
热门标签
热门文章
- 1基于区块链的不动产登记电子证照应用服务系统设计方案---3.总体设计_基于区块链的可信电子证照方案设计
- 2Qt Design Studio使用场景
- 3Qt Quick QML 与 C++ 交互系列之二
- 4自然语言处理在智能客服中的实践与优化
- 5元学习Meta-Learning_元学习的情景训练
- 6一切皆是映射:AI的去中心化:区块链技术的融合
- 7macOS系统安装pycharm社区版本_pycharm社区版本下载mac
- 8火车票预售系统(JavaGUI)_网上购票系统java+gui界面
- 9快速查询的秘籍 —— B+索引的建立_索引 b+ 页中查询
- 10骨架算法(skeleton)的实现_skeleton3d函数图示
当前位置: article > 正文
Kylin的构建原理及简单优化 二_kylin rowkeys优化
作者:很楠不爱3 | 2024-06-10 06:58:40
赞
踩
kylin rowkeys优化
目录
5 Cube存储原理
在计算之前,会为每一个维度建立一个维度字典表
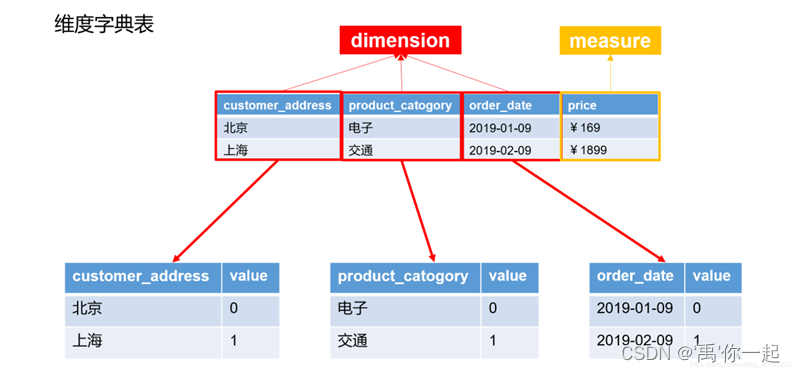
在HBase中存储的K是Cuboid+纬度值,其中Cuboid是指参与的维度数量,1为参与,0为不参与;纬度值指是以十六进制存储的取自于维度字典表中所对应得值。

6 使用衍生维度(derived dimension)
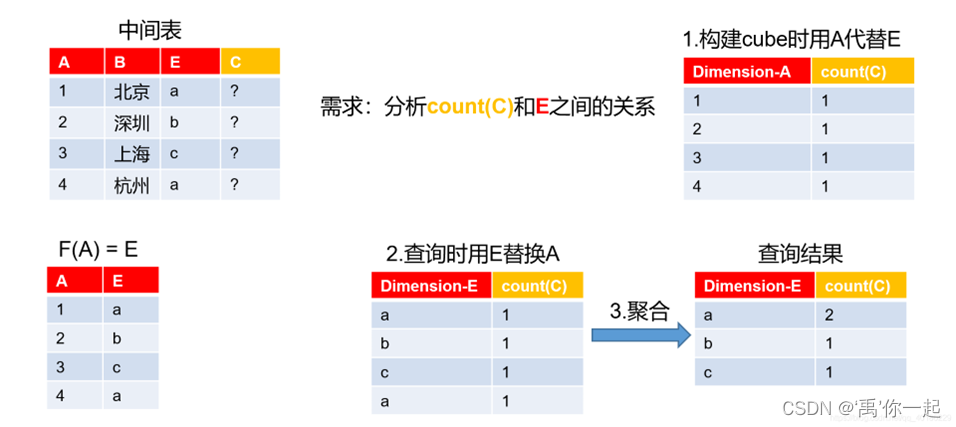
在kylin中属于构建优化,在选择维度表时有normal和derived,derived就是使用衍生维度。
加快了计算,减少了查询得速度
为了减少计算得cuboid
同一个维度表中,有选择derived时,不会真正参与构建,参与构建的是这个表对应事实表的外键
如果两者都存在,则有normal选normal,有derived 选择事实表主键
简单得来说,在维度表得字段选用了derived后,在进行预计算时,维度表得字段并不会真正参与,参与得是对应这个维度表中事实表得外键,查询时,用外键进行替换,最后进行聚合得到查询结果
最后尽量不要使用衍生维度
7 使用聚合组(Aggregation group)
属于构建优化
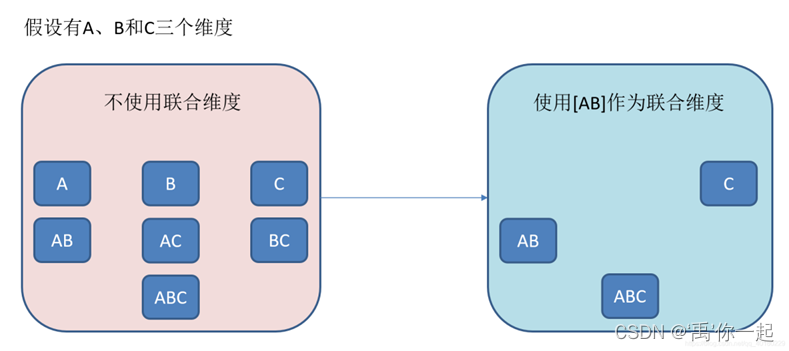
聚合组(Aggregation Group)是一种强大的剪枝工具
分为三种:强制维度,层级维度,联合维度
强制维度(Mandatory): 除了带有A维度的cuboid,其他都会被过滤

层级维度(Hierarchy):B要依赖A才能存在,A能单独出现,B不可以

联合维度(Joint):AB维度,要么都存在,要么都不存在
 8 Row Key优化
8 Row Key优化
Kylin会把所有的维度按照顺序组合成一个完整的Rowkey,并且按照这个Rowkey升序排列Cuboid中所有的行
设计良好的Rowkey将更有效地完成数据的查询过滤和定位,减少IO次数,提高查询速度,维度在rowkey中的次序,对查询性能有显著的影响。
被用作where过滤的维度放在前边。

基数大的维度放在基数小的维度前边。

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/很楠不爱3/article/detail/697636
推荐阅读
相关标签

