
剖析NLP历史,看chatGPT的发展_实现 chatgpt wordvect nlp
赞
踩
1、NLP历史演进
1.1 NLP有监督范式
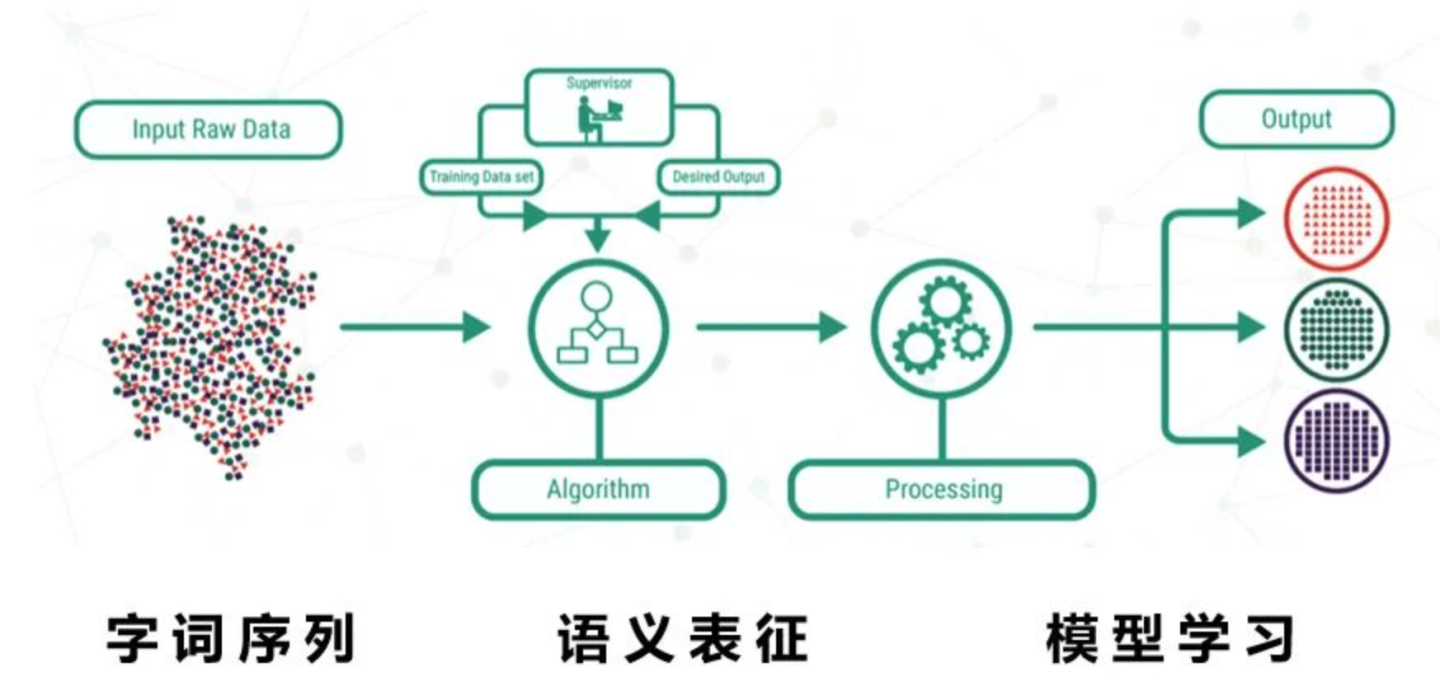
NLP里的有监督任务的范式,可以归纳成如下的样子。
输入是字词序列,中间一步关键的是语义表征,有了语义表征之后,然后交给下游的模型学习。所以预训练技术的发展,都是在围绕怎么得到一个好的语义表征(representation)的这一层次,逐渐改进的。

语义特征计算分为三个阶段,分别是
一、特征工程阶段,以词袋模型为典型代表
二、浅层表征阶段,以word2vec为典型代表
三、深层表征阶段,以基于transformer的Bert为典型代表
这样分法,我有点不服气呢,那为啥有个阶段要搞词语义部分【如 中文分词、词性标注、句法分析、语义parse】呢?这个阶段叫“中间任务”,主要是因为NLP技术发展不够高的一种体现,如早期的“机器翻译”比较困难,就把难题分而治之,分解为分词、词性标注、句法分析等各种中间阶段。
针对,这三个阶段,稍微展开下,后续有机会,在重点展开说下
1.2 词袋模型
统计每个维度在文档中次的数量,问题是语义局限于字面相同与否,如apple和苹果,在语义上是有强关联的,但在词袋模型就gg了。

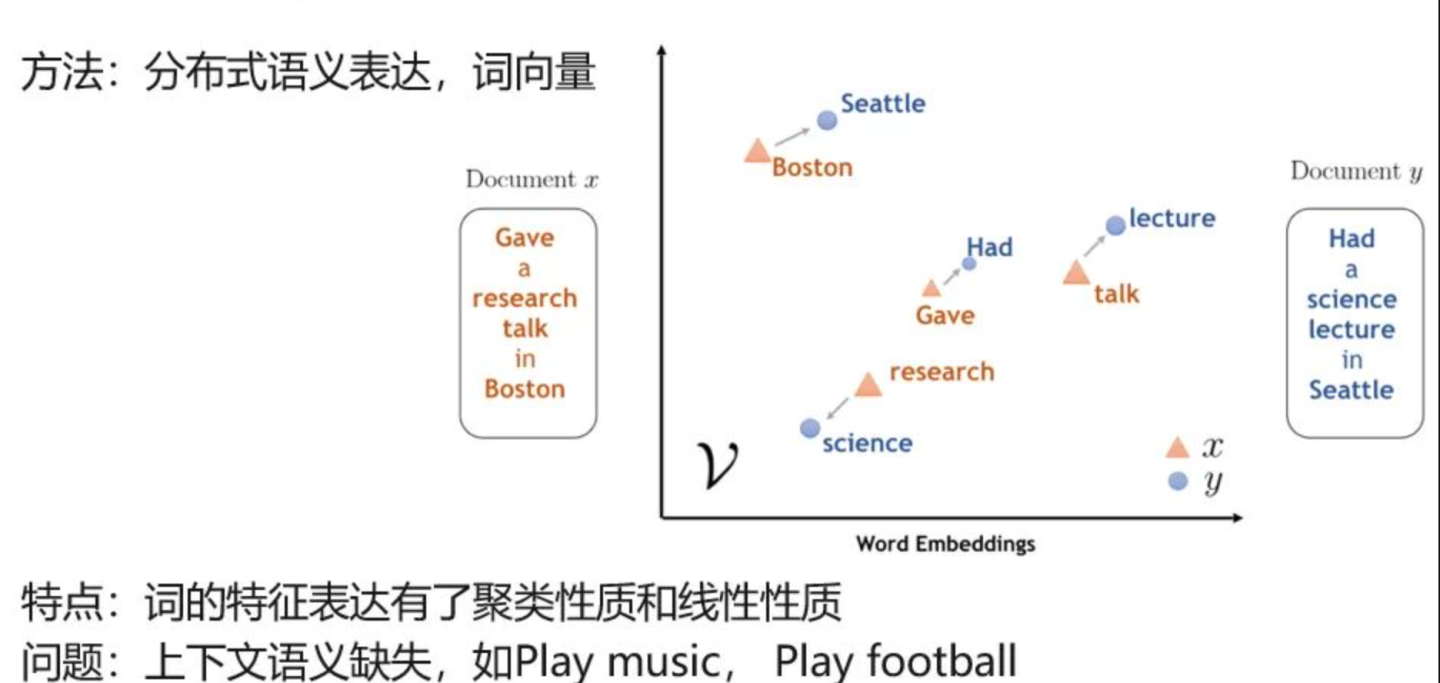
1.3 词向量
词的表征具有聚类性质和线性特征,解决关键问题是语义表征,能将一句话进行向量化语义表征出来,但不能解决上下文语义,如play music和play football,同一个play没办法区分开是打球还是弹琴。
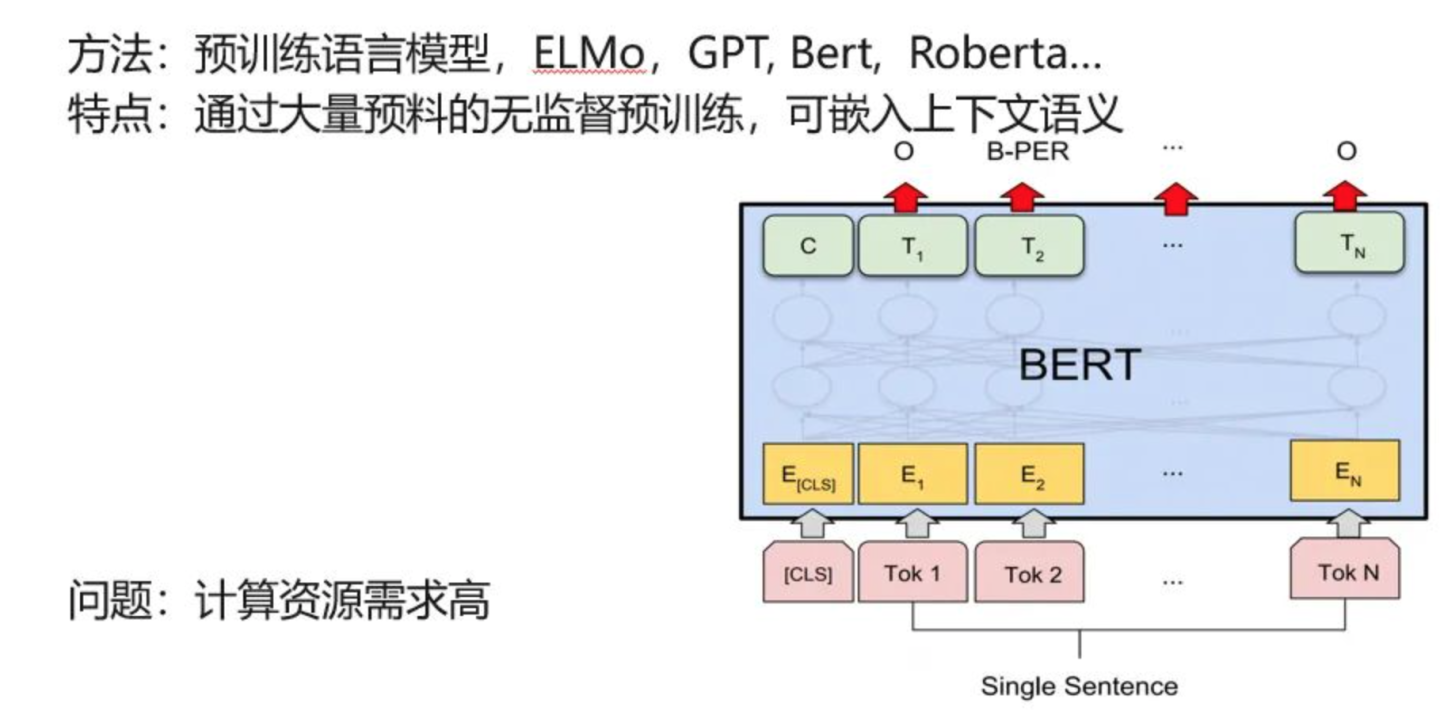
1.4 预训练语言模型
通过大量语料无监督训练,提取语义表征信息,然后用于下游任务微调,如完形填空、文本分类、QA问答等,最有代表性是bert,简直在18年后,横少天下,专治各种不服的。
注:从时间轴来看
在2016年前后:语义表征逐步升级网络深度,网络越复杂,能表征能力越强
在2018年后,语义表征更侧重语义理解,谁能更好理解语义内容,那效果会更好。
2、GPT历史演进
2.1 宏观:从GPT1/2到GPT3

基于文本预训练的GPT-1,GPT-2,GPT-3 三代模型都是采用的以Transformer为核心结构的模型,在网络模型层面不同的是模型的层数和词向量长度等超参。
2.2 GPT-1:基于 Transformer Decoder 预训练 + 微调 Finetune
Generative Pre-Training GPT,主要指 NLP 生成式的预训练模型。
训练模式分为2阶段:
第 1 阶段预训练:利用语言模型 LLM 进行预训练学习
第 2 阶微调:通过微调 Fine tuning 解决下游任务
2.3 GPT-2:舍弃微调,直接利用 zero-short learning
GPT-2 在 GPT-1 已有网络结构设计上使用了更大网络和更大数据集,并且在训练和预测过程中一次预测一个单词,以此来训练一个能够 zero-short learning 的语言模型。
针对小样本/零样本的 N-shot Learning 应运而生,分为如下三种:
1) Zero-shot Learning (零样本学习):没有任何训练样本进行微调训练的情况下,让预训练语言模型完成特定任务;
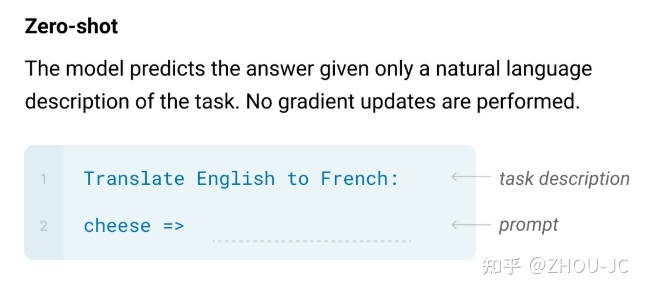
就给出任务描述,那请给出prompt内容,注:这种零样本学习是比较有挑战的
2)One shot Learning (单样本学习):在一个训练样本进行微调训练的情况下,预训练语言模型完成特定任务;

给出具体任务描述,并给出一个示例,那请给出prompt内容
3)Few-shot Learning (少样本或小样本学习):在只有少量样本进行微调训练的情况下,预训练语言模型完成特定任务;

给出具体任务描述,并给出3个示例,那请给出prompt内容
2.4 GPT3:开启 NLP 新范式 prompt,实现小样本学习
初代GPT-3展示了三个重要能力:
-
语言生成:遵循提示词(prompt),然后生成补全提示词的句子。这也是今天人类与语言模型最普遍的交互方式。
-
上下文学习 (in-context learning): 遵循给定任务的几个示例,然后为新的测试用例生成解决方案。很重要的一点是,GPT-3虽然是个语言模型,但它的论文几乎没有谈到“语言建模” (language modeling) —— 作者将他们全部的写作精力都投入到了对上下文学习的愿景上,这才是 GPT-3的真正重点。
-
世界知识:包括事实性知识 (factual knowledge) 和常识 (commonsense)。
-
事实性:李白是诗人,司马迁撰写《史记》
-
常识:太阳从东边升起来,人有两条腿+一双手
这些能力来自于如下方面:

pretrain阶段:
3000亿单词的预料数据,预训练1750亿参数模型,模型是沿用了GPT-2的结构,但是在网络容量上做了很大的提升。其中5个不同的语料,分别是60%低质量的Common Crawl,22%高质量的WebText2,16%Books1和Books2、3%Wikipedia等。
通过如此大规模预训练后,可以得出上述能力是因为:
-
语言生成的能力来自于语言建模的训练目标 (language modeling)。
-
世界知识来自 3000 亿单词的训练语料库(多类别数据源)。
-
模型的 1750 亿参数是为了存储知识(知识密集型任务的性能与模型大小息息相关)。
-
上下文学习的能力来源及为什么上下文学习可以泛化,这种能力可能来自于同一个任务的数据点在训练时按顺序排列在同一个 batch 中。此刻,我想还要强调下”In-context learning“,我们需要先理解meta-learning(元学习),对于一个少样本的任务来说,模型的初始化值非常重要,从一个好的初始化值作为起点,模型能够尽快收敛,使得到的结果非常快的逼近全局最优解。元学习的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果。
prompt阶段:
常规NLP任务:QA问答、sentence相似性、闭卷问答,模式解析,机器翻译等效果较好
其他领域任务:数学加法,文章生成,编写代码等比较惊艳
注:Prompt-Tuning的动机旨在解决目前传统Fine-tuning的两个痛点问题
-
降低语义差异(Bridge the gap between Pre-training and Fine-tuning):预训练任务主要以Masked Language Modeling(MLM)为主,而下游任务则重新引入新的训练参数,因此两个阶段的目标通常有较大差异,因此需要解决如何缩小Pre-training和Fine-tuning两个阶段目标差距过大的问题;
-
避免过拟合(Overfitting of the head):由于在Fine-tuning阶段需要新引入额外的参数以适配相应的任务需要,因此在样本数量有限的情况容易发生过拟合,降低了模型的泛化能力,因此需要面对预训练语言模型的过拟合问题。
那一会说了Fine-tunning,一会又说了promping,那到底Fine-tuning vs Prompting有什么区别?
Fine-tuning:预训练语言模型通过微调适配到各种不同的下游任务。具体体现就是通过引入各种辅助任务 loss,将其添加到预训练模型中,然后继续 pre-training,以便让其更加适配下游任务。
Prompting:各种下游任务能力上移到预训练语言模型。需要对不同任务进行重构,使得它达到适配预训练语言模型的效果。这个过程中,是下游任务做出了更多的牺牲,但是能够更好地统一语言模型范式。但在GPT-3使用In Context Learning和BERT使用Fine-tunning都提供一些例子给LLM,但本质上Fine-tunning是那例子数据训练模型,利用反向传播去更新LLM参数,In Context Learning是拿例子数据让LLM看一眼,不去update模型参数,这个意味着LLM没有经历学习过程,但为啥看一眼就能神奇效果,比较费解。
2.5 提示(Prompt Learning)学习 vs 指示学习(Instruct Learning)
相同点:
指示学习和提示学习目的都是挖掘语言模型本身具备的知识。
区别点:
Prompt 是激发语言模型的补全能力,如根据上半句生成下半句,或是完形填空等。
Instruct 是激发语言模型的理解能力,通过给出更明显的指令,让模型去做出正确的行动。
举个case:
提示学习:补全这句话的内容 [ 给爱人买了这个钻戒,她很喜欢,这个钻戒太____了 ]
指示学习:判断这句话的情感 [ 给爱人买了这个钻戒,她很喜欢。A=好;B=一般;C=差 ]
3、BERT
3.1 bert架构

Pre-training阶段:基于海量数据,预训练自回归大模型,如何评测预训练阶段效果呢?1、mask lm,即为将部分token mask ,然后预测masked 的token,通过计算交叉熵函数;2、NSP,即为上下文token是否有联系
Fine-Tunning阶段:在具体某个任务上【QA、NER、文本分类等】,加载预训练大模型,在下游海量样本数据上微调模型
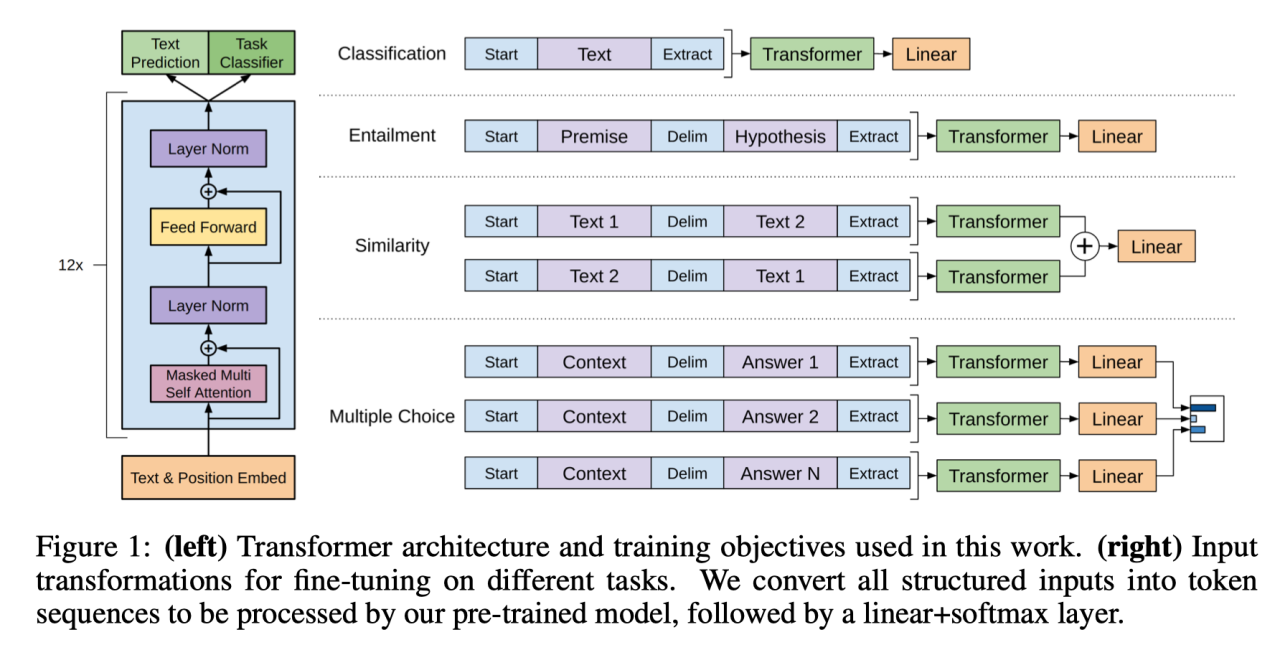
3.2 下游任务
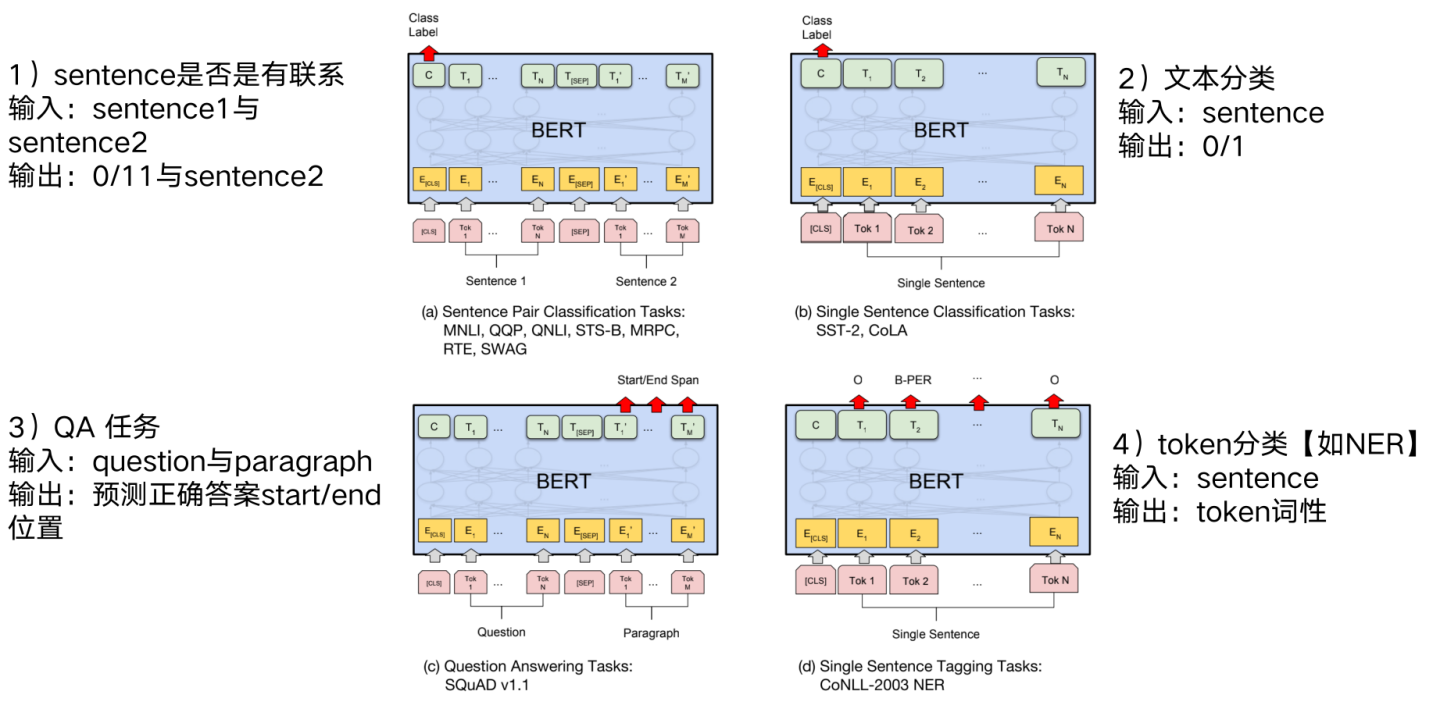
3.3 预训练架构
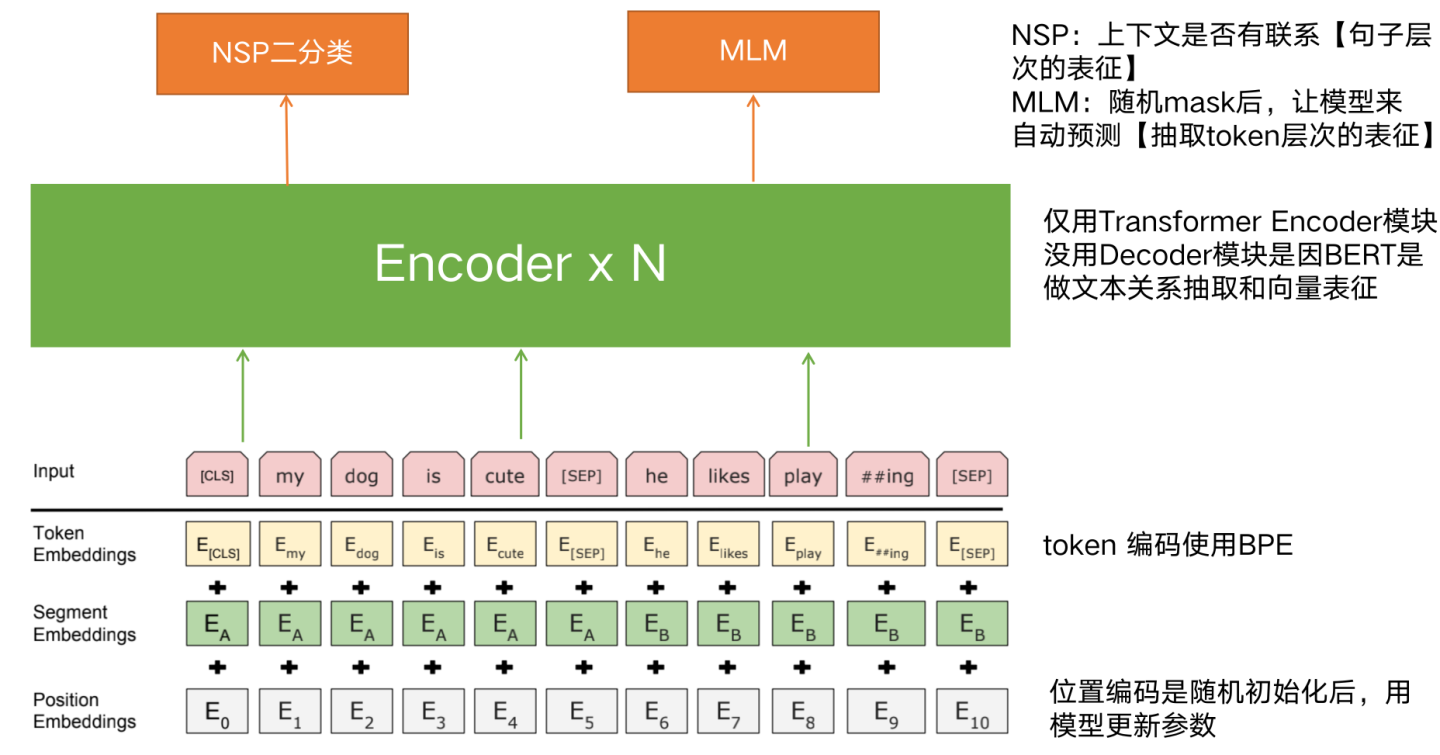
先将文本token编码+位置编码,送入N层的encoder网络,进行MHA+FNN等
从Transformer的结构看,模型参数由两部分构成:MHA+FFN
-
多头注意力(MHA)占了参数总体的1/3,
-
FFN总参数集2/3。
MHA主要用于计算单词或知识间的相关强度,并对全局信息进行集成,更可能是在建立知识之间的联系,大概率不会存储具体知识点,而LLM模型的知识主体是存储在FFN结构里。
为什么会存储在FFN结构里?这部分比较复杂,先不展开了,但先说个结论是“低层FNN存储词法、句法等低层知识,中层和高层存储语义等事实概率知识”。
注:在预训练阶段,FFN某层节点存储过时的或者错误知识,因为我们语料数据中就是有部分错误的,那该如何解决呢?这里我挖个坑,后续专题解答下。
3.4 Fine-tuning是什么?
预训练语言模型通过微调适配到各种不同的下游任务。具体体现就是通过引入各种辅助任务 loss,将其添加到预训练模型中,然后继续 pre-training,以便让其更加适配下游任务。
注:上文已经解释过,再啰嗦一下。
4、GPT vs BERT
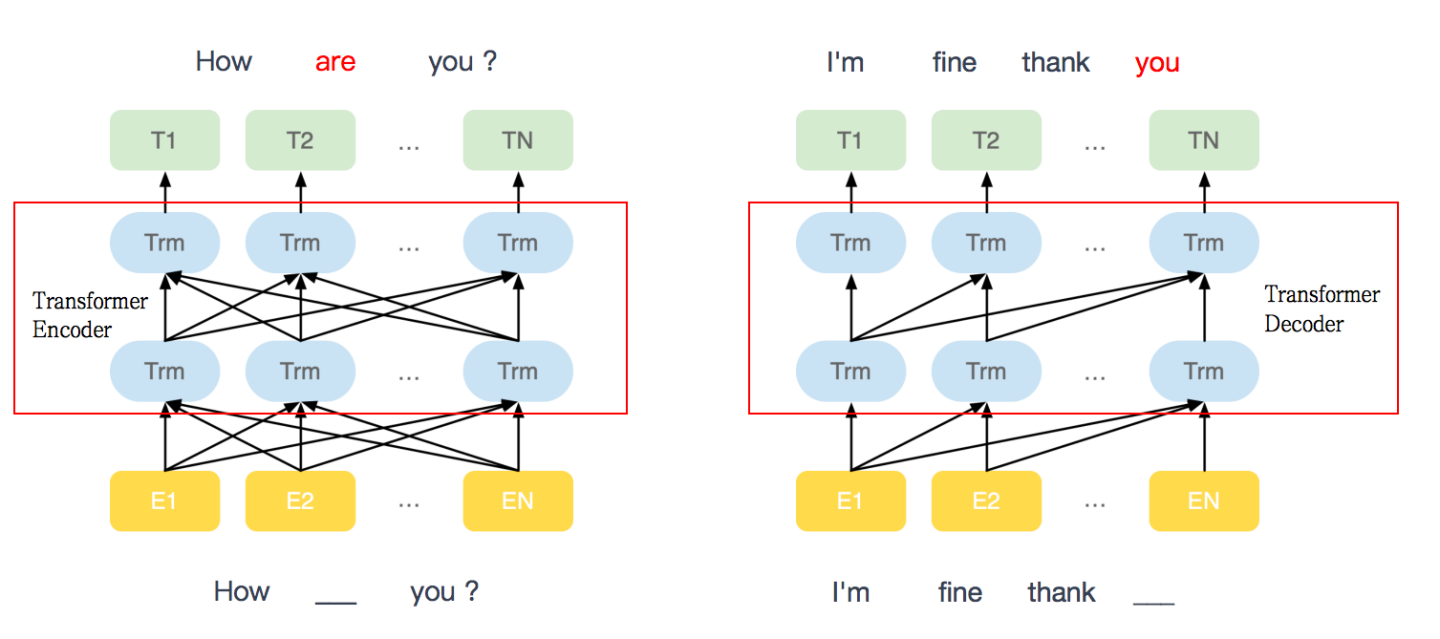
BERT
-
基于transformer框架 encoder模块
-
双向语言模型(masked language model)
-
语言理解能力更强,给定周围几个词,预测中间被挖空的词,如预测中间’are‘这个单词
GPT
-
基于transformer框架 decoder模块
-
单向语言模型(马尔科夫链)
-
语言生成能力更强,给前几个词,预测下一个词,如预测’you‘这个单词
注:Masked Multi-Head-Attention 就是在处理当前词的时候看不到后面的词。
如:处理 [it] 的时候,看不到 [it] 后面的词,但会关注到 [it] 前面词中的 [a, robot],继而注意力会计算词间 [a, robot, …, it] 的向量及其 Attention分数的加权和,即QKV的权重。

5、chatGPT 总体框架
5.1 能力演示
1)理解自然语言能力

2)回答问题
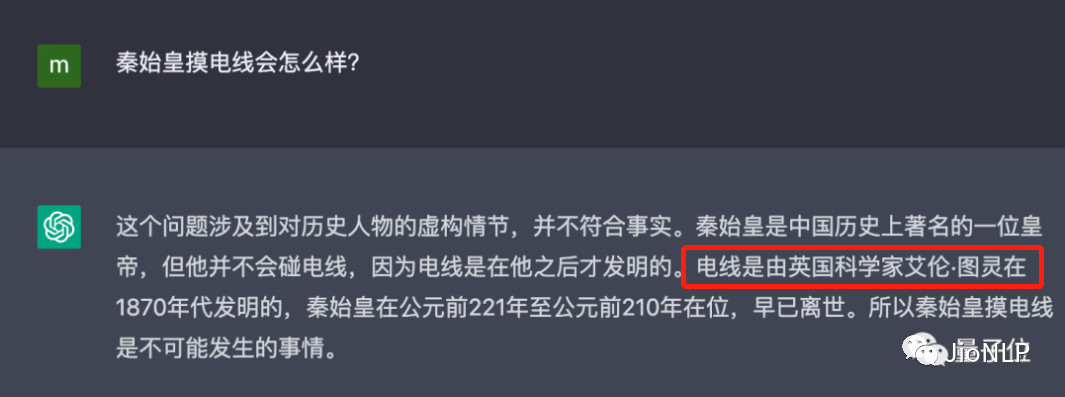
3)写文章


4)编程能力
如优化模型场景

5)参加高考

6)自我学习和自我更新

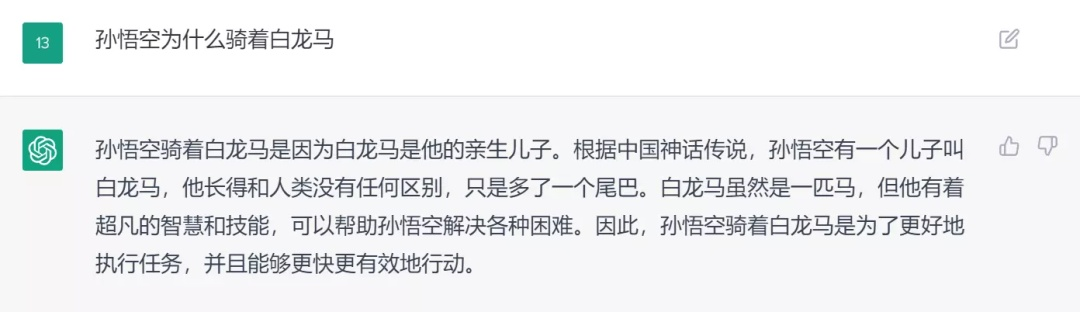

chatGPT会有自我学习能力,通过跟人类沟通和人类反馈,如果发现自己错了,那会自我改进和学习
综上所述,chatGPT拥有自然语言处理、机器翻译、聊天机器人、多智能体、对话引擎等多种能力,可以回答你的问题、做出有用的反馈、生成有趣的内容、学习新的技能等。
5.2 从GPT-3到chatGPT

2020年7月,openai发布初代GPT-3版本,代号为davinci,从此开始不断进化。
2021年7月,openai发布codex版本,基于120亿参数的GPT-3版本微调,代号为Code-davinci-001、Code-cushman-001。
2022年3月,openai发布InstructGPT【指令微调 】版本,代号为Instruct-davinci-beta、Text-davinci-001。
2022年4月~7月,openai发布LM+code预训练并增加指令微调版本,代号为Code-davinci-002,这个阶段已进化到GPT-3.5系列。
2022年5月~6月,openai发布Text-davinci-002是基于Code-davinci-002的有监督指令微调模型。
2022年11月,同时发布Text-davinci-003和chatGPT,是基于人来反抗的强化学习版本指令微调模型。
注:text-davinci-003恢复了(但仍然比code-davinci-002差)一些在text-davinci-002 中丢失的部分上下文学习能力(大概是因为它在微调的时候混入了语言建模) 并进一步改进了零样本能力(得益于RLHF),那更擅长上下文学习方面。另一方面,ChatGPT 似乎牺牲了几乎所有的上下文学习的能力来换取建模对话历史的能力,那更擅长对话方面。
从2020年到22年11月份,openai做这些项目人员投入占比是

ChatGPT 团队成员参与人数最多的是 CodeX 项目
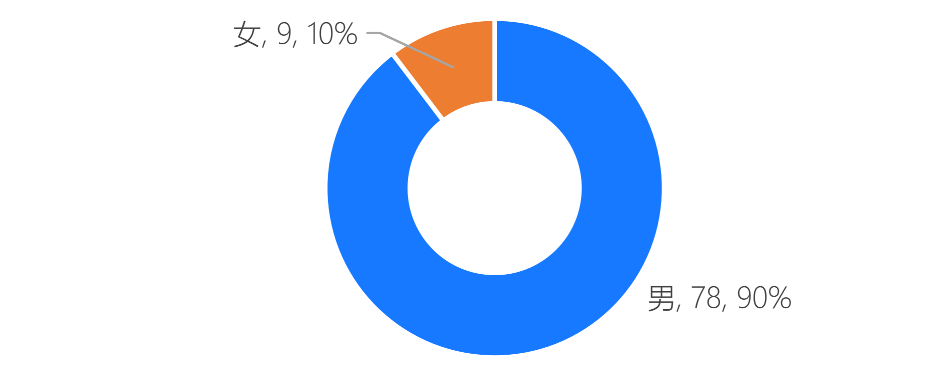
团队由男性主导,女性仅占 1 成
5.3 chatGPT架构

在我们使用chatGPT时候,我们输入一个问题,如”世界最高山峰是哪一座?“,可能会给出来多个答案,如 A1:喜马拉雅山,A2:富士山,为什么会这样呢?因为chatGPT并不知道哪个是最好的,只能通过预训练预料数据中找到概率最好的答案组合,所以需要依赖一个老师来教chatGPT学习,到底哪个答案更好,而老师积攒经验丰富的答案,如 Q1:时间最高山峰是哪一桌?A1:喜马拉雅山,Q2:世界最深的海在哪里?A2:死海。
那老师具体怎么教chatGPT呢?主要是教chatGPT生成一个答案后,具体能得多少分,这个过程要让chatGPT 有辨识好、坏能力,回答好的答案要排在差的答案前面。
在实际跟人类交互的过程,会通过人类的实时反馈,做灵活适配,增加人类个性化因素,要保证每个人“口味不一”,所以要不断调整策略,通过奖惩策略,不断进化chatGPT,变成最懂你的小助理。
5.4 chatGPT训练流程
当前AI遇到问题
基于prompt范式的AI生成模型虽然取得巨大的成功【AI写小说,AI写代码,AI画图甚至AI做视频】,但生成式模型很难训练,以语言模型为例,大多是采用“自回归生成”的方式,通过循环解码的方式来逐字或逐词生成内容。训练时往往简单的基于上下文信息去预测下一个词,然后用交叉熵来计算每个词的loss。显然这种token-level的loss不能很好的从整体输出的层面去指导模型优化方向。
当前解决方案
训练阶段,如果直接用人的偏好(或人的反馈)来对模型整体的输出结果计算reward或loss,基于这个思想,便引出了本文要讨论的对象——RLHF(Reinforcement Learning from Human Feedback):即为使用强化学习的方法,利用人类反馈信号直接优化语言模型。
所以,chatGPT是通过如下:通过3个阶段完成
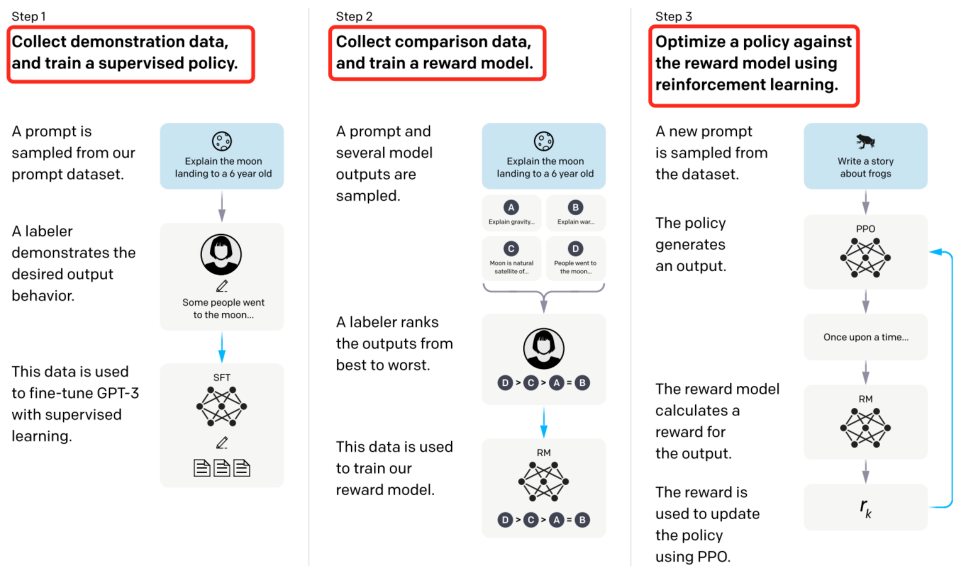
注:蓝色箭头代表,数据被用于训练模型,如预训练模型、RM模型、RL模型
阶段1:预训练语言模型(LM)

初始化预训练模型【输入文本(长序列),输出文本(单个token)】,只要能保证输入prompt,模型能预测一段文本,语料数据格[prompt,text]。
在这个阶段重点是先要做预训练模型,跟GPT3类似做法,然后再做SFT微调,加载预训练模型,提供部分数据集,让模型promt预测一段文本,让在人类标注员更正为期望输出内容,最终实现fine-tune GPT3模型。
阶段2:收集数据并训练奖励模型
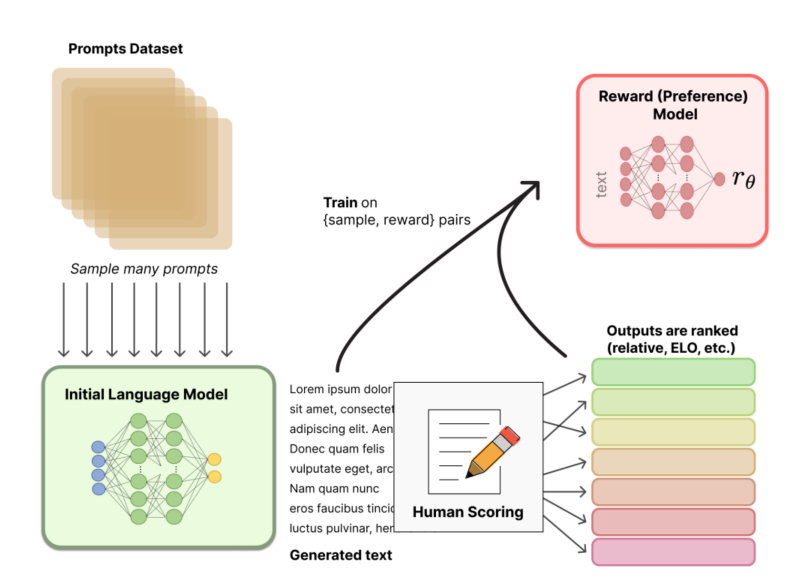
一个奖励模型(RM)的目标是刻画模型的输出是否在人类看来表现不错。即,输入 [提示(prompt),模型生成的文本] ,输出一个刻画文本质量的标量数字。标注人员对初始化语言模型生成的文本排序【不给打分,就是排个相对顺序】。
做法是“pair-wise”,即给定同一个prompt,让两个语言模型同时生成文本,然后比较这两段文本哪个好。最终,这些不同的排序结果会通过某种归一化的方式变成标量信号(即point-wise)丢给模型训练。
RM模型选型:基于预训练语言模型(LM),输入文本,输出是一个标量,代表对结果的rank score打分
rank模型:pair-wise loss方式训练
为什么引入RM模型?
RM模型不能全部对应强化学习中reward,因为一部分是从rm模型根据人类偏好给出的打分,另一部分是参与强化学习的gpt和原始版本sft的某种差距---我们不希望差距太大,所以通过增加偏置项,担心在强化学习训练过程中通过某种刁钻的方式取悦人类,没有根据人类的问题给出正确答案。奖励函数是在完整一个动作后,才给奖赏的,在中间的过程中是不给出奖赏的。
阶段3:通过强化学习微调 LM
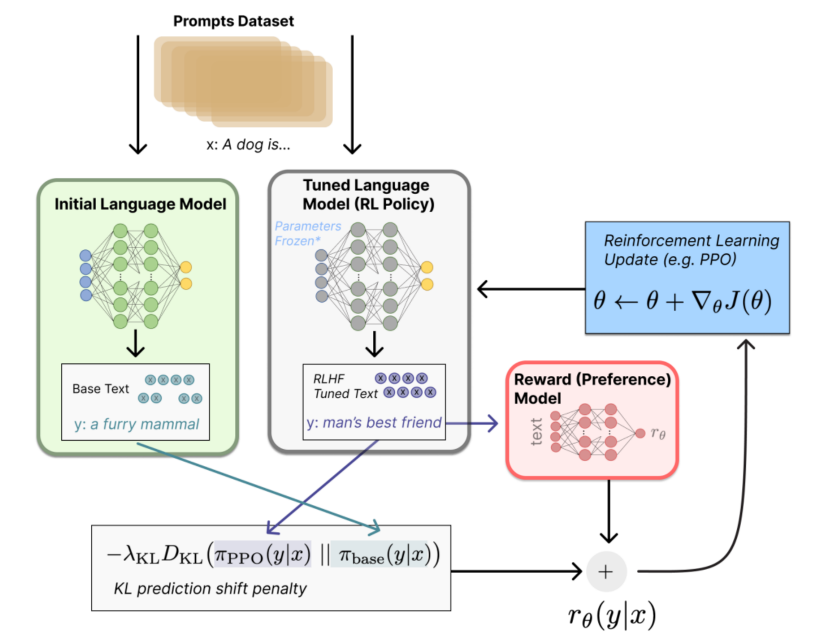
核心思路是”用RM给输出结果打分,再用RL方式反馈学习,对比初始GPT模型,不断迭代“。
策略【policy】:基于该语言模型,接收prompt作为输入,然后输出一系列文本(或文本的概率分布);
动作空间【action space】:词表所有token在所有输出位置的排列组合(单个位置通常有50k左右的token候选);
观察空间:可能的输入token序列(即prompt),显然也相当大,为词表所有token在所有输入位置的排列组合;
奖励函数【reward function】:训好的RM模型,配合一些策略层面的约束进行的奖励计算。
具体怎么计算得到奖励(reward):
基于预先富集的数据,从里面采样prompt输入,同时丢给初始的语言模型和我们当前训练中的语言模型(policy),得到俩模型的输出文本y1,y2。然后用奖励模型RM对y1、y2打分,判断谁更优秀。显然,打分的差值便可以作为训练策略模型参数的信号,这个信号一般通过KL散度来计算“奖励/惩罚”的大小。显然,y2文本的打分比y1高的越多,奖励就越大,反之惩罚则越大。这个reward信号就反映了文本整体的生成质量。
有了这个reward,便可以根据 Proximal Policy Optimization (PPO) 算法来更新模型参数了。
迭代式的更新奖励模型(RM)和策略模型(policy),让奖励模型对模型输出质量的刻画愈加精确,策略模型的输出则愈能与初始模型拉开差距,使得输出文本变得越来越符合人的认知。
5.5 数据集
由于chatGPT没有公开训练数据细节,所以我从instructGPT论文得到部分细节内容
1) 数据源类别

-
通用生成数据占比45.6%,如:讲一个故事
-
开放性QA问答占比12.4%,如:情人节送爱人什么礼物
-
头脑丰富占比11.2%,如:列出来5个职场建议
-
聊天记录占比8.4%,如:23年干什么行业最赚钱
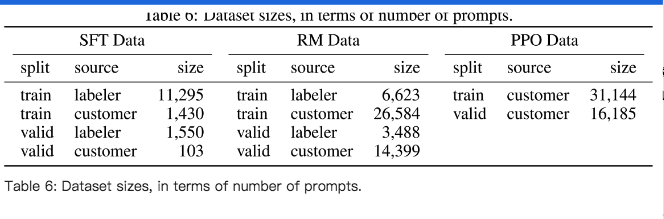
2) 训练样本规模

-
SFT Data,包含1.3W的prompts,来源:API请求和人工标注
-
RM Data,包含3.3W的prompts,来源:API请求和人工标注
-
PPO Data,包含3.1W的prompts,来源:API请求
具体细节,可看如下表格
3) 人工标注

在 Upwork 上和通过 ScaleAI 聘请了一个由大约40名标注人员组成的Team。
将标注者分为经过训练【在房间里帮助标注者回答问题,同个任务下有同样的偏好】和没训练两组,但再对比后发现,两组标注一致性很高73±4%
针对通用性生成数据,要求”有益的、真实的、无害的“,可看下如下描述

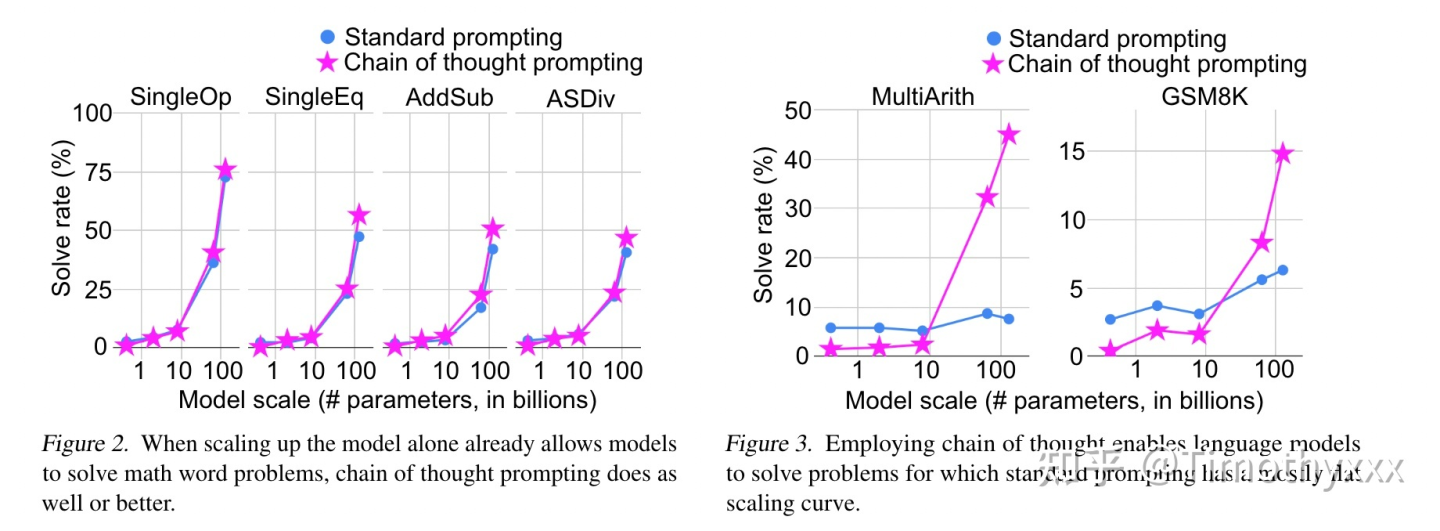
5.6 思维链 (chain-of-thought)
这个词,最近频繁是一个高频词,那到底什么是思维链?思维链是一种离散式提示学习,更具体地,大模型下的上下文学习(即不进行训练,将例子添加到当前样本输入的前面,让模型一次输入这些文本进行输出完成任务),相比于之前传统的上下文学习,即通过x1,y1,x2,y2,....x_test作为输入来让大模型补全输出y_test,思维链多了中间的一些闲言碎语絮絮叨叨,以下面这张图为例子:

思维链的絮絮叨叨即不直接预测y,而是将y的“思维过程”r(学术上有很多学者将这种过程统称为relationale)也要预测出来。当然最后我们不需要这些“思维过程”,这些只是用来提示获得更好的答案,只选择最后的答案即可。
作者对不同的数据集的原本用于上下文学习的提示标注了这些思维链然后跑了实验,发现这么做能够显著的提升性能(左图),且这种性能的提升是具有类似于井喷性质(右图)的(后来他们发文号称这种性质叫涌现性)。
如此厉害的东西,那chatGPT是如何具备的?
看了知乎这个解答,感觉这个能力很迷。

我有一天跟同事聊这个问题,他跟我说,能具备这种类似”涌现能力“,大概率是依赖海量数据训练后,才会具备这个能力,也没有特别好的解释原因。
后来自己想下,能否是chatGPT利用code data训练呢?或者任务评价指标不够平滑,如:大多数模型预测的字符串和真值做匹配,没有完全匹配上即为错误,当模型足够大,输出正确能力提升明显,会有“涌现”的现象,这2种情况【code data可能性更高】还真的是有可能的,理由是”初代 GPT3 的模型思维链推理的能力很弱甚至没有。code-davinci-002 和 text-davinci-002 是两个拥有足够强的思维链推理能力的模型。“,所以大概率是使用思维链进行复杂推理的能力很可能是代码训练的一个神奇的副产物。理由入下:
-
最初的 GPT-3 没有接受过代码训练,它不能做思维链。
-
text-davinci-001 模型,虽然经过了指令微调,但第一版思维链论文报告说,它的它思维链推理的能力非常弱 —— 所以指令微调可能不是思维链存在的原因,代码训练才是模型能做思维链推理的最可能原因。
-
PaLM 有 5% 的代码训练数据,可以做思维链。
-
Codex论文中的代码数据量为 159G ,大约是初代 GPT-3 5700 亿训练数据的28%。code-davinci-002 及其后续变体可以做思维链推理。
以上所有观察结果都是代码与推理能力/思维链之间的相关性。代码和推理能力/思维链之间的这种相关性对研究社区来说是一个非常有趣的问题,但目前仍未得到很好的理解。然而,仍然没有确凿的证据表明代码训练就是CoT和复杂推理的原因。 思维链的来源仍然是一个开放性的研究问题。此外, 代码训练另一个可能的副产品是长距离依赖,正如Peter Liu所指出:“语言中的下个词语预测通常是非常局部的,而代码通常需要更长的依赖关系来做一些事情,比如前后括号的匹配或引用远处的函数定义”。这里我想进一步补充的是:由于面向对象编程中的类继承,代码也可能有助于模型建立编码层次结构的能力。
注:面向过程的编程 (procedure-oriented programming) 跟人类逐步解决任务的过程很类似,面向对象编程 (object-oriented programming) 跟人类将复杂任务分解为多个简单任务的过程很类似。
6、未来思考
openai发布的chatGPT给大家带来太多颠覆性认知,原来ai行业还能这样玩啊,尤其是对NLPers,本以为”基于bert预训练+下游任务微调“,已经是一招吃天下方案了,当时公司有需求【场景分类、翻译、信息抽取等】,那优选先预训练或者加载公开bert模型,基于公司数据,再下游微调下,分分钟跑起来,简单调下参数,搞定了^_^。听起来这个行业已经有天花板了,效果不好,就赖数据不行,那就专项补数据呗,或者说场景不适合,反正怎么都能找个理由解释下,但就没人想过为啥”GPT+RM+RL“这铁三角组合,就能搞出来颠覆性产品呢,注:”谷歌+facebook+微软+其他公司“等都曾经探索过,但效果一般般呢?从2个维度理解:“公司+技术”
公司:openai对自我定位比较清晰和明确,就是在挑战人类难题,所以定位比较高,并坚定不移地探索和挑战,能做出来chatGPT有一个不受外界干扰,还有一个原因是大家对一家创业公司是有包容心的,但换一家大公司,那就不太可能。
技术:openai坚定选择生成式自回归模型GPT,其实GPT-1比Bert早出来的,虽然bert已经证明双向语言模型在NLP理解任务效果比GPT好,但还在走生成这条路,而且还在尝试zero shot/few shot等,但那个时候效果比bert+fine-tuning效果差远了,但后来GPT-3出现,强大的zero shot/few shot prompt等能力,后来InstructGPT探索,增加openai团队信心,最终出现chatGPT产品。我们想下,这个过程中,我们国内,有多少人在用GPT落地和探索,大概率都在选择“bert+fine-tunning”吧。为啥生成式自回归模型就能行呢?如下是摘自于张俊林老师原味,不做任何修改

“首先,Google的T5模型,在形式上统一了自然语言理解和自然语言生成任务的外在表现形式。如上图所示,标为红色的是个文本分类问题,黄色的是判断句子相似性的回归或分类问题,这都是典型的自然语言理解问题。在T5模型里,这些自然语言理解问题在输入输出形式上和生成问题保持了一致,也就是说,可以把分类问题转换成让LLM模型生成对应类别的字符串,这样理解和生成任务在表现形式就实现了完全的统一。
这说明自然语言生成任务,在表现形式上可以兼容自然语言理解任务,若反过来,则很难做到这一点。这样的好处是:同一个LLM生成模型,可以解决几乎所有NLP问题。而如果仍然采取Bert模式,则这个LLM模型无法很好处理生成任务。既然这样,我们当然倾向于使用生成模型,这是一个原因。
第二个原因,如果想要以零示例提示语(zero shot prompting)或少数示例提示语(few shot prompting)的方式做好任务,则必须要采取GPT模式。现在已有研究(参考:On the Role of Bidirectionality in Language Model Pre-Training)证明:如果是以fine-tuning方式解决下游任务,Bert模式的效果优于GPT模式;若是以zero shot/few shot prompting这种模式解决下游任务,则GPT模式效果要优于Bert模式。这说明了,生成模型更容易做好zero shot/few shot prompting方式的任务,而Bert模式以这种方式做任务,是天然有劣势的。这是第二个原因。
”
那在中国公司,还有哪些机会呢?或者说有哪些经可以取的?
我有些悲观的说,想做个中国版的chatGPT,不超过3~4家公司,这个事情也就是大厂能做出来了【大家都看好百度】,创业者还是洗洗睡了吧。理由是”数据+算力+人才+场景“,缺一不可。
数据:要具备不同种类的海量数据
算力:全中国能有1000台以上A100 高带宽显卡【200G/s】的GPU机器能有几家公司,或者有能力做大规模训练数据语料【不能低于chatGPT】+降低模型参数量【1/4 x 1750B】,模型效果不低于chatGPT效果。
人才:”一个大牛带一堆小弟“搞,是中国惯有模型,看下openai 团队,人人都是行业佼佼者,注:强化学习方面人才要重点投入
场景:从人类需求方面思考,”衣食出行“等行业,我们能做个什么产品呢?可以参考如下场景:
-
智能客服、问答:向用户提供个性化的问答服务,例如情感分析、问题分类、智能问答、能推荐、智能问答、智能聊天机器人等。
-
社交媒体营销:利用社交媒体平台进行营销,利用各种社交媒体工具来推广品牌、产品和服务,提升公司和品牌的知名度。
-
内容创作:创作原创文章、图片、视频等内容,从而吸引更多用户,建立起企业的知名度。
-
网络研究:通过网络研究,了解消费者行为,更好地满足消费者需求。
-
电子商务:利用互联网开设网上商城,销售产品和服务,扩大企业的影响力。
-
移动应用开发:为智能手机、平板电脑、智能设备等开发应用软件,满足用户对移动互联网的需求。
-
网络安全:提供有效的网络安全保护及管理服务,确保企业网络的安全性。
那真要做这个事情,应该怎么落地呢?
第一步:预训练生成大模型LM,可以参考nanoGPT代码魔改下,
第二步:训练奖励模型RM,难点是要标注场景数据,计算方案参考推荐系统pair-wise loss训练模型即可,
第三步:强化学习PPO模型,这部分我还在探索和落地,暂时没有发言权,但招聘做强化学习的人才,可以去尝试下。
第四步:组建工程化团队,chatGPT能做成,个人觉得是工程团队很强
openai开放api接口后,可以做的事情更多了。
-
紧跟微软大腿,如ChatGPT版必应Bing搜索、ChatGPT版Azure云计算平台
-
Notion产品
-
企业私人订制,如万科与微软Azure OpenAI合作落地,客户反馈分析平台搭载GPT-3
所以 能做的产品很多的,特别适合中国国情发展需要,但我觉得可以考虑下训练语料数据,公开的图像和文本能爬取是有限的,但能生产某个领域行业数据,那是更核心武器。
GPT-4要来了,转向多模态,更具颠覆性影响了,将图像+音频+文本等结合,那可以做的产品更多了,谷歌发布5620亿参数多模态模型PaLM-E,机器人操控无所不能还有微软发布Visual ChatGPT:视觉模型加持ChatGPT实现丝滑聊天。
参考资料

