
热门标签
热门文章
- 1做独立开发者,能在AppStore赚到多少钱?_app独立开发者 收入
- 2浅谈大模型 SFT 的实践落地:十问十答_bert和llm的区别
- 3React项目封装axios网络请求文件(初级)_react项目中标准的request文件封装
- 4linux之某命令负载很大
- 5深入浅出理解机器学习算法—神经网络(前向传播)_深入浅出神经网络
- 6网站暴力破解入门
- 7cmd 命令行执行 Python 脚本_cmd执行python脚本
- 8详解汽车数字钥匙(Digital Key)规范_汽车电子 钥匙位置信息识别 csdn
- 9决策树案例:基于python的商品购买能力预测系统
- 10Docker 实战:使用 Docker Desktop 在 MacOS 上安装 Docker_dockerdesktop
当前位置: article > 正文
大模型三阶段训练
作者:很楠不爱3 | 2024-06-17 14:31:53
赞
踩
大模型三阶段训练
为了训练专有领域模型,选择LLaMA2-7B作为基座模型,由于LLaMA模型中文词表有限,因此首先进行中文词表的扩展,然后进行三阶段训练(增量预训练,有监督微调,强化学习)。
代码将全部上传到github:
https://github.com/hjandlm/LLM_Train
欢迎关注公众号

1. 中文词表扩展
原生词表大小是32K,在词表扩展后,词表大小是63608。
2. 增量预训练
为了防止模型的通用能力减弱或消失,将通用数据和领域数据混合,经过调研决定设置5:1的数据配比进行增量预训练。由于资源有限,显卡是一块A100,40G,因此训练较慢。
目前还处于预训练阶段,情况如下:
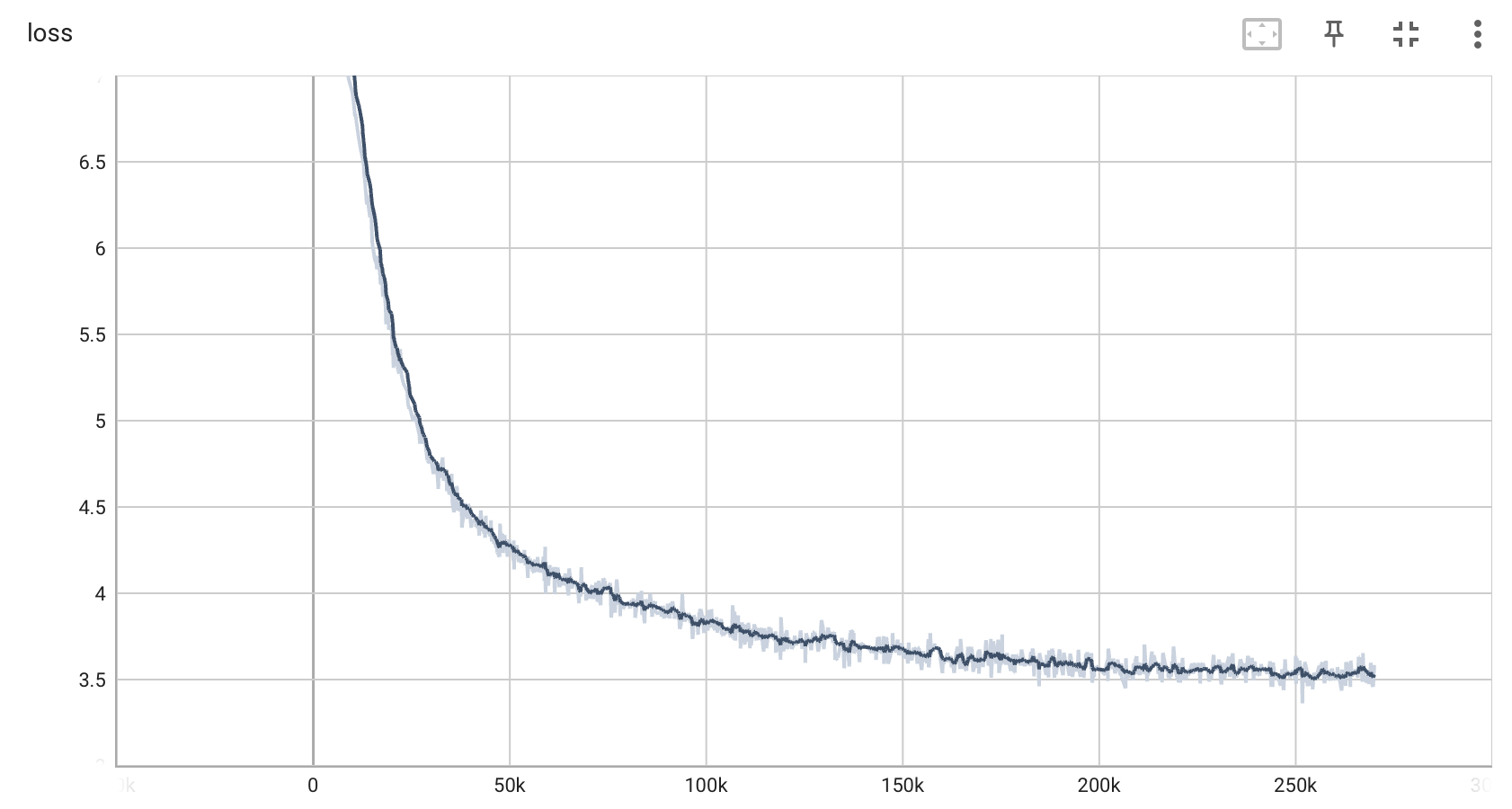
训练集损失曲线:
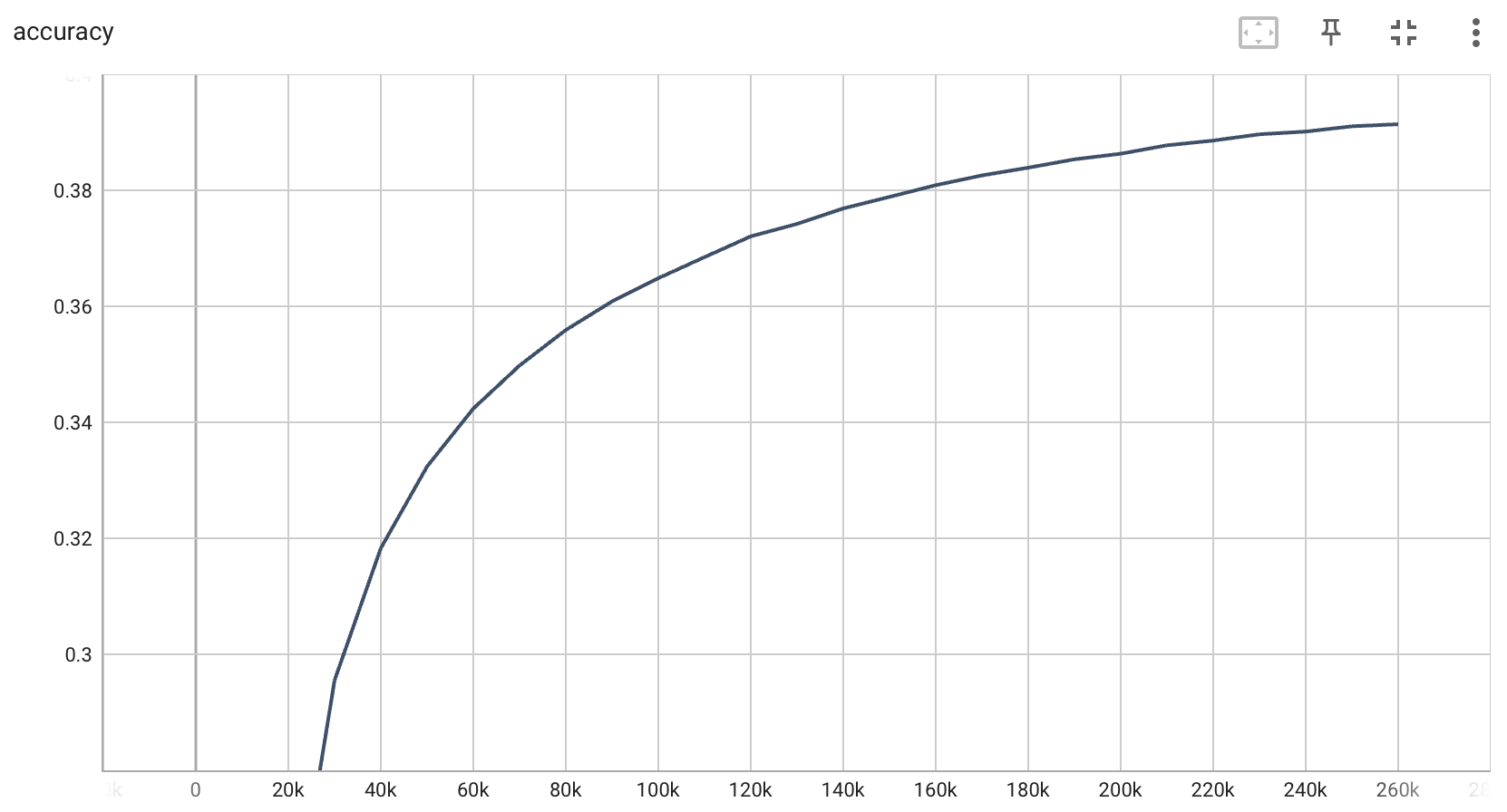
测试集准确率曲线:
测试集损失曲线:
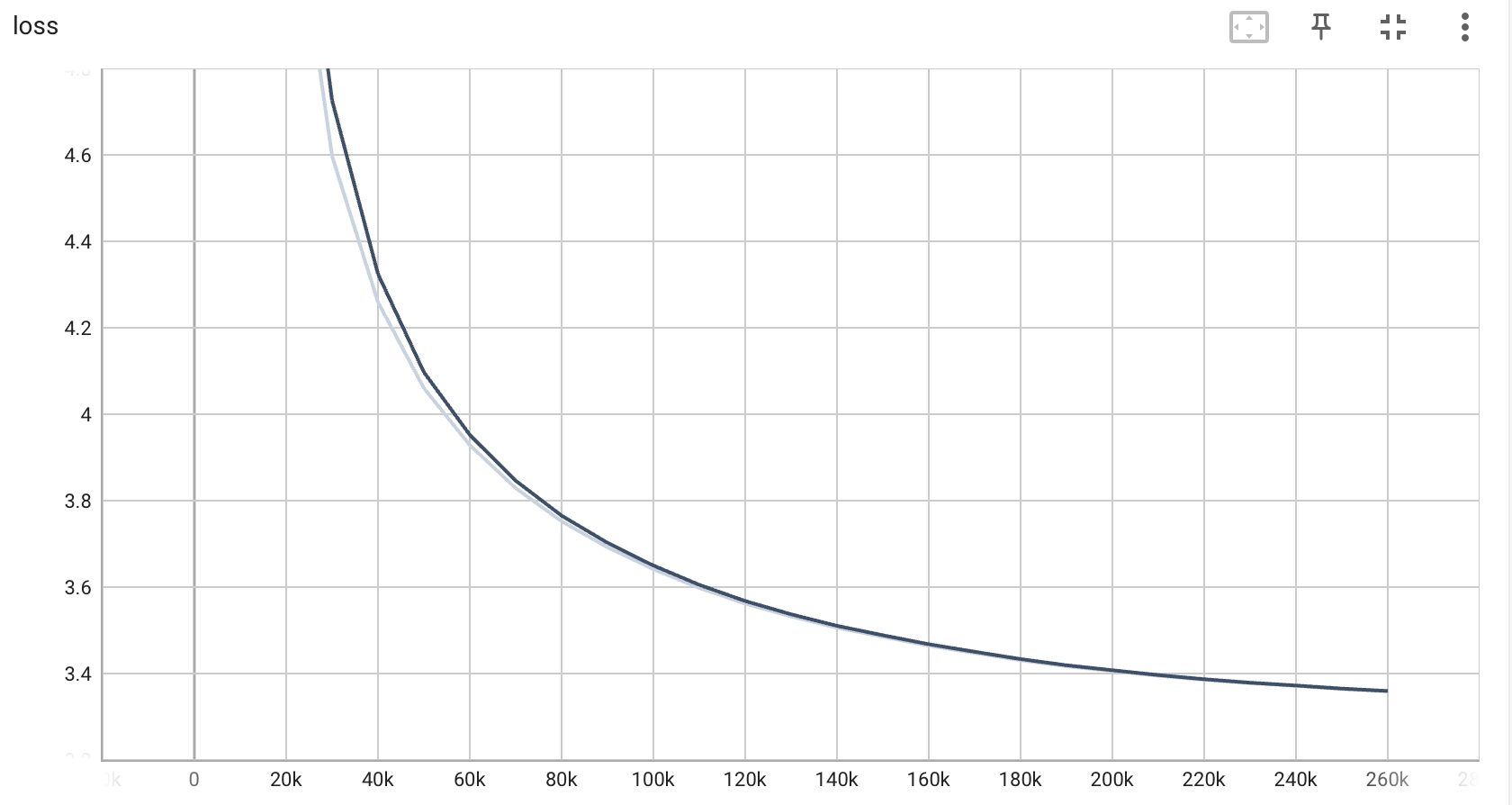
训练集损失曲线、测试集准确率曲线、测试集损失曲线已经趋于平衡,表示模型已经收敛到一个相对稳定的状态。
3. 有监督微调
…
4. 强化学习
…
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/很楠不爱3/article/detail/731587
推荐阅读
相关标签

