
- Mybatis在处理${}时, 是原值传入 ,就是把{}替换成变量的值,相当于JDBC中的Statement编译
- 变量替换后,#{} 对应的变量自动加上单引号 ‘’;变量替换后,${} 对应的变量不会加上单引号 ‘’。
- #{} 可以有效的防止SQL注入,提高系统安全性;${} 不能防止SQL 注入
5.2 在mapper中如何传递多个参数?
- 顺序传参法,where user_name = #{0} and dept_id = #{1},不推荐。
- @Param注解传参法,参数少的推荐。
- Map传参法,多个参数,比较灵活,确点是不直观。
- Java Bean传参法,这种方法直观,需要建一个实体类,扩展不容易,需要加属性,但代码可读性强,业务逻辑处理方便,推荐使用。
5.3 Mapper 编写有哪几种方式?
第一种:接口实现类继承 SqlSessionDaoSupport:使用此种方法需要编写mapper 接口,mapper 接口实现类、mapper.xml 文件。
第二种:使用 org.mybatis.spring.mapper.MapperFactoryBean:
第三种:使用 mapper 扫描器:
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="mapper 接口包地址
"></property>
<property name="sqlSessionFactoryBeanName"
value="sqlSessionFactory"/>
</bean>
- 1
- 2
- 3
- 4
- 5
- 6
mapper.xml 中的 namespace 为 mapper 接口的地址;
mapper 接口中的方法名和 mapper.xml 中的定义的 statement 的 id 保持一致;
6.Mybatis是如何进行分页的?分页插件的原理是什么?
Mybatis使用RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分页,而非物理分页,可以在sql内直接书写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页。
分页插件的基本原理是使用Mybatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的sql,然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数。
举例:select * from student,拦截sql后重写为:select t.* from (select * from student) t limit 0, 10
7.简述Mybatis的插件运行原理,以及如何编写一个插件。
Mybatis仅可以编写针对ParameterHandler、ResultSetHandler、StatementHandler、Executor这4种接口的插件,Mybatis使用JDK的动态代理,为需要拦截的接口生成代理对象以实现接口方法拦截功能,每当执行这4种接口对象的方法时,就会进入拦截方法,具体就是InvocationHandler的invoke()方法,当然,只会拦截那些你指定需要拦截的方法。
实现Mybatis的Interceptor接口并复写intercept()方法,然后在给插件编写注解,指定要拦截哪一个接口的哪些方法即可,记住,别忘了在配置文件中配置你编写的插件。
8.Mybatis的一级、二级缓存?
1)一级缓存: 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当 Session flush 或 close 之后,该 Session 中的所有 Cache 就将清空,默认打开一级缓存。
2)二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储,不同在于其存储作用域为 Mapper(Namespace),并且可自定义存储源,如 Ehcache。默认不打开二级缓存,要开启二级缓存,使用二级缓存属性类需要实现Serializable序列化接口(可用来保存对象的状态),可在它的映射文件中配置 ;
3)对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了C/U/D 操作后,默认该作用域下所有 select 中的缓存将被 clear。
十四、方案设计&架构能力?
1.限流的原理的基本方案?具体实现?如何实现分布式的限流?
2.如何实现秒杀系统?千万并发抢购原理和如何设计?
3.如何优化分布式订单系统?接口的调用顺序优化?
4.打日志的实现方式有几种?
- 最简单的方式,就是system.println.out(error) ,这样直接在控制台打印消息了;
- Java.util.logging ; 在JDK 1.4 版本之后,提供了日志的API ,可以往文件中写日志了;
- log4j , 最强大的记录日志的方式。 可以通过配置 .properties 或是 .xml 的文件, 配置日志的目的地,格式等等;
- commons-logging, 最综合和常见的日志记录方式, 经常是和log4j 结合起来使用;
- logback是java的日志开源组件,是log4j创始人写的,性能比log4j要好;
5.微服务中如何实现 session 共享 ?
在微服务中,一个完整的项目被拆分成多个不相同的独立的服务,各个服务独立部署在不同的服务器上,各自的 session 被从物理空间上隔离开了,但是经常,我们需要在不同微服务之间共享 session 。
常见的方案就是 Spring Session + Redis 来实现 session 共享。将所有微服务的 session 统一保存在 Redis 上,当各个微服务对 session 有相关的读写操作时,都去操作 Redis 上的 session 。这样就实现了 session 共享,Spring Session 基于 Spring 中的代理过滤器实现,使得 session 的同步操作对开发人员而言是透明的,非常简便。
6. 如何保证高可用?
- 系统拆分:微服务架构,将一个复杂的业务域按DDD的思想拆分成若干子系统,每个子系统负责专属的业务功能,做好垂直化建设,各个子系统之间做好边界隔离,降低风险蔓延。
- 解耦:该内聚低耦合,随着业务功能迭代,如何做到每次改动不对原来的旧代码产生影响。Spring 框架给我们提供了一个很好的思路,里面有个重要设计 AOP ,面向切面编程。方法调用前后,增加我们需要的额外处理逻辑。
当然还有一个重要思路就是事件机制,通过发布订阅模式,新增的需求,只需要订阅对应的事件通知,针对性消费即可。不会对原来的代码侵入性修改,是不是会好很多。 - 异步:如果是非实时响应的动作可以采用异步来完成,线程不需要一直等待,而是继续执行后面的逻辑。
- 重试:受 网络抖动、线程资源阻塞 等因素影响,请求无法及时响应,
- 补偿:采用补偿玩法,实现数据最终一致性。
- 备份:主从数据库。redis、kafka、MySQL。
- 异地多活:集群异地多活。
- 隔离:隔离属于物理层面的分割,将若干的系统低耦合设计,独立部署,从物理上隔开。
- 限流:而对于超过限制的流量,则通过拒绝服务的方式保证整体系统的可用性。
- 熔断:熔断,其实是对调用链路中某个资源出现不稳定状态时(如:调用超时或异常比例升高),对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联错误。
- 降级:可以对一些非核心的功能进行降级,降低系统压力,比如把商品评价、成交记录等功能临时关掉。弃车保帅,保证 创建订单、订单支付 等核心功能的正常使用。


