
从Oracle 23 AI:又甩开国产数据库几条街_oracle 23ai
赞
踩
昨天蓝星最强的关系型数据库Oracle发布了最新版的Oracle 23 Ai,实际上很早之前我们就测试并了解了一些Oracle 23c的内容,没想到正式Release的时候,直接改名为Ai版本了。 难道是因为现在Ai很火或者是Larry很狂? 我想这次正式版本的rename应该不是单纯的为了营销,那么一定是软件在Ai方面有很多创新。
Oracle 23 Ai Vector Search
实际上之前我已经大致看过了Oracle 23c的New Features了,不知道这次rename后的23 Ai版本,是否有会一些新的变化。
基于我个人的理解,这里我给大家总结一下,我认为23 Ai版本一些比较强悍的地方(这块应该够国产数据库学很多年了)。
首先我们来看看Oracle目前走在最前沿的地方,Ai vector,如下是一个示意图:
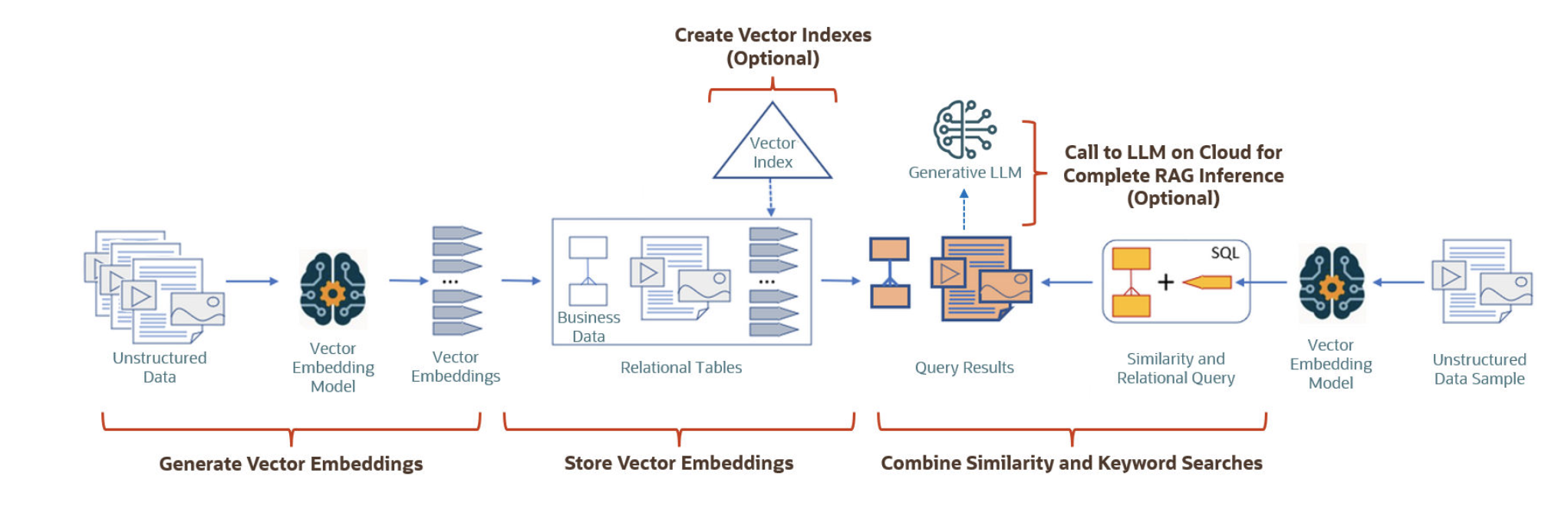
实际上对于向量化,在12.2版本就开始出现了,针对OLAP场景一种优化技术;这个技术在后面版本中不断迭代进步。
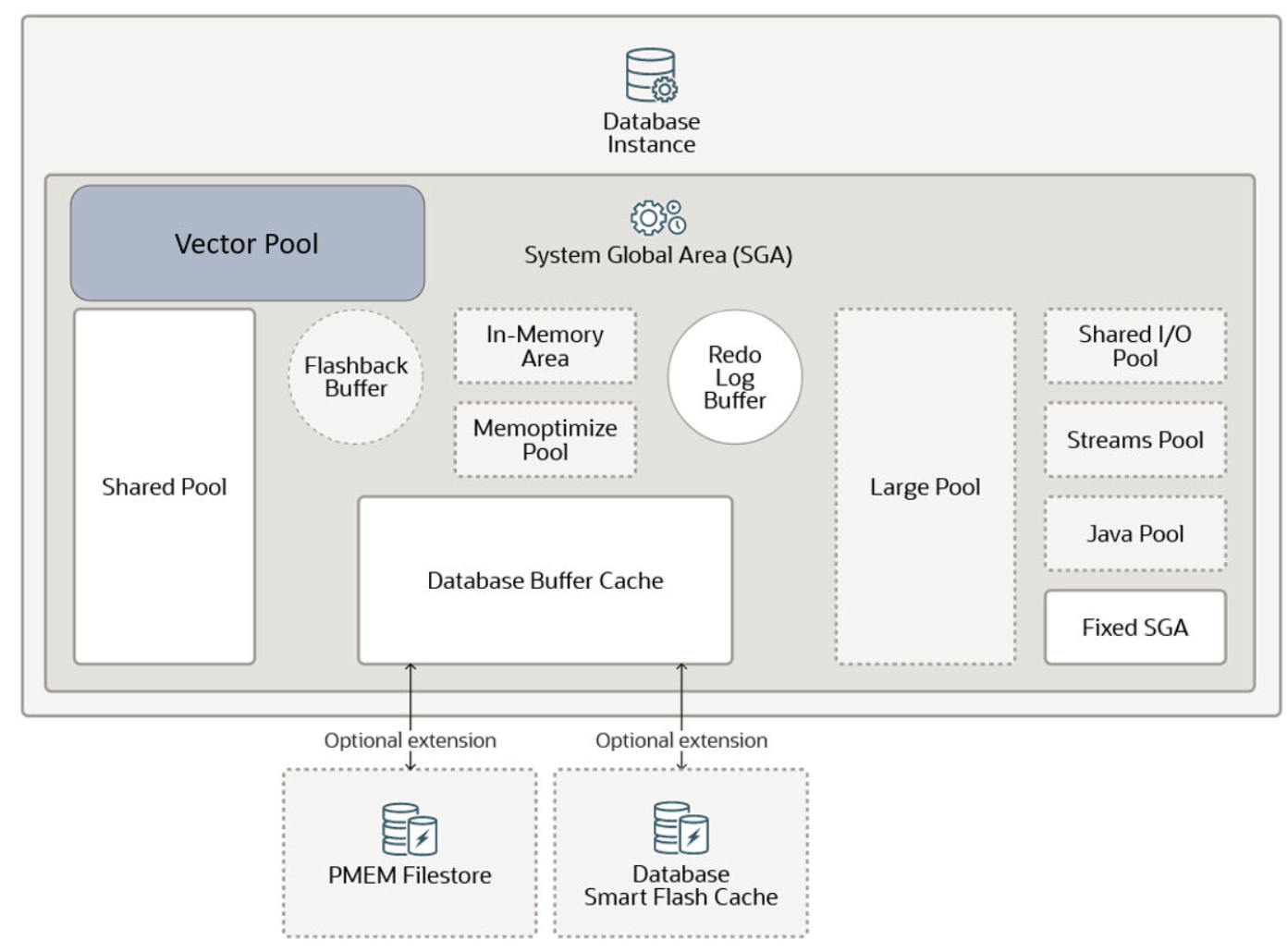
从23 Ai版本的架构来看,针对Ai Vector检索,引入了一个新的内存结构Vector Pool,该内存结构也位于SGA中,且需要单独设置vector_memory_size来实现。该内存结构主要存vector相关的一些元数据信息等内容。
从文档介绍来看还支持In-Memory Neighbor Graph Vector Index、Neighbor Partition Vector Index等(从这个角度来看,以后图数据库可以淘汰了)。 除此之外,23 Ai版本的vector search功能,还支持很多SQL function 操作,并且还支持通过PlSQL代码来进行调用,也就是说提供了Pl/SQL APIs;翻了一下文档,其实就是提供了2个新的PL/SQL Package. dbms_vector、dbms_vector_chain。
老实说,虽然现在Ai各种满天飞,实际上我认为Database Ai还比较早,还需要很长一段时间才会成熟,因此这部分功能我反而不是很关心;我更关心的是其中的OTLP and Core database部分,这才是数据库内核的关键所在。
Changes in Oracle Globally Distributed Database for Oracle Database 23ai
这是Oracle 23 Ai版本中gds的增强部分,其实GdS也出来了很多年了,从Oracle 12.2 shareding 就开始了。 曾经记得很多年之前,国内互联网几乎天天讲shareding,没想到没多久Oracle 也推出了自己的sharding。早期版本的gds中还需要依赖goldengate,从23 Ai版本开始,彻底废弃了GolgenGate的依赖,以后gds不再支持Goldengate了。
这里说说其中几个非常关键的特性。
Raft Replication
Directory-Based Sharding
Synchronous Duplicated Tables
Fine-Grained Refresh Rate Control For Duplicated Tables
Sharded Database Coordinated Backup and Restore Enhancements
Automatic Data Move on Sharding Key Update
Move Data Chunks Between Shardspaces
PL/SQL Function Cross-Shard Query Support
Pre-Deployment Network Validation
Parallel Cross-Shard DML Support
特性实在是太多了,我这里还没罗列完毕,大家可以去看看官方文档,这里我对raft replication是非常感兴趣的,我想大家应该也一样。
我的第一感觉,raft replication,这玩意儿不是分布式数据库才有的东西吗?Oracle引入这个干什么呢?或许从这一刻开始,我们不能说Oracle说集中式数据库了,它说一个真正的分布式数据库了(尽管Oracle 12.2 就引入了sharding,我认为之前的版本都很鸡肋)。
对于raft replication,Oracle这里有3个比较重要的概念:raft unit,raft group,raft factor.
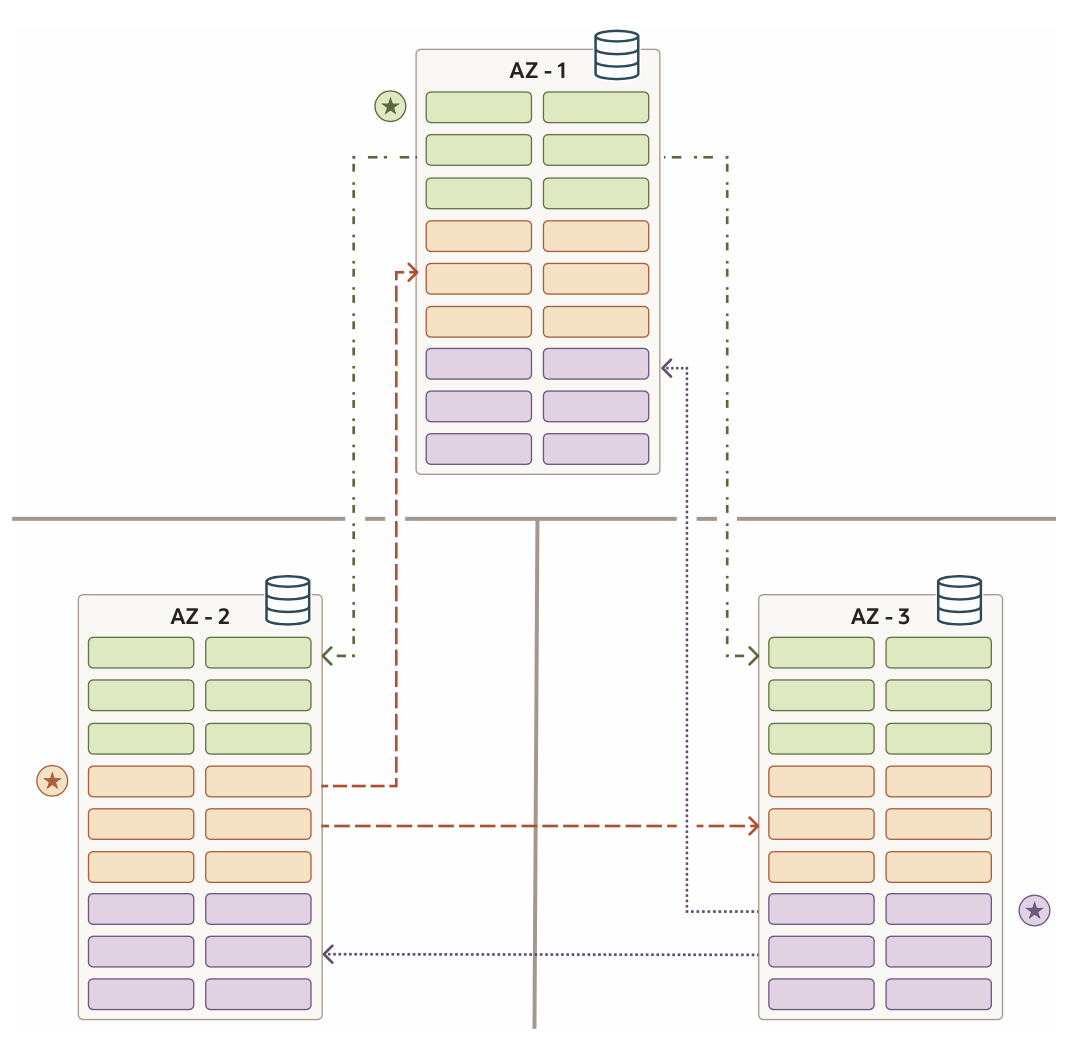
从上面的示例图可以看出,其中有3个AZ区,3个raft replication副本,其中leader和fellower 都位于不同的AZ。
另外 Raft factor是什么意思呢?从Oracle 文档的解释来看,Raft factor的含义就是指raft group中的副本数量。其中rf可能的取值为3或者5,3表示可以容忍一个副本失效,5表现可以容忍2个副本失效(遵循多数派原则)。
如果Leader副本遭遇节点或者AZ级别的故障,整个shared集群是会进行自动选主,当节点或者AZ恢复之后,会自动加入集群。
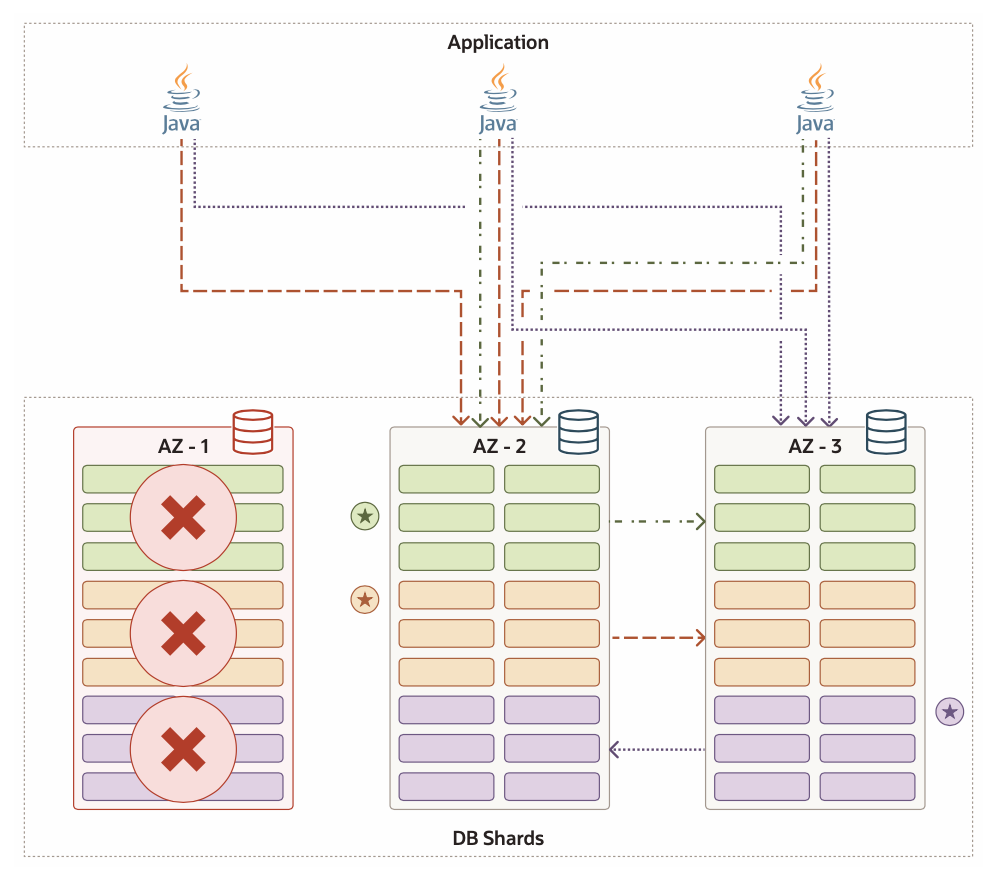
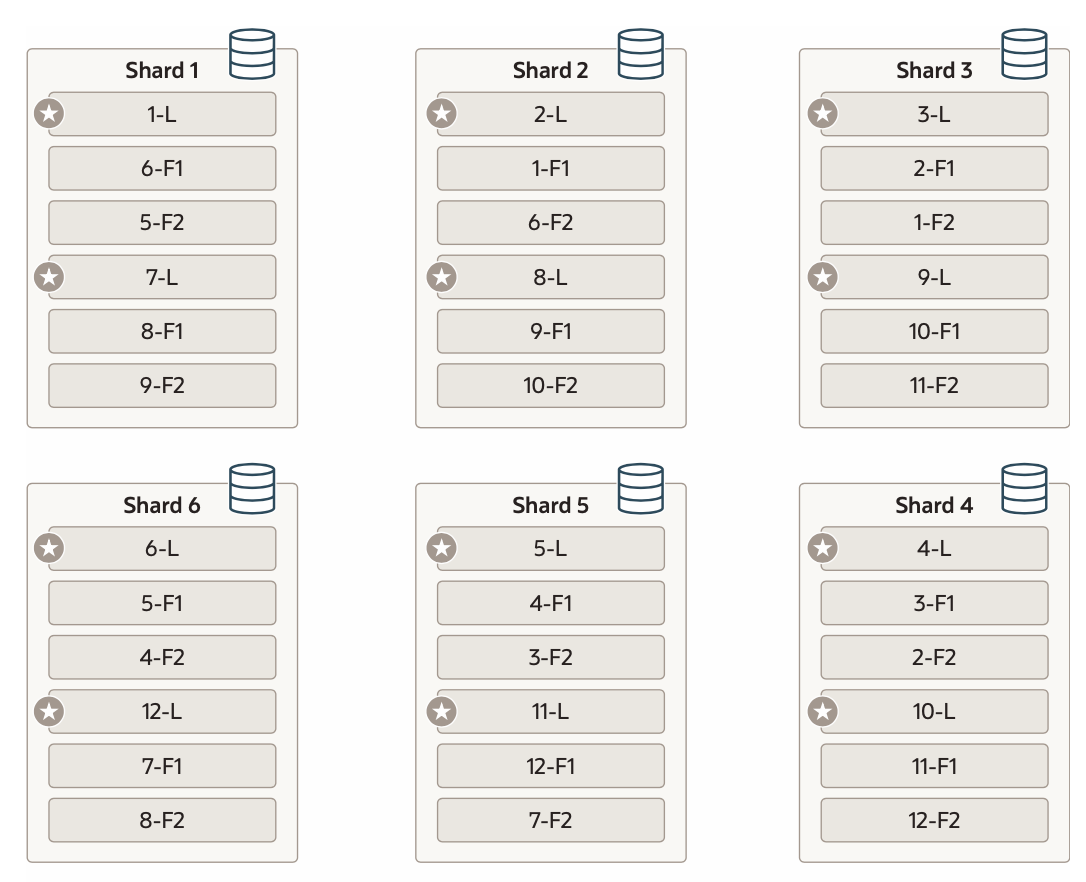
如果是fellower副本节点故障,leader节点会不断尝试去往异常节点复制raft log,或者你此时也可以部署一个心的fellower节点。 这里分享一个相对完整的架构图,其中L表示leader,F表示fellower 副本。
23Ai版本中的多租户增强
这块儿新特性其实我认为也非常不错,主要就2个关键核心功能(我个人认为哈),分别有如下2点: Hybrid read-only mode for pluggable databases
Control PDB Open Order
第一点这里我就不再过多阐述了,实际上很早之前我就做过技术分享了,这里贴一下之前的测试例子。
++Session 1
SQL> create user C##test identified by test123;
User created.
SQL> grant connect,resource,dba to C##test;
Grant succeeded.
SQL> grant connect,resource,dba to C##test container=all;
Grant succeeded.
SQL> alter pluggable database enmopdb1 close immediate;
Pluggable database altered.
SQL> alter pluggable database enmopdb1 open hybrid read only;
Pluggable database altered.
++Session 2
SQL> conn C##test/test123@enmopdb1
Connected.
SQL> select CON_NAME,OPEN_MODE,CPU_COUNT,CON_ID,RESTRICTED,IS_HYBRID_READ_ONLY from v$container_topology;
CON_NAME OPEN_MODE CPU_COUNT CON_ID RES IS_
------------------------------------------ ---------- ---------- ---------- --- ---
ENMOPDB1 READ WRITE 16 3 NO YES
SQL> select name, open_mode from v$pdbs;
NAME OPEN_MODE
------------------------------------------ ----------
ENMOPDB1 READ WRITE
SQL> create table t0711(a number);
Table created.
SQL> insert into t0711 values(1);
1 row created.
SQL> commit;
Commit complete.
SQL> select * from t0711;
A
----------
1


- 1
可能有人会问,这个混合read only pdb有什么用呢?或者说有什么应用场景? 实际上有了这个小功能之后,超级管理员可以很方便的对只读pdb进行维护,这难道不香吗?
对于第二点,我个人还未进行测试,从官方文档介绍来看主要有几个功能,其中有2个我认为是非常实用的,比如单独对某个pdb的状态进行修改以及进行pdb级别的failover、switchover操作。这真的是非常的给力。
实际上对于修改单个pdb的状态(open、restoration、upgrade 3种模式),非常的实用,想想几年前我们修复一套12.2 cdb多租户数据库的时候,恢复好一些pdb之后,本来想暂时恢复部分业务,但是发现在恢复其他pdb的时候,还需要反复去操作cdb甚至重启,因此就非常的麻烦。这个难点,看上去在23 Ai版本讲不复存在了。
ASM 增强
曾经处理过很多次ASM故障了,其中我认为比较经典的场景是一个用户的ASM diskgroup中的磁盘组使用不均匀,有些磁盘使用率高,有些比较低,到个别磁盘free接近0的甚至等于0的时候,该diskgroup 是无法进行reblance操作的。我想应该不少人都遇到过类似的场景吧。
在Oracle之前的磁盘组支持磁盘组和文件级别的Scrubbing 操作,而在最新的23 Ai版本中,已经支持Scrubbing extent了,可不能忽略这个小小的改进。我认为是非常实用的。 或许从这个版本开始,ASM的管理真的做到极致了,以前那些磁盘实用不均衡的场景,可能再也看不到了。
函数自动转换成表达式
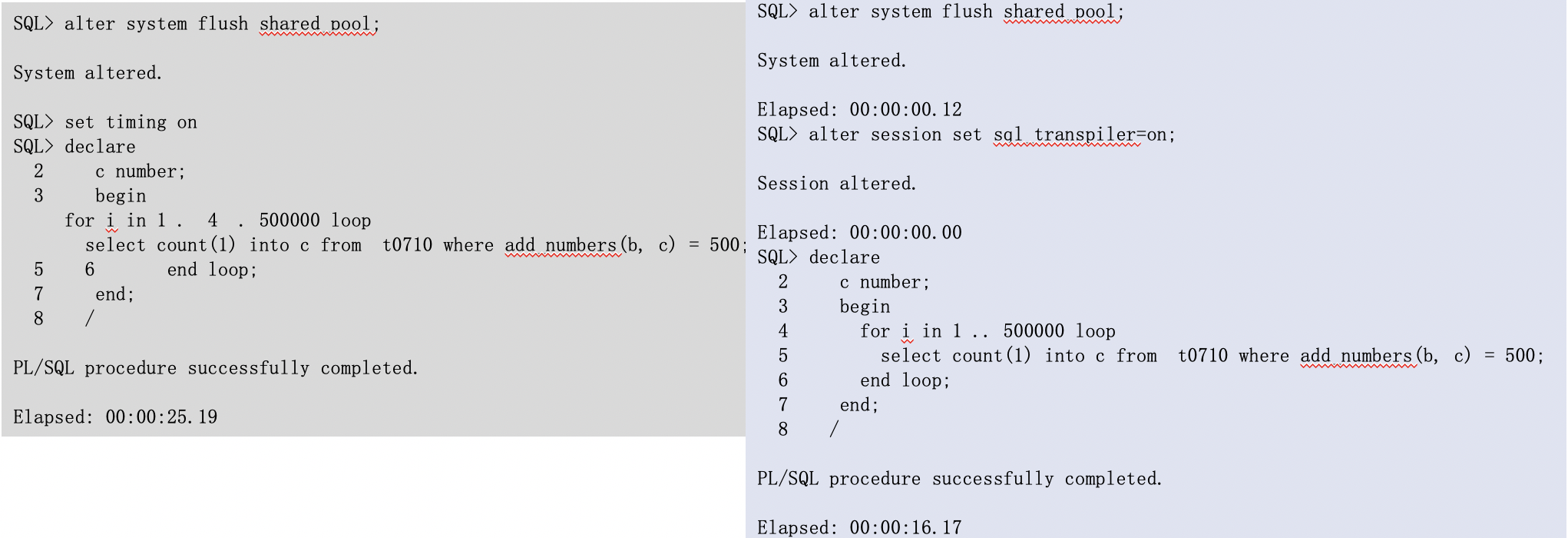
这个小功能我认为也是非常值得讲的,因为提升不小的性能,这就是sql_transpiler(这个功能我们在几个月前就已经提交给MogDB 内核研发了,或许很快国产数据库也将具备这个特性)。
SQL> alter session set container=enmopdb1;
Session altered.
SQL> conn roger/roger@enmopdb1
Connected.
SQL> create table t0710 (
2 a number,
3 b number,
c number
); 4 5
Table created.
SQL> insert into t0710 values (1, 2, 3), (2, 20, 30), (3, 200, 300);
3 rows created.
SQL> commit;
Commit complete.
SQL> create or replace function add_numbers(p1 in number, p2 in number)
2 return number as
3 begin
4 return p1 + p2;
5 end;
6 /
Function created.
SQL> set autot on
SQL> select a, b, c from t0710 where add_numbers(b, c) = 500;
A B C
---------- ---------- ----------
3 200 300
Execution Plan
----------------------------------------------------------
Plan hash value: 925956317
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 39 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T0710 | 1 | 39 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("ADD_NUMBERS"("B","C")=500)
SQL> alter system flush shared_pool;
System altered.
SQL> alter session set sql_transpiler=on;
Session altered.
SQL> select a, b, c from t0710 where add_numbers(b, c) = 500;
A B C
---------- ---------- ----------
3 200 300
Execution Plan
----------------------------------------------------------
Plan hash value: 925956317
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 39 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T0710 | 1 | 39 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("B"+"C"=500)
- 1
最后给大家看下测试对比,性能大概可以提升36%。
另外23 Ai版本在机器学习、向量化等、运维(自动化诊断框架)、可视化、安全等方面都有极大的增强,新特性太多,大家自行去看看官方文档吧。
如果大家对国产数据库MogDB有兴趣或者想了解更多细节,可以关注MogDB公众号,后续会有一系列技术文章和视频推出! MogDB 技术讨论群已经满,如有兴趣,可以添加我的微信(Roger_database),我邀请入群!

本文由 mdnice 多平台发布

