- 1服务器基本故障排查方法_服务器故障排除
- 22024美赛数学建模D题思路分析 - 大湖区水资源问题_2024美赛d题
- 3python3+scapy扫描获取局域网主机ip和mac_python3写arp扫描mac和ip地址对应程序
- 4vue中element UI的 select值改变,内容改变方法_vue的select控件change方法
- 5保姆级教程:从0到1使用Stable Diffusion XL训练LoRA模型 |【人人都是算法专家】_stable diffusion xl 加载lora模型
- 6Midjourney 完整版教程(从账号注册到设计应用)_midjouney 创作从入门到应用
- 7深入浅出ES6的标准内置对象Proxy_proxy {} originaltarget
- 8Conda 快速入门,轻松拿捏 Python
- 9【Android 插件化】VirtualApp 源码分析 ( 安装应用源码分析 | HomePresenterImpl 添加应用 | AppRepository.addVirtualApp )_virtualapp 添加不了
- 10Android下相机的调用
Sora给中国AI带来的真实变化
赞
踩
OpenAI的最新技术成果——文生视频模型Sora,在春节假期炸裂登场,令海内外的AI从业者、投资人彻夜难眠。
如果你还没有关注到这个新闻,简单介绍一下:Sora是OpenAI使用超大规模视频数据,训练出的一个通用视觉模型,可以理解和模拟运动中的物理世界,生成不同时间、纵横比和分辨率的视频,最大版本的Sora能够生成长达一分钟的高保真视频。
Sora发布之前,也有许多采用各种方法的视频生成模型,但都使用较少的视觉数据,只能生成较短(4秒)或固定大小的视频。所以,Sora逼真的视觉效果、碾压级的性能提升,在震撼整个科技圈之余,也导致了“中国AI焦虑症”的人传人现象。
广大网友们再一次痛心疾首,对中国A发出质问:
为什么又一个AI元创新没能发生在中国?我们点错了科技树,好难过;
中国跟美国的AI差距越来越大,Sora这波国内慢了十年吧?这下真跟不上了;
复制Sora算力是最大阻碍,从芯片禁运开始咱们就完败了,没戏了。
当然也不乏阴阳怪气的,“等国外的类Sora模型开源,国內AI公司就又能创新啦”。

在中美对弈的时代背景下,上述焦虑情绪,每一次在海外科技取得重大突破的时候,都会蔓延开来。但时间证明,作为全球唯二的AI大国之一,中国发展了多年AI技术,就算美国真有什么新AI成果是其他国家做不了、赶不上的,那也绝对不是中国。
拿并不遥远的ChatGPT来说,经过一年狂奔,“中国有没有自己的ChatGPT”已经不再成为问题。2023年很多国产“类ChatGPT”大语言模型已经向公众开放使用,走进行业场景,有数亿用户检测过中国AI的真实水平,或许与OpenAI还存在差距,但肯定不是一些人担忧的那样,认为“中国做不到”“技术有代差”。
这就像我们经常会看到一类“震惊体”新闻,一种新药问世,就说人类离永生不远了;一个AI突破,就说AGI要实现了,人类要被毁灭了。读者在这些奇谈怪论中“死去活来”,对AI的认知也在“成神”和“骗子”之间反复横跳。而真正懂药的人,肯定不会相信一种药能包治百病,而是搞清楚疗效和副作用,在对应的症状上使用。
同理,真正了解AI产业的人,也能正视中国AI的长处,承认现实差距,不卑不亢,积极应对。
尤其是经过了ChatGPT的“练兵”之后,这一次我们应该更有底气,客观看待Sora对中国AI带来的真实变化,准备迎接又一个“AI之春”。
变化一:拉近差距
在“ChatGPT为什么没有诞生在中国?”之后,龙年版本已经成了“Sora为什么没有诞生在中国?”接连两次错失“元创新”,让期待中国AI“弯道超车”“后来居上”的急性子读者,大感失望。
科技发展从来不是一步登天,现实并没有爽文小说中逆袭打脸的“金手指”,只能是一步一个脚印迈进。不能否认,大语言模型、文生视频模型的颠覆性产品,没有首发在中国,但也必须看到,中国AI一直都在正确的道路上,并且脚步在加速。

Sora的发布,反而会让中美AI的距离进一步拉近,原因有三:
首先,方向一致。
错过一场技术革命,最可怕的不是来得晚,而是点错技能树,比如历史上日本大力发展的“五代机”,选错方向就错过了一个时代。OpenAI的ChatGPT、Sora都是在大规模预训练模型的技术路径上,进行大量的工程实践创新。由此可见,一项新突破,技术积累、技术选型是十分重要的,而这条以Transformer架构为主的“大模型之路”,中国AI一直在持续跟进,基础设施和算法层面的坚实程度是肉眼可见的。
其次,目标明确。
OpenAI的元创新让人应接不暇,处于全球AI领先地位,中国AI企业确实与其存在差距,始终在追赶。但这并不是讽刺中国AI的理由。“没有从头发明xx技术”,并不代表不优秀,OpenAI也不是Transformer发明者。而且,OpenAI本身就是一家集合了全球顶尖人才、力量与资本的特殊AI公司,就连谷歌都跟在后面屡败屡战,用OpenAI的标准去要求各方面资源受限的中国AI产学研机构,其实是不公平的。
Sora明确了,“视频生成模型是一条构建物理世界通用模拟器的有效路径”,印证了暴力计算的又一次胜利,“Scaling Law”大力出奇迹的涌现效果,相当于为中国AI领域完成了“探路”。有了清晰的追赶目标,中国AI各界反而能快速整合资源、投入研发,从而进一步拉近中美在文生视频上的距离。和ChatGPT一样,中国AI做出“类Sora”也是必然的,绝不可能错过这一波或者彻底跟不上。
最后,能力具备。
或早或晚,中国一定会做出“类Sora”,但到底是三年后、五年后,还是十年后?我们认为,2024年应该就会看到国产Sora问世。无论是Sora所用到的基础模型LLM、文生图模型DALL·E 3、大规模视频数据集、AI算力体系、大模型开发工具栈等核心基础设施,中国都已经具备。比如原创的基础大语言模型文心一言、讯飞星火、BAICHUAN等,以及文生图模型文心一格、腾讯混元等,加上过去一年大模型存算传基础设施的突飞猛进,有能力和条件支持中国AI修成正果,在视频生成赛道再现 类ChatGPT 式的成功。
面对Sora,中国AI努力追赶是必须的,但数一数行囊中的工具和果实,不必妄自菲薄,更不用乱了阵脚。沿着正确且清晰的道路,加速向前跑,中美AI的差距才能缩小。
变化二:
国产大模型格局再优化
和LLM一样,不会出现Sora在全球一枝独秀,而国内却无视频生成模型可用的情况。衷心希望,我们在不久的未来,不会像LLM百模大战一样,从担忧“中国没有Sora”,转而担忧“中国要那么多Sora怎么用”。
从这个角度看,OpenAI从ChatGPT到Sora的持续输出,会让国内AI大模型市场少一点虚火,多一分理性。
少一点虚火,是指底层模型的重要性,被Sora再一次“划重点”,避免国产大模型低水平的重复建设。
2023年一个又一个大语言模型被训练出来,推向市场,其中原创性的基础模型占比最小,更多是行业大模型,以及很多私有化部署的大模型,在数据规模、参数规模上无法与基座模型相提并论,生成效果也会差很多。这种低水平的重复建设,也会造成AI算力、投资的浪费。
而Sora在视频领域的惊艳表现,再次证明了暴力美学的有效性,将曾经大火的AI视频创业公司的模型直接碾压。正如OpenAI CEO奥特曼在YC W24 启动会上的演讲中所说:最正确的做法是设想一个“上帝般的”模型正在运作,然后基于这种设想来构建最好的产品。

对中国AI来说,将为数不多具有底层原创能力的基座模型,如文心、星火等,作为大模型基础设施与支柱,支持初创企业和千行百业做好精调、优化,避免“重复造轮子”,是非常重要的。
多一分理性,是在被Sora惊艳的同时,也要想到应用和商业化的渐进性,以更合理的方案来进行国产类Sora的开发。
类ChatGPT的大语言模型在狂奔一年之后,在与各个行业结合的过程中,已经暴露出实际应用场景局限、商业价值虽有但不多、大模型投入产出比较低的挑战。如何用好大模型,已经成为中国AI的关键考验。
相比“人人皆可上手”的大语言模型,视频生成模型的应用门槛更高,受众群体更小,目前OpenAI仅开放给创作者使用,而非像ChatGPT那样开放给大众。不难看到,视频生成模型从研发到落地,整个过程会更加缓慢,应用潜力与商业出口还有待探索。
这一方面留给中国AI产学各界了较长的追赶窗口期,同时,由于Sora能够激活多大的商业价值尚不明确,除了字节跳动、流媒体平台等要全力投入,其他科技企业和初创公司都要考虑到商业化的问题,为创作、商用场景打磨好工具,做好视频生成模型的提示词工程,以便非专业背景的广大行业用户们上手使用。
大模型的价值需要商业化来证明,Sora也不例外。视频生成模型走向行业的长跑,才刚刚开始。在更广袤的产业空间里,如何让类Sora产品带来真实价值,这个答案OpenAI没有给,美国AI不会给,只能由中国AI自己来书写,而这也是国內更胜一筹的地方。
变化三:
长期动能的查漏补缺
不必焦虑Sora,并不意味着中国AI就能躺平“坐看云卷云舒”了。必须承认,国产大模型还有很多瓶颈尚待解决。
Sora模拟物理世界的通用能力,不仅可以用于影视制作等内容创意行业,还可以为游戏、自动驾驶、工业数字孪生、电商、文旅等各行各业,提供一个构建虚实融合世界的技术支柱。
那么问题来了,国产Sora一定会出现,但我们做好各行业规模应用Sora的准备了吗?恐怕今天的答案还是,没有。
前面提到,Sora的“暴力美学”再次证明了Scale的价值。而要达到涌现效果,基座模型仍然高度依赖于大量高质量数据集,超大规模算力,大量工程化调优人才,以及由此带来的巨大开发及运行成本。
即使背靠微软云的OpenAI,也没有面向公众开放使用Sora,也没有向开发者开放API接入,就连正式开放使用的时间表都欠奉。国产AI本就存在的专项算力紧缺问题,在Sora问世之后变得更加紧迫。
同时不难预料,为了进一步阻截中国AI的发展,围绕AI算力的新一轮限制一定会来。完善和发展AI基础设施,构建自主可控的产业链,让大语言模型、视频生成模型等新AI技术都不缺席中国式现代化的进程,让算力成为中国数字经济长期发展的动能,中国计算行业依旧重任在肩。
此外,在中美AI差距中,数据的规模与质量成为越不过的门槛。2023年5月英国《经济学人》提出,中国在建立基础模型方面比美国落后两到三年,造成这一差距的首要原因就是数据,AI模型在训练时难以充分利用互联网内容。
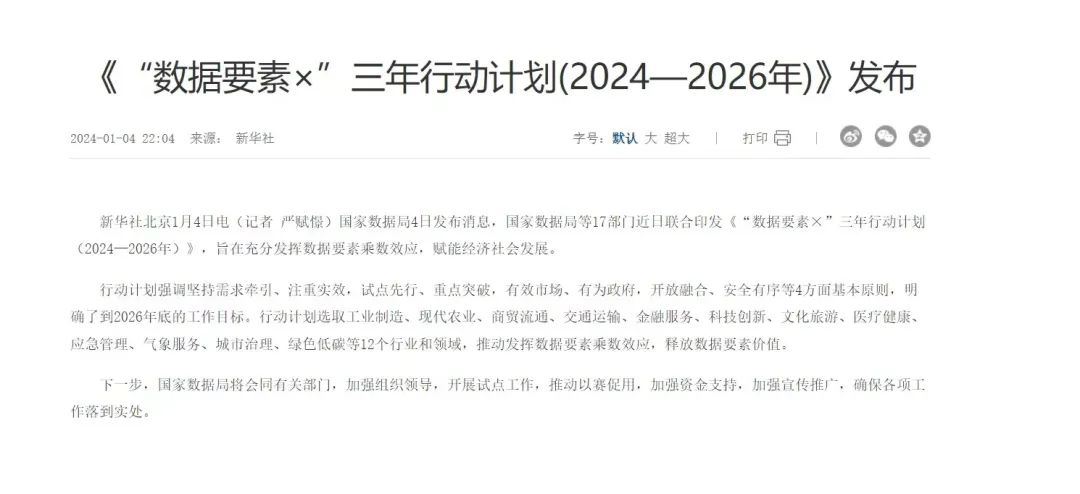
针对这一现状,2023年12月15日,国家数据局同中央网信办、科技部、工业和信息化部等17个部门联合印发《“数据要素×”三年行动计划(2024—2026年)》,目标是到2026年底,数据要素应用场景广度和深度大幅扩展。2024年,我们一定会见证该行动的推进与落地,见证数据要素成为国产AI的养料。
由此可见,中国AI的查漏补缺,不是一朝一夕的事,也不是某一家AI企业、某一个模型厂商的事,面对已经在行动的中国产业各界,何妨多一些耐心。
智者不惑,仁者不忧,勇者不惧。正视Sora给中国AI带来的变化与挑战,不为一时的缺席而焦虑,是相信我们有能力登场,也终将登场。